




Extracting Event Highlights Using iYUNDONG Sports App
iYUNDONG is an Internet company aiming to engage more sport lovers and participants of events such as marathon races. It builds artificial intelligence (AI) tools that can analyze media captured during sporting events to automatically generate highlights. For example, by uploading a selfie, a user of the iYUNDONG sports App who took part in a sport event can instaneously retrieve his or her own photos or video clips from a massive media dataset of the event.
One of the key features of iYUNDONG App is called “Find me in motion“. Photographers usually take massive volumes of photos or videos during a sporting event such as a marathon race, and would upload the photos and videos in real time to the iYUNDONG media database. Marathon runners who want to see their highlighted moments can retrieve pictures including themselves simply by uploading one of their selfies. This saves them a lot of time because an image retrieval system in the iYUNDONG App does all the image matching. Milvus is adopted by iYUNDONG to power this system as Milvus can greatly accelerate the retrieval process and return highly accurate results.
Jump to:
- Difficulties and solutions
- What is Milvus
- Why Milvus
- System and Workflow
- iYUNDONG App Interface
- Conclusion
Difficulties and solutions
iYUNDONG faced the following issues and successfully found corresponding solutions when building its image retrieval system.
- Event photos must be immediately available for search.
iYUNDONG developed a function called InstantUpload to ensure that event photos are available for search immediately after they are uploaded.
- Storage of massive datasets
Massive data such as photos and videos are uploaded to the iYUNDONG backend every millisecond. So iYUNDONG decided to migrate onto cloud storage systems including AWS, S3, and Alibaba Cloud Object Storage Service (OSS) for handling gargantuan volumes of unstructured data in a secure, fast and reliable way.
- Instant reading
In order to achieve instant reading, iYUNDONG developed its own sharding middleware to achieve horizontal scalability easily and mitigate the impact on the system from disk reading. In addition, Redis is used to serve as a caching layer to ensure consistent performance in situation of high concurrency.
- Instant extraction of facial features
In order to accurately and efficiently extract facial features from user-uploaded photos, iYUNDONG developed a proprietary image conversion algorithm which converts images into 128-dimensional feature vectors. Another issue encountered was that, oftentimes, many users and photographers uploaded images or videos simultaneously. So system engineers needed to take dynamic scalability into consideration when deploying the system. More specifically, iYUNDONG fully leveraged its elastic compute service (ECS) on the cloud to achieve dynamic scaling.
- Quick and large-scale vector search
iYUNDONG needed a vector database to store its large number of feature vectors extracted by AI models. According to its own unique business application scenario, iYUNDONG expected the vector database to be able to:
- Perform blazing fast vector retrieval on ultra-large datasets.
- Achieve mass storage at lower costs.
Initially, an average of 1 million images were processed annually, so iYUNDONG stored all its data for search in RAM. However, in the past two years, its business boomed and saw an exponential growth of unstructured data – the number of images in iYUNDONG’s database exceeded 60 milllion in 2019, meaning that there were more than 1 billion feature vectors that needed to be stored. A tremendous amount of data inevitably made the iYUNDONG system heavily-built and resource-consuming. So it had to continuously invest in hardware facilities to ensure high performance. Specifically, iYUNDONG deployed more search servers, larger RAM, and a better-performing CPU to achieve greater efficiency and horizontal scalability. However, one of the defects of this solution was that it drove the operating costs prohibitively high. Therefore, iYUNDONG started to explore a better solution to this issue and pondered on leveraging vector index libraries like Faiss to save costs and better steer its business. Finally iYUNDONG chose open-source vector database Milvus.
What is Milvus
Milvus is an open-source vector database that is easy to use, highly flexible, reliable, and blazing fast. Combined with various deep learning models such as photo and voice recognition, video processing, natural language processing, Milvus can process and analyze unstructured data that are converted into vectors by using various AI algorithms. Below is the workflow of how Milvus processes all unstructured data:
● Unstructured data are converted into embedding vectors by deep learning models or other AI algorithms.
● Then embedding vectors are inserted into Milvus for storage. Milvus also builds indexes for those vectors.
● Milvus performs similarity search and returns accurate search results based on various business needs.
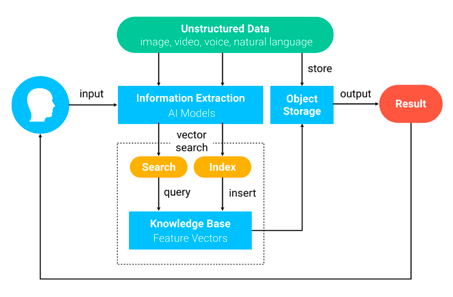 An overview of Milvus.
An overview of Milvus.
Why Milvus
Since the end of 2019, iYUNDONG has carried out a series of testings on using Milvus to power its image retrieval system. The testing results turned out that Milvus outperforms other mainstream vector databases as it supports multiple indexes and can efficiently reduce RAM usage, significantly compressing the timeline for vector similarity search.
Moreover, new versions of Milvus are released regularly. Over the testing period, Milvus has went through multiple version updates from v0.6.0 to v0.10.1.
Additionally, with its active open-source community and powerful out-of-the-box features, Milvus allows iYUNDONG to operate on a tight development budget.
System and Workflow
iYUNDONG’s system extracts facial features by detecting faces in event photos uploaded by photographers first. Then those facial features are converted into 128-dimensional vectors and stored in the Milvus library. Milvus creates indexes for those vectors and can instantaneously return highly accurate results.
Other additional information such as photo IDs and coordinates indicating the position of a face in a photo are stored in a third-party database.
Each feature vector has its unique ID in the Milvus library. iYUNDONG adopted the Leaf algorithm, a distributed ID generation service developed by Meituan basic R&D platform, to associate the vector ID in Milvus with its corresponing additional information stored in another database. By combining the feature vector and the additional information, the iYUNDONG system can return similar results upon user search.
iYUNDONG App Interface
A series of latest sports events are listed on the homepage. By tapping one of the events, users can see the full details.
After tapping the button on the top of the photo gallery page, users can then upload a photo of their own to retrieve images of their highlights.
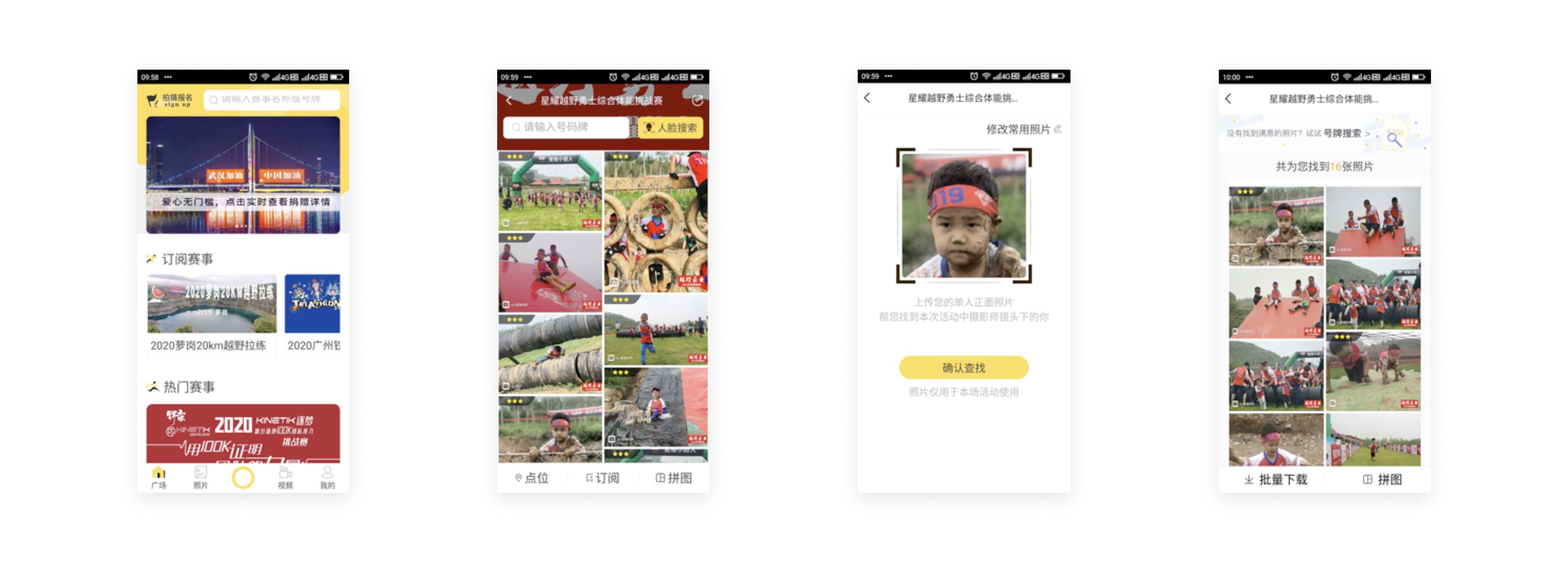 iYUNDONG app interface.
iYUNDONG app interface.
Conclusion
This article introduces how iYUNDONG App builds an intelligent image retrieval system that can return accurate search results based on user uploaded photos varying in resolution, size, clarity, angle, and other ways that complicate similarity search. With the help of Milvus, iYUNDONG App can successfully run millisecond-level queries on a database of 60+ million images. And accuracy rate of photo retrieval is constantly above 92%. Milvus makes it easier for iYUNDONG to create a powerful, enterprise-grade image retrieval system in a short time with limited resources.
Read other user stories to learn more about making things with Milvus.
Keep Reading

How Zilliz Ended Up at the Center of NVIDIA’s Unstructured Data Story at GTC 2026
If unstructured data is the context of AI, then the ceiling of AI applications will be set not just by models, but by how mature the infrastructure for unstructured data becomes.

Zilliz Cloud Now Available in AWS Europe (Ireland)
Zilliz Cloud launches in AWS eu-west-1 (Ireland) — bringing low-latency vector search, EU data residency, and full GDPR-ready infrastructure to European AI teams. Now live across 30 regions on five cloud providers.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.