




Wie Sie den richtigen Milvus-Bereitstellungsmodus für Ihre KI-Anwendungen auswählen
Milvus ist eine Open-Source-Vektordatenbank, die Milliarden von Vektoreinbettungen speichert, indiziert und abruft. Sie ist auch eine unverzichtbare Komponente der Retrieval Augmented Generation (RAG), einer beliebten und effektiven Technik zur Abschwächung von Halluzinationen in großen Sprachmodellen (LLMs).
Im Gegensatz zu anderen Open-Source-Vektorsuchprojekten wie Qdrant, Weaviate und Chroma bietet Milvus den Entwicklern drei wichtige Einsatzoptionen, die auf unterschiedliche Datensatzgrößen, Anwendungsfälle und Geschäftsanforderungen abgestimmt sind. Die große Auswahl ist zwar ein Vorteil, kann aber auch ein wenig überwältigend sein. Viele Entwickler sind sich nicht sicher, wie sie den besten Bereitstellungsmodus für ihre spezifischen KI-Anwendungen auswählen sollen. In diesem Blog-Beitrag geben wir Ihnen eine klare und detaillierte Anleitung, die Ihnen hilft, die richtige Milvus-Version für Ihre Projekte auszuwählen.
Milvus Lite vs. Standalone vs. Verteilt
Milvus bietet drei Bereitstellungsoptionen: Milvus Lite, Standalone und Verteilt.
Milvus Lite
Milvus Lite ist eine Python-Bibliothek und eine ultra-leichte Version von Milvus. Sie ist perfekt für schnelles Prototyping in Python- oder Notebook-Umgebungen und für kleine lokale Experimente. Sie können sie direkt über das pymilvus-Paket mit einer einfachen Zeile pip install pymilvus installieren. Es besteht keine Notwendigkeit, einen separaten Server zu betreiben, und die Datenpersistenz erfolgt über lokale Dateien, was die Einrichtung und Verwendung vereinfacht.
Milvus Standalone
Milvus Standalone ist die Einzelknoten-Option für Milvus, die ein Client-Server-Modell verwendet. Man kann es sich als das Milvus-Äquivalent zu MySQL vorstellen, während Milvus Lite mit SQLite vergleichbar ist. Alle Milvus Standalone-Komponenten sind in einem Docker-Image gebündelt, was die Serverbereitstellung sehr einfach macht. Der Betrieb einer einzelnen Milvus Standalone-Instanz auf einem Rechner mit ausreichend Speicher ist für die meisten Projekte, die keine umfangreiche Skalierung erfordern, ausreichend. Darüber hinaus bietet Milvus Standalone hohe Verfügbarkeit mit einem primären Backup-Modus, was es zu einer zuverlässigen Wahl für Produktionsumgebungen macht.
Milvus Verteilt
Milvus Distributed ist der verteilte Modus von Milvus, der ideal für Unternehmensanwender ist, die große Vektordatenbank-Systeme oder Vektordaten-Plattformen aufbauen. Milvus Distributed verwendet eine Cloud-native Architektur mit Lese- und Schreibtrennung, um die Leistung zu optimieren. Die Schlüsselkomponenten von Milvus Distributed sind mit eingebauten Backups und zusätzlichen Instanzen ausgestattet, so dass bei einem Ausfall eines Teils andere nahtlos übernehmen können, um sicherzustellen, dass das System nicht unterbrochen wird. Dieses Maß an Redundanz erhöht die Zuverlässigkeit und garantiert [kontinuierliche Verfügbarkeit] (https://zilliz.com/learn/ensuring-high-availability-of-vector-databases). Von den drei Bereitstellungsoptionen bietet Milvus Distributed die höchste Skalierbarkeit und Verfügbarkeit. Es bietet auch Elastizität auf Komponentenebene, so dass Sie Proxy, Abfrageknoten und Indexknoten unabhängig voneinander skalieren können, je nach Ihren spezifischen geschäftlichen Lastanforderungen.
Die folgende Tabelle fasst die wichtigsten Funktionen von Milvus Lite, Milvus Standalone und Milvus Distributed zusammen und vergleicht sie.
| Fähigkeiten | Milvus Lite | Milvus Standalone | Milvus Distributed |
| SDK | Python | Python, Go, Java, Node.js, C#, RESTful | Python, Go, Java, Node.js, C#, RESTful |
| Datentypen | Dichte VektorenSparse VektorenBinäre Vektoren Boolesche Skalare Integer Skalare Float Skalare Strings Arrays JSON | Dichte VektorenSparse VektorenBinäre Vektoren Boolesche Skalare Integer Skalare Float Skalare Strings Arrays JSON | Dichte VektorenSparse VektorenBinäre Vektoren Boolesche Skalare Integer Skalare Float Skalare Strings Arrays JSON |
| Suche | Vektorsuche (ANN-Suche)Gefilterte Vektorsuche BereichssucheHybride Suche Skalare Ausdrucksabfrage Primärschlüsselabfrage (get) | Vektorsuche (ANN-Suche)Gefilterte Vektorsuche BereichssucheHybride Suche Skalare Ausdrucksabfrage Primärschlüsselabfrage (get) | Vektorsuche (ANN-Suche)Gefilterte Vektorsuche BereichssucheHybride Suche Skalare Ausdrucksabfrage Primärschlüsselabfrage (get) |
| Grundlegende CRUD-Fähigkeiten | ✔️ | ✔️ | ✔️ |
| Erweiterte Funktionen | - | RBAC (rollenbasierte Zugriffskontrolle) | RBAC (rollenbasierte Zugriffskontrolle) Sharding Partition Partition Key Physikalische Ressourcengruppierung |
| Konsistenz | Stark | Stark Begrenzte Staleness Session Eventually | Stark Begrenzte Staleness Session Eventually |
Tabelle: Vergleich von Milvus Lite, Milvus Standalone und Milvus Distributed
Wie man die richtige Milvus-Implementierung für jede Entwicklungsphase auswählt
Die Wahl der geeigneten Milvus-Bereitstellungsoption hängt von der Phase Ihrer Anwendungsentwicklung ab. Zu diesen Phasen gehören Rapid Prototyping, Early Production Deployment und Large-Scale Production Deployment. Lassen Sie uns jede Phase im Detail betrachten.
Milvus Lite für Rapid Prototyping von KI-Anwendungen
Bei der Entwicklung und dem Prototyping von KI-Anwendungen, wie z. B. einem persönlichen Assistenten, einer [semantischen Suchmaschine] (https://zilliz.com/glossary/semantic-search) oder einer End-to-End-RAG, haben die Geschwindigkeit und Flexibilität der Anwendung in der Regel Vorrang vor der Leistung und Stabilität. Daher ist Milvus Lite in diesem Stadium eine ideale Wahl. Mit Milvus Lite können Sie schnell eine End-to-End-Funktionalität in einer Notebook-Umgebung erstellen und leichtgewichtige Experimente durchführen, die sich auf das Testen der Effektivität konzentrieren.
Übergang zu Milvus Standalone für die Validierung von großen Datensätzen
Milvus Standalone ist der nächste logische Schritt, wenn Sie Ihre Ergebnisse auf einem großen Datenbestand validieren müssen. Milvus Lite und Standalone sind so konzipiert, dass sie nahtlos zusammenarbeiten und einen einfachen Übergang vom lokalen Prototyping zur serverbasierten Validierung bieten. Da Milvus Lite, Standalone und Distributed dieselbe Client-Schnittstelle nutzen, können Sie dieselbe Geschäftslogik sowohl für lokale als auch für umfangreiche Datenvalidierungen wiederverwenden. Darüber hinaus unterstützt Milvus Standalone mehrere Benutzer, was es agilen Entwicklungsteams erleichtert, mit einer einzigen Instanz zusammenzuarbeiten oder Daten gemeinsam zu nutzen.
Milvus Standalone für die frühe Produktionsbereitstellung
In der Anfangsphase der App-Produktion, wenn Ihr Projekt gerade erst gestartet wurde und sich noch in der Phase der Produkt-Markt-Anpassung befindet, sind die Geschäftsanforderungen und Datenmengen relativ gering. Der Schwerpunkt sollte eher auf der geschäftlichen Effektivität und Wettbewerbsfähigkeit als auf der Infrastruktur liegen. Milvus Standalone ist für diese Phase gut geeignet. Bei Online-Diensten sorgt der Einsatz von Milvus in einem hochverfügbaren primären Backup-Modus für Zuverlässigkeit. Für Testumgebungen ist in der Regel eine Einzelknotenbereitstellung ausreichend.
Hinweis: Milvus Standalone bietet keine physische Ressourcenisolierung zwischen Tabellen. Wenn Sie zwei kritische, leistungsempfindliche Anwendungen haben, ist es besser, deren Daten mit separaten Milvus Standalone-Instanzen zu isolieren. Dies kann zwar zu einer gewissen Ressourcenineffizienz führen, ist aber immer noch kostengünstiger als die Verwaltung einer verteilten Milvus-Installation in diesem Stadium.
Sie können Milvus Lite weiterhin für spezifische Debugging-Aufgaben verwenden, sollten dies aber nicht in der Produktionsumgebung tun, in der Milvus Standalone eingesetzt wird, da dies zu Leistungs- und Stabilitätsrisiken führen könnte.
Milvus Distributed für den groß angelegten Produktionseinsatz
Wenn Ihre Daten über die Kapazität eines einzelnen Servers hinauswachsen oder schnell wachsen, ist es an der Zeit, sich auf die zukünftige Skalierbarkeit vorzubereiten. Milvus Distributed wird in dieser Phase unverzichtbar.
Bei dieser bewährten Methode werden anfangs sowohl Milvus Standalone- als auch Milvus Distributed-Instanzen gleichzeitig betrieben und der Datenverkehr schrittweise von Standalone auf Distributed verlagert. Stellen Sie sicher, dass Sie das System mindestens einen Monat lang überwachen, bis Milvus Distributed stabil läuft.
Während dieser Phase müssen Sie auch Ihr Betriebsmanagement verbessern. Milvus Distributed unterstützt von Haus aus Prometheus und bietet Management-Tools wie [Attu] (https://zilliz.com/attu). Milvus bietet zwar eine breite Palette an speziellen Betriebstools und Ecosystem-Integrationen, aber die Verwaltung eines großen verteilten Systems kann eine Herausforderung sein. Wir ermutigen Sie, der offenen und aktiven Milvus-Community beizutreten, um Unterstützung anzufordern, Code beizutragen, an Veranstaltungen teilzunehmen und viele andere wertvolle Beiträge zu leisten.
Wie Sie die richtige Bereitstellung für Ihre Vektordatensätze wählen
Milvus ist so konzipiert, dass es mit Ihrem Projekt mitwächst und bietet verschiedene Bereitstellungsmodi, um den sich entwickelnden Anforderungen Ihres Datensatzes zu entsprechen. Um die Unterschiede zu verdeutlichen, werden wir aufschlüsseln, wie Milvus Lite, Standalone und Distributed im Vergleich zueinander und, was noch wichtiger ist, zu anderen [Open-Source-Vektordatenbanken] (https://zilliz.com/comparison) auf dem Markt wie Chroma, [Weaviate] (https://zilliz.com/comparison/milvus-vs-weaviate) und [Qdrant] (https://zilliz.com/comparison/milvus-vs-qdrant) abschneiden.
Chroma hat seit letztem Jahr unter Entwicklern an Zugkraft gewonnen, insbesondere für kleinere Projekte. Wie Milvus Lite ist auch Chroma eine leichtgewichtige Vektordatenbank. Sie eignet sich am besten für Anwendungen, die weniger als Hunderttausende von Vektoren verarbeiten. Chroma bietet grundlegende Funktionen wie das Einfügen von Vektordaten und die Ähnlichkeitssuche, was es zu einer leichtgewichtigen Option für das schnelle Prototyping macht. Aufgrund des begrenzten Funktionsumfangs und der mangelnden Produktionsreife bietet jedoch selbst Milvus Lite robustere Funktionen.
Für produktionsreife Lösungen sind Milvus Standalone und Distributed, zusammen mit Weaviate und Qdrant, die bessere Wahl. Weaviate ist bekannt für seine Integration mit KI-Anwendungen und bietet native Unterstützung für verschiedene Upstream-Modelle. Qdrant hingegen konzentriert sich auf die Kernfunktionalitäten von Vektordatenbanken mit Schwerpunkt auf der Vektorsuchleistung. Laut [VectorDBBench] (https://zilliz.com/learn/open-source-vector-database-benchmarking-your-way), einem Open-Source-Benchmarking-Tool für Vektordatenbanken, übertrifft Milvus jedoch Qdrant in Bezug auf die [Suchleistung] (https://zilliz.com/learn/benchmark-vector-database-performance-techniques-and-insights), was es zu einem Top-Anwärter in diesem Bereich macht.
