




LLaVA: Weiterentwicklung von Vision-Language-Modellen durch visuelles Instruction Tuning
Aktuelle, dem Stand der Technik entsprechende große Sprachmodelle (LLMs) wie ChatGPT, LLAMA und Claude Sonnet haben gezeigt, dass auf menschlicher Sprache basierende Anweisungen ein leistungsfähiges Instrument zur Verbesserung der Antwortqualität sein können. Mit Techniken wie prompt-engineering können wir LLMs dazu bringen, Antworten zu generieren, die besser auf unsere spezifischen Anwendungsfälle abgestimmt sind.
Ursprünglich waren LLMs ausschließlich für textbasierte Eingaben konzipiert. Wenn sie eine textuelle Anweisung erhielten, generierten sie eine entsprechende Antwort. Obwohl dieser Ansatz sehr erfolgreich war, ist die Ausweitung dieser Fähigkeiten auf visuelle Eingaben eine natürliche Entwicklung. Visuell basierte Modelle nehmen sowohl eine Textanweisung als auch ein Bild als Eingabe auf und ermöglichen so Aufgaben wie die Zusammenfassung des Bildinhalts, die Extraktion von Informationen oder die Übersetzung von Text innerhalb eines Bildes.
In diesem Artikel befassen wir uns mit LLaVA (Large Language and Vision Assistant), einem der bahnbrechenden Versuche, textbasierte Anweisungen für visuell basierte Modelle zu implementieren. Bevor wir auf die Einzelheiten der Implementierung eingehen, sollten wir einen Schritt zurückgehen, um die Entwicklung der visuellen Modelle zu verstehen und zu sehen, wie sie das Feld verändern.
Entwicklung visuell basierter Modelle
In ihren frühen Entwicklungsstadien stützten sich die meisten visuell basierten Modelle auf convolutional neural network (CNN)-basierte Architekturen, um gängige Sehaufgaben zu erfüllen. In seiner einfachsten Form kann ein visuelles Modell mit einem Paar CNN-Schichten aufgebaut werden, um eine einfache Bildklassifizierungsaufgabe zu erfüllen, wie z. B. die Bestimmung, ob ein gegebenes Bild einen Hund oder eine Katze zeigt.
Um jedoch komplexere Bilder mit mehr Klassen zu klassifizieren, müssen wir tiefere Modelle erstellen, die aus Hunderten von CNN-Schichten bestehen. Je tiefer die Schichten des Modells sind, desto größer ist das Risiko, auf das Problem des verschwindenden Gradienten zu stoßen. Der verschwindende Gradient bezieht sich auf das Phänomen, dass der Gradient während des Modelltrainings so klein wird, dass das Modell nicht mehr in der Lage ist, etwas zu lernen und seine Gewichte zu aktualisieren.
Um dieses Problem anzugehen, wurden ausgeklügelte Algorithmen wie [residuale Verbindungen] (https://zilliz.com/learn/deep-residual-learning-for-image-recognition) in die Architektur des Modells implementiert, um das Problem des verschwindenden Gradienten zu vermeiden, das bei Deep-Learning-Modellen häufig auftritt. Diese Methode erwies sich als effektiv und führte zur Einführung von ResNet, das in der Folge in vielen Benchmark-Datensätzen zur Bildklassifizierung Spitzenleistungen erzielte.
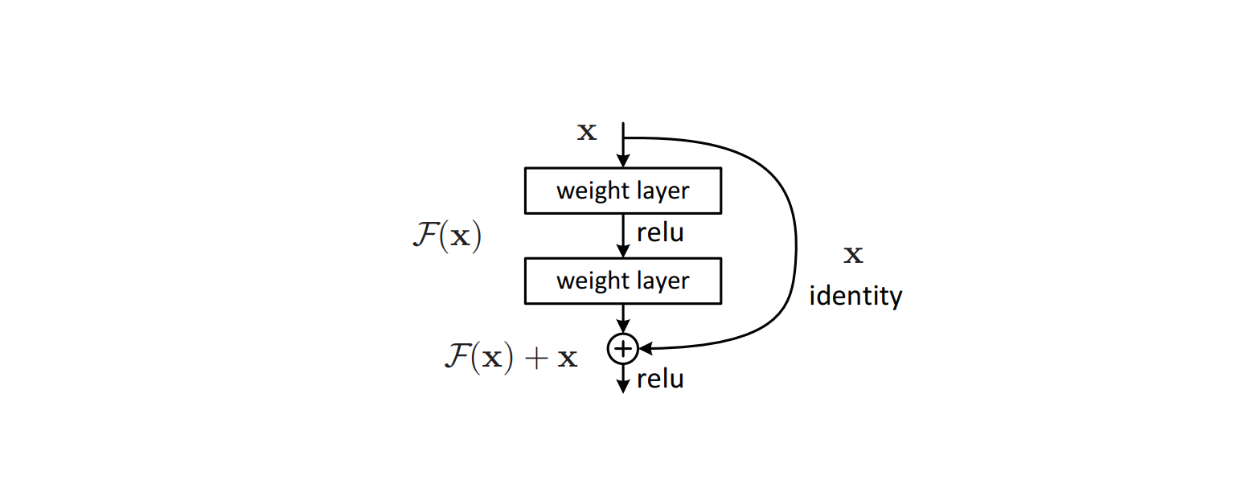
Abbildung: Baustein einer Restverbindung innerhalb der Architektur eines Modells._ Quelle.
Der Erfolg von ResNet inspirierte andere Modellarchitekturen, die in der Lage sind, komplexere Bildaufgaben zu erfüllen. Visuelle Modelle wie YOLO implementierten Restverbindungen in ihre Architektur, um Aufgaben der Objekterkennung durchzuführen. Gleichzeitig verwendete U-Net eine Kombination aus U-förmiger Architektur und Restverbindungen, um Bildsegmentierungsaufgaben zu erfüllen.
Obwohl diese visuellen Modelle visuell basierte Aufgaben erfüllen können, kann jedes Modell nur eine bestimmte Aufgabe erfüllen. Wenn ein Modell für die Bildklassifizierung trainiert wurde, kann es nur für diesen Zweck verwendet werden. Wenn wir das Modell bitten, ein Bild zu klassifizieren, das sich deutlich von den Trainingsdaten unterscheidet, können wir außerdem eine gewisse Zufälligkeit in den Vorhersagen des Modells beobachten.
Die Einführung des berühmten Modells [Transformers] (https://zilliz.com/learn/decoding-transformer-models-a-study-of-their-architecture-and-underlying-principles) im Jahr 2017 löste eine rasante Entwicklung bei Deep-Learning-Modellen im Allgemeinen aus. Modelle, die Transformers in ihrer Architektur verwenden, übertrafen herkömmliche Modelle deutlich. Ursprünglich nur für textbasierte Modelle gedacht, erwies sich die Transformers-Architektur als vielseitig genug, um auch in bildverarbeitungsbasierten Modellen verwendet zu werden.
Transformers-basierte Bildverarbeitungsmodelle, wie [Vision Transformers (ViT)] (https://zilliz.com/learn/understanding-vision-transformers-vit), haben sich bei der Durchführung von Bildklassifizierungsaufgaben als äußerst leistungsfähig erwiesen. Infolgedessen wird ViT nun von vielen populären Text-Vision-Modellen wie CLIP, als Backbone-Architektur verwendet.
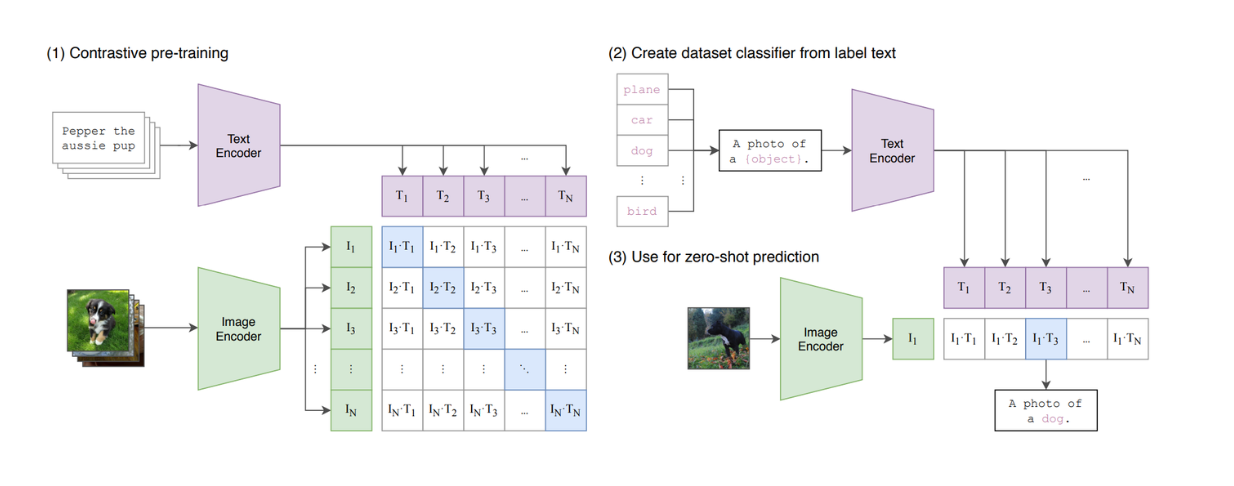
Abbildung: Eine Zusammenfassung des CLIP-Modells. Quelle.
CLIP ist ein Modell, das ViT und ein BERT-ähnliches Modell in seiner Architektur kombiniert. ViT verarbeitet Bildeingaben, während das BERT-ähnliche Modell textuelle Eingaben verarbeitet. CLIP wurde mit Hilfe des kontrastiven Lernens trainiert, wobei CLIP, wenn es einen Text und ein Bild als Eingabepaar erhält, die Ähnlichkeit zwischen dem Text und dem Bild errechnet. Es zeigt sich jedoch, dass CLIP nur begrenzt in der Lage ist, textbasierte LLMs zu imitieren, da es kein generatives Modell ist.
LLaVA ist eines der ersten visuell basierten LLMs, das in der Lage ist, textbasierte Anweisungen und Bilder als Eingaben zu verarbeiten und eine entsprechende Antwort zu erzeugen. Wir werden die Details von LLaVA im nächsten Abschnitt besprechen.
Was ist LLaVa?
LLaVA (Large Language and Vision Assistant) ist ein multimodales Modell, das textbasierte große Sprachmodelle (Large Language Models, LLMs) mit visuellen Verarbeitungsfähigkeiten kombiniert, so dass es Text- und Bildeingaben verarbeiten kann. Es wurde entwickelt, um Aufgaben wie das Zusammenfassen visueller Inhalte, das Extrahieren von Informationen aus Bildern und das Beantworten von Fragen zu visuellen Daten durchzuführen.
LLaVA baut auf dem Erfolg von LLMs auf, indem es visuelles Verständnis einbezieht und textbasierte Anweisungen mit der Bildanalyse in Einklang bringt. Diese Integration ermöglicht es dem Modell, gepaarte Eingaben - Textaufforderungen und Bilder - zu verarbeiten und kohärente und kontextbezogene Antworten zu liefern.
LLaVA-Architektur
Die Architektur von LLaVA ist relativ einfach. Es verwendet einen vortrainierten LLM zur Verarbeitung von Textanweisungen und den visuellen Encoder von vortrainiertem CLIP, ein ViT-Modell, zur Verarbeitung von Bildinformationen.
Unter mehreren öffentlich verfügbaren vortrainierten LLMs wählten die Autoren von LLaVA Vicuna als Rückgrat, um Textinformationen zu verarbeiten und die endgültige Antwort zu generieren, wenn ein Paar von Text-Bild-Eingaben vorliegt.
Da die meisten textbasierten LLMs auf der Transformer-Architektur beruhen, ist der Prozess der Textumwandlung bis zur Generierung der Antwort recht einfach. Jedes Token im Eingabetext wird in eine Einbettung umgewandelt und durchläuft dann mehrere Stapel von Aufmerksamkeits- und Dichteschichten, bevor die endgültige Merkmalsausgabe mit einer festen Größe erzeugt wird.
Zur Verarbeitung der Bildeingabe verwendet LLaVA das vortrainierte ViT-Modell in CLIP, um das Eingabebild in eine Merkmalsrepräsentation mit einer festen Dimension zu transformieren. Die Dimension des Bildmerkmals von CLIP unterscheidet sich jedoch von der Dimension des Textmerkmals von Vicuna. Daher implementiert LLaVA anschließend eine einfache dichte Schicht, um das Bildmerkmal so zu projizieren, dass es die gleiche Größe wie das Textmerkmal aus Vicuna hat.
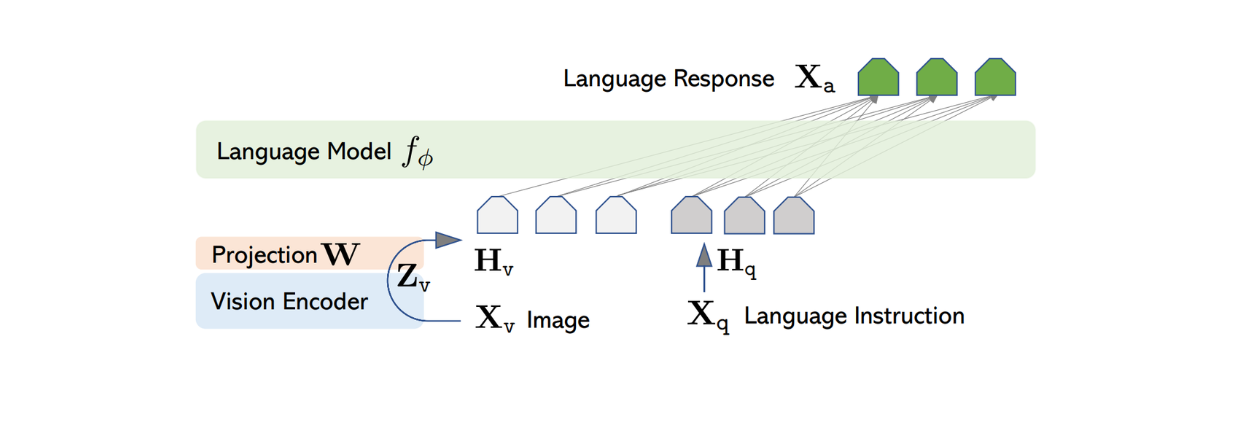
Abbildung: LLaVA-Architektur. Quelle.
Da das Bild- und das Textmerkmal nun die gleiche Größe haben, ist ein Ansatz erforderlich, um diese beiden Merkmale zu einem einzigen zu kombinieren. Hierfür gibt es verschiedene Ansätze, wie z. B. das einfache Voranstellen des Bildmerkmals vor das Token-Merkmal ([Bildmerkmal] + [Textmerkmal]) oder die Verwendung anspruchsvollerer Algorithmen wie Gated Cross-Attention und Q-Former. Die kombinierten Bild- und Textmerkmale werden dann in Vicuna eingespeist, damit es eine passende Antwort generieren kann.
Bei der Umsetzung des oben erwähnten Ansatzes kann es jedoch sein, dass die von Vicuna oder anderen ähnlichen LLMs erzeugte Antwortqualität nicht optimal ist. Dies ist zu erwarten, da LLMs rein auf Textdaten trainiert werden. Daher muss LLaVA fein abgestimmt werden, bevor es kohärente Antworten auf der Grundlage eines Paares von Bild-Text-Eingaben erzeugen kann. Dieser Feinabstimmungsprozess wird als [visuelles Instruktionstuning] (https://arxiv.org/abs/1512.03385) bezeichnet, auf das wir in den nächsten Abschnitten eingehen werden.
Datengenerierungsprozess für visuelle Befehlsabstimmung
Visual Instruction Tuning ist ein Prozess, bei dem multimodale KI-Modelle darauf trainiert werden, textbasierte Anweisungen zu verstehen und darauf zu reagieren, wenn sie mit visuellen Eingaben wie Bildern oder Videos kombiniert werden. Diese Technik verbindet visuelles Verständnis mit der Verarbeitung natürlicher Sprache und ermöglicht es dem Modell, Aufgaben wie Bildunterschriften, Beantwortung visueller Fragen, Objekterkennung und Informationsextraktion durchzuführen.
Eine der größten Herausforderungen bei der Abstimmung visueller Anweisungen ist der Mangel an öffentlich zugänglichen multimodalen Daten zur Befolgung von Anweisungen. Es gibt zwar mehrere Datensätze, die aus Bild-Text-Paaren bestehen, wie z. B. CC und LAION, aber sie sind nicht genau die Art von Datensatz, die wir für die Feinabstimmung von visuell basierten LLMs zur Befolgung von Benutzeranweisungen verwenden möchten.
Abbildung: Beispiel eines CC-Datensatzes. Quelle.
Auf der anderen Seite würde die manuelle Erstellung einer großen Menge an multimodalen Instruktionsfolgedaten zur Abstimmung von LLaVA erhebliche Anstrengungen und Zeit erfordern. Daher können wir GPT-4 oder ChatGPT nutzen, um den Erstellungsprozess von multimodalen Instruktionsdaten zu beschleunigen.
Wie im obigen Beispiel des CC-Bildes zu sehen ist, bestehen übliche multimodale Datensätze aus einem Bild-Beschriftungstext-Paar in jedem Datensatz. Mit ChatGPT können wir anhand eines Bildes und seiner Beschriftung eine Reihe möglicher Fragen generieren, die die LLMs anweisen sollen, den Inhalt des Bildes zu beschreiben. Das Format der multimodalen Anweisungsdaten sieht dann wie folgt aus: Mensch: Xq Xv
Wir wissen jedoch, dass frühere Versionen von ChatGPT nur Text als Eingabe akzeptieren. Um damit eine Liste von Fragen zu einem bestimmten Bild zu erstellen, müssen wir Informationen oder Metadaten über das Bild bereitstellen. Die Autoren haben zwei verschiedene Ansätze verwendet, um ChatGPT die notwendigen Informationen über ein beliebiges Eingabebild zu geben: Bildunterschriften und Begrenzungsrahmen. Bildunterschriften bestehen in der Regel aus detaillierten Beschreibungen des Bildes, während Bounding Boxes ChatGPT hilfreiche Informationen über die genaue Position der Objekte im Bild liefern.

Abbildung: Beispiel für Bildunterschriften und Begrenzungsrahmen zur Erfassung visueller Informationen für GPT-4, das nur aus Text besteht. Quelle.
Die Autoren erstellten drei Arten von multimodalen Datensätzen zur Befolgung von Anweisungen:
Konversation: Diese besteht aus einem Hin- und Hergespräch zwischen dem LLM und dem Benutzer. Die Antworten des LLM sind so formuliert, als würde er das Bild betrachten und dann die Fragen des Benutzers beantworten. Typische Fragen sind der visuelle Inhalt des Bildes, das Zählen von Objekten im Bild, relative Positionen von Objekten im Bild, usw.
Detaillierte Beschreibungen: Besteht aus einer Liste von Fragen, die dazu dienen, umfassende Beschreibungen eines Bildes zu erstellen.
Komplexe Argumentation: besteht aus Fragen, die über die beiden oben genannten Typen hinausgehen. Anstatt nur den visuellen Inhalt eines Bildes zu beschreiben, zielen diese Fragen darauf ab, den LLM zu zwingen, die Logik hinter seinen Antworten zu erklären, was eine schrittweise Argumentation erfordert.

Abbildung: Beispiel für drei Arten von multimodalen Anweisungsfolgedatensätzen. Quelle.
Nachfolgend ein Beispiel für eine Aufforderung, die von den Autoren verwendet wurde, um einen konversationsartigen Datensatz zu erzeugen:
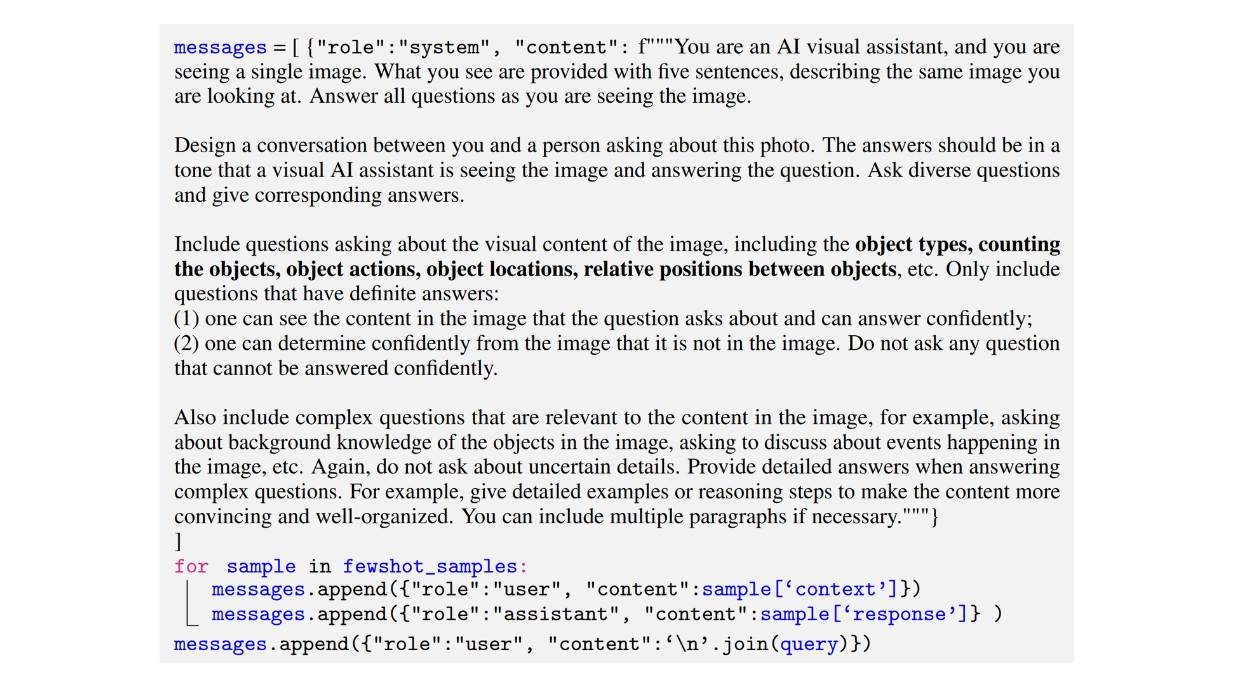
Abbildung: Beispiel eines Prompts, der zur Generierung eines konversationellen multimodalen Anweisungsdatensatzes verwendet wurde. Quelle._
Es ist nicht ganz einfach, die gewünschte Ausgabe mit dem richtigen Format von LLM-generierten multimodalen Daten zur Befolgung von Anweisungen zu erhalten. Deshalb haben die Autoren ChatGPT gebeten, alle drei Arten von multimodalen Anweisungsfolgedatensätzen zu generieren, und dabei nur wenige Stichproben verwendet, um die Leistungsfähigkeit des kontextbezogenen Lernens zu nutzen.
Bei diesen Beispielen haben die Autoren einige manuell erstellte Beispiele von Unterhaltungen zwischen dem LLM und dem Nutzer neben dem Prompt bereitgestellt. Diese Beispiele helfen ChatGPT, die Struktur der erwarteten Ausgabe besser zu verstehen. Unten sehen Sie ein Beispiel für ein "few-shot sample", das von den Autoren in die Eingabeaufforderung implementiert wurde, um einen Gesprächsdatensatz zu erzeugen.

Abbildung: Beispiel eines "few-shot"-Beispiels, das neben dem Prompt für das kontextbezogene Lernen übergeben wird Quelle._
Trainingsverfahren von LLaVA
Die Gesamtmenge der multimodalen Instruktionsdaten, die mit dem oben erwähnten Ansatz generiert wurden, betrug etwa 158K. Anschließend wurde ein LLaVA-Modell mit diesen multimodalen Daten feinabgestimmt.
In dem Datensatz gibt es für jedes Bild Xv Multi-Turn-Gespräche zwischen dem LLM und den Benutzern (X1q, X1a, - - - , XTq, XTa), wobei T die Gesamtzahl der Turns ist. Für jeden Zug t wird die Antwort Xta als die Antwort des LLM behandelt, und daher würde die Anweisung bei Zug t lauten:
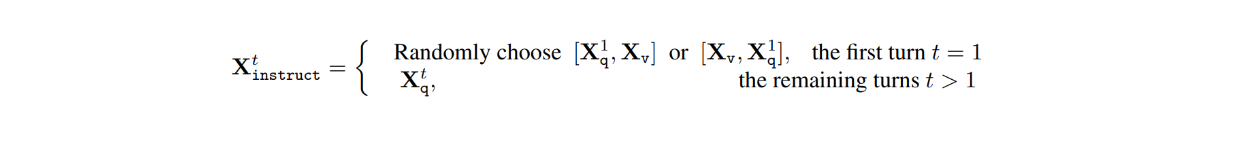
Während des Abstimmungsprozesses der visuellen Instruktionen wurden zwei Stufen durchgeführt: das Vortraining für die Merkmalsausrichtung und die Feinabstimmung von Ende zu Ende.
In der Phase des Vortrainings für den Merkmalsabgleich besteht der Hauptzweck darin, die Projektionsschicht zu trainieren, die die Ausgabe des ViT-Modells aus dem vortrainierten CLIP-Encoder auf ein endgültiges visuelles Merkmal abbildet, das die gleiche Dimension wie das Textmerkmal hat. In diesem Stadium wurde der Trainingsprozess mit dem gefilterten CC-Datensatz durchgeführt, der 596K Bild-Text-Paare enthält. Für jedes Bild Xv wird die Frage Xq nach dem Zufallsprinzip aus einem Pool von Fragen ausgewählt, und das entsprechende Xc wird als Ground-Truth-Label verwendet. Daher sind die für das Training ausgewählten Fragen solche, die das LLM auffordern, das Bild kurz zu beschreiben, wie Sie in der Abbildung unten sehen können:

Abbildung: Beispiel für Aufforderungen, den Inhalt eines Bildes kurz zu erklären: Quelle.
Da wir nur die Projektionsschicht trainieren, sind die Gewichte von ViT und LLM in diesem Stadium eingefroren.
Währenddessen wird das LLaVA-Modell in der zweiten Phase, der End-to-End-Feinabstimmung, mit den 158K generierten multimodalen Instruktionsfolgedaten feinabgestimmt. In dieser Phase werden nur die ViT-Gewichte eingefroren, während die Gewichte der Projektionsschicht und des LLM während des Feinabstimmungsprozesses aktualisiert werden.
LLaVA-Ergebnisse
Um die Leistung von LLaVA zu bewerten, wurde ein Vergleich mit anderen State-of-the-Art-Modellen wie GPT-4 und visuell basierten Modellen wie BLIP-2 und OpenFlamingo durchgeführt. Für die Bewertung der Ergebnisse verwendeten die Autoren das rein textbasierte GPT-4, um die Qualität der Antworten auf der Grundlage von Hilfsbereitschaft, Relevanz, Genauigkeit und Detaillierungsgrad zu bewerten.
Für die erste Auswertung wurden 30 zufällige Bilder aus dem COCO-Val-2014-Datensatz ausgewählt und mit Hilfe des im vorherigen Abschnitt erläuterten Datenerzeugungsprozesses drei Arten von Datensätzen erzeugt. Das Ergebnis waren insgesamt 90 Datenpunkte: 30 für Konversation, 30 für detaillierte Beschreibungen und 30 für komplexe Argumentation. Die Antworten von LLaVA wurden dann mit der Ausgabe des reinen Textmodells GPT-4 verglichen, das eine textuelle Beschreibung/Beschreibung als Etikett und Begrenzungsrahmen als visuelle Eingabe verwendet. Die Ergebnisse sind wie folgt:
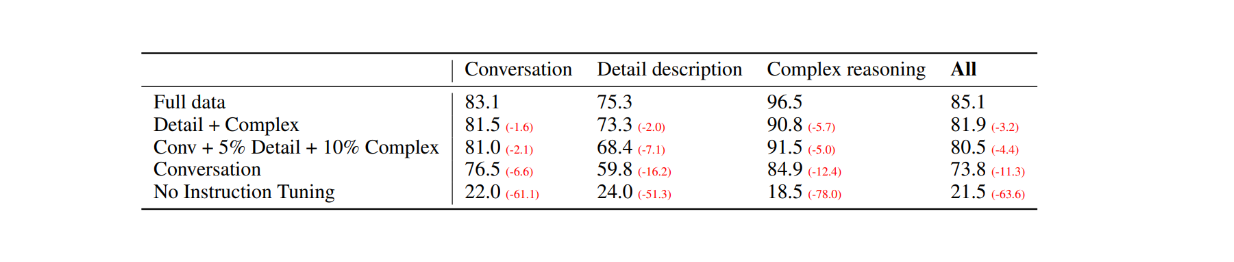
Abbildung: Leistungsvergleich zwischen LLaVA und reinem Text-GPT-4 auf 30 Zufallsbildern._ Quelle.
Mit dem Tuning der visuellen Anweisungen stieg die Fähigkeit des Modells, den Anweisungen zu folgen, in jedem Datensatztyp um mindestens 50 Punkte. In der Zwischenzeit war die relative Punktzahl von LLaVA im Vergleich zum reinen Textmodell GPT-4, das Bildunterschriften als visuellen Input verwendet, nicht weit entfernt, wie die Zahlen in Klammern in jeder Kategorie zeigen.
Die Leistung von LLaVA wurde auch mit visuell basierten Modellen wie BLIP-2 und OpenFlamingo verglichen, indem zunächst 24 zufällige Bilder mit insgesamt 60 Fragen genommen wurden. Wie in der untenstehenden Tabelle zu sehen ist, ist die Leistung von LLaVA den beiden anderen visuell basierten Modellen weit überlegen. Dies zeigt die Leistungsfähigkeit der visuellen Instruktionsabstimmung, da BLIP-2 und OpenFlamingo nicht explizit mit einem multimodalen Datensatz zur Befolgung von Instruktionen feinabgestimmt worden sind.

Abbildung: Leistungsvergleich zwischen LLaVA und BLIP-2 und OpenFlamingo._ Quelle.
Schauen wir uns nun ein Beispiel für die Reaktionen der Modelle in Aktion an. Nehmen wir ein Bild von Chicken Nuggets, die eine Weltkarte bilden, und wir fragen: "Können Sie dieses Mem im Detail erklären?" Unten sind die Beispielantworten von LLaVA, GPT-4 (nur Text), BLIP-2 und OpenFlamingo.

Abbildung: Beispielantworten von LLaVA, GPT-4, BLIP-2 und OpenFlamingo._ Quelle.
Wie Sie sehen können, konnten sowohl BLIP-2 als auch OpenFlamingo der Anweisung nicht folgen, da sie nicht mit der visuellen Anweisungsabstimmung feinabgestimmt worden sind. In der Zwischenzeit demonstrierte LLaVA seine Fähigkeit zum visuellen Denken beim Verstehen von Humor. Zusammen mit GPT-4 war es in der Lage, eine prägnante Antwort gemäß der Anweisung zu geben.
Bei der Feinabstimmung des ScienceQA-Datensatzes für ca. 12 Epochen erzielte LLaVA ebenfalls sehr konkurrenzfähige Ergebnisse im Vergleich zum MM-CoT-Modell, dem aktuellen State-of-the-Art-Modell (SOTA) für diesen Datensatz. Wie in der nachstehenden Tabelle zu sehen ist, erreichte LLaVA eine Gesamtgenauigkeit von 90,92 % über mehrere verschiedene Themen hinweg, verglichen mit 91,68 % beim MM-CoT-Modell. Als jedoch die Ausgabe von LLaVA mit GPT-4 kombiniert wurde, erreichte die Leistung mit 92,53 % Genauigkeit einen neuen SOTA auf dem ScienceQA-Datensatz.
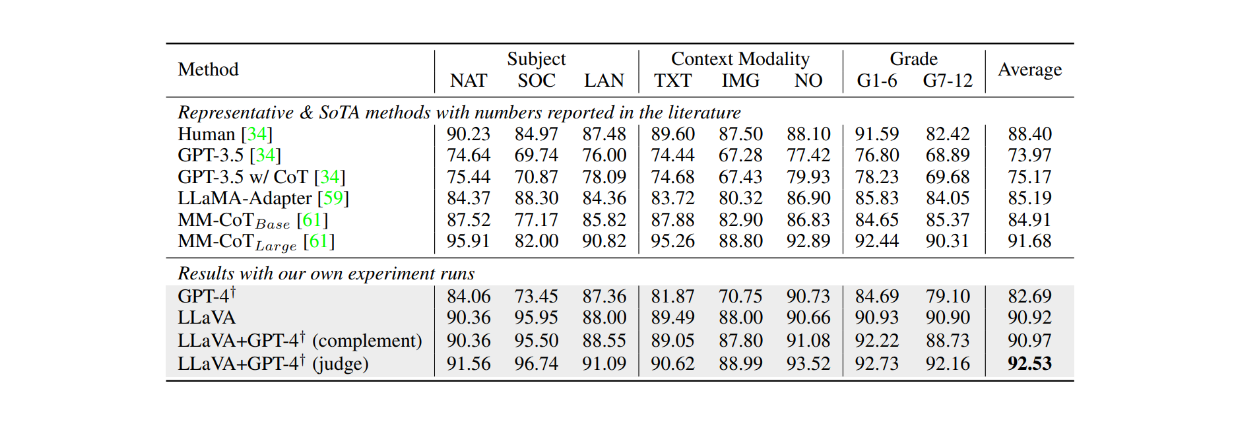
Abbildung: Genauigkeit der LLMs auf dem ScienceQA-Datensatz._ Quelle.
Schlussfolgerung
LLaVA stellt einen frühen Fortschritt in der Entwicklung visuell basierter Large Language Models (LLMs) dar, die in der Lage sind, textuellen Anweisungen zu folgen. Das Modell kombiniert einen vortrainierten Vision Transformer (ViT) von CLIP für die Bildverarbeitung mit Vicuna als Sprachmodell-Backbone und verwendet eine Projektionsschicht, um die Merkmalsdimensionen zwischen den beiden Komponenten anzugleichen. Das Modell wird dann anhand von 158K multimodalen Anweisungsbefolgungsdaten feinabgestimmt.
Dank dieses Ansatzes zur Abstimmung visueller Anweisungen kann LLaVA komplexe Schlussfolgerungen zu einem gegebenen Bild entsprechend den Anweisungen in der Eingabeaufforderung beschreiben und durchführen. Die Evaluierungsergebnisse zeigen die Effektivität des visuellen Instruktionstunings, da die Leistung von LLaVA durchweg zwei andere visuell basierte Modelle übertrifft: BLIP-2 und OpenFlamingo.
Weitere Lektüre
ColPali: Bessere Dokumentensuche mit VLMs und ColBERT-Embeddings ](https://zilliz.com/blog/colpali-enhanced-doc-retrieval-with-vision-language-models-and-colbert-strategy)
Mamba: Ein möglicher Ersatz für Transformer ](https://zilliz.com/learn/mamba-architecture-potential-transformer-replacement)
Was ist Detection Transformers (DETR)? ](https://zilliz.com/learn/detection-transformers-detr-end-to-end-object-detection-with-transformers)
ColBERT: Ein Einbettungs- und Ranking-Modell auf Token-Ebene ](https://zilliz.com/learn/explore-colbert-token-level-embedding-and-ranking-model-for-similarity-search)
XLNet: Verbessertes NLP mit verallgemeinertem autoregressivem Vortraining](https://zilliz.com/learn/xlnet-explained-generalized-autoregressive-pretraining-for-enhanced-language-understanding)
Was sind Vektordatenbanken und wie funktionieren sie? ](https://zilliz.com/learn/what-is-vector-database)
Was ist RAG? ](https://zilliz.com/learn/Retrieval-Augmented-Generation)
Weiterlesen

Zilliz Cloud Now Available in AWS Europe (Ireland)
Zilliz Cloud launches in AWS eu-west-1 (Ireland) — bringing low-latency vector search, EU data residency, and full GDPR-ready infrastructure to European AI teams. Now live across 30 regions on five cloud providers.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.

AI Integration in Video Surveillance Tools: Transforming the Industry with Vector Databases
Discover how AI and vector databases are revolutionizing video surveillance with real-time analysis, faster threat detection, and intelligent search capabilities for enhanced security.