




Einsatz eines multimodalen RAG-Systems mit vLLM und Milvus
Stellen Sie sich vor, Sie haben Monate damit verbracht, Ihre KI-Anwendung über einen API-Anbieter auf ein bestimmtes LLM abzustimmen. Dann, aus heiterem Himmel, erhalten Sie eine E-Mail: "Wir verwerfen das von Ihnen verwendete Modell zugunsten unserer neuen Version". Kommt Ihnen das bekannt vor? Cloud-API-Anbieter bieten zwar den Komfort leistungsstarker, sofort einsatzbereiter KI-Funktionen, doch die ausschließliche Nutzung dieser Funktionen birgt auch einige erhebliche Risiken:
- Mangel an Kontrolle: Sie haben keine Kontrolle über Modellversionen oder Updates.
- Unvorhersehbarkeit: Es kann zu plötzlichen Änderungen im Verhalten oder in den Fähigkeiten des Modells kommen.
- Beschränkter Einblick: Es gibt oft nur einen begrenzten Einblick in die Leistung und die Nutzungsmuster.
- Datenschutzbedenken: Der Datenschutz kann ein kritisches Thema sein, insbesondere beim Umgang mit sensiblen Informationen.
Was ist also die Lösung? Wie können Sie die Kontrolle zurückerlangen? Wie können Sie diese Risiken mindern und gleichzeitig die Fähigkeiten Ihres Systems verbessern? Die Antwort liegt im Aufbau eines robusteren, unabhängigen Systems unter Verwendung von Open-Source-Lösungen.
Dieser Blog führt Sie durch die Erstellung eines Multimodalen RAG mit [Milvus] (https://zilliz.com/what-is-milvus) und [vLLM] (https://zilliz.com/product/integrations/vllm). Durch die Nutzung der Leistungsfähigkeit einer quelloffenen Vektordatenbank in Kombination mit quelloffener LLM-Inferenz können Sie ein System entwickeln, das in der Lage ist, mehrere Datentypen zu verarbeiten und zu verstehen - Text, Bilder, Audio und sogar Videos. Dieser Ansatz gibt Ihnen nicht nur die vollständige Kontrolle über die Technologie, sondern gewährleistet auch ein System, das sowohl leistungsfähig als auch vielseitig ist und herkömmliche textbasierte Lösungen übertrifft.
Was wir bauen: ein multimodales RAG, das vollständig unter Ihrer Kontrolle steht
Wir werden ein Multimodales RAG-System mit Milvus und vLLM aufbauen, das zeigt, wie Sie Ihr LLM selbst hosten und die volle Kontrolle über Ihre KI-Anwendungen erhalten können. Unser Tutorial wird Sie durch die Erstellung einer Streamlit-Anwendung führen, die die Leistungsfähigkeit der Integration mehrerer Datentypen demonstriert. Das werden wir abdecken:
Verarbeiten von Video-Input durch Extrahieren von Frames und Transkribieren des Audios
Speichern und effizientes Indizieren multimodaler Daten mit Milvus
- Wir verwenden [OpenAI CLIP] (https://zilliz.com/learn/exploring-openai-clip-the-future-of-multimodal-ai-learning), um die Bilder in Einbettungen zu kodieren, die dann mit Milvus durchsucht werden können
- Wir verwenden das Mistral Embedding Modell, um den Text in Einbettungen zu kodieren.
Abrufen von relevantem Kontext auf der Grundlage von Benutzeranfragen mit Milvus
Generierung von Antworten mit Pixtral unter Verwendung von vLLM, wobei sowohl visuelles als auch textuelles Verständnis genutzt wird
Am Ende dieses Tutorials werden Sie ein flexibles, skalierbares System entwickelt haben, das Sie vollständig unter Kontrolle haben - Sie müssen sich keine Gedanken mehr über veraltete APIs oder unerwartete Änderungen machen.
Was ist Milvus?
Milvus ist eine quelloffene, leistungsstarke und hoch skalierbare Vektordatenbank, die Milliarden von unstrukturierten Daten durch hochdimensionale Vektoreinbettungen speichern, indizieren und durchsuchen kann. Sie eignet sich perfekt für den Aufbau moderner KI-Anwendungen wie Retrieval Augmented Generation (RAG), semantische Suche, multimodale Suche und Empfehlungssysteme. Milvus läuft effizient in verschiedenen Umgebungen, von Laptops bis zu großen verteilten Systemen.
Was ist vLLM?
Die Kernidee von vLLM (Virtual Large Language Model) ist die Optimierung der Bereitstellung und Ausführung von LLMs durch den Einsatz effizienter Speicherverwaltungstechniken. Hier sind die wichtigsten Aspekte:
- Optimierte Speicherverwaltung: vLLM implementiert fortschrittliche Speicherzuweisungs- und -verwaltungstechniken, um die verfügbaren Hardwareressourcen vollständig zu nutzen. Diese Optimierung hilft bei der effizienten Ausführung großer Sprachmodelle und verhindert Speicherengpässe, die die Leistung beeinträchtigen können.
- Dynamisches Batching: vLLM passt Stapelgrößen und Sequenzen basierend auf den Speicher- und Rechenkapazitäten der zugrunde liegenden Hardware an. Diese dynamische Anpassung erhöht den Verarbeitungsdurchsatz und minimiert die Latenzzeit während der Modellinferenz.
- Modularer Aufbau: Die Architektur von vLLM ist modular aufgebaut und erleichtert die problemlose Integration mit verschiedenen Hardware-Beschleunigern. Diese Modularität ermöglicht auch eine einfache Skalierung über mehrere Geräte oder Cluster hinweg, so dass die Lösung an unterschiedliche Einsatzszenarien angepasst werden kann.
- Effiziente Ressourcennutzung: vLLM optimiert die Nutzung kritischer Ressourcen wie CPUs, GPUs und Speicher. Diese Effizienz ermöglicht es dem System, größere Modelle zu unterstützen und eine höhere Anzahl gleichzeitiger Anfragen zu bewältigen, was in Produktionsumgebungen, in denen sowohl Skalierbarkeit als auch Leistung entscheidend sind, unerlässlich ist.
- Nahtlose Integration: vLLM wurde so konzipiert, dass es sich nahtlos in bestehende Frameworks und Bibliotheken für maschinelles Lernen integrieren lässt und bietet eine benutzerfreundliche Schnittstelle. Dadurch wird sichergestellt, dass Entwickler große Sprachmodelle in einer Reihe von Anwendungen ohne umfangreiche Neukonfiguration problemlos einsetzen und verwalten können.
Kernkomponenten unseres multimodalen RAG
Die multimodale RAG-Anwendung, die wir entwickeln, besteht aus den folgenden Hauptkomponenten:
- vLLM ist die Inferenzbibliothek, die wir für die Inferenz und Bereitstellung des multimodalen Modells von Pixtral verwenden werden.
- Koyeb stellt die Infrastrukturschicht für unseren Einsatz bereit und bietet eine serverlose Plattform, die auf KI-Workloads spezialisiert ist. Mit nativer vLLM-Integration und automatisiertem GPU-Ressourcenmanagement ist es einfach, LLM einzusetzen und gleichzeitig eine produktionsgerechte Leistung und Skalierbarkeit zu gewährleisten.
- Pixtral von Mistral AI fungiert als unser multimodales Gehirn und kombiniert einen 400M-Parameter-Vision-Encoder mit einem 12B-Parameter-Multimodal-Decoder. Diese Architektur ermöglicht es, sowohl Bilder als auch Text innerhalb desselben Kontextfensters zu verarbeiten.
- Milvus liefert die Grundlage für die Vektorspeicherung und verwaltet effizient Einbettungen aus verschiedenen Modalitäten. Seine Fähigkeit, mehrere Vektortypen zu verarbeiten und eine schnelle Ähnlichkeitssuche durchzuführen, macht es perfekt für multimodale Anwendungen.
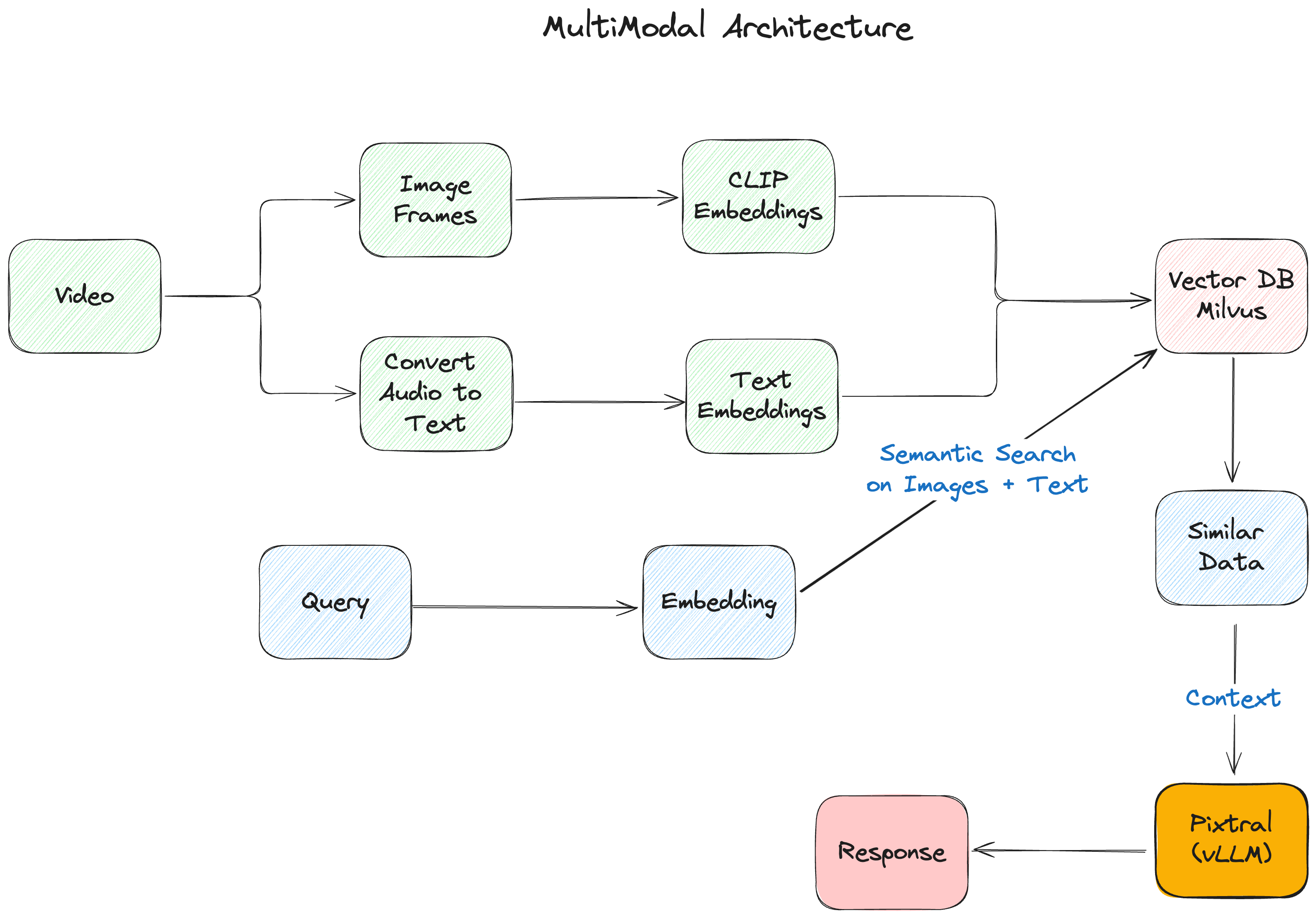 Abbildung- Die multimodale RAG-Architektur.png
Abbildung- Die multimodale RAG-Architektur.png
Abbildung: Die multimodale RAG-Architektur
Erste Schritte
Installieren wir zunächst unsere Abhängigkeiten:
# Kern-LlamaIndex-Pakete
pip install -U llama-index-vector-stores-milvus llama-index-multi-modal-llms-mistralai llama-index-embeddings-mistralai llama-index-multi-modal-llms-openai llama-index-embeddings-clip llama_index
# Video- und Audioverarbeitung
pip install moviepy pytube pydub SpeechRecognition openai-whisper ffmpeg-python soundfile
# Bildverarbeitung und Visualisierung
pip install torch torchvision matplotlib scikit-image git+https://github.com/openai/CLIP.git
# Dienstprogramme und Infrastruktur
pip install pymilvus streamlit ftfy regex tqdm
Einrichten der Umgebung
Wir beginnen damit, unsere Umgebung zu konfigurieren und die notwendigen Bibliotheken zu importieren:
importiere os
importiere base64
importiere json
from pathlib importieren Pfad
from dotenv importieren load_dotenv
from llama_index.core import Einstellungen
from llama_index.embeddings.mistralai importieren MistralAIEmbedding
# Umgebungsvariablen laden
load_dotenv()
# Standard-Einbettungsmodell konfigurieren
Einstellungen.embed_model = MistralAIEmbedding(
"mistral-embed",
api_key=os.getenv("MISTRAL_API_KEY")
)
Video Processing Pipeline
Das Herzstück unseres Systems ist die Videoverarbeitungspipeline, die rohe Videoinhalte in Daten umwandelt, die unser RAG-System verstehen und effizient verarbeiten kann.
def process_video(video_path: str, output_folder: str, output_audio_path: str) -> dict:
# Ausgabeverzeichnis erstellen, wenn es nicht existiert
Path(output_folder).mkdir(parents=True, exist_ok=True)
# Bilder aus dem Video extrahieren
video_to_images(video_path, output_folder)
# Audio extrahieren und transkribieren
video_zu_audio(video_pfad, output_audio_pfad)
text_data = audio_to_text(ausgabe_audio_pfad)
# Transkription speichern
with open(os.path.join(output_folder, "output_text.txt"), "w") as file:
file.write(text_data)
os.remove(ausgabe_audio_pfad)
return {"Autor": "Beispiel Autor", "Titel": "Beispiel Titel", "Ansichten": "1000000"}
Diese Pipeline unterteilt die Videos in:
- Einzelbilder (extrahiert mit 0,2 FPS)
- Audio-Transkription mit Whisper
- Metadaten über das Video
Erstellen des Vektorindexes
Wir verwenden Milvus, um unsere multimodalen Einbettungen zu speichern. Hier sehen Sie, wie wir unseren Index erstellen:
def create_index(output_folder: str):
# Verschiedene Sammlungen für Text und Bilder erstellen
text_store = MilvusVectorStore(
uri="milvus_local.db",
collection_name="text_collection",
overwrite=True,
dim=1024
)
image_store = MilvusVectorStore(
uri="milvus_local.db",
collection_name="image_collection",
overwrite=True,
dim=512
)
storage_context = StorageContext.from_defaults(
vector_store=text_store,
image_store=image_store
)
# Dokumente laden und indizieren
documents = SimpleDirectoryReader(output_folder).load_data()
return MultiModalVectorStoreIndex.from_documents(
documents,
storage_context=storage_context
)
Abfrageverarbeitung mit Pixtral
Wenn ein Benutzer eine Frage stellt, müssen wir das tun:
- Den relevanten Kontext aus unserem Vektorspeicher abrufen
- Die Anfrage mit Pixtral verarbeiten, wobei sowohl Text als auch Bilder verwendet werden.
Hier ist unsere Abfrageverarbeitungsfunktion:
def process_query_with_image(query_str, context_str, metadata_str, image_document):
client = OpenAI(
base_url=os.getenv("KOYEB_ENDPOINT"),
api_key=os.getenv("KOYEB_TOKEN")
)
with open(image_document.image_path, "rb") as image_file:
image_base64 = base64.b64encode(image_file.read()).decode("utf-8")
qa_tmpl_str = """
Anhand der bereitgestellten Informationen, einschließlich relevanter Bilder und des aus dem Video abgerufenen Kontexts
Kontext aus dem Video, genau und präzise die Abfrage beantworten, ohne
ohne zusätzliches Vorwissen.
