




Evaluación RAG mediante Ragas
*Este artículo ha sido escrito por Christy Bergman, Shahul Es y Jithin James.
La recuperación es un componente crucial de los sistemas de IA generativa, y sus retos son especialmente evidentes en Retrieval Augmented Generation (RAG). La Generación Aumentada de Recuperación mejora los chatbots con IA generando respuestas basadas en una gran cantidad de datos con los que se han entrenado grandes modelos lingüísticos ([LLM](https://zilliz.com/glossary/large-language-models-(llms)). A pesar de la sofisticación de los sistemas RAG, la precisión de la recuperación sigue siendo un obstáculo importante, como ponen de manifiesto las bajas puntuaciones obtenidas en pruebas de referencia como WikiEval. Para superar estos retos, es esencial establecer un marco de evaluación exhaustivo y realizar experimentos minuciosos para ajustar los parámetros de la GAR y lograr un rendimiento óptimo.
**Sin embargo, antes de experimentar con la GAR, es necesario evaluar qué experimentos han dado los mejores resultados.
Fuente de la imagen: https://arxiv.org/abs/2309.15217
¿Qué son las Ragas?
Ragas es un marco de evaluación especializado diseñado para evaluar el rendimiento de los sistemas Retrieval Augmented Generation (RAG). Proporciona un enfoque estructurado para evaluar la eficacia de las implementaciones RAG mediante el aprovechamiento de modelos avanzados de grandes lenguajes (LLM) como jueces. Ragas se centra en la automatización del proceso de evaluación, ofreciendo soluciones escalables y rentables para evaluar las respuestas generadas por IA. El marco pretende abordar los sesgos y ofrecer puntuaciones continuas y explicables para los resultados del lenguaje natural. Ragas simplifica la evaluación de sistemas GAR complejos proporcionando métricas intuitivas y agilizando el proceso de evaluación de la calidad de la recuperación.
Importancia de evaluar los sistemas GAR
Evaluar eficazmente los sistemas GAR es vital para perfeccionar las respuestas de la IA. Un marco de evaluación sólido garantiza que los experimentos produzcan resultados fiables y que la IA ofrezca respuestas precisas y adecuadas al contexto. La automatización del proceso de evaluación puede agilizar y acelerar esta tarea, haciéndola más rentable y escalable.
Aprovechamiento de los LLM como jueces
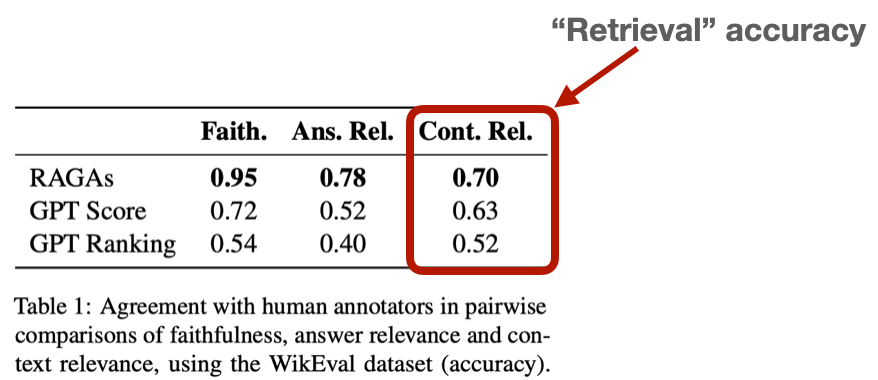
El uso de grandes modelos lingüísticos (LLM) como GPT-4 para la evaluación ha ganado adeptos debido a su capacidad para evaluar diversos aspectos de la calidad de la recuperación, como la relevancia y la precisión. Aunque pueda parecer inusual que un LLM evalúe a otro, la investigación indica que GPT-4 coincide con las evaluaciones humanas en un 80% de las ocasiones, lo que coincide con el "límite bayesiano " de la concordancia humana. Este método automatiza el proceso de evaluación, ofreciendo escalabilidad y reduciendo costes en comparación con el etiquetado humano manual.
Enfoques de la evaluación basada en LLM
Existen dos enfoques principales para utilizar los LLM como jueces para la evaluación GAR:
- MT-Bench utiliza un LLM para juzgar sólo los pares pregunta-respuesta verificados por humanos. Los humanos examinan inicialmente las preguntas y respuestas para asegurarse de que las preguntas son lo suficientemente complejas como para realizar pruebas dignas antes de que el LLM utilice los 80 pares pregunta-respuesta para evaluar diferentes decodificadores (componentes generativos de IA). Paper, Code, Leaderboard.
Ragas se basa en la idea de que los LLM pueden evaluar eficazmente la salida del lenguaje natural formando paradigmas que superan los sesgos de usar LLM como jueces directamente y proporcionando puntuaciones continuas que son explicables e intuitivas de entender). Paper, Code, Docs.
El resto de este blog mostrará Ragas, que hace hincapié en la automatización y la escalabilidad para las evaluaciones RAG.
Datos de evaluación necesarios para Ragas
Según la documentación de Ragas, su evaluación de tuberías RAG necesitará cuatro puntos de datos clave.
Pregunta: La pregunta formulada.
Contextos: Los fragmentos de texto de los datos que mejor se ajustan al significado de la pregunta.
Respuesta: Respuesta generada por su chatbot RAG a la pregunta.
Respuesta verdadera: Respuesta esperada a la pregunta.
Métrica de Evaluación de Ragas](https://assets.zilliz.com/RAG_Evaluation_Metrics_8f5973cd74.png)
Principales parámetros de evaluación
Puede encontrar explicaciones para cada métrica de evaluación, incluidas sus fórmulas subyacentes, en la documentación. Por ejemplo, fidelidad. Ragas proporciona una serie de puntuaciones de evaluación para calibrar la eficacia de los sistemas RAG:
Fidelidad**: Esta puntuación evalúa la precisión con la que la respuesta generada refleja la información en el contexto proporcionado. Mide la exactitud factual de la respuesta, garantizando que se ajusta al contexto del que se deriva. Las puntuaciones van de 0 a 1, y los valores más altos indican mayor precisión y coherencia.
Relevancia de la respuesta**: Esta métrica de relevancia de la respuesta evalúa en qué medida la respuesta generada responde a la pregunta. Se centra en la integridad y relevancia de la respuesta, penalizando las respuestas incompletas o redundantes. La puntuación de relevancia se obtiene a partir de la pregunta, el contexto y la respuesta, y las puntuaciones más altas reflejan una mejor alineación con la pregunta.
Recuperación del contexto: La recuperación del contexto mide la eficacia con la que el contexto recuperado coincide con la respuesta real. Calcula la proporción de piezas relevantes que se recuperaron con éxito en comparación con lo que se esperaba. Las puntuaciones van de 0 a 1, y los valores más altos indican que se recuperó una mayor parte del contexto relevante.
Precisión del contexto**: Esta métrica evalúa si los elementos de contexto más relevantes se clasifican mejor que los menos relevantes. Comprueba si todos los fragmentos de contexto pertinentes aparecen al principio de la lista. La precisión del contexto se determina utilizando la pregunta, la verdad básica y los contextos, y las puntuaciones más altas indican una mejor clasificación de la información relevante.
Relevancia del contexto**: Esta puntuación de relevancia del contexto evalúa la relevancia del contexto recuperado para la pregunta. Mide el grado en que el contexto coincide con la intención de la consulta. La métrica oscila entre 0 y 1, y los valores más altos indican que el contexto es más pertinente para la pregunta.
Recuperación de entidades de contexto: Esta métrica calcula en qué medida el contexto recuperado captura las entidades mencionadas en la verdad sobre el terreno. Mide la proporción de entidades encontradas tanto en el contexto como en la verdad sobre el terreno en relación con el número total de entidades en la verdad sobre el terreno. Las puntuaciones más altas indican una mejor captura de las entidades importantes en el contexto.
Los detalles sobre cómo se calculan estas métricas pueden consultarse en su paper.
Ejemplo de código de evaluación RAG
Este código de evaluación asume que ya tienes una demo RAG. Para mi demo, he creado un chatbot RAG utilizando Milvus Technical documentation y Milvus base de datos vectorial para la recuperación. El código completo de mi demo RAG notebook y Eval notebooks están en GitHub.
Usando esa demo RAG, le hice preguntas, obtuve los contextos RAG de Milvus, y generé respuestas bot de un LLM (ver las 2 últimas columnas más abajo). Además, proporciono respuestas "reales" a las mismas preguntas (columna "contextos" más abajo).
Debes instalar OpenAI, (HuggingFace) dataset, ragas, langchain, y pandas.
# pip install openai dataset ragas langchain pandas
importar pandas como pd
eval_df = pd.read_csv("data/milvus_ground_truth.csv")
display(eval_df.head())

Convierte el marco de datos pandas en un conjunto de datos HuggingFace.
from datasets import Dataset
def assemble_ragas_dataset(input_df):
lista_preguntas, lista_verdad, lista_contexto = [], [], []
lista_preguntas = entrada_df.pregunta.a_lista()
truth_list = eval_df.ground_truth_answer.to_list()
context_list = input_df.Custom_RAG_context.to_list()
context_list = [[context] para context en context_list]
rag_answer_list = input_df.Custom_RAG_answer.to_list()
# Cree un conjunto de datos HuggingFace a partir de las listas ground truth.
ragas_ds = Dataset.from_dict({"pregunta": lista_preguntas,
"contextos": lista_contextos,
"answer": rag_answer_list,
"verdad_fundamental": lista_verdad
})
return ragas_ds
# Crear un conjunto de datos de Ragas HuggingFace a partir del df de pandas.
ragas_input_ds = assemble_ragas_dataset(eval_df)
display(ragas_input_ds)

El modelo LLM por defecto que utiliza Ragas es gpt-3.5-turbo-16k de OpenAI y el modelo de incrustación por defecto es text-embedding-ada-002. Puedes cambiar ambos modelos por el que desees.
Cambiaré el modelo LLM-as-judge por el modelo gpt-3.5-turbo ya que el último blog de OpenAI anunció que éste es el más barato. También he cambiado el modelo de incrustación a text-embedding-3-small ya que el blog indica que estas nuevas incrustaciones soportan modo de compresión.
En el código que aparece a continuación, sólo utilizo la métrica de evaluación RAG context para centrarme en la medición de la calidad de recuperación de los documentos relevantes.
import os, openai, pprint
from openai import OpenAI
# Guarda la clave api en una variable env.
openai_api_key=os.environ['OPENAI_API_KEY']
# Elige las métricas que quieres ver.
from ragas.metrics import ( context_recall, context_precision, fidelidad, )
metrics = ['context_recall', 'context_precision', 'faithfulness']
# Cambia el llm-como-crítico.
from ragas.llms import llm_factory
LLM_NAME = "gpt-3.5-turbo"
ragas_llm = llm_factory(model=NOMBRE_LLM)
# Cambia también las incrustaciones.
from langchain_openai.embeddings import OpenAIEmbeddings
from ragas.embeddings import LangchainEmbeddingsWrapper
lc_embeddings = OpenAIEmbeddings( model="text-embedding-3-small", dimensions=512 )
ragas_emb = LangchainEmbeddingsWrapper(embeddings=lc_embeddings)
# Cambiar los modelos por defecto utilizados para cada métrica.
for métrica in métricas:
globals()[metric].llm = ragas_llm
globals()[metric].embeddings = ragas_emb
# Evaluar el conjunto de datos.
from ragas import evaluar
ragas_result = evaluate( ragas_input_ds,
métricas=[ precisión_contexto, recuperación_contexto, fidelidad, ],
llm=ragas_llm,
)
# Ver evaluaciones.
ragas_output_df = ragas_result.to_pandas()
ragas_output_df.head()

Puedes ver el código completo de mi demo cuaderno RAG y cuadernos Eval en GitHub.
Conclusión
Este blog ha explorado los retos actuales de la recuperación en la IA Generativa, con un énfasis particular en las técnicas de Generación Aumentada de Recuperación (RAG) para el avance de los sistemas de IA de lenguaje natural. La experimentación eficaz es esencial para optimizar los parámetros de la RAG de modo que se adapten a datos y casos de uso específicos, garantizando el mejor rendimiento. La evaluación de los sistemas RAG puede ahora mejorarse enormemente mediante la automatización utilizando LLMs como evaluadores. Cubrimos las métricas clave de evaluación de la GAR y sus métodos de cálculo, ofreciendo una visión de sus aplicaciones prácticas. Además, se destacó un ejemplo de implementación utilizando la base de datos vectorial Milvus junto con el paquete Ragas, demostrando cómo estas herramientas pueden utilizarse eficazmente para mejorar y ampliar sus marcos de evaluación RAG. Este enfoque no sólo agiliza el proceso de evaluación, sino que también aumenta la eficacia general de la recuperación de contexto en soluciones basadas en IA. Para profundizar en el tema, considere la posibilidad de investigar aplicaciones del mundo real, abordar desafíos, explorar futuras direcciones, adherirse a las mejores prácticas y acceder a recursos adicionales para profundizar en su comprensión de la evaluación de los sistemas GAR y perfeccionar su canalización GAR.

Sigue leyendo

A Few Notes from Databricks Data + AI Summit 2026: Why the Data Layer Matters Again
James Luan shares notes from Databricks Data + AI Summit 2026 on why production AI is pushing the data layer back to the center of infrastructure.

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.