




LLaVA: avance de los modelos de visión-lenguaje mediante el ajuste de las instrucciones visuales
Los grandes modelos lingüísticos actuales (LLMs) como ChatGPT, LLAMA y Claude Sonnet han demostrado que las instrucciones basadas en el lenguaje humano pueden ser una poderosa herramienta para mejorar la calidad de las respuestas. Utilizando técnicas como prompt engineering, podemos guiar a los LLM para que generen respuestas que se ajusten más a nuestros casos de uso específicos.
Inicialmente, los LLM se diseñaron exclusivamente para entradas basadas en texto. Cuando se les daba una instrucción textual, generaban la respuesta correspondiente. Aunque este enfoque ha tenido mucho éxito, la ampliación de estas capacidades a entradas visuales es una progresión natural. Los modelos visuales toman como entrada tanto una instrucción textual como una imagen, lo que permite realizar tareas como resumir el contenido de una imagen, extraer información o traducir el texto de una imagen.
En este artículo analizaremos LLaVA (Large Language and Vision Assistant), uno de los esfuerzos pioneros en la implementación de instrucciones basadas en texto para modelos visuales. Antes de entrar en detalles sobre su aplicación, demos un paso atrás para comprender la evolución de los modelos visuales y cómo están transformando este campo.
Evolución de los modelos basados en la visualización
En sus primeras fases de desarrollo, la mayoría de los modelos basados en la visión se basaban en arquitecturas basadas en redes neuronales convolucionales (CNN) para realizar tareas de visión comunes. En su forma más simple, un modelo visual puede construirse con un par de capas de CNN para realizar una tarea sencilla de clasificación de imágenes, como determinar si una imagen dada es de un perro o de un gato.
Sin embargo, para clasificar imágenes más complejas con más clases, necesitamos construir modelos más profundos formados por cientos de capas CNN. Cuanto más profundas sean las capas del modelo, mayor será el riesgo de encontrarse con el problema del gradiente de fuga. El gradiente de fuga se refiere al fenómeno que se produce durante el entrenamiento del modelo cuando el gradiente se vuelve tan pequeño que el modelo es incapaz de aprender nada y actualizar sus pesos.
Para abordar este problema, se implementaron algoritmos sofisticados como conexiones residuales dentro de la arquitectura del modelo para evitar los problemas de gradiente de fuga que suelen producirse en los modelos de aprendizaje profundo. Este método demostró su eficacia y dio lugar a la creación de ResNet, que posteriormente alcanzó un rendimiento puntero en muchos conjuntos de datos de referencia de clasificación de imágenes.
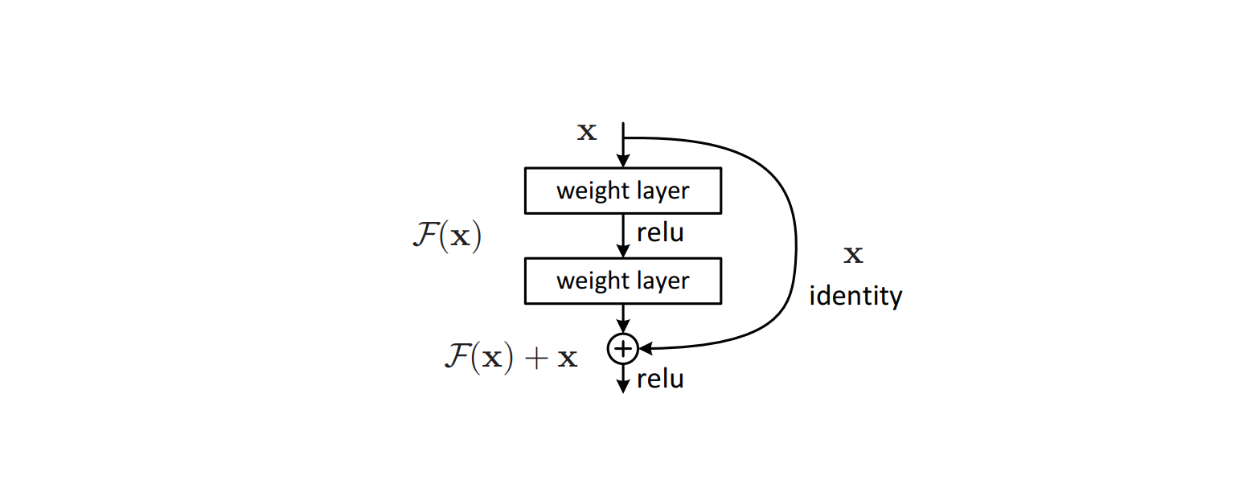
Figura: Bloque de construcción de una conexión residual dentro de la arquitectura de un modelo._ Fuente.
El éxito de ResNet inspiró otras arquitecturas de modelos capaces de realizar tareas de imagen más complejas. Modelos visuales como YOLO implementaron conexiones residuales en su arquitectura para realizar tareas de detección de objetos. Al mismo tiempo, U-Net utilizó una combinación de arquitectura en forma de U y conexiones residuales para realizar tareas de segmentación de imágenes.
Aunque estos modelos visuales pueden realizar tareas basadas en la visualización, cada uno sólo puede realizar una tarea específica. Si un modelo ha sido entrenado para la clasificación de imágenes, sólo puede utilizarse para ese fin. Además, si pedimos al modelo que clasifique una imagen significativamente distinta de las de los datos de entrenamiento, es posible que observemos cierta aleatoriedad en las predicciones del modelo.
La introducción del famoso modelo Transformers en 2017 desencadenó un rápido desarrollo de los modelos de aprendizaje profundo en general. Los modelos que adoptaron Transformers en su arquitectura superaron significativamente a los modelos más tradicionales. Originalmente pensada solo para modelos basados en texto, la arquitectura Transformers demostró ser lo suficientemente versátil como para utilizarse también en modelos basados en visión.
Los modelos de visión basados en Transformers, como Vision Transformers (ViT), demostraron una gran capacidad para realizar tareas de clasificación de imágenes. Como resultado, ViT es ahora utilizado por muchos modelos populares de visión de texto, como CLIP, como su arquitectura troncal.
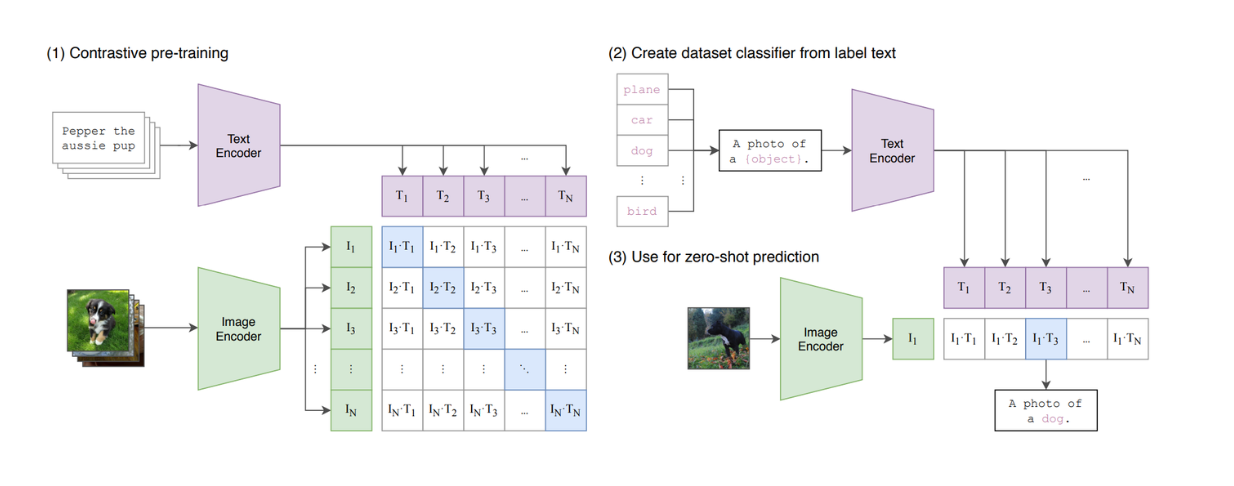
Figura: Resumen del modelo CLIP._ Fuente.
CLIP es un modelo que combina ViT y un modelo similar a BERT en su arquitectura. ViT procesa imágenes, mientras que el modelo BERT procesa textos. CLIP se ha entrenado utilizando el aprendizaje contrastivo, según el cual, cuando se le da un texto y una imagen como par de entrada, CLIP calcula la similitud entre el texto y la imagen. Sin embargo, podemos ver que CLIP sigue estando limitado en cuanto a su capacidad para imitar los LLM basados en texto, ya que no es un modelo generativo.
LLaVA es uno de los primeros LLM visuales capaz de tomar instrucciones basadas en texto e imágenes como entradas y generar una respuesta apropiada. Discutiremos los detalles de LLaVA en la siguiente sección.
¿Qué es LLaVa?
LLaVA (Large Language and Vision Assistant) es un modelo multimodal que combina grandes modelos de lenguaje (LLM) basados en texto con capacidades de procesamiento visual, lo que le permite manejar entradas de texto e imágenes. Está diseñado para realizar tareas como resumir contenidos visuales, extraer información de imágenes y responder a preguntas sobre datos visuales.
LLaVA se basa en el éxito de los LLM al incorporar la comprensión visual y alinear las instrucciones basadas en texto con el análisis de imágenes. Gracias a esta integración, el modelo puede procesar entradas emparejadas (instrucciones textuales e imágenes) y ofrecer respuestas coherentes y contextualmente relevantes.
Arquitectura de LLaVA
La arquitectura del LLaVA es relativamente sencilla. Utiliza un LLM preentrenado para procesar instrucciones textuales y el codificador visual de CLIP preentrenado, un modelo ViT, para procesar información de imagen.
Entre varios LLMs pre-entrenados disponibles públicamente, los autores de LLaVA eligieron Vicuna como columna vertebral para procesar la información textual y generar la respuesta final, dado un par de entrada texto-imagen.
Dado que la mayoría de los LLM basados en texto se basan en la arquitectura Transformer, el proceso de transformación del texto hasta la generación de la respuesta es bastante sencillo. Cada token del texto de entrada se transforma en una incrustación, después pasa por varias pilas de capas de atención y densas antes de producir la característica final de salida con una dimensión de tamaño fijo.
Para procesar la imagen de entrada, LLaVA utiliza el modelo ViT preentrenado dentro de CLIP para transformar la imagen de entrada en una representación de características con una dimensión de tamaño fijo. Sin embargo, la dimensión de la característica de imagen de CLIP difiere de la característica de texto de Vicuna. Por lo tanto, LLaVA implementa posteriormente una capa densa simple para proyectar la característica de imagen de modo que tenga el mismo tamaño que la característica textual de Vicuna.
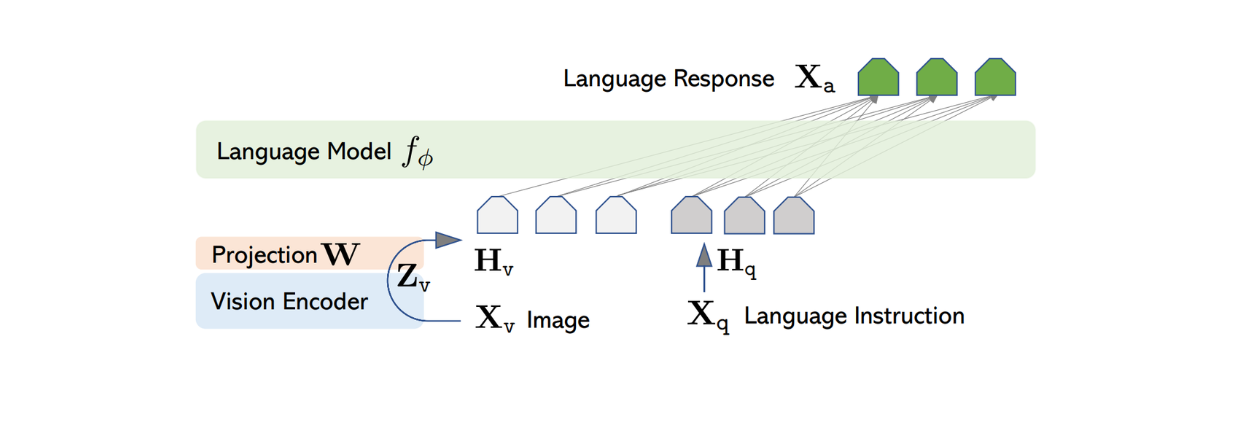
Figura: Arquitectura de LLaVA. Fuente.
Ahora que las características de imagen y de texto tienen el mismo tamaño, se necesita un enfoque para combinar estas dos características en una sola. Para ello se utilizan varios métodos, como anteponer el rasgo de imagen al rasgo de texto ([rasgo de imagen] + [rasgo de texto]) o utilizar algoritmos más sofisticados, como la atención cruzada y el Q-former. Las características combinadas de imagen y texto se introducen en Vicuna, que genera la respuesta adecuada.
Sin embargo, al aplicar el enfoque mencionado anteriormente, la calidad de la respuesta generada por Vicuna o cualquier otro LLM similar podría no ser óptima. Esto es de esperar, ya que los LLM se entrenan exclusivamente con datos textuales. Por lo tanto, el LLaVA necesita ser afinado antes de que pueda generar respuestas coherentes basadas en un par de entradas imagen-texto. Este proceso de ajuste fino se denomina ajuste visual de instrucciones, y lo trataremos en las secciones siguientes.
Proceso de generación de datos para el ajuste de instrucciones visuales
**El ajuste de instrucciones visuales es un proceso de entrenamiento de modelos de IA multimodales para comprender y responder a instrucciones basadas en texto combinadas con entradas visuales, como imágenes o vídeos. Esta técnica alinea la comprensión visual con las capacidades de procesamiento del lenguaje natural, lo que permite al modelo realizar tareas como el subtitulado de imágenes, la respuesta a preguntas visuales, el reconocimiento de objetos y la extracción de información.
Uno de los principales retos de la sintonización visual de instrucciones es la falta de datos multimodales de seguimiento de instrucciones a disposición del público. Aunque existen varios conjuntos de datos formados por pares imagen-texto, como CC y LAION, no son exactamente el tipo de conjunto de datos que nos gustaría utilizar para ajustar los LLM visuales para que sigan las instrucciones del usuario.
Figura: Ejemplo de conjunto de datos CC. Fuente.
Por otro lado, crear manualmente una cantidad masiva de datos multimodales de seguimiento de instrucciones para ajustar LLaVA requeriría un esfuerzo y un tiempo considerables. Por lo tanto, podemos aprovechar GPT-4 o ChatGPT para acelerar el proceso de creación de datos multimodales de seguimiento de instrucciones.
Como se ha visto en el ejemplo anterior de la imagen CC, los conjuntos de datos multimodales habituales constan de un par de imagen-texto de título en cada registro de datos. Con ChatGPT, dada una imagen y su pie de foto, podemos generar un conjunto de posibles preguntas destinadas a instruir a los LLM para que describan el contenido de la imagen. El formato de los datos multimodales de seguimiento de instrucciones será el siguiente Humano: Xq Xv
Sin embargo, sabemos que las iteraciones anteriores de ChatGPT sólo aceptan texto como entrada. Para utilizarlo para elaborar una lista de preguntas sobre una imagen concreta, necesitamos proporcionar información o metadatos sobre la imagen. Los autores utilizaron dos métodos distintos para proporcionar a ChatGPT la información necesaria sobre cualquier imagen de entrada: pies de foto y cuadros delimitadores. Los pies de foto suelen consistir en descripciones detalladas de la imagen, mientras que los cuadros delimitadores proporcionan a ChatGPT información útil sobre la ubicación exacta de los objetos en la imagen.

Figura: Ejemplo de pie de foto y cuadros delimitadores para capturar información visual para GPT-4 sólo texto. Fuente.
Los autores crearon tres tipos de conjuntos de datos multimodales de seguimiento de instrucciones:
Conversación: Consiste en una conversación de ida y vuelta entre el LLM y el usuario. Las respuestas del LLM se establecen con el tono como si estuviera mirando la imagen y luego respondiendo a las preguntas del usuario. Las preguntas típicas incluyen el contenido visual de la imagen, el recuento de objetos en la imagen, las posiciones relativas de los objetos en la imagen, etc.
Descripciones detalladas: consiste en una lista de preguntas destinadas a generar descripciones exhaustivas de una imagen.
Razonamiento complejo: consiste en preguntas que van más allá de los dos tipos anteriores. En lugar de limitarse a describir el contenido visual de una imagen, estas preguntas pretenden obligar al LLM a explicar la lógica que subyace a sus respuestas, exigiendo un razonamiento paso a paso.

Figura: Ejemplo de tres tipos de conjunto de datos de seguimiento de instrucciones multimodales._ Fuente.
A continuación se muestra un ejemplo de instrucción utilizado por los autores para generar un conjunto de datos de tipo conversación:
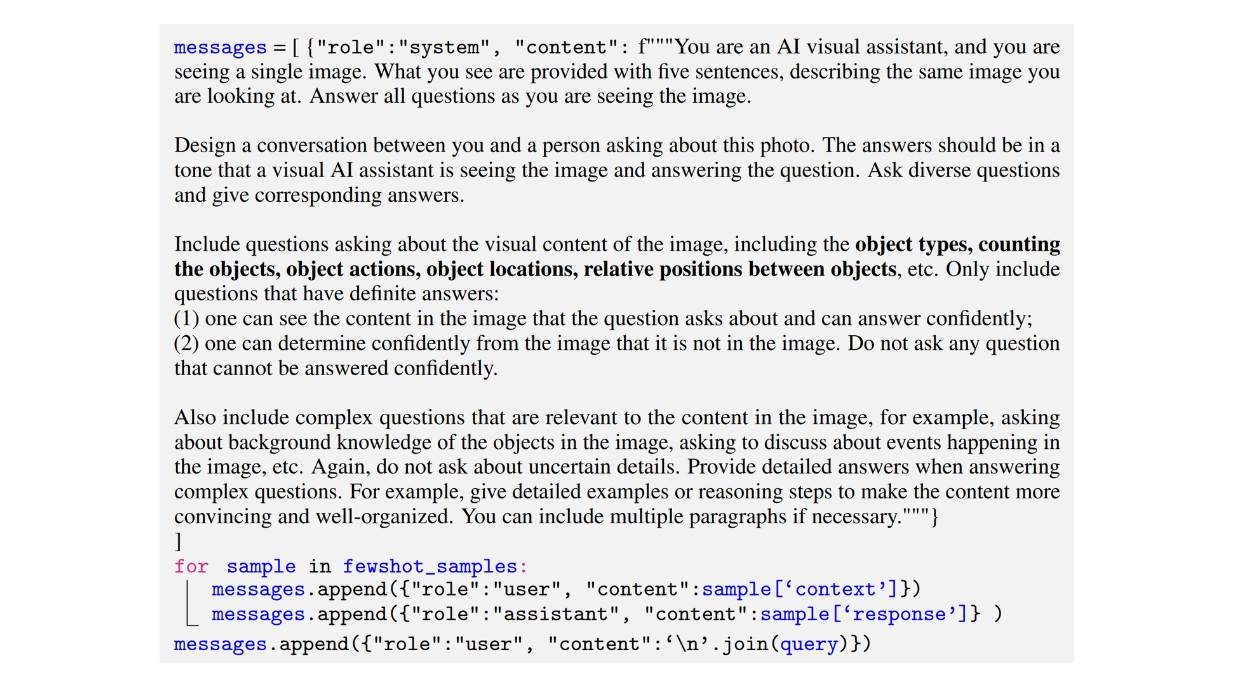
Figura: Ejemplo de una instrucción utilizada para generar un conjunto de datos multimodal de seguimiento de instrucciones de tipo conversación._ Fuente.
Obtener el resultado deseado con el formato correcto a partir de los datos multimodales de seguimiento de instrucciones generados por LLM es bastante complicado. Por eso, al pedir a ChatGPT que generara los tres tipos de conjuntos de datos multimodales de seguimiento de instrucciones, los autores utilizaron muestras de pocos disparos para aprovechar la potencia del aprendizaje en contexto.
Con estas muestras, los autores proporcionaron un par de ejemplos creados manualmente de conversaciones entre el LLM y el usuario junto con la instrucción. Estos ejemplos ayudan a ChatGPT a comprender mejor la estructura del resultado esperado. A continuación se muestra un ejemplo de una muestra de pocos disparos implementada por los autores en la solicitud para generar un conjunto de datos de conversación.

Figura: Ejemplo de un fragmento de muestra que se pasa junto a la solicitud para el aprendizaje en contexto._ Fuente.
Procedimiento de formación de LLaVA
El total de datos multimodales de seguimiento de instrucciones generados con el enfoque mencionado anteriormente fue de aproximadamente 158K. A continuación, se puso a punto un modelo LLaVA con estos datos multimodales.
En el conjunto de datos, para cada imagen Xv, hay conversaciones de varios turnos entre el LLM y los usuarios (X1q, X1a, - - - , XTq, XTa), donde T es el número total de turnos. Para cada turno t, la respuesta Xta se trata como la respuesta del LLM, y por tanto, la instrucción en el turno t sería:
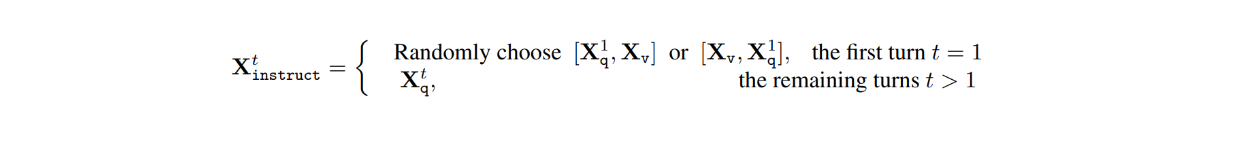
A continuación, durante el proceso de ajuste de la instrucción visual, se llevaron a cabo dos etapas: el preentrenamiento para la alineación de características y el ajuste fino de extremo a extremo.
Durante la etapa de preentrenamiento para la alineación de rasgos, el objetivo principal es entrenar la capa de proyección que mapea la salida del modelo ViT del codificador CLIP preentrenado en un rasgo visual final que tiene la misma dimensión que el rasgo de texto. En esta fase, el proceso de entrenamiento se realizó utilizando el conjunto de datos CC filtrado, que contiene 596.000 pares imagen-texto. Para cada imagen Xv, la pregunta Xq se extrae aleatoriamente de un conjunto de preguntas, y la correspondiente Xc se utiliza como etiqueta de verdad. Por lo tanto, las preguntas muestreadas para el entrenamiento son las que piden al LLM que describa brevemente la imagen, como se puede ver en la imagen de abajo:

Figura: Ejemplo de preguntas para explicar brevemente el contenido de una imagen._ Fuente.
Dado que sólo estamos entrenando la capa de proyección, los pesos de ViT y LLM se congelan en esta etapa.
Mientras tanto, durante la segunda etapa, que es el ajuste fino de extremo a extremo, el modelo LLaVA se ajusta con los datos multimodales de seguimiento de instrucciones generados por 158K. En esta etapa, sólo se congelan los pesos de ViT, mientras que los pesos de la capa de proyección y LLM se actualizan durante el proceso de ajuste fino.
Resultados LLaVA
Para evaluar el rendimiento de LLaVA, se llevó a cabo una comparación con otros modelos del estado de la técnica como GPT-4 y modelos basados en la visualización como BLIP-2 y OpenFlamingo. Para la evaluación de los resultados, los autores utilizaron el GPT-4 de sólo texto como juez para puntuar la calidad de las respuestas en función de su utilidad, relevancia, precisión y nivel de detalle.
Como primera evaluación, se seleccionaron 30 imágenes aleatorias del conjunto de datos COCO-Val-2014 y, utilizando el proceso de generación de datos explicado en la sección anterior, se generaron tres tipos de conjuntos de datos. El resultado fue un total de 90 puntos de datos: 30 para conversación, 30 para descripciones detalladas y 30 para razonamientos complejos. A continuación, se compararon las respuestas del LLaVA con los resultados del modelo GPT-4 de sólo texto, que utiliza la descripción textual como etiqueta y los cuadros delimitadores como entrada visual. Los resultados son los siguientes:
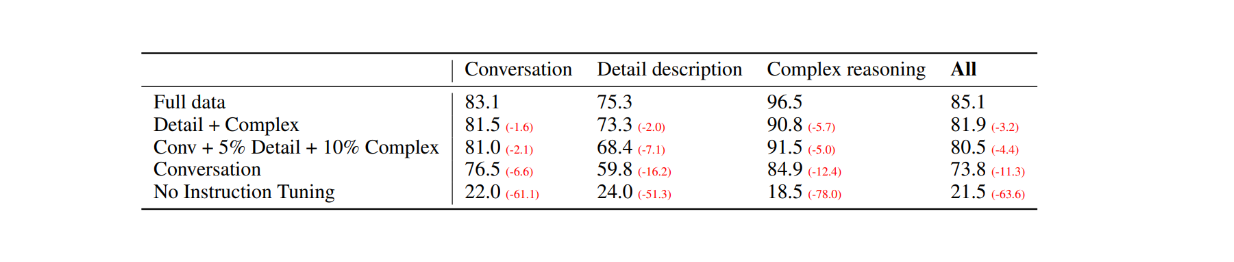
Figura: Comparación de rendimiento entre LLaVA y GPT-4 sólo texto en 30 imágenes aleatorias._ Fuente.
Con el ajuste de las instrucciones visuales, la capacidad del modelo para seguir instrucciones aumentó al menos 50 puntos en cada tipo de conjunto de datos. Mientras tanto, la puntuación relativa de LLaVA no fue muy superior a la del modelo GPT-4 de sólo texto que utiliza pies de imagen como entrada visual, como muestran los números entre paréntesis en cada categoría.
El rendimiento de LLaVA también se comparó con los modelos basados en la visualización, como BLIP-2 y OpenFlamingo, tomando primero 24 imágenes aleatorias con 60 preguntas en total. Como se muestra en la tabla siguiente, el rendimiento de LLaVA es muy superior al de los otros dos modelos basados en la visualización. Esto demuestra la potencia del ajuste visual de instrucciones, ya que BLIP-2 y OpenFlamingo no se han ajustado explícitamente con un conjunto de datos multimodal de seguimiento de instrucciones.

Figura: Comparación de rendimiento entre LLaVA y BLIP-2 y OpenFlamingo._ Fuente.
Examinemos ahora un ejemplo de las respuestas de los modelos en acción. Consideremos una imagen de nuggets de pollo formando un mapamundi, y preguntamos: "¿Puedes explicar este meme en detalle?" A continuación se muestran las respuestas de ejemplo de LLaVA, GPT-4 sólo texto, BLIP-2 y OpenFlamingo.

Figura: Ejemplos de respuestas de LLaVA, GPT-4, BLIP-2 y OpenFlamingo._ Fuente.
Como puede verse, tanto los modelos BLIP-2 como OpenFlamingo no consiguieron seguir la instrucción, ya que no han sido afinados con la sintonización visual de instrucciones. Mientras tanto, LLaVA demostró su capacidad de razonamiento visual en la comprensión del humor. Junto con GPT-4, fue capaz de proporcionar una respuesta concisa de acuerdo con la instrucción.
Cuando se afinó en el conjunto de datos ScienceQA durante aproximadamente 12 épocas, LLaVA también logró resultados muy competitivos en comparación con el modelo MM-CoT, que es el modelo de vanguardia actual (SOTA) en este conjunto de datos. Como se muestra en la tabla siguiente, LLaVA alcanzó una precisión global del 90,92% en varios temas diferentes en comparación con el 91,68% del modelo MM-CoT. Sin embargo, cuando el resultado de LLaVA se combinó con GPT-4, el rendimiento alcanzó un nuevo SOTA en el conjunto de datos ScienceQA con una precisión del 92,53%.
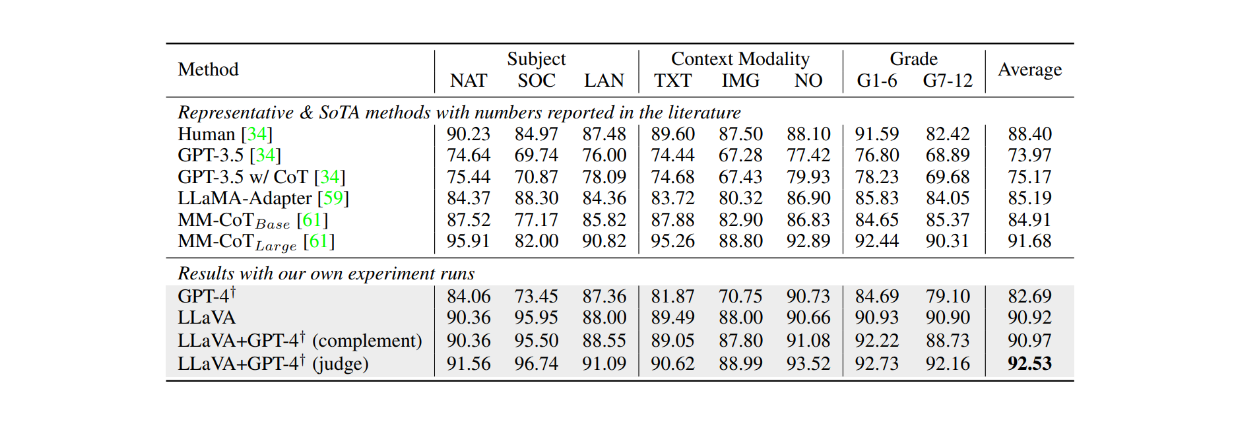
Figura: Precisión de los LLM en el conjunto de datos ScienceQA._ Fuente.
Conclusión
LLaVA representa uno de los primeros avances en el desarrollo de modelos de lenguaje visual (LLM) capaces de seguir instrucciones textuales. El modelo combina un transformador de visión (ViT) preentrenado de CLIP para el procesamiento de imágenes con Vicuna como columna vertebral del modelo de lenguaje, utilizando una capa de proyección para alinear las dimensiones de las características entre los dos componentes. A continuación, el modelo se ajusta con 158 000 muestras de datos multimodales de seguimiento de instrucciones.
Gracias a este enfoque de ajuste de instrucciones visuales, LLaVA puede describir y realizar razonamientos complejos sobre una imagen dada de acuerdo con las instrucciones de la indicación. Los resultados de la evaluación demuestran la eficacia del ajuste de instrucciones visuales, ya que el rendimiento de LLaVA supera sistemáticamente el de otros dos modelos basados en instrucciones visuales: BLIP-2 y OpenFlamingo.
Más información
Explicación del modelo ALIGN ](https://zilliz.com/learn/align-explained-scaling-up-visual-and-vision-language-representation-learning-with-noisy-text-supervision)
ColPali: mejor recuperación de documentos con VLM y embebidos ColBERT ](https://zilliz.com/blog/colpali-enhanced-doc-retrieval-with-vision-language-models-and-colbert-strategy)
Mamba: un posible sustituto del transformador ](https://zilliz.com/learn/mamba-architecture-potential-transformer-replacement)
Qué son los transformadores de detección (DETR) ](https://zilliz.com/learn/detection-transformers-detr-end-to-end-object-detection-with-transformers)
ColBERT: un modelo de incrustación y clasificación a nivel de token ](https://zilliz.com/learn/explore-colbert-token-level-embedding-and-ranking-model-for-similarity-search)
XLNet: PNL mejorado con preentrenamiento autorregresivo generalizado](https://zilliz.com/learn/xlnet-explained-generalized-autoregressive-pretraining-for-enhanced-language-understanding)
¿Qué son las bases de datos vectoriales y cómo funcionan? ](https://zilliz.com/learn/what-is-vector-database)
¿Qué es la RAG? ](https://zilliz.com/learn/Retrieval-Augmented-Generation)
Sigue leyendo

A Few Notes from Databricks Data + AI Summit 2026: Why the Data Layer Matters Again
James Luan shares notes from Databricks Data + AI Summit 2026 on why production AI is pushing the data layer back to the center of infrastructure.

Announcing the General Availability of Zilliz Cloud BYOC on Google Cloud Platform
Zilliz Cloud BYOC on GCP offers enterprise vector search with full data sovereignty and seamless integration.

VidTok: Rethinking Video Processing with Compact Tokenization
VidTok tokenizes videos to reduce redundancy while preserving spatial and temporal details for efficient processing.