




Всё, что вам нужно знать о Llama 2

Всё, что вам нужно знать о Llama 2
Что такое Llama 2?
Llama 2, представленная Meta AI в 2023 году, — это значительный шаг вперёд в развитии больших языковых моделей (LLM). Эти модели, Llama 2 и Llama 2-CHAT, масштабируются до 70 миллиардов параметров и доступны для исследовательских и коммерческих целей бесплатно, представляя собой прорыв в возможностях обработки естественного языка (NLP), от генерации текста до интерпретации программного кода.
Развивая идеи своего предшественника, LLaMa 1, который изначально был доступен только исследовательским учреждениям по некоммерческой лицензии, Llama 2 знаменует важный сдвиг в сторону демократизации доступа к передовым технологиям ИИ. В отличие от своего предшественника, модели Llama 2 являются «open-source» и, следовательно, свободно доступны для исследовательских и коммерческих приложений, что отражает стремление Meta к развитию более инклюзивной и совместной экосистемы генеративного ИИ.
Выпуск Llama 2 предоставляет доступ к современным LLM и решает вычислительные проблемы, связанные с их разработкой. Оптимизируя производительность без экспоненциального увеличения количества параметров, Llama 2 предлагает модели с различными размерами параметров — от 7 миллиардов до 70 миллиардов. Такой стратегический подход позволяет небольшим организациям и исследовательским сообществам использовать мощь LLM без чрезмерных вычислительных ресурсов.
Кроме того, приверженность Meta прозрачности очевидна в её решении опубликовать как код, так и веса модели Llama 2, что способствует лучшему пониманию и сотрудничеству внутри исследовательского сообщества ИИ. Снижая барьеры для входа и повышая доступность, Llama 2 прокладывает путь к более инклюзивному и инновационному будущему в исследованиях и разработке ИИ.
Llama 2
Llama 2 — это обновлённая версия Llama 1, обученная на новой смеси общедоступных данных. Предобученный набор данных был увеличен на 40%, длина контекста была удвоена, а команда Meta при создании Llama 2 применила grouped-query attention.
| Обучающие данные | Параметры | Длина контекста | Group-query attention | Токены | |
| Llama 1 | См. Touvron et al.(2023) | 7B | 2K | - | 1.0T |
| 13B | 2K | - | 1.0T | ||
| 33B | 2K | - | 1.4T | ||
| 65B | 2K | - | 1.4T | ||
| Llama 2 | Новая смесь общедоступных онлайн-данных | 7B | 4K | - | 2.0T |
| 13B | 4K | - | 2.0T | ||
| 34B | 4K | ✓ | 2.0T | ||
| 70B | ✓ | 2.0T |
Llama 2-CHAT
Llama 2-CHAT — это дообученная версия Llama 2, которую команда Meta оптимизировала для сценариев использования естественного языка. Варианты этой модели доступны с 7B, 13B и 70B параметрами. Llama 2-Chat подвержена тем же широко признанным ограничениям, что и другие LLM, включая прекращение обновления знаний после предварительного обучения, возможность генерации нефактического контента, такого как неквалифицированные советы, и склонность к галлюцинациям.
Llama 2 с открытым исходным кодом
Хотя Meta щедро предоставила доступ к исходному коду и весам моделей Llama 2 для исследовательских и коммерческих целей, возникли дискуссии относительно уместности обозначения ее как "open source" из-за определенных ограничений, изложенных в ее лицензионном соглашении.
Дебаты вокруг классификации условий лицензирования Llama 2 зависят от технических и семантических нюансов. Хотя "open source" обычно используется в разговорной речи для обозначения любого программного обеспечения со свободно доступным исходным кодом, оно имеет конкретное значение как формальное обозначение, контролируемое Open Source Initiative (OSI). Чтобы считаться "Open Source Initiative approved," лицензия на программное обеспечение должна соответствовать десяти критериям, изложенным в официальном Open Source Definition (OSD).
Таким образом, применимость ярлыка "open source" к моделям Llama 2 зависит от того, соответствуют ли ее условия лицензирования строгим критериям, установленным OSI. Это различие подчеркивает важность ясности и точности при обсуждении доступности и распространения программных ресурсов в более широком сообществе разработчиков.
Однако, хотя Llama 2 не является полностью открытой, она предлагает разработчикам привлекательную модель с гораздо большей гибкостью, чем закрытые модели, созданные OpenAI, Google и другими крупными игроками в области генеративного ИИ.
Архитектура Llama 2
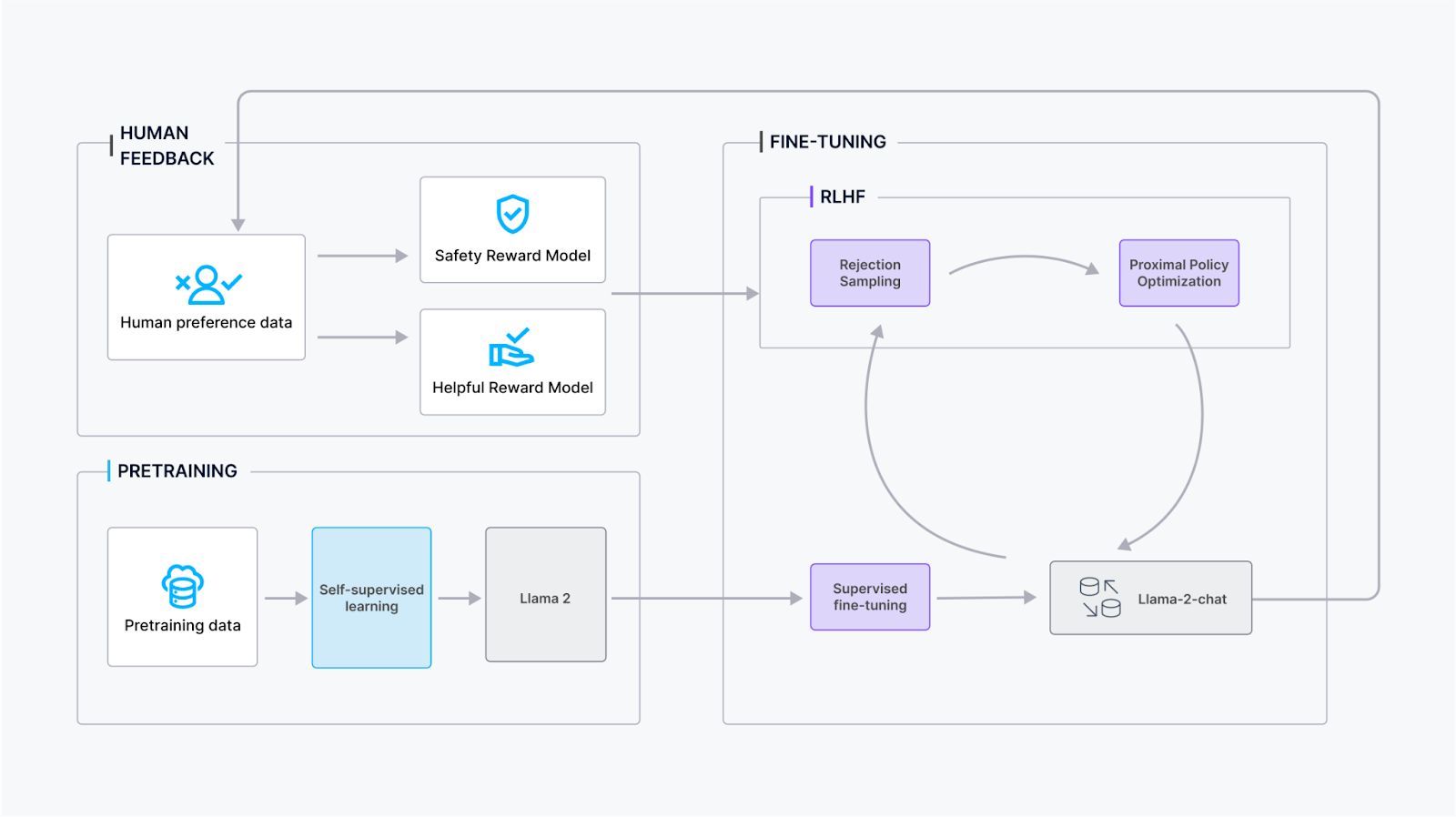
Процесс обучения Llama 2-Chat включает несколько этапов для обеспечения оптимальной производительности и доработки:
Предварительное обучение: Llama 2 проходит предварительное обучение с использованием общедоступных онлайн-источников для формирования базовых знаний и понимания языка.
Контролируемое дообучение: Команда Meta создала первоначальную версию Llama 2-Chat посредством контролируемого дообучения, при котором модель учится на размеченных данных, чтобы улучшить свои разговорные возможности.
Обучение с подкреплением на основе обратной связи от человека (RLHF): Модель проходит итеративную доработку с использованием методологий RLHF, главным образом через выборку с отклонением и Proximal Policy Optimization (PPO). Этот этап включает непрерывное взаимодействие с человеческой обратной связью для повышения качества диалога.
Итеративное моделирование вознаграждения: На протяжении этапа RLHF накопление данных для итеративного моделирования вознаграждения происходит параллельно с улучшениями модели. Итеративное моделирование вознаграждения гарантирует, что модели вознаграждения остаются в пределах распределения, способствуя постоянному улучшению разговорных способностей модели.
Благодаря включению этих этапов обучение Llama 2-Chat направлено на достижение устойчивой разговорной производительности при адаптации к обратной связи пользователей и сохранении согласованности с моделями вознаграждения.
Что такое Embedding в машинном обучении?
В машинном обучении embedding означает изученное представление объектов в непрерывном векторном пространстве, таких как слова, изображения или сущности. Эти embeddings фиксируют семантические отношения и сходства между объектами, делая их более подходящими для вычислительных задач. В обработке естественного языка (NLP), например, word embeddings сопоставляют слова из словаря с плотными векторами в многомерном пространстве, где похожие слова находятся близко друг к другу.
В Llama 2 эмбеддинги играют ключевую роль в понимании и генерации естественного языка. Llama 2 использует эмбеддинги для представления слов, фраз или целых предложений в непрерывном векторном пространстве. Llama 2 может эффективно обрабатывать и генерировать текст, встраивая языковые входные и выходные данные и при этом улавливая семантические связи и нюансы.
Например, Llama 2 изучает эмбеддинги для слов и фраз из огромного корпуса текста, на котором она обучается в процессе обучения. Эти эмбеддинги кодируют семантическую информацию о языке, позволяя Llama 2 понимать запросы или подсказки и генерировать связные ответы на них.
Эмбеддинги в машинном обучении, включая те, которые используются в Llama 2, облегчают представление языка и других данных в структурированном и семантически осмысленном виде, обеспечивая эффективную обработку, понимание и генерацию естественного языка.
Как использовать Llama 2?
Чтобы эффективно использовать Llama 2, получите доступ к модели через предоставленный интерфейс или API, убедившись, что необходимые разрешения оформлены. Подготовьте входные данные, будь то текст, изображения или совместимые форматы, и при необходимости выполните их предварительную обработку. Укажите задачу для Llama 2, например генерацию текста или суммаризацию. Передайте предварительно обработанные данные в Llama 2, получите выходной результат и оцените его качество. Экспериментируйте с различными форматами и конфигурациями, чтобы оптимизировать результаты. Отслеживайте показатели производительности, такие как точность и скорость, корректируя стратегии на основе обратной связи. Следите за обновлениями и улучшениями, чтобы максимально повысить эффективность, открывая новые возможности для проектов и приложений. Вы также можете использовать Llama 2 с такими инструментами, как LangChain, LlamaIndex и Semantic Kernel, при создании RAG-приложений.
Производительность Llama 2
Общую производительность можно оценить, рассмотрев некоторые популярные агрегированные бенчмарки. Ниже приведена таблица результатов производительности по сравнению с моделями на базе open-source, как указано в статье LLama 2:
| Модель | Размер | Код | Рассуждение здравого смысла | Знания о мире | Понимание прочитанного | Математика | MMLU | BBH | AGI Eval |
| MPT | 7B | 20.5 | 57.4 | 41.0 | 57.5 | 4.9 | 26.8 | 31.0 | 23.5 |
| 30B | 28.9 | 64.9 | 50.0 | 64.7 | 9.1 | 46.9 | 38.0 | 33.8 | |
| Falcon | 7B | 5.6 | 56.1 | 42.8 | 36.0 | 4.6 | 26.2 | 28.0 | 21.2 |
| 40B | 15.2 | 69.2 | 56.7 | 65.7 | 12.6 | 55.4 | 37.1 | 37.0 | |
| Llama 1 | 7B | 14.1 | 60.8 | 46.2 | 58.5 | 6.95 | 35.1 | 30.3 | 23.9 |
| 13B | 18.9 | 66.1 | 52.6 | 62.3 | 10.9 | 46.9 | 37.0 | 33.9 | |
| 33B | 26.0 | 70.0 | 58.4 | 67.6 | 21.4 | 57.8 | 39.8 | 41.7 | |
| 65B | 30.7 | 70.7 | 60.5 | 68.6 | 30.8 | 63.4 | 43.5 | 47.6 | |
| Llama 2 | 7B | 16.8 | 63.9 | 48.9 | 61.3 | 14.6 | 45.3 | 32.6 | 29.3 |
| 13B | 24.5 | 66.9 | 55.4 | 65.8 | 28.7 | 54.8 | 39.4 | 39.1 | |
| 33B | 27.8 | 69.9 | 58.7 | 68.0 | 24.2 | 62.6 | 44.1 | 43.4 | |
| 65B | 37.5 | 71.9 | 63.6 | 69.4 | 35.2 | 68.9 | 51.2 | 54.2 |
Вы можете видеть, что Llama 2 превосходит Llama 1 в ряде категорий, таких как MMLU и BBH, и даже показывает хорошие результаты по сравнению с моделью Falcon.
Llama 2 против GPT 4
В статье о Llama 2 также представлены некоторые сравнения Llama 2 с GPT 4 и несколькими другими моделями, как показано ниже:
| Бенчмарк (shots) | GPT-3.5 | GPT-4 | PaLM | PaLM-2-L | Llama 2 |
| MMLU (5 shot) | 70.0 | 86.4 | 69.3 | 78.3 | 68.9 |
| TriviaQA (1-shot) | — | — | 81.4 | 86.1 | 85.3 |
| Natural Questions (1-shot) | — | — | 29.3 | 37.5 | 33.0 |
| GSM8K (8-shot) | 57.1 | 92.0 | 56.5 | 80.7 | 56.8 |
| HumanEval (0-shot) | 48.1 | 67.0 | 26.2 | — | 29.9 |
| BIG-Bench Hard (3-shot) | — | — | 52.3 | 65.7 | 51.2 |
- MMLU (5-shot): Модели предоставляют 5 фрагментов или примеров для генерации ответа.
- TriviaQA (1-shot): Набор данных, в котором модели предоставляется один контекст или вопрос перед генерацией ответа.
- Natural Questions (1-shot): Еще один набор данных, в котором модели на вход подается один вопрос.
- GSM8K (8-shot): Набор данных, в котором модели предоставляют 8 фрагментов или примеров для ответа на вопросы или выполнения задач.
- HumanEval (0-shot): Набор данных или сценарий оценки, в котором модель оценивается на задачах или вопросах, на которых она не была явно обучена, отсюда "0-shot."
Работает ли Zilliz с Llama 2?
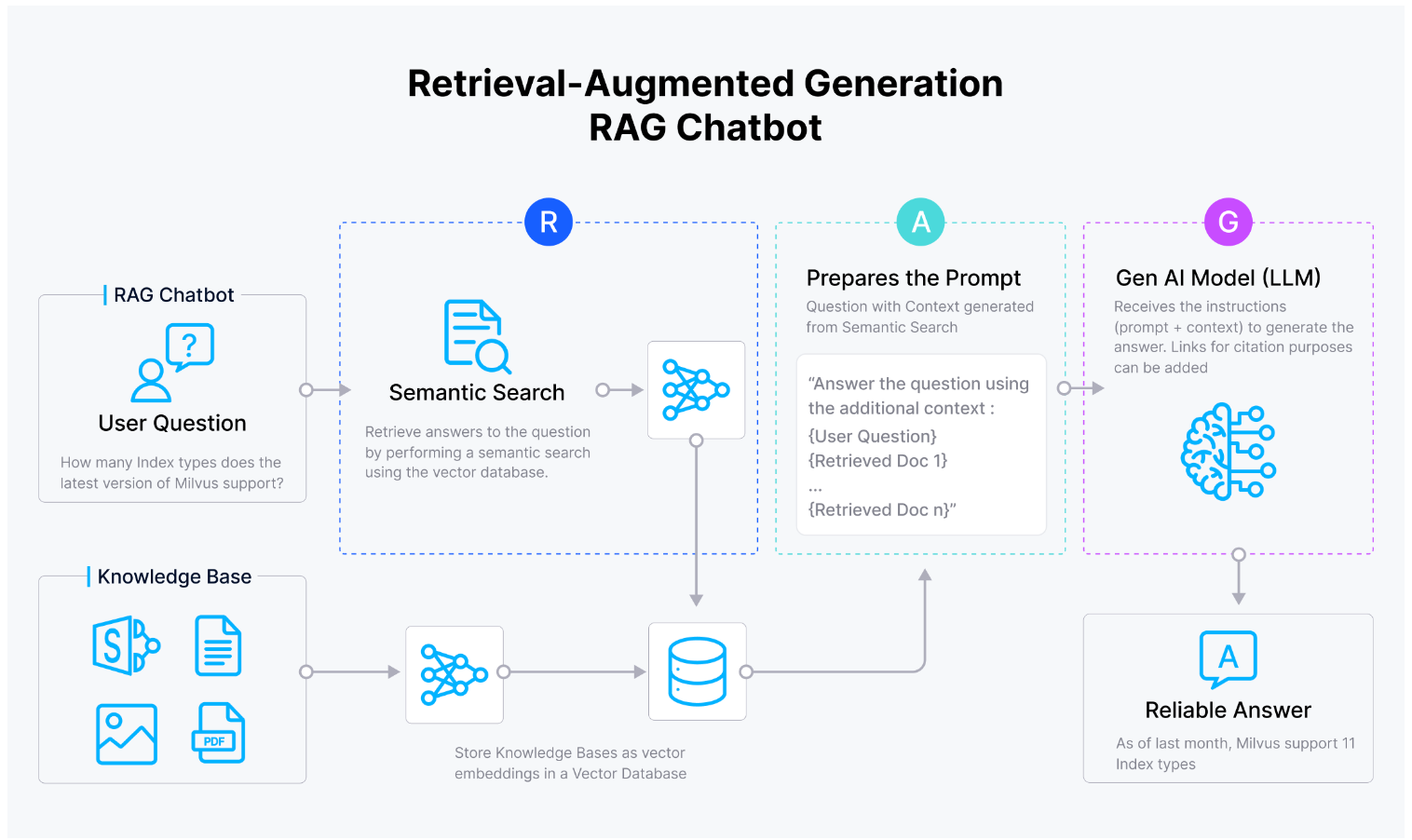
Самый распространенный вариант использования Zilliz Cloud совместно с Llama 2 — разработка приложений Retrieval Augmented Generation (RAG). RAG-приложения используют возможности больших языковых моделей (LLMs), таких как Llama 2, которые обучены на огромных наборах данных, но по своей природе работают в рамках конечного объема данных. Сама по себе Llama 2 склонна "галлюцинировать" ответы, генерируя их даже тогда, когда может не хватать достаточного контекста или точной информации. RAG — один из способов решить проблему этой галлюцинации.
Сочетание Zilliz Cloud и Llama 2 позволяет пользователям бесшовно интегрировать расширенные возможности понимания и генерации языка с эффективными и масштабируемыми системами векторного поиска, предоставляемыми Zilliz Cloud. Используя сильные стороны обеих платформ, разработчики могут создавать сложные приложения, которые отлично справляются с задачами, требующими комплексной обработки языка, поиска информации и функций генерации.
Ключевые ресурсы
- Что такое Llama 2?
- Архитектура Llama 2
- Что такое Embedding в машинном обучении?
- Как использовать Llama 2?
- Производительность Llama 2
- Llama 2 против GPT 4
- Работает ли Zilliz с Llama 2?
- Ключевые ресурсы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно