




Che cos’è una finestra di contesto nell’IA?

Che cos’è una finestra di contesto nell’IA?
Nell’IA, una finestra di contesto definisce quanto testo il modello può elaborare in una sola volta, misurato in token. Comprendere la finestra di contesto è fondamentale poiché influisce sulla capacità di un modello di IA di generare risposte accurate e coerenti. Questa guida esplorerà che cos’è una finestra di contesto, la sua importanza nei modelli di IA e le sfide nella gestione di finestre di contesto più ampie.
Comprendere i token
Prima di parlare della finestra di contesto, impariamo innanzitutto il concetto di token.
I token sono le unità di dati più piccole che i modelli di IA utilizzano per elaborare e apprendere dal testo. Sono essenzialmente le parti di una frase—come singole parole o segni di punteggiatura—che un computer utilizza per comprendere ed elaborare il linguaggio. Quando un computer legge una frase, la suddivide in parti più piccole (token) per darle un senso. Ad esempio, nella frase "It's sunny!", i token sarebbero "It's", "sunny" e "!". Questo processo, chiamato tokenizzazione, aiuta il computer ad analizzare il testo per attività come tradurre lingue, rilevare spam o rispondere a domande.
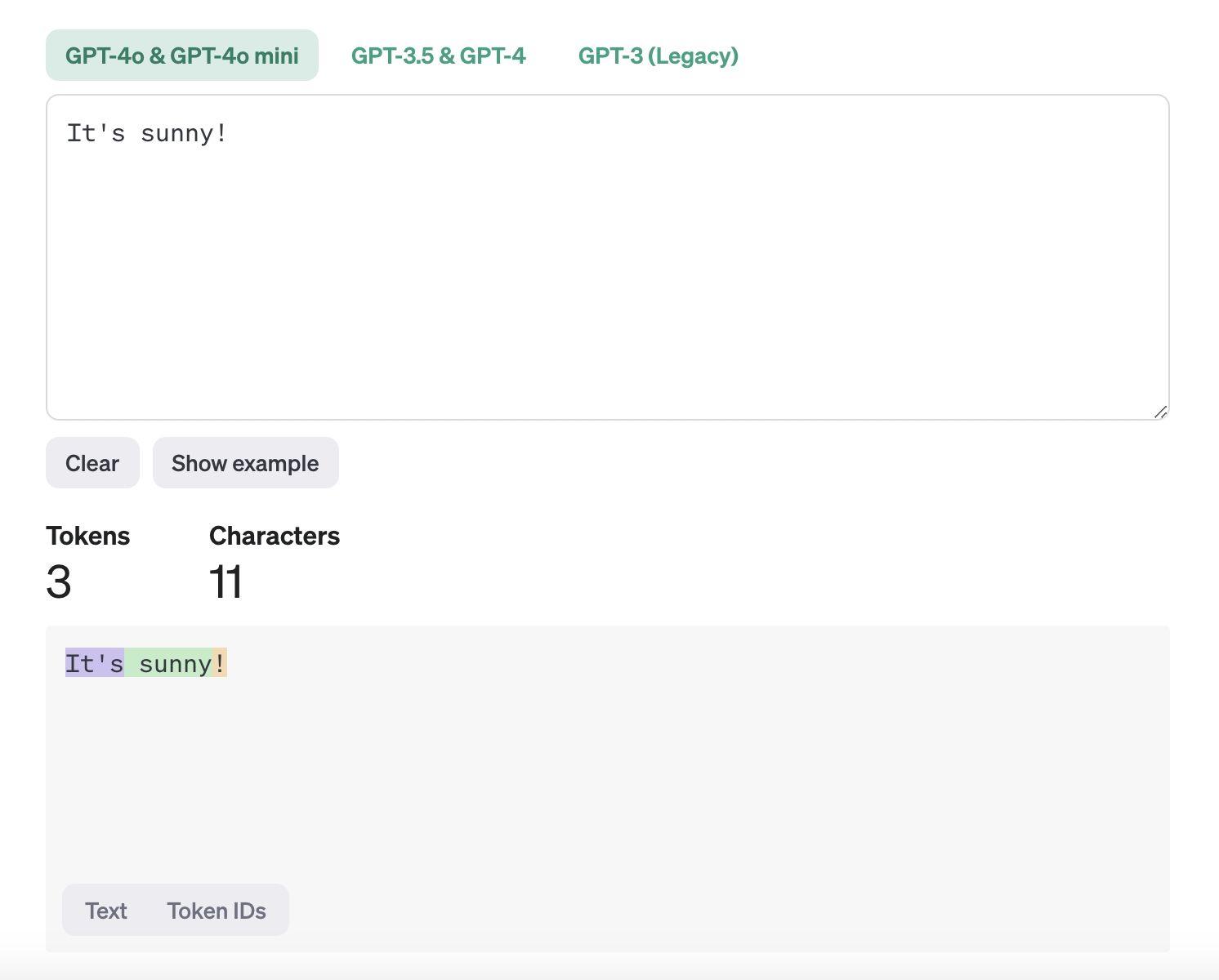 Che cosa sono i token.jpeg
Che cosa sono i token.jpeg
Che cos’è una finestra di contesto nell’IA?
