




Как Biomap трансформирует открытия в науках о жизни в масштабе с помощью векторного поиска на базе ИИ с использованием Milvus
В 22 раза быстрее
Поиск белков с сокращением времени выполнения запросов с 10–20 минут до менее чем одной минуты.
50 млрд+
Sequence Scale расширилась с сотен миллионов до десятков миллиардов биологических последовательностей.
Обнаружение в реальном времени
Ответы менее чем за секунду на сложные биологические запросы в рабочих процессах RAG.
Кросс-модальная интеграция
Объединил белки, ДНК, РНК, текстовые и клеточные данные в единую поисковую систему.
Milvus has become the bridge that connects our multi-modal foundation models with real-world applications. It's not just about performance – it's about enabling entirely new approaches to biological discovery that were previously impossible.
Xiaoming Zhang
О Biomap
Biomap — ведущая компания в области ИИ для наук о жизни, сосредоточенная на создании ИИ-моделей, которые ускоряют открытия в разработке лекарств, синтетической биологии и медицинских исследованиях. В основе ее платформы находится xTrimo — семейство крупномасштабных фундаментальных моделей, специально созданных для биологии. Масштабируясь до 210 миллиардов параметров, xTrimo объединяет белки, ДНК, РНК, клетки, молекулы и научные тексты в единую структуру, обеспечивая прогнозы и инсайты, с которыми традиционные методы не могут сравниться.
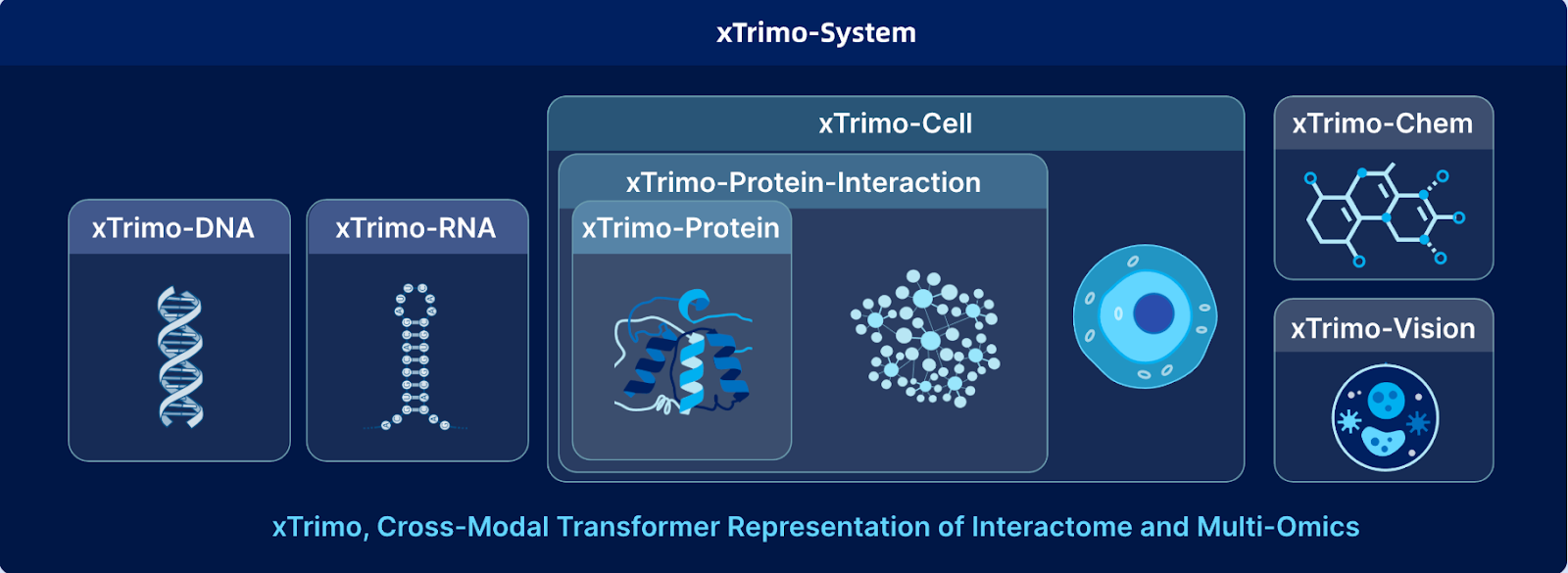
Для достижения этой возможности потребовалось преодолеть технические барьеры, включая зашумленные биологические данные, чрезвычайно разнообразные форматы и необходимость поиска по миллиардам последовательностей в реальном времени. Biomap решила эти задачи, разработав собственные модели эмбеддингов для биологических сущностей и развернув передовую инфраструктуру данных, такую как Milvus Vector Database, чтобы обеспечить быстрый и точный поиск в масштабе. Благодаря этой основе исследователи теперь могут ускорять прорывы в различных областях, включая иммунологию, неврологию, онкологию и лечение редких заболеваний.
