




Den K-Means-Clustering-Algorithmus im maschinellen Lernen verstehen
K-Means-Clustering oder K-Means-Algorithmus oder K-Means-Clustering-Algorithmus – nun, bevor wir uns damit befassen, worum es bei Clustering-Algorithmen überhaupt geht, müssen wir verstehen, wie wesentlich sie für moderne Unternehmen sind, um Daten sinnvoll zu nutzen – Daten über Produkte, Daten über Kunden, Daten über Transaktionen und so weiter.
In einer Welt, in der Technologie die Geschäftslandschaft neu definiert, geben Unternehmen Millionen von Dollar für die Analyse von Daten aus, um Muster zu entwickeln, die ihnen helfen, effizienter zu werden und ihre Gewinne zu steigern. Das Gruppieren von Objekten auf Grundlage von Attributen ist eine der ersten Aufgaben in diesem Prozess, solche Muster zu entwickeln.
Das Gruppieren von Objekten hilft Unternehmen, verschiedene Strategien für verschiedene Situationen zu entwerfen. Kunden, Produkte und Transaktionen sind Objekte von zentralem Interesse in solchen Prozessen. Das Gruppieren von Kunden auf Grundlage ihres Verhaltens hilft Unternehmen, personalisierte Angebote zu entwickeln. Das Gruppieren von Produkten hilft ihnen, Kunden alternative Auswahlmöglichkeiten anzubieten. Und das Gruppieren von Transaktionen hilft ihnen, ungewöhnliche Muster zu erkennen, die genauerer Aufmerksamkeit bedürfen.
Hier kommt Clustering ins Spiel. Clustering ist ein unüberwachter Machine-Learning-(ML)-Algorithmus, der Objekte auf Grundlage von Attributen gruppiert.
Dieser umfassende Artikel von Zilliz, einem führenden Unternehmen für Vektordatenbanken für produktionsreife KI, führt Sie tief in die Frage ein, worum es beim K-Means-Clustering-Algorithmus im Machine Learning geht und wie Sie ihn mit Python implementieren können. Er wird außerdem erläutern, wann der K-Means-Clustering-Algorithmus verwendet werden sollte, und ein echtes Beispiel für K-Means-Clustering geben.
Was ist Clustering?
Clustering ist der Prozess des Gruppierens von Datenpunkten, sodass jedes Element in einer bestimmten Gruppe den Elementen in dieser Gruppe ähnlicher ist als den Elementen in anderen Gruppen. Clustering bezieht sich nicht auf einen bestimmten Algorithmus. Es ist eine generische Aufgabe, die mithilfe vieler Algorithmen gelöst werden kann. Clustering-Algorithmen definieren im Allgemeinen eine Metrik, um die Ähnlichkeit systematisch zu quantifizieren. Clustering wird in vielen Bereichen eingesetzt, etwa in der Bildverarbeitung, im Information Retrieval, in Empfehlungsmaschinen und in der Datenkompression.
Clustering stellt Ähnlichkeit auf Grundlage der Attribute der Objekte her, die es clustert. Die Attribute unterscheiden sich je nach Domäne. Beispielsweise sind im Fall eines Bildes die Attribute Pixelwerte. Im Fall eines Benutzerprofils sind die Attribute Details wie Alter, Geschlecht und Kaufhistorie. Im Fall eines Produkts sind die Attribute Kategorie, Farbe, Preis usw. Clustering wird als unüberwachte Aufgabe bezeichnet, weil es keinen vom Benutzer überwachten Trainingsprozess gibt, der die Vorbereitung gelabelter Daten umfasst.
Wie funktionieren Clustering-Algorithmen?
Die meisten Clustering-Algorithmen funktionieren, indem sie die Ähnlichkeit zwischen allen Paaren von Stichproben berechnen. Jeder Datenpunkt wird auf Grundlage von Distanzberechnungen dem nächstgelegenen Zentroid zugewiesen, was ein grundlegender Schritt im Clustering-Prozess ist.
Die Fähigkeit, mit dem Umfang des Datensatzes zu skalieren, ist ein wesentlicher Faktor, der bei der Entscheidung für den Clustering-Algorithmus für ein Problem berücksichtigt werden sollte. Die Ausführungszeit steigt mit der Anzahl der Elementpaare. In Extremfällen kann sie proportional zum Quadrat des Datenvolumens variieren.
Vier Ansätze für Clustering
Es gibt vier gängige Ansätze für Clustering: zentroidbasiert, dichtebasiert, hierarchisch und verteilungsbasiert. Sehen wir sie uns der Reihe nach an.
1. Zentroidbasiertes Clustering
Diese Methode organisiert Datenpunkte basierend auf dem Zentroid aller Datenpunkte im Cluster in einzelne Cluster ohne jegliche Hierarchie. Der Zentroid ist das geometrische Zentrum eines Objekts. Einfach ausgedrückt ist er das arithmetische Mittel aller Punkte, die dieses Objekt im n-dimensionalen Raum bilden. Hier ist ein Cluster eine Sammlung von Punkten, die sich um einen Zentroid befinden. Zentroid-basiertes Clustering leidet unter Problemen im Zusammenhang mit anfänglichen Zuweisungen und Ausreißern.
2. Dichtebasiertes Clustering
Wie der Name schon sagt, berechnet es die Dichte von Punkten in einem Bereich und weist dann Datenpunkte Clustern zu, wo immer eine hohe Dichte gefunden wird. In diesem Fall können die Cluster jede beliebige Form annehmen. Dichtebasiertes Clustering stößt auf Probleme, wenn die Daten von Natur aus eine hohe Varianz in der Dichte aufweisen. Es funktioniert nicht gut, wenn die Datendimension hoch ist, da es Schwierigkeiten haben kann, zwischen Clustern und benachbarten Clustern zu unterscheiden.
3. Hierarchisches Clustering
Diese Methode stellt einen Baum von Clustern bereit, mit der Möglichkeit, dass sich Cluster innerhalb größerer Cluster befinden. Diese Methode passt gut, wenn Daten eine inhärente Hierarchie aufweisen. Hierarchisches Clustering ermöglicht es, nach der Ausführung eine beliebige Anzahl verschiedener Cluster auszuwählen, da der Analyst den Baum an der erforderlichen Stelle trennen und nur die Cluster nach diesem Punkt berücksichtigen kann.
4. Verteilungsbasiertes Clustering
Diese Methode verwendet das Konzept von Wahrscheinlichkeitsverteilungen, um Cluster zu finden. Sie geht davon aus, dass die Wahrscheinlichkeit, dass sich ein Punkt in einem Cluster befindet, abnimmt, wenn die Entfernung vom Clusterzentrum zunimmt. Entwickler sollten die Verteilung ihrer Daten kennen, um diese Methode effektiv zu nutzen.
Was ist K-means-Clustering?
Der K-means-Clustering-Algorithmus ist ein Zentroid-basierter Clustering-Algorithmus. Es handelt sich um einen unüberwachten Lernalgorithmus, da er nicht auf gelabelten Daten basiert. Das „K“ in einem K-means-Clustering-Algorithmus steht für die Anzahl der Cluster.
K-means ist ein iterativer Algorithmus, der den Mittelwert oder Zentroid viele Male berechnet, bevor er konvergiert. Die Zeit bis zur Konvergenz hängt von der anfänglichen Zuweisung und der optimalen Anzahl der verwendeten Cluster ab. Im Allgemeinen beträgt die Zeitkomplexität von K-means
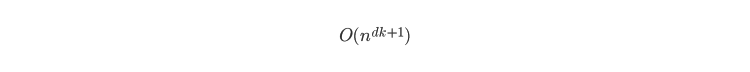
wobei d die Anzahl der Dimensionen ist, k die Anzahl der Cluster ist und n die Anzahl der k Cluster von Datenelementen ist.
Der K-means-Clustering-Algorithmus funktioniert, indem er die Entfernung jedes Datenelements vom geometrischen Zentrum eines Clusters berechnet. Anschließend konfiguriert er den Cluster neu, wenn er einen Punkt findet, der zu einem bestimmten Cluster gehört und näher am Zentroid eines anderen Clusters liegt. Danach berechnet er den Cluster-Zentroid erneut und wiederholt den Prozess, bis keine weitere Cluster-Neuzuweisung mehr erfolgt.
Schauen wir uns an, wie der Algorithmus funktioniert.
Wie funktioniert der K-means-Clustering-Algorithmus?
