




Tokenisierung: Text verstehen, indem man ihn aufbricht
Tokenisierung: Text verstehen, indem man ihn aufbricht
TL; DR
Unter Tokenisierung versteht man das Zerlegen von Text in kleinere Einheiten, so genannte Token, wie z. B. Wörter, Phrasen oder Teilwörter, um ihn für maschinelle Lernmodelle vorzubereiten. Zum Beispiel könnte der Satz "Tokenization in Milvus is powerful" in Token wie `["Tokenization", "in", "Milvus", "is", "powerful"] zerlegt werden. Diese Token werden in numerische Einbettungen umgewandelt, die ihre Bedeutung für Aufgaben wie semantische Suche erfassen. In der Milvus Vektordatenbank ist die Tokenisierung in integrierte Analysatoren integriert, die den Text für die Indizierung und Abfrage effizient verarbeiten. Diese Funktion vereinfacht die Arbeitsabläufe und ermöglicht es Entwicklern, Rohtext direkt zu verarbeiten und erweiterte Suchanwendungen mit hoher Präzision und Skalierbarkeit zu betreiben;
Einführung
Das Herzstück vieler Systeme für künstliche Intelligenz (KI) und natürliche Sprachverarbeitung (NLP) ist ein Prozess, der Rohtext in "strukturierte Daten" umwandelt - die Tokenisierung. Aber was genau ist die Tokenisierung, und warum ist es für Maschinen so wichtig, Text in kleinere Stücke zu zerlegen?
Bei der Tokenisierung wird der Text in kleinere Einheiten zerlegt, damit Maschinen die Sprache besser analysieren und verstehen können. Dieser wichtige Schritt ermöglicht es Computern, menschliche Sprache für verschiedene NLP-Aufgaben zu verarbeiten, z. B. Stimmungsanalyse, Sprachübersetzung und Texterstellung.
 Tokenisierung
Tokenisierung
Was ist Tokenisierung?
Bei der Tokenisierung werden Texte, wie z. B. Wörter oder Zeichen, in kleinere Einheiten unterteilt, die Token genannt werden. Dies ist ein grundlegender Schritt im NLP, der es Maschinen ermöglicht, menschliche Sprache besser zu verarbeiten und zu verstehen.
Warum brauchen wir Tokenisierung?
Tokenisierung ist wie das Erlernen einer neuen Sprache: Man beginnt damit, Sätze in kleinere Einheiten zu zerlegen, um ihre Bedeutung und Struktur zu verstehen. Auf die gleiche Weise unterteilen Computer einen Textblock in kleinere, handhabbare Einheiten, um ihn zu verarbeiten. Durch die Tokenisierung lernt der Computer, diese grundlegenden Komponenten wie Wörter oder Unterwörter zu erkennen, so dass er den Text verstehen und analysieren kann.
Technisch gesehen wird durch die Tokenisierung unstrukturierter Text in ein strukturiertes Format umgewandelt, das ein Computer verarbeiten kann. Wenn Sie beispielsweise einen Satz in ein NLP-Modell eingeben, zerlegt der Tokenizer ihn in Token, denen dann numerische Werte zugewiesen werden. Diese Werte ermöglichen es Computern, mathematische Operationen durchzuführen, Beziehungen zu erkennen und aus den Daten eine Bedeutung zu extrahieren. Ohne Tokenisierung würde der Text für die Maschine eine unverständliche Zeichenfolge bleiben, die eine weitere Analyse unmöglich macht.
Schlüsselkonzepte der Tokenisierung
Im Folgenden werden die wichtigsten Konzepte erläutert, die Sie über die Tokenisierung verstehen müssen.
Token
Ein Token ist eine Grundeinheit eines Textes, die für die Analyse als sinnvoll erachtet wird. Token können Zeichen, Wörter oder Teilwörter sein, die als primäre Eingabe für nachfolgende Textverarbeitungsaufgaben dienen.
Tokenizer
Tokenizer sind die grundlegenden Werkzeuge, die es Computern ermöglichen, menschliche Sprache zu zerlegen und zu interpretieren, indem sie den Text in Token zerlegen. Sie wenden spezifische Regeln an, wie z. B. die Aufteilung durch Leerzeichen oder die Verwendung von Techniken auf Teilwortebene, um die Granularität der Textdarstellung zu definieren.
Analyzer
Ein Analyzer geht über die einfache Tokenisierung hinaus, um Text tiefgreifend zu verarbeiten und zu verstehen. Nach der Tokenisierung werden Filter auf die Token angewandt, um sie durch zusätzliche Verarbeitung weiter zu verfeinern, z. B. durch Kleinschreibung, Stemming, Lemmatisierung oder das Entfernen von Stoppwörtern.
Vokabular
Das Vokabular ist die Menge der eindeutigen Token (Wörter, Unterwörter oder Zeichen), die ein Modell verarbeiten kann. Es wird aus den Token gebildet, die bei der Tokenisierung erzeugt werden. Das Vokabular dient dem Modell als Referenz für das Textverständnis. Sein Aufbau und seine Größe beeinflussen die Fähigkeit des Modells, Sprache zu verarbeiten, insbesondere seltene oder unbekannte Wörter.
Abbildung - Tokenizer und Analyzer in Milvus (https://assets.zilliz.com/Figure_Tokenizer_and_Analyzer_in_Milvus_2f283b3046.png)
Abbildung: Tokenisierer und Analyzer in Milvus
Dieses Diagramm veranschaulicht den Textverarbeitungsfluss, bei dem der Rohtext in Token umgewandelt wird. Anschließend wendet ein Analysator Filter an, um die Token in Kleinbuchstaben umzuwandeln und Stoppwörter zu entfernen, was zu einer verfeinerten Liste sinnvoller Token führt.
Arten der Tokenisierung
Die Tokenisierungsmethoden variieren je nach der Granularität der Textaufschlüsselung und den spezifischen Anforderungen der jeweiligen Aufgabe. Hier sind die gängigen Arten der Tokenisierung:
1. Zeichen-Tokenisierung: Sie zerlegt den Text in einzelne Zeichen. Dies kann bei Sprachen mit komplexer Morphologie und bei Aufgaben wie der Rechtschreibkorrektur oder dem Umgang mit verrauschtem Text nützlich sein.
Abbildung - Tokenisierung von Zeichen](https://assets.zilliz.com/Figure_Character_tokenization_c7c185282c.png)
Abbildung: Tokenisierung von Zeichen
2. Wort-Tokenisierung: Dies ist die häufigste Art der Tokenisierung, bei der der Text in einzelne Wörter zerlegt wird. Sie ist nützlich für Sprachmodellierung, Part-of-Speech-Tagging und Named-Entity-Recognition, die auf einer Analyse auf Wortebene beruhen.
Abbildung- Wort-Tokenisierung](https://assets.zilliz.com/Figure_Word_tokenization_8b09acd648.png)
Abbildung: Wort-Tokenisierung.
3. Satz-Tokenisierung: Diese Art segmentiert den Text in Sätze. Er trennt Absätze oder lange Textblöcke in einzelne Sätze auf. Verwenden Sie diesen Typ für Aufgaben wie Stimmungsanalyse und Textzusammenfassung, bei denen eine Analyse der Struktur auf Satzebene erforderlich ist.
Abbildung- Satz-Tokenisierung](https://assets.zilliz.com/Figure_Sentence_tokenization_c0dadf08e4.png)
Abbildung: Tokenisierung von Sätzen.
4. Tokenisierung von Teilwörtern: Diese Methode zerlegt Wörter in kleinere, sinnvolle Einheiten (z. B. Präfixe, Suffixe oder Stämme). Sie hilft bei der Reduzierung des Vokabulars und ist besonders nützlich für Aufgaben wie die Texterstellung.
Abbildung - Tokenisierung von Unterwörtern](https://assets.zilliz.com/Figure_Subword_tokenization_9cc8b0d197.png)
Abbildung: Teilwort-Tokenisierung
Bei der Teilwort-Tokenisierung wird der Satz in Teilwort-Token zerlegt. Seltene Wörter wie "Zilliz" und "Milvus" werden in kleinere Einheiten zerlegt. Außerdem wird "open-source" in ["open", "-", "source"] aufgeteilt, wobei der Bindestrich als separates Token behandelt wird.
Codebeispiel
Hier ist ein Python-Beispiel, das den [BERT-Tokenizer] von Hugging Face verwendet (https://huggingface.co/docs/transformers/v4.47.1/en/model_doc/bert#transformers.BertTokenizer). Es demonstriert, wie der Satz mit dem WordPiece-Algorithmus unter Verwendung von Teilwort-Tokenisierung tokenisiert wird:
from transformers import AutoTokenizer
# Einen vortrainierten Tokenizer laden
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# Tokenisierung eines Satzes
sentence = "Zilliz hat Milvus entwickelt, eine leistungsstarke Open-Source-Vektordatenbank"
tokens = tokenizer.tokenize(satz)
print(tokens)
Ausgabe
['z', '##ill', '##iz', 'created', 'mil', '##vus', ',', 'a', 'powerful', 'open', '-', 'source', 'vector', 'database']
Vergleich zwischen Tokenisierung und Worteinbettung
Tokenisierung und Worteinbettung sind beides grundlegende Techniken in der Verarbeitung natürlicher Sprache (NLP), dienen aber unterschiedlichen Zwecken. Bei der Tokenisierung wird der Text in kleinere Einheiten zerlegt, während die Einbettung diese Einheiten in eine numerische Form umwandelt.
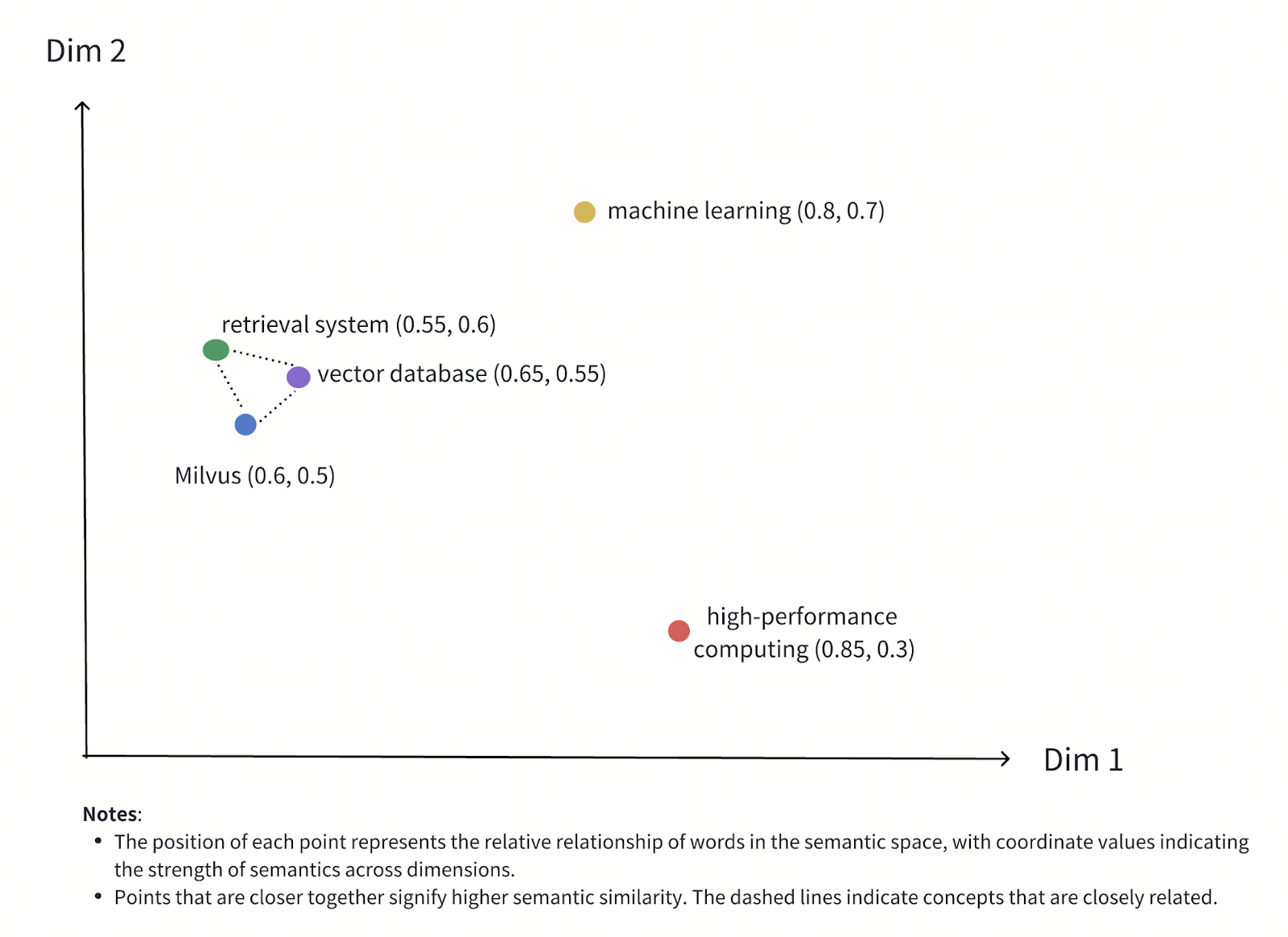 Abbildung - Semantische Beziehung zwischen Wörtern im Vektorraum
Abbildung - Semantische Beziehung zwischen Wörtern im Vektorraum
Abbildung: Semantische Beziehung zwischen Wörtern im Vektorraum
Hier ist ein Vergleich von Tokenisierung und Worteinbettung:
| Aspekt | Tokenisierung | Worteinbettung |
|---|---|---|
| Definition | Der Prozess der Aufteilung von Text in kleinere Einheiten (Token) | Eine Methode zur Darstellung von Token als dichte Vektoren im hochdimensionalen Vektorraum |
| Zweck | Zerlegen von Text in verarbeitbare Einheiten | Erfassen der semantischen Bedeutung und der Beziehung zwischen Wörtern in der Vektordarstellung |
| Beispiele | Satz: "Tokenisierung ist entscheidend "Tokens: ["Tokenization", "is", "crucial"] | Word: "Milvus "Einbettung: [0.23, 0.56, -0.12, ...] |
| Vorteile | Konvertiert unstrukturierten Text in ein strukturiertes Format, das ein Computer verarbeiten kann | Erfasst Wortsemantik, Beziehungen und Kontext |
| Einschränkungen | Erfasst nicht die Semantik der Token | Erfordert große Rechenleistung zur Erzeugung von Einbettungen |
Vorteile und Herausforderungen der Tokenisierung
Die Tokenisierung ist bei der Textverarbeitung von entscheidender Bedeutung. Sie bietet verschiedene Vorteile für die Sprachmodellierung und -analyse, hat aber auch ihre eigenen Herausforderungen. Lassen Sie uns beide Aspekte untersuchen.
Vorteile
Effektive Textverarbeitung: Die Tokenisierung ist grundlegend für die Vorbereitung von Textdaten für NLP-Aufgaben. Sie macht den Text besser geeignet für maschinelle Lernmodelle.
Granularitätskontrolle: Die Tokenisierung ermöglicht die Kontrolle über die Granularität, so dass das Modell je nach Aufgabe mit Wörtern, Teilwörtern oder sogar Zeichen arbeiten kann. Verschiedene Aufgaben haben unterschiedliche Anforderungen, und eine spezifische Granularität kann die Leistung verbessern.
Sprachunabhängigkeit: Tokenisierungsverfahren können an verschiedene Sprachen und Schriften angepasst werden, um verschiedenen Sprachen gerecht zu werden.
Erleichtert die Sprachmodellierung: Die Tokenisierung ist für die Sprachmodellierung entscheidend. Sie definiert die Grundeinheiten (Token), die das Modell verarbeitet, und ermöglicht so ein besseres Verständnis und eine bessere Generierung von Text.
Herausforderungen
Mehrdeutigkeit: Die Tokenisierung steht vor Herausforderungen aufgrund der Mehrdeutigkeit der Sprache. So kann sich das Wort "Bank" beispielsweise je nach Kontext auf ein Finanzinstitut oder auf das Ufer eines Flusses beziehen. Ebenso können Ausdrücke wie "High School" als zwei getrennte Wörter oder als eine einzige Einheit tokenisiert werden, was die Interpretation beeinflusst.
Token-Verlust: Bei einigen Tokenisierungsmethoden können Informationen verloren gehen, indem Wörter in kleinere Token zerlegt werden, wodurch es für Modelle schwieriger wird, den vollständigen Kontext oder die Bedeutung des ursprünglichen Textes zu verstehen.
Behandlung von Interpunktionen: Die Segmentierung von Token, die Interpunktionen wie Apostrophe oder Bindestriche enthalten, kann für NLP-Algorithmen manchmal problematisch sein.
Sprachen ohne klare Grenzen: Die Tokenisierung kann in Sprachen ohne klare Wortgrenzen, wie z. B. Chinesisch oder Japanisch, wo Leerzeichen nicht immer Wörter trennen, besonders schwierig sein. Diese Sprachen erfordern ausgefeiltere Tokenisierungsmethoden, um den Text genau aufzuteilen.
Anwendungsfälle der Tokenisierung
Die Tokenisierung wird bei verschiedenen NLP-Aufgaben eingesetzt und hilft Systemen bei der Verarbeitung und Analyse von Textdaten. Im Folgenden sind einige der wichtigsten Anwendungsfälle für Tokenisierung aufgeführt:
Suchmaschinen: Die Tokenisierung ermöglicht es Suchmaschinen, relevante Inhalte schnell zu indizieren und abzurufen, indem sie Suchbegriffe und Dokumente in Token aufschlüsselt und so genaue Ergebnisse für Benutzeranfragen gewährleistet.
Maschinenübersetzung: Die Tokenisierung ist bei der maschinellen Übersetzung von entscheidender Bedeutung, da sie dazu beiträgt, Ausgangs- und Zielsprachen in Token aufzuschlüsseln, die ein Modell abbilden und effektiv zwischen Sprachen übersetzen kann.
Spracherkennung: Die Tokenisierung hilft bei der Umwandlung von gesprochener Sprache in Text, indem sie die Audioeingabe für die Verarbeitung in Token segmentiert, so dass Systeme gesprochene Wörter auf strukturierte Weise verstehen können.
Stimmungsanalyse: Die Tokenisierung ist für die Stimmungsanalyse unerlässlich, bei der der Text für die weitere Verarbeitung in Token zerlegt wird, um festzustellen, ob die geäußerte Stimmung positiv, negativ oder neutral ist.
Chatbots und virtuelle Assistenten: Die Tokenisierung ermöglicht es Chatbots und virtuellen Assistenten, Benutzeranfragen zu verstehen und zu verarbeiten, indem sie den Text in handhabbare Einheiten aufteilen. Dadurch können sie auf der Grundlage der Eingaben intelligent reagieren.
Tools für die Tokenisierung
Für die Tokenisierung im NLP werden üblicherweise mehrere Tools verwendet:
NLTK: Es handelt sich um eine leistungsstarke Python-Bibliothek für die Verarbeitung natürlicher Sprache, die Tools für Tokenisierung, Stemming, Lemmatisierung, POS-Tagging und mehr bietet.
SpaCy: Eine schnelle NLP-Bibliothek mit einem leistungsstarken Tokenizer für Wörter und Sätze und einer anpassbaren Tokenisierung, die es zu einem bevorzugten Werkzeug für industrielle Anwendungen macht.
Hugging Face Tokenizer: Es tokenisiert transformatorbasierte Modelle wie BERT und GPT mit Teilwortbehandlung.
Gensim: Beliebt für die Themenmodellierung, enthält es Textvorverarbeitungs- und Tokenisierungsfunktionen.
Tokenisierung in der Milvus-Vektor-Datenbank
Eine Vektordatenbank dient der Speicherung, Indizierung und Suche von unstrukturierten Daten - wie Text, Bilder und Videos - unter Verwendung hochdimensionaler Vektoreinbettungen. Diese Einbettungen ermöglichen einen schnellen semantischen Informationsabruf und ähnlichkeitsbasierte Suchen, was Vektordatenbanken für Anwendungen wie Empfehlungssysteme, Suchmaschinen und KI-Workflows unverzichtbar macht.
Die Tokenisierung ist der erste Schritt in diesem Prozess. Dabei wird der Rohtext in kleinere Einheiten wie Wörter, Phrasen oder Unterwörter zerlegt, die dann von [maschinellen Lernmodellen] in numerische Darstellungen (Vektoreinbettungen) umgewandelt werden (https://zilliz.com/ai-models). Milvus, eine von Zilliz entwickelte Open-Source-Vektordatenbank, speichert diese Einbettungen in einem hochdimensionalen Raum, in dem sie effizient auf Ähnlichkeit abgefragt werden können.
Eingebaute Tokenisierung in Milvus
Milvus vereinfacht die Tokenisierung mit seinen eingebauten Analysatoren, die auf verschiedene Sprachen und Anwendungsfälle zugeschnitten sind. Diese Analysatoren integrieren Tokenisierer und Filter, um Textdaten für eine effiziente Indizierung und Abfrage zu verarbeiten:
Standard-Analysator: Der Standard-Analyzer für die allgemeine Textverarbeitung. Er führt eine grammatikbasierte Tokenisierung durch, konvertiert Token in Kleinbuchstaben und unterstützt die Suche ohne Berücksichtigung der Groß-/Kleinschreibung.
Englischer Analyzer: Speziell für englischen Text entwickelt. Er beinhaltet Stemming (Reduktion von Wörtern auf ihre Stammformen) und entfernt häufige Stoppwörter und konzentriert sich auf sinnvolle Begriffe.
Chinese Analyzer: Optimiert für die Verarbeitung chinesischer Texte, mit Tokenisierung, die auf die besonderen Sprachstrukturen abgestimmt ist.
Diese integrierten Analysatoren ermöglichen es Entwicklern, Rohtexte direkt in Milvus einzugeben, ohne dass eine externe Vorverarbeitung erforderlich ist, wodurch Arbeitsabläufe rationalisiert und die Komplexität reduziert werden.
Wie Milvus die Tokenisierung handhabt
Ab Milvus 2.5 enthält die Datenbank eingebaute Volltextsuche Fähigkeiten, die es ihr ermöglichen, Rohtexteingaben intern zu verarbeiten. Wenn Sie Textdaten eingeben, verwendet Milvus den angegebenen Analysator, um den Text in einzelne, durchsuchbare Begriffe zu zerlegen. Diese Begriffe werden dann mit Algorithmen wie BM25 in Sparse Vector Representations umgewandelt und für einen effizienten Abruf gespeichert.
Dieser hybride Ansatz ermöglicht es Milvus, sowohl dichte Vektoren (semantische Einbettungen) als auch spärliche Vektoren (schlagwortbasierte Repräsentationen) zu verarbeiten. Als Ergebnis unterstützt Milvus fortschrittliche hybride Suchszenarien, die semantisches Verständnis mit Schlüsselwortpräzision kombinieren und dabei Tokenisierung und Vektorisierung nahtlos in der Datenbank verwalten.
Vorteile der integrierten Tokenisierung in Milvus
Vereinfachter Arbeitsablauf: Die integrierten Analysatoren von Milvus machen externe Tokenisierungs-Tools überflüssig und erleichtern die direkte Aufnahme von Rohtextdaten.
Erweiterte Suchfähigkeiten: Durch die Kombination von Volltextsuche und [Vektorähnlichkeitssuche] (https://zilliz.com/learn/vector-similarity-search) liefert Milvus hochpräzise und relevante Ergebnisse für verschiedene Anwendungen.
Skalierbarkeit: Die interne Handhabung von Tokenisierung und Vektorisierung stellt sicher, dass Milvus große Textdaten in einer Vielzahl von Anwendungsfällen effizient verarbeiten kann.
Mit diesen Funktionen ermöglicht Milvus Entwicklern die einfachere Erstellung intelligenter Such- und Analyseanwendungen, wobei der Schwerpunkt auf Innovation und nicht auf den Feinheiten der Textvorverarbeitung liegt. Ganz gleich, ob Sie an einer natürlichsprachlichen Suche, KI-gesteuerten Empfehlungen oder hybriden Retrievalsystemen arbeiten, Milvus bietet eine robuste und entwicklerfreundliche Plattform für Ihre Anwendungen.
FAQs über Tokenisierung
01. Warum ist Tokenisierung in NLP wichtig?
Durch Tokenisierung wird unstrukturierter Text in handhabbare Einheiten umgewandelt, die es Computern ermöglichen, Sprache zu verarbeiten. Sie hilft NLP-Modellen dabei, Token numerische Repräsentationen zuzuweisen, was mathematische Operationen und die Extraktion sinnvoller Muster ermöglicht.
02. Was ist der Unterschied zwischen Wort- und Zeichen-Tokenisierung?
Bei der Wort-Tokenisierung wird der Text in einzelne Wörter zerlegt, wobei jedes Wort als separates Token behandelt wird. Bei der Zeichentokenisierung hingegen wird der Text in einzelne Zeichen zerlegt.
03. Was ist Lemmatisierung und Tokenisierung?
Bei der Tokenisierung wird der Text in kleinere Einheiten wie Wörter oder Sätze zerlegt, was die Verarbeitung für Computer erleichtert. Bei der Lemmatisierung werden Wörter auf ihre Grundform reduziert, z. B. wird "laufen" in "laufen" umgewandelt, was ein einheitliches Sprachverständnis gewährleistet.
04. Wie wirkt sich die Tokenisierung auf die Modellleistung aus?
Die Tokenisierung wirkt sich darauf aus, wie der Text aufgeschlüsselt und von einem Modell verstanden wird. Eine korrekte Tokenisierung kann die Modellleistung verbessern, indem sie genaue Beziehungen zwischen Wörtern erfasst, während eine schlechte Tokenisierung zu Fehlinterpretationen oder Bedeutungsverlusten führen kann.
05. Welche Rolle spielt die Tokenisierung bei der Stimmungsanalyse oder Textklassifizierung?
Bei der Stimmungsanalyse und Textklassifizierung wird der Text durch die Tokenisierung in kleinere Einheiten wie Wörter oder Phrasen zerlegt, die dann auf Muster oder Stimmungen untersucht werden können. Dieser Prozess ermöglicht es Algorithmen, einzelne Token zu verarbeiten und den Text genau zu klassifizieren oder ihm eine Stimmung zuzuordnen.
Verwandte Ressourcen
Was ist Milvus | Milvus Dokumentation](https://milvus.io/docs/overview.md)
NLP-Grundlagen: Token, N-Gramme und Bag-of-Words-Modelle](https://zilliz.com/learn/introduction-to-natural-language-processing-tokens-ngrams-bag-of-words-models)
Top 10 der beliebtesten NLP-Techniken für Datenwissenschaftler
Einsteigerhandbuch zur natürlichen Sprachverarbeitung](https://zilliz.com/learn/A-Beginner-Guide-to-Natural-Language-Processing)
Was ist Information Retrieval? Ein umfassender Leitfaden](https://zilliz.com/learn/what-is-information-retrieval)
- TL; DR
- Einführung
- Was ist Tokenisierung?
- Warum brauchen wir Tokenisierung?
- Schlüsselkonzepte der Tokenisierung
- Token
- Arten der Tokenisierung
- Vergleich zwischen Tokenisierung und Worteinbettung
- Vorteile und Herausforderungen der Tokenisierung
- Anwendungsfälle der Tokenisierung
- Tools für die Tokenisierung
- Tokenisierung in der Milvus-Vektor-Datenbank
- FAQs über Tokenisierung
- Verwandte Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren