




Как DiDi Food преобразовал поиск продуктов по всей Латинской Америке с помощью Milvus

Снижение на 19%
в запросах без результатов, выполненных с помощью семантического векторного поиска Milvus
Увеличение на 4%
конверсии в корзине благодаря семантическому сопоставлению товаров на базе Milvus
15% запросов
теперь выигрывайте от векторного поиска, дополняющего традиционный текстовый поиск
Субсекундный векторный поиск
с индексированием Milvus IVF_FLAT и сходством по скалярному произведению
О DiDi Food
DiDi, мировой лидер в сфере заказа поездок с более чем 800 миллионами пользователей по всему миру, запустила DiDi Food — свой сервис доставки продуктов — в 12 крупных городах Латинской Америки, включая Мексику, Колумбию и Коста-Рику. Используя свою существующую логистическую сеть и возможности оптимизации в реальном времени, они добились впечатляющего роста: 2 миллиона ежемесячно активных пользователей, 500 000 ежедневных заказов и более $120 миллионов GMV в первом квартале 2025 года — всего за шесть месяцев.
Платформа доставляет свежие продукты и товары первой необходимости за 30–45 минут, при этом партнерские магазины предлагают до 30 миллионов SKU каждый. Работая на разнообразных рынках с многоязычным взаимодействием, динамическим ценообразованием и управлением запасами в реальном времени, DiDi Food создала впечатляющую бизнес-основу. Но по мере роста масштаба увеличивалась и сложность задачи: помогать миллионам клиентов находить именно то, что им нужно, в огромных каталогах товаров. Именно здесь векторная база данных Milvus преобразила их поисковые возможности, обеспечив семантическое понимание, которое работает на разных языках и справляется с реальной хаотичностью того, как люди на самом деле ищут.
Проблема поиска: когда Elasticsearch на основе ключевых слов перестает справляться
Инженерная команда DiDi столкнулась с ограничениями, которые характерны для их базы данных Elasticsearch на основе ключевых слов. Простые опечатки, переключение между языками или нестандартные описания часто приводили к пустым страницам результатов, создавая трение в процессе покупки.
Высокая доля запросов «без результатов»: скрытая потеря выручки
DiDi Food столкнулась с критической проблемой: слишком много поисковых запросов клиентов возвращали нулевые результаты, что приводило к прерванным покупательским сессиям и потере выручки. Реальные примеры из поисковых данных DiDi выявили три основные причины этих неудач.
Опечатки и ошибки в написании были самыми распространенными виновниками. Пользователи вводили "Genjibr", когда искали "Jengibre" (имбирь), "hedaho" вместо "HELADO" (мороженое) или "Kellongs" вместо "Kelloggs." Их существующие системы поиска по ключевым словам на базе Elasticsearch не могли преодолеть эти небольшие, но критически важные орфографические разрывы.
Артефакты методов ввода создавали еще один барьер. Мобильные клавиатуры и разные системы ввода генерировали необычные вариации Unicode, такие как "𝑤𝑖𝑛𝑒" вместо "wine," "𝑏𝑎𝑛𝑎𝑛𝑎" вместо "banana" или "𝑐ℎ𝑜𝑐𝑜𝑙𝑎𝑡𝑒𝑠" вместо "chocolates." Эти технические проблемы кодировки не позволяли клиентам находить товары, которые явно были в наличии.
Запросы на смешанных языках представляли самую большую сложность на рынках Латинской Америки. Клиенты естественным образом искали "apple juice orgánico" или "leche sin lactosa," комбинируя английские и испанские термины. Региональные различия усугубляли ситуацию — один и тот же продукт мог называться по-разному в Мексике, Колумбии и Коста-Рике.
Каждый неудачный поиск означал разочарованного клиента и прямую потерю выручки. Для платформы, обрабатывающей 500 000 ежедневных заказов, даже небольшой процент запросов без результатов может привести к значительному влиянию на бизнес.
Масштабируемость и многоязычная сложность
Помимо отдельных неудачных поисковых запросов, DiDi столкнулась с системными проблемами, которые угрожали ее способности масштабироваться. Индексация десятков миллионов уникальных названий SKU в текстовом виде увеличивала затраты на хранение и ухудшала производительность запросов по мере расширения каталога товаров в нескольких странах.
Многоязычная сложность была глубже, чем запросы на смешанных языках. Работа в Мексике, Колумбии, Коста-Рике и других рынках Латинской Америки означала, что один и тот же продукт мог иметь совершенно разные названия в каждом регионе. "Palta" в одних странах, "aguacate" в других — оба слова обозначают авокадо. Традиционные системы на основе ключевых слов, работающие на Elasticsearch, требовали поддерживать отдельные индексы для каждого регионального варианта, что увеличивало требования к хранилищу и усложняло обслуживание.
Культурные и лингвистические нюансы создавали дополнительные барьеры. Местный сленг, вариации названий брендов и даже разные системы измерения (метрическая и имперская) — всё это приводило к сбоям поиска. Подход на основе ключевых слов потребовал бы вручную сопоставить тысячи региональных вариаций — невозможная задача в масштабах DiDi.
Инженерной команде DiDi срочно требовалось решение, которое могло бы преодолеть эти трудности и понимать намерение, стоящее за пользовательскими запросами, независимо от языка, региона или того, как клиенты предпочитали выражать свои потребности.
Решение: создание семантической поисковой системы с Milvus
Система на базе Elasticsearch с трудом справляется с языковым разнообразием и вариативностью пользовательского ввода, поскольку рассматривает слова как отдельные токены, а не как осмысленные концепции. Векторные базы данных, однако, могут понимать семантический смысл и намерение пользовательских запросов с помощью векторных эмбеддингов и возвращать более точные и релевантные результаты независимо от языка или опечаток.
Инженерная команда DiDi решила создать семантическую поисковую систему, используя многоязычные модели эмбеддингов и векторную базу данных. Модель эмбеддингов преобразует как названия и описания продуктов, так и пользовательские запросы в векторные эмбеддинги, которые представляют их семантический смысл в многомерном пространстве, тогда как векторная база данных хранит эти эмбеддинги и выполняет семантический поиск, вычисляя расстояния между векторами запросов и векторами продуктов.
После тщательной оценки они выбрали jina-embeddings-v3 в качестве основной модели эмбеддингов, поскольку она отображает текст на разных языках в одно и то же многомерное математическое пространство. Это означает, что запросы "苹果" (китайский), "apple" (английский) или "manzana" (испанский) дают почти идентичные векторы, обеспечивая точное межъязыковое сопоставление без необходимости в сложных системах перевода. Даже слова с ошибками или фонетически похожие варианты ввода создают векторы, близкие к правильным терминам.
DiDi выбрала Milvus в качестве своей векторной базы данных благодаря её зрелости как open-source-проекта, способности горизонтально масштабироваться до миллиардов векторов, миллисекундной задержке, проверенной высокопроизводительной архитектуре и богатому набору функций.
Архитектура данных и стратегия оптимизации
Чтобы поддерживать низколатентный векторный поиск по 30 миллионам SKU, сохраняя связи на уровне магазинов, инженеры DiDi реализовали несколько ключевых оптимизаций.
Вместо хранения отдельных векторов для каждой комбинации SKU-магазин они объединили идентичные названия товаров в единые векторные записи с соответствующими ID магазинов, сохранёнными в массивах. Этот подход сократил их векторную библиотеку с 30 миллионов записей до 200 000 уникальных векторов, резко уменьшив использование памяти при сохранении полного покрытия товаров.
Команда выбрала конфигурацию индекса
IVF_FLATв Milvus, отдавая приоритет точности поиска, а не сложности сжатия. Когда пользователи отправляют запрос в систему, Milvus возвращает top-k наиболее похожих векторов из агрегированного индекса, после чего выполняется быстрая фильтрация по ID магазинов, чтобы выделить товары, доступные в текущем местоположении покупателя.Для обеспечения актуальности данных DiDi приняла ночной цикл обновления T+1. Новые и обновлённые SKU ежедневно объединяются в пакеты, повторно эмбеддируются с использованием GPU-кластеров и отправляются для обновления коллекции Milvus. Эта стратегия обеспечивает баланс между актуальностью данных и вычислительной эффективностью в их огромном каталоге товаров.
Проектирование схемы Milvus
Схема коллекции отражает специфические требования DiDi к поиску продуктов, сочетая гибкость с производительностью:
item_name = FieldSchema(
name="item_name",
dtype=DataType.VARCHAR,
is_primary=True,
max_length=1000
)
vector = FieldSchema(
name="vector",
dtype=DataType.FLOAT_VECTOR,
dim=1024
)
shop_info = FieldSchema(
name='shop_info',
dtype=DataType.ARRAY,
element_type=DataType.INT64,
max_capacity=4096)
schema = CollectionSchema(
fields=[item_name, vector, shop_info],
description="embedding using jina-embeddings-v3",
enable_dynamic_field=True
)
prop = {"shards_num": 1}
try:
collection = Collection(name=collection_name, schema=schema, using='default', properties=prop,
dimension=1024)
except CollectionNotExistException:
return False
index_params = {
"metric_type": "IP",
"index_type": "IVF_FLAT",
"params": {"nlist": 1024},
}
collection.create_index(field_name="vector", index_params=index_params)
utility.index_building_progress(collection_name)
return collection
Генерация эмбеддингов с ускорением на GPU
Первоначальная генерация эмбеддингов на CPU с моделью jina-embeddings-v3 приводила к неприемлемой задержке в 5 секунд на запись. Чтобы добиться производительности в реальном времени, DiDi развернула GPU-инстансы на своей платформе Luban, сократив время создания эмбеддинга примерно до 50 миллисекунд на запрос:
from transformers import AutoModel
jina_model = AutoModel.from_pretrained("jinaai/jina-embeddings-v3", trust_remote_code=True)
jina_model.to("cuda")
def get_jina_embedding(item_name):
vec = []
try:
vec = jina_model.encode(item_name, task="text-matching")
except Exception as e:
print(e)
return vec
Архитектура гибридного поискового пайплайна
Вместо того чтобы полностью заменять существующую инфраструктуру, DiDi внедрила Milvus как интеллектуальное дополнение к своей уже используемой системе Elasticsearch. Двойной пайплайн позволяет Elasticsearch обрабатывать стандартные ключевые запросы, тогда как Milvus обеспечивает семантическое понимание для сложных случаев.
Поисковый поток работает по следующим шагам:
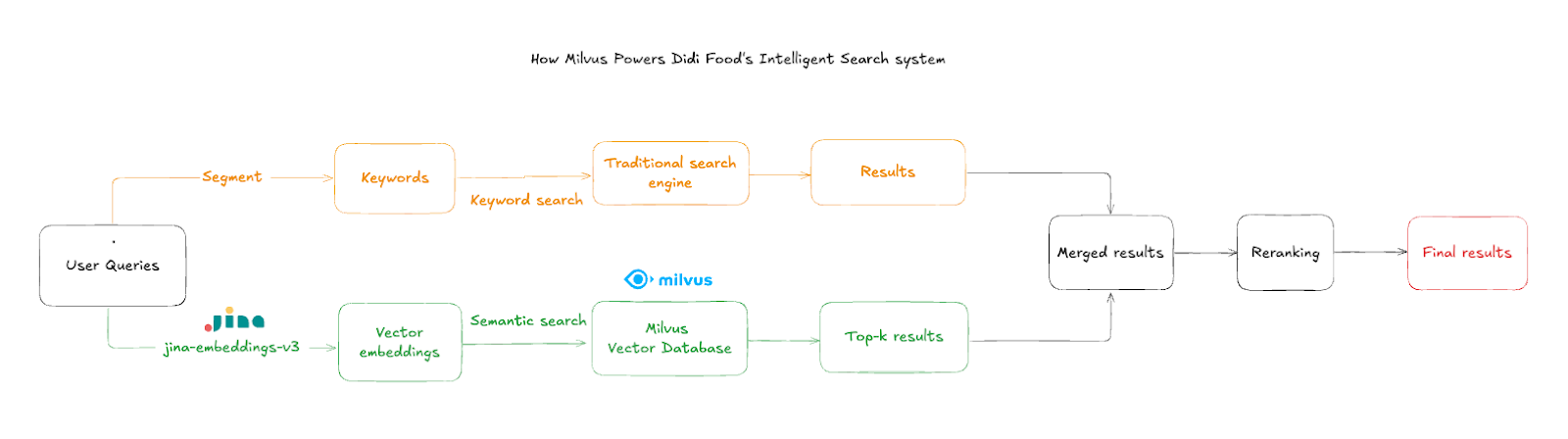
Ввод пользовательского запроса: клиенты вводят названия или описания товаров, часто с опечатками или на смешанных языках
Текстовые эмбеддинги: система использует
jina-embeddings-v3для преобразования ввода в высокоразмерные семантические векторы примерно за ~50 мсПоиск по сходству: Milvus запрашивает агрегированные векторы товаров, чтобы найти ближайшие семантические совпадения
Фильтрация по магазину: результаты фильтруются по ID магазина, чтобы отображались только товары в наличии в текущем магазине
Объединение результатов: векторные результаты комбинируются с результатами Elasticsearch, когда традиционный поиск дает неудовлетворительные результаты, обеспечивая более богатый и полный поисковый опыт
Критически важной для пользовательского опыта является фильтрация на уровне магазина, которая гарантирует, что результаты принадлежат текущему контексту местоположения покупателя. Система использует интеллектуальную агрегацию результатов — когда Elasticsearch выдает неудовлетворительные результаты, семантически релевантные товары из Milvus дополняют ответ.
Результаты производительности и реальное влияние
Внедрение Milvus в DiDi обеспечило конкретные улучшения по ключевым бизнес-метрикам.
Система достигла снижения числа запросов без результатов на 19%, что означает: почти каждый пятый ранее неудачный поиск теперь возвращает релевантные товары, напрямую восстанавливая упущенные возможности выручки. Для платформы, обрабатывающей 500 000 заказов в день, такой уровень восстановления представляет значительную бизнес-ценность.
Векторный поиск срабатывает для 15% от общего числа запросов, дополняя традиционный текстовый поиск именно тогда, когда семантическое понимание добавляет ценность, не перегружая основной конвейер обработки запросов. Что особенно важно, пользователи, которым показываются товары, найденные с помощью векторного поиска, демонстрируют рост конверсий в добавление в корзину на 4%, что доказывает: повышение релевантности поиска приводит к измеримому изменению покупательского поведения.
Теперь система обрабатывает запросы на нескольких языках, включая английский, испанский, китайский, корейский и японский, с особенно заметным повышением точности для испанского языка, что критически важно для присутствия DiDi на латиноамериканском рынке. Тестирование многоязычной производительности показало силу семантического понимания: поиск по запросу "Liquid Foundation" работает одинаково хорошо независимо от того, вводят ли пользователи английский термин, китайский "液体妆前乳" или испанский "Base de maquillaje líquida." Система преодолевает языковые разрывы, которые полностью поставили бы в тупик традиционные подходы на основе ключевых слов.
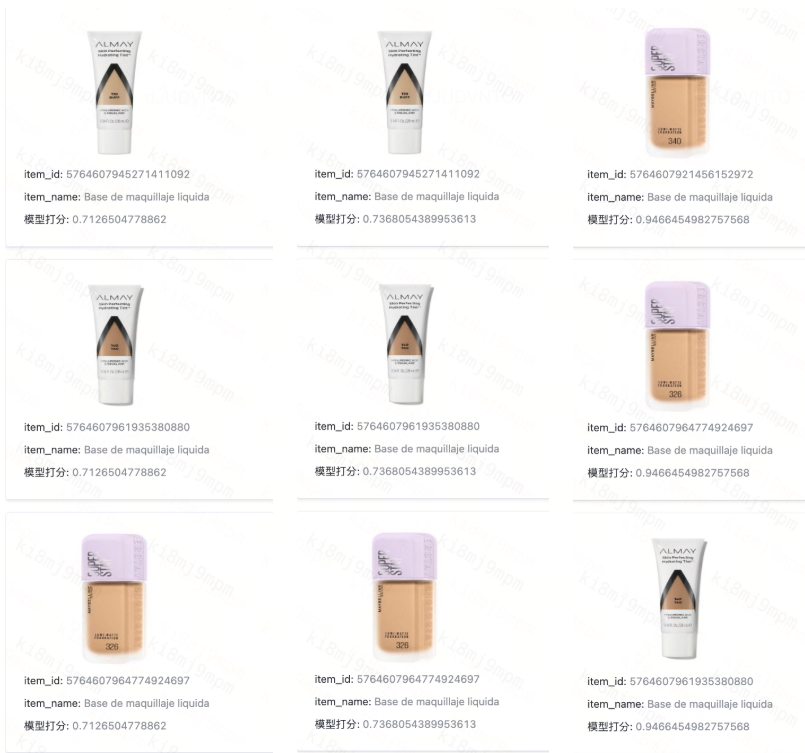
Рисунок: Поиск по запросу "Liquid Foundation" работает одинаково хорошо независимо от того, вводят ли пользователи английский термин, китайский "液体妆前乳" или испанский "Base de maquillaje líquida."
Сложные товарные запросы демонстрируют контекстное понимание векторного поиска. Когда пользователи ищут "Redac PalancaPara WC Blanca" (белый рычаг смыва для унитаза), векторная система точно сопоставляет запрос, несмотря на составную техническую терминологию, тогда как традиционный поиск не справляется с разбором многоcловного описания товара.
Эти улучшения превращаются в более плавный покупательский опыт, более высокую удовлетворенность клиентов и явное конкурентное преимущество на рынке e-commerce свежих продуктов.
Дорожная карта на будущее: поисковые возможности следующего поколения
Опираясь на этот прочный фундамент, DiDi и Milvus сотрудничают над несколькими расширенными возможностями для следующего этапа разработки.
Синхронизация каталога в реальном времени снизит задержку между изменениями в ассортименте и доступными для поиска данными благодаря потоковым обновлениям, гарантируя, что пользователи никогда не увидят товары, которых фактически нет в наличии. Интеграция поведенческих сигналов объединит векторное сходство с историей пользователя, предпочтениями и контекстными сигналами, чтобы предоставлять гиперперсонализированные рекомендации, которые со временем улучшаются.
Расширенный гибридный поиск и reranking, пожалуй, представляют собой самое интересное направление развития. Эта система будет сочетать бизнес-метрики, включая цену, рейтинги, промоакции и уровни запасов, с семантической релевантностью, чтобы показывать действительно оптимальные рекомендации для каждого отдельного покупателя.
Улучшенная многоязычная поддержка расширит языковое покрытие и улучшит обработку региональных диалектов по мере выхода DiDi на новые рынки. Динамическая оптимизация embeddings внедрит механизмы непрерывного обучения для повышения качества embeddings на основе реальных паттернов взаимодействия пользователей, тем самым создавая поисковую систему, которая становится все умнее по мере использования.
Постоянно внедряя инновации, DiDi переосмысливает опыт поиска продуктов, гарантируя, что каждый покупатель всегда находит именно то, что ему нужно.
Заключение
Путь DiDi Food с Milvus показывает, что семантический поиск — это больше, чем техническое обновление: это фундаментальное переосмысление того, как пользователи взаимодействуют с большими товарными каталогами. Сочетая продуманную архитектуру данных, правильный выбор технологий и неизменную сосредоточенность на пользовательском опыте, они создали поисковую систему, которая по-настоящему понимает намерения на разных языках и в разных культурах.
Результаты подтверждают этот подход: меньше разочарованных пользователей, больше успешных покупок и покупательский опыт, который работает независимо от того, как клиенты предпочитают выражать свои потребности. Для 2 миллионов ежемесячных пользователей DiDi это означает стабильную возможность находить то, что им нужно, когда им это нужно, на любом языке, который кажется им наиболее естественным.
Эта история успеха показывает, что становится возможным, когда инновационные компании внедряют семантическое понимание в масштабе. По мере того как DiDi продолжает расширяться в Латинской Америке, ее поисковая архитектура на базе Milvus обеспечивает надежную основу для дальнейших инноваций и удовлетворенности пользователей. Технология работает, бизнес-результаты очевидны, а улучшение пользовательского опыта ощутимо — именно это и должна обеспечивать отличная инженерия.
- О DiDi Food
- Проблема поиска: когда Elasticsearch на основе ключевых слов перестает справляться
- Решение: создание семантической поисковой системы с Milvus
- Результаты производительности и реальное влияние
- Дорожная карта на будущее: поисковые возможности следующего поколения
- Заключение
Контент
Пример использования
Отрасль
Электронная коммерция
Используемая технология