




Dalle parole ai vettori: Capire il Word2Vec nell'elaborazione del linguaggio naturale (NLP)
Dalle parole ai vettori: Capire il Word2Vec nell'elaborazione del linguaggio naturale (NLP)
Che cos'è Word2Vec?
Word2Vec è un modello di apprendimento automatico che converte le parole in rappresentazioni numeriche vettoriali per catturare il loro significato in base al contesto in cui appaiono. Sviluppato da Tomas Mikolov e dal suo team di Google, utilizza grandi insiemi di dati testuali per comprendere le relazioni tra le parole e rappresentare le somiglianze semantiche e sintattiche. A differenza degli approcci tradizionali, come la codifica a un solo punto, Word2Vec crea incorporazioni dense e significative in cui le parole simili sono posizionate più vicine in uno spazio vettoriale continuo. Word2Vec è ampiamente utilizzato in applicazioni di elaborazione del linguaggio naturale come l'analisi del sentiment e i sistemi di raccomandazione.
Perché abbiamo bisogno di Word2Vec?
La comprensione delle relazioni e dei significati delle parole è una delle sfide principali dell'elaborazione del linguaggio naturale (NLP) (https://zilliz.com/ai-faq/what-is-natural-language-processing-nlp). I metodi tradizionali, come la codifica one-hot, rappresentano le parole come vettori radi e ad alta dimensionalità in cui ogni parola è indipendente dalle altre. Questo approccio non riesce a cogliere le relazioni semantiche o sintattiche tra le parole. Ad esempio, con la codifica one-hot, i vettori per "re" e "regina" apparirebbero completamente slegati, anche se i loro significati sono strettamente collegati.
Inoltre, queste rappresentazioni rade sono inefficienti dal punto di vista computazionale, soprattutto per i vocabolari di grandi dimensioni, e non si generalizzano bene a parole o contesti non visti. Questa limitazione ha reso difficile per le macchine comprendere veramente il linguaggio, ostacolando i progressi in compiti come la traduzione automatica, l'analisi del sentimento e il posizionamento nelle ricerche.
Word2Vec risolve queste sfide creando [word embeddings] compatti e densi (https://zilliz.com/ai-faq/what-is-word-embedding) che rappresentano le relazioni tra le parole in base a come appaiono nel testo. Catturando sia il significato delle parole che il loro contesto, Word2Vec ha trasformato il modo in cui le macchine interpretano ed elaborano il linguaggio umano, rendendolo più efficiente e significativo.
Come funziona Word2Vec?
Il cuore di Word2Vec sono i word embeddings, vettori a bassa densità (https://zilliz.com/learn/dense-vector-in-ai-maximize-data-potential-in-machine-learning) che catturano le proprietà semantiche e sintattiche delle parole. Word2Vec opera analizzando grandi volumi di testo per imparare le relazioni tra le parole. Si tratta di una rete neurale poco profonda (https://zilliz.com/learn/Neural-Networks-and-Embeddings-for-Language-Models) che genera rappresentazioni vettoriali delle parole, catturandone i significati semantici e sintattici. Il modello identifica i modelli di co-occorrenza delle parole nelle frasi e utilizza queste informazioni per posizionare le parole correlate più vicine tra loro in uno spazio vettoriale continuo.
Il concetto principale è che vettori simili rappresentano parole con significati o contesti d'uso simili. Ad esempio, le parole "re" e "regina" avranno vettori strettamente correlati, con differenze che codificano distinzioni semantiche specifiche, come il genere.
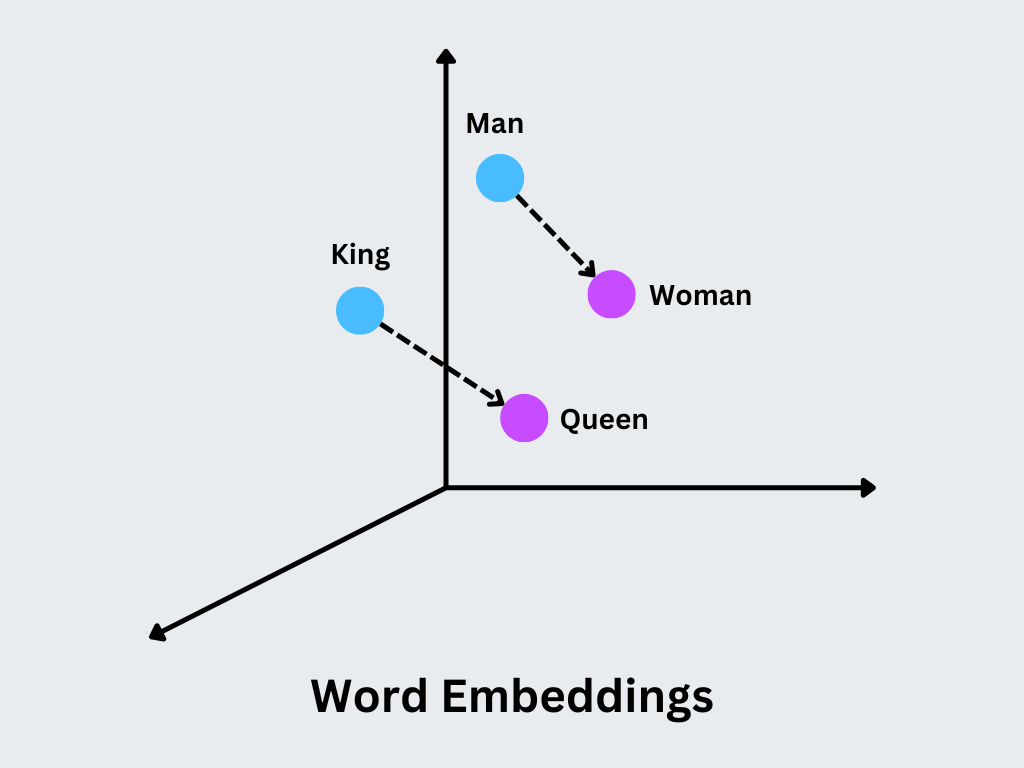 Figura- Word Embeddings.png
Figura- Word Embeddings.png
Figura: Matrici di parole
Word2Vec offre due approcci per generare embeddings, a seconda di come viene gestito il contesto:
Sacchetto continuo di parole (CBOW)
Il Continuous [bag of words] (https://zilliz.com/learn/introduction-to-natural-language-processing-tokens-ngrams-bag-of-words-models#Bag-of-Words-Models) si concentra sulla previsione di una parola target in base alle parole che la circondano. Ad esempio, nella frase "Le mele sono dolci e succose", il CBOW utilizza le parole del contesto ("mele", "sono", "e" e "succose") per prevedere la parola target, come "dolce".
CBOW è efficiente dal punto di vista computazionale, perché calcola la media delle parole di contesto per prevedere l'obiettivo. Tuttavia, si comporta meglio con le parole frequenti e può avere difficoltà con i termini rari.
Caso d'uso: CBOW è comunemente usato in applicazioni come il completamento automatico e il controllo ortografico, dove è necessario prevedere una parola mancante o successiva.
Modello Skip-Gram
Skip-Gram inverte il processo di predizione. Invece di predire una parola target dal suo contesto, predice le parole del contesto sulla base della parola target. Ad esempio, se la parola target è "dolce", Skip-Gram predice le parole di contesto "mele", "sono", "e" e "succose".
Skip-Gram gestisce meglio le parole rare ed è particolarmente efficace nel catturare relazioni più sfumate quando si lavora con grandi insiemi di dati.
Caso d'uso: Skip-Gram è prezioso in attività come la creazione di sistemi di raccomandazione o il raggruppamento di termini simili in campi specializzati.
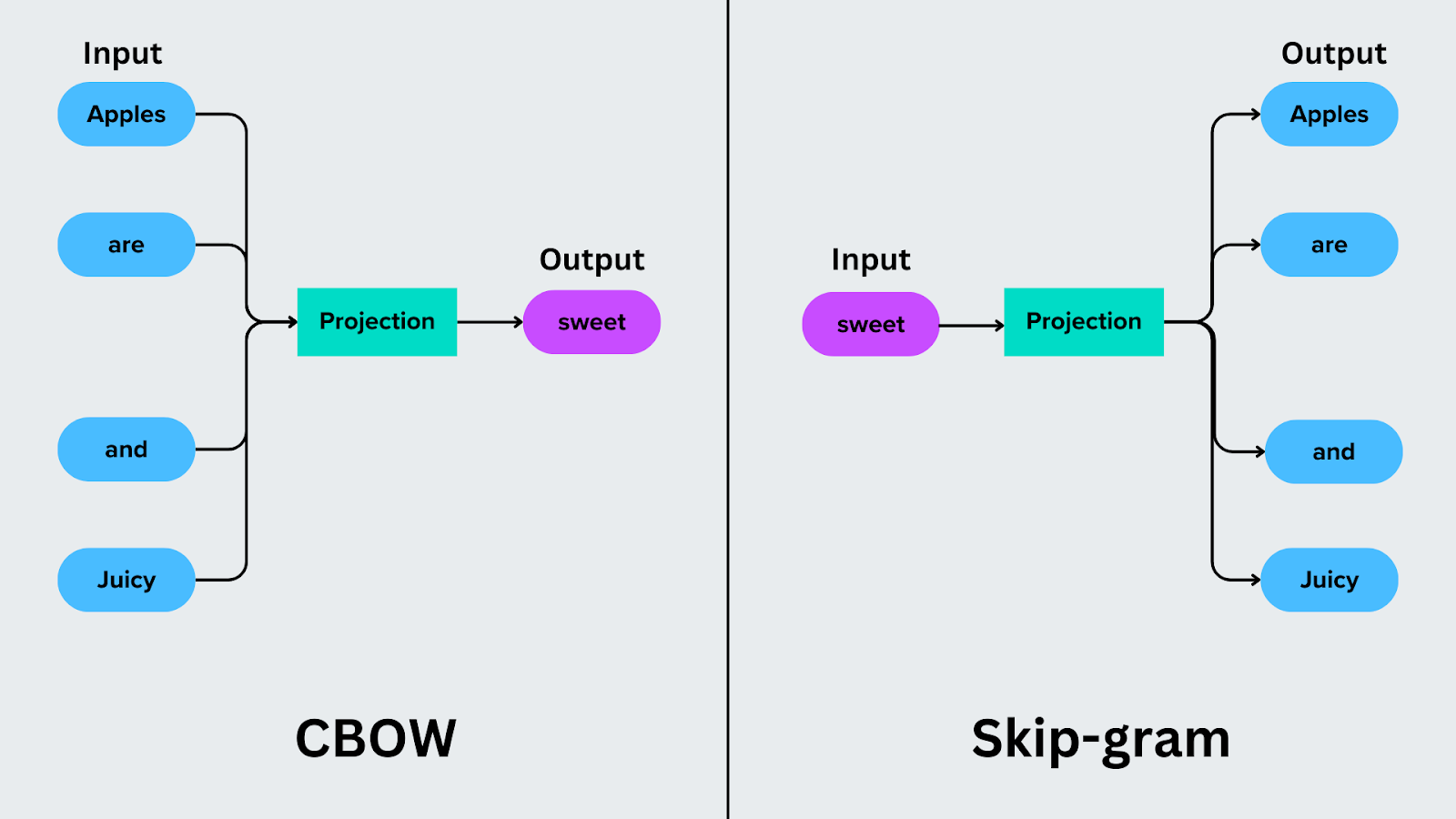 Figura- CBOW vs Skip-gram.png
Figura- CBOW vs Skip-gram.png
Figura: CBOW vs Skip-gram
Differenza tra il modello CBOW e il modello Skip-Gram
Sebbene sia il CBOW che lo Skip-Gram mirino a rappresentare le parole in modo significativo, differiscono nel modo in cui elaborano e predicono le parole in base al contesto. Di seguito viene presentato un confronto per evidenziare le differenze principali tra questi due approcci:
| Feature | Continuous Bag of Words (CBOW) | Skip-Gram |
|---|---|---|
| Obiettivo | Determina la parola target utilizzando il contesto circostante. | Prevede le parole del contesto in base alla parola target. |
| Efficienza | Più veloce da addestrare. | Più lento da addestrare. |
| Focus | Funziona bene con le parole frequenti. | Gestisce efficacemente le parole rare. |
| Complessità | Più semplice ed efficiente dal punto di vista computazionale. | Più complesso e intensivo dal punto di vista computazionale. |
| Caso d'uso | Adatto a compiti come la previsione di parole e la correzione automatica. | Ideale per compiti specializzati come i sistemi di raccomandazione. |
| Finestra di contesto | Considera la media di tutte le parole di contesto. | Valutare separatamente le singole parole di contesto. |
| Requisiti di dimensione del set di dati | Funziona bene con set di dati più piccoli. | Si comporta meglio con insiemi di dati di grandi dimensioni. |
| Esempio | Prevede "abbaiare" da "Il cane è ___". | Prevede "Il", "cane" e "è" da "abbaiare". |
Tabella: CBOW vs Skip-Gram
Implementazione di Word2Vec in Python
Di seguito è riportata l'implementazione in Python di Word2Vec utilizzando i metodi CBOW e Skip-Gram. Questo codice si allena su un piccolo set di dati personalizzato per imparare gli embeddings delle parole, dimostrando come entrambi i metodi funzionino per catturare le relazioni tra le parole in base al loro contesto. Entrambe le sezioni del codice sono progettate per confrontare il modo in cui CBOW e Skip-Gram apprendono le relazioni tra le parole in modo diverso, ma condividono gli stessi parametri per un confronto equo. L'implementazione è disponibile in questo [notebook Kaggle] (https://www.kaggle.com/code/fariba999/word2vec-implementation).
Codice
da gensim.models import Word2Vec
# Un corpus piccolo e mirato
corpus = [
["gatto", "cane", "abbaiato"],
["cane", "inseguito", "gatto"],
["gatto", "seduto", "tappetino"],
["cane", "correva", "veloce"],
["gatto", "correva", "veloce"],
["cane", "seduto", "tappetino"].
]
# Addestrare un modello CBOW
cbow_model = Word2Vec(
frasi=corpus,
vector_size=10, # Dimensione del vettore più piccola per semplicità
window=2, # Dimensione della finestra contestuale
min_count=1, # Include tutte le parole
sg=0 # Imposta sg=0 per CBOW
)
# Addestrare un modello Skip-Gram
skipgram_model = Word2Vec(
frasi=corpus,
vector_size=10, # Dimensione del vettore più piccola per semplicità
window=2, # Dimensione della finestra contestuale
min_count=1, # Include tutte le parole
sg=1 # Imposta sg=1 per lo Skip-Gram
)
# Funzione per visualizzare vettori di parole e parole simili
def display_model_results(model, model_name):
print(f"\n--- {nome_modello} ---")
per parola in ["gatto", "cane"]:
print(f "Vettore di parole per '{parola}': {modello.wv[parola][:5]}...") # Visualizza i primi 5 valori del vettore
parole_simili = model.wv.most_similar(word, topn=3)
print(f "Più simile a '{parola}': {[(w, round(sim, 2)) per w, sim in similar_words]}")
# Visualizzare i risultati del modello CBOW
display_model_results(cbow_model, "CBOW Model")
# Visualizzazione dei risultati del modello Skip-Gram
display_model_results(skipgram_model, "Modello Skip-Gram")
Output:
--- Modello CBOW ---
Vettore di parole per 'gatto': [ 0.07380505 -0.01533471 -0.04536613 0.06554051 -0.0486016 ]... I più simili a "gatto": [('cane', 0,54), ('veloce', 0,33), ('abbaiato', 0,23)]. Vettore di parole per "cane": [-0,00536227 0,00236431 0,0510335 0,09009273 -0,0930295 ]... Più simili a "cane": [("gatto", 0,54), ("veloce", 0,3), ("correva", 0,1)].
--- Modello Skip-Gram ---
Vettore di parole per 'gatto': [ 0.07380505 -0.01533471 -0.04536613 0.06554051 -0.0486016 ]... I più simili a "gatto": [('cane', 0,54), ('veloce', 0,33), ('abbaiato', 0,23)]. Vettore di parole per "cane": [-0,00536227 0,00236431 0,0510335 0,09009273 -0,0930295 ]... Più simili a "cane": [("gatto", 0,54), ("veloce", 0,3), ("correva", 0,1)].
Nella parte CBOW del codice:
Il modello viene addestrato utilizzando il parametro sg=0, che indica a Word2Vec di utilizzare il metodo Continuous Bag of Words.
Il CBOW determina una parola utilizzando il contesto delle parole che la circondano. Ad esempio, nella frase ["cane", "inseguito", "gatto"], il modello potrebbe utilizzare "cane" e "gatto" per prevedere "inseguito".
Il vettore_size=10 definisce la dimensione delle incorporazioni di parole (quanti numeri rappresentano ogni parola).
Il parametro window=2 specifica la context window, cioè considera fino a 2 parole prima e dopo la parola target.
Nella parte di codice Skip-Gram:
Il modello viene addestrato utilizzando il parametro sg=1, che fa passare Word2Vec al metodo Skip-Gram.
Skip-Gram identifica le parole circostanti che utilizzano una determinata parola target. Ad esempio, se la parola target è "inseguito", il modello predice "cane" e "gatto" come suoi vicini.
Simile a CBOW:
vector_size=10 definisce la dimensione delle incorporazioni di parole.
window=2 imposta l'intervallo di parole contestuali da considerare.
Vantaggi di Word2Vec
Di seguito sono riportati alcuni vantaggi chiave che rendono Word2Vec una tecnica fondamentale in NLP:
Cattura le relazioni semantiche: Word2Vec crea embeddings in cui parole semanticamente simili (ad esempio, "re" e "regina") sono posizionate l'una vicina all'altra nello spazio vettoriale per analizzare e utilizzare queste relazioni in attività di NLP.
Comprensione contestuale: Analizzando la co-occorrenza delle parole in grandi corpora, Word2Vec cattura le relazioni dipendenti dal contesto, consentendo ai modelli di comprendere meglio il significato delle parole in contesti specifici.
Rappresentazione efficiente: Le incorporazioni di parole sono dense e poco dimensionali rispetto alle rappresentazioni rade come la codifica one-hot, il che le rende una tecnica efficiente in termini di memoria e costi computazionali.
Gestisce grandi vocabolari**: A differenza delle tecniche più vecchie, Word2Vec è in grado di adattarsi efficacemente a grandi insiemi di dati e vocabolari, rendendola pratica per le applicazioni del mondo reale.
Supporta l'apprendimento per trasferimento**: Gli embeddings Word2Vec pre-addestrati possono essere riutilizzati per più compiti, risparmiando tempo e risorse computazionali e migliorando i risultati.
Aritmetica sulle parole: Word2Vec supporta l'aritmetica vettoriale significativa che consente di calcolare analogie come "re - uomo + donna = regina" direttamente utilizzando gli embedding.
Casi d'uso di Word2Vec
Word2Vec ha un'ampia gamma di applicazioni per compiti di NLP. Di seguito sono riportati alcuni dei suoi casi d'uso pratici e d'impatto:
Traduzione automatica: Migliora la mappatura delle parole tra le lingue utilizzando gli embeddings per allineare le parole con significati simili e migliorare l'accuratezza della traduzione.
Analisi dei sentimenti: Identifica il tono del testo analizzando le relazioni tra le parole e il contesto per classificare i sentimenti positivi, negativi o neutrali.
Classificazione delle ricerche: Migliora i motori di ricerca comprendendo la somiglianza tra le query di ricerca e i contenuti indicizzati, per ottenere risultati più pertinenti.
Raccomandazioni sui prodotti**: Abbina le preferenze degli utenti a prodotti o servizi analizzando le descrizioni testuali e trovando articoli simili.
Modellazione di argomenti: Organizza e analizza grandi insiemi di dati testuali raggruppando i documenti in cluster basati sulla somiglianza degli incorporamenti di parole.
Completamento automatico del testo: Suggerisce parole o frasi pertinenti prevedendo parole contestualmente simili, migliorando l'esperienza dell'utente negli strumenti di digitazione o codifica.
Chatbots: Consente una migliore comprensione degli input e del contesto dell'utente, aiutando i chatbot a generare risposte accurate e pertinenti.
Limitazioni di Word2Vec
Nonostante i suoi vantaggi, Word2Vec presenta dei limiti:
Mancanza di consapevolezza del contesto: Word2Vec genera un singolo embedding per ogni parola, indipendentemente dal suo contesto. Ad esempio, la parola "banca" avrà la stessa rappresentazione vettoriale, sia che si riferisca a una riva del fiume che a un istituto finanziario.
Dipendenza dai dati: Un addestramento efficace richiede insiemi di dati testuali di grandi dimensioni e di alta qualità. Insiemi di dati poco curati o di piccole dimensioni possono portare a incorporazioni non ottimali.
Gestione delle parole rare: Problemi con parole poco frequenti o termini fuori dal vocabolario, che potrebbero non comparire nei dati di addestramento per generare incorporazioni significative.
Nessuna rappresentazione a livello di frase**: Word2Vec si concentra sulle incorporazioni a livello di parola e non fornisce rappresentazioni per intere frasi o documenti, limitando la sua portata a compiti specifici di NLP.
Ignora l'ordine delle parole**: Il modello considera le parole all'interno di una finestra di contesto, ma non la loro sequenza, che può influire sulla comprensione della grammatica o della struttura della frase.
Oggiata rispetto ai modelli moderni: Word2Vec è stato principalmente superato da modelli avanzati come BERT, GLoVE e GPT, che forniscono incorporazioni contestuali e più robuste.
Colmare il divario: da Word2Vec a GloVe, BERT e GPT
I modelli predittivi come Word2Vec creano incorporazioni di parole concentrandosi sul contesto locale attraverso le reti neurali. Tuttavia, il fatto che si basino su coppie di parole vicine introduce una limitazione: Non riescono a cogliere relazioni più ampie e globali in un intero corpus testuale. Per esempio, mentre Word2Vec eccelle nell'identificare le associazioni di parole vicine, spesso non coglie le connessioni semantiche più ampie.
Per ovviare a questo problema, GloVe (Global Vectors for Word Representation) utilizza statistiche di co-occorrenza globali per creare embeddings di parole. Analizza la frequenza con cui le parole appaiono insieme nell'intero corpus per catturare sia il contesto locale sia le relazioni semantiche più ampie per una rappresentazione più completa del linguaggio.
Più recentemente, modelli come BERT (Bidirectional Encoder Representations from Transformers) e GPT (Generative Pre-trained Transformer) sono andati oltre le incorporazioni statiche. BERT ha introdotto le incorporazioni contestuali, rappresentando le parole in modo diverso in base al loro utilizzo in una frase, mentre GPT si è concentrato sulla generazione di testi coerenti attraverso la comprensione del contesto sequenziale. Questi modelli hanno trasformato ulteriormente l'NLP incorporando rappresentazioni dinamiche e consapevoli del contesto, affrontando i limiti di metodi precedenti come Word2Vec e GloVe.
Word2Vec con Milvus: ricerca vettoriale efficiente per applicazioni NLP
Word2Vec fornisce un modo per creare incorporazioni di parole che sono essenziali per compiti come la [ricerca semantica] (https://zilliz.com/glossary/semantic-search), la similarità dei documenti e i sistemi di raccomandazione, dove la comprensione delle relazioni tra le parole è fondamentale. Tuttavia, la gestione e l'interrogazione di ampie collezioni di incorporazioni in modo efficiente può rappresentare una sfida.
È qui che entra in gioco Milvus, il database vettoriale open-source sviluppato da Zilliz. Milvus offre una soluzione robusta per archiviare, indicizzare e interrogare le incorporazioni Word2Vec o qualsiasi altro tipo di incorporazioni su scala, per una perfetta integrazione nei flussi di lavoro NLP. Ecco come Word2Vec e Milvus lavorano insieme:
**Word2Vec genera embeddings ad alta dimensione per le parole del vocabolario, che possono crescere significativamente in termini di dimensioni con set di dati più grandi. Milvus gestisce in modo efficiente queste incorporazioni:
Magazzino scalabile: Memorizzazione di milioni di incorporazioni di parole senza degrado delle prestazioni.
Recupero veloce: Gli algoritmi ottimizzati garantiscono una ricerca rapida di incorporazioni simili, fondamentali per le applicazioni NLP in tempo reale come i sistemi di raccomandazione o i chatbot.
Ricerca semantica avanzata: gli embeddings Word2Vec eccellono nel catturare le relazioni tra le parole. Se combinati con Milvus, questi embeddings sono in grado di alimentare la ricerca semantica avanzata. Ad esempio:
Ricerca di sinonimi o termini correlati (ad esempio, interrogando "re" si ottengono embeddings come "regina" o "principe").
Implementare sistemi di ricerca robusti come Retrieval Augmented Generation (RAG) che si basano sulla similarità delle parole per ottenere risultati migliori.
**Milvus semplifica i flussi di lavoro NLP che coinvolgono Word2Vec:
Permette di memorizzare e interrogare in modo efficiente le incorporazioni Word2Vec pre-addestrate.
Supportando l'integrazione con framework di apprendimento automatico per il clustering, la similarità dei documenti e la ricerca in tempo reale.
Conclusione
Word2Vec ha trasformato il modo in cui lavoriamo con i dati linguistici, introducendo le incorporazioni di parole che catturano i significati e le relazioni delle parole. Ha risolto molte sfide dei metodi tradizionali, come l'incapacità di catturare le somiglianze semantiche e sintattiche. Viene utilizzato in applicazioni come la sentiment analysis, la traduzione e i sistemi di raccomandazione. Nonostante i suoi limiti, Word2Vec ha gettato le basi per molti progressi nel campo e ha influenzato lo sviluppo di modelli più sofisticati come GLoVE, BERT e GPT.
FAQ su Word2Vec
- **Che cos'è Word2Vec e perché è importante?
Word2Vec è un modello di apprendimento automatico che crea rappresentazioni vettoriali dense delle parole, chiamate word embeddings, basate sul loro contesto. È importante perché cattura le relazioni e i significati delle parole per attività di NLP come l'analisi del sentimento, la traduzione e la ricerca.
- **Come si differenzia Word2Vec dai metodi tradizionali di rappresentazione delle parole?
A differenza dei metodi tradizionali, come la codifica one-hot, che rappresentano le parole come vettori sparsi senza relazioni intrinseche, Word2Vec crea incorporazioni dense che catturano le somiglianze semantiche e sintattiche tra le parole, rendendole molto più efficienti e significative.
- **Quali sono le principali architetture utilizzate in Word2Vec?
Word2Vec ha due architetture principali: Continuous Bag of Words (CBOW) e Skip-Gram. CBOW determina una parola target dal contesto circostante, mentre Skip-Gram identifica le parole del contesto utilizzando una data parola target. Ciascuna ha i suoi punti di forza a seconda del caso d'uso e del set di dati.
- **Quali sono i principali casi d'uso di Word2Vec?
Word2Vec viene utilizzato in applicazioni come l'analisi del sentiment, la traduzione automatica, i sistemi di raccomandazione, il ranking di ricerca, la modellazione di argomenti e lo sviluppo di chatbot. La sua capacità di comprendere le relazioni tra le parole lo rende versatile in diverse attività di NLP.
- **Quali sono i limiti di Word2Vec?
Word2Vec presenta diversi limiti, tra cui la mancanza di consapevolezza del contesto (ad esempio, non distingue tra diversi significati della stessa parola), la dipendenza da grandi insiemi di dati per l'addestramento e l'incapacità di catturare l'ordine delle parole o il significato a livello di frase. Questi inconvenienti hanno portato allo sviluppo di modelli più avanzati come GloVe, BERT e GPT.
Risorse correlate
Le 10 principali tecniche di PNL che ogni scienziato dei dati dovrebbe conoscere
Top 10 degli strumenti e delle piattaforme di elaborazione del linguaggio naturale
20 popolari dataset aperti per l'elaborazione del linguaggio naturale
GloVe: un algoritmo di apprendimento automatico per la decodifica delle connessioni tra parole
- Che cos'è Word2Vec?
- Perché abbiamo bisogno di Word2Vec?
- Come funziona Word2Vec?
- Implementazione di Word2Vec in Python
- Vantaggi di Word2Vec
- Casi d'uso di Word2Vec
- Limitazioni di Word2Vec
- Colmare il divario: da Word2Vec a GloVe, BERT e GPT
- Word2Vec con Milvus: ricerca vettoriale efficiente per applicazioni NLP
- Conclusione
- FAQ su Word2Vec
- Risorse correlate
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente