




RAG local con LangGraph y Llama 3.2
Actualizado el 25 de septiembre de 2024 con Llama 3.2
En este post, demostraremos cómo construir agentes que pueden llamar inteligentemente a herramientas para realizar tareas específicas usando LangGraph y Llama 3, mientras que también aprovechan Milvus Lite para un almacenamiento de datos eficiente. Estos agentes reúnen varias capacidades importantes, como la planificación, la memoria y la llamada a herramientas, para mejorar el rendimiento de los sistemas de generación de recuperación aumentada (RAG).
Introducción a LangGraph y Llama 3
LangGraph es una extensión de LangChain, diseñada para construir aplicaciones multi-actor robustas y llenas de estado con grandes modelos de lenguaje (LLMs). Mientras que LangChain ofrece un marco para la integración de LLMs en diversos flujos de trabajo, LangGraph avanza en esto mediante el modelado de tareas como nodos y aristas en una estructura gráfica. Esto permite flujos de control más complejos, permitiendo a los LLM planificar, aprender y adaptarse a la tarea en cuestión. LangGraph proporciona la flexibilidad necesaria para implantar sistemas en los que los agentes utilizan el razonamiento en varios pasos, seleccionando dinámicamente las herramientas adecuadas para cada paso. Además, LangGraph puede utilizarse para construir agentes GAR fiables que sigan un flujo de control definido por el usuario cada vez que se ejecuten, garantizando la coherencia y previsibilidad de sus respuestas.
LangGraph también permite comportamientos más intrincados, similares a los de los agentes, al permitir la incorporación de ciclos en los flujos de trabajo. Estos ciclos permiten a los agentes volver a pasos anteriores si es necesario, lo que posibilita ajustes dinámicos de las acciones que realizan en función de nueva información o reflexiones. El resultado son agentes más inteligentes capaces de refinar su razonamiento con el tiempo, creando sistemas GAR más robustos y adaptables.
Llama 3, un gran modelo lingüístico de código abierto, sirve como motor de razonamiento central de la memoria del agente. Cuando se combina con LangGraph, Llama 3 puede analizar la entrada, decidir qué acciones tomar e invocar las herramientas necesarias. En lugar de limitarse a generar texto, Llama 3 -impulsado por LangGraph- permite a los agentes planificar, ejecutar y reflexionar sobre sus acciones, lo que los hace más inteligentes y capaces.
En este post, mostraremos cómo crear un sistema langgraph agentic rag usando LangGraph con Llama 3 y Milvus Lite. Esta configuración le permite ejecutar todo localmente sin necesidad de servidores externos, por lo que es ideal para los usuarios conscientes de la privacidad y los entornos fuera de línea.
Construyendo una Herramienta-Agente de Llamadas con LangGraph
El flujo de trabajo de LangGraph está construido alrededor del concepto de nodos, donde cada nodo representa una tarea o herramienta específica. Estas tareas pueden incluir llamar a LLMs, recuperar información, o invocar herramientas personalizadas. En un agente de llamada a herramientas, hay dos componentes clave en juego:
Nodo LLM: Este nodo decide qué herramienta utilizar en función de la información introducida por el usuario. Analiza la consulta y muestra el nombre de la herramienta y los argumentos relevantes.
**Este nodo toma el nombre de la herramienta y los argumentos del nodo LLM, invoca la herramienta apropiada y devuelve el resultado al LLM.
Al estructurar las tareas (como la búsqueda en la web) como nodos y aristas, LangGraph permite la creación de flujos de trabajo inteligentes de múltiples pasos en los que los LLM pueden razonar sobre las preguntas de los usuarios acerca de qué acciones realizar, qué herramientas utilizar, qué respuestas dar a las preguntas y cómo refinar sus respuestas. Milvus Lite desempeña aquí un papel clave al proporcionar un almacenamiento y una recuperación eficientes de datos vectorizados a nivel local.
Cómo Milvus Lite mejora los agentes de llamada de herramientas locales
Milvus Lite es una versión ligera y local de Milvus que no requiere Docker o Kubernetes para funcionar. Esto facilita la ejecución de Milvus en su ordenador portátil, cuaderno Jupyter, o incluso en Google Colab. El despliegue local de Milvus Lite le permite almacenar vectores generados a partir de diferentes fuentes web o documentos sin necesidad de depender de [bases de datos] externas (https://zilliz.com/glossary/ai-database). Se integra perfectamente con LangGraph para gestionar las búsquedas de vectores, lo que lo convierte en una solución ideal para los sistemas locales de GAR.
Por ejemplo, Milvus Lite puede utilizarse para almacenar documentos indexados que son recuperados por el agente durante una búsqueda en la web. Cuando el agente busca información, la base de datos vectorial permite una recuperación rápida y precisa de los documentos relevantes.
Creación de un sistema RAG local con LangGraph y Llama 3
Utilizamos LangGraph para crear un agente RAG local personalizado basado en Llama 3.2 que utiliza diferentes enfoques:
Implementamos cada enfoque como un flujo de control en LangGraph:
Enrutamiento (RAG Adaptativo)** - Permite al agente enrutar de forma inteligente las consultas de los usuarios al método de recuperación más adecuado en función de la propia pregunta. El nodo LLM analiza la consulta y, basándose en las palabras clave o en la estructura de la pregunta, puede dirigirla a nodos de recuperación específicos.
Ejemplo 1 Las preguntas que requieran respuestas objetivas pueden dirigirse a un nodo de recuperación de documentos que busque en una base de conocimientos preindexada (con Milvus).
Ejemplo 2: Las preguntas abiertas y creativas pueden dirigirse al LLM para tareas de generación.
Fallback (RAG correctiva)** - Asegura que el agente tiene un plan de respaldo si sus métodos de recuperación iniciales no proporcionan resultados relevantes. Supongamos que los nodos de recuperación iniciales (por ejemplo, recuperación de documentos de la base de conocimientos) no devuelven respuestas satisfactorias (en función de la puntuación de relevancia o los umbrales de confianza). En ese caso, el agente vuelve a un nodo de búsqueda web.
- El nodo de búsqueda web puede utilizar API de búsqueda externas.
Autocorrección (Self-RAG) - Permite al agente identificar y corregir sus propios errores o resultados engañosos. El nodo LLM genera una respuesta, y luego es enrutada a otro nodo para su evaluación. Este nodo de evaluación puede utilizar varias técnicas:
Reflexión: El agente puede cotejar su respuesta con la consulta original para ver si aborda todos los aspectos.
Análisis de la puntuación de confianza: El LLM puede asignar una puntuación de confianza a su respuesta. Si la puntuación es inferior a un umbral determinado, la respuesta se devuelve al LLM para su revisión.
Ideas generales para los agentes
Reflexión-** El mecanismo de autocorrección es una forma de reflexión en la que el agente LangGraph reflexiona sobre su recuperación y generaciones. Se repite la información para su evaluación y permite al agente exhibir una forma de reflexión rudimentaria, mejorando su calidad de salida con el tiempo.
Planificación- El flujo de control establecido en el grafo es una forma de planificación, el agente no sólo reacciona a la consulta, sino que establece un proceso paso a paso para recuperar o generar la mejor respuesta.
El flujo de control del agente LangGraph incorpora nodos específicos para varias herramientas. Puede incluir nodos de recuperación para la base de conocimientos (por ejemplo, Milvus), lo que demuestra su capacidad para acceder a un vasto conjunto de información, y nodos de búsqueda web para información externa.
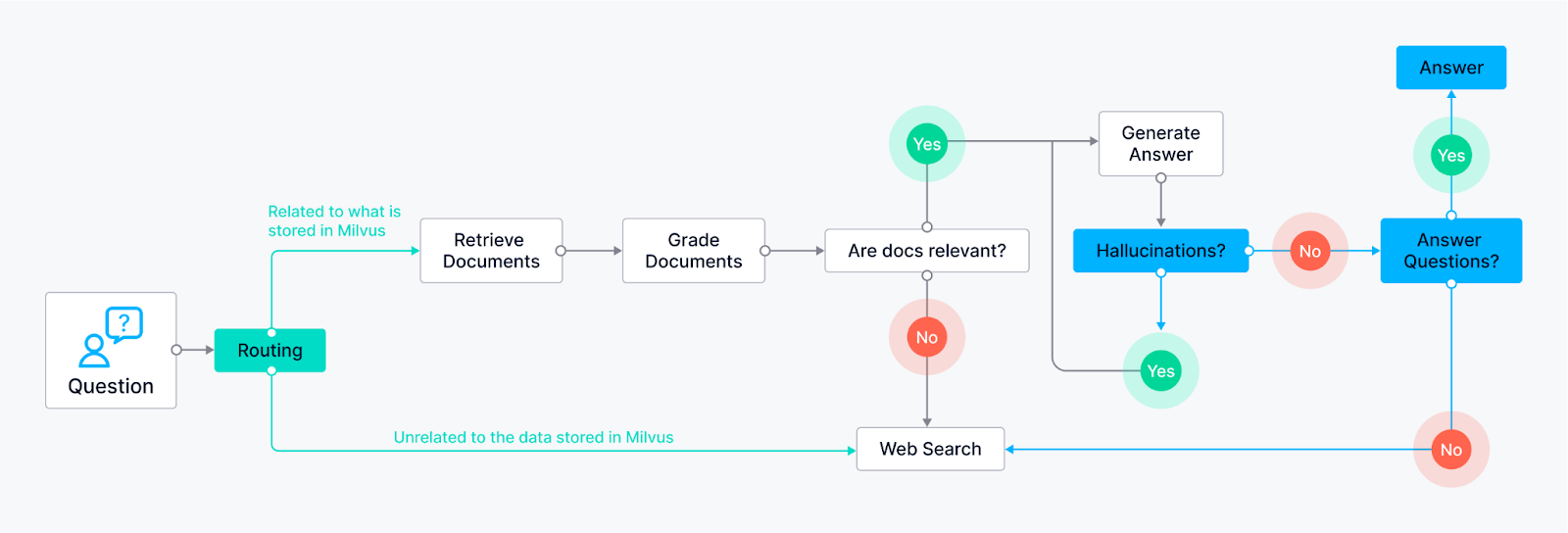
Ejemplos de agentes
Para mostrar las capacidades de nuestros agentes LLM, veamos dos componentes clave: el Hallucination Grader y el Answer Grader. Aunque el código completo está disponible al final de este post, estos fragmentos proporcionarán una mejor comprensión de cómo funcionan estos agentes dentro del marco LangChain.
Alucinación Grader
El calificador de alucinaciones intenta solucionar un problema común de los LLM: las alucinaciones, en las que el modelo genera respuestas que suenan plausibles pero carecen de base factual. Este agente actúa como un verificador de hechos, evaluando si la respuesta del LLM se alinea con un conjunto proporcionado de documentos recuperados de Milvus.
### Calificador de alucinaciones
# LLM
llm = ChatOllama(model=local_llm, format="json", temperature=0)
#Instrucción
prompt = PromptTemplate(
template="""Usted es un calificador que evalúa si
una respuesta está fundamentada / apoyada por un conjunto de hechos. Dé una puntuación binaria 'sí' o 'no' para indicar
si la respuesta se basa en / se apoya en un conjunto de hechos. Proporcione la puntuación binaria como un JSON con una única clave
con una única clave "puntuación" y sin preámbulo ni explicación.
Estos son los hechos:
{documentos}
Aquí está la respuesta:
{generación}
""",
input_variables=["generación", "documentos"],
)
hallucination_grader = prompt | llm | JsonOutputParser()
hallucination_grader.invoke({"documentos": docs, "generación": generación})
Calificador de respuestas
Tras el calificador de alucinaciones, interviene otro agente. Este agente comprueba otro aspecto crucial: asegurarse de que la respuesta del LLM responde directamente a la pregunta original del usuario. Utiliza el mismo LLM pero con una pregunta diferente, diseñada específicamente para evaluar la relevancia de la respuesta para la pregunta.
def grado_generación_v_documentos_y_pregunta(estado):
"""
Determina si la generación se basa en el documento y responde a las preguntas.
Args:
state (dict): El estado actual del grafo
Devuelve
str: Decisión para el siguiente nodo a llamar
"""
print("---CHECK HALLUCINATIONS---")
pregunta = estado["pregunta"]
documentos = estado["documentos"]
generación = state["generación"]
puntuación = hallucination_grader.invoke({"documentos": documentos, "generación": generación})
puntuación = puntuación['puntuación']
# Comprobar alucinación
if grade == "yes
print("---DECISIÓN: LA GENERACIÓN ESTÁ FUNDAMENTADA EN DOCUMENTOS---")
# Comprobar pregunta-respuesta
print("---GRADO GENERACIÓN vs PREGUNTA---")
score = answer_grader.invoke({"pregunta": pregunta, "generación": generación})
puntuación = puntuación['puntuación']
if grade == "yes":
print("---DECISIÓN: LA GENERACIÓN RESPONDE A LA PREGUNTA---")
return "útil"
else:
print("---DECISIÓN: LA GENERACIÓN NO RESPONDE A LA PREGUNTA---")
return "no útil
si no:
pprint("---DECISIÓN: LA GENERACIÓN NO ESTÁ BASADA EN DOCUMENTOS, REINTENTAR---")
return "no compatible"
Puedes ver en el código anterior que estamos comprobando las predicciones del LLM que usamos como clasificador.
Compilando el grafo LangGraph
Esto compilará todos los agentes que hemos definido y hará posible el uso de diferentes herramientas para tu sistema RAG.
# Compilar
app = workflow.compile()
# Probar
from pprint import pprint
inputs = {"pregunta": "¿Qué es la ingeniería rápida?"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f "Terminada la ejecución: {clave}:")
pprint(valor["generación"])
'Finalizada la ejecución: generar:'
('La ingeniería de prompts es el proceso de comunicación con grandes modelos lingüísticos '
(LLMs) para dirigir su comportamiento hacia los resultados deseados sin '
'actualizar los pesos del modelo. Se centra en la alineación y la dirigibilidad del modelo, '
'requiere experimentación y heurística debido a los efectos variables entre '
modelos. El objetivo es mejorar la generación de texto controlable mediante la optimización de las indicaciones para aplicaciones específicas.
' 'indicaciones para aplicaciones específicas.')
Conclusión
En esta entrada de blog, hemos mostrado cómo construir un sistema RAG usando agentes con LangChain/ LangGraph, Llama 3.2, y Milvus. Estos agentes hacen posible que los LLMs tengan capacidades de planificación, memoria y uso de diferentes herramientas, lo que puede llevar a respuestas más robustas e informativas.
Próximos pasos para la mejora
Aunque la implementación actual del sistema agentic RAG es eficaz para flujos de trabajo locales de un solo agente, hay varias direcciones interesantes para seguir mejorando e innovando.
Coordinación Multi-Agente: Actualmente, LangGraph se utiliza para diseñar sistemas mono-agente que operan dentro de un flujo de control predefinido como una búsqueda web. Sin embargo, una progresión natural sería extender este sistema para soportar múltiples agentes trabajando en paralelo o en coordinación. En situaciones en las que una tarea requiere conocimientos especializados o múltiples fuentes de recuperación, los agentes pueden procesar en colaboración distintas partes de la tarea. Por ejemplo, un agente podría centrarse en recuperar información objetiva, mientras que otro se encargaría de las tareas creativas o de la interacción con el usuario, y un tercero evaluaría la calidad general del resultado. Estos sistemas multiagente permitirían operaciones más complejas, lo que redundaría en una mayor eficacia y precisión en el tratamiento de consultas diversas.
Actualizaciones de datos en tiempo real: Otra mejora potencial podría ser permitir a los agentes actualizar sus fuentes de datos en tiempo real. Actualmente, Milvus Lite sirve como base de conocimiento estática; sin embargo, en dominios dinámicos, la información puede quedar obsoleta rápidamente. Los agentes podrían diseñarse para supervisar y actualizar continuamente su almacén local de vectores con datos frescos de la web u otras API, garantizando que los resultados del sistema sigan siendo relevantes y estén actualizados. Por ejemplo, si se pregunta a un agente por las últimas cotizaciones bursátiles o las noticias de última hora, podría obtener automáticamente los datos más recientes, con lo que el sistema sería mucho más adaptable y útil en entornos de ritmo rápido.
**Aunque el mecanismo de reflexión actual es útil, se puede mejorar en términos de autocorrección. Futuras versiones del agente podrían incorporar técnicas más avanzadas, como el aprendizaje por refuerzo o mecanismos de aprendizaje continuo, que permitan al agente aprender de sus experiencias y errores pasados a lo largo del tiempo. Permitiendo que la memoria del agente trabaje para mejorar la calidad de sus respuestas de forma iterativa, podríamos conseguir un sistema que no sólo recuperara y generara respuestas de alta calidad, sino que también refinara sus procesos basándose en la retroalimentación.
Incorporando estos pasos, podemos mejorar significativamente las capacidades de los sistemas RAG agénticos, haciéndolos más flexibles, adaptables y eficaces a la hora de resolver tareas complejas en diversos sectores.
No dude en consultar el código disponible en el repositorio Milvus Bootcamp.
Si te ha gustado esta entrada del blog que muestra cómo construir langgraph agentic rag, considera darnos una estrella en , y compartir tus experiencias con la comunidad uniéndote a nuestro
Esto está inspirado en el Repositorio Github de Meta con recetas para usar Llama 3

Sigue leyendo

Introducing Functions and Model Inference on Zilliz Cloud: Automatic Embedding and Reranking with Hosted Models
Zilliz Cloud Functions auto-generate embeddings via OpenAI, Voyage AI, Cohere, or Zilliz Hosted Models. Built-in reranking — just insert text and search.

Build for the Boom: Why AI Agent Startups Should Build Scalable Infrastructure Early
Explore strategies for developing AI agents that can handle rapid growth. Don't let inadequate systems undermine your success during critical breakthrough moments.

DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
Discover DeepRAG, an advanced retrieval-augmented generation (RAG) model that improves LLM accuracy by retrieving only essential data through step-by-step reasoning.