




Skalarquantisierung und Produktquantisierung
Im vorherigen Tutorial haben wir uns zwei der grundlegendsten Indexierungsalgorithmen angesehen – Flat Indexing und Inverted File (IVF). Flat Indexing ist die einfachste und naivste Strategie für die Vektorsuche, kann aber überraschend gut funktionieren, wenn die Gesamtgröße des Datensatzes klein ist (ein paar tausend Vektoren) und/oder wenn du eine GPU für Abfragen verwendest. IVF hingegen ist in hohem Maße erweiterbar, um sehr erweiterbar zu sein, und funktioniert gleichzeitig gut mit anderen Indexierungsstrategien.
In diesem Tutorial bauen wir auf diesem Wissen auf, indem wir tiefer in Quantisierungstechniken eintauchen – insbesondere in skalare Quantisierung (auch Integer-Quantisierung genannt) und Produktquantisierung. Wir werden unsere eigenen Algorithmen für skalare und Produktquantisierung in Python implementieren.
Quantisierung vs. Dimensionsreduktion
Wie in einem früheren Tutorial zur Vektorähnlichkeitssuche erwähnt, ist Quantisierung eine Technik zur Reduzierung der Gesamtgröße der Datenbank, indem die gesamte Präzision der Vektoren reduziert wird. Beachte, dass sich dies stark von der Dimensionsreduktion (PCA, LDA usw.) unterscheidet, die versucht, die Länge der Vektoren zu reduzieren:
>>> vector.size # length of our original vector
128
>>> quantized_vector.size # length of our quantized vector
128
>>> reduced_vector.size # length of our reduced vector
16
Dimensionsreduktions-Methoden wie PCA verwenden lineare Algebra, um die Eingabedaten in einen niedriger dimensionalen Raum zu projizieren. Ohne hier zu tief in die Mathematik einzusteigen, solltest du wissen, dass diese Methoden im Allgemeinen nicht als primäre Indexierungsstrategie verwendet werden, da sie tendenziell Einschränkungen hinsichtlich der Verteilung der Daten haben. PCA funktioniert beispielsweise am besten bei Daten, die in unabhängige, gaußverteilte Komponenten getrennt werden können.
Quantisierung hingegen trifft keine Annahmen über die Verteilung der Daten – vielmehr betrachtet sie jede Dimension (oder Gruppe von Dimensionen) separat und versucht, jeden Wert in einen von vielen diskreten Buckets „einzusortieren“. Anstatt eine Flat Search über alle ursprünglichen Vektoren durchzuführen, können wir stattdessen eine Flat Search über die quantisierten Vektoren durchführen – dies kann zu geringerem Speicherverbrauch sowie zu einer erheblichen Beschleunigung führen.
Skalare Quantisierung
Skalare Quantisierung ist eine wichtige Datenkompressionstechnik, die Gleitkommawerte in niedrigdimensionale Ganzzahlen umwandelt. Schauen wir uns ein Beispiel an:
>>> vector.dtype # data type of our original vector
dtype('float64')
>>> quantized_vector.dtype
dtype('int8')
>>> reduced_vector.dtype
dtype('float64')
Aus dem obigen Beispiel können wir sehen, dass die skalare Quantisierung die Gesamtgröße unserer Vektoren (und der Vektordatenbank) um satte 8x reduziert hat. Schön.
Wie funktioniert skalare Quantisierung?
Wie genau funktioniert skalare Quantisierung? Schauen wir uns zunächst den Indexierungsprozess an, d. h. die Umwandlung von Gleitkomma-Vektoren in Integer-Vektoren. Für jede Vektordimension nimmt die skalare Quantisierung den Maximal- und Minimalwert dieser bestimmten Dimension, wie er in der gesamten Datenbank vorkommt, und teilt diese Dimension gleichmäßig über ihren gesamten Bereich in Bins auf.
Versuchen wir, das in Code zu schreiben. Zuerst generieren wir einen Datensatz aus tausend 128D-Gleitkomma-Vektoren, die aus einer multivariaten Verteilung gezogen wurden. Da dies ein Spielzeugbeispiel ist, ziehe ich Stichproben aus einer Gaußverteilung; in der Praxis sind tatsächliche Embeddings selten gaußverteilt, es sei denn, dies wurde beim Training des Modells als Einschränkung hinzugefügt (wie etwa bei variational autoencoders):
>>> import numpy as np
>>> dataset = np.random.normal(size=(1000, 128))
Dieser Datensatz dient als unsere Dummy-Daten für die Verwendung in dieser Implementierung der skalaren Quantisierung. Bestimmen wir nun die Maximal- und Minimalwerte jeder Dimension des Vektors und speichern sie in einer Matrix namens ranges:
>>> ranges = np.vstack((np.min(dataset, axis=0), np.max(dataset, axis=0)))
Dir wird auffallen, dass die mins und maxes hier über alle Dimensionen hinweg für dieses Spielzeugbeispiel ziemlich einheitlich sind, da die Eingabedaten aus Gauß-Verteilungen mit Mittelwert null und Einheitsvarianz gezogen wurden – darum musst du dir vorerst keine Sorgen machen, denn der gesamte Code hier lässt sich auch auf echte Daten übertragen. Wir haben nun den Minimal- und Maximalwert jeder Vektordimension im gesamten Datensatz. Damit können wir nun den Startwert und die Schrittgröße für jede Dimension bestimmen. Der Startwert ist einfach der Minimalwert, und die Schrittgröße wird durch die Anzahl der diskreten Bins im Integer-Typ bestimmt, den wir verwenden werden. In diesem Fall verwenden wir 8-Bit-Unsigned-Integer uint8_t für insgesamt 256 Bins:
>>> starts = ranges[0,:]
>>> steps = (ranges[1,:] - ranges[0,:]) / 255
Das ist die gesamte Einrichtung, die benötigt wird. Die eigentliche Quantisierung erfolgt dann, indem alle Startwerte für jede Dimension (starts) subtrahiert und der resultierende Wert durch die Schrittgröße (steps) geteilt wird:
>>> dataset_quantized = np.uint8((dataset - starts) / steps)
>>> dataset_quantized
array([[136, 58, 156, ..., 153, 182, 30],
[210, 66, 175, ..., 68, 146, 33],
[100, 136, 148, ..., 142, 86, 108],
...,
[133, 146, 146, ..., 137, 209, 144],
[ 63, 131, 96, ..., 174, 174, 105],
[159, 78, 204, ..., 95, 87, 146]], dtype=uint8)
Wir können auch die mins und maxes des quantisierten Datensatzes überprüfen:
>>> np.min(dataset_quantized, axis=0)
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=uint8)
>>> np.max(dataset_quantized, axis=1)
array([255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 254, 254, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 254, 255, 255, 255, 255, 254, 255, 255, 254,
254, 255, 255, 254, 255, 255, 255, 254, 255, 255, 255, 255, 255,
255, 255, 255, 255, 254, 255, 255, 255, 255, 255, 254, 255, 255,
255, 254, 255, 255, 255, 255, 255, 254, 254, 255, 255, 255, 255,
255, 255, 255, 254, 255, 255, 255, 255, 254, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255], dtype=uint8)
Beachte, wie wir den vollständigen uint8_t-Bereich von [0,255] für jede Dimension verwendet haben (einige der Maximalwerte sind 254 statt 255 aufgrund von Gleitkomma-Ungenauigkeiten).
Fassen wir nun alles in einer ScalarQuantizer-Klasse zusammen:
import numpy as np
class ScalarQuantizer:
def __init__(self):
self._dataset = None
def create(self):
"""Calculates and stores SQ parameters based on the input dataset."""
self._dtype = dataset.dtype # original dtype
self._starts = np.min(dataset, axis=1)
self._steps = (np.max(dataset, axis=1) - self._starts) / 255
# the internal dataset uses `uint8_t` quantization
self._dataset = np.uint8((dataset - self._starts) / self._steps)
def quantize(self, vector):
"""Quantizes the input vector based on SQ parameters"""
return np.uint8((vector - self._starts) / self._steps)
def restore(self, vector):
"""Restores the original vector using SQ parameters."""
return (vector * self._steps) + self._starts
@property
def dataset(self):
if self._dataset:
return self._dataset
raise ValueError("Call ScalarQuantizer.create() first")
>>> dataset = np.random.normal(size=(1000, 128))
>>> quantizer = ScalarQuantizer(dataset)
Und das war's mit der skalaren Quantisierung! Die Umwandlungsfunktion für skalare Quantisierung kann statt einer linearen Funktion, wie wir sie im obigen Beispiel haben, in eine quadratische oder exponentielle Funktion geändert werden, aber die allgemeine Idee bleibt dieselbe – den gesamten Raum jeder Dimension in diskrete Bins aufzuteilen, um den gesamten Speicherbedarf der Vektordaten zu reduzieren.
Produktquantisierung
Produktquantisierung (PQ) ist eine weitere Datenkompressionstechnik, die im Vergleich zur skalaren Quantisierung wesentlich leistungsfähiger und flexibler für die Quantisierung von Vektoren ist. Ein großer Nachteil der skalaren Quantisierung besteht darin, dass sie die Verteilung der Werte in jeder Dimension nicht berücksichtigt. Stellen wir uns zum Beispiel vor, wir haben einen Datensatz mit den folgenden 2-dimensionalen Vektoren:
array([[ 9.19, 1.55],
[ 0.12, 1.55],
[ 0.40, 0.78],
[-0.04, 0.31],
[ 0.81, -2.07],
[ 0.29, 0.82],
[ 0.05, 0.96],
[ 0.12, -1.10]])
Wenn wir uns entscheiden, diese Vektoren in 3-Bit-Ganzzahlen (Bereich [0,7]) zu quantisieren, werden 6 der Bins für die 0. Dimension vollständig ungenutzt bleiben! Offensichtlich muss es einen besseren Weg geben, Quantisierung durchzuführen, insbesondere wenn eine der Dimensionen eine nicht gleichmäßige Verteilung aufweist. Hier kann die Produktquantisierung zur Rettung kommen.
Wie funktioniert Produktquantisierung?
Die Hauptidee hinter der Produktquantisierung besteht darin, einen hochdimensionalen Vektor algorithmisch in einen niedrigerdimensionalen Unterraum aufzuteilen, wobei die Dimension des Unterraums mehreren Dimensionen im ursprünglichen hochdimensionalen Vektor entspricht. Dieser Reduktionsprozess wird typischerweise mit einem speziellen Algorithmus namens Lloyd's algorithm durchgeführt, einem Quantisierer, der effektiv dem k-Means-Clustering entspricht. Wie bei der skalaren Quantisierung ergibt jeder ursprüngliche Vektor nach der Quantisierung einen Vektor aus Ganzzahlen, und jede Ganzzahl entspricht einem bestimmten Zentroid.
Das mag komplex klingen, wird aber viel leichter verständlich, wenn wir es aus algorithmischer Perspektive aufschlüsseln. Gehen wir zunächst die Indexierung durch:
- Bei einem Datensatz mit insgesamt
NVektoren teilen wir zunächst jeden Vektor inMTeilvektoren auf (auch als Unterraum bezeichnet). Diese Teilvektoren müssen nicht unbedingt die gleiche Länge haben, in der Praxis ist das jedoch fast immer der Fall. - Anschließend verwenden wir k-Means (oder einen anderen Clustering-Algorithmus) für alle Teilvektoren im Datensatz. Dadurch erhalten wir eine Sammlung von
KZentroiden für jeden Unterraum, denen jeweils eine eigene eindeutige ID zugewiesen wird. - Nachdem alle Zentroide berechnet wurden, ersetzen wir alle Teilvektoren im ursprünglichen Datensatz durch die ID ihres nächstgelegenen Zentroids.
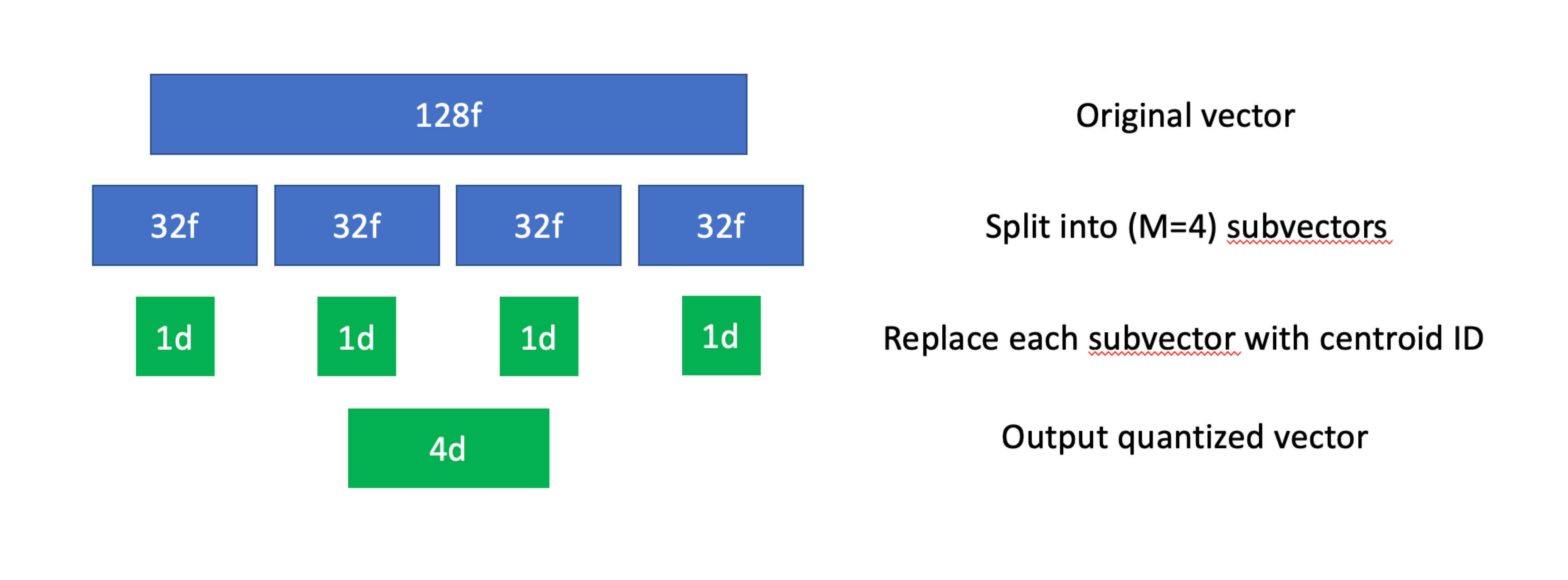 Produktquantisierung, visualisiert.
Produktquantisierung, visualisiert.
PQ kann sowohl den Speicherverbrauch reduzieren als auch die Geschwindigkeiten der Suche nach nächsten Nachbarn deutlich erhöhen, auf Kosten eines kleinen Genauigkeitsverlusts. Der Kompromiss hängt von den verwendeten Parametern ab – mehr Zentroide und Teilvektoren verbessern die Suchgenauigkeit, führen aber nicht zu ebenso starker Kompression oder Beschleunigung.
Gehen wir eine sehr einfache PQ-Implementierung durch. Wie im vorherigen Beispiel zur skalaren Quantisierung werden wir die Vektoren in 8-Bit-Ganzzahlen ohne Vorzeichen (uint8_t) reduzieren, unter Verwendung von M = 16 und K = 256, d. h. jeder 128D-Vektor wird in 16 Teilvektoren der Größe 8 aufgeteilt, wobei jeder Teilvektor anschließend in einen von 256 Buckets quantisiert wird.
>>> (M, K) = (16, 256)
Wir beginnen damit, einen Toy-Datensatz zu erzeugen, wie wir es im Beispiel zur skalaren Quantisierung getan haben:
>>> import numpy as np
>>> dataset = np.random.normal(size=(1000, 128))
Mit dem Datensatz zur Hand spalten wir den ersten Satz von Teilvektoren ab:
>>> sublen = dataset.shape[1] // M
>>> subspace = dataset[:,0:sublen] # this is the 0th subspace
>>> subspace.shape
(1000, 8)
Wie bei IVF verwenden wir die kmeans2-Implementierung von scipy, um Zentroide zu bestimmen:
>>> from scipy.cluster.vq import kmeans2
>>> (centroids, assignments) = kmeans2(subspace, K, iter=32)
Die scipy-k-means-Implementierung gibt die Zentroid-Indizes im Format int32_t zurück, daher führen wir eine schnelle Konvertierung zu uint8_t durch, um die Sache abzuschließen:
>>> quantized = np.uint8(assignments)
Dieser Prozess wird für jeden Unterraum wiederholt, bis wir alle Vektoren quantisiert haben.
Wie schon bei der skalaren Quantisierung fassen wir auch hier alles in einer Klasse zusammen:
import numpy as np
from scipy.cluster.vq import kmeans2
class ProductQuantizer:
def __init__(self, M=16, K=256):
self.M = 16
self.K = 256
self._dataset = None
def create(self, dataset):
"""Fits PQ model based on the input dataset."""
sublen = dataset.shape[1] // self.M
self._centroids = np.empty((self.M, self.K, sublen), dtype=np.float64)
self._dataset = np.empty((dataset.shape[0], self.M), dtype=np.uint8)
for m in range(self.M):
subspace = dataset[:,m*sublen:(m+1)*sublen]
(centroids, assignments) = kmeans2(subspace, self.K, iter=32)
self._centroids[m,:,:] = centroids
self._dataset[:,m] = np.uint8(assignments)
def quantize(self, vector):
"""Quantizes the input vector based on PQ parameters"""
quantized = np.empty((self.M,), dtype=np.uint8)
for m in range(self.M):
centroids = self._centroids[m,:,:]
distances = np.linalg.norm(vector - centroids, axis=1)
quantized[m] = np.argmin(distances)
return quantized
def restore(self, vector):
"""Restores the original vector using PQ parameters."""
return np.hstack([self._centroids[m,vector[m],:] for m in range(M)])
@property
def dataset(self):
if self._dataset:
return self._dataset
raise ValueError("Call ProductQuantizer.create() first")
>>> dataset = np.random.normal(size=(1000, 128))
>>> quantizer = ProductQuantizer()
>>> quantizer.create(dataset)
Und das war's mit der Produktquantisierung! Um die Dinge während des Suchprozesses wirklich zu beschleunigen, können wir ein wenig zusätzlichen Speicher aufwenden, um Distanz-Tabellen für alle Zentroide in jedem Unterraum zu berechnen, aber das überlasse ich dir als Übung.
Zusammenfassung
In diesem Tutorial haben wir uns eingehend mit skalarer Quantisierung und Produktquantisierung beschäftigt und dabei unsere eigenen einfachen Implementierungen erstellt. Skalare Quantisierung ist ein gutes Werkzeug, aber Produktquantisierung ist viel leistungsfähiger und kann unabhängig von der Verteilung unserer Vektordaten verwendet werden. Bitte beachte, dass PQ zwar dazu beitragen kann, Abfragezeiten erheblich zu beschleunigen und gleichzeitig den Speicherbedarf zu reduzieren, für den Recall jedoch im Allgemeinen nicht besonders gut ist. Wir werden PQ zusammen mit mehreren anderen Indexierungsstrategien in einem zukünftigen Tutorial benchmarken.
Im nächsten Tutorial setzen wir unseren Deep Dive in Indexierungsstrategien mit Hierarchical Navigable Small Worlds (HNSW) fort – einem graphbasierten Indexierungsalgorithmus, der heute wohl die beliebteste Methode zur Indexierung von Vektoren ist (auch wenn er ebenfalls seine eigenen Nachteile mit sich bringt). Wir sehen uns im nächsten Tutorial!
Der gesamte Code für dieses Tutorial ist frei auf Github verfügbar: https://github.com/fzliu/vector-search.
Wirf noch einen Blick auf die Vector Database 101-Kurse
- Einführung in unstrukturierte Daten
- Was ist eine Vektordatenbank?
- Vergleich von Vektordatenbanken, Vektorsuchbibliotheken und Vektorsuch-Plugins
- Einführung in Milvus
- Milvus Quickstart
- Einführung in die Vektorähnlichkeitssuche
- Grundlagen von Vektorindizes und der Inverted File Index
- Skalarquantisierung und Produktquantisierung
- Hierarchical Navigable Small Worlds (HNSW)
- Approximate Nearest Neighbors Oh Yeah (ANNOY)
- Den richtigen Vektorindex für Ihr Projekt auswählen
- DiskANN und der Vamana-Algorithmus
Weiterlesen

From Vector Database to Vector Lakebase
Zilliz offers a fully managed Vector Lakebase powered by Milvus, unifying real-time vector search, lake-scale discovery, and Al data operations.

Introducing Functions and Model Inference on Zilliz Cloud: Automatic Embedding and Reranking with Hosted Models
Zilliz Cloud Functions auto-generate embeddings via OpenAI, Voyage AI, Cohere, or Zilliz Hosted Models. Built-in reranking — just insert text and search.

Vector Databases vs. Spatial Databases
Use a vector database for AI-powered similarity search; use a spatial database for geographic and geometric data analysis and querying.