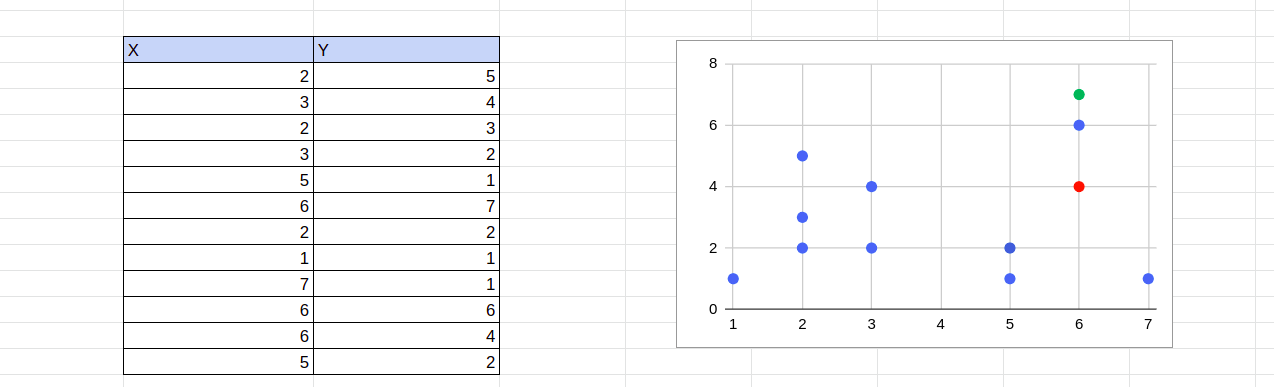
Der K-means-Clustering-Algorithmus ist ein iterativer Prozess, der vier wesentliche Schritte umfasst. Um diese Schritte zu verstehen, betrachten wir ein zweidimensionales Clustering-Problem. Nehmen wir an, die Punkte sind (x1,y1),(x2,y2) und so weiter. Beginnen wir mit einer Clustergröße von 2.
Anfängliche Zuweisung
Dieser Schritt weist jeden Punkt einem beliebigen Cluster zu. Eine Möglichkeit besteht darin, zufällige Punkte als Cluster-Zentroide zuzuweisen und die Abstände zwischen jedem Datenpunkt und den Zentroiden zu berechnen.
Punkte werden dem Cluster zugewiesen, dessen Zentroid ihnen am nächsten liegt. Der Abstand zwischen zwei Clustern wird mithilfe der euklidischen Distanzformel berechnet. Wenn beispielsweise x3,y3 einer der zufällig zugewiesenen Zentroide ist, kann man den Abstand zwischen x1,y1 und x3,y3 mit dieser Formel berechnen:
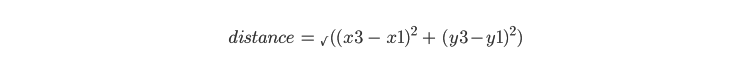
 Y vs. X
Y vs. X
Y vs. X
Die roten und grünen Punkte bezeichnen die anfänglichen zufälligen Zentroid-Zuweisungen. Allein auf Grundlage dieser anfänglichen Cluster-Zentroide erscheint die anfängliche Cluster-Zuweisung wie unten dargestellt:
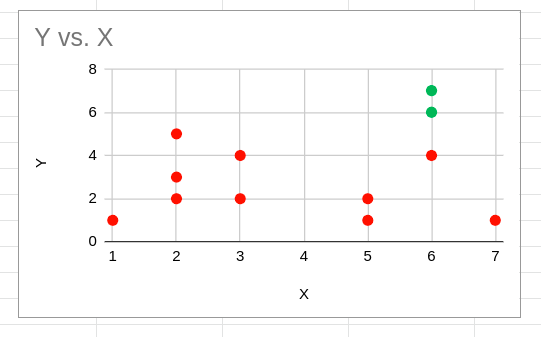 Y vs. X
Y vs. X
Y vs. X
Berechnung von Zentroiden
Dieser Schritt umfasst die Neuberechnung der Zentroide für jeden Cluster. Der Zentroid für einen Cluster wird mithilfe des arithmetischen Mittels aller Elemente in diesem Cluster berechnet. Nehmen wir zum Beispiel an, x1,y1, x2,y2 und x3,y3 gehören zu einem Cluster. Der Zentroid dieses Clusters wird wie folgt berechnet:
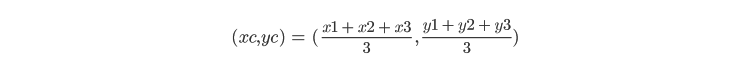
Die Punkte in Diamantform, wie unten gezeigt, werden zu den neuen Zentroiden.
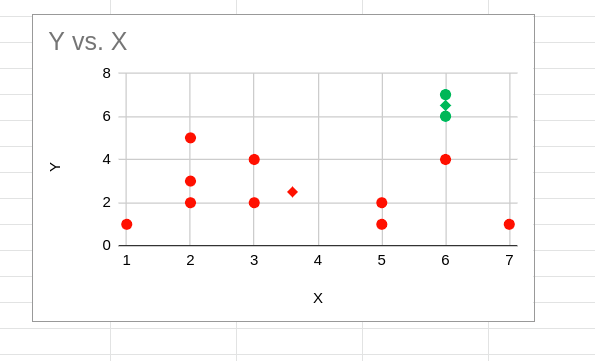 Y vs. X
Y vs. X
Y vs. X
Neuzuweisung von Clustern
Sobald neue Zentroide für alle drei Cluster gefunden wurden, wird die Distanz zwischen jedem Punkt und den neuen Zentroiden neu berechnet. Wenn sich einer der Punkte näher am Zentroid eines Clusters befindet, dem er derzeit zugewiesen ist, werden die Punkte neu zugewiesen.
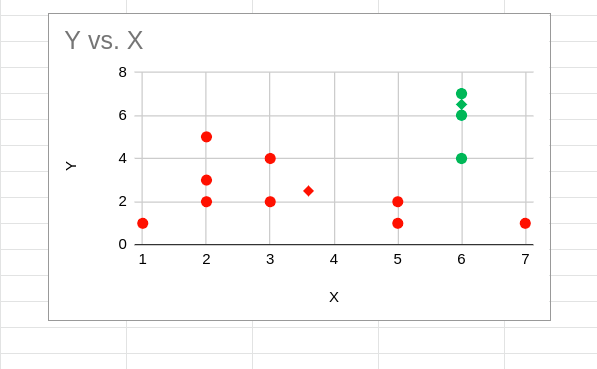 Y vs. X
Y vs. X
Y vs. X
Konvergenz
Nach der Neuzuweisung von Clustern werden die Zentroide erneut berechnet, und der Prozess wiederholt sich. Die Berechnung von Zentroiden und die Neuzuweisung von Clustern werden so lange ausgeführt, bis es keine weiteren neuen Neuzuweisungen mehr gibt. Die konvergierte Clustering-Aufgabe wird in diesem Fall wie unten gezeigt erscheinen:
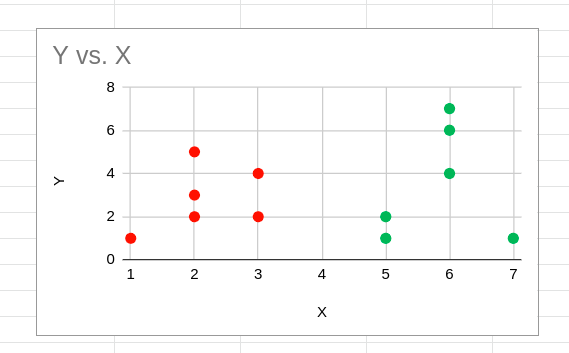 Y vs. X
Y vs. X
Y vs. X
Auswahl der Anzahl der Cluster
Zwei häufig verwendete Methoden zur Auswahl der idealen Anzahl von Clustern sind die Elbow-Methode und die Silhouette-Methode.
Elbow-Methode
Die Elbow-Methode berechnet eine Metrik namens WCSS (Within Cluster Sum of Squares). WCSS ist die Summe der Quadrate der Distanz jedes Punkts vom Zentroid seines nächstgelegenen Clusters oben. Der Plot von WCSS in Bezug auf die Anzahl der Cluster wird als Hinweis verwendet, um die optimale Anzahl von Clustern auszuwählen.
Entwickler führen K-means-Clustering für Clusterzahlen von 1 bis n aus und berechnen dann WCSS für jeden dieser Durchläufe. WCSS ist bei einer Ausführung mit einem einzigen Cluster am höchsten und sinkt, wenn die Anzahl der Cluster steigt. Der Punkt, an dem WCSS einen scharfen Knick aufweist, wie der Ellbogen eines Arms, gilt als die ideale optimale Anzahl von Clustern.
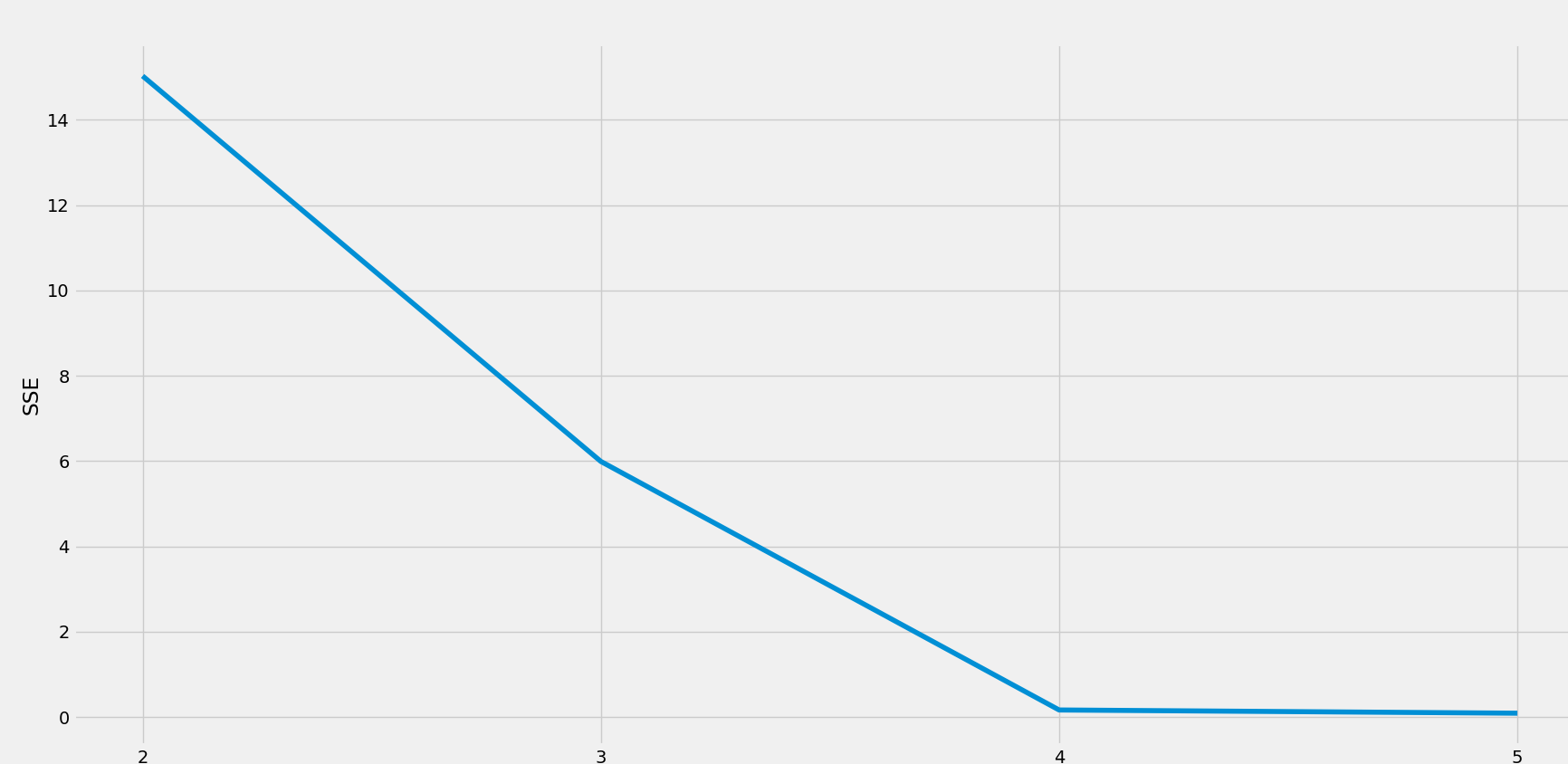 Elbow Method
Elbow Method
Elbow-Methode
Silhouette-Methode
Diese Methode versucht zu verstehen, wie ähnlich ein Objekt anderen Mitgliedern desselben Clusters ist und wie stark die Objekte von anderen Clustern getrennt sind. Der Silhouette-Score für einen Punkt wird berechnet, indem die durchschnittliche Distanz dieses Punkts zu anderen Punkten im Cluster (a) und die durchschnittliche Distanz dieses Punkts zu allen Punkten, die zu anderen Clustern gehören (b), einschließlich benachbarter Cluster, kombiniert werden. Sobald a und b gefunden wurden, wird der Silhouette-Score für einen Punkt wie folgt berechnet:
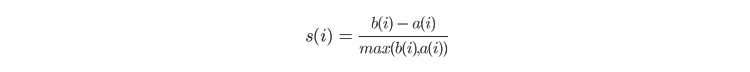
Der Score für jeden Punkt wird anschließend gemittelt, um den Silhouette-Score zu ermitteln. Der Score wird für alle Kandidaten für die optimale Anzahl berechnet, und dann wird derjenige mit den k Punkten und dem höchsten Score als optimale Anzahl ausgewählt.
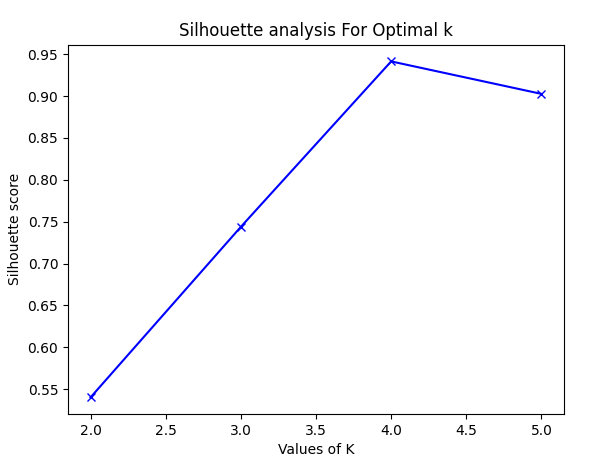 Silhouette Method
Silhouette Method
Silhouette-Methode
Ein reales Beispiel für den K-means-Clustering-Algorithmus (Implementierung von K-means-Clustering mit Python)
Dieses Tutorial demonstriert, wie K-means-Clustering mit Python implementiert und die optimale Clustergröße ermittelt wird. Nehmen wir dazu eine Problemstellung an, die im E-Commerce-Bereich üblich ist. Das Clustering von Kunden basierend auf ihren demografischen Attributen und Ausgabegewohnheiten ist eine häufige Aufgabe im E-Commerce-Bereich. Zur Vereinfachung des K-means-Clustering-Beispiels verwenden wir hier zwei Attribute: das Alter des Kunden und den durchschnittlich pro Monat ausgegebenen Betrag.
- Verwenden wir dazu eine Python-Bibliothek für maschinelles Lernen namens scikit-learn und eine Plotting-Bibliothek namens matplotlib. Initialisieren Sie zunächst die Bibliotheken mithilfe der unten angegebenen import-Anweisungen:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette\_score
from sklearn.preprocessing import StandardScaler
- Der nächste Schritt besteht darin, den Eingabedatenrahmen zu definieren. Hier ist das erste Attribut das Alter und das zweite Attribut die durchschnittlichen monatlichen Ausgaben in Indischen Rupien (INR). Der Einfachheit halber initialisieren wir das Array direkt im Code. Wir haben hier 16 Datenpunkte:
raw\_features = np.array([[22,200],[24,200],[24,200],[20,800],[24,800],[24,800],[25,200],[54,200],[24,200],[54,200],[50,800],[53,800],[24,800],[55,800],[53,800],[50,800]])
- Anschließend normalisieren Sie die Datenpunkte, damit Variationen in einem Attribut Variationen in anderen Attributen nicht überdecken.
scaler = StandardScaler()
features = scaler.fit\_transform(raw\_features)
- Implementieren Sie eine for-Schleife, um K-Means-Clustering für eine Anzahl von Clustern von 2 bis 6 auszuprobieren. Anschließend berechnen wir die Summe der Quadrate und stellen sie gegen die Anzahl der Cluster dar, um die optimale Anzahl von Clustern zu ermitteln.
sse = []
s\_scores=[]
for i in range(2,6):
kmeans = KMeans(init = **"random"** ,n\_clusters = i,n\_init = 10,max\_iter = 300,random\_state = 42)
kmeans.fit(features)
sse.append(kmeans.inertia\_)
s\_scores.append(silhouette\_score(features, kmeans.labels\_))
- Verwenden Sie die matplotlib-Bibliothek, um die Summe der Quadrate gegen die Anzahl der Cluster darzustellen.
plt.style.use( **"fivethirtyeight"** )
plt.plot(range(1, 6), sse)
plt.xticks(range(1, 6))
plt.xlabel( **"Number of Clusters"** )
plt.ylabel( **"SSE"** )
plt.show()
- Das Ausführen des obigen Codes führt zu einem Diagramm, das wir verwenden können, um die optimale Anzahl von Clustern zu ermitteln.
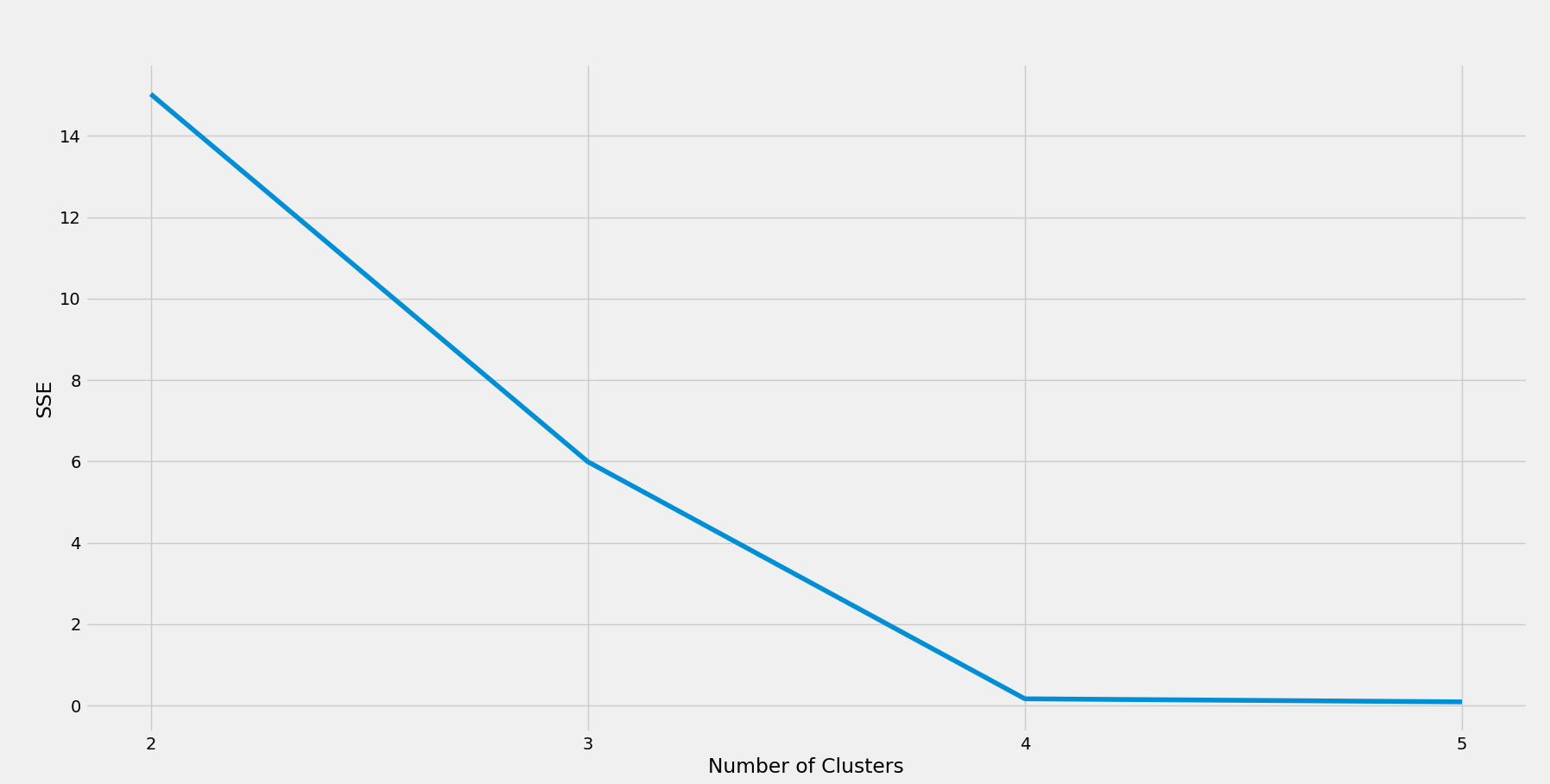 K-Means-Clustering
K-Means-Clustering
K-Means-Clustering-Algorithmus
Das obige Streudiagramm zeigt einen deutlichen „Ellbogen“ bei 4. Die optimale Anzahl von Clustern ist hier also 4. Mit etwas Domänenwissen kann ein Data Scientist diese Zahl als vier Kombinationen erklären – Kunden mit niedrigem Alter und hohen Ausgaben, niedrigem Alter und niedrigen Ausgaben, hohem Alter und hohen Ausgaben sowie hohem Alter und niedrigen Ausgaben. Solche Erklärungen sind jedoch möglicherweise nicht immer möglich, und die optimale Anzahl von Clustern variiert je nach Problemspezifikation.
Das ist alles, was zum Ausführen von K-Means-Clustering in Python gehört. Die Frameworks scikit-learn und matplotlib machen es sehr einfach, Clustering in Python zu verwenden.
Wann der K-Means-Clustering-Algorithmus verwendet werden sollte
Wie wir gelernt haben, ist Clustering also ein unüberwachter Machine-Learning-Algorithmus, der hilft, Objekte basierend auf Ähnlichkeit zu gruppieren. Er wird in vielen Branchenbereichen häufig für die explorative Datenanalyse eingesetzt.
Er ist in Bereichen wie Kundensegmentierung, Empfehlungssystemen und Ähnlichkeitssuche nützlich. Dennoch ist der K-Means-Clustering-Algorithmus nicht die einzige Technik, die zur Lösung dieser Probleme verwendet werden kann. Eine weitere Möglichkeit, ein solches Problem zu lösen, besteht darin, Vektoreinbettungen für jedes Objekt basierend auf seinen Attributen zu erzeugen.
Deep-Learning-basierte Trainingsnetzwerke können mehrdimensionale Einbettungen für Objekte mit einer großen Anzahl von Attributen erzeugen. Diese Einbettungen können in Verbindung mit einer guten Vektordatenbank ähnlichkeitsbasierte Probleme mit deutlich besserer Kontrolle lösen.
Wenn Sie an solchen Problemen arbeiten, sehen Sie sich Zilliz an. Es bietet eine Komplettlösung für Herausforderungen beim Umgang mit unstrukturierten Daten, insbesondere für Unternehmen, die AI/ML-Anwendungen erstellen, die Vektorähnlichkeitssuche nutzen.
Zilliz hat Milvus entwickelt, eine beliebte Open-Source-Vektordatenbank, die von über tausend Unternehmenskunden weltweit weithin anerkannt ist. Das Unternehmen bietet außerdem einen vollständig verwalteten Vektordatenbankdienst, Zilliz Cloud, an, der es Unternehmen ermöglicht, die volle Leistungsfähigkeit von Milvus zu nutzen, ohne sich um den Aufbau und die Verwaltung der Infrastruktur kümmern zu müssen.
Wenn Sie wissen möchten: Was ist eine Vektordatenbank? – können Sie sich den ausführlichen Leitfaden ansehen. Suchen Sie nach weiteren Informationen zu verwandten Themen? Sehen Sie sich diese Erklärung zu Approximate Nearest Neighbor Search (ANNS) an. Möchten Sie mehr darüber erfahren, wie Zilliz Ihnen helfen kann? Alles, was Sie tun müssen, ist, hier zu klicken und zu fragen!
Weiterlesen

Vector Lakebase: End the AI Data Silo
Learn how Vector Lakebase unifies vector search, data lakes, and AI data operations so teams can serve RAG and agents without copy-and-sync pipelines.

3 Easiest Ways to Use Claude Code on Your Mobile Phone
Run Claude Code from your phone with Remote Control, Happy Coder, or SSH + Tailscale. Comparison table, setup steps, and tools for typing, memory, and parallel tasks.

Similarity Metrics for Vector Search
Exploring five similarity metrics for vector search: L2 or Euclidean distance, cosine distance, inner product, and hamming distance.