---------------------
Kontext: {Kontext_str}
Metadaten: {metadata_str}
---------------------
Abfrage: {query_str}
Antwort: """
# Nachrichten für Pixtral vorbereiten
messages = [
{
"role": "Benutzer",
"content": [
{
"type": "text",
"text": qa_tmpl_str.format(
kontext_str=kontext_str,
query_str=query_str,
metadaten_str=metadaten_str
)
},
{
"type": "image_url",
"image_url": {
"url": f "data:image/jpeg;base64,{image_base64}"
}
},
],
}
]
completion = client.chat.completions.create(
model="mistralai/Pixtral-12B-2409",
messages=messages,
max_tokens=300
)
return abschluss.auswahlen[0].nachricht.inhalt
Aufbau der Streamlit-Schnittstelle
Schließlich erstellen wir eine benutzerfreundliche Schnittstelle mit Streamlit:
def main():
st.title("MultiModal RAG mit Pixtral & Milvus")
# Sitzungszustand initialisieren
if 'index' nicht in st.session_state:
st.session_state.index = None
st.session_state.retriever_engine = Keine
st.session_state.metadata = Keine
# Videoeingabe
video_path = st.text_input("Videopfad eingeben:")
if video_path und nicht st.session_state.index:
with st.spinner("Processing video..."):
# Video verarbeiten und Index erstellen
[... Verarbeitungscode ...]
if st.session_state.index:
st.subheader("Chat mit dem Video")
query = st.text_input("Stellen Sie eine Frage zum Video:")
if abfrage:
with st.spinner("Antwort generieren..."):
# Erzeugen und Anzeigen der Antwort
[... Abfrageverarbeitungscode ...]
if __name__ == "__main__":
main()
Ausführen der Anwendung
Bevor Sie die Anwendung starten, vergewissern Sie sich, dass Sie Folgendes haben:
- Richten Sie Ihre Umgebungsvariablen in
.envein. - Installieren Sie alle erforderlichen Abhängigkeiten
Starten Sie dann die Anwendung:
streamlit run app.py
Du wirst die Homepage sehen, auf der du das tun kannst:
- Videos zur Bearbeitung hochladen
- Fragen zum Inhalt des Videos stellen
- die Antworten von Pixtral mit den entsprechenden Videobildern lesen
 Abbildung- Die Schnittstelle Ihrer multimodalen RAG-App, erstellt mit Milvus und Pixtral.png
Abbildung- Die Schnittstelle Ihrer multimodalen RAG-App, erstellt mit Milvus und Pixtral.png
Abbildung: Die Schnittstelle Ihrer multimodalen RAG-App, die mit Milvus und Pixtral erstellt wurde
Von nun an können Sie mit dem Video interagieren und zum Beispiel mehr über die Gaußsche Verteilung erfahren.
 Abbildung- Durchführen der multimodalen Suche.png
Abbildung- Durchführen der multimodalen Suche.png
Abbildung: Durchführen der multimodalen Suche
Schlussfolgerung
In diesem Blogbeitrag haben wir gezeigt, wie man mit Milvus, Pixtral und vLLM ein leistungsfähiges multimodales RAG-System aufbaut. Durch die Kombination der effizienten Vektorspeicherfähigkeiten von Milvus und des fortschrittlichen multimodalen Verständnisses von Pixtral haben wir ein System geschaffen, das Abfragen zu Videoinhalten verarbeiten, verstehen und beantworten kann. Und dieses System ist vollständig unter Ihrer Kontrolle.
Wir würden gerne hören, was Sie denken!
Wenn Ihnen dieser Blog-Beitrag gefallen hat, ziehen Sie ihn bitte in Betracht:
- ⭐ Geben Sie uns einen Stern auf GitHub
- 💬 Treten Sie unserer Milvus Discord Community bei, um Ihre Erfahrungen zu teilen
- 🔍 Erkunden Sie unser Bootcamp-Repository für weitere Beispiele multimodaler Anwendungen mit Milvus

Weiterlesen

3 Easiest Ways to Use Claude Code on Your Mobile Phone
Run Claude Code from your phone with Remote Control, Happy Coder, or SSH + Tailscale. Comparison table, setup steps, and tools for typing, memory, and parallel tasks.

How to Install and Run OpenClaw (Previously Clawdbot/Moltbot) on Mac
Turn your Mac into an AI gateway for WhatsApp, Telegram, Discord, iMessage, and more — in under 5 minutes.

Zilliz Cloud Introduces Advanced BYOC-I Solution for Ultimate Enterprise Data Sovereignty
Explore Zilliz Cloud BYOC-I, the solution that balances AI innovation with data control, enabling secure deployments in finance, healthcare, and education sectors.