




Auswahl des richtigen Einbettungsmodells für Ihre Daten
Was sind Einbettungsmodelle?
Einbettungsmodelle sind Modelle für maschinelles Lernen, die unstrukturierte Daten (Text, Bilder, Audio usw.) in Vektoren fester Größe umwandeln, die auch als Vektoreinbettungen (sparse, dense, binäre Einbettung usw.) bezeichnet werden. Diese Vektoren erfassen die semantische Bedeutung der unstrukturierten Daten und erleichtern so die Durchführung verschiedener Aufgaben wie Ähnlichkeitssuche, Verarbeitung natürlicher Sprache (NLP), Computer Vision, Clustering, Klassifizierung usw.
Es gibt verschiedene Arten von Einbettungsmodellen, darunter Worteinbettungen, Satzeinbettungen, Bildeinbettungen, multimodale Einbettungen und viele mehr.
Worteinbettungen: Repräsentieren Wörter als dichte Vektoren. Beispiele sind Word2Vec, GloVe und FastText.
Satzeinbettungen: Repräsentieren ganze Sätze oder Absätze. Beispiele hierfür sind Universal Sentence Encoder (USE) und Sentence-BERT.
Bildeinbettungen: Stellen Bilder als Vektoren dar. Beispiele hierfür sind Modelle wie ResNet und CLIP.
Multimodale Einbettungen: Kombinieren verschiedene Datentypen (z. B. Text und Bilder) in einem einzigen Einbettungsraum. CLIP von OpenAI ist ein bemerkenswertes Beispiel.
**Einbettungsmodelle und Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) ist ein Muster in der generativen KI, bei dem Sie Ihre Daten verwenden können, um das Wissen des LLM-Generatormodells (wie ChatGPT) zu erweitern. Dieser Ansatz ist eine perfekte Lösung, um die lästigen Halluzinationsprobleme von LLMs anzugehen. Er kann Ihnen auch dabei helfen, Ihre domänenspezifischen oder privaten Daten zu nutzen, um GenAI-Anwendungen zu entwickeln, ohne dass Sie sich über Datensicherheitsprobleme Gedanken machen müssen.
RAG besteht aus zwei verschiedenen Modellen, den Einbettungsmodellen und den großen Sprachmodellen (LLMs), die beide im Inferenzmodus verwendet werden. In diesem Blog wird vorgestellt, wie man das beste Einbettungsmodell auswählt und wo man es auf der Grundlage der Art der Daten und möglicherweise der Sprache oder des Fachgebiets (z. B. Recht) findet.
Wie Sie das beste Einbettungsmodell für Ihre Daten auswählen
Um das richtige Einbettungsmodell für Ihre Daten auszuwählen, müssen Sie Ihren spezifischen Anwendungsfall, die Art Ihrer Daten und die Leistungsanforderungen Ihrer Anwendung kennen.
Textdaten: MTEB Bestenliste
Das HuggingFace MTEB-Leaderboard ist ein One-Stop-Shop für die Suche nach Texteinbettungsmodellen! Für jedes Einbettungsmodell können Sie die durchschnittliche Leistung bei allen Aufgaben sehen.
Ein guter Einstieg ist es, absteigend nach der Spalte "Retrieval Average" zu sortieren, da dies die Aufgabe ist, die am meisten mit der Vektorsuche zu tun hat. Suchen Sie dann nach dem am besten bewerteten kleinsten Modell (GB Speicher).
- Die Einbettungsdimension ist die Länge des Vektors, d. h. der y-Teil in f(x)=y, den das Modell ausgibt.
Max Token ist die Länge des Eingabetextes, d. h. des x-Teils in f(x)=y, den Sie in das Modell eingeben können.
Zusätzlich zur Retrieval-Aufgabe können Sie auch filtern nach:
- Sprache: Französisch, Englisch, Chinesisch oder Polnisch. Zum Beispiel: Aufgabe=Abrufen und Sprache=Chinesisch.
Rechtlich: Zum Beispiel Aufgabe=Retrieval und Sprache=Recht, für Modelle, die auf juristische Texte abgestimmt sind.
Da die Trainingsdaten erst seit kurzem öffentlich zugänglich sind, sind einige MTEB-Einträge leider überangepasste Modelle, die täuschend besser abschneiden, als sie realistischerweise auf Ihren Daten leisten. In diesem Blog von HuggingFace finden Sie Tipps, wie Sie entscheiden können, ob Sie einem Modell-Ranking vertrauen. Klicken Sie auf den Modell-Link (die sogenannte "Modellkarte").
Suchen Sie nach Blogs und Artikeln, die erklären, wie das Modell trainiert und bewertet wurde. Schauen Sie sich sorgfältig die Sprachen, Daten und Aufgaben an, für die das Modell trainiert wurde. Suchen Sie auch nach Modellen, die von seriösen Unternehmen erstellt wurden. Auf der Modellkarte voyage-lite-02-instruct sind zum Beispiel andere VoyageAI-Modelle aus der Produktion aufgeführt, nicht aber dieses. Das ist ein Hinweis! Dieses Modell ist ein Vanity-Overfit-Modell. Verwenden Sie es nicht!
- Im Screenshot unten würde ich den neuen Eintrag von Snowflake, "snowflake-arctic-embed-1", ausprobieren, weil er hochrangig ist, klein genug ist, um auf meinem Laptop zu laufen, und die Modellkarte Links zu einem Blog und einer Zeitung enthält.
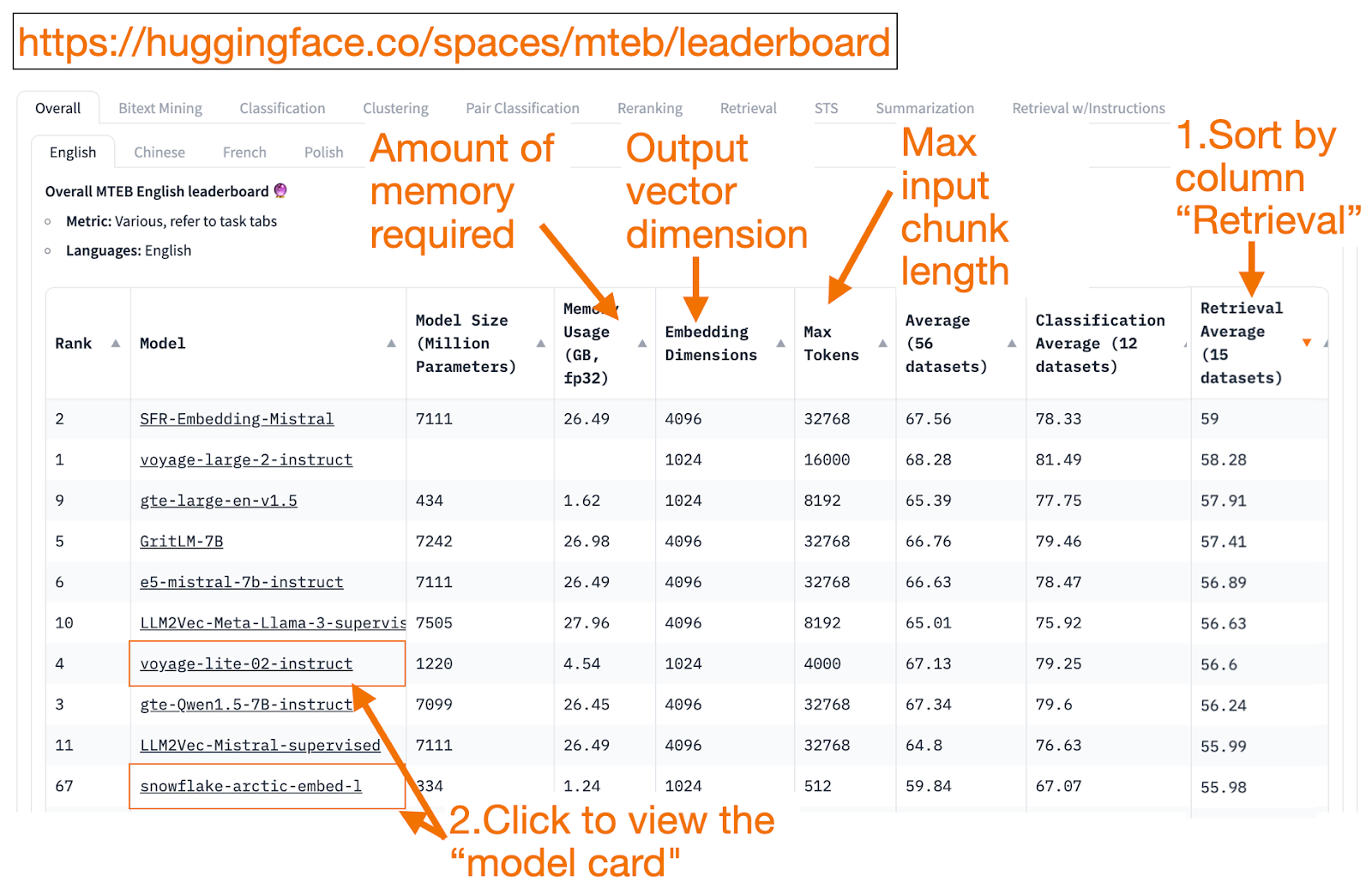 Screenshot von Snowflake auf der MTEB-Rangliste
Screenshot von Snowflake auf der MTEB-Rangliste
Das Schöne an der Verwendung von HuggingFace-Modellen ist, dass man das Modell ändern kann, indem man den **model_name** im Code ändert, sobald man sein Einbettungsmodell ausgewählt hat!
torch importieren
from sentence_transformers import SentenceTransformer
# Torch-Einstellungen initialisieren
torch.backends.cudnn.deterministic = True
DEVICE = torch.device('cuda:3' if torch.cuda.is_available() else 'cpu')
# Laden Sie das Modell von huggingface.
model_name = "WhereIsAI/UAE-Large-V1" # Ändern Sie einfach model_name, um ein anderes Modell zu verwenden!
encoder = SentenceTransformer(model_name, device=DEVICE)
# Ermitteln Sie die Modellparameter und speichern Sie sie für später.
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Modellparameter ausgeben.
print(f "model_name: {model_name}")
print(f "EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f "MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH_IN_TOKENS}")

Bilddaten: ResNet50
Manchmal möchte man nach ähnlichen Bildern wie einem Eingabebild suchen. Vielleicht suchen Sie nach weiteren Bildern von Scottish Fold-Katzen? In diesem Fall würden Sie Ihr Lieblingsbild einer Scottish Fold-Katze hochladen und die Suchmaschine bitten, ähnliche Bilder zu finden!
ResNet50 ist ein beliebtes Convolutional Neural Network (CNN) Modell, das ursprünglich im Jahr 2015 von Microsoft auf ImageNet-Daten trainiert wurde.
Auch für die umgekehrte Videosuche kann ResNet50 noch Videos einbetten. Dann wird eine umgekehrte Bildähnlichkeitssuche mit der Videostandbilddatenbank durchgeführt. Das nächstgelegene Video (ohne die Eingabe) wird dem Benutzer als das ähnlichste Video zurückgegeben.
Ton-Daten: PANNs
Ähnlich wie bei der umgekehrten Bildersuche anhand eines eingegebenen Bildes könnte man auch die Suche nach Audioclips anhand eines eingegebenen Tonstücks umkehren.
PANNs (Pretrained Audio Neural Networks) sind beliebte Einbettungsmodelle für diese Aufgabe, da sie auf großen Audiodatensätzen vortrainiert sind und sich für Aufgaben wie Audioklassifizierung und Tagging eignen.
Multimodale Bild- und Textdaten: SigLIP oder Unum
In den letzten Jahren sind Einbettungsmodelle entstanden, die auf einer Mischung aus [unstrukturierten Daten] (https://zilliz.com/glossary/unstructured-data) trainiert werden: Text, Bild, Audio oder Video. Solche Einbettungsmodelle erfassen die Semantik mehrerer Arten von unstrukturierten Daten auf einmal im selben Vektorraum.
Multimodale Einbettungsmodelle ermöglichen die Verwendung von Text für die Suche nach Bildern, die Erstellung von Textbeschreibungen für Bilder oder die umgekehrte Bildsuche anhand eines Eingabebildes.
CLIP (Contrastive Language-Image Pretraining) von OpenAI aus dem Jahr 2021 war früher das Standard-Einbettungsmodell. Praktiker fanden es jedoch schwer zu verwenden, da es einer Feinabstimmung bedurfte. Im Jahr 2024 scheint SigLIP oder sigmoidal-CLIP von Google ein verbessertes CLIP zu sein, mit Berichten über gute Ergebnisse bei der Verwendung von zero-shot Prompts.
Kleine Modellvarianten von LLMs werden immer beliebter. Anstatt einen großen Cloud-Computing-Cluster zu benötigen, können sie auf Laptops laufen (wie mein M2 Apple mit nur 16 GB RAM). Kleine Modelle benötigen weniger Speicher, was bedeutet, dass sie eine geringere Latenz aufweisen und potenziell schneller laufen können als große Modelle. Unum bietet multimodale kleine Einbettungsmodelle an.
Multimodale Text- und/oder Ton- und/oder Videodaten
Die meisten multimodalen Text-zu-Ton-RAG-Systeme verwenden ein multimodales generatives LLM, um zunächst Ton in Text umzuwandeln. Sobald die Ton-Text-Paare erstellt sind, wird der Text in Vektoren eingebettet, und Sie können Ihre RAG verwenden, um den Text auf die übliche Weise abzurufen. Im letzten Schritt wird der Text wieder in Ton umgewandelt, um die Schleife Text-zu-Ton oder umgekehrt zu beenden.
Whisper von OpenAI kann Sprache in Text umwandeln.
Text-to-Speech (TTS) von OpenAI kann ebenfalls Text in gesprochenes Audio umwandeln.
Multimodale Text-zu-Video-RAG-Systeme verwenden einen ähnlichen Ansatz, um Videos zunächst in Text umzuwandeln, den Text einzubetten, den Text zu durchsuchen und Videos als Suchergebnisse zurückzugeben.
[Sora] (https://openai.com/index/sora) von OpenAI kann Text in Video umwandeln. Ähnlich wie bei Dall-e geben Sie den Text vor, und der LLM erzeugt ein Video. Sora kann auch Videos aus Standbildern oder anderen Videos erzeugen.
Zusammenfassung
In diesem Blog wurden einige beliebte Einbettungsmodelle behandelt, die in [RAG-Anwendungen] (https://zilliz.com/learn/Retrieval-Augmented-Generation) verwendet werden.
Weitere Ressourcen
Referenzen
MTEB-Rangliste, Papier, Github: https://huggingface.co/spaces/mteb/leaderboard
Bewährte MTEB-Verfahren zur Vermeidung der Wahl eines überangepassten Modells: https://huggingface.co/blog/lyon-nlp-group/mteb-leaderboard-best-practices
Suche nach ähnlichen Bildern: https://milvus.io/docs/image_similarity_search.md
Bild-zu-Video-Suche: https://milvus.io/docs/video_similarity_search.md
Suche nach ähnlichen Tönen: https://milvus.io/docs/audio_similarity_search.md
Text-zu-Bild-Suche: https://milvus.io/docs/text_image_search.md
2024 SigLIP (sigmoid loss CLIP) paper: https://arxiv.org/pdf/2401.06167v1
Multimodale Einbettungsmodelle im Taschenformat von Unum: https://github.com/unum-cloud/uform

Weiterlesen

Data Deduplication at Trillion Scale: How to Solve the Biggest Bottleneck of LLM Training
Explore how MinHash LSH and Milvus handle data deduplication at the trillion-scale level, solving key bottlenecks in LLM training for improved AI model performance.

Vector Databases vs. Document Databases
Use a vector database for similarity search and AI-powered applications; use a document database for flexible schema and JSON-like data storage.

Proactive Monitoring for Vector Database: Zilliz Cloud Integrates with Datadog
we're excited to announce Zilliz Cloud's integration with Datadog, enabling comprehensive monitoring and observability for your vectorDB deployments.