




AI 애플리케이션에 적합한 Milvus 배포 모드를 선택하는 방법
Milvus는 수십억 개의 벡터 임베딩을 저장, 색인, 검색하는 오픈 소스 벡터 데이터베이스입니다. 또한 대규모 언어 모델(LLM에서 환각 문제를 완화하는 데 널리 사용되는 효과적인 기술인 검색 증강 생성(RAG)에 없어서는 안 될 구성 요소입니다.)
Qdrant](https://zilliz.com/comparison/milvus-vs-qdrant), Weaviate, Chroma 등 다른 오픈 소스 벡터 검색 프로젝트와는 달리, Milvus는 개발자에게 데이터 세트의 크기, 사용 사례, 비즈니스 요구 사항에 맞는 세 가지 주요 배포 옵션을 제공합니다. 선택의 폭이 넓다는 것은 장점이지만, 다소 부담스러울 수도 있습니다. 많은 개발자가 특정 AI 애플리케이션에 가장 적합한 배포 모드를 선택하는 방법을 잘 모릅니다. 이 블로그 게시물에서는 프로젝트에 적합한 Milvus 버전을 선택하는 데 도움이 되는 명확하고 자세한 가이드를 제공합니다.
Milvus Lite 대 독립형 대 분산형 비교
Milvus는 세 가지 배포 옵션을 제공합니다: 밀버스 라이트, 독립형, 분산형.
밀버스 라이트
밀버스 라이트는 파이썬 라이브러리이자 밀버스의 초경량 버전입니다. 파이썬 또는 노트북 환경에서의 빠른 프로토타이핑과 소규모 로컬 실험에 적합합니다. pymilvus패키지를 통해pip install pymilvus` 한 줄로 바로 설치할 수 있습니다. 별도의 서버를 실행할 필요가 없으며 로컬 파일을 사용하여 데이터 지속성을 처리하므로 설정과 사용이 간편합니다.
밀버스 스탠드얼론
Milvus Standalone은 클라이언트-서버 모델을 사용하는 Milvus의 단일 노드 배포 옵션입니다. Milvus Lite는 SQLite와 비슷하지만, Milvus에 해당하는 MySQL이라고 생각하시면 됩니다. 모든 Milvus 독립형 구성 요소는 Docker 이미지에 번들로 제공되므로 서버 배포가 간단합니다. 충분한 메모리를 갖춘 컴퓨터에서 단일 Milvus Standalone 인스턴스를 실행하면 광범위한 확장이 필요하지 않은 대부분의 프로젝트에서 잘 작동합니다. 또한 Milvus Standalone은 기본 백업 모드를 통해 고가용성을 제공하므로 프로덕션 환경에서 신뢰할 수 있는 선택이 될 수 있습니다.
Milvus 분산형
Milvus Distributed는 대규모 벡터 데이터베이스 시스템이나 벡터 데이터 플랫폼을 구축하는 기업 사용자에게 이상적인 Milvus의 분산 모드입니다. 읽기-쓰기 분리가 가능한 클라우드 네이티브 아키텍처를 채택하여 성능을 최적화합니다. Milvus Distributed의 주요 구성 요소에는 백업 및 추가 인스턴스가 내장되어 있어 한 부분에 장애가 발생하더라도 다른 부분이 원활하게 이를 대신하여 시스템을 중단 없이 유지할 수 있습니다. 이러한 수준의 이중화는 안정성을 향상시키고 [지속적인 가용성]을 보장합니다(https://zilliz.com/learn/ensuring-high-availability-of-vector-databases). 세 가지 배포 옵션 중 Milvus Distributed는 가장 높은 확장성과 가용성을 제공합니다. 또한 구성 요소 수준의 탄력성을 제공하여 특정 비즈니스 부하 요구 사항에 따라 프록시, 쿼리 노드, 인덱스 노드를 독립적으로 확장할 수 있습니다.
아래 표는 Milvus Lite, Milvus Standalone, Milvus Distributed의 주요 기능을 요약하여 비교한 것입니다.
| 기능 | Milvus Lite | Milvus Standalone | Milvus Distributed | **기능 |
| SDK | Python | Python, Go, Java, Node.js, C#, RESTful | Python, Go, Java, Node.js, C#, RESTful | |
| 데이터 유형 | 고밀도 벡터스파스 벡터 이진 벡터 부울 스칼라 정수 스칼라 부동 스칼라 문자열 배열 JSON | 고밀도 벡터 스파스 벡터 이진 벡터 부울 스칼라 정수 스칼라 부동 스칼라 문자열 배열 JSON | 고밀도 벡터 스파스 벡터 이진 벡터 부울 스칼라 정수 스칼라 부동 스칼라 문자열 배열 JSON | 고밀도 벡터 스파스 벡터 부울 스칼라 정수 스칼라 부동 스칼라 문자열 배열 JSON |
| 검색 | 벡터 검색(ANN 검색)필터링된 벡터 검색 범위 검색 하이브리드 검색 스칼라 식 쿼리 기본 키 쿼리(get) | 벡터 검색(ANN 검색)필터링된 벡터 검색 범위 검색 하이브리드 검색 스칼라 식 쿼리 기본 키 쿼리(get) | 벡터 검색(ANN 검색)필터링된 벡터 검색 범위 검색 하이브리드 검색 스칼라 식 쿼리 기본 키 쿼리(get) | |
| 기본 CRUD 기능 | ✔️ | ✔️ | ✔️ | ✔️ |
| 고급 기능 | - | RBAC(역할 기반 접근 제어) | RBAC(역할 기반 접근 제어) 샤딩 파티션 파티션 키 물리적 리소스 그룹화 | |
| 정합성 | 강함 | 강함 경계가 설정된 유효성 검사 세션 결국 | 강함 경계가 설정된 유효성 검사 세션 결국 |
Table: Milvus Lite, Milvus Standalone, Milvus Distributed 비교표
각 개발 단계에 적합한 Milvus 배포를 선택하는 방법
애플리케이션 개발 단계에 따라 적합한 Milvus 배포 옵션을 선택해야 합니다. 이러한 단계에는 신속한 프로토타이핑, 초기 프로덕션 배포 및 대규모 프로덕션 배포가 포함됩니다. 각 단계를 자세히 살펴보겠습니다.
AI 애플리케이션의 신속한 프로토타이핑을 위한 Milvus Lite
개인 비서, 시맨틱 검색 엔진 또는 엔드투엔드 RAG와 같은 AI 애플리케이션을 개발 및 프로토타이핑할 때는 일반적으로 성능과 안정성보다 앱 속도와 유연성이 우선시됩니다. 따라서 이 단계에서는 Milvus Lite가 이상적인 선택입니다. 노트북 환경 내에서 엔드투엔드 기능을 빠르게 구축하고 효과 테스트에 초점을 맞춘 가벼운 실험을 수행할 수 있습니다.
대규모 데이터 세트에 대한 유효성 검사를 위해 Milvus Standalone으로 전환하기
대규모 데이터 세트에서 결과를 검증해야 하는 경우 Milvus Standalone이 다음 단계입니다. Milvus Lite와 Standalone은 원활하게 함께 작동하도록 설계되어 로컬 프로토타이핑에서 서버 기반 유효성 검사로 쉽게 전환할 수 있습니다. Milvus Lite, Standalone, Distributed는 동일한 클라이언트 인터페이스를 공유하므로 로컬 및 대규모 데이터 유효성 검사 모두에 동일한 비즈니스 로직을 재사용할 수 있습니다. 또한 Milvus Standalone은 여러 사용자를 지원하므로 애자일 개발 팀이 단일 인스턴스를 사용하여 더 쉽게 협업하거나 데이터를 공유할 수 있습니다.
초기 프로덕션 배포를 위한 Milvus Standalone
프로젝트가 새로 출시되어 제품 시장에 적합성을 찾는 앱 제작 초기 단계에서는 비즈니스 요청과 데이터 양이 상대적으로 적습니다. 인프라보다는 비즈니스 효율성과 경쟁력에 초점을 맞춰야 합니다. Milvus Standalone은 이 단계에 적합합니다. 온라인 서비스의 경우, 고가용성 기본 백업 모드로 Milvus를 배포하면 안정성을 보장할 수 있습니다. 테스트 환경의 경우 일반적으로 단일 노드 배포로 충분합니다.
**참고: Milvus Standalone은 테이블 간에 물리적 리소스 격리를 제공하지 않습니다. 성능에 민감한 중요 애플리케이션이 두 개 있는 경우, 별도의 Milvus Standalone 인스턴스를 사용하여 데이터를 격리하는 것이 좋습니다. 이 경우 리소스 비효율성이 발생할 수 있지만, 현 단계에서 Milvus Distributed 설정을 관리하는 것보다 비용 효율성이 높습니다.
특정 디버깅 작업에는 Milvus Lite를 계속 사용할 수 있지만, 성능 및 안정성 위험이 발생할 수 있으므로 Milvus Standalone이 배포된 프로덕션 환경에서는 사용하지 않는 것이 좋습니다.
대규모 프로덕션 배포를 위한 Milvus 배포
데이터가 단일 서버의 용량을 초과하거나 빠르게 확장되고 있다면 향후 확장성에 대비해야 할 때입니다. 이 단계에서는 밀버스 디스트리뷰티드가 필수적입니다.
이 모범 사례는 처음에는 Milvus Standalone과 Milvus Distributed 인스턴스를 동시에 실행하고 점차적으로 데이터 트래픽을 Standalone에서 Distributed로 전환하는 것입니다. Milvus Distributed가 안정적으로 작동할 때까지 최소 한 달 동안 시스템을 모니터링해야 합니다.
이 단계에서는 운영 관리도 강화해야 합니다. Milvus Distributed는 기본적으로 Prometheus를 지원하며 Attu와 같은 관리 도구를 제공합니다. Milvus는 다양한 전용 운영 도구와 에코시스템 통합을 제공하지만, 대규모 분산 시스템을 관리하는 것은 어려울 수 있습니다. 개방적이고 활발한 Milvus 커뮤니티에 가입하여 지원을 요청하고, 코드를 기여하고, 이벤트에 참석하고, 기타 많은 가치 있는 기여를 하시기 바랍니다.
벡터 데이터 세트에 적합한 배포를 선택하는 방법
Milvus는 프로젝트에 따라 확장할 수 있도록 설계되어 데이터 세트의 진화하는 요구사항에 맞춰 다양한 배포 모드를 제공합니다. 그 차이점을 명확히 하기 위해 Milvus Lite, 독립형, 분산형을 서로 비교하고, 더 중요한 것은 시장에 나와 있는 다른 오픈 소스 벡터 데이터베이스, 즉 Chroma, Weaviate, Qdrant와 비교하는 방법을 분석해 보겠습니다.
특히 소규모 프로젝트를 위한 Chroma는 작년부터 개발자들 사이에서 주목을 받고 있습니다. 밀버스 라이트**와 마찬가지로 크로마는 경량 벡터 데이터베이스입니다. 수십만 개 미만의 벡터를 처리하는 애플리케이션에 가장 적합합니다. Chroma는 벡터 데이터 삽입 및 유사도 검색과 같은 기본 기능을 제공하므로 빠른 프로토타입 제작을 위한 경량 옵션입니다. 그러나 제한된 기능 세트와 프로덕션 준비가 부족하다는 점은 Milvus Lite가 더 강력한 기능을 제공한다는 것을 의미합니다.
프로덕션 준비가 완료된 솔루션의 경우, Milvus Standalone 및 Distributed와 함께 Weaviate 및 Qdrant가 더 강력한 선택입니다. Weaviate는 다양한 업스트림 모델에 대한 기본 지원을 제공하는 AI 애플리케이션과의 통합으로 잘 알려져 있습니다. 반면 Qdrant는 벡터 검색 성능에 중점을 둔 핵심 벡터 데이터베이스 기능에 중점을 두고 있습니다. 그러나 오픈 소스 벡터 데이터베이스 벤치마킹 도구인 VectorDBBench에 따르면 Milvus는 검색 성능에서 여전히 Qdrant를 능가하여 이 분야에서 최고의 경쟁자로 자리매김하고 있습니다.
다음은 각 벡터 데이터베이스에 적합한 데이터 규모에 대한 분석입니다:
그림 2- 벡터 저장 및 검색을 위한 Milvus 대 Chroma 대 Qdrant 대 Weaviate 비교](https://assets.zilliz.com/Figure_2_Milvus_vs_Chroma_vs_Qdrant_vs_Weaviate_for_vector_storage_and_retrieval_5877bdd81a.png)
Milvus Lite와 Chroma**는 최대 100만 개의 벡터까지 데이터 스케일링에 이상적입니다_. 이들은 사용 편의성을 위해 설계되었으며, 단순성을 위해 일부 시스템 기능을 희생했습니다.
밀버스 스탠드얼론, 위비게이트, 큐드란트**: 백만에서 수천만 개의 벡터에 이르는 데이터 규모에 가장 적합합니다. 이러한 데이터베이스는 강력한 시스템 기능과 사용 편의성 간에 균형을 이루고 있어 초기 단계의 프로덕션에 적합합니다.
밀버스 분산: 수천만 개 이상의 데이터 규모를 처리하도록 설계되었습니다_. Milvus 커뮤니티는 수십억 규모의 사용 사례에 대한 지원을 검증했으며, 현재 수백억 개의 벡터가 포함된 상황에 대해 구현되고 있습니다.
Chroma, Weaviate, Qdrant와 같은 다른 벡터 데이터베이스도 나름의 강점이 있지만, Milvus와 같은 수준의 유연성, 확장성, 장기적인 지원을 제공하기에는 부족한 경우가 많습니다. 프로젝트가 성장함에 따라 벡터 데이터베이스를 교체하는 것은 비용이 많이 들고 복잡해질 수 있습니다. 다양한 배포 옵션을 갖춘 Milvus는 다양한 데이터 규모에 걸쳐 혼합 워크플로우를 지원하므로 데이터베이스 솔루션의 규모를 초과하지 않도록 보장합니다.
Milvus Lite, 독립형 및 분산형 기본 구성 요소
Milvus는 공유 기본 구성 요소 덕분에 세 가지 배포 모드에서 일관된 사용자 환경과 균일한 발전을 제공합니다. 이러한 설계는 가벼운 작업에 Milvus Lite를 사용하든 대규모 작업에 Milvus Distributed를 사용하든 동일한 핵심 기능을 활용할 수 있도록 보장합니다.
아래 다이어그램은 이러한 각 Milvus 배포 모드에서 다루는 기능 구성 요소를 보여줍니다:
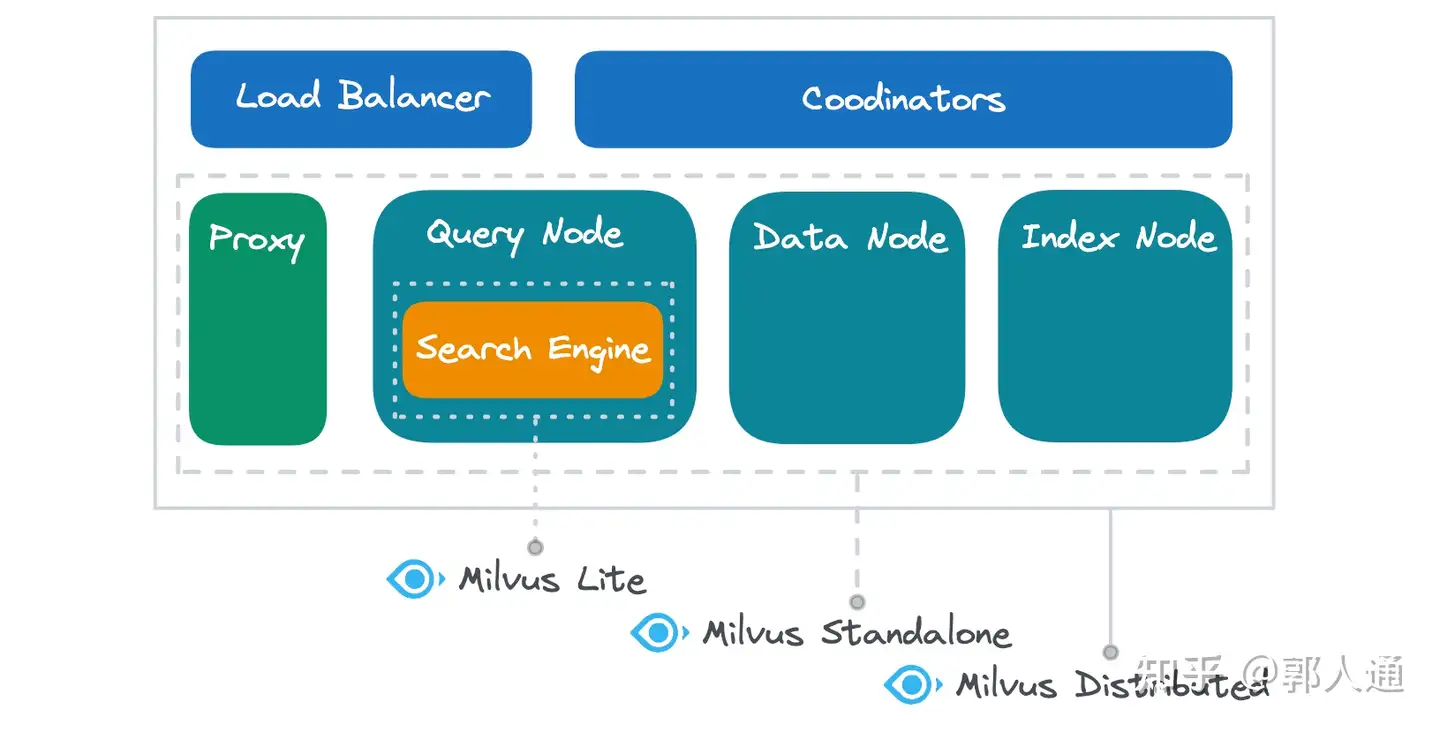 그림 2 Milvus Lite 대 독립형 대 기본 구성 요소에 분산
그림 2 Milvus Lite 대 독립형 대 기본 구성 요소에 분산
Milvus Lite는 주로 검색 엔진을 캡슐화하는 동시에 데이터 삽입, 지속성, 인덱스 구축, 메타데이터 관리와 같은 필수 작업에 대한 로컬 구현을 제공합니다. Milvus Lite는 단순한 도구가 아니라 강력한 라이브러리라고 생각하세요. 밀버스 라이트의 검색 엔진은 크로마와 같은 기본적인 라이브러리에 비해 뛰어난 성능과 쿼리 기능을 제공하므로 벡터 임베딩에 이상적입니다. FAISS](https://zilliz.com/learn/faiss) 또는 HNSWLib의 대안을 찾고 있다면, Milvus Lite는 기본적으로 주류 벡터 검색h 알고리즘 라이브러리를 통합하고 성능과 기능 모두에 대해 광범위한 최적화를 거쳤기 때문에 강력한 후보가 될 수 있습니다.
Milvus Standalone에는 로드 밸런싱과 멀티노드 관리(코디네이터)를 제외한 Milvus 시스템의 모든 기능 구성 요소가 포함되어 있습니다. 이러한 구성 요소는 동일한 Docker 환경 내에서 작동하여 효율적인 로컬 통신을 촉진하고 서버 대기 시간을 최소화합니다.
Milvus Distributed는 다양한 기능 구성 요소를 자랑합니다. 독립형과 분산 모드 모두 동일한 기능을 갖춘 프록시, 쿼리 노드, 데이터 노드, 인덱스 노드를 포함하지만, Milvus Distributed는 배포 유연성이 더 뛰어납니다. 각 기능 구성 요소를 여러 번 배포하여 더 높은 부하를 처리할 수 있으며, 여러 구성 요소를 동일한 물리적 노드에 배포하여 리소스를 공유하거나 다른 노드에 배포하여 리소스 격리를 보장할 수 있습니다. 또한 분산 모드를 사용하면 각 구성 요소를 독립적으로 확장할 수 있으므로 다양한 부하 특성에 적응하고 리소스 활용도를 효과적으로 개선할 수 있습니다.
요약
이 글에서는 Milvus가 제공하는 세 가지 배포 옵션에 대해 살펴보았습니다: Milvus Lite, 독립형, 분산형입니다. 각 배포 모드는 다양한 개발 단계, 데이터 크기 및 사용 사례를 충족하도록 맞춤화되어 있어 Milvus를 프로젝트와 함께 확장할 수 있습니다.
Milvus Lite**는 Python 환경 내에서 신속한 프로토타이핑과 소규모 실험에 이상적입니다. 설정과 사용이 간편하여 테스트 및 개발을 위해 가볍지만 강력한 솔루션이 필요한 개발자에게 적합합니다.
Milvus Standalone**은 프로토타이핑에서 프로덕션으로 전환할 준비가 된 개발자를 위한 다음 단계입니다. 이 단일 노드 배포 옵션은 초기 프로덕션 환경에 필요한 모든 구성 요소를 제공하여 성능과 리소스 효율성의 균형을 맞춥니다. 데이터 크기가 적당하고 사용자 요구가 증가하는 프로젝트에 적합합니다.
Milvus Distributed**는 고가용성, 확장성, 유연성이 필요한 대규모 프로덕션 배포를 위해 설계되었습니다. 대량의 데이터를 다루는 기업 및 애플리케이션을 위한 최적의 선택으로, 비즈니스 요구사항에 따라 벡터 데이터베이스를 확장할 수 있습니다.
추가 리소스
Milvus 문서](https://milvus.io/docs)
검색 증강 생성(RAG)이란 무엇인가요](https://zilliz.com/learn/Retrieval-Augmented-Generation)
벡터 데이터베이스 학습 센터](https://zilliz.com/learn)

계속 읽기

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

The Great AI Agent Protocol Race: Function Calling vs. MCP vs. A2A
Compare Function Calling, MCP, and A2A protocols for AI agents. Learn which standard best fits your development needs and future-proof your applications.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.