




ArXiv Scientific Papers Milvus 2.1によるベクトル類似性検索
#はじめに
最新のデータサイエンスのトピックを学ぶ最良の方法の一つは、arxiv.orgにあるオープンソースの研究論文を読むことである。しかし、膨大な数の研究論文を整理するのは、熟練した研究者でも圧倒されることがあります。connected papers](https://www.connectedpapers.com/)のようなツールは役立ちますが、これらのツールは論文間で共有されている引用と書誌に基づいて類似性を測定するものであり、文書内のテキストの意味論ではありません。
この投稿では、1つの「クエリ」論文を入力とし、最先端のNLPを使用して、約640Kのコンピュータサイエンス論文からなるarxivコーパスから、上位K個の最も類似した論文を見つける、意味的類似性検索エンジンの構築に着手した!この検索は、ラップトップ1台で50ミリ秒以下の待ち時間で実行される!具体的には、この投稿では以下のことを取り上げる。
1.環境のセットアップとKaggleからのarXivデータのダウンロード 2.Daskを使ってPythonにデータを読み込む 3.Milvusベクトルデータベースを使用した科学論文意味的類似性検索アプリケーションの実装
この投稿で使われたテクニックは、科学論文に限らず、あらゆるNLP意味的類似性検索エンジンを構築するテンプレートとして使うことができる。唯一の違いは、事前に訓練されたモデルを使うことである。
この投稿では、作者がCC0: Public Domainライセンスで公開したarXiv Dataset from Kaggleを使用する。
私は前の投稿でプロダクション・スケールのベクトル類似性検索に関する考察を概説した。これらの検討事項はすべてこのプロジェクトにも当てはまります。Milvusのベクターデータベースは非常によく設計されているので、多くのステップは全く同じであり、ここでは完全性を期すために再現しているだけである。
環境をセットアップし、Kaggleからarxivデータをダウンロードする。
コーネル大学はarXivコーパス全体をKaggle datasetにアップロードし、CC0: Public Domainライセンスでライセンスしています。KaggleのAPIを使って直接データセットをダウンロードすることができます。まだの方は、以下の手順に従って、あなたのシステムでKaggle APIをセットアップしてください。
この投稿では、semantic_similarityというconda環境を使用します。あなたのシステムにcondaをインストールしていない場合は、そのGitHubリポジトリからオープンソースのmini forgeをインストールすることでインストールできます。以下のステップでは、必要なディレクトリとconda環境を作成し、必要なPythonライブラリをインストールし、arxiv dataset from Kaggleをダウンロードする。
# 必要なディレクトリを作成する
mkdir -p semantic_similarity/notebooks semantic_similarity/data semantic_similarity/milvus
# CDをデータディレクトリに入れる
cd semantic_similarity/data
# conda 環境を作成し、有効化する
conda create -n semantic_similarity python=3.9
conda activate semantic_similarity
## conda を使わない場合は venv を使って仮想環境を作成する。
# python -m venv semantic_similarity
# ソース semantic_similarity/bin/activate
# Pip で必要なライブラリをインストールする
pip install jupyterlab kaggle matplotlib scikit-learn tqdm ipywidgets
pip install "dask[complete]" 文章変換器
pip install pandas pyarrow pymilvus protobuf==3.20.0
# kaggle APIを使ってデータをダウンロードする
kaggle datasets download -d Cornell-University/arxiv
# データをローカルディレクトリに解凍する
arxiv.zipを解凍する
# Zipファイルを削除
rm arxiv.zip
Daskを使ってPythonにデータをロードする
Kaggleからダウンロードしたデータは、約200万件の論文を含む3.3GBのJSONファイルです!このような大きなデータセットを効率的に処理するためには、pandasを使ってデータセット全体をメモリにロードするのは得策ではありません。その代わりに、Daskを使ってデータを複数のパーティションに分割し、いつでもいくつかのパーティションだけをメモリにロードすることができる。
Dask
Daskはオープンソースのライブラリで、pandasのようなAPIで簡単に並列計算を行うことができます。セットアップにあるように、pip install dask[complete]を実行することで、簡単にローカルマシンにセットアップすることができます。まず、必要なライブラリをインポートすることから始めよう。
import dask.bag as db
import json
from datetime import datetime
インポートタイム
data_path = '../data/arxiv-metadata-oai-snapshot.json'
Daskの2つのコンポーネントを使用して、大きなarxiv JSONファイルを効率的に処理する。
1.Dask Bag:これは、JSONファイルを固定サイズのブロックでロードし、データの各行に対していくつかの前処理関数を実行することができます。 2.Dask DataFrame:dask bagをdask dataframeに変換することで、pandasのようなAPIにアクセスすることができます。
ステップ1: JSONファイルをDaskバッグに読み込む
各ブロックのサイズが10MBのdask bagにJSONファイルをロードしてみましょう。各ブロックの大きさは blocksize 引数で調整できます。次に .map() 関数を使って json.loads 関数を dask bag の各行に適用し、JSON 文字列を Python 辞書にパースします。
# 10MB 単位でファイルを読み込み、JSON をパースする。
papers_db = db.read_text(data_path, blocksize="10MB").map(json.loads)
# 最初の行を表示
papers_db.take(1)
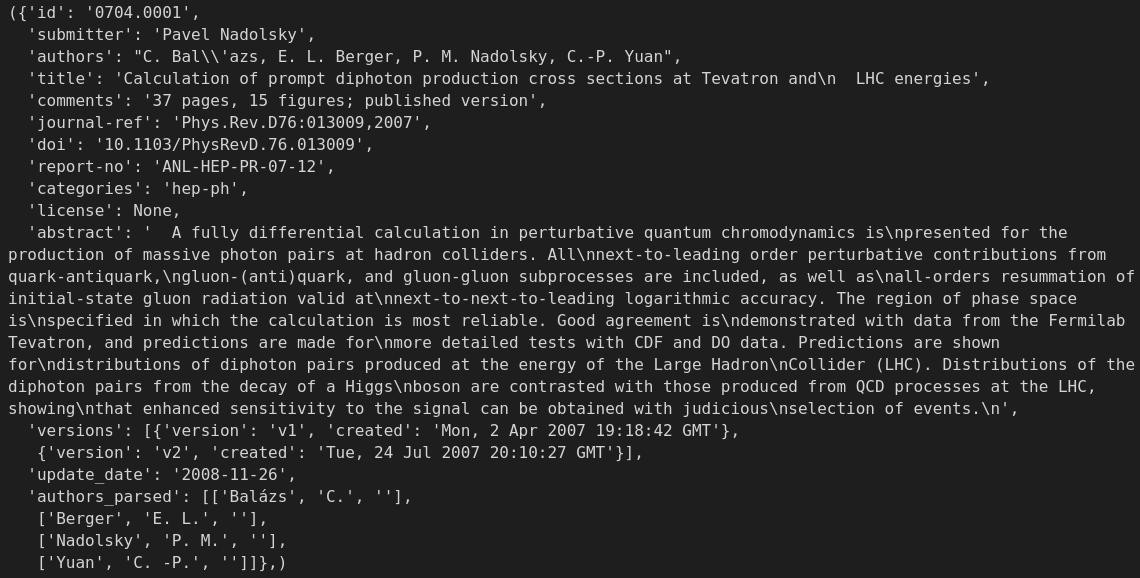 著者による画像
著者による画像
ステップ2:前処理ヘルパー関数を書く
プリントアウトから、各行には論文に関連するいくつかのメタデータが含まれていることがわかる。データセットの前処理を助けるヘルパー関数を3つ書いてみよう。
1.v1_date():この関数は、著者が論文の最初のバージョンをarXivにアップロードした日付を抽出する。日付をUNIX時間に変換し、その行の新しいフィールドとして格納する。 2.text_col():この関数は、"[SEP]"トークンを使用して "title "と "abstract "フィールドを結合し、これらのテキストをSPECTRE embedding modelに入力できるようにします。SPECTREについては次のセクションで詳しく説明します。
3.filters()`:この関数は、様々な列のテキストの最大長やComputer Scienceカテゴリの論文など、いくつかの基準を満たす行のみを保持する。
def v1_date(row):
"""
dask bagの各行に対して
論文の最初のバージョンの日付を見つけ
新しいカラムとして行に追加する
引数
row: dask bag の行
戻り値
unix_time" カラムが追加された dask bag の行
"""
バージョン = row["versions"]
日付 = なし
for version in versions:
if version["version"] == "v1":
date = datetime.strptime(version["created"], "%a, %d %b %Y %H:%M:%S %Z")
date = int(time.mktime(date.timetuple()))
行["unix_time"] = date
行を返す
def text_col(row):
"""
データフレームの行を受け取り、'text'という新しいカラムを追加する。
これは 'title' と 'abstract' カラムを連結したものです。
引数
row: データフレームの行
戻り値
textカラムが追加された行。
"""
row["text"] = row["title"] + "[SEP]"+ row["abstract"]
戻り行
def filters(row):
"""
dask bag内の各行について、フィルタ条件を満たす場合のみその行を保持する
引数
row: データフレームの行
戻り値
ブールマスク
"""
戻り値: ((len(row["id"])<16) かつ
(len(row["categories"])<200) かつ
(len(row["title"])<4096) かつ
(len(row["abstract"])<65535) and
("cs." in row["categories"]) # CS論文のみを残す
)
ステップ 3: Dask bag上で前処理ヘルパー関数を実行する
以下のように、.map()関数と.filter()関数を使って、Dask bagの各行に対してヘルパー関数を実行することができます。Dask はメソッドチェイニングをサポートしているので、この機会に Dask bag に必要な数列だけを残し、残りを削除します。
# 最終テーブルに残すカラムを指定する
cols_to_keep = ["id", "categories", "title", "abstract", "unix_time", "text"] # 最終テーブルに残すカラムを指定します。
# 前処理を適用する
papers_db = (
papers_db.map(lambda row: v1_date(row))
.map(lambda row: text_col(row))
.map(
lambda row:{
キー: 値
for key, value in row.items()
if key in cols_to_keep
}
)
.filter(filters)
)
# 最初の行を印刷する
papers_db.take(1)
 著者による画像
著者による画像
ステップ4: Dask BagをDask DataFrameに変換します。
データロードの最後のステップは、Dask BagをDask Dataframeに変換し、データの各ブロックまたはパーティションでpandasのようなAPIを使用することです。
# Dask BagをDask Dataframeに変換する
schema = {
"id": str、
"title": str、
"categories": str、
"abstract": str、
"unix_time": int、
「text": str、
}
papers_df = papers_db.to_dataframe(meta=schema)
# 最初の5行を表示
papers_df.head()
著者による画像](https://miro.medium.com/max/1400/1*tRRD9digiho57wFnVCaf-UQ.png)
Milvusベクトルデータベースを用いた科学論文意味的類似性検索アプリケーションの実装
Milvusは、非常にスケーラブルで高速な類似検索のために構築された、最も人気のあるオープンソースのベクトルデータベースの一つです。この記事では、ローカルマシン上でMilvusを実行するため、Milvus Standaloneを使用します。
ステップ1: ローカルマシンにMilvusベクトルデータベースをインストールする。
Docker](https://docs.docker.com/engine/install/)とDocker Composeをインストールする。その後、docker-compose.ymlをダウンロードし、以下のコードに示すようにDockerコンテナを起動するだけだ!milvus.ioのウェブサイトには、MilvusスタンドアロンとMilvusクラスタの両方をインストールするための多くのオプションが用意されています。Kubernetesクラスタにインストールする、オフラインでインストールする必要がある場合は、ぜひチェックしてみてください。
# CDをmilvusディレクトリに入れる
cd semantic_similarity/milvus
# スタンドアロン版のMilvusをダウンロードする docker compose
wget https://github.com/milvus-io/milvus/releases/download/v2.1.0/milvus-standalone-docker-compose.yml -O ./docker-compose.yml
# ローカルでMilvusサーバのdockerコンテナを実行する。
sudo docker-compose up -d
ステップ2:Milvusコレクションの作成
ローカルマシン上でMilvusベクトルデータベースサーバが動作するようになったので、 pymilvus ライブラリを使ってMilvusとやりとりすることができる。まず、必要なモジュールをインポートし、localhost上で動作しているMilvusサーバに接続しよう。パラメータ alias と collection_name は自由に変更して構わない。emb_dim`パラメータの値は、テキストを埋め込みデータに変換する際に使用するモデルによって決定される。SPECTREの場合、エンベッディングは768dである。
# Milvusサーバーがすでに起動していることを確認する。
from pymilvus import connections, utility.
from pymilvus import Collection, CollectionSchema, FieldSchema, DataType
# Milvusサーバに接続する
connections.connect(alias="default", host="localhost", port="19530")
# コレクション名
コレクション名 = "arxiv"
# 埋め込みサイズ
埋め込みサイズ = 768
# 既存のコレクションをチェックし、存在すれば削除する
# if utility.has_collection(collection_name):
# print(utility.list_collections())
# utility.drop_collection(collection_name)
オプションで、collection_nameで指定したコレクションが既にMilvusサーバに存在するかどうかをチェックすることができる。この例では、コレクションがすでに利用可能であれば、それを削除します。しかし、本番サーバではこのようなことはせず、以下のコレクション作成コードをスキップすることになるでしょう。
Milvusコレクションは従来のデータベースのテーブルに似ています。データを格納するコレクションを作成するには、まずコレクションのスキーマを指定する必要があります。この例では、Milvus 2.1の文字列インデックスとフィールドを格納する機能を利用して、各論文に関連する必要なメタデータを格納している。主キー idx とその他のフィールド categories、title、abstract は VARCHAR データ型で最大長も適切であり、embedding は emb_dim 次元の埋め込みを含む FLOAT_VECTOR フィールドである。Milvusは我々のドキュメントページに示されているように、様々なデータ型をサポートしている。
# コレクションのスキーマを作成する
idx = FieldSchema(name="id", dtype=DataType.VARCHAR, is_primary=True, max_length=16)
categories = FieldSchema(name="categories", dtype=DataType.VARCHAR, max_length=200)
title = FieldSchema(name="title", dtype=DataType.VARCHAR, max_length=4096)
abstract = FieldSchema(name="abstract", dtype=DataType.VARCHAR, max_length=65535)
unix_time = FieldSchema(name="unix_time", dtype=DataType.INT64)
embedding = FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=emb_dim)
# コレクション内のフィールド
fields = [idx, categories, title, abstract, unix_time, embedding].
schema = CollectionSchema(
fields=fields, description="科学論文の意味的類似性"
)
# スキーマでコレクションを作成する
コレクション = コレクション(
name=collection_name, schema=schema, using="default", shards_num=10
)
コレクションが作成されたら、テキストとベクトルをアップロードする準備ができました。
ステップ3:Daskデータフレームのパーティションを繰り返し、SPECTERを使ってテキストを埋め込み、Milvusベクトルデータベースにアップロードします。
まず、意味的類似性検索を実行するために、Daskデータフレーム内のテキストを埋め込みベクトルに変換する必要があります。以下の投稿で、テキストを埋め込みベクトルに変換する方法を紹介します。特に、科学論文を埋め込みに変換するには、SPECTREと呼ばれるSBERT Bi-Encoderモデルを使用します。
SPECTER [paper]Github]:Scientific Paper Embeddings using Citation-informed TransformERsは、科学論文をエンベッディングに変換するモデルです。
- 各論文のTitleとAbstractテキストを[SEP]トークンで連結し、事前に学習されたTransformerモデル(SciBERT)の[CLS]トークンを使ってエンベッディングに変換します。
- 文書間の関連性の代理シグナルとして引用を使用する。ある論文が別の論文を引用していれば、両者は関連していると推測できる。
- トリプレットロスの学習目的:Transformerモデルを学習することで、引用を共有する論文は埋め込み空間においてより近くなる。
- 言い換えると、ポジティブ論文はクエリ論文で引用された論文であり、ネガティブ論文はクエリ論文で引用されていない論文である。ランダムに抽出されたネガは「簡単な」ネガである。
- パフォーマンスを向上させるために、クエリ論文では引用されていないが、ポジティブ論文では引用されている論文を使って「難しい」ネガティブ論文を作成する。
- 推論の際に必要となるのは、タイトルと抄録のみである。引用は不要であるため、SPECTERはまだ引用のない新しい論文であっても埋め込みを行うことができます!
- SPECTERは科学論文のトピック分類、引用予測、推薦において、SciBERTよりも優れた性能を発揮します。
オープンソース化されたSPECTER論文のスクリーンショットを用いた著者による画像](https://miro.medium.com/max/1400/1*BOJpwXkfk00xWYI4i4dMqQ.png)
訓練済みSPECTREモデルの使用は、Sentence Transformerライブラリを使えば簡単です。以下のように、たった1行のコードで訓練済みモデルをダウンロードすることができます。また、Daskのデータフレームパーティションからテキストの列全体をエンベッディングに変換する簡単なヘルパー関数も記述します。
from sentence_transformers import SentenceTransformer
from tqdm import tqdm
# 科学論文 SBERT モデル
model = SentenceTransformer('allenai-specter')
def emb_gen(partition):
return model.encode(partition['text']).tolist()
データをMilvusコレクションにアップロードするために、Daskデータフレームのパーティションを繰り返し処理する必要があります。各繰り返しの間に、そのパーティションから行のみをメモリにロードし、メタデータカラムのデータを変数 data に追加します。dask の .map_partitions() API を使って、パーティション内のすべての行に埋め込み生成を適用し、その結果を同じ data 変数に追加します。最後に、collection.insertでデータをMilvusにアップロードします。
# 初期化
コレクション = コレクション(コレクション名)
for partition in tqdm(range(papers_df.npartitions)):
# パーティションの dask データフレームを取得する
subset_df = papers_df.get_partition(partition)
# データフレームが空かどうかをチェック
if len(subset_df.index) != 0:
# メタデータ
データ = [
subset_df[col].values.compute().tolist()
for col in ["id", "categories", "title", "abstract", "unix_time" ]。
]
# エンベッディング
データ += [
サブセット_df
.map_partitions(emb_gen)
.compute()[0]
]
# データを挿入する
コレクション.insert(データ)
data変数に追加するカラムの順番は、スキーマ作成時に定義したfields` 変数と同じ順番でなければならないことに注意してください!
ステップ 4: アップロードされたデータに近似最近傍 (ANN) インデックスを作成する。
すべての埋め込みデータをMilvusベクトルデータベースに挿入した後、検索を高速化するためにANNインデックスを作成する必要があります。この例では HNSW という 最も高速で正確なANNインデックスの一つ を使用しています。HNSW`インデックスとそのパラメータについてはMilvus documentationを参照されたい。
# コレクションにANNインデックスを追加する
index_params = {
"metric_type":"L2",
"index_type":"HNSW"、
「params":params": {"efConstruction":128, "M":8},
}
collection.create_index(field_name="embedding", index_params=index_params)
ステップ 5: ベクトル類似性検索クエリを実行する!
最後に、Milvusコレクションのデータをクエリする準備ができました。まず、コレクションに対してクエリを実行するために、コレクションをメモリにロードする必要があります。
# コレクションをメモリにロードする
コレクション = コレクション(コレクション名)
collection.load()
次に、query_textを受け取り、SPECTREエンベッディングに変換し、MilvusコレクションをANN検索し、結果を出力する簡単なヘルパー関数を作成した。HNSWのドキュメントページ](https://milvus.io/docs/v2.1.x/index.md#HNSW)で説明されている search_params を使って検索の質とスピードをコントロールすることができる。
def query_and_display(query_text, collection, num_results=10):
# クエリテキストを埋め込む
query_emb = [model.encode(query_text)].
# 検索パラメータ
search_params = {"metric_type":"L2", "params":{"ef":128}}
# 検索
query_start = datetime.now()
results = collection.search(
data=query_emb、
anns_field="embedding"、
param=search_params、
limit=num_results、
expr=None、
output_fields=["title", "abstract"]、
)
query_end = datetime.now()
# 結果を印刷する
print(f "Query Speed: {(query_end - query_start).total_seconds():.2f} s")
print("結果:")
for res in results[0]:
title = res.entity.get("title").replace("\n ", "")
print(f"➡️ ID: {res.id}. L2 Distance: {res.distance:.2f}")
print(f "Title: {title}")
print(f "Abstract: {res.entity.get('abstract')}")
このヘルパー関数を使うと、Milvusコレクションに保存されているコンピュータサイエンスの論文(~640K件)全体に対して、arXivのセマンティック論文検索をたった1行のコードで実行することができます。例えば、以前の投稿で詳しく説明したSimCSE論文に似た論文を検索しています。トップ10の結果は、私の検索クエリにかなり関連しており、ほとんどが文の埋め込みの対照学習に関連しています!さらに印象的なのは、私のノートパソコンで検索を実行しただけで、30ミリ秒しかかからなかったことだ!
# SimCSE論文に類似した論文を検索する
title = "SimCSE: 文の埋め込みの簡単な対照学習"
抄録 = """本稿では、SimCSEを紹介する。SimCSEはシンプルな対照学習フレームワークであり、最先端の文埋め込みを大きく前進させる。まず、教師なしアプローチについて説明する。このアプローチは、入力文を受け取り、標準的なドロップアウトをノイズとして使用するのみで、それ自体を対照的に予測する。この単純な手法は驚くほどうまく機能し、これまでの教師あり手法と同等の性能を発揮する。我々はドロップアウトが最小限のデータ補強として働き、それを取り除くと表現が崩れることを発見した。次に、自然言語推論データセットからの注釈付きペアを、「含意」ペアをポジティブ、「矛盾」ペアをハードネガティブとして、我々の対比学習フレームワークに組み込む、教師ありアプローチを提案する。SimCSEを標準的な意味的テキスト類似度(STS)タスクで評価したところ、BERTベースを用いた教師なしモデルと教師ありモデルは、それぞれ平均76.3%と81.6%のスピアマンの相関を達成し、以前の最高結果と比較して4.2%と2.2%の改善を示した。また、我々は、理論的にも経験的にも、対照学習目的が、事前に訓練された埋込みの異方性空間をより均一に正則化し、教師付き信号が利用可能な場合に、正対をより良く整列させることを示す。"""
query_text = f"{タイトル}[SEP]{アブストラクト}"
query_and_display(query_text, collection, num_results=10)
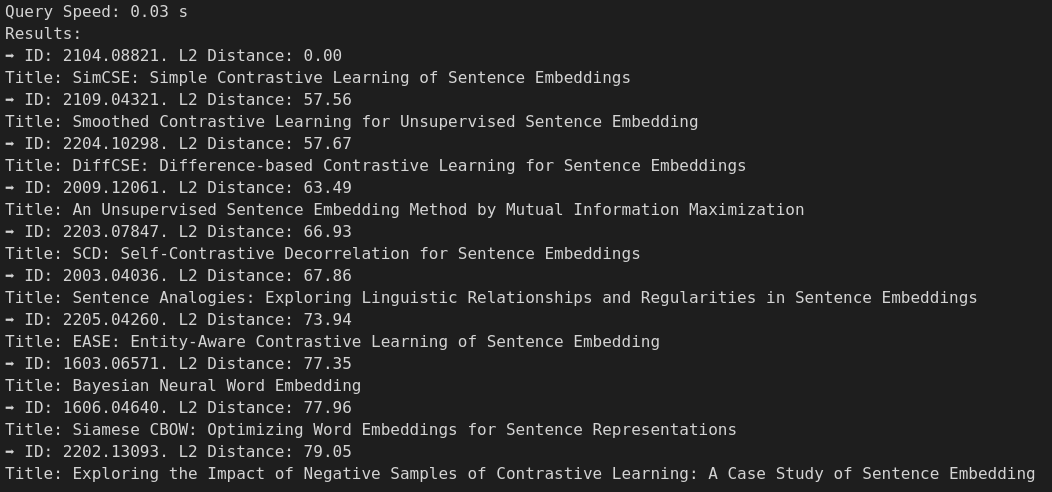 著者による画像
著者による画像
これ以上クエリを実行する必要がない場合、コレクションを解放してマシンのメモリを解放することができます。コレクションをメモリから削除しても、データはディスクに保存され、必要なときに再びロードできるので、データの損失は発生しません。
# 不要になったらコレクションをメモリから解放する
collection.release()
Milvusサーバを停止し、ディスクから全てのデータを削除したい場合は、Stop Milvus instructionsに従ってください。注意してください!この操作は不可逆的であり、Milvusクラスタ内のすべてのデータが削除されます。
結論
この投稿では、SPECTREエンベッディングとMilvusベクトルデータベースを用いて、超スケーラブルな科学論文のセマンティック検索サービスを簡単なステップで実装した。このアプローチは、数億から数十億のベクトルまで拡張可能です。サンプル論文のクエリを用いて検索をテストしたところ、わずか30msでトップ10の結果が返されました!Milvusは非常にスケーラブルで高速なベクトル類似検索データベースとして高い評価を得ています!
Milvusのアプリケーションの詳細については、MilvusベクターデータベースdemoおよびBootcampをご覧ください。
読み続けて

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.
Milvus/Zilliz + Surveillance: How Vector Databases Transform Multi-Camera Tracking
See how Milvus vector database enhances multi-camera tracking with similarity-based matching for better surveillance in retail, warehouses and transport hubs.

Milvus WebUI: A Visual Management Tool for Your Vector Database
Explore Milvus WebUI to monitor, manage, and optimize your vector database with real-time insights, performance tracking, and system health monitoring.