




Agentic RAG: 自律型エージェントによる、よりスマートなAI検索
Agentic RAG: 自律型エージェントによる、よりスマートなAI検索
質問をしたときに、単に1つのデータベースを検索するだけでなく、どの情報源を参照すべきかを知的に判断し、見つけた情報を検証し、必要であればより良い結果を得るために質問を言い換える研究アシスタントがいると想像してみてください。これこそが、agentic RAGが人工知能システムにもたらすものです。
従来のRetrieval-Augmented Generation(RAG)システムは、AIアプリケーションが外部知識にアクセスする方法を大幅に改善しましたが、単一の知識源と1回の検索試行に限定された、一本道の思考のように動作します。Agentic RAGは、この直線的なアプローチを、複数の情報源にわたって考え、計画し、行動できる知的で適応的なシステムへと変革し、より正確で包括的な回答を提供します。
Agentic RAGとは?
Agentic RAGは、複雑な情報検索および生成ワークフローをオーケストレーションするためにAI agentsを組み込んだ、Retrieval-Augmented Generationの拡張実装です。固定された検索と生成のシーケンスに従う従来のRAGシステムとは異なり、agentic RAGは、ユーザーのクエリに最適に回答する方法について推論、計画、意思決定を行える知的エージェントを採用しています。
その中核において、agentic RAGはAIエージェントを活用して検索拡張生成を促進し、適応性と正確性によってRAGパイプラインを強化すると同時に、大規模言語モデルが複数の情報源から情報検索を行い、より複雑なワークフローを処理できるようにします。
これらのシステムはLLMをAIエージェントへと変換し、ツール、関数、外部知識源を活用できるようにすることで、標準的なRAG実装よりも高度な情報処理アプローチを生み出します。
Agentic RAGの主な特徴
マルチソース・インテリジェンス: このシステムは、MilvusやZilliz Cloudなどのベクトルデータベースに加え、従来のSQLデータベースを含む複数のデータベースに接続できます。エージェントは、クエリ要件に基づいて、内部文書、外部API、Web検索、専門データベースに同時にアクセスできます。
適応的なクエリ処理: AIエージェントは、時間の経過とともに結果を最適化するために、以前のプロセスを反復できます。初期結果が不十分な場合、エージェントはクエリを言い換えたり、異なる情報源を試したり、複雑な質問を扱いやすいサブクエリに分解したりできます。
知的な計画とオーケストレーション: このアプローチにおけるエージェントは、複数のステップと論理的推論を必要とするタスクを計画し、推論しながら進めることができます。コーディネーターエージェントは、特定のデータ型やドメインに最適化された異なる検索エージェントに、専門化されたタスクを割り当てることができます。
品質検証: 従来のシステムとは異なり、agentic RAGには検索されたコンテンツを評価するための組み込みメカニズムが含まれています。AIエージェントは、時間の経過とともに結果を最適化するために、以前のプロセスを反復できます。この検証レイヤーにより、ハルシネーションが大幅に削減され、回答の正確性が向上します。
ツール統合: さまざまなリトリーバーツールにアクセスできる検索エージェント、例えば、(典型的なRAGパイプラインのように)ベクトルインデックスに対してベクトル検索を実行するベクトル検索エンジン(クエリエンジンとも呼ばれる)、Web検索、Calculator、メールやチャットプログラムなどのソフトウェアにプログラム的にアクセスするための任意のAPIにより、単純な文書検索を超えた包括的な情報収集が可能になります。
Agentic RAGの仕組み
Agentic RAGは、複数のAIエージェントと高度な推論機能を組み合わせた洗練されたアーキテクチャを通じて動作します。システムがクエリを最初から最後までどのように処理するかは次のとおりです。
ステップごとのワークフロー
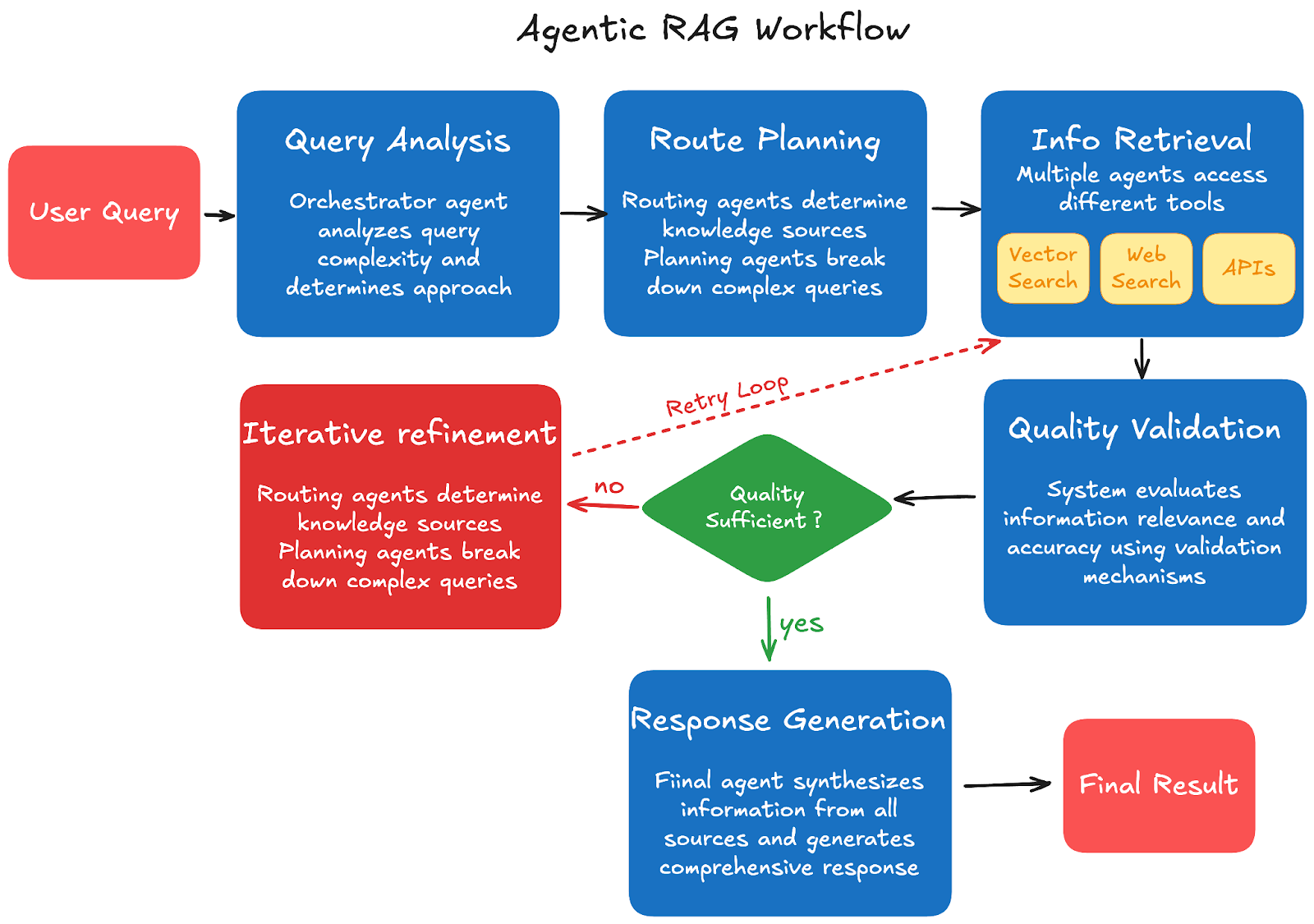
Step 1: クエリ分析: ユーザーが主要なオーケストレーターエージェントにクエリを送信すると、そのエージェントがクエリの複雑さを分析し、必要なアプローチを決定します。システムは、クエリの範囲と複雑さに基づいて、単一または複数の検索ステップが必要かどうかを判断します。
ステップ2:ルート計画: ルーティングエージェントは使用する外部知識ソースとツールを決定し、クエリ計画エージェントは複雑なクエリを管理しやすいサブタスクに分解します。システムは、利用可能なリソースと、包括的な情報を収集するための最も効率的な経路に基づいて実行計画を作成します。
ステップ3:情報検索: 検索エージェントは実行計画に基づいてさまざまなツールにアクセスします。これには、ドキュメントデータベース用のベクトル検索エンジン、最新情報のためのWeb検索、特定のソフトウェアまたはサービスデータのためのAPI、計算タスクのための計算機が含まれます。複数のエージェントが異なるソースで同時に作業し、効率とカバレッジを最大化できます。
ステップ4:品質検証: システムは、組み込みの検証メカニズムを使用して、取得した情報の関連性と正確性を評価します。コンテンツが不十分または無関係な場合、エージェントはクエリを再構成し、検証メカニズムが複数のソース間の一貫性を確認して、信頼できる情報品質を確保します。
ステップ5:反復的な改善: システムは、収集した情報の品質と完全性に基づいて、追加の検索が必要かどうかを判断します。エージェントは改良された検索語で再クエリを実行でき、このプロセスは包括的な回答を提供するのに十分な品質の情報が集まるまで繰り返されます。
ステップ6:回答生成: 最終エージェントは、すべてのソースからの情報を一貫した回答に統合します。検証済みのコンテキストを使用して包括的な回答を生成し、該当する場合は透明性と信頼性を維持するために引用と出典表示を提供します。
エージェントの種類と役割
ルーティングエージェント: ユーザーのクエリに対応するために使用される外部知識ソースとツールを決定します
クエリ計画エージェント: 複雑なクエリを処理し、段階的なプロセスに分解します
ReActエージェント: 動的なワークフロー適応のために推論能力と行動能力を組み合わせます
Plan-and-Executeエージェント: 継続的な調整なしに、多段階ワークフローを独立して処理します
 Agentic RAG workflow.png
Agentic RAG workflow.png
Agentic RAGの利点と課題
Agentic RAGは、従来のアプローチに比べて大きな利点を提供する一方で、いくつかの運用上の考慮事項ももたらします。
利点
精度の向上: 複数ソースによる検証と相互参照により、ハルシネーションが大幅に減少し、回答の信頼性が向上します。複数のナレッジベースにわたって情報を検証するシステムの能力は、従来のRAGでは匹敵できない堅牢なファクトチェックの仕組みを生み出します。
複数ソースの統合: 多様なナレッジベース、API、外部ツールへのアクセスにより、構造化データベース、Web検索、計算機、専門ソフトウェアから包括的な情報収集が可能になります。この汎用性により、システムは複数のドメインからの情報を必要とする複雑なクエリを処理できます。
反復的な改善: 複数の検索および検証サイクルを通じて回答品質を継続的に改善することで、最適でない初期結果を強化できます。システムは各反復から学習し、クエリを再構成し、満足のいく情報品質が達成されるまで検索戦略を改善します。
適応的な問題解決: インテリジェントなルーティングと動的なワークフロー調整により、複雑なクエリに対してプロアクティブに対応します。システムは最適な検索戦略を自律的に決定し、変化するコンテキストに適応し、手動介入や大規模なプロンプトエンジニアリングを必要とせずに予期しないシナリオに対処できます。
課題
コストの増加: より多くのエージェントと反復プロセスには、より多くの計算リソースとトークン使用量が必要となり、従来のRAGと比較して運用費用が2〜3倍に増加する可能性があります。マルチエージェントアーキテクチャでは、複雑なワークフローをサポートするために、より多くのAPI呼び出し、より長い処理時間、追加のインフラストラクチャが求められます。
レイテンシの増加: 複数のエージェント間のやり取り、検証ステップ、潜在的な反復サイクルにより、応答時間が大幅に遅くなる可能性があります。複雑なクエリでは、検索と改善に数回のラウンドが必要になる場合があり、即時応答を求めるリアルタイムアプリケーションにはシステムがあまり適さなくなります。
信頼性の問題: エージェントは複雑なタスクを完了するのに苦労したり失敗したりする可能性があり、ワークフロー内に障害点を生み出します。複数のエージェント間の調整は不安定になることがあり、不完全な応答、無限ループ、または高度なエラー処理メカニズムを必要とする相反する判断につながる可能性があります。
統合の複雑さ: 多様なツール、知識ソースの接続、およびマルチエージェント調整の管理には、高度なオーケストレーションと広範なテストが必要です。システムアーキテクチャは従来のRAGよりも大幅に複雑になり、デプロイ、保守、トラブルシューティングには専門的な知識が求められます。
Agentic RAGとTraditional RAGの比較
 Agentic RAG vs Traditional RAG.jpg
Agentic RAG vs Traditional RAG.jpg
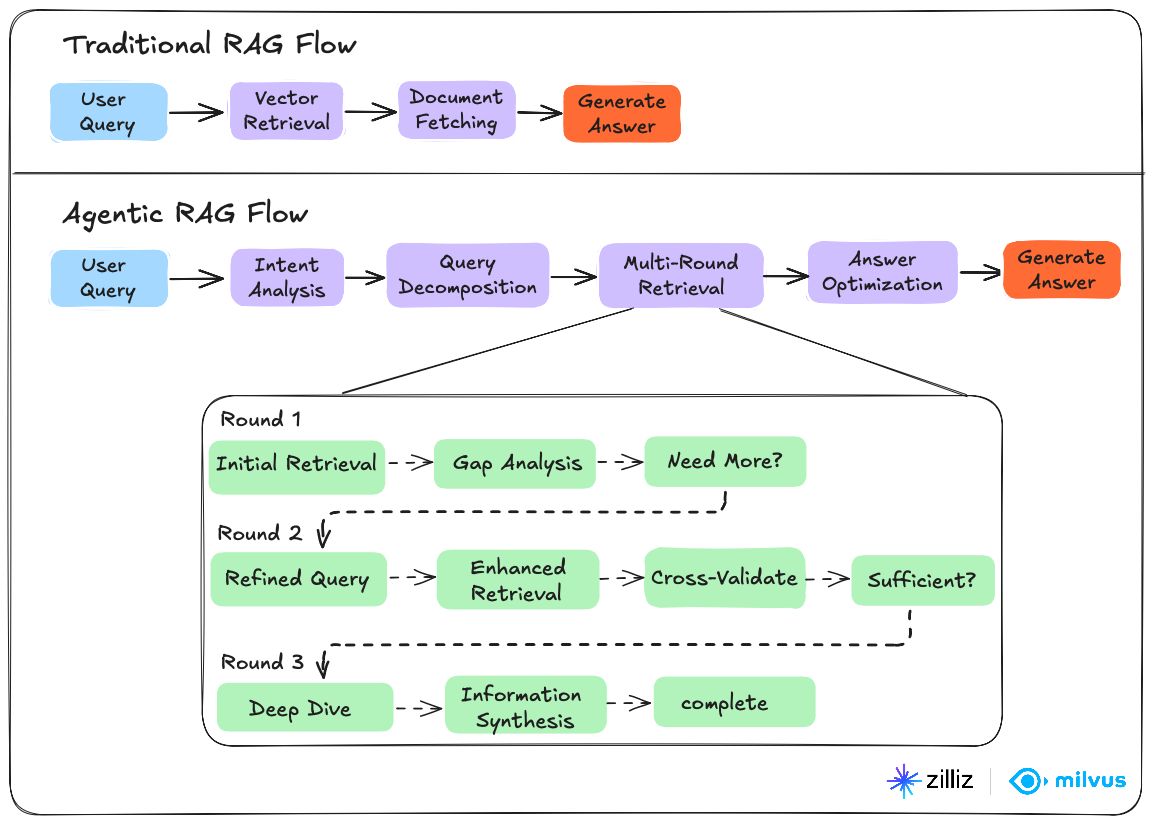
| 特徴 | Traditional RAG | Agentic RAG |
|---|---|---|
| データソース | 単一の知識ベース | 複数のソースと外部ツール |
| クエリ処理 | ワンショット検索 | 多段階の反復的アプローチ |
| 検証 | 組み込みの検証なし | 自動品質評価 |
| 適応性 | 静的、ルールベース | 動的で知的な意思決定 |
| ツールアクセス | ベクトルデータベースに限定 | APIs、Web検索、計算機、外部サービス |
| 計画能力 | 単純な検索と生成 | 複雑な推論とタスク分解 |
| エラー処理 | 手動介入が必要 | 自己修正と再試行メカニズム |
| スケーラビリティ | 単一ソースに制限 | 追加のエージェントとソースに応じてスケール |
| コスト | トークン使用量が少ない | 計算オーバーヘッドが高い |
| 応答速度 | 初期応答が速い | 複雑さに応じて変動 |
Agentic RAGのユースケース
エンタープライズナレッジ管理: エージェント駆動型RAGシステムは、異種のエンタープライズデータから情報を確認し取得することに優れています。企業は、内部文書、データベース、メール、外部の市場インテリジェンスを横断して自動検索し、複雑なビジネス上の質問に答えるシステムを導入できます。
カスタマーサポートの自動化: カスタマーサポートサービスを効率化したい企業は、自動化されたRAGシステムを使用して、より簡単な顧客問い合わせに対応できます。agentic RAGシステムは、より難しいサポートリクエストを人間の担当者にエスカレーションできます。システムは、製品マニュアル、FAQデータベース、顧客履歴、リアルタイムのステータス情報にアクセスして、包括的なサポートを提供できます。
医療情報システム: 医療専門家はagentic RAGを使用して、患者記録、医学文献、医薬品データベース、臨床ガイドラインに同時にアクセスでき、データプライバシーとコンプライアンス基準を維持しながら、より十分な情報に基づいた意思決定が可能になります。
金融意思決定支援: 複数のRAGエージェントは、計算の実行、天気情報の検索、株式および市場トレンドの推奨、データ分析などを行うことができます。金融アナリストは、内部ポートフォリオデータと外部市場情報、規制当局への提出書類、経済指標を組み合わせたシステムにクエリを実行できます。
FAQs
Q: agentic RAGは複数の文書に同時にアクセスできますか?
A: RAGエージェントは、提供された複数のドキュメント内のデータにアクセスし、取得し、比較できます。このシステムは、多様なソースからの情報を1つの回答に統合することに優れています。
Q: エージェント型RAGは標準的なRAGとどのように異なりますか?
A: 従来のRAGは単一のソースから情報を取得できますが、エージェント型RAGは複数のエージェントを使用して、多様なソースからデータにアクセスし、オーケストレーションします。従来のRAGは受動的である一方、エージェント型RAGは能動的で知的です。
Q: エージェント型RAGアプリケーションの構築にはどのフレームワークを使用できますか?
A: RAGエージェントの分析と監視にすぐに使えるコンポーネントやツールを備えたPythonフレームワークがいくつか利用できます。これらのフレームワークには、Phidata、LangGraph、Swarm、Microsoft Autogenなどがあります。
Q: エージェント型RAGは常に従来のRAGより優れていますか?
A: 必ずしもそうではありません。エージェント型RAGは、関数呼び出し、多段階推論、マルチエージェントシステムによって結果を最適化しますが、常により良い選択肢であるとは限りません。単純な単一ソースのクエリでは、従来のRAGのほうが効率的で費用対効果が高い場合があります。
Q: エージェント型RAGは異なるデータタイプに対応できますか?
A: はい、最新のエージェント型RAGシステムはマルチモーダル処理をサポートしており、テキスト、画像、音声、その他の構造化および非構造化データ形式を扱えます。