La finestra di contesto è un concetto fondamentale nell’IA, in particolare nei large language models (LLM). Si riferisce alla quantità massima di testo, misurata in token, che un modello di IA può ricordare e utilizzare durante una conversazione quando genera una risposta.
Pensa a una finestra di contesto come alla capacità di memoria a breve termine del modello. Ad esempio, se un modello come ChatGPT ha una finestra di contesto di 4.096 token, può "ricordare" le informazioni degli ultimi 4.096 token (parole o segni di punteggiatura) che ha elaborato. Questo è simile al modo in cui una persona può tenere traccia solo di una certa quantità di informazioni mentre legge o ascolta. Quando questo limite di token viene raggiunto, le informazioni più vecchie iniziano a "svanire" man mano che arrivano nuove informazioni, influenzando la capacità del modello di fare riferimento a parti precedenti della conversazione. Questo concetto è cruciale per determinare quanto bene un modello possa mantenere il contesto durante discussioni o documenti lunghi.
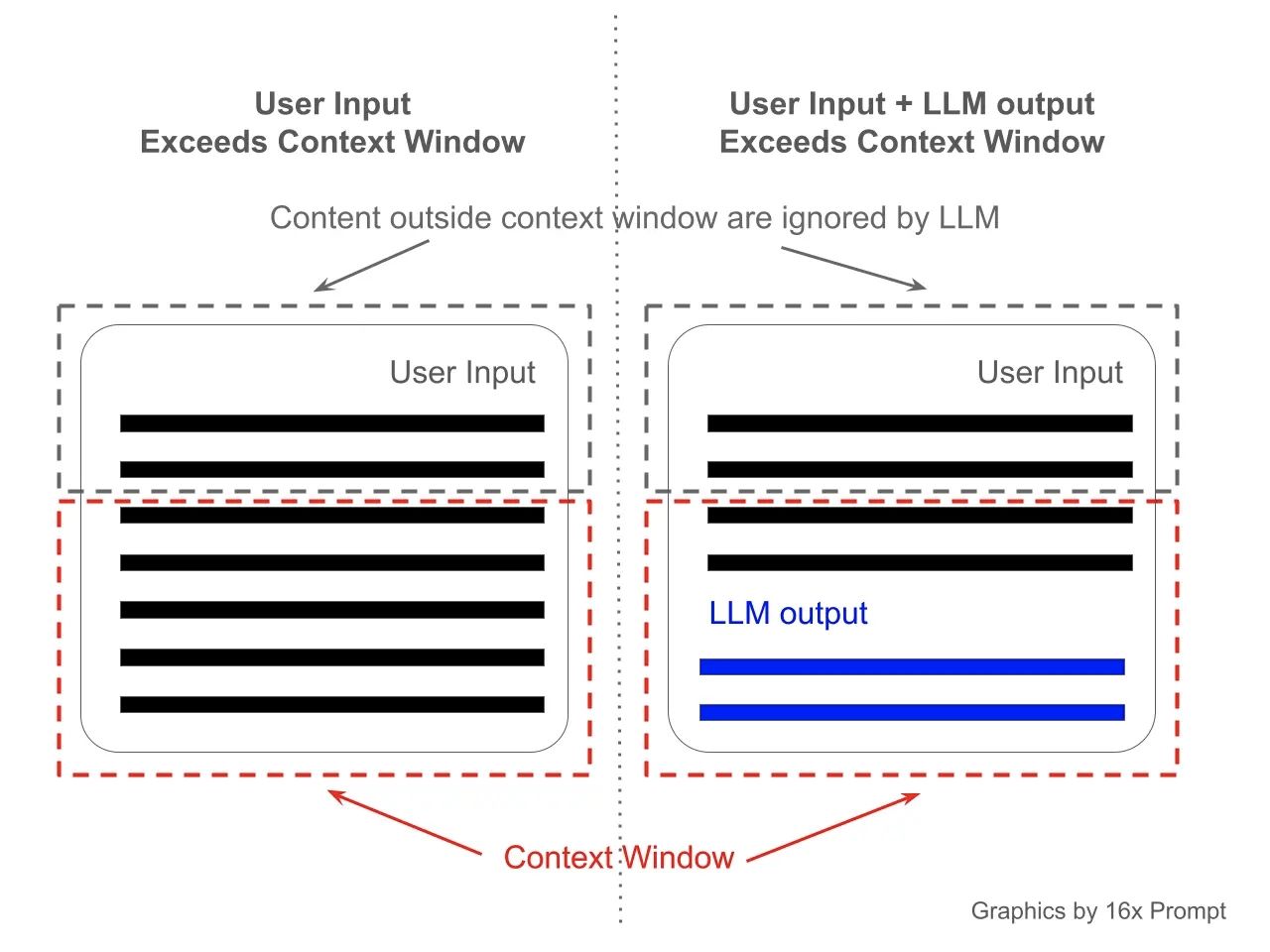 Finestra di contesto visualizzata, credito 16x Prompt.jpeg
Finestra di contesto visualizzata, credito 16x Prompt.jpeg
La finestra di contesto non si applica solo all’input o alla cronologia della conversazione in corso, ma anche alle risposte generate dal modello. Ad esempio, se una risposta contiene essa stessa 500 token, questo conteggio viene detratto dal totale dei token disponibili per l’elaborazione della cronologia della conversazione. Di conseguenza, se ci si avvicina al limite di token, i primi 500 token della conversazione potrebbero non essere considerati nell’elaborazione in corso.
Limiti di token all’interno della finestra di contesto
La dimensione della finestra di contesto, o limite di token, è il numero totale di token che il modello può considerare in una sola volta. Se la conversazione supera questo limite, vengono mantenuti solo i token più recenti e quelli più vecchi vengono eliminati. Ad esempio, il modello avanzato di OpenAI GPT-4o offre una finestra di contesto molto più ampia, fino a 128.000 token, consentendo un’interazione più ampia e approfondita con il testo.
 Finestra di contesto e limite di token di output di GPT-4o.jpeg
Finestra di contesto e limite di token di output di GPT-4o.jpeg
Limiti di token di output e input
Oltre alla finestra di contesto, i modelli di IA hanno limiti di token specifici per output e input:
- Limite di token di output: Questo è il numero massimo di token che il modello può generare in una singola risposta. Ad esempio, GPT-4o-mini di OpenAI ha un limite di token di output di 16.348 token. Se la risposta generata raggiunge questo limite, il modello interromperà la generazione di token, potenzialmente troncando la risposta.
 Limite di token di output di GPT-4o-mini .jpeg
Limite di token di output di GPT-4o-mini .jpeg
- Limite dei token di input: Questo determina quanti token dell'input possono essere elaborati in una sola volta. Superare questo limite significa che il modello deve segmentare l'input in parti più piccole, il che potrebbe influire sulla coerenza e sull'accuratezza della risposta.
Bilanciare i limiti dei token
Il volume del limite dei token influenza significativamente le prestazioni di un modello, determinando la sua capacità di analizzare e interpretare efficacemente informazioni complesse. Bilanciare il numero di token con la potenza di elaborazione del modello è essenziale, poiché capacità di elaborazione più complete consentono di gestire idee complesse in modo più efficace, sebbene con necessari compromessi nelle strategie di tokenizzazione ed elaborazione.
Importanza di finestre di contesto più ampie nei modelli di IA
 Una rappresentazione visiva dell'importanza di finestre di contesto più ampie nell'IA..jpeg
Una rappresentazione visiva dell'importanza di finestre di contesto più ampie nell'IA..jpeg
Finestre di contesto più ampie migliorano significativamente la capacità di un'IA di comprendere e analizzare documenti estesi, rendendole indispensabili in ambiti come la ricerca legale e medica. Ad esempio, nella ricerca legale, l'IA può estrarre efficacemente informazioni rilevanti da grandi set di dati, fornendo rapidamente insight preziosi. Analogamente, nella ricerca medica, ampie finestre di contesto facilitano la sintesi di articoli scientifici complessi, aiutando i ricercatori a ricavare tempestivamente insight.
La maggiore capacità di elaborare oltre un milione di token consente ai modelli di IA di gestire efficacemente attività diverse, dall'elaborazione dei dati alla generazione di codice. Claude 3.5 Sonnet, ad esempio, presenta una dimensione della finestra di contesto di 200.000 token, consentendogli di gestire istruzioni complesse e attività ricche di sfumature con notevole precisione. Questa capacità sottolinea il ruolo critico di finestre di contesto più ampie nel migliorare le prestazioni dell'IA.
Tuttavia, finestre di contesto più ampie nei modelli di IA stessi comportano dei compromessi. Possono portare a costi operativi più elevati e richiedere solide strategie sui dati per garantire l'utilizzo efficace dei dati di addestramento rilevanti. Inoltre, gestire una finestra di contesto più ampia può causare un sovraccarico informativo, riducendo l'efficacia del modello nell'identificare i punti chiave. Pertanto, un approccio equilibrato è essenziale per sfruttare appieno il potenziale di finestre di contesto più ampie mitigando al contempo le sfide associate.
Nella sezione seguente, esploreremo le sfide legate all'espansione delle finestre di contesto.
Sfide legate all'espansione delle finestre di contesto nei modelli di IA
L'espansione delle finestre di contesto nei modelli di IA introduce vari compromessi che richiedono un'attenta considerazione. Consentire input e output più lunghi può aumentare la ricchezza delle risposte generate, ma aumenta anche la complessità dell'elaborazione. L'equilibrio tra finestre di contesto più lunghe ed elaborazione efficiente è cruciale per mitigare potenziali svantaggi nelle prestazioni dell'IA.
Risorse computazionali
Con l'aumentare delle dimensioni delle finestre di contesto, il fabbisogno di potenza di elaborazione aumenta sostanzialmente, portando a tempi di inferenza più lenti. La complessità dello scaling quando si aumentano le finestre di contesto deriva da parametri che aumentano quadraticamente, il che pone sfide significative. Quando la lunghezza delle sequenze di testo raddoppia, le esigenze di memoria e calcolo quadruplicano, evidenziando le maggiori richieste delle finestre di contesto più ampie.
Per affrontare queste sfide, sono state implementate tecniche come la ring attention per migliorare l'efficienza dei modelli che gestiscono finestre di contesto estese. Tuttavia, la teoria della ‘Zona di Sviluppo Prossimale’ suggerisce che sovraccaricare i modelli linguistici con informazioni oltre le loro capacità attuali può diminuirne l'efficacia. Pertanto, è necessaria un'attenta considerazione per gestire efficacemente le risorse computazionali.
Implicazioni sui costi
Finestre di contesto più lunghe possono comportare costi computazionali e finanziari significativi, che le organizzazioni devono gestire in modo efficace. Espandere la finestra di contesto da 4K a 8K token può portare a un aumento esponenziale delle spese operative. Pertanto, le organizzazioni devono valutare i benefici di un miglioramento delle prestazioni dei modelli di IA rispetto all’aumento dei costi delle finestre di contesto più lunghe.
Strategie efficaci di gestione dei costi sono cruciali per le organizzazioni che considerano l’espansione delle finestre di contesto nei modelli di IA. Implementare queste strategie aiuta le organizzazioni a bilanciare capacità di IA potenziate con le relative implicazioni finanziarie, garantendo operazioni di IA sostenibili ed efficienti.
Gestione dei dati
Gestire volumi più grandi di dati di addestramento presenta sfide significative per i modelli di IA, in particolare nell’ottimizzare le prestazioni senza sovraccaricare il sistema. La ricerca indica che fornire un insieme mirato di documenti rilevanti produce prestazioni migliori per i modelli linguistici rispetto a sommergerli con un volume eccessivo di informazioni non filtrate. Questo approccio garantisce che l’IA possa elaborare e rispondere in modo efficace, mantenendo la rilevanza nei suoi output.
Filtrare e gestire il contesto dei dati di addestramento è essenziale per consentire risposte accurate e prestazioni efficienti del modello. Selezionare e organizzare strategicamente i dati rilevanti consente ai modelli di IA di fornire output contestualmente appropriati e significativi, anche con finestre di contesto più grandi.
RAG: potenziare i modelli di IA con una base di conoscenza esterna per una memoria estesa
Finestre di contesto più grandi sono cruciali nei modelli di IA per una migliore comprensione e gestione di compiti complessi. Consentono ai modelli di mantenere e sfruttare informazioni più estese, migliorando la continuità e la rilevanza nelle risposte. Ciò si rivela particolarmente vantaggioso per gestire compiti intricati. Tuttavia, mantenere una finestra di contesto ampia può aumentare le esigenze computazionali, i costi e la complessità nella gestione dei dati.
Per dotare i modelli di IA di capacità di memoria a lungo termine affrontando al contempo queste sfide, i ricercatori hanno esplorato approcci innovativi come Retrieval-Augmented Generation (RAG). Questa tecnica migliora l’output dei modelli di IA collegandoli a una base di conoscenza esterna ospitata in un database vettoriale. Così facendo, fornisce ai modelli un contesto più ampio senza l’overhead associato a grandi finestre di contesto interne. Questa base di conoscenza esterna agisce come una memoria estesa, aiutando i modelli ad accedere dinamicamente a un vasto bacino di informazioni, il che è cruciale per l’elaborazione di query complesse e per migliorare la profondità e l’accuratezza delle risposte.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) combina la potenza generativa dei modelli linguistici con il recupero dinamico di documenti esterni. Questo approccio amplia il potenziale degli LLM accedendo e integrando una gamma più ampia di informazioni, migliorando così la rilevanza e l’accuratezza delle risposte generate.
Un sistema RAG standard integra di solito un embedding model, un database vettoriale come Milvus o la sua versione gestita Zilliz Cloud, e un LLM (o un modello multimodale), dove l’embedding modeltrasforma il testo in embedding vettoriali, il database vettoriale archivia e recupera informazioni contestuali per le query degli utenti, e l’LLM genera risposte basate sul contesto recuperato.
 Figura- flusso di lavoro RAG.png
Figura- flusso di lavoro RAG.png
Sfruttare RAG consente ai modelli di IA di recuperare dinamicamente documenti o punti dati rilevanti durante il processo di generazione, garantendo output ricchi di contesto e allineati con l’intento dell’utente. Questa tecnica è particolarmente utile in scenari che richiedono informazioni dettagliate e precise, come la ricerca legale o l’analisi scientifica.
Confronto delle dimensioni della finestra di contesto tra i modelli più diffusi
 Un grafico comparativo delle dimensioni della finestra di contesto tra i modelli di IA più diffusi
Un grafico comparativo delle dimensioni della finestra di contesto tra i modelli di IA più diffusi
Diversi LLM hanno dimensioni della finestra di contesto variabili, pensate per requisiti e attività differenti. GPT-4o, ad esempio, presenta una dimensione della finestra di contesto di 128.000 token, migliorando significativamente la sua capacità di elaborare input estesi e generare risposte contestualmente rilevanti. Nel frattempo, Gemini 1.5 Pro può utilizzare una finestra di contesto di oltre 2 milioni di token, offrendo vantaggi sostanziali nella gestione di grandi dataset.
Claude 3.5 Sonnet e Llama 3.2 mostrano anch’essi dimensioni della finestra di contesto diverse, ciascuno con i propri punti di forza e limiti. Claude 3.5 Sonnet ha una dimensione della finestra di contesto di 200.000 token, che gli consente di gestire informazioni estese in una singola interazione. Al contrario, Llama 3.2 supporta una finestra di contesto di 128.000 token.
| Modello | Finestra di contesto | Token massimi in output |
|---|---|---|
| GPT-4o | 128.000 token | 16.384 token |
| GPT-4-turbo | 128.000 token | 4.096 token |
| GPT-4 | 8.192 token | 8.192 token |
| Gemini 1.5 Pro | 2.097.152 token | 8.192 token |
| Claude 3.5 Sonnet | 200.000 token | 8192 token |
| Llama 3.2 | 128.000 token | 2048 token |
Riepilogo
In conclusione, padroneggiare la finestra di contesto è essenziale per far progredire le capacità dell’IA. Finestre di contesto più ampie migliorano la capacità dell’IA di elaborare e analizzare documenti estesi, rendendole preziose in ambiti come la ricerca legale e medica. Tuttavia, l’espansione delle finestre di contesto comporta sfide, tra cui maggiori esigenze computazionali, costi più elevati e requisiti complessi di gestione dei dati.
Implementando tecniche come la Retrieval-Augmented Generation (RAG) e database vettoriali, i modelli di IA possono ottimizzare l’utilizzo di lunghe finestre di contesto con una base di conoscenza esterna alimentata da database vettoriali, garantendo risposte contestualmente rilevanti e accurate. Guardando al futuro, bilanciare la dimensione della finestra di contesto con l’efficienza ed esplorare strategie innovative sarà cruciale per sviluppare applicazioni di IA avanzate in grado di gestire efficacemente compiti complessi. Il percorso per padroneggiare le finestre di contesto è in corso, e le possibilità sono illimitate.
Domande frequenti
Che cos’è una finestra di contesto nell’IA?
Una finestra di contesto nell’IA è l’intervallo di testo che circonda un token target e che il modello utilizza per generare risposte, determinando la quantità di informazioni che può elaborare in un dato momento. Comprendere questo concetto è fondamentale per ottimizzare le interazioni con l’IA.
Perché le finestre di contesto più ampie sono importanti?
Le finestre di contesto più ampie sono cruciali poiché migliorano significativamente la comprensione di un modello di IA e la sua capacità di analizzare documenti estesi, producendo risposte più coerenti e contestualmente rilevanti. Questo progresso migliora in ultima analisi la qualità complessiva dell’interazione.
In che modo i limiti di token influiscono sui modelli di IA?
I limiti dei token influiscono in modo critico sui modelli AI determinando la dimensione massima dell'input che possono gestire. Superare questi limiti comporta output incompleti o imprecisi, rendendo necessaria la suddivisione del testo in parti più piccole.
Quali sono le sfide dell'espansione delle finestre di contesto?
L'espansione delle finestre di contesto comporta sfide significative, tra cui maggiori requisiti computazionali e costi operativi più elevati. Inoltre, complica la gestione dei dati, rendendo necessaria un'attenta valutazione prima dell'implementazione.
Come possono essere migliorati i modelli AI con finestre di contesto lunghe?
I modelli AI possono essere migliorati con finestre di contesto lunghe utilizzando tecniche come la Retrieval-Augmented Generation (RAG) e integrando database vettoriali, che aiutano a garantire risposte contestualmente rilevanti e accurate. Questo approccio migliora significativamente le prestazioni del modello nella gestione di informazioni estese.
Ulteriori risorse
- Comprendere i token
- Che cos’è una finestra di contesto nell’IA?
- Importanza di finestre di contesto più ampie nei modelli di IA
- Sfide legate all'espansione delle finestre di contesto nei modelli di IA
- RAG: potenziare i modelli di IA con una base di conoscenza esterna per una memoria estesa
- Confronto delle dimensioni della finestra di contesto tra i modelli più diffusi
- Riepilogo
- Domande frequenti
- Ulteriori risorse
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente