




Benchmark Masivo de Embeddings de Texto (MTEB)
Benchmark Masivo de Embeddings de Texto (MTEB)
Los embeddings de texto a menudo se prueban en un pequeño número de conjuntos de datos de una sola tarea, lo que no muestra qué tan bien funcionan para otras tareas. No está claro si los mejores embeddings para Similitud Textual Semántica (STS) funcionan igual de bien para tareas como clustering o reranking. Esto dificulta ver el progreso en el campo, ya que comúnmente se evalúan y proponen constantemente nuevos modelos y embeddings sin pruebas consistentes.
Para abordar este problema, los investigadores han creado el Benchmark Masivo de Embeddings de Texto (MTEB). MTEB cubre 8 tareas de embedding en 58 conjuntos de datos en 112 idiomas. Los investigadores probaron 8 tareas de embedding que cubren 33 modelos en MTEB, lo que lo convierte en el benchmark más completo para embeddings de texto hasta ahora.
Descubrieron que ningún método de embedding único es el mejor para todas las tareas. Esto sugiere que aún no se ha desarrollado un método universal de embedding de texto que funcione mejor para todas las tareas de embedding, incluso cuando se escala. Esto también destaca la importancia de hacer la debida diligencia para elegir los modelos de embedding que mejor se adapten a tus requisitos.
MTEB viene con código de código abierto, una tabla de clasificación pública y una divertida MTEB Arena para votar sobre cosas como qué modelos recuperan el mejor documento, hacen mejor clustering, etc., ambos en el sitio web de Hugging Face. Este benchmark ayudará a la comunidad a probar nuevos métodos de manera consistente y a hacer un seguimiento de las mejoras en la tecnología de embeddings de texto.
Antecedentes y Motivación
Los embeddings de texto se han convertido en una parte clave de muchas tareas de Procesamiento del Lenguaje Natural (NLP). Estos embeddings convierten palabras, oraciones o documentos en representaciones numéricas que capturan su significado. Se utilizan en diversas aplicaciones como traducción automática, reconocimiento de entidades nombradas, respuesta a preguntas, análisis de sentimientos y resumen.
A lo largo de los años, los investigadores han creado muchos conjuntos de datos y benchmarks para probar estos embeddings. Algunos conocidos incluyen SemEval, GLUE, SuperGLUE, Big-Bench, WordSim353 y SimLex-999. Estos suelen centrarse en evaluar embeddings de palabras estándar y contextuales.
Sin embargo, todavía hay algunas brechas en la forma en que se evalúan los embeddings de texto:
Pocos benchmarks cubren tanto embeddings de palabras como embeddings de oraciones.
Muchas evaluaciones se centran en tareas específicas de NLP, no en qué tan bien los embeddings capturan el significado general del texto.
Los benchmarks existentes a menudo no consideran cómo podrían usarse los embeddings en aplicaciones del mundo real.
Existe la necesidad de un benchmark integral que pueda evaluar una amplia gama de tareas de comprensión de texto. Este benchmark debería ser útil tanto para investigadores de NLP como para personas que trabajan en aplicaciones prácticas. El Benchmark Masivo de Embeddings de Texto (MTEB) tiene como objetivo llenar esta brecha.
Embeddings de Texto
Un embedding de texto es una forma de representar texto como una lista de números. Estos números pueden representar una sola palabra, una oración o incluso un documento completo. La lista suele tener cientos de números.
Las incrustaciones de texto se usan en muchas tareas de NLP. Para palabras, se usan en cosas como la corrección ortográfica y la búsqueda de relaciones entre palabras. Para textos más largos, se usan en tareas como averiguar el sentimiento de un escrito o generar texto nuevo.
Hay muchas formas diferentes de crear incrustaciones de texto. Algunos métodos populares incluyen:
Métodos basados en modelos de lenguaje como ULMFit, GPT, BERT y PEGASUS
Métodos entrenados en varias tareas de NLP, como ELMo
Métodos basados en palabras como word2vec y GloVe, que se usan a menudo en la investigación de visión por computadora
Los investigadores han creado muchas incrustaciones diferentes: hay al menos 165 para comparar. También han creado 15 herramientas diferentes (como árboles de decisión y Random Forests) para ayudar a entender las fortalezas y debilidades de estas incrustaciones.
Sin embargo, no existe una forma estándar de comparar todas estas incrustaciones diferentes. Este es un problema que el Massive Text Embedding Benchmark (MTEB) intenta resolver.
Diseño e implementación del Massive Text Embedding Benchmark
MTEB fue diseñado con varios objetivos importantes en mente:
Diversidad: MTEB prueba modelos de incrustación en muchas tareas diferentes. Incluye 8 tipos diferentes de tareas, con hasta 15 conjuntos de datos para cada una. De los 58 conjuntos de datos totales, 10 funcionan con varios idiomas, cubriendo 112 idiomas en total. El benchmark prueba tanto textos cortos (a nivel de oración) como largos (a nivel de párrafo) para ver cómo se desempeñan los modelos con diferentes longitudes de texto.
Simplicidad: MTEB es fácil de usar. Cualquier modelo que pueda tomar una lista de textos y producir una lista de representaciones numéricas (vectores) puede ser probado. Esto significa que se pueden comparar muchos tipos diferentes de modelos.
Extensibilidad: Es fácil añadir nuevos conjuntos de datos a MTEB. Para tareas existentes, solo necesitas añadir un archivo que describa la tarea y apunte a dónde están almacenados los datos en Hugging Face. Añadir nuevos tipos de tareas requiere un poco más de trabajo, pero MTEB acepta contribuciones de la comunidad para ayudarlo a crecer.
Reproducibilidad: MTEB facilita la repetición de experimentos. Lleva un registro de diferentes versiones de conjuntos de datos y software. Los resultados del artículo de MTEB están disponibles como archivos JSON, para que cualquiera pueda verificarlos o usarlos.
Estas características hacen de MTEB una herramienta integral y flexible para evaluar modelos de incrustación de texto en tareas que cubren una amplia variedad total de tareas e idiomas.
Tareas y evaluación en Massive Text Embedding Benchmark
Massive Text Embedding Benchmark incluye 8 tipos diferentes de tareas para probar modelos de incrustación. Aquí tienes un desglose sencillo de cada tarea:
Minería bitextual: Encontrar oraciones coincidentes en dos idiomas diferentes. La medida principal es la puntuación F1.
Clasificación: Usar incrustaciones para ordenar textos en categorías. La medida principal es la exactitud.
Agrupamiento: Agrupar textos similares. La medida principal es v-measure.
Clasificación de pares: Decidir si dos textos son similares o no. La medida principal es la precisión promedio.
Reordenamiento: Ordenar una lista de textos según qué tan bien coincidan con una consulta. La medida principal es MAP (Mean Average Precision).
Recuperación: Encontrar documentos relevantes para una consulta dada. La medida principal es nDCG@10.
Similitud textual semántica (STS): Medir qué tan similares son dos oraciones. La medida principal es la correlación de Spearman.
Resumen: Puntuar resúmenes generados por máquina frente a los escritos por humanos. La medida principal también es la correlación de Spearman.
Para cada tarea, MTEB usa el modelo de embeddings para convertir textos en embeddings vectoriales. Luego usa métodos como la similitud del coseno o la regresión logística para realizar la tarea y calcular puntuaciones.
MTEB incluye muchos datasets para cada tarea, que cubren diferentes idiomas y longitudes de texto. Esto ayuda a probar qué tan bien funcionan los modelos de embeddings en diversas situaciones.
Al usar estas diversas tareas y datasets, el Massive Text Embedding Benchmark proporciona una forma integral de evaluar y comparar diferentes modelos de embeddings de texto.
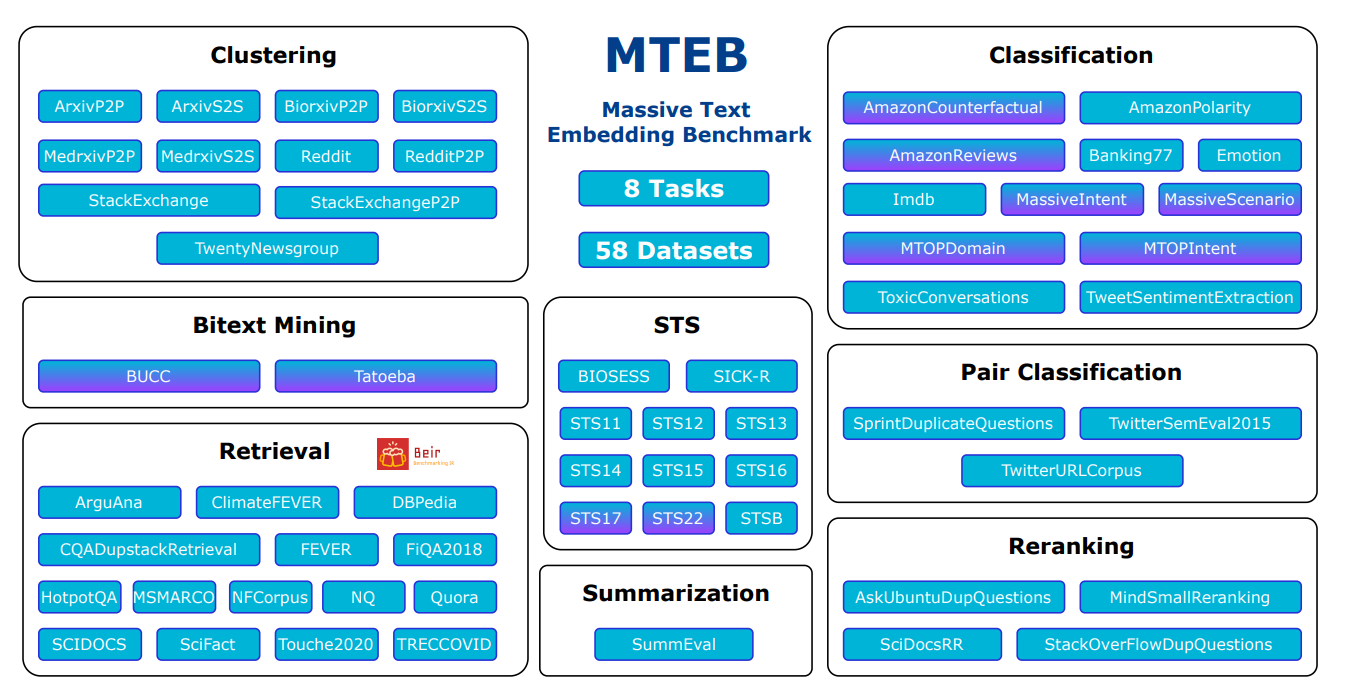 Descripción general de tareas y datasets en MTEB
Descripción general de tareas y datasets en MTEB
Fuente: MTEB: Massive Text Embedding Benchmark
Datasets en el Massive Text Embedding Benchmark
El Massive Text Embedding Benchmark usa muchos datasets diferentes para probar métodos y modelos particulares de embeddings de texto. Estos datasets se agrupan en tres tipos principales según la longitud de los textos que se comparan:
Sentence to Sentence (S2S): Esto ocurre cuando una oración se compara con otra. Por ejemplo, en las tareas de Similitud Textual Semántica, el objetivo es averiguar qué tan similares son dos oraciones.
Paragraph to Paragraph (P2P): Esto implica comparar fragmentos de texto más largos. MTEB no establece un límite sobre qué tan largos pueden ser, dejando que los modelos manejen textos más largos si es necesario. Algunas tareas, como el clustering, se realizan tanto como S2S (comparando solo títulos) como P2P (comparando títulos y contenido).
Sentence to Paragraph (S2P): Esto se usa en algunas tareas de recuperación, donde una consulta corta (oración) se compara con documentos más largos (párrafos).
MTEB incluye 56 datasets diferentes. Algunos de estos datasets son similares entre sí:
Algunos usan los mismos datos de texto subyacentes (como ClimateFEVER y FEVER).
Los datasets para tareas similares (como diferentes versiones de CQADupstack o STS) tienden a parecerse.
Las versiones S2S y P2P del mismo dataset suelen ser similares.
Los datasets sobre temas similares (como artículos científicos) tienden a parecerse, incluso si son para tareas diferentes.
Al usar una variedad tan amplia de datasets, MTEB puede probar qué tan bien funcionan los modelos de embeddings con diferentes tipos de texto y diferentes tareas. Esto ayuda a dar una imagen más completa de las fortalezas y debilidades de cada modelo.
Modelos en la evaluación comparativa inicial del Massive Text Embedding Benchmark
Para la primera ronda de pruebas con MTEB, los investigadores analizaron modelos que afirman ser los mejores y aquellos que son populares en Hugging Face Hub. Esto significó que probaron muchos modelos transformer. Agruparon los modelos en tres tipos para ayudar a las personas a elegir el mejor para sus necesidades:
Modelos más rápidos: Modelos como Glove son muy rápidos, pero no entienden bien el contexto. Esto significa que no obtienen puntuaciones tan altas en MTEB en general.
Modelos equilibrados: Modelos como all-mpnet-base-v2 o all-MiniLM-L6-v2 son un poco más lentos que los más rápidos, pero tienen un rendimiento mucho mejor. Ofrecen una buena combinación de velocidad y calidad.
Modelos con mejor rendimiento: Los modelos grandes con miles de millones de parámetros, como ST5-XXL, GTR-XXL o SGPT-5.8B-msmarco, son los que mejor funcionan en MTEB. Pero pueden ser más lentos y necesitar más almacenamiento. Por ejemplo, SGPT-5.8B-msmarco crea embeddings con 4096 números, lo que ocupa más espacio.
Es importante señalar que el rendimiento de un modelo puede cambiar mucho según la tarea y el dataset específicos. Los investigadores sugieren consultar la clasificación de MTEB para ver qué modelo podría funcionar mejor para una sola tarea y tus necesidades específicas.
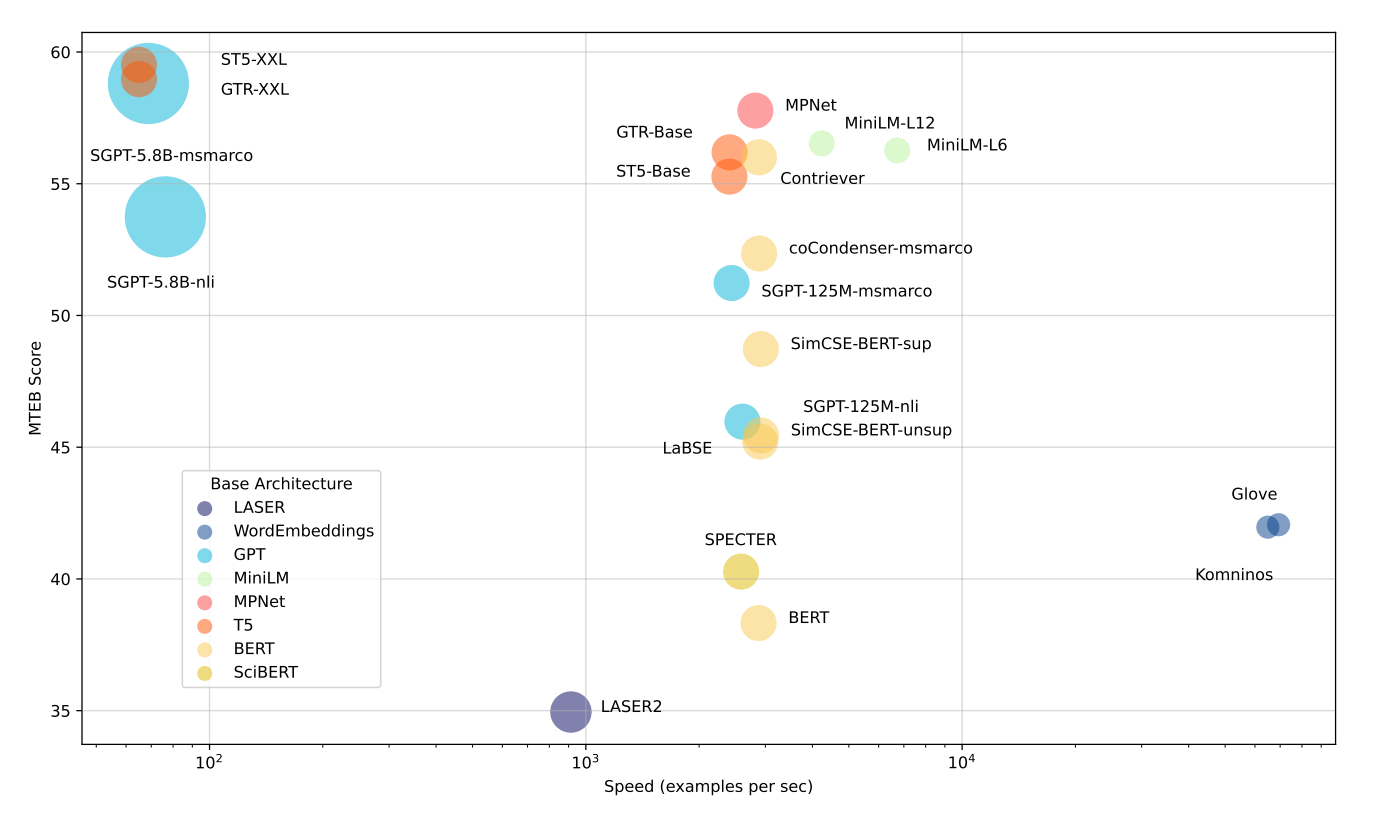 Resultados de las evaluaciones comparativas de la prueba inicial
Resultados de las evaluaciones comparativas de la prueba inicial
Fuente: MTEB: Massive Text Embedding Benchmark
Este enfoque de evaluación ofrece una imagen clara de las compensaciones entre velocidad y rendimiento en diferentes modelos de embeddings, lo que ayuda a los usuarios a tomar decisiones informadas según sus requisitos específicos. Si quieres probarlo por tu cuenta, hay un excelente blog en Huggigng Face que te guía paso a paso para evaluar cualquier modelo que produzca embeddings vectoriales.
Cuándo usar Massive Text Embedding Benchmark
MTEB es una herramienta para evaluar qué tan bien funcionan los modelos de embeddings de texto en muchas tareas diferentes. Es útil en varias situaciones:
Evaluar tu modelo: Si has creado un nuevo modelo de embeddings, puedes usar MTEB para ver cómo se compara con otros modelos. Puedes añadir tus resultados a la clasificación pública, lo que te ayuda a ver cómo se posiciona tu modelo frente a los demás.
Elegir el modelo adecuado: Diferentes modelos funcionan mejor para diferentes tareas. La clasificación de MTEB muestra cómo se desempeñan los modelos en varias tareas, lo que te ayuda a elegir el mejor modelo para tus necesidades específicas.
Ayudar a mejorar MTEB: MTEB es de código abierto y, por lo tanto, está abierto a que cualquiera contribuya. Si has creado una nueva tarea, conjunto de datos, forma de medir el rendimiento o modelo, puedes añadirlo a MTEB. Esto ayuda a que el benchmark sea aún mejor.
Investigación: Si estás estudiando embeddings de texto, MTEB te ofrece una forma exhaustiva de evaluar modelos. Puede mostrarte qué pueden hacer los mejores modelos actuales y dónde hay margen de mejora.
Al proporcionar una forma estándar de evaluar modelos en muchas tareas, MTEB ayuda a investigadores y desarrolladores a comprender y mejorar la tecnología de embeddings de texto. Es una herramienta valiosa para cualquiera que trabaje con embeddings de texto o los estudie.
Cómo usar la clasificación de Massive Text Embedding Benchmark
En primer lugar, ¡no te dejes engañar por las puntuaciones de MTEB!
MTEB es una herramienta útil, pero es importante comprender sus limitaciones. Aunque muestra puntuaciones, no te dice si las diferencias entre ellas son significativas. Muchos de los mejores modelos tienen puntuaciones promedio muy cercanas, que provienen de muchas tareas diferentes, pero no hay información sobre cuánto varían estas puntuaciones. El modelo mejor clasificado podría parecer mejor, pero la diferencia podría no ser importante. Los usuarios pueden obtener los resultados sin procesar para comprobarlo por sí mismos. Algunos investigadores han descubierto que varios de los mejores modelos en ciertos benchmarks de lenguaje son en realidad igual de buenos, estadísticamente hablando. En lugar de fijarse solo en las puntuaciones promedio, es mejor centrarse en cómo se desempeñan los modelos en tareas similares al caso de uso previsto. Esto podría aportar más información sobre cómo funcionará un modelo para una aplicación específica que la puntuación general. No es necesario estudiar los conjuntos de datos en detalle, pero saber qué tipo de texto contienen es beneficioso. Esta información suele estar disponible en la descripción del conjunto de datos y con un vistazo rápido a algunos ejemplos. Massive Text Embedding Benchmark es una herramienta útil, pero no es perfecta. Es importante pensar críticamente sobre los resultados y cómo se aplican a necesidades específicas. En lugar de simplemente elegir el modelo con la puntuación general más alta, es mejor profundizar para encontrar el mejor modelo para la tarea en cuestión.
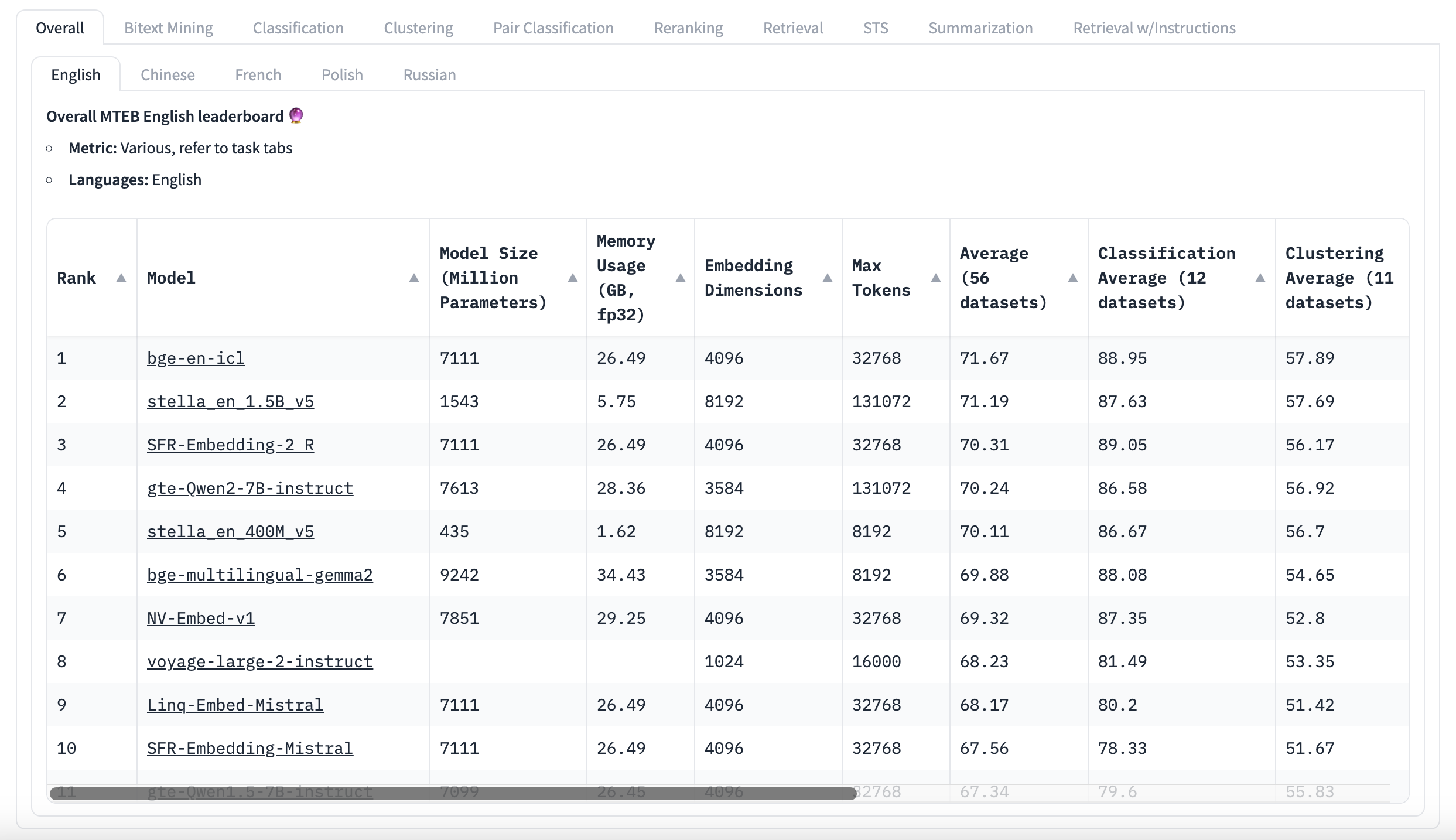 Clasificación de MTEB en inglés
Clasificación de MTEB en inglés
Recuerda considerar las necesidades de tu aplicación
No existe un modelo único que sirva para todas las tareas. Por eso existe Massive Text Embedding Benchmark: para ayudarte a elegir el modelo adecuado para tus necesidades específicas. Al consultar la clasificación de Massive Text Embedding Benchmark, es importante pensar en lo que requiere tu aplicación. Aquí tienes algunas cosas que considerar:
Idioma: ¿El modelo admite el idioma con el que estás trabajando?
Vocabulario especializado: Si trabajas con textos financieros o legales, necesitarás un modelo que entienda términos específicos del campo.
Tamaño del modelo: Piensa en dónde ejecutarás el modelo. ¿Tendrá que caber en una laptop?
Uso de memoria: ¿Cuánta memoria de la computadora puedes reservar para el modelo?
Longitud máxima de entrada: ¿Qué tan largos son los textos con los que trabajarás?
Una vez que sepas qué es importante para tu tarea, puedes ordenar varios modelos en la tabla de clasificación de MTEB según estas características. Esto facilita encontrar un modelo que no solo tenga un buen rendimiento, sino que también se ajuste a tus requisitos prácticos.
Al considerar tanto el rendimiento como las necesidades prácticas, puedes elegir un modelo que funcione mejor para tu situación específica.
El recurso Zilliz AI Model
Ahora que has elegido tu modelo de incrustación de texto del Massive Text Embedding Benchmark, pongámoslo a trabajar para crear incrustaciones de texto que se almacenarán y recuperarán en Milvus de código abierto o Zilliz Cloud. En el sitio web de Zilliz, puedes encontrar la página AI Models, que enumera algunos de los modelos multimodales y de incrustación de texto más populares.
 Página Zilliz AI Model
Página Zilliz AI Model
Una vez que seleccionas un modelo en esta página, puedes ver que hay algunas instrucciones detalladas sobre cómo crear las incrustaciones vectoriales usando los distintos SDK, PyMilvus y más.
Conclusión
El Massive Text Embedding Benchmark (MTEB) es un avance significativo en la evaluación de modelos de incrustación de texto. Aborda las limitaciones de los benchmarks anteriores al cubrir una amplia variedad de tareas, idiomas y longitudes de texto. El diseño de MTEB se centra en la diversidad, la simplicidad, la extensibilidad y la reproducibilidad, lo que lo convierte en una herramienta valiosa tanto para investigadores como para profesionales en el campo del Procesamiento del Lenguaje Natural.
El enfoque de benchmark más completo de MTEB, que prueba modelos en 8 tareas diferentes y 58 conjuntos de datos, proporciona una imagen más completa de las capacidades de un modelo que los benchmarks anteriores. Revela que ningún método de incrustación único sobresale en todas las tareas, lo que destaca la importancia de elegir el modelo adecuado para aplicaciones específicas.
Al usar MTEB, es crucial mirar más allá de las puntuaciones generales y considerar las necesidades específicas de tu aplicación. Factores como la compatibilidad con idiomas, el vocabulario especializado, el tamaño del modelo, el uso de memoria y la longitud máxima de entrada deben desempeñar un papel en el proceso de toma de decisiones.
Aunque MTEB es una herramienta potente, es importante usarla de forma crítica. Las diferencias en las puntuaciones entre los modelos principales pueden no ser siempre estadísticamente significativas, y el rendimiento puede variar considerablemente según la tarea y el conjunto de datos específicos.
Como proyecto de código abierto, MTEB da la bienvenida a contribuciones de la comunidad, lo que le permite crecer y adaptarse a las necesidades cambiantes del campo. Este enfoque colaborativo garantiza que MTEB siga siendo un recurso relevante y valioso para evaluar y mejorar la tecnología de incrustación de texto.
Al proporcionar una forma estandarizada de evaluar modelos de incrustación de texto en una amplia variedad de tareas e idiomas, MTEB está ayudando a impulsar el progreso en el campo, lo que en última instancia conduce a modelos de incrustación de texto mejores y más versátiles para diversas aplicaciones.
Referencias
Muennighoff, Niklas and Tazi, Nouamane and Magne, Lo{\"\i}c and Reimers, Nils. "MTEB: Massive Text Embedding Benchmark" arXiv 2022
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff. "C-Pack: Packaged Resources To Advance General Chinese Embedding" arXiv 2023
Michael Günther, Jackmin Ong, Isabelle Mohr, Alaeddine Abdessalem, Tanguy Abel, Mohammad Kalim Akram, Susana Guzman, Georgios Mastrapas, Saba Sturua, Bo Wang, Maximilian Werk, Nan Wang, Han Xiao. "Jina Embeddings 2: 8192-Token General-Purpose Text Embeddings for Long Documents" arXiv 2023
Silvan Wehrli, Bert Arnrich, Christopher Irrgang. "Benchmark de agrupamiento de incrustaciones de texto en alemán" arXiv 2024
Orion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Benjamin Van Durme, Dawn Lawrie, Luca Soldaini. "FollowIR: Evaluación y enseñanza de modelos de recuperación de información para seguir instrucciones" arXiv 2024
Dawei Zhu, Liang Wang, Nan Yang, Yifan Song, Wenhao Wu, Furu Wei, Sujian Li. "LongEmbed: Extensión de modelos de incrustaciones para la recuperación en contextos largos" arXiv 2024
Kenneth Enevoldsen, Márton Kardos, Niklas Muennighoff, Kristoffer Laigaard Nielbo. "Los benchmarks escandinavos de incrustaciones: evaluación integral de incrustaciones de texto multilingües y monolingües" arXiv 2024
- Antecedentes y Motivación
- Embeddings de Texto
- Diseño e implementación del Massive Text Embedding Benchmark
- Cuándo usar Massive Text Embedding Benchmark
- Cómo usar la clasificación de Massive Text Embedding Benchmark
- El recurso Zilliz AI Model
- Conclusión
- Referencias
Contenido
Comienza Gratis, Escala Fácilmente
Prueba la base de datos vectorial completamente gestionada construida para tus aplicaciones GenAI.
Prueba Zilliz Cloud Gratis