




Milvusベクトルデータベース入門
ようこそ、Vector Database 101へ! 前回のチュートリアルでは、ベクトルデータベースを簡単に見学し、理想的なベクトルデータベースが実装すべき機能を列挙しました。その後、ベクトルデータベースをベクトル検索ライブラリ[1]およびベクトル検索プラグイン[2]と比較しました。例コードを通じて、ベクトル検索ライブラリもベクトル検索プラグインも、非構造化データの大規模データセットの保存、インデックス作成、検索の面において、必要なの機能をすべて備えていないことがわかりました。だから、ベクトルデータベースの開発者が直面するいくつかの技術的課題を検討するきっかけとなりました。
Milvusの歴史
Milvusの開発は2018年にZillizで始まり、それが世界初のオープンソースベクトルデータベースとなりました。Milvusの最初の構想は、検索アプリケーションを構築およびスケーリングするためのインフラストラクチャでした。そのため、Milvusは当初、非構造化データのためのGoogle/Bingのようなものを目指していました。その当時、ベクトルインデックスと検索戦略は広く使われていましたが、ベクトルデータベースはまだ比較的に未知の概念でした。この過程で、Milvusコミュニティは、Milvusが当初の想定を大きく超える可能性を秘めていることを発見しました。 私たちがMilvusを開発する中で、その概念を洗練し、検索、ストレージ、インデックス作成を組み合わせたものとして、Milvusを完全な管理型データベースにしました。2019年11月、私たちはApache 2.0ライセンスに従って、Milvusをオープンソース化し、最初の広く利用可能なベクトルデータベースソリューションとして一般に公開しました。Milvusのv0.6リリース時点では、主にシングル・インスタンスで作動し、サポートされるインデックスはわずかでした。 2020年3月、MilvusはLinux Foundationの傘下にある非営利団体「LF AI & Data Foundation」に参加しました。この組織の支援を受けて、MilvusコミュニティはAI時代に適したデータベースとしての地位を確立するとともに、より広い範囲でオープンソースコミュニティとの関与を深めることができました。LF AI & Dataに属している間も、MilvusはZillizおよびオープンソースコミュニティの両方から継続的にアップデートを受けています。 同じ年、私たちの最初の完全な学術論文が、世界有数のデータベース会議の1つであるACM SIGMOD 2021に採択されました。また、完全分散型でクラウドネイティブなMilvusのバージョンの開発を開始し、それを適切に「Milvus 2.0」と名付けました。次のセクションで、Milvus 2.0について詳しく説明します。 Milvusは、数多くの開発者がベクトルデータベースについて語るときに最初に思い浮かべるものの1つであり、最も重要なものの1つでもあります。それは主に、Milvusの豊かな歴史、つまり継続的に進化し続ける歴史に繋がっているかもしれません。そしてその歴史には、いつかあなたの活躍も期待しております。
Milvus 2.x
Milvusの歴史について、次にMilvus 1.0(1.x)と2.0(2.x)、そしてそれらの主要な違いについて説明します。 Milvus 1.0は2021年3月にリリースされ、初の主要リリースとなりました。このバージョンは以前のリリースを基盤に構築され、いくつかの類似性メトリクス(ユークリッド/L2距離、ハミング距離、ジャカード類似度など)と複数のANNインデックス(FAISS、HNSW、ANNOY、および標準の転置インデックス)をサポートしました。水平スケーリングは「Mishards」という機能を通じて実現され、ストレージはローカルストレージまたはNFSを通じて行われました。また、Milvus 1.0は、NVidia GPUやXilinx FPGAなど、機械学習エンジニアが使用する汎用計算プロセッサを用いた高速なインデックス作成とクエリをサポートしていました。 Milvus 2.0の最初のバージョンは2021年6月にリリースされ、その同じ月にMilvusはLF AI & Data Foundationの「卒業生」となりました。Milvus 1.xとは異なり、Milvus 2.xのアーキテクチャは完全にクラウドネイティブで、数百の個別ノードまでスケール可能であり、目標可用性/稼働率は99.9%です。また、Milvus 1.xと対照的に、Milvus 2.xはデータ整合性における複数のレベルを取り入れており、アプリケーション開発において最大限の柔軟性を提供します。Milvus 2.xはさらに高度な機能、たとえばマルチクラウド統合、管理コンソール(ZillizのAttu経由)、そして「タイムトラベル」(とはいえ、Milvusはタイムマシンではありませんが…)と呼ばれる機能をサポートしています。これらの成果と、機械学習およびベクトルデータベース分野におけるコミュニティの影響力は、また別のトップクラスの学術会議「VLDB 2022」で認識されました。この会議における私たちの論文を読むことができます。 アプリケーションに使用できるベクトルデータベースを探している場合、私たちはMilvus 2.xを強く推奨します。Milvus 2.xは、Milvus 1.xと比較してまったく斬新なベクトルデータベースシステム/ソリューションであり、非常に高い可用性、スケーラビリティ、分散性を備えています。これらのアーキテクチャ上の進歩により、Milvus 1.xは正式に廃止されました。
Milvusのアーキテクチャ巡り
Milvusの歴史とMilvus 2.xと1.xの違いを説明しましたので、ここでMilvus 2.xのアーキテクチャについて詳しく見ていきます。簡単な復習として、以下はベクトルデータベースが実装すべき主な機能です[3]:
- スケーラビリティと可調整性
- マルチテナンシーとデータの隔離
- 完全なAPIスイート
- 直感的なユーザーインターフェース/管理コンソール 以下の図表を参考にしながら、Milvus 2.0の各個別コンポーネントを確認し、これらの主要な機能をどのように実現しているかを見ていきましょう。
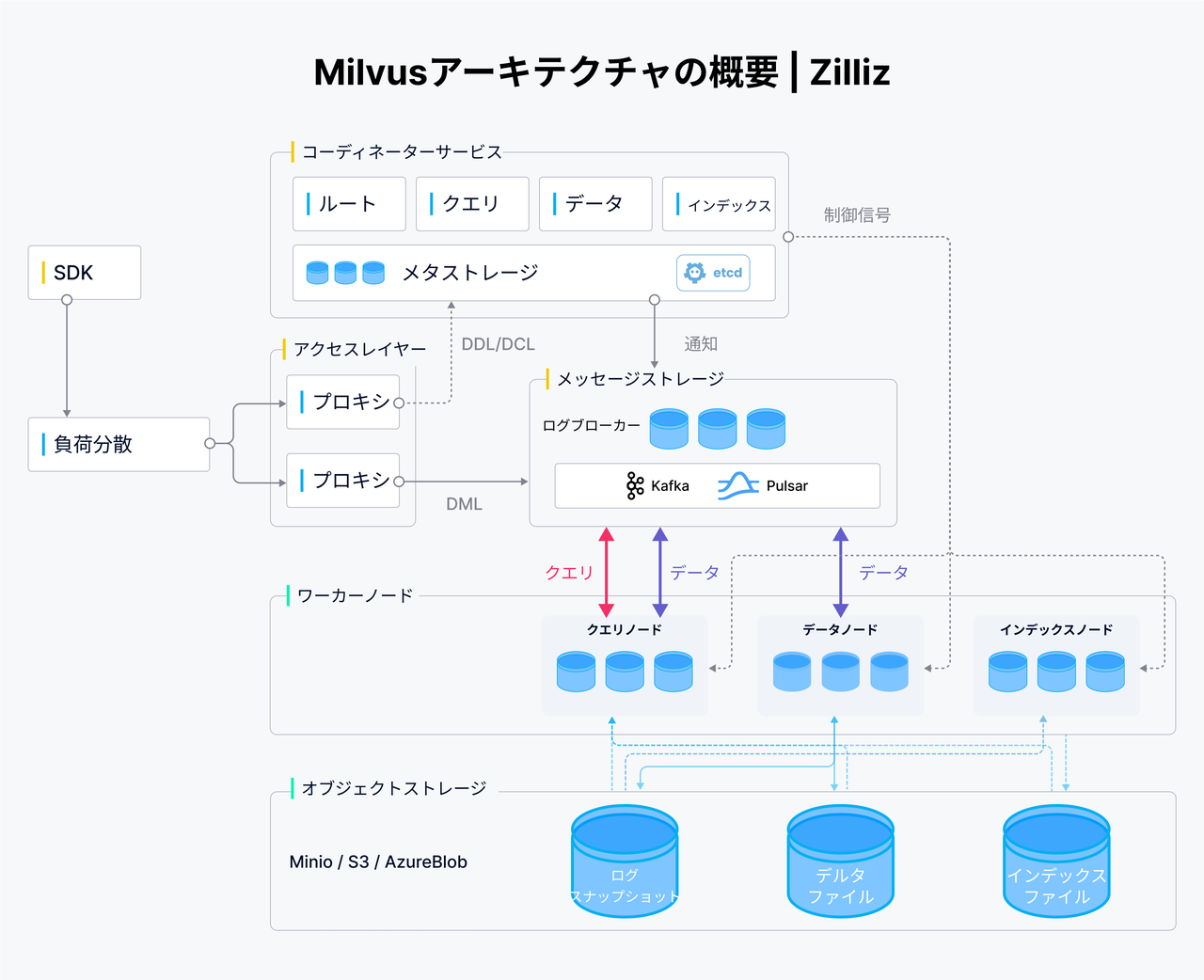 Mivusアーキテクチャの概要
Mivusアーキテクチャの概要
技術的な内容が多く含まれるため、シートベルトを締めて、さっそく始めましょう。
アクセスレイヤー
名前が示す通り、アクセスレイヤーは外部との通信を担当し、「完全なAPIスイート」という機能を実装します。Milvusがリクエストを受け取ると、それはまずアクセスレイヤーに転送され、ここでプロキシがクライアントの接続を処理し、静的検証と動的チェックを実行した後、適切なサービスにリクエストを送ります。ダウンストリームのサービスが実行を完了すると、関連データをアクセスレイヤーに返し、最終的にユーザーに転送されます。 アクセスレイヤー内のプロキシは基本的にステートレスなコンテナであり、Nginx、Kubernetes Ingress、NodePort、LVSなどの負荷分散コンポーネントを通じて外部に統一されたフロントを提供します。Milvusは大規模並列処理(Massive Parallel Processing, MPP)アーキテクチャを採用しており、プロキシはワーカーノードから収集された結果をグローバルなアグリゲーションと後処理を経て返します。
コーディネーターサービス
コーディネーターサービスはMilvusの中央指令センターとして機能し、負荷分散からデータ管理までの全てを担当します。このサービスは以下の4つのコーディネーターで構成されています:ルートコーディネーター、クエリコーディネーター、データコーディネーター、インデックスコーディネーター
- ルートコーディネーターは、コレクションやパーティション、インデックスの作成/削除リクエストなど、データ関連リクエストを処理します。また、グローバルなタイムスタンプを管理します。タイムスタンプとは、ルートコーディネーターがリクエストを受け取る時に、全てのリクエストが割り当てられるものです。
- クエリーコーディネーターは、Milvus内の全てのクエリノードを管理します。その名の通り、クエリノードはインデックスとデルタファイルを用いた検索を実行する役割を持っています。
- データコーディネーターは、Milvus内の全てのデータノードを管理し、メタデータを維持します。また、フラッシュやコンパクトといったバックグラウンドデータ操作をトリガーします。これらの操作については、後のチュートリアルでさらに詳しく説明します。
- インデックスコーディネーターは、インデックスノードとインデックスメタデータを維持します。必要に応じて、生の埋め込みベクトルをロードしてベクトルインデックスを構築/再構築するよう、各ノードに自動的に指示します。
ワーカーノード
Milvus内のワーカーノードは実行を担当します。ワーカーノードは水平にスケール可能なポッドで、Hadoopのデータノードのように、対応するコーディネーターサービスからのコマンドを実行します[4]。例えば、Milvusに与えたクエリリクエストはまずアクセスレイヤー内のプロキシを介し、次にクエリコーディネーターに到達します。クエリクラスターの状態に応じて、コーディネーターはリクエストを正しく実行するために、適切な制御/指令信号をクエリクラスターに送ります。 コーディネーターは対応するワーカーノードとともに、「スケーラビリティと可調整性」および「マルチテナンシーとデータの隔離」というベクトルデータベースの特徴を実現します。スケーラビリティは明らかです。つまり、データ量やクエリ数、インデックス要件の増減に応じて、個々のワーカーノードクラスターはシステム負荷に合わせて水平に拡大/縮小可能です。クエリ、インデックス作成とストレージを分離することで、Milvusは非常に調整可能であり、クエリ/書き込み速度や整合性のレベルが異なるアプリケーションをサポートできます。
オブジェクトストレージ
オブジェクトストレージレイヤーは、Milvusをデータベースたらしめる要素であり、データ永続化の役割を持っています。このレイヤーは以下の3つのコンポーネントで構成されています:
- メタストア:コレクションスキーマ、ノードの状態、メッセージ消費のチェックポイントなど、メタデータのスナップショットを保存します。Milvusは、この機能を提供するために分散型キー値ストアである etcd に依存しています。etcdはサービス登録や健康診断にも利用されます。
- ログブローカー:ログブローカーは、再生機能を持つパブ/サブシステムであり、ストリーミングデータの永続化、堅実な非同期クエリ実行、イベント通知、クエリ結果の返却を担当します。ノードがダウンタイムから復旧する際、ログブローカーは「ログブローカー・プレイバック」機能を通じて増分データの統合性を確保します。Milvusは、分散モードでは「Pulsar」を、スタンドアロンモードでは「RocksDB」をログブローカーとして使用します。また、KafkaやPravegaなどのストリーミングストレージサービスもログブローカーとして利用可能です。
- オブジェクトストレージ オブジェクトストレージ層は、ログスナップショット、インデックスファイル、中間クエリ処理結果を保存します。Milvusは、AWS S3、Azure Blob Storage、とMinIO(軽量でオープンソースのオブジェクトストレージサービス)をサポートしています。ただし、オブジェクトストレージサービスはアクセス遅延が高く、クエリごとの料金が発生するため、Milvusは性能向上とコスト削減を目的にメモリ/SSDベースのキャッシュプールに加えて、ホット/コールドデータの隔離もサポートする予定です。
将来の行き先(最終目標/長期の目論見)
Milvusは、すでに数千の企業に使用され、信頼されており、スケーリングを目的に、実際の生産システムに投入しています。GitHubの統計によれば、Milvusは世界で最も人気があり、最も先進なオープンソースのベクトルデータベースと言えます。また、非構造化データ処理分野での成果は、業界のトップレベルの学術会議(SIGMOD 2021、VLDB 2022)で認められています。 私たちは根っからの技術者コミュニティです。スケーラビリティとパフォーマンスに影響を与える要素に特に注意を払っていますので、Milvusを他のベクトルデータベースソリューションよりも優れたものにしたいと思います。[5]さまざまな高度な機能(異なる種類のインデックス、タイムトラベル、マルチクラウドオブジェクトストレージなど)を備えており、あなたの次の非構造化データアプリケーションには、Milvusは最適な選択と言っても過言ではありません。また、Zillizのおかげで、完全管理型のソリューションという「最後の欠片」も提供されるようになりました。 Milvusの最終目標は、非構造化データ処理のための完全なデータベースとなることです。Milvus 2.xには、すでにクエリ、インデックス作成、ストレージのための高いスケーラビリティと柔軟性を持つアーキテクチャを所有していますが、ベクトルデータベース・エコシステムを完成させるためにさらなる改善する余地はあります。それは、次の要素が含まれます。1) 非構造化データETLの統合、2)Microsoft AzureおよびGoogle Cloud Platformにおけるサポートの拡張、3) リストやJSONオブジェクトなどの伝統的なメタデータ型への対応。 今後数年間で、より広範なるMilvusコミュニティは引き続きMilvusの機能や性能を向上させる予定です。私たちは、Milvusが非構造化データに関連するすべてにおける主要なプラットフォームとなるまで努力を頼らず、頑張って続けます。 Milvusは、非構造化データ処理に革命をもたらしましたが、今後もそれに先立っていくことでしょう。
まとめ
このチュートリアルでは、Milvusの概要、歴史、およびMilvus 1.xと2.xの主な違いを紹介しました。また、Milvus 2.xのアーキテクチャを一通り目を通し、Milvusのアーキテクチャがベクトルデータベースに必要なすべての機能をどのように実装しているかを明らかにしました。 次回以降のチュートリアルでは、Milvusインスタンスを数分で起動して使用するための一連のクイックスタートを提供します:
- 最初のチュートリアル:スタンドアロン版Milvusのクイックスタートを提供し、ローカルx86またはARM/M1インスタンスでMilvusを起動する方法を説明します。
- 2番目のチュートリアル:ローカルマシンでクラスターをエミュレートし、Milvus分散型クラスターの起動方法を示します。
- 3番目のチュートリアル:オンプレミス版Milvusを展開する方法を説明します。 最後に、Milvusコミュニティによる短い動画「Milvusを150秒で紹介」をご覧ください。コーヒーを片手に、前列席でこの動画を楽しんでください!
読み続けて

Why Teams Are Migrating from Weaviate to Zilliz Cloud — and How to Do It Seamlessly
Explore how Milvus scales for large datasets and complex queries with advanced features, and discover how to migrate from Weaviate to Zilliz Cloud.

Vector Databases vs. Key-Value Databases
Use a vector database for AI-powered similarity search; use a key-value database for high-throughput, low-latency simple data lookups.

Top 5 AI Search Engines to Know in 2025
Discover the top AI-powered search engines of 2025, including OpenAI, Google AI, Bing, Perplexity, and Arc Search. Compare features, strengths, and limitations.