




What Is a Vector Lakebase?
TL;DR
- A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.
- It lets the same unstructured data power online serving (RAG, agents, semantic search) and offline discovery (clustering, deduplication, re-embedding, governance) — without copying data between systems.
- Zilliz Vector Lakebase is an implementation of this architecture: an evolution of Zilliz Cloud from a managed vector database into a unified AI data platform.
What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI. It combines vector-database-grade serving, open lake storage, reusable lake-level indexes, and a shared semantic layer, so the same unstructured data can support online AI applications, interactive discovery, and offline analytics — without copying it between systems. It answers a different question than retrieval alone: what happens when production AI teams need the same data for retrieval, discovery, analytics, governance, feedback, and continuous improvement?
It is best understood as an expansion of the vector database, not a replacement for it. Vector search remains the low-latency serving path; a Vector Lakebase places that path inside a broader foundation that can also store, index, govern, and continuously improve the data around it.
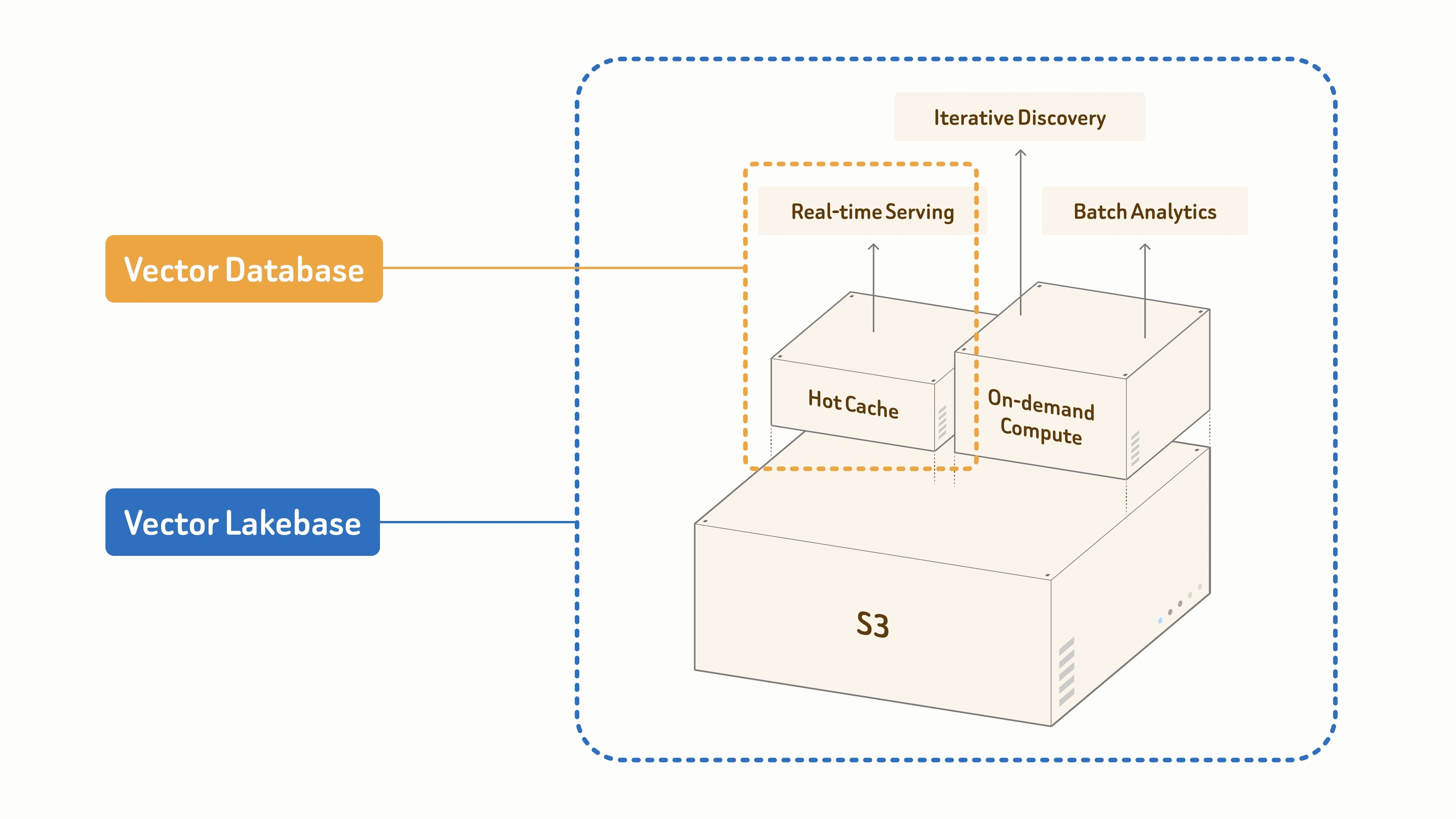
Why modern AI workloads need a Vector Lakebase
Vector databases solved the first data problem of modern AI: fast semantic retrieval at scale, powering RAG, agents, and semantic search. That problem still matters — more than ever, as AI systems spread.
But production AI teams increasingly need more than retrieval from the same data — deduplication and clustering for training sets, anomaly and drift detection, re-embedding as models change, governance and lineage, and feedback from production behavior.
Most stacks handle these workflows as separate systems: a data lake for raw files, a vector database for online retrieval, batch pipelines for preprocessing, and separate jobs for embeddings and indexes. Data is copied between them, indexes are rebuilt, and online serving and offline discovery drift out of sync.
A Vector Lakebase removes that fragmentation by providing a single logical data foundation for serving and discovery. It keeps the low-latency retrieval path vector databases are built for, but connects it to a lake-native foundation where data, vectors, indexes, metadata, and semantic context can be stored, governed, versioned, reused, and improved over time. The goal isn't to replace the vector database with the lake; it's to integrate vector search, semantic context, and unstructured-data processing into a single architecture. (For the industry context and engineering behind this shift, see Why We Built Vector Lakebase.)
Vector Lakebase core design principles: One Data, One Index, One Semantic Layer
A Vector Lakebase architecture rests on three principles: One Data, One Index, and One Semantic Layer. They describe where the system of record lives, how indexes are managed, and how meaning is organized.

One Data: the lake as the shared data foundation
One Data means open lake storage becomes the shared foundation for unstructured AI data. Raw files, cleaned data, vectors, scalar fields, metadata, index artifacts, semantic labels, lineage, and offline processing results all reside within a single logical data foundation.
In this architecture, the vector database is not a new data silo. It becomes part of the low-latency serving path. The authoritative data remains lake-native, while online systems cache hot data and indexes when needed. This reduces duplicate storage, governance, and cross-system migration, and enables the same data to support online applications, offline processing, model training, evaluation, and governance.
For example, a document used in a RAG system may also be part of an offline clustering job, a training-data exploration workflow, a compliance review, and a future re-embedding process. In a fragmented architecture, each workflow creates its own copy or derived representation. In a Vector Lakebase, those workflows operate over the same logical data foundation.
One Index: indexes become lake-level assets
One Index means indexes are not locked inside a single online serving engine. They become data assets that can be built, versioned, reused, and served across different compute modes. This matters because indexes are expensive and operationally important — they encode how a system retrieves and organizes data. If every workflow has to build its own index, teams waste compute, create inconsistent retrieval behavior, and make governance harder.
In a Vector Lakebase, a logical index can map to different serving forms based on access pattern and cost. Hot indexes support millisecond-level online retrieval; warm data is served through cache or tiered storage; cold data remains in the lake for exploration, governance, and offline analysis. The same index lineage can support RAG serving, semantic search, agent memory, data exploration, and batch processing — letting teams choose the right latency and cost profile without breaking the data model.
One Semantic Layer: meaning becomes a shared system layer
One Semantic Layer means the system manages more than embeddings. An embedding is only one representation of the underlying asset. A useful AI data foundation also needs entities, labels, summaries, topics, context fragments, source information, model versions, access policies, lineage, and feedback signals. This semantic layer lets teams organize unstructured data by meaning rather than by file path, table, bucket, or collection alone.
A RAG system can retrieve trusted context from the semantic layer. An AI agent can understand previous tasks, memories, and tool-call results. A training-data workflow can discover coverage gaps, duplicates, outliers, and bias. A governance system can trace an answer, feature, or sample back to the source data and model version that produced it.
The semantic layer is also the center of the data flywheel: online applications generate queries, clicks, citations, corrections, and feedback; offline discovery turns those signals into better metadata, cleaner datasets, improved indexes, and stronger context; and those improvements flow back into serving. That loop is where a Vector Lakebase becomes more than storage plus retrieval.
How Vector Lakebase works: the CS/CD flywheel, in four stages
A Vector Lakebase runs as a continuous loop between serving and discovery — we call this CS/CD (Continuous Serving and Continuous Discovery). Serving generates feedback and new data, discovery turns it into cleaner data and better indexes, and those improvements flow back into serving.
Operationally, the same loop runs through four stages: data ingestion, vectorization and enrichment, query serving, and offline processing.
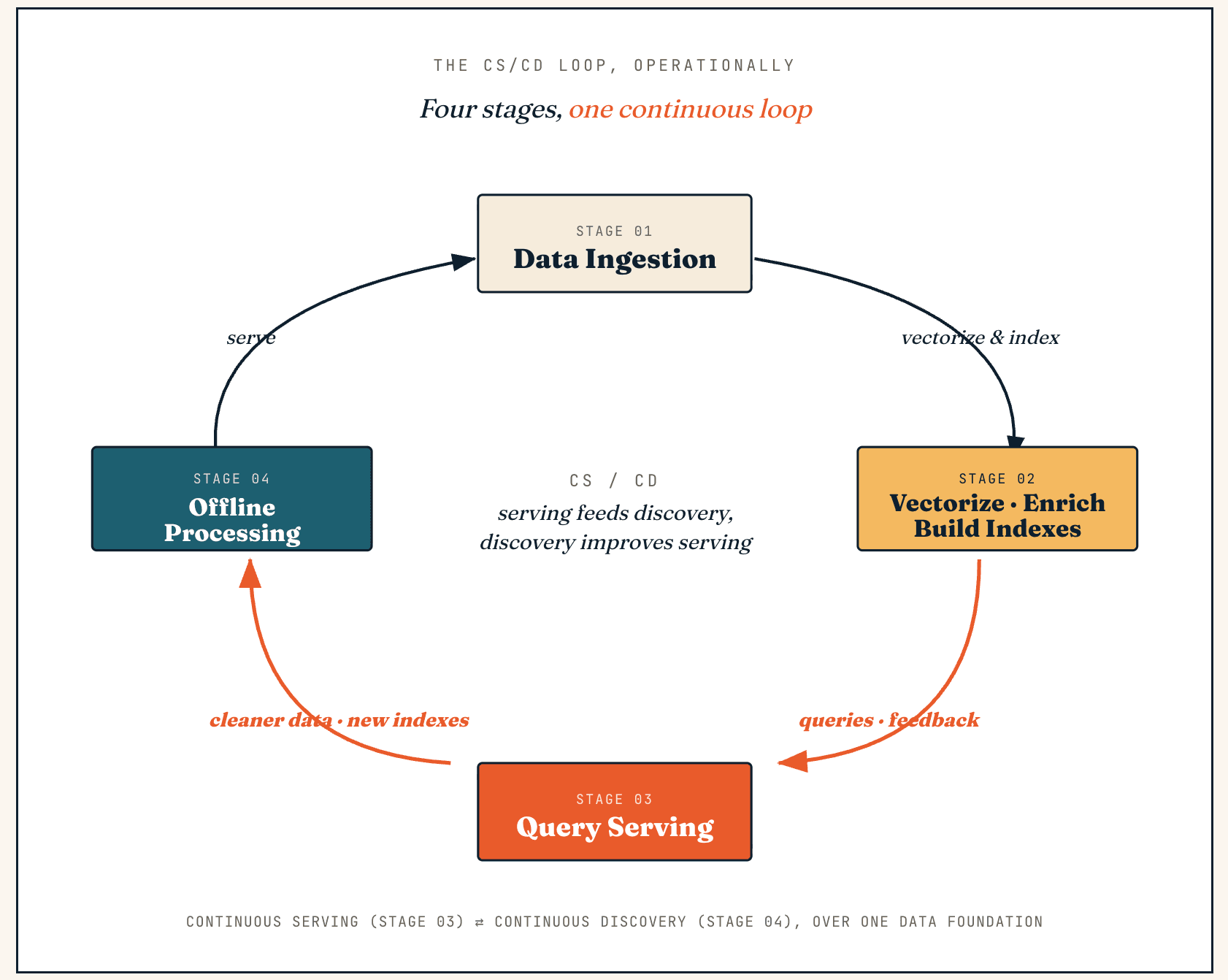
Data ingestion
Data can enter the system through a vector database API, a document pipeline, object storage, or an existing open lake format. The data may include documents, vectors, scalar fields, business metadata, images, audio, video, code, logs, conversations, support tickets, or agent traces.
As unstructured data grows, ingestion must also support cleaning, normalization, access control, source tracking, and lineage. The system needs to know not just what the data is, but where it came from, which model processed it, who can access it, and how it can be used. This is especially important for enterprise AI. A RAG system or agent cannot treat every piece of retrieved data as equally trusted. Context needs source awareness, permission awareness, freshness, and sometimes business-specific governance rules.
Vectorization, enrichment, and index construction
After ingestion, the system generates vector representations using embedding models and data-processing jobs. It also enriches the data with metadata — entities, labels, summaries, topics, source information, permissions, timestamps, and model versions. Then it builds query structures over the lake data: vector indexes, keyword indexes, full-text indexes, JSON indexes, scalar indexes, and other structures needed for hybrid retrieval.
Architecturally, this is the key point: indexes aren't tied to any single serving engine. They can be versioned, published, reused, and traced back to the data snapshot they were built from — which makes index lifecycle management part of the data foundation, not an implementation detail buried inside one application.
Query serving
A Vector Lakebase provides retrieval paths for RAG, agentic search, semantic search, multimodal retrieval, AI memory, recommendation, and other AI application workloads. The query path can use a vector database or cache layer for hot data that needs low latency, and access lake-native data and indexes for colder or less frequent workloads.
A query may combine vector search, keyword search, full-text search, metadata filtering, scalar predicates, permissions, and hybrid ranking — because production AI retrieval is rarely based on vector similarity alone. A good result often depends on semantic relevance, freshness, access rights, source quality, business metadata, and user intent.
Offline processing
Offline processing includes clustering, deduplication, anomaly detection, data quality analysis, training data exploration, schema evolution, re-embedding, evaluation, and index rebuilding. These workflows run on large data batches and do not always require millisecond latency, but they need access to the same vectors, metadata, indexes, and semantic context used by online applications.
Their output is written back into the lake, the index system, and the semantic layer — cleaner datasets, better labels, improved context fragments, new index versions, or updated feedback signals — and published as an atomic snapshot so production never reads half-built indexes. This is the core operational loop: serving generates feedback, discovery improves the data, and the improved data returns to serving.
Three workload shapes for Vector Lakebases
AI data workloads are not one shape. Some need millisecond-level serving all day. Some need an interactive search for a short analysis session. Some need large offline processing jobs that run, publish results, and disappear. A single always-on online storage model cannot efficiently cover all of these.
A traditional vector database is primarily optimized for the first workload shape. A Vector Lakebase is designed for all three over one logical dataset.
In Zilliz Vector Lakebase, these workloads map to three compute modes — long-running (resident, millisecond serving), on-demand (interactive, billed by the minute, the bridge between serving and discovery), and offline batch (large jobs that release their compute when finished).
| Workload type | Typical examples | Compute pattern |
|---|---|---|
| Real-time serving | Production RAG, agent memory, semantic search, recommendation, personalization, AI search | Long-running serving clusters with hot indexes, warm caches, and predictable latency |
| Interactive discovery | Feedback analysis, agent trace inspection, anomaly search, cold-data retrieval, semantic exploration | On-demand compute that starts when needed and releases resources when the session ends |
| Batch analytics | Corpus deduplication, clustering, full re-embedding, training data preparation, index rebuilding | Batch compute for large jobs that run, publish results, and disappear |
Common use cases of Vector Lakebases
Because a Vector Lakebase unifies serving and discovery on a single foundation, its use cases fall into two groups.
 图片12
图片12
Retrieval use cases (shared with a vector database, now on a governed foundation):
- RAG — documents, knowledge bases, code, and logs as searchable context, kept fresh, permissioned, and re-indexable as models change.
- AI agent memory and tool use — store and retrieve agent memory, then analyze it offline and feed findings back.
- Agentic and multimodal search — vector, keyword, full-text, and metadata search across text, images, audio, video, and entities.
- Recommendation systems and more.
Data-lifecycle use cases (beyond what a vector database alone covers):
- Feature and context engineering — derive entities, summaries, topics, labels, and clusters, stored next to the data they came from.
- Training-data exploration — cluster samples, find near-duplicates, inspect outliers, and trace examples back to source.
- Unstructured-data preprocessing — deduplication, anomaly detection, enrichment, and quality filtering, written back into the lake.
How a Vector Lakebase relates to vector databases and Lakebases
A Vector Lakebase is related to two architectures: vector databases and Lakebase. It is a replacement for neither. The table below is a quick view; the sections that follow explain each relationship.
| Vector database | Vector Lakebase | Lakebase | |
|---|---|---|---|
| Primary data | Vector embeddings + associated unstructured data | Unstructured & multimodal data, plus the full lifecycle around it | Structured / transactional application data |
| Core job | Low-latency semantic retrieval | Unify online serving and offline discovery over one foundation | Bring database (OLTP) capabilities to open lake storage |
| Indexes | Built and held inside the serving engine | Lake-level assets: built, versioned, reused across compute modes | Table / SQL indexes |
| Compute | Always-on serving | Long-running + on-demand + offline batch | Transactional |
| Storage of record | Often coupled to the engine | Open lake storage | Open lake storage |
| Best fit | Fast vector search for online application | Serving and continuously improving unstructured data at scale | Transactional app data on the lake |
| Relationship with vector lakebase | Becomes the serving engine inside a Vector Lakebase | - | The structured-data counterpart of the same lake-native idea |
Vector Lakebase vs. vector databases
A Vector Lakebase does not replace vector databases. If an organization only needs low-latency vector search for a single application, a vector database may be sufficient — it remains the right system for production retrieval when latency, scale, filtering, and operational reliability matter. Milvus, for example, is built for this kind of production vector search.
The calculus changes when an organization needs to reuse the same unstructured data, embeddings, indexes, and semantic context across many teams, models, applications, and processing workflows.
In that world, the vector database should not be the only place data and indexes live; it becomes the serving engine inside a broader unstructured-data architecture. Its role becomes more specific and more important — it provides the serving path AI applications need, while the Vector Lakebase provides the broader data foundation around that path. The result is not less vector search; it is vector search connected to the full lifecycle of unstructured data.
If I only need a vector database, is Vector Lakebase still a good fit?
That's a perfectly good place to start — because the vector database is already part of a Vector Lakebase. You can use the serving cluster layer exactly like a standalone vector database (low-latency ANN search, hybrid search, metadata filtering, full-text retrieval, JSON filtering, index management, production reliability) and never touch interactive discovery or batch analytics on day one. The difference is that you are not locked into a retrieval-only architecture: if the workload later expands into cold-data search, large-scale deduplication, re-embedding, training-data preparation, or semantic governance, the broader architecture is already in place — no rebuild, no duplicated data.
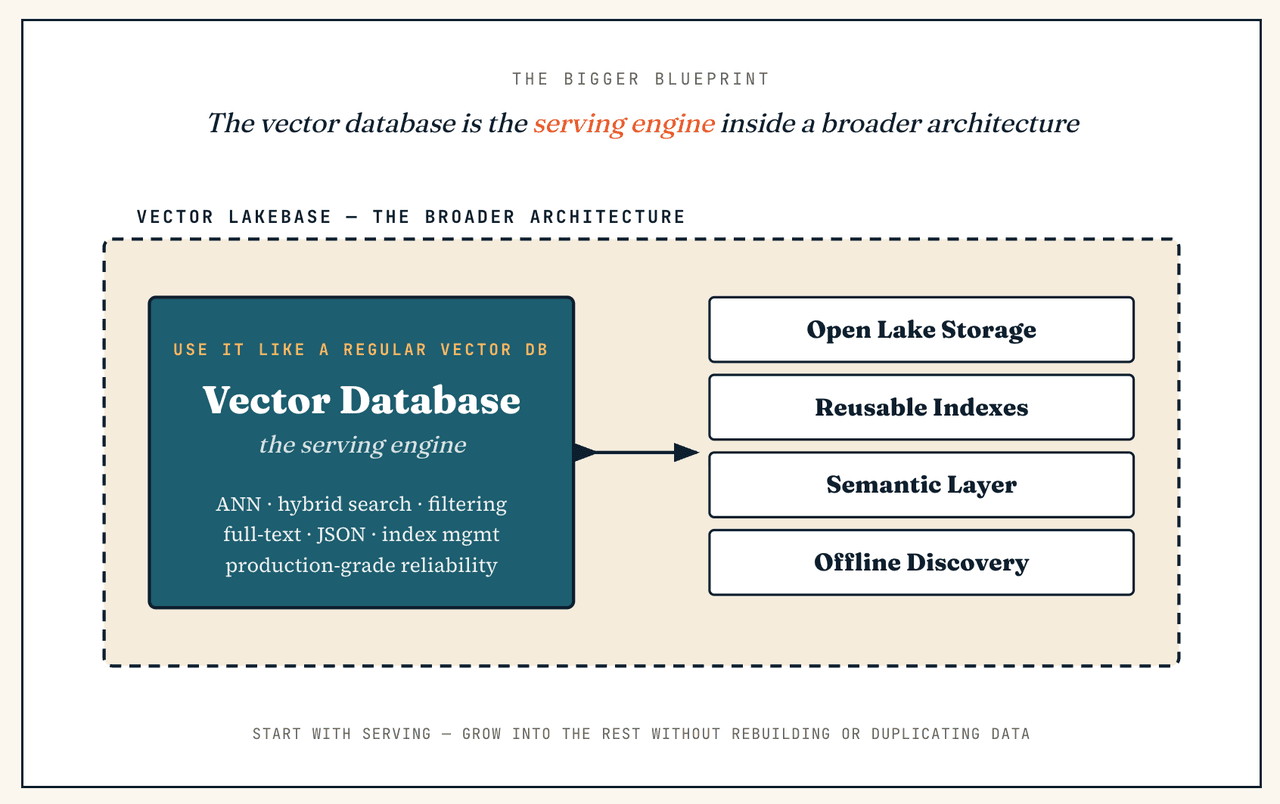
Vector Lakebase vs. Lakebase
A Vector Lakebase is related to a Lakebase, but it is not just "Lakebase plus vectors."

A Lakebase-style architecture brings database-like capabilities to open lake storage for structured application data — structured records, transactions, schemas, elastic compute, and unified governance, queried through known fields and relationships.
A Vector Lakebase addresses a different center of gravity: unstructured and multimodal data for AI. The problem is not how to store application state on a lake; it is how to manage semantic representations, vector indexes, metadata, context, feedback, and offline discovery workflows over unstructured data — which needs semantic interpretation, retrieval, refinement, and feedback rather than lookups over known fields. It is best described not as a replacement for the Lakebase, but as the Lakebase idea extended into the era of vectors, indexes, and semantic context.
| Dimension | Lakebase | Vector Lakebase |
|---|---|---|
| Primary data | Structured application data, transactional records, application state | Documents, images, audio, video, logs, code, conversations, vectors, metadata, and semantic context |
| Core abstractions | Tables, transactions, schemas, branches, clones | Vectors, indexes, chunks, entities, labels, summaries, permissions, feedback, and semantic relationships |
| Main workloads | Application reads and writes, transactions, real-time analytics | RAG, agent memory, agentic search, multimodal retrieval, discovery, context engineering, training data workflows |
| Query model | SQL, transactional queries, analytical queries | Vector search, hybrid search, full-text search, JSON filtering, multimodal retrieval, semantic discovery |
| Semantic model | Business meaning expressed mostly through schema | Meaning expressed through embeddings, metadata, entities, summaries, model versions, lineage, and feedback |
| AI value | Brings database-like capabilities to open lake storage | Brings AI context, vector indexing, semantic retrieval, and offline discovery to lake-native unstructured data |
What a Vector Lakebase is not
Because Vector Lakebase is a new architecture pattern, it is worth being clear about what it is not.
- It is not just a data lake with embeddings stored in a column. Storing embeddings in a lake table preserves the vectors but provides none of the indexing, serving, semantic metadata, hybrid retrieval, feedback loop, or low-latency retrieval path that production AI systems need. Vectors are useful when they can be searched, governed, versioned, filtered, connected to source data, and improved over time — not merely stored.
- It is not just a vector database connected to object storage. Putting object storage behind a vector database may reduce storage cost, but it does not address index reuse, offline discovery, governance, versioning, or consistency between processed and served data. The hard part is not where the bytes live; it is how data, indexes, metadata, semantic signals, and compute modes work together as one operational system.
- It is not an offline analytics system. Offline discovery is only one side of the architecture. A Vector Lakebase also serves production traffic, supports hot retrieval paths, manages indexes, enforces access control, and returns relevant context to applications and agents. The point is not to choose between serving and analytics — it is to connect them.
- It is not a departure from vector databases. This may be the most important point we've mentioned repeatedly. Vector Lakebase does not make vector databases less relevant. It gives them a broader architecture to operate in.
Zilliz Vector Lakebase is available in public preview
We've launched the public preview of Zilliz Vector Lakebase — a major evolution of Zilliz Cloud from a pure managed vector database into a unified semantic data platform that combines low-latency vector serving with the openness, scalability, and economics of a data lake.
Zilliz Vector Lakebase core capabilities:
- Tiered serving optimized for different real-time performance-cost trade-offs
- On-demand search for large-scale or exploratory workloads without always-on compute
- External data lake search — index and search directly over your existing lake data
- Full-spectrum AI search across vectors, text, JSON, and geospatial data with hybrid retrieval and reranking
- Unified lake-native storage built on Vortex, an open format with faster and cheaper random reads than Lance or Parquet
If your current stack splits serving and discovery into separate systems, Vector Lakebase might be worth a look. Try it on Zilliz Cloud — new work email signups get $100 free credits — or talk to us about your use case.
Learn more about Vector Lakebases
- From Vector Database to Vector Lakebase
- We spent 8 years making vector search faster. Then AI changed the compute model
- Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
- Vector Lakebase: End the AI Data Silo
- Zilliz Cloud On-Demand Compute: Pay Only for What You Use
- Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Keep Reading

Milvus 2.6.x Now Generally Available on Zilliz Cloud, Making Vector Search Faster, Smarter, and More Cost-Efficient for Production AI
Milvus 2.6.x is now GA on Zilliz Cloud, delivering faster vector search, smarter hybrid queries, and lower costs for production RAG and AI applications.

Zilliz Cloud Introduces Advanced BYOC-I Solution for Ultimate Enterprise Data Sovereignty
Explore Zilliz Cloud BYOC-I, the solution that balances AI innovation with data control, enabling secure deployments in finance, healthcare, and education sectors.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.