




Авторегрессионная интегрированная скользящая средняя (ARIMA)

Авторегрессионная интегрированная скользящая средняя (ARIMA)
Вы когда-нибудь задумывались, как компании точно прогнозируют спрос на продукты в предстоящие сезоны и оптимизируют их запуск? Именно здесь в игру вступает ARIMA. ARIMA — это статистическая модель, которая прогнозирует будущие значения временных рядов, анализируя прошлые закономерности.
Давайте обсудим важность, преимущества и сложности ARIMA, рассмотрев, как она работает.
Что такое ARIMA?
Авторегрессионная интегрированная скользящая средняя (ARIMA) — это популярная статистическая модель для прогнозирования временных рядов. Она использует исторические данные, чтобы понять закономерности набора данных и спрогнозировать будущие значения. Модель использует три компонента для прогнозирования будущих значений: авторегрессию (AR), дифференцирование (I) и скользящую среднюю (MA). Каждый компонент формирует прогнозы модели, описывая связь между прошлыми и будущими значениями.
Вот что делает каждый компонент:
Авторегрессия (p): AR предполагает, что будущее значение зависит от прошлого значения. Порядок AR относится к числу прошлых значений, которые модель использует для прогнозирования текущего значения. Например, если порядок AR равен 3, модель прогнозирует текущее значение на основе трех самых последних прошлых значений.
Дифференцирование/ интегрирование (d): Это определяет степень дифференцирования, необходимую для приведения временного ряда к стационарному виду. В нестационарных временных рядах, где статистические свойства, такие как среднее и дисперсия, меняются со временем, применение дифференцирования помогает стабилизировать ряд.
Скользящая средняя (q): MA фиксирует связь между текущим значением временного ряда и прошлыми ошибками прогноза. Порядок MA отражает связь между текущим значением временного ряда и прошлыми ошибками прогноза. Например, MA(2), или MA порядка 2, рассчитывает взвешенное среднее двух прошлых ошибок для прогнозирования текущего значения.
Математически модель ARIMA представляется как ARIMA (p, d, q) и выражается как:
y′t=I+α1y′t−1+α2y′t−2+⋯+αpy′t−p+et+θ1et−1+θ2et−2+⋯+θqet−q
Где:
Yt: Текущее значение временного ряда
c: Постоянный член
φ₁, φ₂, ..., φp: Авторегрессионные коэффициенты
θ₁, θ₂, ..., θq: Коэффициенты скользящей средней
εt: Шумовой член ошибки
p: Порядок авторегрессии
q: Порядок скользящей средней
d: Порядок дифференцирования/ интегрирования
Это означает, что текущее значение дифференцированного временного ряда (y′t) является линейной комбинацией его прошлых значений (y′t-₁, y′t-₂, ..., y′t-p) и прошлых членов ошибки (et-₁, et-₂, ..., et-q).
Как работает ARIMA?
Автокорреляция и скользящие средние являются важными компонентами моделей ARIMA. Автокорреляция помогает выявлять прямые связи между прошлыми и текущими значениями, тогда как скользящие средние помогают учитывать косвенные эффекты прошлых ошибок прогноза.
Вот пошаговый разбор того, как они работают вместе:
Стационарность
Первый шаг в прогнозировании временных рядов с помощью моделей ARIMA — убедиться, что временной ряд является стационарным. Поскольку нестационарные данные могут приводить к неточным прогнозам и смещенным результатам модели, ARIMA основана на предположении о стационарности. Если данные временного ряда нестационарны, ARIMA применяет дифференцирование, чтобы сделать их стационарными. Это включает вычитание предыдущего значения из текущего значения. Порядок дифференцирования (d) определяет количество повторений этого процесса.
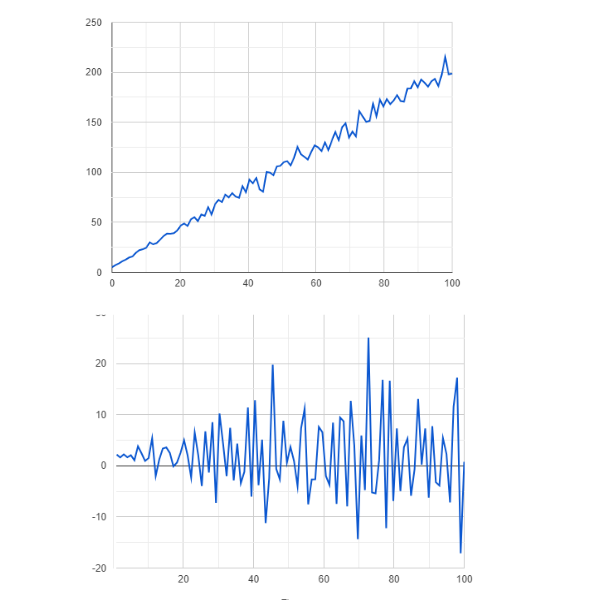 Рисунок- Нестационарные и стационарные данные .png
Рисунок- Нестационарные и стационарные данные .png
Рисунок: Нестационарные и стационарные данные
Идентификация модели
Идентификация модели определяет подходящие значения для авторегрессионного (p) и компонента скользящей средней (q). Функция автокорреляции (ACF) и частная функция автокорреляции (PACF) являются важными инструментами для этого процесса:
Функция автокорреляции
Функция автокорреляции определяет порядок авторегрессионной (AR) компоненты (p). Если она показывает корреляцию на лаге k, это указывает на то, что текущее значение связано со значением k периодов назад, где k представляет количество лагов (временных шагов) между текущим значением и предыдущим значением во временном ряду.
Частичная автокорреляционная функция
Частичная автокорреляционная функция (PACF) определяет порядок компоненты скользящего среднего (MA) (q). Если она показывает значимую корреляцию на лаге k, это указывает на то, что текущее значение связано с ошибкой прогноза, произошедшей k периодов назад.
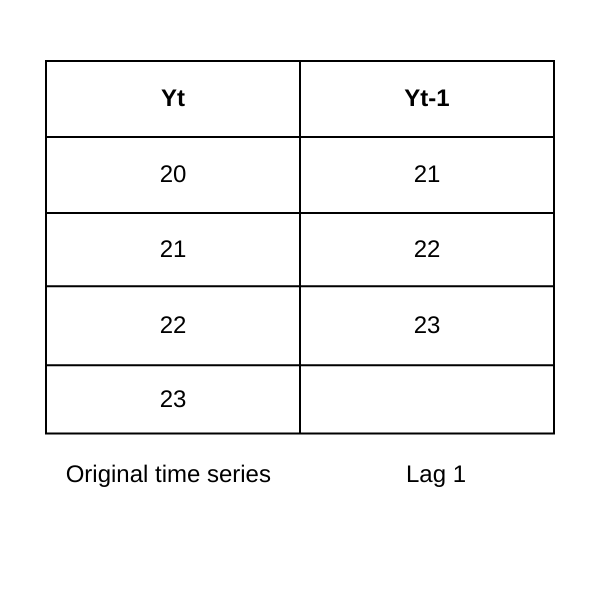 Figure- Lag-1 autocorrelation.png
Figure- Lag-1 autocorrelation.png
Рисунок: автокорреляция с лагом 1
Оценка модели
После определения порядков авторегрессионной (AR) и компонентов скользящего среднего (MA) ARIMA оценивает параметры модели. Параметры модели количественно выражают силу связей между текущим значением и его прошлыми значениями (AR), а также между текущим значением и прошлыми ошибками (MA).
Оценка максимального правдоподобия (MLE) — наиболее распространенный метод оценки параметров в моделях ARIMA. MLE оценивает параметры модели, находя значения, которые максимизируют вероятность наблюдения данных. Для моделей ARIMA функция правдоподобия обычно основана на предположении, что ошибки имеют нормальное распределение. Метод наименьших квадратов и байесовские методы — другие подходы к оценке параметров в моделях ARIMA.
Прогнозирование с помощью модели
Оцененная модель ARIMA в итоге прогнозирует будущие значения на основе исторических данных. При необходимости модель также можно уточнить, изменив порядки компонентов AR и MA или учитывая другие факторы, такие как сезонность.
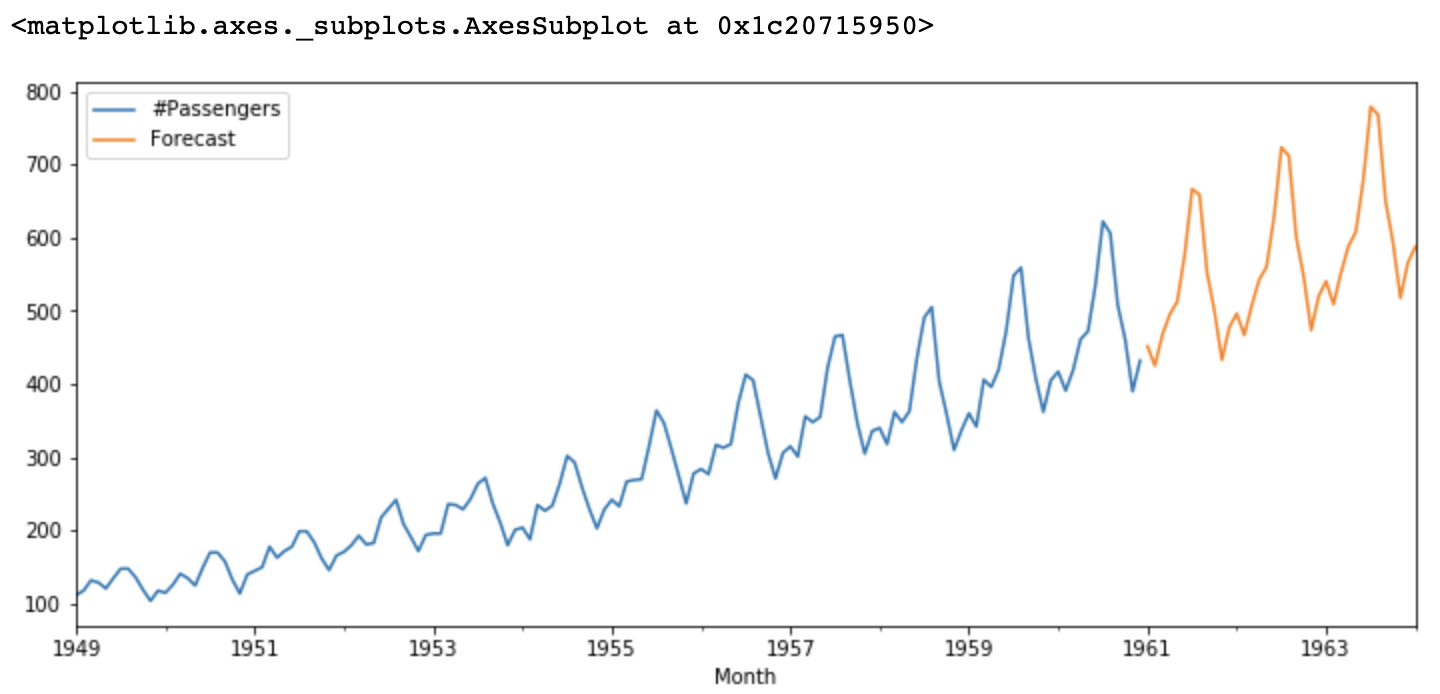 Figure- ARIMA forecasts.png
Figure- ARIMA forecasts.png
Рисунок: прогнозы ARIMA
Сравнение с похожими концепциями
ARIMA часто сравнивают с другими похожими концепциями в контексте анализа данных и прогнозирования. Вот сравнение, которое помогает развеять распространенные заблуждения:
ARIMA vs. SARIMA: SARIMA (Seasonal ARIMA) — это расширение ARIMA, которое специально учитывает сезонность при анализе данных временных рядов. ARIMA — это статистическая модель для данных временных рядов без четкого сезонного паттерна.
ARIMA vs. Exponential Smoothing: ARIMA и экспоненциальное сглаживание — это методы прогнозирования временных рядов. ARIMA использует статистические методы для моделирования базовых паттернов, включая тренды, сезонность и автокорреляцию. Экспоненциальное сглаживание, с другой стороны, применяет более простой метод взвешенного усреднения, при котором недавним наблюдениям придается больший вес, чем более старым. В то время как ARIMA лучше подходит для данных со сложными паттернами, экспоненциальное сглаживание хорошо работает для временных рядов с относительно стабильным трендом и минимальной сезонностью, что делает его менее адаптируемым к сложным данным.
ARIMA vs. Vector Autoregression (VAR): VAR подходит для прогнозирования многомерных временных рядов, где несколько переменных влияют друг на друга. ARIMA подходит для одномерных временных рядов и требует дифференцирования ряда для достижения стационарности.
Преимущества и сложности ARIMA
ARIMA предлагает несколько преимуществ, что делает ее одной из наиболее широко используемых моделей прогнозирования временных рядов. Однако она также имеет определенные сложности, которые требуют учитывать свойства вашего анализа и конкретные цели перед применением ARIMA.
Преимущества
Преимущества использования моделей ARIMA для прогнозирования временных рядов включают:
Гибкость: ARIMA может обрабатывать широкий спектр данных временных рядов, включая линейные и нелинейные тренды, сезонные паттерны, волатильность и автокорреляцию. Это позволяет ей учитывать распространенные характеристики реальных временных рядов, такие как экономические индикаторы и нелинейные паттерны в ценах акций.
Простота: Модели ARIMA легко понять благодаря их простому функционированию и прозрачным предположениям. Они могут обрабатывать длинные временные ряды с относительно большим числом наблюдений.
Точность: Точность моделей ARIMA зависит от качества данных. Поэтому учет предположений и выбор подходящих моделей приводят к точным результатам.
Интерпретируемость: Параметры модели ARIMA имеют четкие интерпретации, включая коэффициенты авторегрессии и скользящего среднего. Эти коэффициенты дают представление о том, как прошлые значения и ошибки влияют на будущие значения.
Широкая применимость: Модели ARIMA широко используются в различных отраслях для задач прогнозирования, таких как финансовое моделирование, прогнозирование спроса и прогнозирование нагрузки. Поэтому они встроены во многие языки программирования и имеют широкое сообщество сторонников.
Основа для других моделей: Модели ARIMA являются основой для более сложных моделей временных рядов, таких как SARIMA и ARIMAX. Учитывая дополнительные факторы, они помогают повысить точность прогнозов за пределами исторических значений временного ряда.
Проблемы
Проблемы моделей ARIMA включают:
Предположение о стационарности: Модель ****ARIMA предполагает, что временной ряд является стационарным; если это не так, она преобразует данные для достижения стационарности. Однако многие реальные наборы данных нестационарны, и их предварительная обработка может усложнить процесс моделирования.
Линейные зависимости: ARIMA — это линейная модель, и она не может улавливать сложные нелинейные зависимости в данных. Поэтому она может неточно отражать внезапные изменения в данных, вызванные экономическими кризисами, внешними шоками и т. д.
Идентификация модели: Производительность модели ARIMA зависит от выбора подходящих параметров (p, d, q). Однако это часто требует метода проб и ошибок или методов поиска по сетке и может привести к переобучению или недообучению.
Чувствительность к выбросам: Модели ARIMA могут быть чувствительны к выбросам, что может повлиять на их производительность. Поэтому для достижения желаемых результатов требуется тщательная предварительная обработка данных.
Долгосрочное прогнозирование: ARIMA не очень хорошо подходит для долгосрочного прогнозирования. Это связано с тем, что модели ARIMA основаны на прошлых закономерностях и могут недостаточно хорошо учитывать непредвиденные события или структурные изменения в процессе генерации данных.
Варианты использования, инструменты и поставщики ARIMA
Модели ARIMA широко применяются для прогнозирования и анализа временных рядов в различных областях. Это включает экономику и финансы, прогнозирование спроса, планирование производства и мощностей, здравоохранение и т. д.
Например, модели ARIMA использовались для прогнозирования распространения COVID-19 в Индии. Исследователи обучили модели ARIMA, используя ежедневные данные о случаях COVID-19 с 14 марта по 3 мая 2020 года, что дало удовлетворительную точность.
Многие языки программирования и статистические пакеты предоставляют инструменты для реализации моделей ARIMA. К ним относятся:
R
R обладает обширными возможностями анализа временных рядов, включая моделирование ARIMA. Несколько библиотек, включая stats, forecast и tseries, предлагают функции для реализации модели ARIMA в R.
Python
Python также предлагает обширные статистические библиотеки для реализации ARIMA. Некоторые из них включают Statsmodels, Numpy и Pandas.
MATLAB
MATLAB — это коммерческое программное обеспечение для математических вычислений со встроенными функциями для моделирования ARIMA. Оно также позволяет интеграцию с другими программными инструментами и языками программирования для сочетания моделирования ARIMA с другими рабочими процессами.
Часто задаваемые вопросы об ARIMA
Для чего используется ARIMA?
AutoRegressive Integrated Moving Average (ARIMA) — это статистическая модель, используемая для анализа и прогнозирования временных рядов. Это популярный метод прогнозирования будущих значений временного ряда на основе его прошлых значений.
Чем ARIMA отличается от других моделей прогнозирования временных рядов?
ARIMA отличается от других моделей прогнозирования временных рядов благодаря своей гибкости, интерпретируемости и широкой применимости. ARIMA может улавливать широкий спектр закономерностей в данных временных рядов, включая тренды, сезонность и автокорреляцию. Параметры в модели ARIMA имеют понятные интерпретации и могут служить базовым уровнем для сравнения с более сложными моделями.
Как интерпретировать прогнозы ARIMA?
Прогнозы ARIMA обычно интерпретируются как точечные оценки ожидаемых будущих значений временного ряда. Для оценки точности прогноза можно использовать различные метрики, такие как среднеквадратичная ошибка (MSE), средняя абсолютная ошибка (MAE) и корень из среднеквадратичной ошибки (RMSE).
Каковы предположения модели ARIMA?
Ниже приведены предположения модели ARIMA:
Стационарность: Статистические свойства временного ряда (среднее, дисперсия, автокорреляция) должны оставаться постоянными во времени.
Линейность: ARIMA предполагает линейную связь между текущим значением и его прошлыми значениями и ошибками.
Нормальность: Предполагается, что ошибки имеют нормальное распределение.
Отсутствие автокорреляции в ошибках: Предполагается, что ошибки некоррелированы.
Связанные ресурсы
Узнайте больше о хранении и предварительной обработке данных временных рядов:
- Что такое ARIMA?
- Как работает ARIMA?
- Сравнение с похожими концепциями
- Преимущества и сложности ARIMA
- Варианты использования, инструменты и поставщики ARIMA
- Часто задаваемые вопросы об ARIMA
- Связанные ресурсы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно