




Captura de datos modificados: mantener tus sistemas sincronizados en tiempo real

Captura de datos modificados: mantener tus sistemas sincronizados en tiempo real
¿Qué es la captura de datos modificados (CDC)?
La captura de datos modificados (CDC) es un método utilizado para identificar y rastrear cambios en los datos a medida que ocurren dentro de una base de datos. En lugar de monitorear manualmente o consultar repetidamente en busca de actualizaciones, CDC captura automáticamente inserciones, actualizaciones y eliminaciones en tiempo real o casi en tiempo real. Las técnicas de CDC, como los registros de transacciones y los disparadores de bases de datos, facilitan que las organizaciones mantengan la consistencia e integridad de los datos en diversos sistemas y entornos de implementación. Esto garantiza que los sistemas y aplicaciones posteriores—ya sea que impulsen análisis tradicionales o modelos de IA basados en vectores—siempre tengan los datos más recientes.
Por ejemplo, en una base de datos vectorial, CDC rastrea las actualizaciones en tiempo real de embeddings para tareas como la búsqueda semántica o la detección de fraude, donde se requieren los datos más recientes para obtener resultados precisos.
Evolución de la integración de datos: el papel de CDC
En el pasado, el procesamiento por lotes era el enfoque principal para la integración de datos. Sin embargo, provocaba retrasos, ya que las actualizaciones de datos se procesaban en masa en intervalos programados, a menudo horas o días después de que ocurrieran los cambios. Esta limitación lo hacía inadecuado para aplicaciones como la búsqueda semántica en tiempo real para chatbots impulsados por IA o sistemas de recomendación, que dependen de bases de datos vectoriales para analizar datos de alta dimensionalidad.
CDC resuelve este problema capturando los cambios a medida que ocurren y actualizando los sistemas en tiempo real. Esta técnica permite a las empresas sincronizar sus bases de datos, impulsar paneles de control en tiempo real y crear aplicaciones receptivas. El auge de CDC coincidió con el crecimiento de los sistemas distribuidos modernos y las arquitecturas nativas de la nube, donde la replicación e integración oportunas de datos son críticas. En lugar de trabajar con datos obsoletos de actualizaciones periódicas, las organizaciones ahora pueden capturar y actuar sobre los cambios a medida que ocurren. Este cambio ha convertido a CDC en un componente vital de las estrategias de datos modernas al ayudar a las empresas a mantenerse receptivas y competitivas en tiempo real.
¿Cómo funciona la captura de datos modificados?
Imagina rastrear las interacciones de un cliente en una plataforma de comercio electrónico. Cada interacción, como navegar, añadir al carrito o comprar, genera nuevos datos. CDC transmite estos datos modificados a una base de datos vectorial como Milvus en tiempo real, donde sus representaciones vectoriales, también conocidas como embeddings vectoriales, pueden actualizarse para tareas como recomendaciones personalizadas o prevención de fraude.
Desglosemos esto en componentes y mecanismos clave para entender cómo funciona CDC.
Componentes clave de CDC
Para que CDC sea funcional, varios componentes trabajan juntos. El diagrama siguiente ilustra el proceso de CDC.
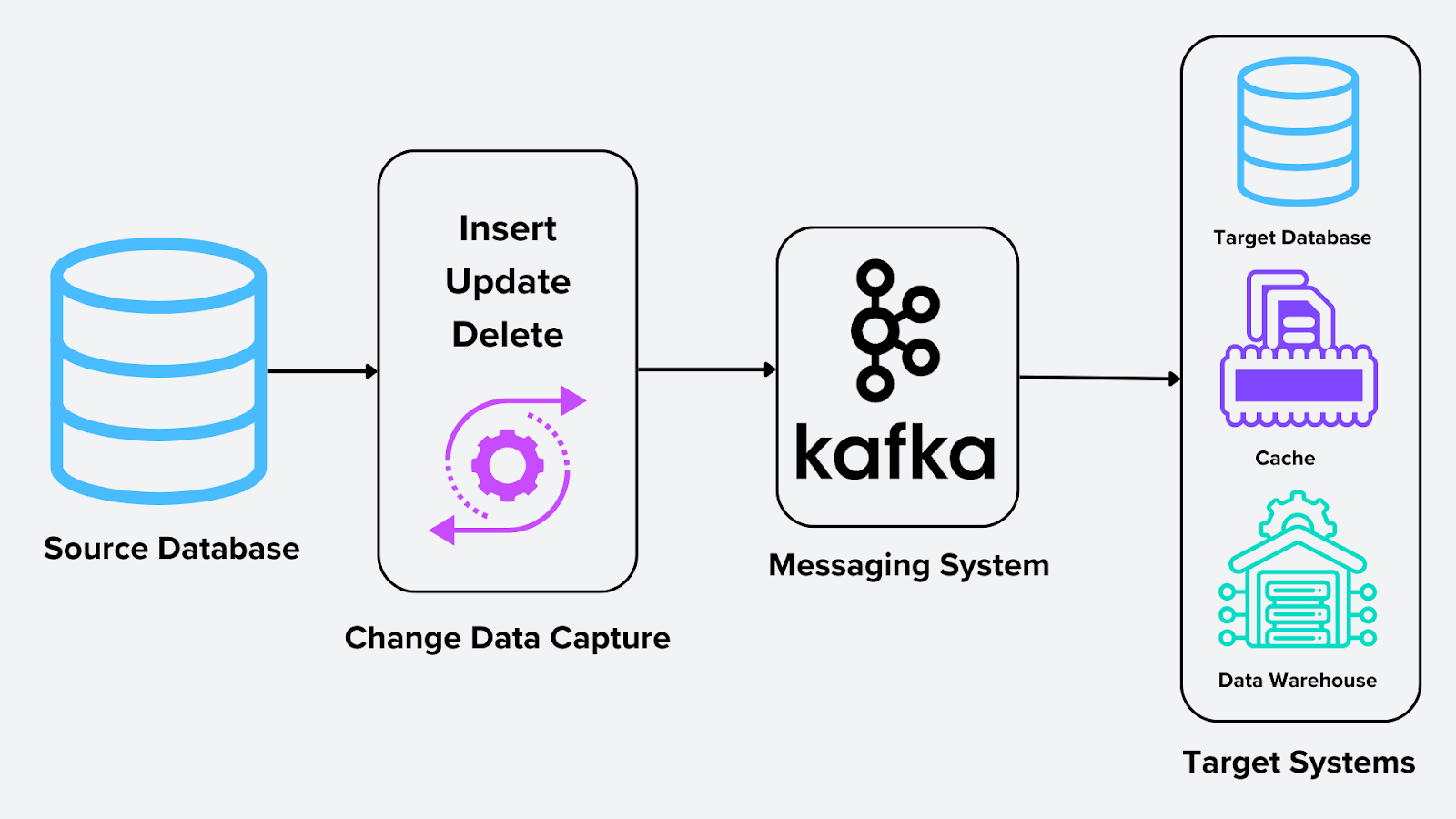 Figura- Proceso de captura de datos modificados .png
Figura- Proceso de captura de datos modificados .png
Figura: Proceso de captura de datos modificados
Origen: El sistema donde se originan los cambios, que podrían ser bases de datos relacionales, sistemas NoSQL o bases de datos vectoriales. En el caso de una base de datos vectorial como Milvus, el origen podrían ser embeddings generados a partir de modelos de aprendizaje profundo o modelos de reconocimiento de imágenes.
Motor CDC: El proceso central que captura y da formato a los cambios. Para bases de datos vectoriales, esto podría significar actualizar embeddings almacenados en Milvus usando herramientas como Milvus-CDC o Confluent Kafka Connect.
Sistema de mensajería: Un sistema de mensajería como Apache Kafka sirve como la columna vertebral para distribuir cambios en tiempo real. Actúa como un intermediario que almacena y transmite los cambios capturados a uno o varios sistemas de destino. Esto garantiza la escalabilidad y la fiabilidad en la canalización de datos.
Sistemas de destino: Los destinos a los que se envían los cambios de datos procesados. Algunos ejemplos incluyen:
Almacenes de datos (p. ej., Snowflake, BigQuery) para análisis.
Cachés para respuestas de consulta más rápidas.
Bases de datos para replicación y sincronización entre sistemas.
Descripción general de los mecanismos de CDC
Hay tres formas principales en que CDC puede capturar cambios de una base de datos. En los ejemplos a continuación, usaremos bases de datos SQL para demostrarlo.
1. CDC basada en registros
Este método se basa en el registro de transacciones de la base de datos, una función a nivel de sistema que registra todos los cambios de la base de datos (inserciones, actualizaciones y eliminaciones). El motor de CDC lee estos registros y extrae los cambios relevantes para su uso posterior. En bases de datos vectoriales, esto podría significar capturar actualizaciones de vectores de incrustación a medida que se insertan o modifican en Milvus.
Cómo funciona:
El registro de transacciones es la única fuente de verdad para todas las operaciones de la base de datos.
La herramienta de CDC supervisa el registro e identifica y captura cambios continuamente sin afectar la base de datos principal.
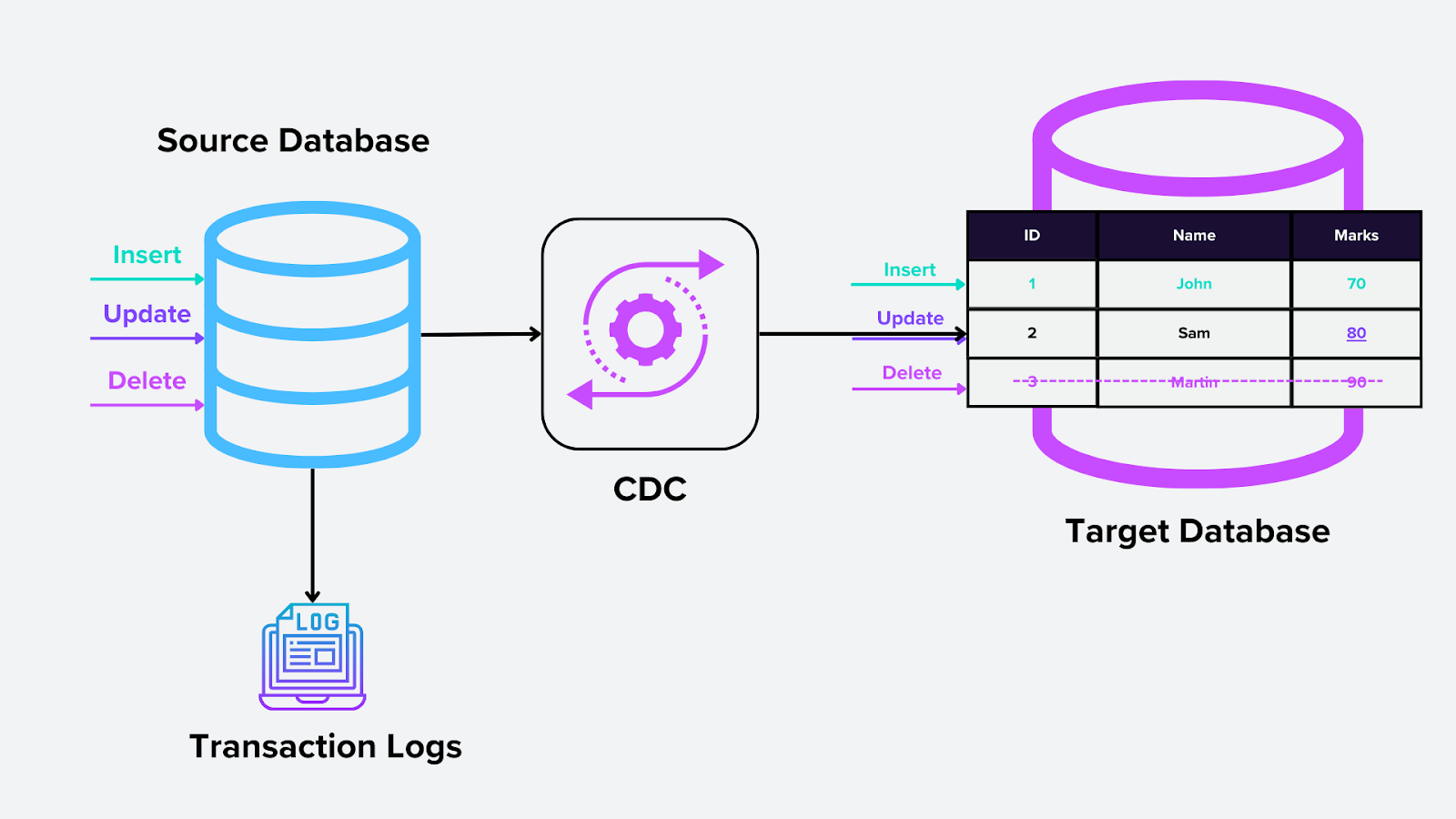 Figura- CDC basada en registros.png
Figura- CDC basada en registros.png
Figura: CDC basada en registros
Ventajas:
Alto rendimiento: Impacto mínimo en la base de datos, ya que lee directamente de los registros.
Integral: Captura todos los cambios, incluidos desencadenadores, procedimientos almacenados u otros métodos indirectos.
Escalable: Funciona bien con sistemas de alta transaccionalidad.
Desventajas:
Complejidad: Requiere una integración profunda con la estructura interna de registros de la base de datos, que puede variar según el tipo de base de datos.
Compatibilidad: No todas las bases de datos exponen registros de transacciones para acceso externo.
2. CDC basada en desencadenadores
Este enfoque utiliza desencadenadores de base de datos, que son lógica personalizada que se ejecuta automáticamente cuando ocurre un cambio específico (p. ej., insertar, actualizar o eliminar) en una tabla. Por ejemplo, los desencadenadores podrían actualizar automáticamente un índice vectorial de Milvus cuando se agregan nuevas incrustaciones.
Cómo funciona:
Se agregan desencadenadores a las tablas de interés en la base de datos.
Cuando ocurren cambios, el desencadenador los captura y envía la información a una ubicación o tabla especificada para su procesamiento posterior.
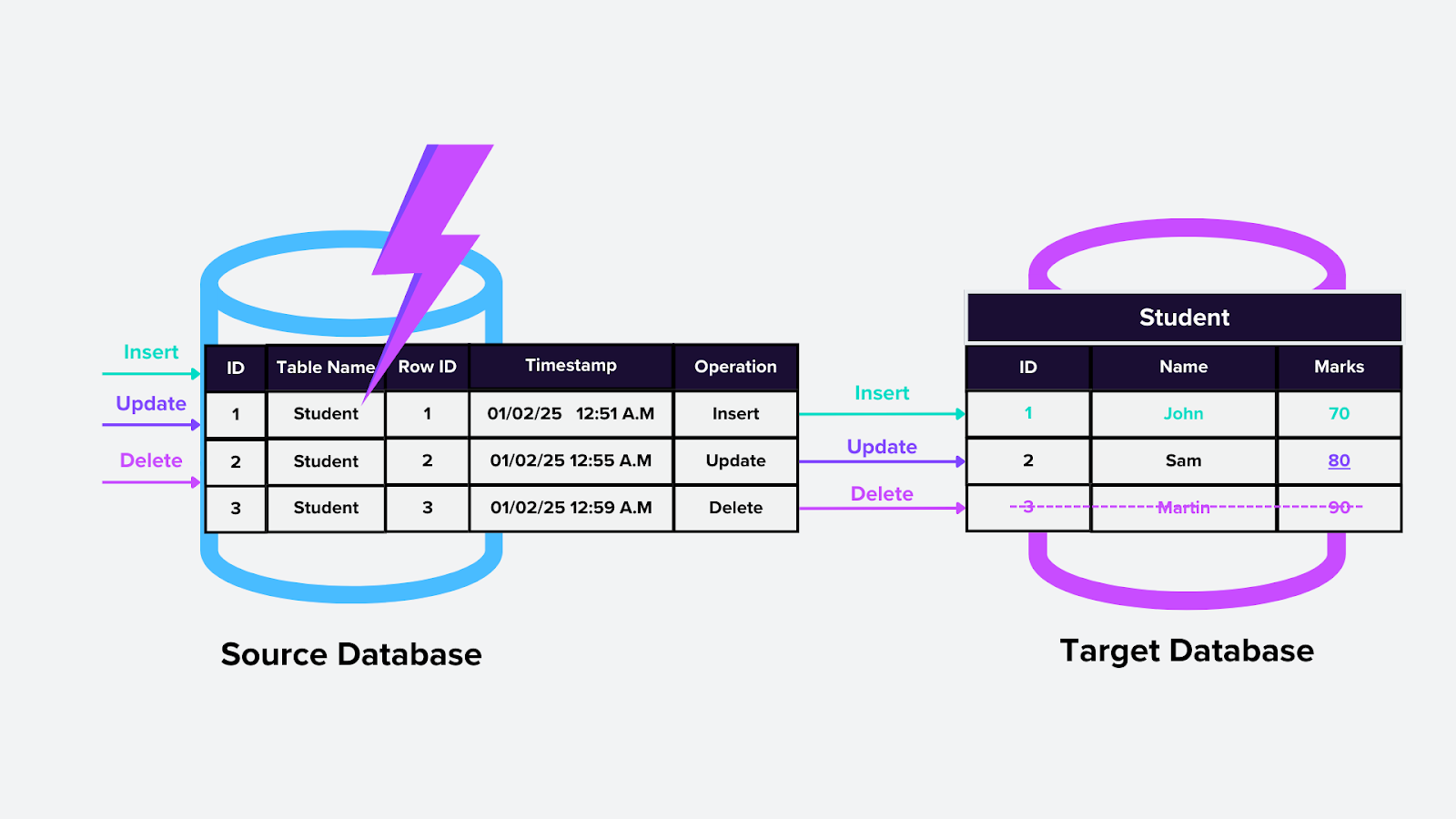 Figura- CDC basada en desencadenadores.png
Figura- CDC basada en desencadenadores.png
Figura: CDC basada en desencadenadores
Ventajas:
Flexible: Puede personalizarse para rastrear cambios para casos de uso específicos.
Ampliamente compatible: Casi todas las bases de datos relacionales admiten desencadenadores.
Desventajas:
Impacto en el rendimiento: Los desencadenadores añaden sobrecarga a la base de datos, especialmente para transacciones de alta frecuencia.
Desafíos de mantenimiento: Gestionar y actualizar desencadenadores en varias tablas puede volverse difícil.
Propenso a errores: Los desencadenadores mal escritos pueden causar cuellos de botella de rendimiento o no capturar casos límite.
3. CDC basada en consultas
Este método implica ejecutar consultas periódicas contra la base de datos para detectar cambios. Las consultas suelen comparar marcas de tiempo o versiones para identificar registros modificados recientemente, como sondear una base de datos vectorial en busca de incrustaciones actualizadas.
Cómo funciona:
El motor de CDC ejecuta consultas a intervalos programados e identifica cambios en función de criterios específicos (p. ej., fecha de última modificación).
Los cambios detectados se envían posteriormente.
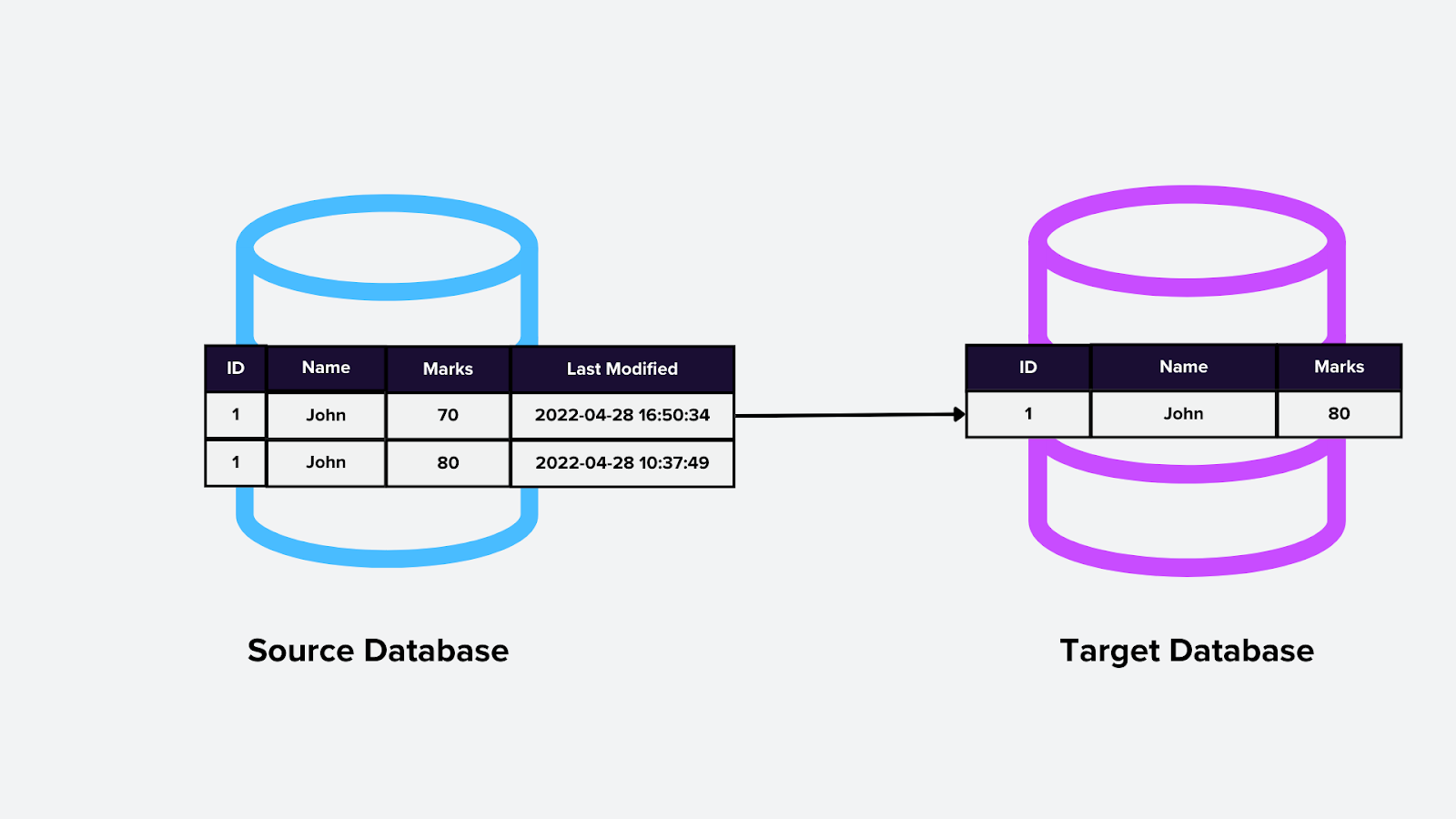 Figura- CDC basada en consultas.png
Figura- CDC basada en consultas.png
Figura: CDC basada en consultas
Ventajas:
Configuración sencilla: No requiere integración profunda ni modificación de la base de datos.
Independiente de la base de datos: Funciona con casi cualquier base de datos que admita consultas.
Desventajas:
Latencia: No es en tiempo real, ya que depende del calendario de consultas.
Sobrecarga de rendimiento: Las consultas frecuentes pueden sobrecargar la base de datos.
Precisión limitada: Puede omitir cambios si las modificaciones de datos ocurren entre intervalos de consulta.
Comparación de mecanismos de CDC
La tabla siguiente proporciona información rápida sobre diferentes mecanismos de CDC y sus casos de uso:
| Mecanismo | Tiempo real | Impacto en el rendimiento | Facilidad de configuración | Idoneidad del caso de uso |
| Basado en logs | Sí | Bajo | Media | Sistemas transaccionales de alto volumen |
| Basado en triggers | Sí | Medio-alto | Baja-media | Casos de uso que requieren lógica de cambios personalizada |
| Basado en consultas | No | Alto | Alta | Configuraciones simples con cambios de baja frecuencia |
Tabla: Comparación de mecanismos de CDC
CDC con Milvus: Integración de datos en tiempo real para bases de datos vectoriales
Milvus, una base de datos vectorial de código abierto (desarrollada por ingenieros de Zilliz) creada para gestionar datos no estructurados como embeddings vectoriales de modelos de aprendizaje automático, cuenta con su propia herramienta de CDC, Milvus-CDC, que está diseñada explícitamente para gestionar tareas de replicación y sincronización de datos dentro de instancias de Milvus. Milvus-CDC captura cambios incrementales de datos para una sincronización fluida entre instancias de Milvus de origen y destino. Esto admite tareas como copia de seguridad incremental, recuperación ante desastres y replicación persistente de datos, manteniendo al mismo tiempo la integridad y la coherencia de los datos. Milvus-CDC incluye dos componentes principales: el HTTP Server, que gestiona las solicitudes de los usuarios, ejecuta tareas y mantiene los metadatos de las tareas, y Corelib, que gestiona la sincronización de tareas, con un lector que extrae datos de la instancia de Milvus de origen y la cola de mensajes, y un escritor que procesa estos cambios y los envía a la instancia de Milvus de destino.
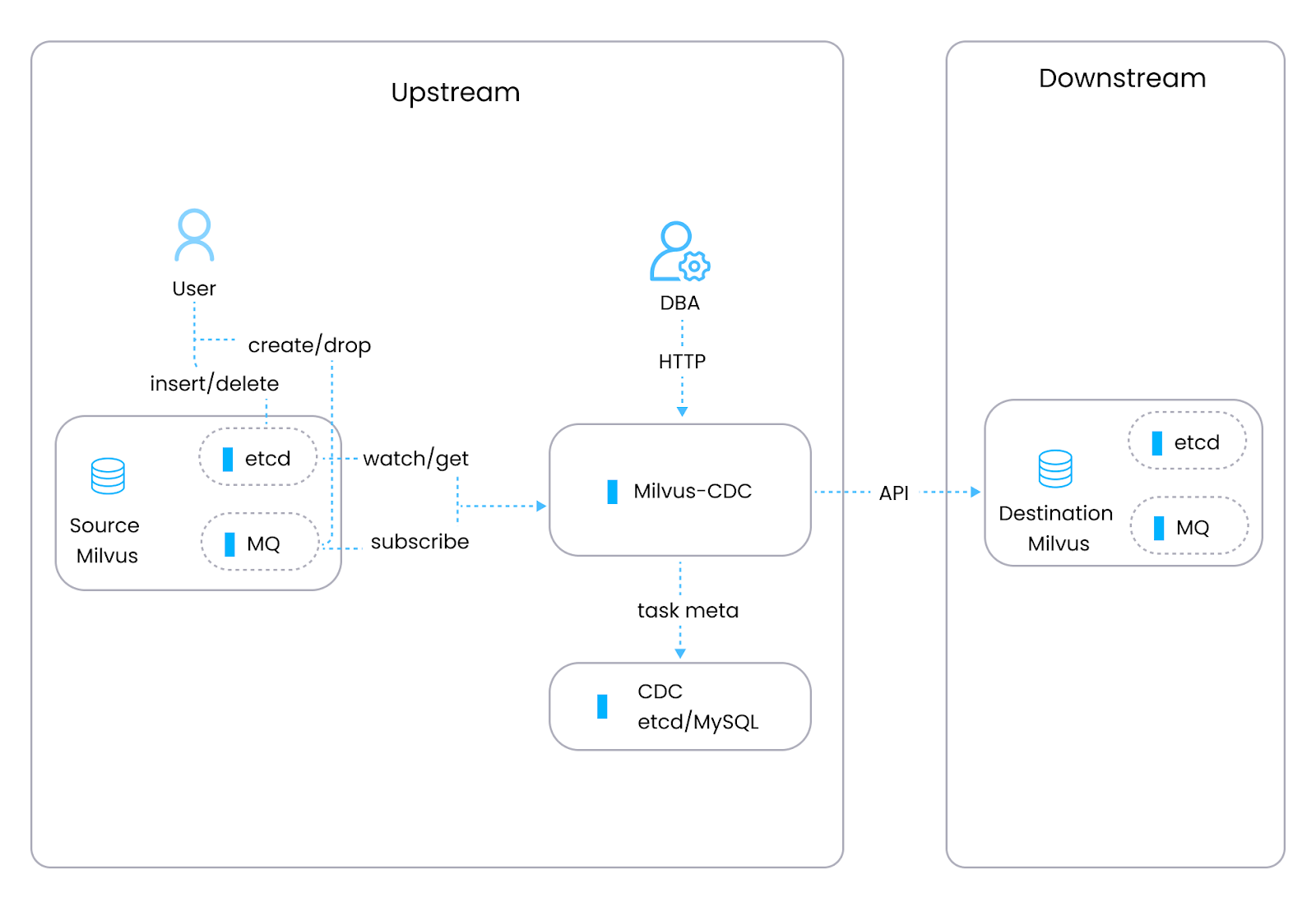 Figura- La arquitectura de Milvus-CDC.png
Figura- La arquitectura de Milvus-CDC.png
Figura: La arquitectura de Milvus-CDC
Milvus-CDC: Características clave
Sincronización secuencial de datos: Garantiza que los cambios se apliquen para preservar la coherencia de los datos entre instancias de Milvus.
Replicación incremental de datos: Captura y replica cambios, como inserciones y eliminaciones, desde el Milvus de origen hasta la instancia de destino.
Gestión de tareas: Los usuarios pueden crear, gestionar y eliminar tareas de CDC usando OpenAPI para integrarse con diversos flujos de trabajo.
Integración con sistemas futuros: Existen planes para ampliar el soporte de integración con sistemas de procesamiento de flujos.
CDC en Milvus usando Kafka
Aunque Milvus-CDC está adaptado explícitamente para Milvus, integrar Milvus con Apache Kafka ofrece otro enfoque para CDC. Kafka es un centro central que captura y propaga cambios de datos desde diversas fuentes usando herramientas de CDC como Kafka Sink connector. Estos cambios se ingieren luego en Milvus para mantener la base de datos vectorial actualizada con los embeddings o vectores de características más recientes.
Para conectar Kafka con Milvus, puedes seguir esta guía: Conectar Kafka con Milvus.
Papel de CDC en bases de datos distribuidas y aplicaciones nativas de la nube
A medida que las organizaciones adoptan bases de datos distribuidas y aplicaciones nativas de la nube para gestionar cargas de trabajo a gran escala y distribuidas geográficamente, CDC desempeña un papel fundamental en la sincronización fluida de datos en estos sistemas complejos.
Sincronización de datos entre sistemas distribuidos: En las bases de datos distribuidas, los datos suelen estar repartidos entre varios nodos o regiones para mejorar el rendimiento y la escalabilidad. CDC propaga de inmediato a otros nodos los cambios realizados en un nodo para mantener la coherencia en todo el sistema.
Intercambio de datos en tiempo real en arquitecturas nativas de la nube: Las aplicaciones nativas de la nube suelen depender de microservicios, cada uno con su propio almacenamiento de datos. CDC permite que estos servicios compartan actualizaciones en tiempo real sin depender de procesos por lotes pesados para admitir arquitecturas basadas en eventos.
Replicación para alta disponibilidad y recuperación ante desastres: Los sistemas distribuidos suelen utilizar la replicación de datos para lograr alta disponibilidad. CDC captura y replica los cambios en nodos de respaldo o sistemas de conmutación por error.
Optimización de canalizaciones de datos: En entornos donde varios sistemas dependen de conjuntos de datos compartidos, CDC proporciona un mecanismo para alimentar cambios en tiempo real en plataformas de análisis, data lakes o colas de mensajes.
Aplicaciones de CDC en bases de datos vectoriales
Estos son casos de uso específicos de CDC, especialmente en aplicaciones de IA que trabajan con una base de datos vectorial:
Búsqueda semántica: CDC actualiza la base de datos vectorial con los embeddings más recientes, lo que permite que los sistemas de búsqueda semántica proporcionen resultados precisos y relevantes. Por ejemplo, un motor de búsqueda empresarial puede ofrecer respuestas precisas basadas en actualizaciones en tiempo real de embeddings de documentos o consultas.
Sistemas de recomendación: Las bases de datos vectoriales utilizan embeddings para generar recomendaciones personalizadas. CDC transmite cambios en tiempo real, como nuevos comportamientos de usuarios o actualizaciones de productos, para que los sistemas de recomendación se adapten rápidamente a los datos en evolución.
Detección de fraude: En los sistemas financieros, los embeddings de datos transaccionales se actualizan continuamente en una base de datos vectorial. CDC garantiza que estas actualizaciones se transmitan en tiempo real para detectar al instante actividad inusual y marcar posibles fraudes.
Reconocimiento de imágenes y videos: Para aplicaciones como etiquetar o encontrar contenido visualmente similar, CDC mantiene actualizados en la base de datos los embeddings vectoriales generados a partir de imágenes o videos. Esto permite resultados precisos y rápidos para casos de uso en tiempo real, como la moderación en redes sociales o la búsqueda visual en comercio electrónico.
Chatbots y asistentes virtuales: CDC ayuda a los chatbots LLM basados en RAG a proporcionar respuestas precisas en tiempo real. Por ejemplo, los embeddings que representan interacciones de usuarios en vivo o bases de conocimiento actualizadas se capturan y actualizan al instante, lo que mejora el rendimiento del chatbot.
Detección de anomalías: La CDC es útil en ciberseguridad, donde los patrones inusuales en el tráfico de red o los registros del sistema requieren atención inmediata.
Beneficios de CDC
CDC ofrece ventajas significativas para que las arquitecturas de datos modernas funcionen de manera eficiente y tomen decisiones informadas. Estos son los beneficios clave:
Información en tiempo real: CDC proporciona los datos más recientes para apoyar la toma rápida de decisiones. Por lo tanto, las empresas pueden supervisar el rendimiento y las tendencias al instante.
Reducción de la latencia de datos: Elimina los retrasos causados por el procesamiento por lotes tradicional. Como los cambios se reflejan en todos los sistemas casi de inmediato, mejoran la capacidad de respuesta en aplicaciones que dependen de datos sincronizados.
Escalabilidad en sistemas grandes: Gestiona altos volúmenes de cambios de datos, lo que lo hace adecuado para bases de datos a gran escala y entornos distribuidos.
Replicación y migración de datos sin interrupciones: Esta función facilita la replicación de datos en tiempo real entre sistemas para alta disponibilidad, recuperación ante desastres y equilibrio de carga. También simplifica las migraciones de bases de datos mediante el uso de datos sincronizados durante las transiciones con un tiempo de inactividad mínimo.
Soporte para arquitecturas orientadas a eventos: Impulsa aplicaciones orientadas a eventos al activar flujos de trabajo o procesos posteriores basados en cambios de datos. Por lo tanto, mejora la automatización y la capacidad de respuesta en las operaciones empresariales.
Precisión y consistencia de los datos: Todos los sistemas conectados tienen datos consistentes y precisos, lo que reduce errores e inconsistencias. Por lo tanto, proporciona una base fiable para crear soluciones sólidas basadas en datos.
Desafíos de implementar CDC
Implementar CDC puede ser complejo, y las organizaciones deben abordar varios desafíos para lograr operaciones eficientes y fiables. Los principales obstáculos incluyen:
Sobrecargas de rendimiento: Capturar y procesar cambios en tiempo real puede generar una carga adicional en la base de datos que afecta al rendimiento de las aplicaciones principales. Además, los métodos que consumen muchos recursos, como los disparadores o las consultas frecuentes, pueden degradar los tiempos de respuesta de la base de datos. Equilibrar la velocidad con la precisión y la fiabilidad exige un diseño optimizado del pipeline.
Gestión de cambios de esquema: Los cambios en el esquema de la base de datos, como añadir columnas, modificar tipos de datos o alterar estructuras de tablas, pueden interrumpir los pipelines de CDC.
Consideraciones de red y almacenamiento: La transmisión continua de datos en CDC requiere suficiente capacidad de almacenamiento y técnicas de compresión eficientes para evitar costes en espiral. Los aumentos en el tráfico de red pueden sobrecargar el ancho de banda, especialmente en sistemas distribuidos geográficamente.
Integridad de los datos en el pipeline de CDC: Los fallos o inconsistencias en el pipeline pueden comprometer la precisión de los sistemas posteriores. Gestionar eventos fuera de orden y resolver conflictos en entornos distribuidos puede añadir complejidad.
Compatibilidad de herramientas y dependencia del proveedor: Algunas soluciones de CDC están vinculadas a bases de datos o tecnologías específicas, lo que limita la flexibilidad en entornos heterogéneos. Cambiar de herramientas o actualizar sistemas puede requerir rediseñar los procesos de CDC.
Riesgos de seguridad y cumplimiento: Transmitir datos sensibles en tiempo real requiere cifrado robusto y controles de acceso para evitar accesos no autorizados. El cumplimiento de normativas de protección de datos como GDPR o CCPA puede complicar la implementación de CDC.
Herramientas y frameworks para CDC
Existen varias herramientas y frameworks disponibles para implementar CDC, cada uno con características únicas adaptadas a casos de uso específicos. Aquí tienes una lista de opciones populares:
Debezium**: Una plataforma CDC de código abierto construida sobre Apache Kafka, Debezium admite varias bases de datos, como MySQL, PostgreSQL, MongoDB y SQL Server. Es ideal para la transmisión de datos en tiempo real y la integración con arquitecturas orientadas a eventos.
Oracle GoldenGate: Una solución CDC robusta y de nivel empresarial de Oracle, GoldenGate admite la replicación de datos de alto rendimiento y la integración en tiempo real entre bases de datos heterogéneas. Se utiliza ampliamente para recuperación ante desastres y migración.
AWS Database Migration Service (DMS): ****Un servicio totalmente gestionado de Amazon que admite CDC para varias bases de datos, tanto locales como en la nube. Simplifica la migración y replicación de datos sin requerir una sobrecarga significativa.
Qlik Replicate: Anteriormente conocido como Attunity Replicate, Qlik Replicate admite CDC para una amplia gama de bases de datos y sistemas de archivos. Está diseñado para una replicación de datos rápida y escalable, así como para la integración en plataformas de analítica.
Confluent Kafka Connect: Parte del ecosistema de Confluent, Kafka Connect ofrece capacidades de CDC para transmitir cambios de datos a temas de Kafka. También se integra sin problemas con la plataforma Kafka para el procesamiento de eventos en tiempo real.
Conclusión
CDC desempeña un papel vital en los sistemas de datos modernos mediante actualizaciones en tiempo real e integración entre plataformas. Al abordar las limitaciones del procesamiento por lotes, CDC admite análisis en tiempo real, arquitecturas impulsadas por eventos y sincronización de datos fluida. Herramientas como Apache Kafka mejoran aún más CDC al optimizar los cambios en sistemas posteriores, incluidas bases de datos vectoriales como Milvus. Esto ayuda a las empresas a gestionar datos no estructurados, escalar operaciones y crear aplicaciones receptivas.
Recursos relacionados
- ¿Qué es la captura de datos modificados (CDC)?
- Evolución de la integración de datos: el papel de CDC
- ¿Cómo funciona la captura de datos modificados?
- CDC con Milvus: Integración de datos en tiempo real para bases de datos vectoriales
- Papel de CDC en bases de datos distribuidas y aplicaciones nativas de la nube
- Aplicaciones de CDC en bases de datos vectoriales
- Beneficios de CDC
- Desafíos de implementar CDC
- Herramientas y frameworks para CDC
- Conclusión
- Recursos relacionados
Contenido
Comienza Gratis, Escala Fácilmente
Prueba la base de datos vectorial completamente gestionada construida para tus aplicaciones GenAI.
Prueba Zilliz Cloud Gratis