Im Folgenden finden Sie eine Aufschlüsselung der geeigneten Datenskalen für jede Vektordatenbank:
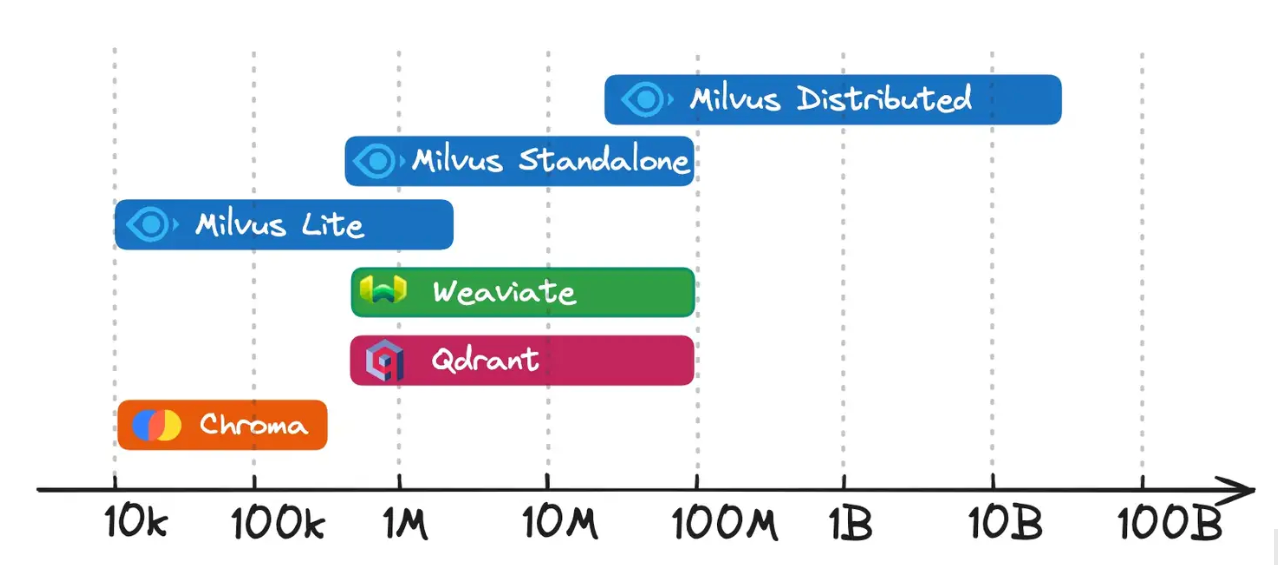 Abbildung 2- Milvus vs. Chroma vs. Qdrant vs. Weaviate für die Speicherung und den Abruf von Vektoren
Abbildung 2- Milvus vs. Chroma vs. Qdrant vs. Weaviate für die Speicherung und den Abruf von Vektoren
Milvus Lite und Chroma sind ideal für die Datenskalierung bis zu einer Million Vektoren. Sie sind auf Benutzerfreundlichkeit ausgelegt, wobei einige Systemfunktionen der Einfachheit halber geopfert werden.
Milvus Standalone, Weaviate und Qdrant: Am besten geeignet für Datenmengen von einer Million bis zu mehreren zehn Millionen Vektoren. Diese Datenbanken bieten ein ausgewogenes Verhältnis zwischen leistungsstarken Systemfunktionen und Benutzerfreundlichkeit, so dass sie sich für die frühe Produktionsphase eignen.
Milvus Verteilt: Entwickelt für die Verarbeitung von Datenmengen im Bereich von zig Millionen und mehr_. Die Milvus-Gemeinschaft hat die Unterstützung für Anwendungsfälle im Milliardenbereich validiert, und sie wird jetzt für Situationen mit mehreren Milliarden Vektoren implementiert.
Andere Vektordatenbanken wie Chroma, Weaviate und Qdrant haben zwar ihre Stärken, bieten aber oft nicht das gleiche Maß an Flexibilität, Skalierbarkeit und langfristigem Support wie Milvus. Wenn Ihr Projekt wächst, kann ein Wechsel der Vektordatenbank kostspielig und komplex werden. Milvus unterstützt mit seinen vielseitigen Bereitstellungsoptionen gemischte Workflows über verschiedene Datenskalen hinweg und stellt so sicher, dass Sie nicht über Ihre Datenbanklösung hinauswachsen.
Milvus Lite, eigenständige und verteilte zugrundeliegende Komponenten
Milvus bietet dank der gemeinsamen zugrundeliegenden Komponenten eine konsistente Benutzererfahrung und eine einheitliche Entwicklung über seine drei Bereitstellungsmodi hinweg. Dieses Design stellt sicher, dass Sie von derselben Kernfunktionalität profitieren, unabhängig davon, ob Sie Milvus Lite für leichtgewichtige Aufgaben oder Milvus Distributed für groß angelegte Operationen verwenden.
Das folgende Diagramm veranschaulicht die funktionalen Komponenten, die von jedem dieser Milvus-Bereitstellungsmodi abgedeckt werden:
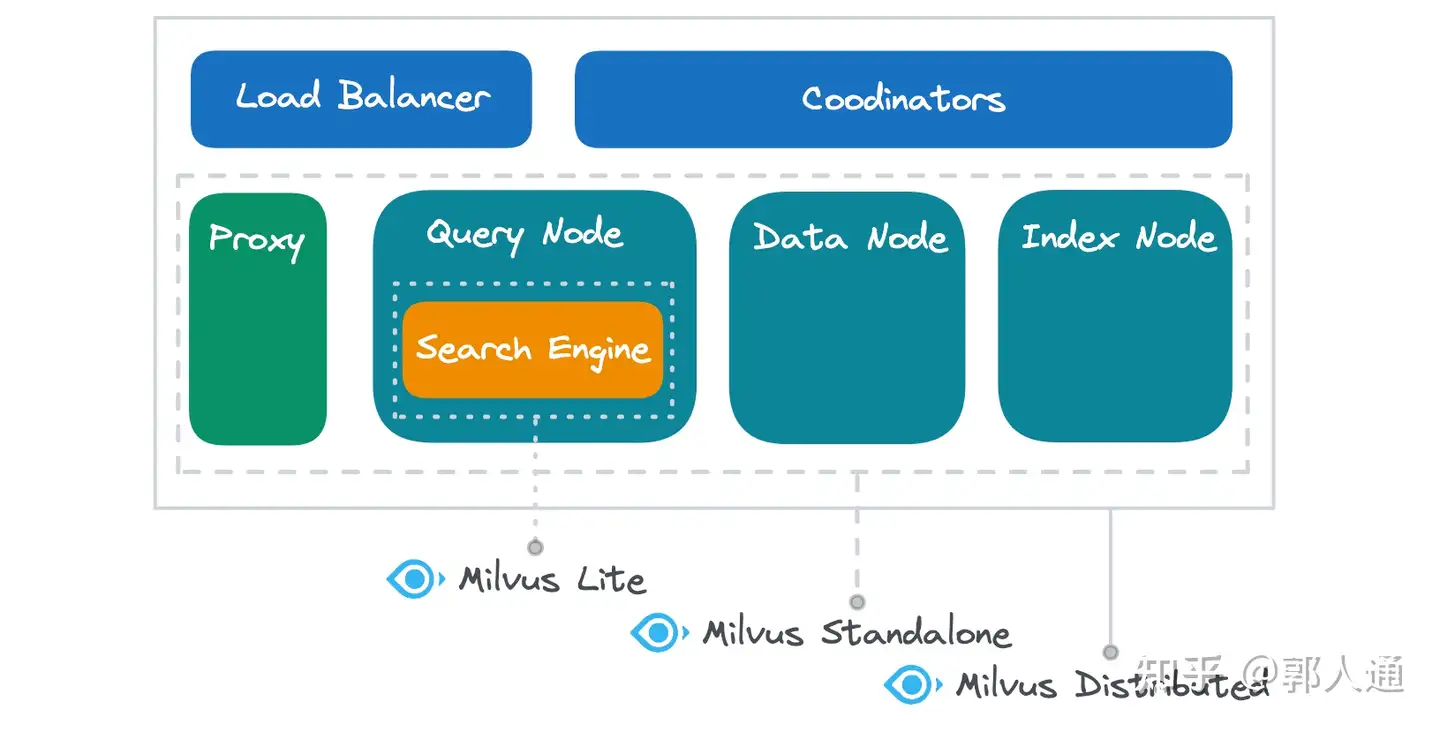 Abbildung 2- Milvus Lite vs. Standalone vs. Distributed auf zugrunde liegenden Komponenten
Abbildung 2- Milvus Lite vs. Standalone vs. Distributed auf zugrunde liegenden Komponenten
Milvus Lite kapselt in erster Linie die Suchmaschine, bietet aber auch lokale Implementierungen für wesentliche Aufgaben wie Dateneinfügung, Persistenz, Indexerstellung und Metadatenverwaltung. Betrachten Sie Milvus Lite eher als eine leistungsstarke Bibliothek denn als ein einfaches Werkzeug. Im Vergleich zu einfacheren Bibliotheken wie Chroma bietet die Suchmaschine von Milvus Lite eine höhere Leistung und bessere Abfragemöglichkeiten, was sie ideal für Vektoreinbettungen macht. Wenn Sie eine Alternative zu FAISS oder HNSWLib suchen, ist Milvus Lite ein guter Kandidat, da es die wichtigsten vector search Algorithmus-Bibliotheken nativ integriert und sowohl hinsichtlich der Leistung als auch der Funktionalität umfassend optimiert wurde.
Milvus Standalone enthält alle funktionalen Komponenten des Milvus-Systems mit Ausnahme des Lastausgleichs und der Verwaltung mehrerer Knoten (Koordinatoren). Diese Komponenten arbeiten innerhalb derselben Docker-Umgebung, was eine effiziente lokale Kommunikation ermöglicht und die Server-Latenzzeit minimiert.
Milvus Distributed verfügt über eine vollständige Palette an funktionalen Komponenten. Während sowohl der Standalone- als auch der Distributed-Modus einen Proxy, einen Abfrageknoten, einen Datenknoten und einen Indexknoten mit identischen Funktionen enthalten, bietet Milvus Distributed eine größere Flexibilität bei der Bereitstellung. Jede funktionale Komponente kann mehrfach eingesetzt werden, um höhere Lasten zu bewältigen, und mehrere Komponenten können auf demselben physischen Knoten eingesetzt werden, um Ressourcen gemeinsam zu nutzen, oder auf verschiedenen Knoten, um eine Ressourcenisolierung zu gewährleisten. Darüber hinaus ermöglicht der verteilte Modus eine unabhängige Skalierung jeder Komponente, so dass Sie sich an unterschiedliche Lastmerkmale anpassen und die Ressourcennutzung effektiv verbessern können.
Zusammenfassung
In diesem Beitrag haben wir uns mit den drei Bereitstellungsoptionen beschäftigt, die Milvus bietet: Milvus Lite, Standalone und Verteilt. Jeder Bereitstellungsmodus ist auf verschiedene Entwicklungsstufen, Datengrößen und [Anwendungsfälle] (https://zilliz.com/vector-database-use-cases) zugeschnitten, um sicherzustellen, dass Milvus mit Ihrem Projekt skalieren kann.
Milvus Lite** ist ideal für schnelles Prototyping und kleine Experimente in Python-Umgebungen. Es ist einfach einzurichten und zu verwenden und damit perfekt für Entwickler, die eine leichtgewichtige und dennoch leistungsstarke Lösung für Tests und Entwicklung benötigen.
Milvus Standalone** ist der nächste Schritt für diejenigen, die vom Prototyping zur Produktion übergehen wollen. Diese Ein-Knoten-Installationsoption bietet alle notwendigen Komponenten für frühe Produktionsumgebungen und sorgt für ein Gleichgewicht zwischen Leistung und Ressourceneffizienz. Sie eignet sich gut für Projekte mit moderaten Datenmengen und wachsenden Benutzeranforderungen.
Milvus Distributed** ist für große Produktionsumgebungen konzipiert, die hohe Verfügbarkeit, Skalierbarkeit und Flexibilität erfordern. Es ist die erste Wahl für Unternehmen und Anwendungen, die mit großen Datenmengen arbeiten, und stellt sicher, dass Ihre Vektordatenbank mit Ihren Geschäftsanforderungen wachsen kann.
Weitere Ressourcen
Was ist Retrieval Augmented Generation (RAG)](https://zilliz.com/learn/Retrieval-Augmented-Generation)
Leistungsstarke KI-Modelle für Ihre GenAI-Anwendungen | Zilliz

Weiterlesen

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

The Great AI Agent Protocol Race: Function Calling vs. MCP vs. A2A
Compare Function Calling, MCP, and A2A protocols for AI agents. Learn which standard best fits your development needs and future-proof your applications.

Optimizing Embedding Model Selection with TDA Clustering: A Strategic Guide for Vector Databases
Discover how Topological Data Analysis (TDA) reveals hidden embedding model weaknesses and helps optimize vector database performance.