Технические барьеры масштабирования биологического ИИ
По мере расширения возможностей ИИ Biomap команда столкнулась с несколькими узкими местами, которые традиционные инструменты не могли преодолеть.
1. Медленный поиск белков
Ранее конвейер прогнозирования структуры белков Biomap опирался на множественное выравнивание последовательностей (Multiple Sequence Alignment, MSA), которому требовалось 10–20 минут для возврата одного результата. Хотя это было приемлемо для исследований малого масштаба, такая задержка была непрактичной для производственных нагрузок, особенно при масштабировании до сотен миллионов — или даже миллиардов — последовательностей.
2. Сложность мультимодальных данных
Биологические данные по своей природе представлены во многих формах — белки, ДНК, РНК, клеточная визуализация и даже текст. Традиционные методы поиска не могли эффективно связывать эти модальности, тем самым упуская кросс-модальные инсайты, которые имеют решающее значение для понимания сложных биологических систем.
3. Дилемма скорости и точности
В биомедицинских исследованиях незначительные ошибки могут иметь серьезные последствия. RAG-ассистент Biomap для научных открытий должен был обеспечивать как ответы на запросы менее чем за секунду для интерактивности, так и точность исследовательского уровня для научной надежности. Однако большинство решений вынуждали выбирать между скоростью и точностью.
4. Специализированные требования к данным
Биологические данные имеют уникальные характеристики, требующие специальных стратегий индексирования, доменно-специфичных моделей эмбеддингов и оптимизации, настроенной для научных нагрузок, — возможностей, которые готовые решения предоставить не могли.
5. Разнообразные требования к производительности
У различных сценариев использования Biomap были очень разные потребности: разговорным ассистентам требовались мгновенные ответы, прогнозирование белков могло допускать минуты на запрос, но нуждалось в эффективной пакетной обработке, а обучение фундаментальных моделей требовало высокопроизводительных конвейеров данных. Управление этими разнообразными требованиями в рамках единой унифицированной инфраструктуры оказалось особенно сложной задачей.
Почему Biomap выбрала Milvus для обеспечения биологического ИИ в масштабе
Biomap быстро поняла, что масштабирование ее ИИ-нагрузок потребует специализированной платформы векторного поиска. Сначала команда обратилась к Faiss, популярной библиотеке векторного поиска, для небольших proof-of-concepts. Хотя Faiss хорошо показала себя в ранних экспериментах, она не справилась при производственных нагрузках, не сумев удовлетворить требованиям масштабируемости, надежности и гибкости реальных приложений в науках о жизни. После тестирования нескольких альтернатив команда обнаружила, что Milvus была единственным решением, которое соответствовало всем требованиям благодаря следующим факторам:
Гибкость открытого исходного кода: Данные в области наук о жизни являются крайне специализированными и часто требуют пользовательской индексации и алгоритмов, адаптированных к биологическим сценариям использования. Открытая архитектура Milvus дала Biomap свободу адаптировать и расширять систему без ограничений. Как объяснил Сяомин Чжан, вице-президент по технологиям Biomap, «Если это не open source, скорее всего, нет пространства для таких кастомизаций, что не подходит для наших сценариев.»
Готовая к продакшену стабильность: Для производственных развертываний Biomap требовалась зрелая платформа, поддерживаемая активной пользовательской базой, особенно среди корпоративных биотехнологических компаний. Благодаря проверенной репутации в разных отраслях и широкому принятию сообществом среди биотехнологических компаний Milvus обеспечил надежность и поддержку экосистемы, которые требовались Biomap.
Комплексный набор функций: Milvus поддерживает широкий спектр типов индексов и возможности гибридного поиска, позволяя оптимизировать поиск по белкам, ДНК, РНК, тексту и другим модальностям — всё в рамках единой системы.
Производительность в масштабе: От интерактивных ассистентов до масштабного поиска белков Biomap требовалась инфраструктура, способная обрабатывать как запросы с временем отклика менее секунды, так и массивные пакетные задания. Горизонтально масштабируемая архитектура Milvus обеспечила стабильную производительность для разных рабочих нагрузок независимо от их размера и масштаба.
Сообщество и партнерство: Команда Biomap также высоко оценила активное open-source-сообщество Milvus и потенциал долгосрочного партнерства с Zilliz, компанией, стоящей за Milvus.
Это сочетание технической глубины, зрелости экосистемы и поддержки, ориентированной на будущее, сделало Milvus очевидным выбором для производственной инфраструктуры Biomap.
Как Biomap использует Milvus для поддержки своих биологических AI-сервисов
Biomap развернула Milvus в трех критически важных сценариях использования, каждый из которых решает уникальную научную задачу, а вместе они формируют основу их биологической AI-платформы.
AI-ассистент для открытий (RAG)
В основе исследовательских процессов Biomap лежит ассистент для открытий на базе продвинутой Retrieval-Augmented Generation (RAG). Построенный на LangGraph для оркестрации, ассистент извлекает данные из огромных коллекций научной литературы, патентов и специализированных биологических баз данных. Такие данные, богатые формулами, структурами белков и предметно-специфической нотацией, затем преобразуются в векторные эмбеддинги и сохраняются в Milvus.
Milvus выполняет гибридный векторный и полнотекстовый поиск, чтобы выдавать наиболее точные результаты по запросам за доли секунды. Это позволяет исследователям выполнять поиск по специализированным биологическим знаниям и получать точные ответы в реальном времени, вместо того чтобы тратить часы на просмотр литературы.
Предсказание структуры белков в масштабе
Biomap также переосмыслила традиционный конвейер поиска белков, заменив медленные методы Multiple Sequence Alignment (MSA) векторным поиском. Их собственные фундаментальные модели белков генерируют высокоразмерные эмбеддинги, которые сохраняются и запрашиваются в Milvus. Эта новая архитектура расширила масштаб их поиска с сотен миллионов до более чем 5 миллиардов белковых последовательностей, позволяя делать открытия, ранее недоступные. Производительность также резко выросла: запросы, которые раньше занимали 10–20 минут, теперь выполняются менее чем за минуту, с более высокой точностью благодаря AI-метрикам сходства.
Кросс-модальная генерация выборок для обучения моделей
Для продвижения разработки мультимодальных фундаментальных моделей Biomap полагается на Milvus для связывания данных между биологическими модальностями. Например, исследователи могут извлекать клеточные изображения, связанные с конкретными белковыми последовательностями, или выравнивать данные молекулярного и клеточного уровней в едином векторном пространстве. Эта возможность поддерживает сложное расширение данных и обнаружение кросс-модальных ассоциаций, ускоряя обучение моделей, которые связывают текстовые, последовательностные и визуальные данные.
В совокупности эти приложения показывают, как Milvus позволяет Biomap сочетать масштаб, точность и скорость в разных областях — от повседневных открытий до передового обучения биологических моделей.
Влияние Milvus на платформу Biomap
Внедрив Milvus, Biomap достигла результатов, которые традиционная инфраструктура не могла обеспечить, преобразив как скорость, так и масштаб своих исследований.
Более быстрый поиск в масштабе миллиардов
Высокопроизводительный механизм индексирования Milvus обеспечил 22-кратное ускорение поиска белковых последовательностей. Запросы, которые раньше занимали 10–20 минут, теперь возвращают результаты менее чем за минуту, даже в масштабе 50 миллиардов последовательностей. Это представляет собой более чем 10-кратное увеличение масштаба — от сотен миллионов до десятков миллиардов биологических последовательностей — без ущерба для точности или надежности.
Более умное биологическое открытие
Milvus также изменил сам подход Biomap к открытиям. Поскольку качество поиска напрямую связано с производительностью их базовых моделей, улучшения точности моделей немедленно преобразуются в более качественные результаты извлечения. Это создает благоприятный цикл: по мере развития моделей поисковая система на базе Milvus становится точнее, раскрывая научные инсайты, которых статические методы на основе выравнивания никогда не смогли бы достичь.
Кросс-модальные прорывы
С Milvus Biomap теперь может объединять данные молекулярного и клеточного уровней в одном и том же векторном пространстве. Такое «сглаживание» различий в масштабе обеспечивает бесшовный кросс-модальный поиск, поддерживая обучение их много-модальных базовых моделей следующего поколения. Это фундаментальный шаг к их долгосрочному видению создания комплексного ИИ-симулятора биологии.
Масштабируемая платформа для наук о жизни
В конечном счете Milvus предоставляет Biomap инфраструктуру для выхода за пределы внутренних исследований к более широким приложениям в области наук о жизни. Та же платформа теперь поддерживает настраиваемые базы знаний и интеллектуальных агентов для фармацевтических компаний, больниц и компаний в области синтетической биологии, распространяя преимущества быстрого, масштабируемого биологического ИИ на всю экосистему.
Взгляд в будущее
Успех Biomap с Milvus заложил основу для расширения по всей экосистеме наук о жизни. Команда теперь расширяет свою платформу, чтобы обслуживать широкий круг заинтересованных сторон, включая фармацевтические компании, которые ускоряют открытие лекарств, медицинские учреждения, которые продвигают клинические исследования, компании в области синтетической биологии, которые оптимизируют дизайн организмов, и агробиотехнологические компании, которые способствуют генетическим улучшениям сельскохозяйственных культур. Каждый новый сценарий использования опирается на ту же базовую инфраструктуру — векторный поиск с Milvus, — которая делает сложные биологические данные доступными и пригодными к практическому применению в масштабе.
Как отметил Xiaoming, «Milvus стал единственным техническим выбором среди векторных баз данных для нашего предстоящего расширения бизнеса в индустрии наук о жизни.»
Это партнерство выходит за рамки технической интеграции. Оно создает основу для того, как биологические открытия будут совершаться в будущем: быстрее, точнее и с возможностью охватывать модальности, которые раньше были изолированы. По мере того как Biomap продолжает следовать своему видению «ИИ-симулятора жизни», Zilliz предоставляет инфраструктуру векторных баз данных, которая превращает эти амбиции в реальность, обеспечивая прорывы, способные преобразить как науку, так и индустрию.
- О Biomap
- Технические барьеры масштабирования биологического ИИ
- Почему Biomap выбрала Milvus для обеспечения биологического ИИ в масштабе
- Как Biomap использует Milvus для поддержки своих биологических AI-сервисов
- Влияние Milvus на платформу Biomap
- Взгляд в будущее
Контент
Пример использования
Отрасль
Науки о жизни
Milvus has become the only technical choice for vector databases in our upcoming business expansion across the life sciences industry.
Xiaoming Zhang