




Spring AIとMilvus:MilvusをSpring AIベクターストアとして使う
#はじめに
今日の世界では、大量のデータを素早く処理・分析する能力が、アプリケーションの機能を大幅に向上させる。特に人工知能や機械学習のような分野では、データが高次元のベクトル形式で存在することが多い。MilvusのようなベクトルデータベースをSpring AIアプリケーションに統合することで、効率的なデータ処理と検索機能を提供し、このニーズに対応します。この統合により、開発者は複雑なクエリや類似検索を迅速かつ正確に実行できるようになり、より良いユーザーエクスペリエンスとよりインテリジェントなアプリケーションの動作を促進します。
Milvusは、ベクトルデータの管理におけるスケーラビリティとパフォーマンスのために調整された堅牢な機能により、ベクトルデータベースの中で際立っています。オープンソースプラットフォームであるMilvusは、高度なアプリケーション検索機能の活用を検討している企業や開発者に柔軟で費用対効果の高いソリューションを提供します。Milvusは、大規模な非構造化ドキュメント全体の検索パフォーマンスを最適化するために重要な、さまざまなインデックス戦略をサポートしています。このため、画像やビデオ認識、テキスト分析、その他類似検索が重要な領域を含むアプリケーションに最適です。
Spring BootアプリケーションとMilvusを統合するためのセットアップと構成
1.### Docker Composeを使ったMilvusのセットアップ
Spring BootアプリケーションでMilvusとSpring AIを統合するには、Docker Composeを使用してMilvusインスタンスをセットアップすることから始めます。この方法は簡単で、開発環境に適しています。
**手順
Docker ComposeのYAMLファイルをダウンロードします:以下のコマンドを使用して、特定のバージョンのMilvus Docker Composeファイルをダウンロードします:
wget https://github.com/milvus-io/milvus/releases/download/v2.4.0/milvus-standalone-docker-compose.yml -O docker-compose.yml
Milvusインスタンスを起動する:docker-compose.ymlファイルのあるディレクトリに移動し、Milvusインスタンスを起動します:
docker-compose up -d
Docker Compose V2がインストールされていることを確認してください。パフォーマンスと互換性を向上させるために、V1よりもV2が推奨されています。コマンドの実行が完了したら、Docker Desktop(Windows)上でVectorDBの存在を確認できます:
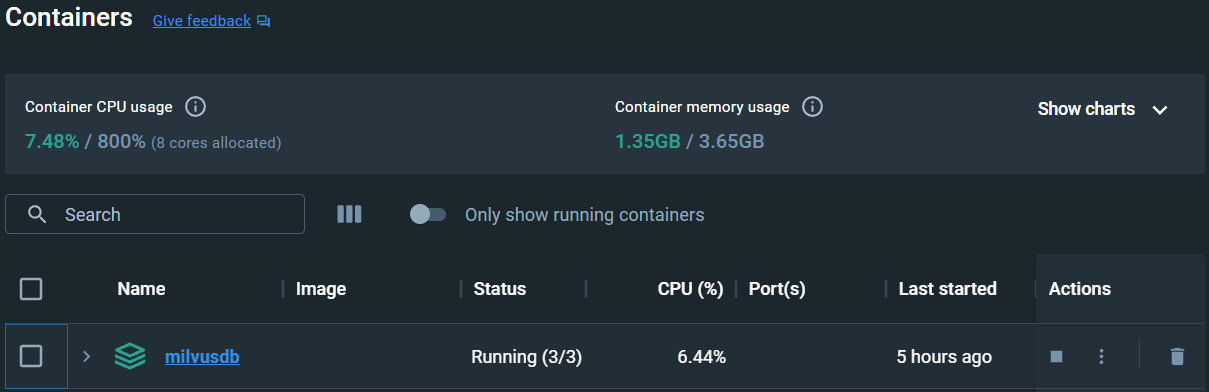
リナックスでは以下のコマンドを実行できる:
docker ps
2.Spring Boot プロジェクトを作成する
プロジェクトを作成する:Spring Initializr](https://start.spring.io/)を使用して、新しいSpring Bootプロジェクトを作成する。ビルドツールとしてMavenかGradle(ここではGradleを使用)を選択し、「Spring Web」や「Spring Data JPA」などの依存関係を追加する。
プロジェクト環境をセットアップする:ダウンロード後、zipファイルを解凍し、好みのIDEでプロジェクトを開く。
Spring Initializr](https://assets.zilliz.com/Spring_Initializr_c580897ff9.png)
3.MilvusとOpenAIの統合のための依存関係の追加
MavenとGradleのどちらを使用しているかによって、MilvusとOpenAIをSpring AIと統合するために必要な依存関係を追加します。
Gradleの場合(build.gradle):
リポジトリ {
mavenCentral()
maven { url 'https://repo.spring.io/milestone' }。
maven { url 'https://repo.spring.io/snapshot' }。
}
依存関係
実装 'org.springframework.ai:spring-ai-milvus-store-spring-boot-starter:0.8.1-SNAPSHOT'
実装 'org.springframework.ai:spring-ai-openai-spring-boot-starter'
実装 'org.springframework.boot:spring-boot-starter-data-jpa'
実装 'org.springframework.boot:spring-boot-starter-web'
// その他の依存関係
}
Spring AIとMilvusの接続: 詳細な設定と使い方
Spring AIのコンテキストでは、Milvusはベクトルデータを保存・管理するバックエンドとして機能し、ベクトルの類似性に基づいて類似したアイテムを迅速かつスケーラブルに検索できるようにする。ここでは、この2つの連携方法を紹介します。
1.Spring BootでMilvusとOpenAIを設定する
application.propertiesまたはapplication.ymlに以下のプロパティを追加して、Milvusへの接続を設定し、OpenAIのエンベッディングを設定します:
application.propertiesの場合:
spring.application.name=demo
spring.autoconfigure.exclude=org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration
spring.ai.vectorstore.milvus.client.host=localhost。
spring.ai.vectorstore.milvus.client.port=19530
spring.ai.vectorstore.milvus.client.username=root
spring.ai.vectorstore.milvus.client.password=milvus
spring.ai.vectorstore.milvus.databaseName=default
spring.ai.vectorstore.milvus.collectionName=vector_store_1
spring.ai.vectorstore.milvus.embeddingDimension=1536
spring.ai.vectorstore.milvus.indexType=IVF_FLAT
spring.ai.vectorstore.milvus.metricType=COSINE
spring.ai.openai.api-key=YOUR_API_KEY
spring.ai.openai.embedding.options.model=text-embedding-ada-002
YOUR_API_KEYはOpenAIから取得した実際のAPIキーに置き換えてください。このセットアップでは、Spring AIとOpenAIのエンベッディングを使用してSpring BootアプリケーションとMilvusを統合するための基本的な設定を提供します。特定の要件や環境に応じて、必要に応じて設定や依存関係を調整してください。
2.サービス内のVectorStoreを自動配線する
Springサービス内でVectorStoreを自動配線し、Milvusデータベースとやり取りします。このようにします:
パッケージ com.example.demo;
インポート java.util.List;
サービス
public class VectorStoreService { {検索リクエスト
@Autowired
private VectorStore vectorStore;
}
3.エンベッディング生成のためのEmbeddingClientの使用.
Milvusに格納できるエンベッディングを生成するには、Spring AIが提供するEmbeddingClientを使用します。その方法は以下の通りです:
パッケージ com.example.demo.controller;
import org.springframework.web.bind.annotation.GetMapping.RequestParnotation; import org.springframework.web.bind.annotation.RequestParnotation
インポートjava.util.List; インポートjava.util.Map; インポートjava.util.Map
インポート java.util.Map; インポート java.util.Map.DataSet
@RestController
public class EmbeddingController {
private final EmbeddingClient embeddingClient;
@Autowired
public EmbeddingController(EmbeddingClient embeddingClient) { 以下のようにします。
this.embeddingClient = embeddingClient;
}
}
Java コード例:ベクトルストレージの実装
ベクトルデータの格納と取り出し
SpringのAIアプリケーションでMilvusのベクトルストレージを効果的に利用するために、開発者はベクトルデータの保存、取得、管理方法を理解する必要があります。以下に、これらの機能を示すJavaコード例を示します。
Milvusへのドキュメントの追加:
サービス
public class VectorStoreService { ベクターストアサービス
@Autowired
private VectorStore vectorStore;
public void addDocuments() { 以下のようにします。
List<Document> documents = List.of(
new Document("Exploring the depths of AI with Spring", Map.of("category", "AI"))、
new Document("Navigating through large datasets efficiently")、
new Document("Harnessing the power of vector search", Map.of("importance", "high"))
);
vectorStore.add(documents);
}
}
類似ドキュメントの検索
public List<Document> searchSimilarDocuments() { 以下のようになります。
return vectorStore.similaritySearch(
SearchRequest.query("Efficient data processing and retrieval")
.withTopK(3)
.withSimilarityThreshold(0.1)
);
}
OpenAIでエンベッディングを生成する:
埋め込みはベクトルベースの検索には欠かせません。ここでは、Spring AIアプリケーション内でOpenAIのサービスを使ってエンベッディングを生成する方法を紹介します:
@RestController
public class EmbeddingController { エンベッディングコントローラ
private final EmbeddingClient embeddingClient;
@Autowired
public EmbeddingController(EmbeddingClient embeddingClient) { 以下のようにします。
this.embeddingClient = embeddingClient;
}
@GetMapping("/ai/embedding")
public Map<String, Object> embed(@RequestParam(value = "message", defaultValue = "What's the latest in AI?") String message) { { EmbeddingResponse embeddingResponse
EmbeddingResponse embeddingResponse = this.embeddingClient.embedForResponse(List.of(message));
return Map.of("embedding", embeddingResponse);
}
}
高度な設定とカスタマイズ
Milvusはベクターの保存と検索を最適化するためのいくつかの高度な設定を提供します。これらにはカスタムインデックス戦略やパフォーマンスチューニングオプションが含まれます。
Milvusの高度な設定例:)
spring.ai.vectorstore.milvus.indexType=HNSW
spring.ai.vectorstore.milvus.metricType=EUCLIDEAN
これらのプロパティをapplication.propertiesファイルに設定することで、HNSW (Hierarchical Navigable Small World)のような異なるインデックス戦略や、距離計算にEUCLIDEANのような異なるメトリックタイプを使用することができます。
Spring AIにおけるMilvusのユースケースと実際のアプリケーション
推薦システム:
Milvusは、ユーザとアイテムのエンベッディングを保存し、類似検索を実行することで、様々な業界のレコメンデーションシステムを強化します。このアプローチは、映画、音楽、商品、コンテンツフィードなどのパーソナライズされたレコメンデーションに特に効果的です。例えば、映画の推薦システムは、Milvusを使用して、ユーザーの嗜好と映画のベクトルを意味的にマッチングさせることができ、明示的なユーザーの問い合わせを必要とせずに、個人の嗜好に沿った映画を提案することができる。詳しくはこちら。
コンテンツ検索エンジン:構造化されていないテキストコンテンツの大規模なデータセットを含むアプリケーションに対して、Milvusはテキストをベクトル形式に変換し、様々な手法で効率的な類似性検索を行うことができる。この機能は、キーワードマッチングにとどまらず、ユーザークエリの意味的文脈を理解し、検索結果の関連性と精度を向上させる洗練された検索エンジンを開発する上で極めて重要である。
課題と解決策
1.**データのスケーラビリティ
膨大な量のベクトルデータを扱うことは困難です。Milvusでは、パーティショニングやシャーディングといった機能により、データを異なるノードに分散することで大規模なデータセットの管理を支援し、パフォーマンスとスケーラビリティを向上させることで、この問題に対処しています。
1.**クエリーレイテンシー
インデックスパラメータの最適化とMilvusクラスタのスケーリングにより、クエリレイテンシを効果的に削減します。MilvusはHNSW、IVF、Product Quantizationのような様々なインデックスタイプをサポートしており、特定のユースケースに合わせて速度と精度のバランスをとることができます。
高度な使用例
**画像・動画認識
Milvusは、ビデオ重複排除システムや画像の類似性検索など、高スループットの画像およびビデオ分析アプリケーションで使用されています。例えば、ShopeeのようなプラットフォームはMilvusを利用し、リアルタイムのビデオ想起や著作権マッチング検索機能を強化しています。
**AI主導のチャットボットとカスタマーサポート
MilvusをAIモデルと統合することで、RAGベースのチャットボットの開発が可能になり、高い関連性と精度でユーザーの問い合わせを理解し、応答することができる。PayPalやFarfetchのような企業は、カスタマーサポートやパーソナライズされたショッピング体験のための会話型AIを強化するためにMilvusを使用しています。
結論
Milvusは、ベクトルデータの効率的な管理と検索を提供することで、Spring AIアプリケーションの機能を大幅に強化する。Milvusの多様性は、様々なドメイン-コマースやエンターテイメントからヘルスケアや金融サービスまで-において、よりインテリジェントで応答性が高く、パーソナライズされたアプリケーション機能を実現することで、業界を変革する可能性を示している。開発者は、Milvusの高度な機能と柔軟な設定オプションを活用してアプリケーションを最適化し、AI主導型ソリューションの新たな可能性を追求することが推奨される。

読み続けて

Zilliz Cloud BYOC Now Available Across AWS, GCP, and Azure
Zilliz Cloud BYOC is now generally available on all three major clouds. Deploy fully managed vector search in your own AWS, GCP, or Azure account — your data never leaves your VPC.

How to Build RAG with Milvus, QwQ-32B and Ollama
Hands-on tutorial on how to create a streamlined, powerful RAG pipeline that balances efficiency, accuracy, and scalability using the QwQ-32B and Milvus.

What is the K-Nearest Neighbors (KNN) Algorithm in Machine Learning?
KNN is a supervised machine learning technique and algorithm for classification and regression. This post is the ultimate guide to KNN.