




Klassifizierung beim maschinellen Lernen: Alles, was Sie wissen sollten

Klassifizierung beim maschinellen Lernen: Alles, was Sie wissen sollten
Was ist Klassifizierung?
Klassifizierung ist ein überwachter Ansatz des maschinellen Lernens, der Daten in vordefinierte Klassen einteilt. Bei einer Eingabe sagt ein Klassifizierungsmodell die Kategorie oder Bezeichnung voraus, zu der die Eingabe gehört. Dies ist eine der häufigsten Aufgaben beim maschinellen Lernen und wird in vielen realen Anwendungen eingesetzt, von der Erkennung von E-Mail-Spam bis zu medizinischen Diagnosen.
Wenn Sie zum Beispiel einen Datensatz von E-Mails haben, kann ein Klassifizierungsmodell lernen, jede E-Mail entweder als "Spam" oder "kein Spam" zu kennzeichnen.
Wie funktioniert die Klassifizierung?
Bei der Klassifizierung wird ein Modell für maschinelles Lernen auf einem Datensatz trainiert, um die Daten anhand der eingegebenen Merkmale in vordefinierte Klassen einzuteilen. Das Modell wird anhand eines markierten Datensatzes trainiert, bei dem jede Eingabe mit einer Ausgabebezeichnung verknüpft ist. Das Modell lernt die Muster in den Daten während des Trainings und verwendet diese Muster, um die Bezeichnungen für neue, ungesehene Daten vorherzusagen.
Stellen Sie sich zum Beispiel vor, dass Sie eine E-Mail als Spam klassifizieren sollen. In der Trainingsphase werden dem Modell E-Mails mit ihren Kennzeichnungen ("Spam" oder "kein Spam") vorgelegt. Es analysiert Merkmale wie das Vorhandensein bestimmter Schlüsselwörter oder die Adresse des Absenders, um Muster zu erkennen. Nachdem das Modell trainiert wurde, analysiert es dieselben Merkmale und sagt voraus, ob eine neue E-Mail zur Kategorie "Spam" oder "Nicht-Spam" gehört.
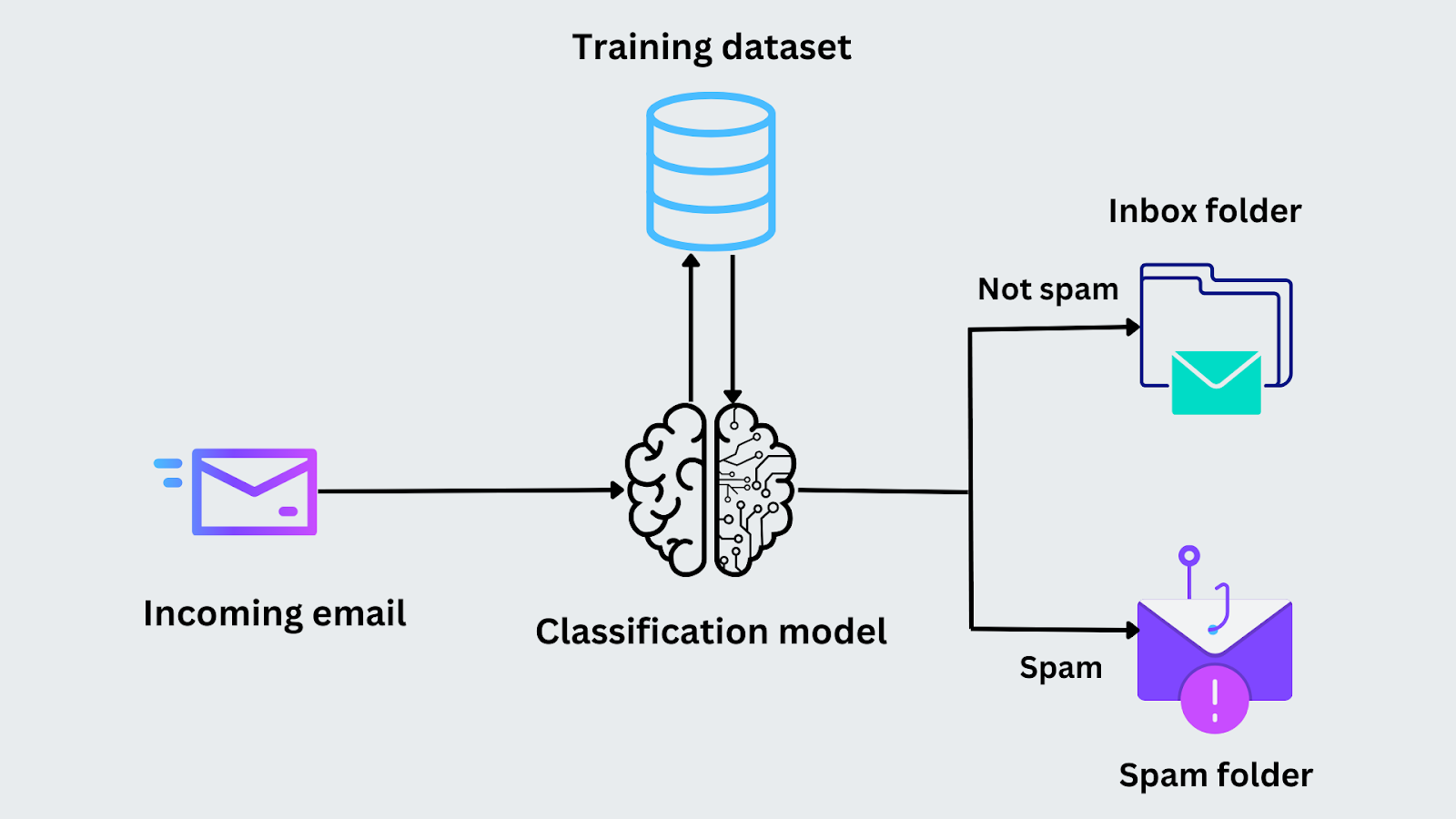 Abbildung - E-Mail-Klassifizierungsprozess.png
Abbildung - E-Mail-Klassifizierungsprozess.png
Abbildung: Prozess der E-Mail-Klassifizierung
Arten der Klassifizierung
Klassifizierungsprobleme treten in verschiedenen Formen auf, je nach Art der Daten und der Anzahl der Klassen. Hier sind die häufigsten Arten:
Binäre Klassifikation
Eine binäre Klassifizierung liegt vor, wenn es nur zwei mögliche Klassen oder Ergebnisse gibt. Das Modell sagt voraus, zu welcher der beiden Kategorien die Eingabe gehört. Ein klassisches Beispiel ist die E-Mail-Spam-Erkennung. Das Modell muss entscheiden, ob eine eingehende E-Mail entweder "Spam" oder "kein Spam" ist. Da es nur zwei Möglichkeiten gibt, handelt es sich um eine binäre Klassifizierungsaufgabe.
Multiklassen-Klassifikation
Bei der Mehrklassenklassifikation sagt das Modell eine von mehr als zwei möglichen Kategorien voraus. Jede Eingabe wird genau einer Klasse zugewiesen. Ein gutes Beispiel ist die [Bilderkennung] (https://zilliz.com/learn/what-is-computer-vision#How-Computer-Vision-Works), bei der das Modell ein Bild als "Katze", "Hund" oder "Vogel" klassifizieren kann. Anders als bei der binären Klassifizierung hat das Modell mit mehreren unterschiedlichen Klassen zu tun und muss für jede Eingabe die richtige Klasse identifizieren.
Multilabel-Klassifikation
Bei der Multilabel-Klassifizierung kann jede Eingabe gleichzeitig mehreren Klassen angehören. Beim Markieren eines Fotos kann dieses beispielsweise gleichzeitig mit "Sonnenuntergang", "Strand" und "Menschen" gekennzeichnet werden. Jede Markierung steht für eine andere Klasse, und das Modell lernt, alle relevanten Markierungen für eine Eingabe vorherzusagen. Dies unterscheidet sich von der Multiklassenklassifizierung, da derselben Eingabe mehrere Kennzeichnungen zugewiesen werden können.
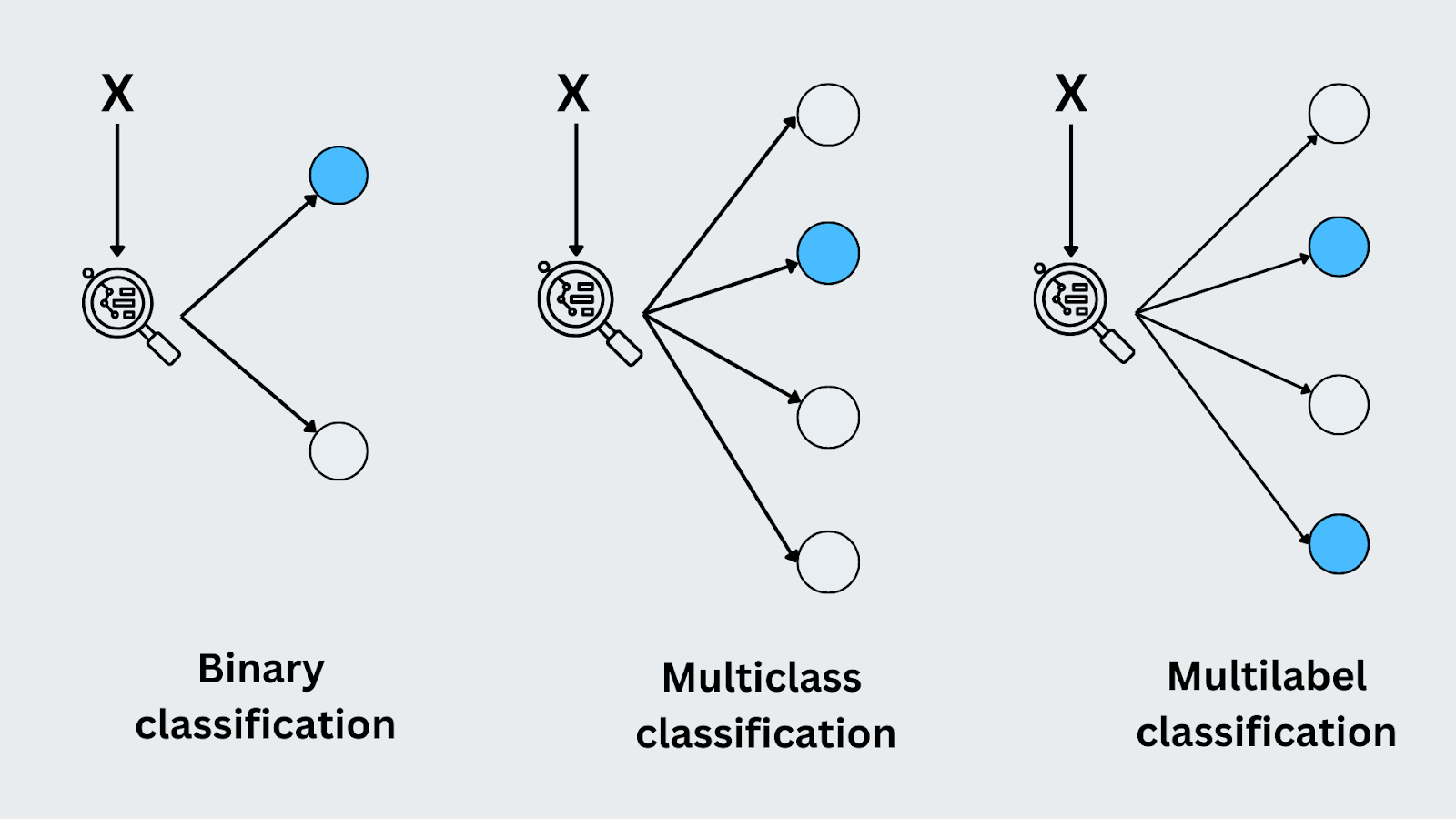 Abbildung- Arten der Klassifizierung.png
Abbildung- Arten der Klassifizierung.png
Abbildung: Arten der Klassifizierung
Lernende in Klassifizierungsalgorithmen
Beim maschinellen Lernen lassen sich die Klassifizierungsalgorithmen danach einteilen, wie sie von den Trainingsdaten verallgemeinern. Diese sind Lazy Learners und Eager Learners. Der Unterschied zwischen diesen beiden Typen liegt darin, wann und wie sie die Daten verarbeiten, um Vorhersagen zu treffen.
Faule Lerner
Faule Lerner sind Algorithmen, die die Verallgemeinerung aufschieben, bis sie eine Vorhersageanfrage erhalten. Sie bauen während der Trainingsphase kein Modell auf, sondern speichern die Trainingsdaten und führen nur dann Berechnungen durch, wenn eine neue Eingabe klassifiziert werden muss.
Beispielalgorithmen: k-Nächste Nachbarn (k-NN), Fallbasiertes Reasoning (CBR).
Eifrige Lerner
Eifrige Lerner versuchen dagegen, gleich in der Trainingsphase ein allgemeines Modell zu erstellen. Sie analysieren die Trainingsdaten, lernen die zugrunde liegenden Muster und verwerfen dann die Trainingsdaten. Sobald das Modell erstellt ist, kann es schnell neue Daten vorhersagen.
Beispielalgorithmen: Entscheidungsbäume, Random Forest, Support Vector Machines (SVM), logistische Regression.
| Aspekt | Faule Lerner | Eifrige Lerner |
| Modellerstellung | Beim Training wird kein Modell erstellt, sondern es werden Daten gespeichert. | Verallgemeinert die Daten während des Trainings zu einem Modell. |
| Trainingszeit | Kurze Trainingszeit; es wird kein Modell erstellt. | Längere Trainingszeit; erstellt ein Modell auf der Grundlage von Daten. |
| Vorhersagezeit | Langsamere Vorhersagen, da die Daten zum Zeitpunkt der Abfrage verarbeitet werden. | Schnellere Vorhersagen, da das Modell bereits erstellt ist. |
| Speicherbedarf | Höherer Speicherbedarf; speichert den gesamten Datensatz. | Geringerer Speicherbedarf; speichert nur Modellparameter. |
| Beispielalgorithmen | k-NN, Case-based Reasoning | Entscheidungsbäume, Logistische Regression, Random Forest |
Tabelle: Faule Lerner vs. eifrige Lerner
Klassifizierungsalgorithmen
Lassen Sie uns nun einige häufig verwendete Klassifizierungsalgorithmen besprechen.
Logistische Regression
Die logistische Regression verwendet nur Wahrscheinlichkeiten zur Vorhersage des Labels in einer binären Klassifizierungsaufgabe. Im Gegensatz zur linearen Regression, die kontinuierliche Werte vorhersagt, sagt die logistische Regression Wahrscheinlichkeiten für zwei Klassen voraus, indem sie die Ausgaben mithilfe der logistischen Funktion (sigmoid) auf einen Bereich zwischen 0 und 1 abbildet. Sie wird häufig für Fälle mit binären Ergebnissen verwendet, wie Ja/Nein- oder 0/1-Szenarien.
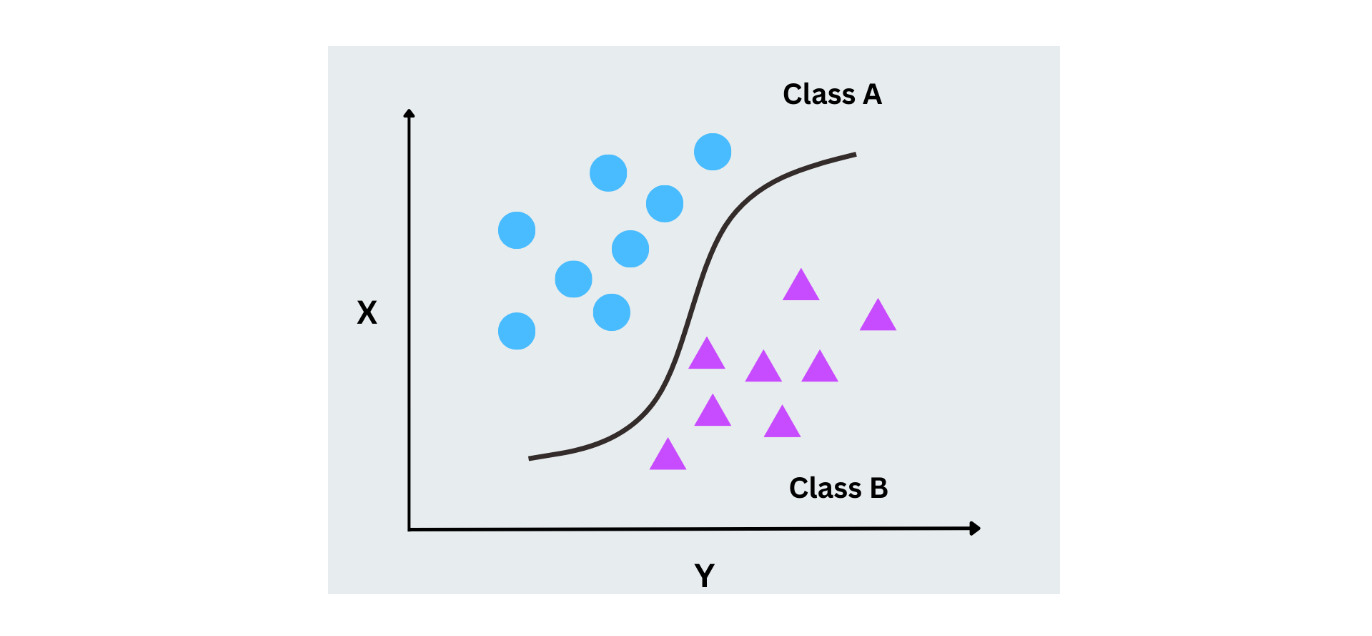 Abbildung - Logistische Regression working.png
Abbildung - Logistische Regression working.png
Abbildung - Logistische Regression im Einsatz
Entscheidungsbäume
Ein Entscheidungsbaum ist ein Modell, das die Daten auf der Grundlage von Merkmalswerten aufteilt und Verzweigungen für jede mögliche Entscheidung erstellt. Jeder Knoten steht für ein Merkmal, und die Zweige stehen für die Entscheidungen, die auf dem Wert dieses Merkmals basieren. Der Prozess wird so lange fortgesetzt, bis der Algorithmus über die Blattknoten der vorhergesagten Klasse entscheidet. Entscheidungsbäume sind einfach zu interpretieren und können sowohl binäre als auch Mehrklassen-Klassifizierungsaufgaben bewältigen.
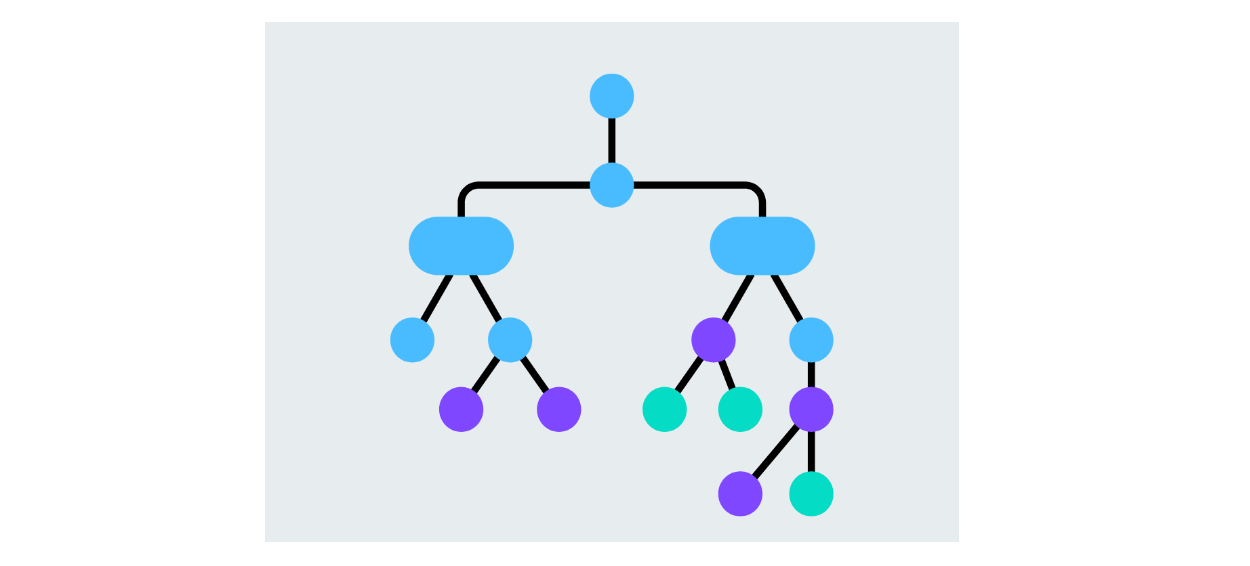 Abbildung- Entscheidungsbaumstruktur.png
Abbildung- Entscheidungsbaumstruktur.png
Abbildung: Struktur des Entscheidungsbaums
Random Forest
Der Random Forest verbessert die Entscheidungsbäume, indem er mehrere Bäume aufbaut und deren Vorhersagen kombiniert. Jeder Baum im Forest wird aus einer zufälligen Teilmenge der Daten und Merkmale gebildet. Die endgültige Vorhersage wird durch Mittelwertbildung der Ergebnisse (bei Regressionsaufgaben) oder durch Mehrheitsentscheidung (bei Klassifizierungsaufgaben) getroffen. Dadurch wird eine Überanpassung vermieden und die Genauigkeit erhöht.
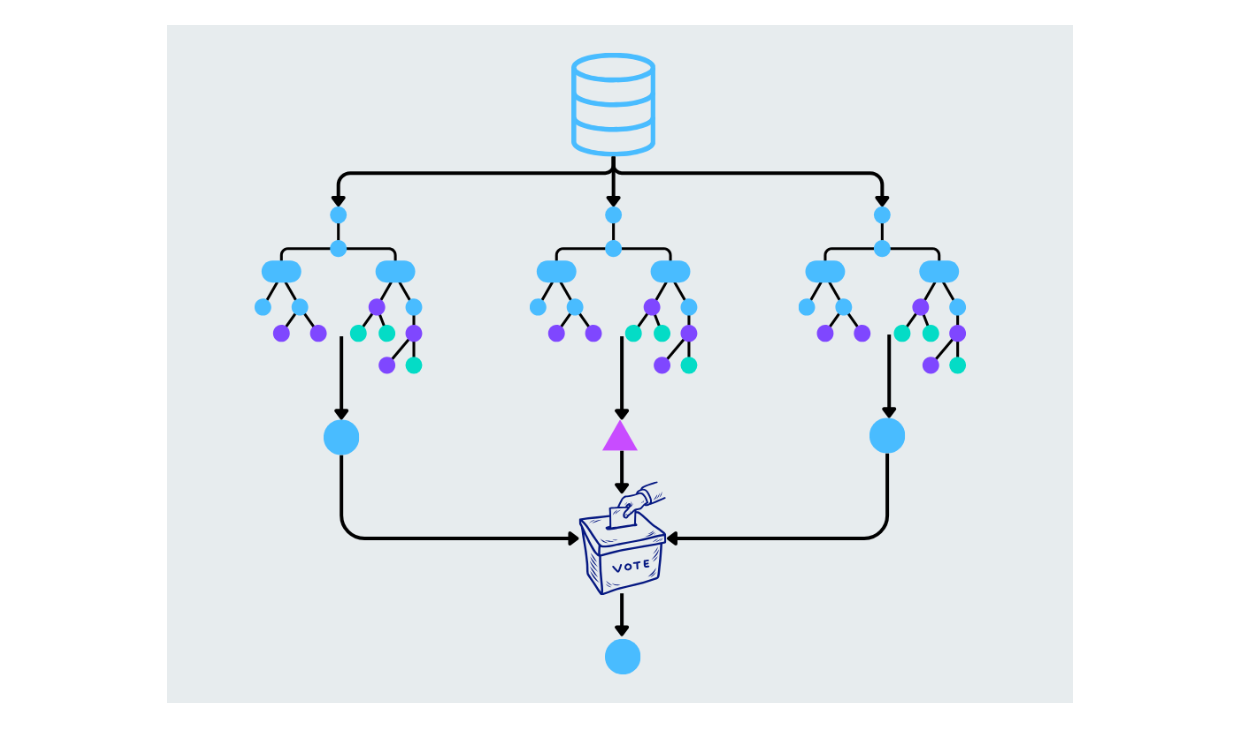 Abbildung- Random forest working.png
Abbildung- Random forest working.png
Abbildung: Random forest working
Support Vector Machines (SVM)
Support Vector Machines (SVM) arbeiten, indem sie die optimale Hyperebene finden, die Datenpunkte aus verschiedenen Klassen trennt. Diese Hyperebene ist eine Linie in zwei Dimensionen, aber SVMs können auch hochdimensionale Daten verarbeiten. Der Grundgedanke besteht darin, die Spanne zwischen den nächstgelegenen Datenpunkten jeder Klasse (Stützvektoren) zu maximieren. SVMs eignen sich gut für binäre und Multiklassen-Klassifizierungsprobleme, insbesondere wenn die Daten nicht linear trennbar sind.
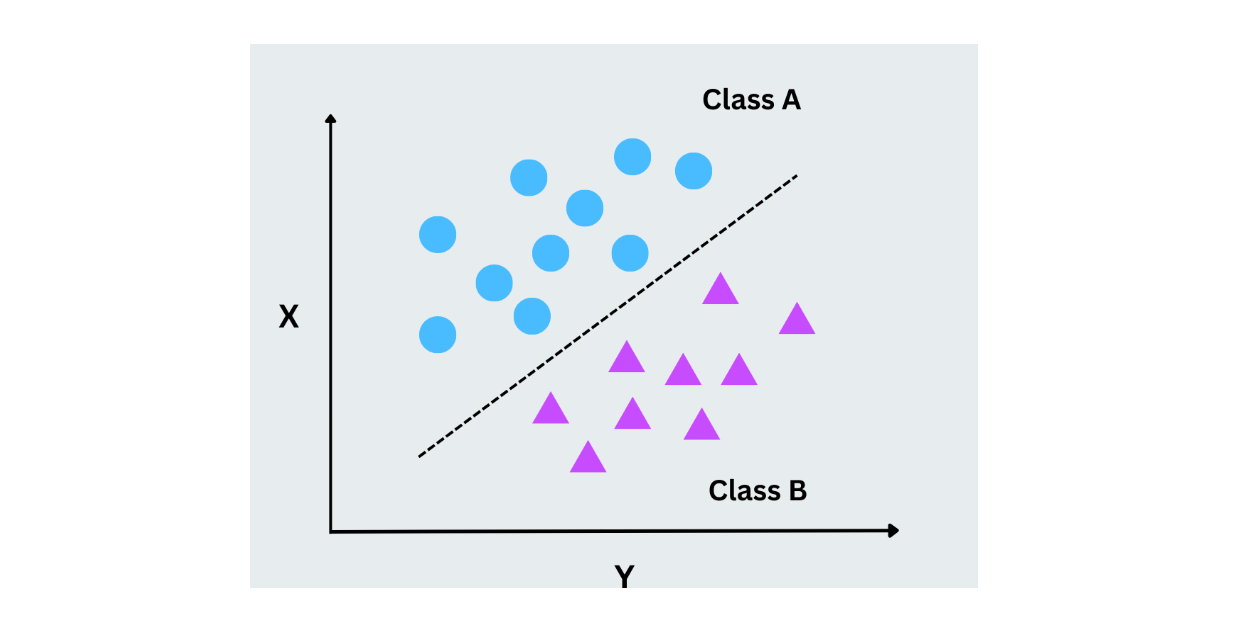 Abbildung- SVM working.png
Abbildung- SVM working.png
Abbildung - SVM im Einsatz
k-Nächste Nachbarn (k-NN)
Der k-NN-Algorithmus klassifiziert Datenpunkte auf der Grundlage der Klassen der k nächsten Nachbarn. Wenn ein neuer Datenpunkt eingeführt wird, betrachtet der Algorithmus die k nächstgelegenen Punkte (basierend auf einer Ähnlichkeitsmetrik wie dem euklidischen Abstand) und weist dem neuen Punkt die Mehrheitsklasse zu. Es handelt sich um einen einfachen, instanzbasierten Lernalgorithmus, der sich für kleinere Datensätze eignet.
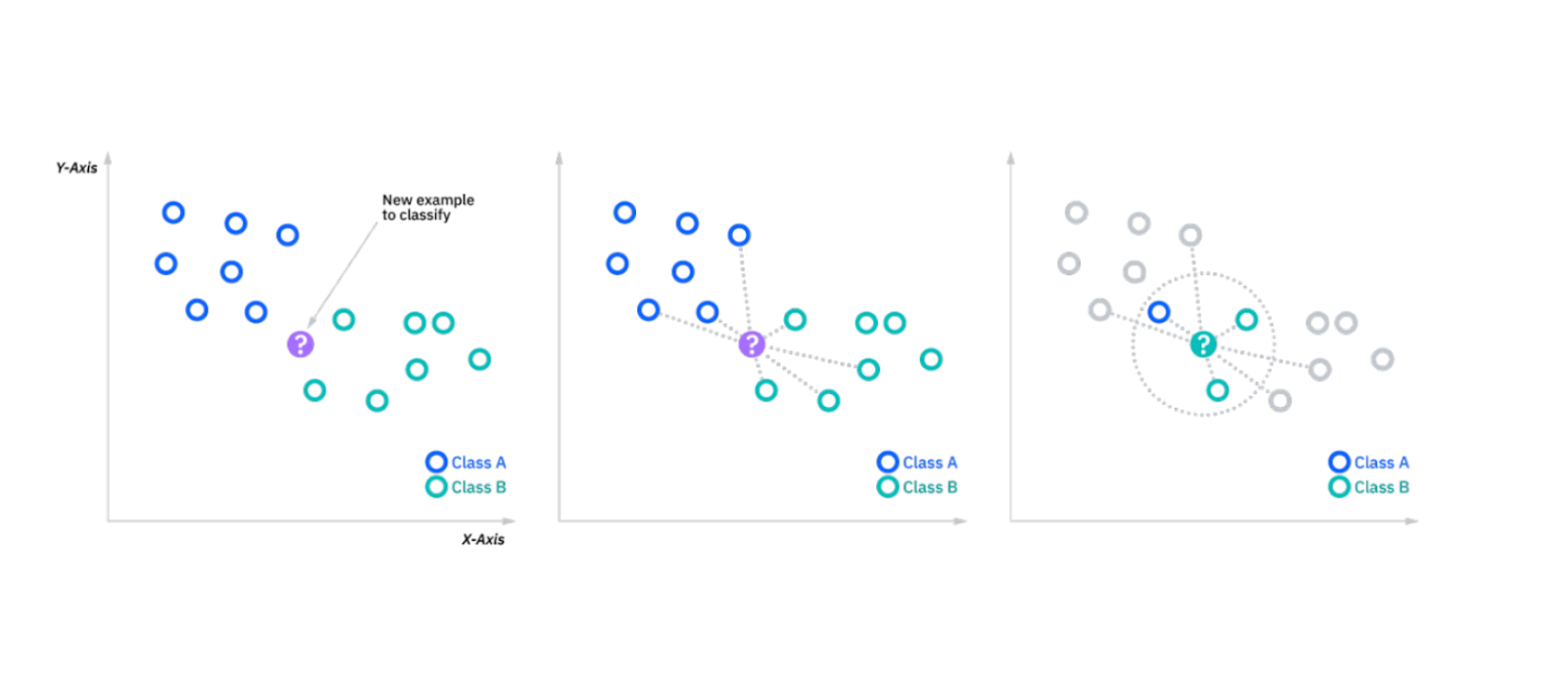 Abbildung - kNN-Algorithmus funktioniert.png
Abbildung - kNN-Algorithmus funktioniert.png
Abbildung: kNN-Algorithmus im Einsatz
Naive Bayes
Naive Bayes basiert auf dem Bayes-Theorem und geht davon aus, dass die Merkmale in den Daten unabhängig voneinander sind (daher der Begriff "naiv"). Trotz dieser Annahme erbringt es gute Leistungen bei verschiedenen realen Aufgaben, insbesondere wenn die Daten kategoriale Merkmale aufweisen. Es funktioniert, indem es die Wahrscheinlichkeit jeder Klasse angesichts der Eingabe berechnet und die Klasse mit der höchsten Wahrscheinlichkeit zuordnet.
P(C|X) = P(X|C) . P(C)P(X))
Dabei ist P(C∣X) die posteriore Wahrscheinlichkeit der Klasse bei gegebener Eingabe, P(X∣C) ist die Wahrscheinlichkeit der Eingabe bei gegebener Klasse, P(C) ist die vorherige Wahrscheinlichkeit der Klasse und P(X) ist die Wahrscheinlichkeit der Eingabe. Naive Bayes wählt auf der Grundlage der beobachteten Merkmale die Klasse mit der höchsten Posteriorwahrscheinlichkeit für die Klassifizierung aus.
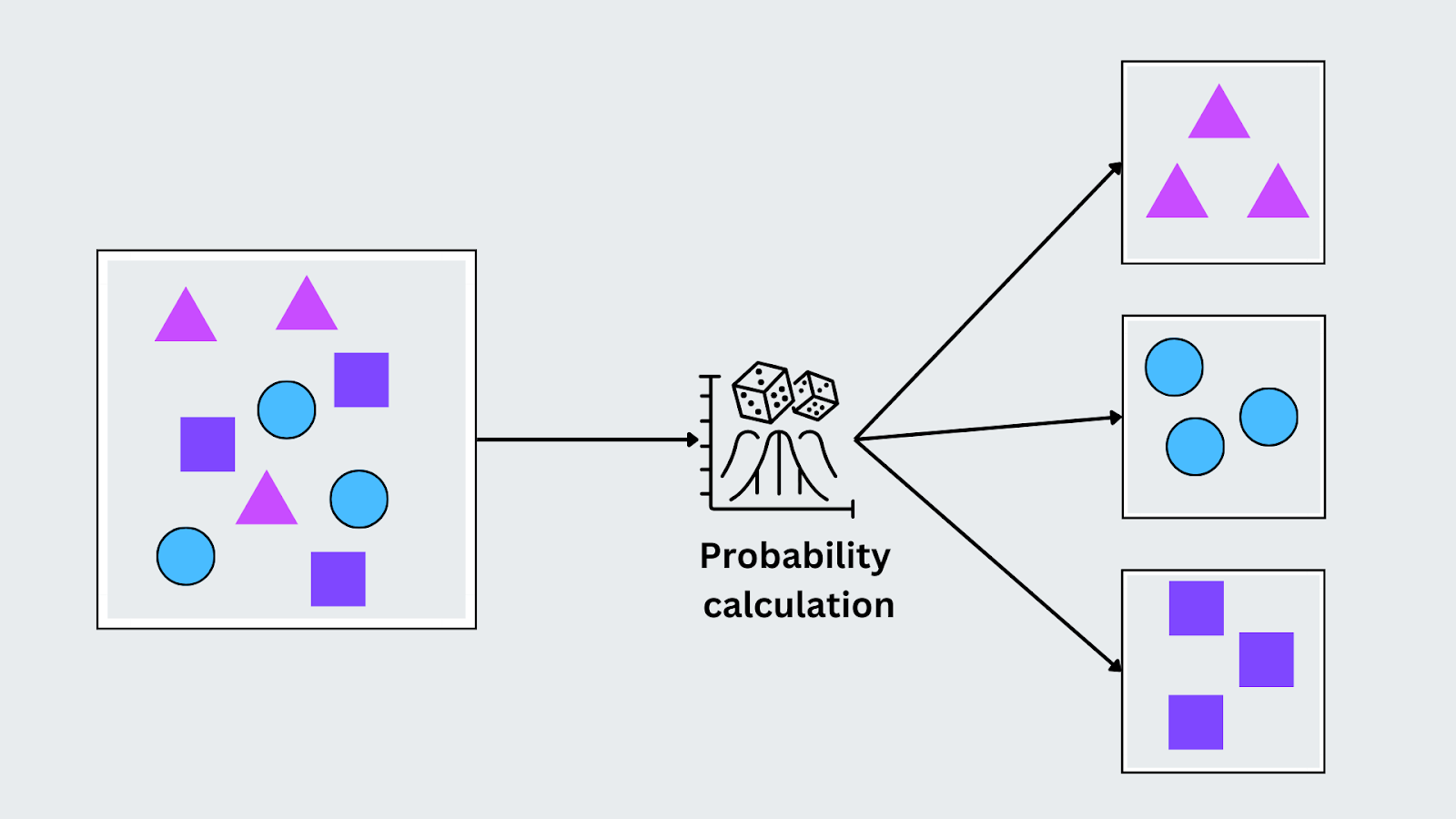 Abbildung- Naive Bayes Algorithmus funktioniert.png
Abbildung- Naive Bayes Algorithmus funktioniert.png
Abbildung: Naive-Bayes-Algorithmus im Einsatz
Bewertungsmetriken in der Klassifikation
Genauigkeit
Die Genauigkeit ist die einfachste Metrik und misst, wie oft die Vorhersagen des Modells richtig sind. Sie wird ermittelt, indem die Anzahl der korrekt vorhergesagten Fälle durch die Gesamtzahl der Fälle geteilt wird.
Formel:
Genauigkeit = (Wahr-Positive + Wahr-Negative)/Gesamtzahl der Instanzen
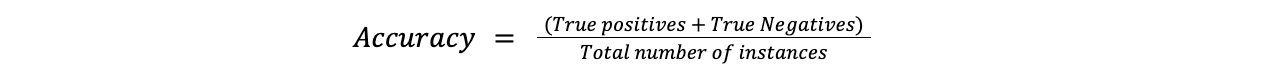 accuracy.png
accuracy.png
Genauigkeit
Die Präzision misst, wie viele der vorhergesagten positiven Instanzen tatsächlich positiv sind. Präzision ist in Situationen wichtig, in denen falsch positive Vorhersagen kostspielig sind. Wenn zum Beispiel eine normale Transaktion bei der Betrugserkennung als betrügerisch eingestuft wird, kann dies zu Unzufriedenheit beim Kunden führen.
Formel:
Präzision = Richtig positive Ergebnisse/(Richtig positive Ergebnisse + Falsch positive Ergebnisse)
 präzision.png
präzision.png
Rückruf
Recall misst den Anteil der positiven Fälle, die korrekt als positiv identifiziert wurden. Die Trefferquote ist in Fällen nützlich, in denen das Verpassen eines positiven Falles kostspielig ist. Beispielsweise ist das Verpassen einer Diagnose (falsch negativ) bei der Erkennung von Krankheiten viel problematischer als ein falscher Alarm.
Formel:
Rückruf = Richtig positive Ergebnisse/(Richtig positive Ergebnisse + Falsch negative Ergebnisse)
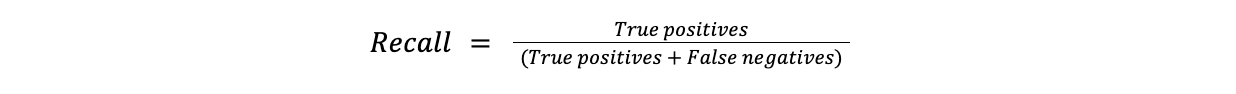 recall.png
recall.png
F1-Score
Der F1-Score ist das harmonische Mittel aus Precision und Recall. Er ist nützlich, wenn ein Gleichgewicht zwischen Präzision und Recall gefunden werden muss, insbesondere wenn eine der beiden Größen wichtiger ist als die andere.
Formel:
F1Score = 2x(Präzision x Recall)/(Präzision + Recall)
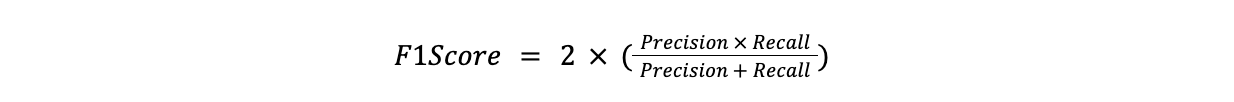 FI score.png
FI score.png
Real-World Use Cases of Classification
Klassifizierungsmodelle sind in verschiedenen Branchen weit verbreitet, um Probleme aus der Praxis zu lösen. Hier sind einige praktische Beispiele:
Medizinische Diagnose: Modelle des maschinellen Lernens helfen Ärzten bei der Klassifizierung von Patientendaten wie "Krankheit" oder "keine Krankheit". Beispielsweise werden Modelle verwendet, um anhand von Krankenakten vorherzusagen, ob ein Patient Diabetes hat.
Stimmungsanalyse: Unternehmen nutzen die Stimmungsanalyse, um Kundenfeedback zu verstehen. Ein Modell kann beispielsweise Produktrezensionen analysieren und sie als positiv, negativ oder neutral einstufen, was den Unternehmen hilft, ihr Angebot auf der Grundlage der Kundenstimmung zu verbessern.
Betrugserkennung: Banken und Finanzinstitute verwenden Klassifizierungsmodelle, um betrügerische Transaktionen zu erkennen. Das Modell lernt Muster aus Transaktionsdaten und klassifiziert jede Transaktion als "betrügerisch" oder "legitim", um finanzielle Verluste zu verhindern.
Objekterkennung in Bildern: Modelle zur Objekterkennung identifizieren bestimmte Bildelemente in Branchen wie Fertigung und Sicherheit. So kann ein Modell beispielsweise Bilder von Produkten auf einem Fließband klassifizieren und sicherstellen, dass nur korrekt zusammengesetzte Produkte die Inspektion passieren.
Gesichtserkennung: Gesichtserkennungssysteme werden im Bereich Sicherheit und Authentifizierung eingesetzt. Diese Modelle klassifizieren Bilder von Gesichtern, um die Identität einer Person zu identifizieren oder zu überprüfen, was häufig beim Entsperren von Smartphones, bei digitalen Anwesenheitssystemen oder bei Sicherheitskontrollen an Flughäfen verwendet wird.
Spracherkennung: Spracherkennungsmodelle wandeln gesprochene Sprache in Text oder Befehle um. Virtuelle Assistenten wie Siri oder Alexa klassifizieren beispielsweise gesprochene Wörter in Befehle, so dass die Benutzer mit Geräten per Sprache interagieren können.
Medizinische Diagnosetests: Modelle für maschinelles Lernen helfen bei der Interpretation von Diagnosetests wie Röntgenaufnahmen oder MRT-Scans. Sie klassifizieren medizinische Bilder als "normal" oder "abnormal" und helfen Radiologen, schnellere und genauere Diagnosen zu stellen.
Vorhersage des Kundenverhaltens: E-Commerce-Plattformen verwenden Klassifizierungsmodelle, um das Kundenverhalten vorherzusagen. Diese Modelle klassifizieren Nutzer als "wahrscheinlich kaufend" oder "unwahrscheinlich kaufend", um personalisierte Marketing- und Produktempfehlungen zu geben.
Produktkategorisierung: Einzelhändler nutzen maschinelles Lernen, um Produkte wie "Elektronik", "Kleidung" oder "Haushaltswaren" anhand ihrer Beschreibungen automatisch zu klassifizieren. Dadurch wird die Bestandsverwaltung rationalisiert und die Sucherfahrung der Kunden verbessert.
Malware-Klassifizierung: Im Bereich der Cybersicherheit erkennen und klassifizieren Klassifizierungsmodelle Malware. Durch die Analyse von Mustern im Softwareverhalten klassifizieren diese Modelle Programme als "sicher" oder "bösartig", um Systeme vor Cyberbedrohungen zu schützen.
Allgemeine Herausforderungen bei der Klassifizierung
Bei der Erstellung von Klassifizierungsmodellen können verschiedene Herausforderungen auftreten, die die Leistung des Modells beeinträchtigen. Hier sind drei häufige Herausforderungen:
Überanpassung
[Überanpassung] (https://zilliz.com/learn/understanding-regularization-in-nueral-networks) bedeutet, dass ein Modell in den Trainingsdaten gut funktioniert, aber nicht auf neue, ungesehene Daten verallgemeinert werden kann. Dies geschieht, wenn das Modell zu komplex wird und anfängt, Rauschen oder spezifische Details des Trainingsdatensatzes zu erfassen, anstatt die zugrunde liegenden Muster.
Unausgewogenheit der Daten
Von einem Datenungleichgewicht spricht man, wenn eine Klasse die anderen deutlich überwiegt. Bei der Erkennung von Betrug machen betrügerische Transaktionen beispielsweise nur 1 % der Daten aus, was dazu führt, dass das Modell stark auf die Mehrheitsklasse ausgerichtet ist. Dies kann zu einer schlechten Erkennung der Minderheitenklasse führen.
Rauschen in Daten
Rauschen bezieht sich auf zufällige Fehler oder irrelevante Informationen in den Daten, die das Modell verwirren können. Zu den verrauschten Daten können falsch beschriftete Beispiele, Ausreißer oder irrelevante Merkmale gehören, die nicht zur Klassifizierung beitragen. Das Vorhandensein von Rauschen kann die Leistung des Modells verringern und die Erkennung von Mustern erschweren.
Klassifizierung vs. Regression
Klassifizierung und Regression sind beides Algorithmen des überwachten Lernens, werden aber für unterschiedliche Aufgaben verwendet. Nachstehend finden Sie einen Vergleich zwischen Klassifizierung und Regression anhand verschiedener Aspekte:
| Aspekt | Klassifikation | Regression |
| Zweck | Sagt diskrete Bezeichnungen oder Kategorien voraus. | Sagt kontinuierliche numerische Werte voraus. |
| Ausgabe | Kategorisch: Klassen wie "Spam" oder "kein Spam". | Kontinuierlich: Werte wie "Preis" oder "Temperatur". |
| Beispielaufgabe | Klassifizierung von E-Mails als "Spam" oder "kein Spam". | Vorhersage von Hauspreisen auf der Grundlage ihrer Merkmale. |
| Verwendete Algorithmen | Logistische Regression, Entscheidungsbäume, Random Forest, etc. | Lineare Regression, Ridge-Regression, Polynomiale Regression, usw. |
| Bewertungsmetriken | Genauigkeit, Präzision, Rückruf, F1-Score, ROC-AUC, usw. | Mittlerer quadratischer Fehler (MSE), R-Quadrat, mittlerer absoluter Fehler (MAE). |
| Art der Zielvariable | Das Ziel ist kategorisch (z. B. Klassenbezeichnungen). | Ziel ist kontinuierlich (z. B. reelle Zahlen). |
| Ausgabegrenzen | Hat feste Klassengrenzen (z. B. 0 oder 1 für binär). | Keine feste Grenze; die Ausgabe ist ein Bereich von reellen Zahlen. |
| Anwendungsfälle in der Praxis | Spam-Erkennung, Betrugserkennung, Krankheitsklassifizierung. | Vorhersage von Verkäufen, Aktienkursen und Wettervorhersagen. |
| Es kann sowohl binäre als auch Multiklassen-Ausgaben verarbeiten. | Normalerweise ist es einfacher, wenn ein kontinuierlicher Wert vorhergesagt wird. |
Tabelle: Klassifizierung vs. Regression
Wie hilft Milvus bei Klassifizierungsaufgaben?
Mit wachsendem Datenvolumen und zunehmender Komplexität können herkömmliche Methoden zur Verwaltung und Abfrage großer Datensätze langsam und ineffizient werden. Hier spielt Zilliz mit seiner leistungsstarken Open-Source-Vektordatenbank [Milvus] (https://zilliz.com/what-is-milvus) eine entscheidende Rolle.
Klassifizierungsaufgaben wie Bilderkennung, Objekterkennung, Videoähnlichkeitssuche, Spam-Erkennung und Empfehlungssysteme erfordern oft die Verarbeitung hochdimensionaler Repräsentationen von unstrukturierten Daten, wie Texteinbettungen, Bildmerkmale oder Audio-Vektoren. Milvus wurde speziell für die effiziente Verwaltung und Suche in diesen großen Mengen von Vektordaten entwickelt.
Vorteile von Milvus für die Klassifizierung
Handhabung hochdimensionaler Daten: Bei der Klassifizierung stützen sich die Modelle häufig auf vektorisierte Daten (z. B. Worteinbettungen oder Bildmerkmalsvektoren), um Vorhersagen zu treffen. Milvus ist für die Speicherung und Verwaltung dieser Vektoren optimiert, um beim Modelltraining und bei der Inferenz schnell auf große Datensätze zugreifen zu können.
Schnelle Ähnlichkeitssuche: Klassifizierungsmodelle müssen häufig die am besten übereinstimmenden Datenpunkte in einem Datensatz finden. Milvus beschleunigt diesen Prozess, indem es eine schnelle Ähnlichkeitssuche auf Vektordaten durchführt, wodurch die Klassifizierung neuer Eingaben auf der Grundlage ihrer nächsten Nachbarn erleichtert wird.
Skalierbarkeit für große Datensätze: Milvus stellt sicher, dass die Leistung auch bei wachsenden Klassifizierungsdatensätzen schnell und effizient bleibt. Milvus lässt sich nahtlos skalieren, damit die Klassifizierungsaufgaben auch bei riesigen Datenmengen reibungslos ablaufen, egal ob es sich um Millionen von Produktvektoren, Bildeinbettungen oder Tausende von Bildeinbettungen handelt.
Schlussfolgerung
Klassifizierung ist eine maschinelle Lerntechnik zur Vorhersage von Etiketten oder Kategorien für Daten in verschiedenen realen Anwendungen, von der Erkennung von Betrug bis zur Erkennung von Bildern. Der erfolgreiche Aufbau und Einsatz von Klassifizierungsmodellen erfordert den Umgang mit großen Datenmengen, oft hochdimensionalen Vektoren. Milvus bietet effiziente Speicherung, schnellen Abruf und Skalierbarkeit für Vektordaten. Es steigert die Leistung von Klassifizierungsaufgaben durch schnelle Ähnlichkeitssuche und skaliert reibungslos mit wachsenden Datensätzen. Mit Milvus können Entwickler die Herausforderungen umfangreicher Klassifizierungsaufgaben problemlos bewältigen, was es zu einem leistungsstarken Werkzeug im Bereich des maschinellen Lernens macht.
FAQs zur Klassifizierung
Was ist Klassifizierung beim maschinellen Lernen?
Klassifizierung beim maschinellen Lernen ist der Prozess der Vorhersage einer Kategorie oder Bezeichnung für eine gegebene Eingabe auf der Grundlage ihrer Merkmale. Ein Modell wird mit markierten Daten trainiert, um Muster zu lernen und dann neue, ungesehene Daten in vordefinierte Klassen wie "Spam" oder "kein Spam" zu klassifizieren.
- Wie unterscheidet sich ein Klassifizierungsalgorithmus von einer Regression?
Klassifizierungsalgorithmen sagen kategorische Ergebnisse (wie Klassen oder Bezeichnungen) voraus, während Regressionsalgorithmen kontinuierliche numerische Werte vorhersagen. So kann beispielsweise durch Klassifizierung festgestellt werden, ob eine E-Mail Spam ist, während durch Regression der Preis eines Hauses vorhergesagt werden kann.
- Warum ist die Datenaufbereitung bei Klassifizierungsaufgaben wichtig?
Die Datenvorbereitung stellt sicher, dass die Eingabedaten sauber, strukturiert und für die Verarbeitung durch das Modell bereit sind. Sie behandelt fehlende Werte, normalisiert die Daten und wählt die relevantesten Merkmale aus. Eine ordnungsgemäße Vorbereitung verbessert die Genauigkeit und Leistung des Modells.
- Wie hilft Milvus bei Klassifizierungsaufgaben?
Milvus ist eine Open-Source-Vektordatenbank, die hochdimensionale Daten, wie Bild- oder Texteinbettungen, effizient speichert und durchsucht. Sie beschleunigt die Klassifizierung durch ihre effiziente Ähnlichkeitssuche, die den Umgang mit großen Datensätzen bei Aufgaben wie Bilderkennung und Empfehlungssystemen erleichtert.
Was sind häufige Herausforderungen bei der Klassifizierung, und wie können sie bewältigt werden?
Zu den üblichen Herausforderungen gehören Überanpassung, Datenungleichgewicht und Rauschen in den Daten. Diese können mit Techniken wie Regularisierung, Resampling-Methoden (z. B. SMOTE), Rauschunterdrückungsstrategien und einer skalierbaren Infrastruktur wie Milvus zur effizienten Verwaltung großer Datenmengen angegangen werden.
Verwandte Ressourcen
Was ist Objekterkennung? Ein umfassender Leitfaden](https://zilliz.com/learn/what-is-object-detection)
Was ist der K-Nächste-Nachbarn-Algorithmus (KNN) beim maschinellen Lernen?](https://zilliz.com/blog/k-nearest-neighbor-algorithm-for-machine-learning)
Approximate Nearest Neighbors - Oh ja (ärgerlich)](https://zilliz.com/learn/approximate-nearest-neighbor-oh-yeah-ANNOY)
Was sind Vektordatenbanken und wie funktionieren sie? ](https://zilliz.com/learn/what-is-vector-database)
Was ist RAG? ](https://zilliz.com/learn/Retrieval-Augmented-Generation)
Computer Vision verstehen ](https://zilliz.com/learn/what-is-computer-vision)
- Was ist Klassifizierung?
- Wie funktioniert die Klassifizierung?
- Arten der Klassifizierung
- Lernende in Klassifizierungsalgorithmen
- Klassifizierungsalgorithmen
- Bewertungsmetriken in der Klassifikation
- Real-World Use Cases of Classification
- Allgemeine Herausforderungen bei der Klassifizierung
- Klassifizierung vs. Regression
- Wie hilft Milvus bei Klassifizierungsaufgaben?
- Schlussfolgerung
- FAQs zur Klassifizierung
- Verwandte Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren