




Comment Inkeep et Milvus ont construit un assistant IA piloté par RAG pour une interaction plus intelligente
En tant que développeurs, il peut être fastidieux de chercher dans la documentation technique de diverses plates-formes ou services. La documentation technique typique contient de nombreuses sections et hiérarchies qui peuvent être confuses ou difficiles à parcourir. Par conséquent, nous passons souvent beaucoup de temps à chercher les réponses dont nous avons besoin. L'ajout d'un assistant IA à la documentation technique peut faire gagner du temps à de nombreux développeurs, car il suffit d'interroger l'IA pour qu'elle réponde à nos questions ou nous redirige vers les pages et les articles pertinents.
Lors d'un récent Unstructured Data Meetup organisé par Zilliz, Robert Tran, cofondateur et directeur technique de Inkeep, a expliqué comment Inkeep et Zilliz ont créé un assistant doté d'une intelligence artificielle pour leur site de documentation. Nous pouvons maintenant voir cet assistant en action sur les sites de documentation de Zilliz et de Milvus.
Dans cet article, nous allons explorer les détails techniques présentés par Robert Tran. Sans plus attendre, commençons par la motivation qui sous-tend l'intégration d'un assistant d'intelligence artificielle dans les pages de documentation technique.
La motivation derrière l'intégration d'un assistant d'intelligence artificielle dans la documentation technique
La documentation technique est une source d'information essentielle que toutes les plateformes doivent fournir pour aider leurs utilisateurs ou leurs développeurs. Elle doit être intuitive, complète et utile pour guider les développeurs, quel que soit leur niveau d'expérience, dans l'utilisation des caractéristiques et des fonctionnalités disponibles sur les plateformes.
Cependant, à mesure que les plateformes introduisent de nombreuses nouvelles fonctionnalités, leur documentation technique peut devenir excessivement complexe. Cette complexité peut potentiellement déconcerter de nombreux développeurs lorsqu'ils naviguent dans la documentation technique d'une plateforme. Les développeurs sont souvent contraints de fournir des résultats rapidement, et le temps passé à rechercher des informations dans la documentation technique peut les distraire du travail de codage et de développement proprement dit.
De nombreuses plateformes offrent des fonctionnalités de recherche de base dans leur documentation technique pour aider les développeurs à trouver rapidement le contenu dont ils ont besoin, de la même manière que nous faisons une recherche sur Google] (https://zilliz.com/learn/evolution-of-search-from-traditional-keyword-matching-to-vector-search-and-genai). Les utilisateurs peuvent taper des mots-clés et la plateforme leur fournit une liste de pages potentiellement pertinentes pour répondre à leurs questions. Toutefois, ces fonctions de recherche de base ne parviennent souvent pas à comprendre le contexte de la requête de l'utilisateur, ce qui se traduit par des résultats de recherche non pertinents ou incomplets.
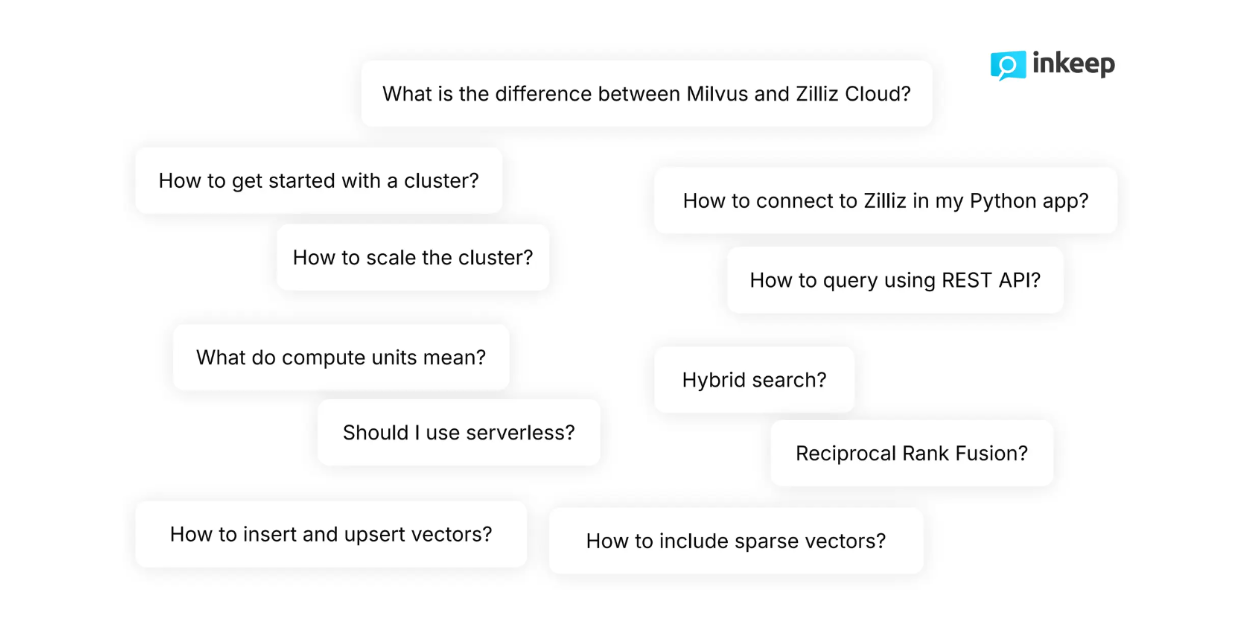 Figure- Questions typiques posées par les développeurs à propos de Milvus .png
Figure- Questions typiques posées par les développeurs à propos de Milvus .png
Figure : Questions typiques posées par les développeurs à propos de Milvus_
En tant que développeurs, nous savons que nos questions sont souvent plus nuancées et parfois trop complexes pour les fonctionnalités de recherche de base. Par exemple, lorsqu'ils naviguent dans la documentation technique de Zilliz, les développeurs posent généralement des questions très techniques telles que "Comment inclure des vecteurs épars aux côtés de vecteurs denses au cours du processus de recherche ?" ou "Comment mettre à l'échelle le cluster de manière dynamique ?" Les fonctionnalités de recherche de base ne parviennent souvent pas à répondre de manière satisfaisante à des questions aussi nuancées et complexes.
L'ajout d'un assistant d'intelligence artificielle résout ces problèmes. Un assistant IA peut comprendre l'intention des développeurs et la signification sémantique de leurs requêtes, ce qui permet aux développeurs d'obtenir les informations dont ils ont besoin en quelques secondes. Les développeurs peuvent simplement taper leur requête et l'assistant IA leur fournira une réponse ou les redirigera vers la page pertinente exacte au lieu de passer en revue un grand nombre de contenus, ce qui est à la fois fastidieux et chronophage.
En outre, les assistants d'IA sont généralement alimentés par les dernières avancées en matière de traitement du langage naturel (NLP), telles que les grands modèles de langage (LLM), la recherche vectorielle et la génération augmentée de recherche (RAG). En fait, l'approche RAG est au cœur de cet assistant d'IA, lui permettant de comprendre les nuances derrière les questions des utilisateurs et de renvoyer des réponses précises et pertinentes en quelques secondes.
Dans la section suivante, nous examinerons les méthodes d'un assistant d'IA.
Le concept de Génération Augmentée de Récupération (GAR)
La [Retrieval Augmented Generation (RAG)] (https://zilliz.com/learn/Retrieval-Augmented-Generation) est une méthode qui combine des techniques avancées de NLP telles que la recherche vectorielle et les LLM pour générer des réponses précises aux requêtes des utilisateurs.
 Figure- RAG workflow.png
Figure- RAG workflow.png
Figure : RAG workflow._
En résumé, le déroulement d'une méthode RAG est assez simple. Tout d'abord, en tant qu'utilisateur, nous posons une question. Ensuite, la méthode RAG recherche les documents pertinents susceptibles de contenir la réponse à notre requête. Ensuite, notre requête et les documents pertinents sont combinés en une invite cohérente avant d'être envoyés à un LLM. Enfin, le LLM génère la réponse à notre requête en utilisant les documents pertinents fournis.
Comme nous pouvons le voir, le concept principal de RAG est de fournir à un LLM un contexte pertinent pour répondre à notre requête. Cette approche présente au moins deux avantages : tout d'abord, elle réduit le risque d'[hallucination] (https://zilliz.com/glossary/ai-hallucination) du LLM, c'est-à-dire de générer des réponses inexactes et mensongères. Deuxièmement, la réponse générée par le LLM sera davantage contextualisée et adaptée à notre requête. Ceci est particulièrement utile lorsque nous posons au LLM des questions sur le contenu de documents internes.
Il y a quatre étapes de RAG que nous devons prendre en compte lors de la mise en œuvre de RAG : l'ingestion, l'indexation, la récupération et la génération.
Ingestion : elle implique la collecte et le prétraitement des données. Les informations pertinentes et les métadonnées de chaque enregistrement peuvent également être collectées.
Indexation : implique le processus de stockage des données avec une méthode d'indexation optimisée pour une recherche rapide. Dans cette étape, les données prétraitées sont transformées en embeddings vectoriels à l'aide d'un modèle d'embedding, puis stockées dans une base de données vectorielles telle que Milvus avec des algorithmes d'indexation avancés tels que FLAT, FAISS, ou HNSW.
Récupération : implique des opérations de recherche vectorielle pour faire correspondre la requête de l'utilisateur avec les données stockées. Dans ce processus, la requête de l'utilisateur est d'abord transformée en un vecteur intégré à l'aide du même modèle d'intégration que celui utilisé pour transformer les données stockées. Ensuite, une recherche de similarité est effectuée entre la requête de l'utilisateur et les données stockées afin de trouver les informations les plus pertinentes dans la base de données vectorielle.
Génération : implique l'utilisation d'un LLM pour produire la réponse finale. Tout d'abord, la requête de l'utilisateur et le contexte le plus pertinent de l'étape de recherche sont combinés en une invite. Ensuite, le LLM génère une réponse à la requête de l'utilisateur sur la base du contexte fourni dans l'invite.
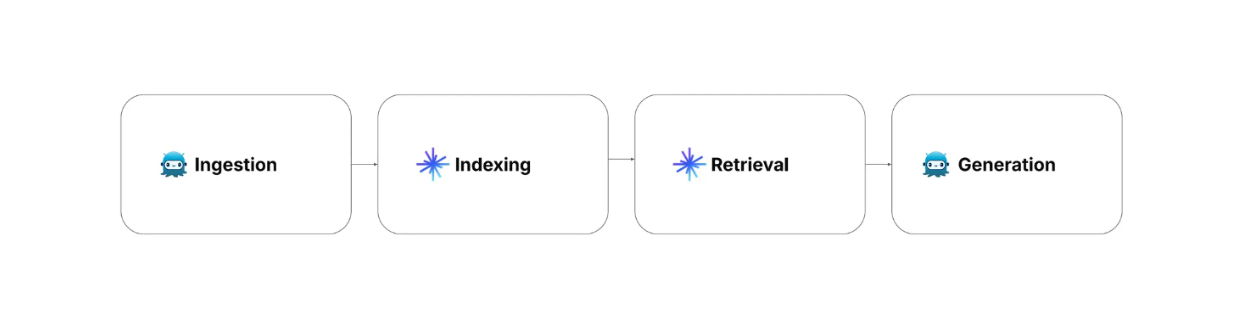 Figure- Steps of RAG..png
Figure- Steps of RAG..png
Figure : Les étapes du RAG._
Plusieurs facteurs doivent être pris en compte lors de la mise en œuvre de chacune des étapes mentionnées ci-dessus. Par exemple, au cours de l'étape d'ingestion, nous devons réfléchir à la source des données, à l'approche de nettoyage des données et à la méthode de découpage. Pendant l'étape d'indexation, nous devons tenir compte du modèle d'intégration et de la base de données vectorielle que nous voulons utiliser, ainsi que des algorithmes d'indexation adaptés à notre cas d'utilisation.
Dans la section suivante, nous discuterons des implémentations détaillées de RAG prises par Inkeep et Zilliz pour construire un assistant IA pour les pages de documentation de Zilliz et Milvus.
Méthodes utilisées par Inkeep et Zilliz pour construire un assistant IA
Pour construire un assistant IA, Inkeep et Zilliz utilisent une combinaison de différentes techniques pour l'implémentation de RAG. Inkeep s'occupe de l'ingestion et de la génération, tandis que Zilliz apporte son soutien à Inkeep pour les étapes d'indexation et de recherche.
Comme indiqué dans la section précédente, la première étape de la mise en œuvre du RAG est l'étape d'ingestion. Dans cette étape, Inkeep collecte les données textuelles relatives à Zilliz et Milvus à partir de diverses sources, telles que la [documentation] technique (https://milvus.io/docs), l'assistance et les FAQ, et les [dépôts GitHub] (https://github.com/milvus-io/milvus). Ces données textuelles sont ensuite nettoyées et découpées pour s'assurer que chaque information n'est ni trop large ni trop granulaire.
Les métadonnées de chaque enregistrement groupé sont également collectées avant de passer à l'étape suivante. Ces métadonnées comprennent
Type de source : les données proviennent-elles d'un dépôt GitHub, d'une documentation technique, d'une page d'assistance et de FAQ, etc.
Type d'enregistrement : la version des données, s'il s'agit d'un texte ou d'un code. S'il s'agit de code, le langage de programmation est également indiqué.
Références hiérarchiques : y compris les enfants, les parents et les frères et sœurs de chaque point de données. Ceci est important car les données sont collectées à partir des sites web de Zilliz.
URL, tags, chemins : tels que les URL à partir desquels les données sont extraites. Ces métadonnées sont très utiles pour fournir des liens vers des citations ou des sources dans la réponse générée par le LLM.
Dates : telles que la date de publication de chaque donnée.
Une fois qu'Inkeep a collecté les données et leurs métadonnées, l'étape suivante est la méthode d'indexation.
Dans la méthode d'indexation, les données prétraitées doivent être transformées en vecteurs intégrés pour permettre la recherche de similarités dans l'étape d'extraction. Pour transformer chaque point de données en un vecteur intégré, Inkeep et Zilliz utilisent trois méthodes d'intégration différentes : un modèle d'intégration clairsemé traditionnel, un modèle d'intégration clairsemé basé sur l'apprentissage profond et un modèle d'intégration dense.
 Figure- Sparse and dense embeddings..png
Figure- Sparse and dense embeddings..png
Figure : Encastrements épars et denses._
Le Sparse embedding est particulièrement utile pour les processus de mise en correspondance simples, basés sur des mots-clés et booléens . Par conséquent, les documents pertinents extraits d'un encapsulage clairsemé contiennent normalement les mots clés de votre requête. En revanche, l'embedding dense est plus utile pour saisir la nuance ou le sens sémantique de votre requête. Les documents extraits de l'intégration dense peuvent ou non contenir les mots clés de votre requête, mais leur contenu sera très pertinent.
Il existe deux types de modèles différents qui peuvent être utilisés pour transformer les données en intégration dense : les modèles traditionnels/statistiques et les modèles basés sur l'apprentissage profond. Pour l'assistant IA, Inkeep et Zilliz utilisent BM25 comme modèle traditionnel et SPLADE/BGE-M3 comme modèle basé sur l'apprentissage profond.
Pour transformer les données en une intégration dense, il existe de nombreux modèles d'apprentissage profond, tels que les modèles d'intégration de [OpenAI] (https://milvus.io/docs/embed-with-sentence-transform.md), [Sentence-Transformers] (https://zilliz.com/learn/training-your-own-text-embedding-model), VoyageAI, etc. Pour l'assistant IA, Inkeep et Zilliz utilisent trois modèles d'intégration différents : MS-MARCO, MPNET et BGE-M3.
Une fois que toutes les données ont été transformées en représentations d'encastrement denses et éparses, les encastrements sont ensuite stockés dans une base de données vectorielle pour permettre une récupération rapide. Pour construire l'assistant IA, Inkeep et Zilliz utilisent Milvus comme base de données vectorielle. La question qui se pose maintenant est la suivante : pourquoi avons-nous besoin d'utiliser une combinaison d'encastrements clairsemés et denses alors que le choix d'un seul d'entre eux pourrait suffire ?
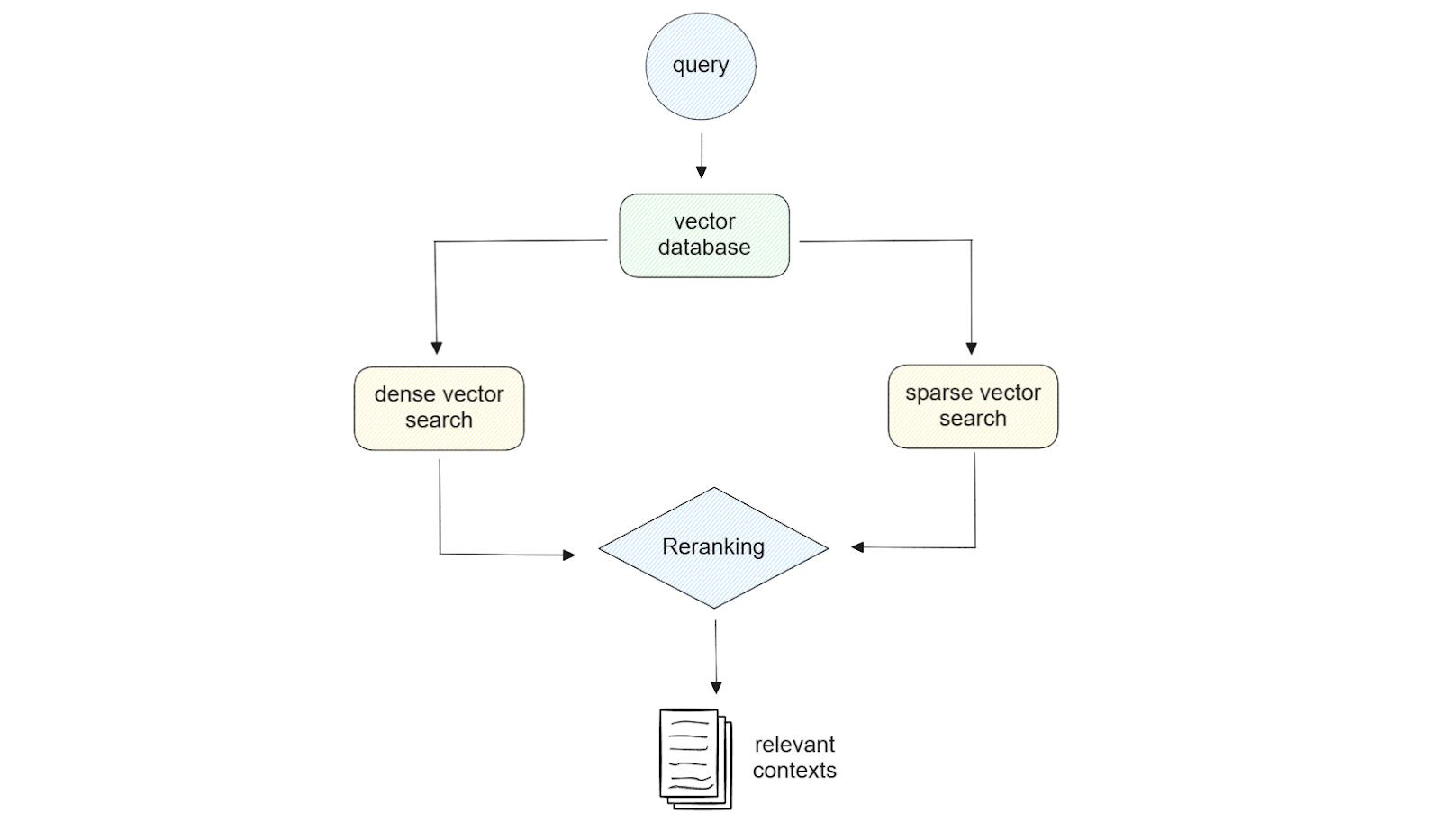 Figure- Illustration de la recherche hybride..png
Figure- Illustration de la recherche hybride..png
Figure : Illustration de la recherche hybride._
L'utilisation de l'intégration dense et éparse offre une certaine souplesse lors de l'étape de recherche. Par exemple, si notre requête est courte (moins de 5 mots), l'utilisation de l'intégration éparse peut être suffisante. En revanche, si notre requête est longue, l'utilisation de l'intégration dense permettra dans la plupart des cas d'obtenir des résultats de meilleure qualité. En outre, si nous utilisons Milvus comme base de données vectorielle, nous pouvons exploiter la puissance de recherche hybride, c'est-à-dire la recherche de similitudes en utilisant une combinaison d'encastrement dense et clairsemé. Nous pouvons également effectuer une recherche de similarité avec un encastrement dense ou clairsemé avec un filtrage des métadonnées si nous le souhaitons.
Lors de la mise en œuvre de la recherche hybride pour trouver le contenu le plus pertinent pour notre requête, nous devons également prendre en compte la [méthode de reclassement] (https://zilliz.com/learn/what-are-rerankers-enhance-information-retrieval). En effet, nous obtiendrons des résultats de similarité à partir de deux méthodes différentes et nous avons besoin d'une approche pour combiner ces résultats. Pour ce faire, Inkeep et Zilliz ont mis en œuvre deux méthodes de reclassement différentes : la notation pondérée et la fusion des rangs réciproques (RRF).
Le concept de la notation pondérée est simple : nous attribuons un poids à chaque méthode. Par exemple, nous pouvons attribuer un poids de 60 % au résultat de similarité de l'intégration dense et de 40 % à celui de l'intégration clairsemée. Par ailleurs, dans la méthode RRF, les scores des contextes sont calculés en additionnant leurs rangs réciproques dans deux méthodes différentes, souvent avec une petite constante supplémentaire k pour éviter la division par zéro.
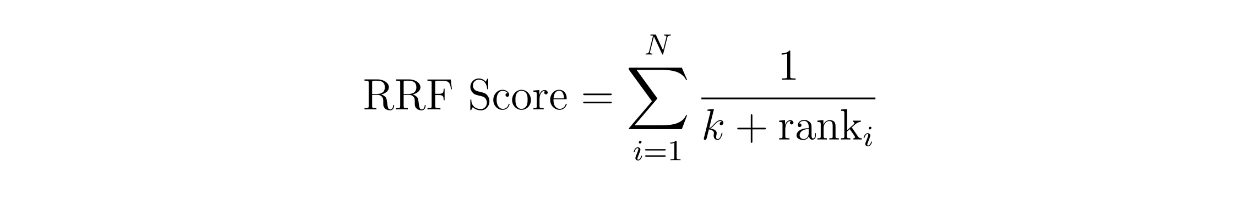 function rrf score.png
function rrf score.png
où N est le nombre de méthodes, qui devrait être de deux puisque nous mettons en œuvre une recherche hybride entre un encastrement clairsemé et un encastrement dense. La variable 'rank' est le rang d'un contexte dans la méthode i, et k est une constante.
En utilisant l'équation RRF ci-dessus, nous pouvons calculer le score RRF pour chaque contexte. Le contexte ayant le score RRF le plus élevé sera sélectionné comme le contexte le plus pertinent pour une requête.
Une fois que le contexte pertinent a été extrait, la requête originale et le contexte le plus pertinent sont combinés en une invite cohérente. Cette invite est ensuite envoyée à un LLM pour générer la réponse finale. Pour le LLM, Inkeep utilise des modèles d'OpenAI et d'Anthropic.
Démonstration de l'assistant IA Milvus
Dans cette section, nous allons fournir une brève introduction à l'utilisation de l'assistant d'IA construit par Inkeep et Zilliz. Si vous voulez suivre, vous pouvez consulter les pages de documentation de Zilliz ou de Milvus. Pour cette démo, nous utiliserons l'assistant d'intelligence artificielle de la page de documentation de Milvus.
Lorsque vous ouvrez la page de documentation de Milvus, vous verrez le bouton "Ask AI" en bas à droite de votre écran. Cliquez sur ce bouton pour accéder à l'assistant IA.
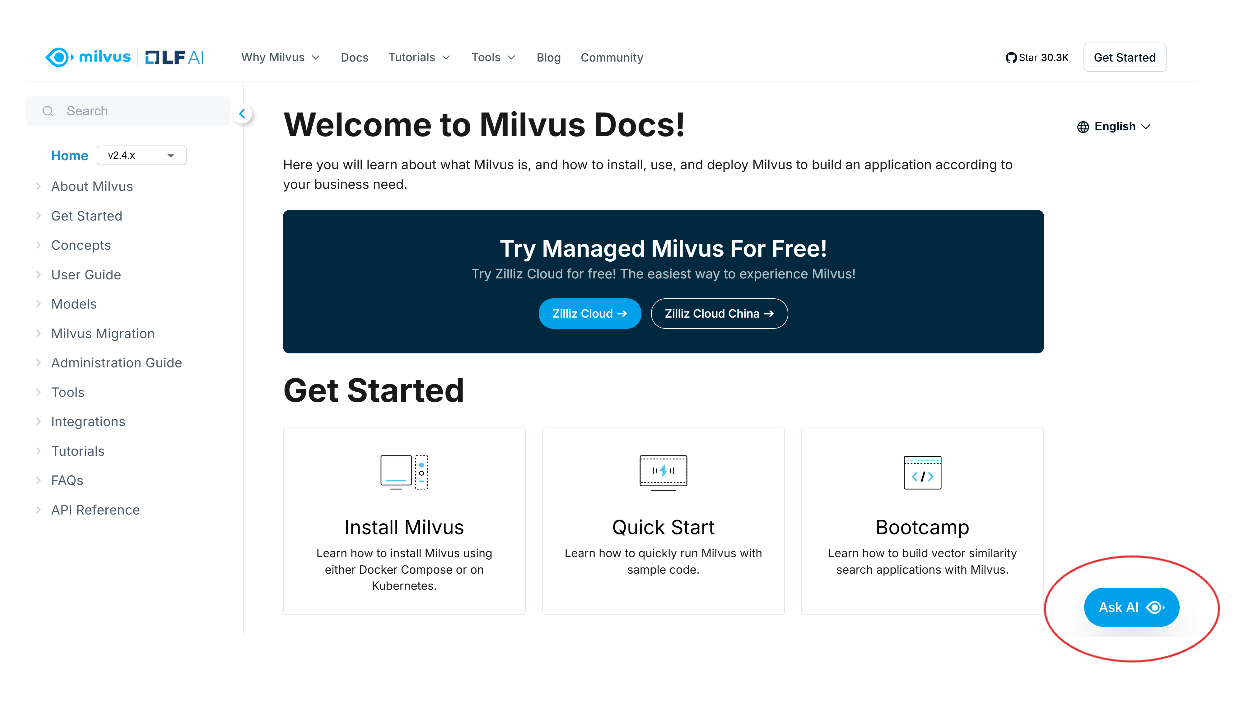 screenshot 1.png
screenshot 1.png
Ensuite, une fenêtre contextuelle s'affiche, vous invitant à demander ce que vous souhaitez trouver dans la documentation Milvus. Vous pouvez également effectuer une recherche de base en cliquant sur l'option "Recherche" en haut à droite de la fenêtre contextuelle.
Disons que nous voulons savoir comment transformer nos données en embeddings vectoriels à l'aide de BGE-M3 avec le SDK Milvus Python. Il nous suffit de taper notre question et l'assistant IA nous fournira une réponse.
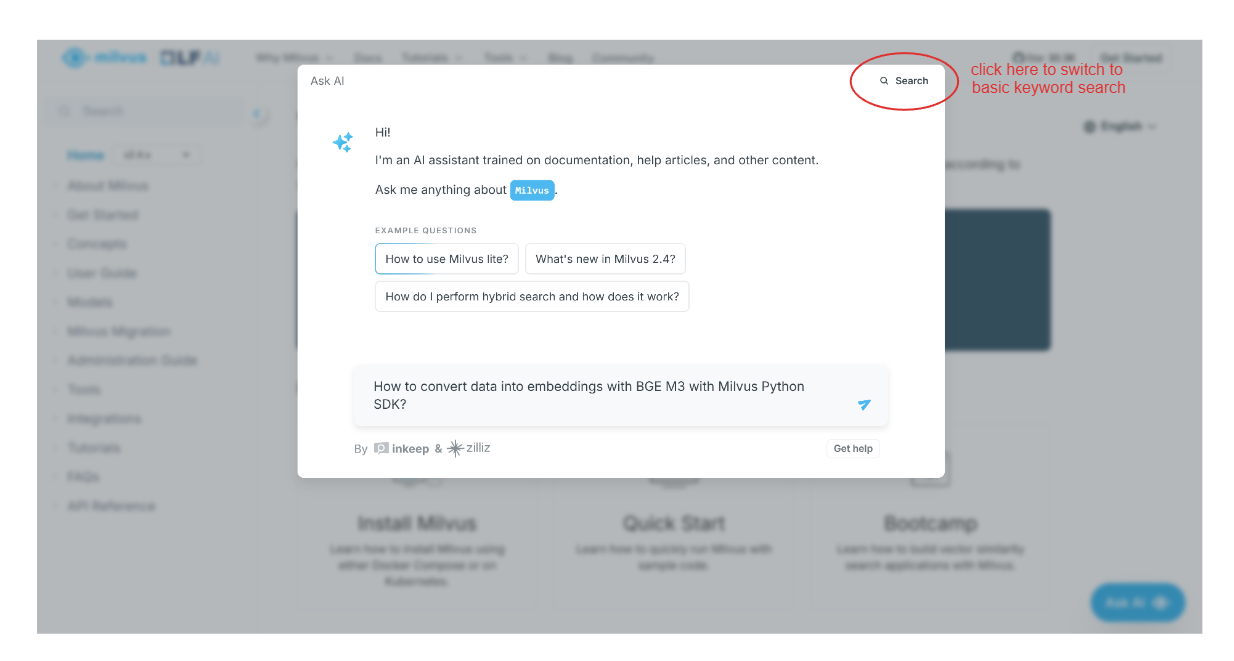 screenshot 2.png
screenshot 2.png
En plus de fournir une réponse, l'assistant d'IA nous donnera également des citations ou des pages pertinentes où nous pourrons trouver des informations supplémentaires en rapport avec la réponse générée.
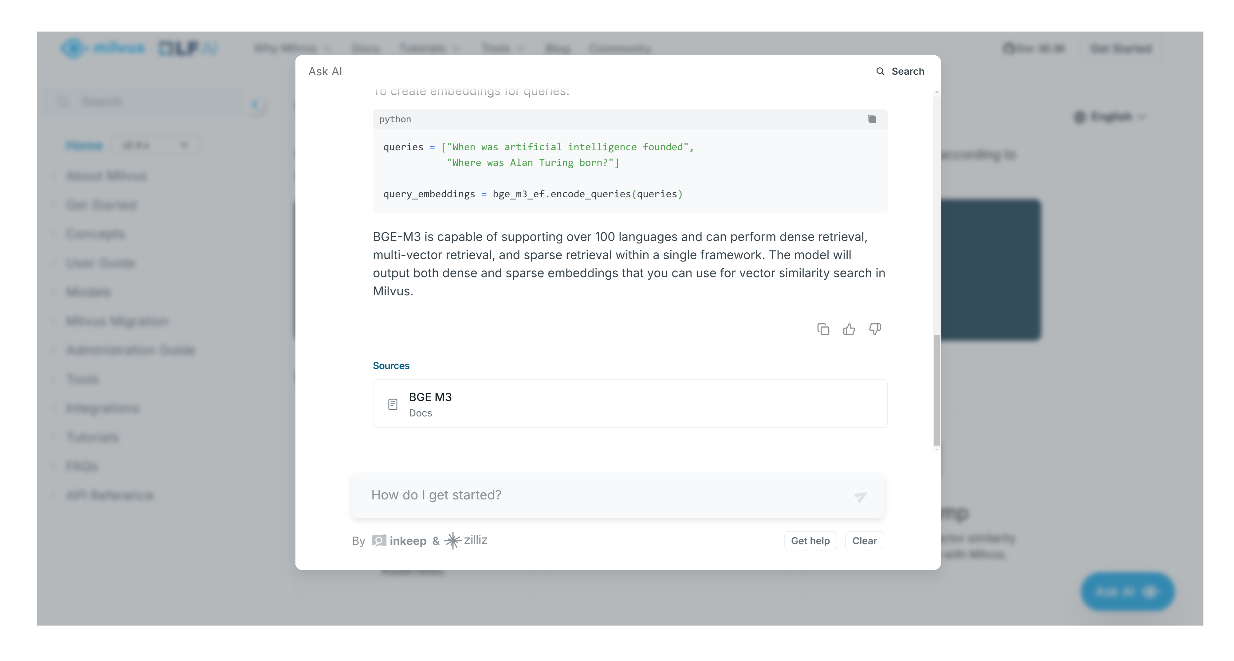 screenshot 3.png
screenshot 3.png
Conclusion
L'intégration d'un assistant d'IA dans la documentation technique, tel que construit par Inkeep et Zilliz, démontre comment les solutions d'IA avancées peuvent améliorer la productivité des développeurs et l'expérience des utilisateurs. RAG est le composant central de cet assistant d'IA, car cette méthode aide le LLM à fournir des réponses plus précises et contextualisées à des requêtes nuancées et complexes.
Le RAG se compose de quatre étapes clés : l'ingestion, l'indexation, la récupération et la génération. Les bases de données vectorielles telles que Milvus sont un élément clé du pipeline RAG, car elles réalisent les étapes d'indexation et d'extraction. Les méthodes utilisées à chaque étape doivent être soigneusement étudiées en fonction du cas d'utilisation spécifique. Dans cet article, nous avons également vu un exemple de la façon dont Inkeep et Zilliz ont mis en œuvre diverses stratégies dans chaque étape du RAG pour construire un assistant d'IA sophistiqué.
Pour en savoir plus sur la manière dont Milvus et Inkeep ont construit cet assistant, consultez la [rediffusion de la conférence de Robert sur YouTube] (https://youtu.be/35JdjmiDvWI?list=PLPg7_faNDlT7SC3HxWShxKT-t-u7uKr--&t=2879).
Pour en savoir plus
Modèles d'IA les plus performants pour vos applications GenAI | Zilliz
Construire des applications d'IA avec Milvus : Tutoriels et carnets de notes
[Qu'est-ce que RAG ?] (https://zilliz.com/learn/Retrieval-Augmented-Generation)
Continuer à lire

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.

Legal Document Analysis: Harnessing Zilliz Cloud's Semantic Search and RAG for Legal Insights
Enhance legal document analysis with Zilliz Cloud’s Semantic Search and RAG. Improve accuracy, efficiency, and scalability for contracts, case law, and compliance.