




Топ-10 техник контекстной инженерии, которые вам следует знать для production RAG
Когда мы впервые создаём демо RAG или агента, всё обычно работает хорошо. С небольшим набором данных, несколькими промптами и простым поиском мы часто можем запустить прототип за несколько часов.
Настоящая проблема появляется, когда мы пытаемся запустить систему в продакшене. По мере роста использования проблемы проявляются быстро. Поиск становится медленнее, ответы — менее надёжными, задержка увеличивается, а затраты растут. То, что работало в небольшом демо, часто ломается, когда появляются реальные данные, реальные пользователи и более длинные контексты.
В этот момент мы обычно понимаем, что проблема не только в модели. Она также связана с тем, как контекст подготавливается и передаётся модели. Именно здесь появляется context engineering. Он фокусируется на поиске, организации, уточнении и управлении информацией, которую языковая модель использует для генерации ответов.
В этой статье мы объясняем, как context engineering работает на практике. Мы рассматриваем современные подходы к построению контекста, его эффективной обработке и управлению им во времени. Эти техники помогают превращать простые демо в системы, которые могут надёжно работать в продакшене.
Примечание: эта статья в основном основана на статье https://arxiv.org/html/2507.13334v1.
Что такое Context Engineering?
Context engineering фокусируется на сборке информации, необходимой большой языковой модели для того, чтобы хорошо ответить на вопрос. Эта информация не ограничивается промптом. Она также включает запрос пользователя, найденные документы, историю разговора и другие релевантные данные. Цель — повысить точность, сократить время ответа и контролировать затраты.
Эта работа в основном выполняется автоматически с помощью алгоритмов. Context engineering объединяет prompt engineering, retrieval-augmented generation (RAG) и multi-agent техники в одну систему, вместо того чтобы использовать их по отдельности.
На практике setup context engineering состоит из двух частей. Первая включает foundational components, которые отвечают за извлечение данных, обработку и оркестрацию. Второй слой состоит из более complex systems, которые объединяют эти компоненты в полноценные приложения. Команды могут комбинировать и повторно использовать эти части, чтобы адаптироваться к разным производственным сценариям.
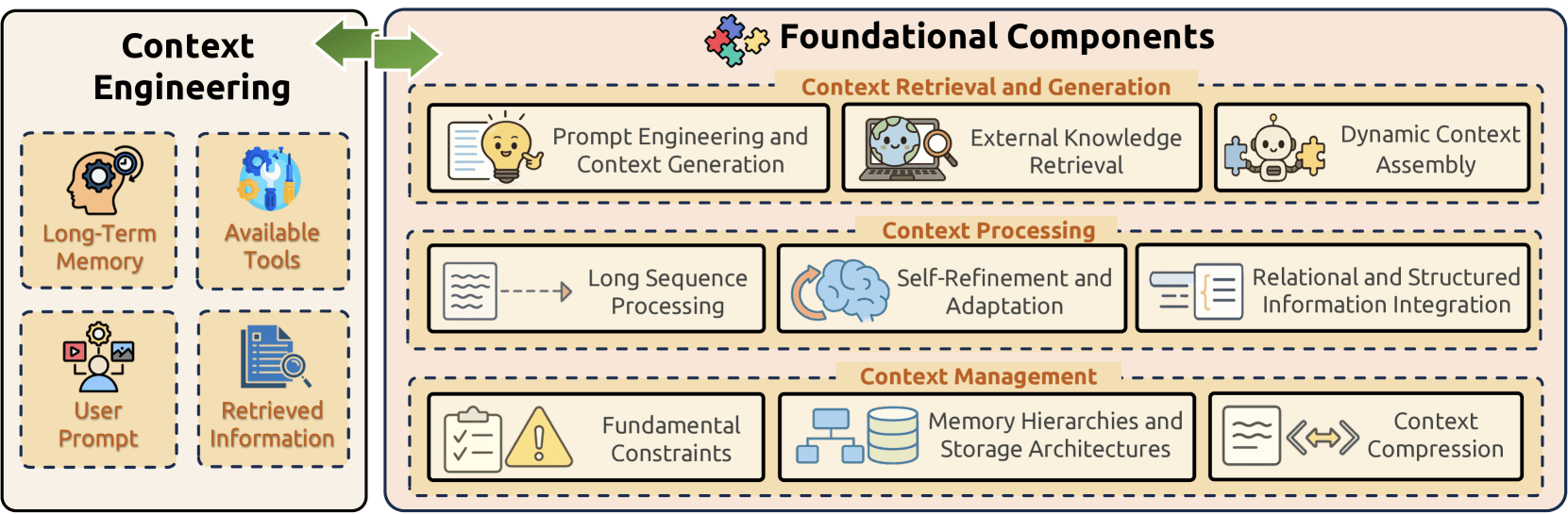
Foundational Components
Context Engineering строится на трёх фундаментальных компонентах, которые вместе решают ключевые задачи управления информацией в больших языковых моделях:
- Context Retrieval and Generation получает подходящую контекстную информацию с помощью prompt engineering, извлечения внешних знаний и динамической сборки контекста;
- Context Processing преобразует и оптимизирует полученную информацию с помощью обработки длинных последовательностей, механизмов самоулучшения и интеграции структурированных данных;
- Context Management решает задачи эффективной организации и использования контекстной информации через преодоление фундаментальных ограничений, внедрение сложных иерархий памяти и разработку методов сжатия.
Complex Systems in Practice
Поверх этих фундаментальных компонентов context engineering применяется через несколько распространённых типов сложных систем.
Retrieval-augmented generation (RAG) позволяет модели искать информацию в базе знаний перед тем, как ответить на вопрос. Это помогает гарантировать, что ответ основан на реальных, актуальных данных, а не на догадках модели. На практике RAG может быть построен как простой модульный pipeline, управляться агентами, которые контролируют поиск, или комбинироваться с графами знаний для более богатого контекста.
Memory systems позволяют моделям отслеживать информацию между взаимодействиями. Краткосрочная память хранит детали текущего разговора, а долгосрочная память сохраняет прошлые разговоры и усвоенные знания. Это делает многоходовые диалоги более последовательными и помогает системе улучшаться со временем.
Рассуждение с интеграцией инструментов позволяет моделям использовать внешние инструменты, такие как калькуляторы, поисковые системы или API, вместо того чтобы полагаться только на текстовое рассуждение. Важная часть такой схемы — вставлять результаты работы инструментов обратно в контекст в нужный момент, чтобы модель могла эффективно их использовать.
Мультиагентные системы используют несколько моделей, которые совместно работают над выполнением сложных задач. У каждого агента есть конкретная роль, а система координирует то, как они общаются, обмениваются информацией и остаются синхронизированными, чтобы получить согласованный результат.
Обработка контекста
Ранее мы представили три основные части контекстной инженерии: извлечение и генерация контекста, обработка контекста и управление контекстом. Они образуют базовые строительные блоки практической контекстной системы.
Обработка контекста особенно важна. Она берет необработанную извлеченную информацию, очищает ее, преобразует и организует так, чтобы модель могла понимать и использовать ее более эффективно.
В этом разделе мы рассмотрим, как обработка контекста выполняется в реальных системах и какие подходы обычно используются.
Обработка длинного контекста
Обработка очень длинных контекстов дорого обходится, потому что трансформерные модели используют self-attention, масштабируемость которого ухудшается по мере роста длины входных данных. Чем длиннее последовательность, тем быстрее растут вычислительные затраты и использование памяти, создавая реальные узкие места в производственных системах.
Например, увеличение длины входа Mistral-7B с 4K до 128K токенов повышает вычислительные затраты примерно в 122×. Использование памяти также резко растет как при prefilling, так и при decoding. На практике такие модели, как Llama 3.1 8B, могут требовать до 16 GB памяти для одного запроса на 128K токенов.
Чтобы обойти эти ограничения, исследователи в основном используют три подхода.
Один из них — создавать новые архитектуры моделей, такие как Mamba, которые изначально дешевле в запуске. Другой — использовать техники вроде позиционной интерполяции, чтобы существующие модели могли обрабатывать гораздо более длинные входы. Третий подход улучшает способ выполнения вычислений, избегая избыточной работы и более эффективно используя память, чтобы обработка длинного контекста была быстрее и требовала меньше ресурсов.
(1) Архитектурные инновации для длинного контекста
Чтобы справиться с квадратичной стоимостью Transformers, исследователи разработали новые архитектуры моделей, которые делают обработку длинных последовательностей дешевле и эффективнее.
- State Space Models (SSMs) поддерживают линейную вычислительную сложность и постоянные требования к памяти за счет скрытых состояний фиксированного размера; такие модели, как Mamba, предлагают эффективные рекуррентные механизмы вычислений, которые масштабируются эффективнее, чем традиционные transformers.
- Подходы dilated attention, такие как LongNet, используют экспоненциально расширяющиеся поля внимания по мере роста расстояния между токенами, достигая линейной вычислительной сложности при сохранении логарифмической зависимости между токенами, что делает возможной обработку последовательностей длиной более одного миллиарда токенов.
- Toeplitz Neural Networks (TNNs) моделируют последовательности с помощью матриц Toeplitz с кодированием относительной позиции, снижая пространственно-временную сложность до лог-линейной и обеспечивая экстраполяцию с 512 обучающих токенов до 14 000 токенов при инференсе.
- Механизмы linear attention снижают сложность с O(N²) до O(N), выражая self-attention как линейные скалярные произведения карт признаков ядра, достигая ускорения до 4000× при обработке очень длинных последовательностей.
Альтернативные подходы, такие как non-attention LLMs, преодолевают квадратичные барьеры, применяя recursive memory transformers и другие архитектурные инновации.
(2) Позиционная интерполяция и расширение контекста
Техники позиционной интерполяции позволяют моделям обрабатывать последовательности за пределами исходных ограничений контекстного окна за счет интеллектуального перемасштабирования позиционных индексов, а не экстраполяции на невиденные позиции.
- Подходы на основе Neural Tangent Kernel (NTK) предоставляют математически обоснованные фреймворки для расширения контекста, при этом YaRN (Yet another RoPE-based Interpolation method) сочетает интерполяцию NTK с линейной интерполяцией и коррекцией распределения внимания.
- Двухэтапные подходы: LongRoPE достигает контекстных окон в 2048K токенов с помощью двухэтапных подходов: сначала выполняется дообучение моделей до длины 256K, затем проводится позиционная интерполяция для достижения максимальной длины контекста.
- Position Sequence Tuning (PoSE) демонстрирует впечатляющее расширение длины последовательности до 128K токенов за счет объединения нескольких стратегий позиционной интерполяции.
- Техники Self-Extend позволяют LLM обрабатывать длинные контексты без дообучения, используя двухуровневые стратегии внимания — grouped attention и neighbor attention — для захвата зависимостей между удаленными и соседними токенами.
(3) Методы оптимизации для эффективной обработки
Не изменяя базовую архитектуру модели, исследователи также разработали ряд методов оптимизации, чтобы сделать обработку длинного контекста более эффективной.
Grouped-Query Attention (GQA) разделяет query heads на группы, которые совместно используют key и value heads, обеспечивая баланс между multi-query attention и multi-head attention при одновременном снижении требований к памяти во время декодирования.
FlashAttention использует асимметричную иерархию памяти GPU для достижения линейного масштабирования памяти вместо квадратичных требований, при этом FlashAttention-2 обеспечивает примерно двукратное ускорение за счет сокращения операций, не связанных с матричным умножением, и оптимизированного распределения работы.
Ring Attention с Blockwise Transformers позволяет обрабатывать чрезвычайно длинные последовательности, распределяя вычисления между несколькими устройствами, используя поблочные вычисления и одновременно перекрывая коммуникацию с вычислением внимания.
Техники Sparse attention включают Shifted sparse attention (S²-Attn) в LongLoRA и SinkLoRA с SF-Attn, которые достигают 92% улучшения перплексии full attention при значительной экономии вычислений.
Управление памятью и сжатие контекста снижают стоимость длинных входных данных. Rolling Buffer Cache ограничивает окно внимания, чтобы уменьшить память KV cache, тогда как StreamingLLM поддерживает длинные последовательности, сохраняя только ключевые токены и недавний контекст. Другие методы, такие как Infini-attention и H2O, повышают эффективность за счет сжимающей памяти и более интеллектуального вытеснения из кэша.
Контекстуальное самоулучшение и адаптация
Самоулучшение позволяет LLM улучшать выходные данные посредством циклических механизмов обратной связи, отражающих человеческие процессы редактирования, используя самооценку через разговорное самовзаимодействие с помощью prompt engineering, отличного от подходов reinforcement learning.
Идея проста: для сложных задач легче написать первую версию, а затем исправить ее, чем сразу сделать все правильно. Когда модели учатся проверять собственную работу и улучшать ее шаг за шагом, они лучше справляются с рассуждением, написанием кода и творческими задачами, а также легче адаптируются к новым ситуациям.
(1) Фундаментальные фреймворки самоулучшения
- Фреймворк Self-Refine использует одну и ту же модель как генератор, поставщик обратной связи и улучшатель, демонстрируя, что выявлять и исправлять ошибки часто проще, чем создавать идеальные начальные решения.
- Reflexion сохраняет рефлексивный текст в буферах эпизодической памяти для будущего принятия решений посредством языковой обратной связи, тогда как структурированное руководство оказывается необходимым, поскольку упрощенные промпты часто не позволяют обеспечить надежную самокоррекцию.
- Фреймворк N-CRITICS реализует ансамблевую оценку, при которой начальные выходные данные оцениваются как генерирующими LLM, так и другими моделями, а скомпилированная обратная связь направляет улучшение до выполнения специфичных для задачи критериев остановки.
(2) Метаобучение и автономная эволюция
На более продвинутом этапе самоулучшение контекста фокусируется на метаобучении и автономном совершенствовании. Цель — помочь модели не только решать задачи, но и со временем учиться учиться лучше.
SELF обучает LLM метанавыкам (самообратная связь, самоулучшение) на ограниченном числе примеров, а затем позволяет модели непрерывно самоэволюционировать, генерируя и фильтруя собственные обучающие данные. Механизмы самовознаграждения позволяют моделям автономно улучшаться через итеративное самооценивание, при котором одна модель принимает на себя двойные роли исполнителя и судьи, максимизируя вознаграждения, которые она назначает себе.
Фреймворк Creator расширяет эту парадигму, позволяя LLM создавать и использовать собственные инструменты через четырехмодульный процесс, охватывающий создание, принятие решений, выполнение и распознавание.
Фреймворк Self-Developing представляет наиболее автономный подход, позволяя LLM обнаруживать, реализовывать и совершенствовать собственные алгоритмы улучшения через итеративные циклы, генерирующие алгоритмические кандидаты в виде исполняемого кода.
Мультимодальный контекст
Мультимодальные большие языковые модели (MLLM) выходят за пределы текста, работая с такими входными данными, как изображения, аудио и 3D-данные. Они объединяют эти разные типы информации в единый контекст, над которым модель может рассуждать.
Это делает возможными более продвинутые приложения, но также создает новые вызовы, такие как интеграция различных модальностей, рассуждение между ними и обработка длинных, сложных входных данных.
(1) Интеграция мультимодального контекста
Интеграция контекста является ядром обработки мультимодального контекста. Она направлена на объединение информации из разных модальностей, таких как изображения, текст и аудио, в единое представление, с которым модель может рассуждать.
Базовый подход превращает изображения в токены с помощью энкодеров вроде CLIP, а затем добавляет их к текстовым токенам перед отправкой всего этого в языковую модель. Это легко реализовать, но разные модальности часто остаются слабо связанными.
Более продвинутые методы улучшают интеграцию. Кросс-модальное внимание позволяет модели изучать прямые связи между визуальными и текстовыми токенами внутри модели, что важно для таких задач, как редактирование изображений и визуальное рассуждение.
Для масштабирования на длинные или сложные входные данные иерархические архитектуры обрабатывают каждую модальность поэтапно. Некоторые системы также объединяют информацию из нескольких изображений или входных данных перед передачей в модель, вместо того чтобы обрабатывать каждое по отдельности.
Другие работы вообще избегают адаптации моделей, обученных только на тексте, с самого начала обучаясь на мультимодальных данных и тексте совместно. Кросс-модальное рассуждение опирается на это, требуя от модели понимать не только каждую модальность отдельно, но и смысл, возникающий при их объединении, например сарказм, выраженный одновременно через изображение и текст.
(2) Внешние мультимодальные энкодеры и модули выравнивания
Интеграция мультимодального контекста строится на двух основных частях: внешних мультимодальных энкодерах и модулях выравнивания, которые соединяют их с языковой моделью.
В большинстве современных систем каждый тип данных обрабатывается специализированным энкодером. Например, изображения обрабатываются моделями вроде CLIP, а аудио — моделями, такими как CLAP. Эти энкодеры превращают сырые входные данные, такие как пиксели или звуковые волны, в векторы признаков.
Затем модули выравнивания преобразуют эти признаки в пространство эмбеддингов языковой модели, чтобы они могли работать вместе с текстовыми токенами. Некоторые системы используют простые отображения вроде MLP, тогда как другие используют Q-Former, который выбирает визуальные признаки, наиболее релевантные тексту, с помощью обучаемых токенов запросов.
Такая модульная схема упрощает сопровождение систем. Энкодеры можно обновлять или заменять без переобучения всей языковой модели, что важно для развертывания в реальных условиях.
Реляционный и структурированный контекст
Большие языковые модели сталкиваются с фундаментальными ограничениями при обработке реляционных и структурированных данных, включая таблицы, базы данных и графы знаний, из-за требований текстового ввода и ограничений последовательной архитектуры.
Линеаризация часто не позволяет сохранить сложные связи и структурные свойства, а производительность снижается, когда информация рассредоточена по всему контексту.
Чтобы решить эту проблему, исследователи искали способы представить структурированные данные в форме, которую языковые модели могут использовать. Цель состоит в том, чтобы помочь моделям лучше справляться с задачами, связанными со сложным рассуждением и проверкой фактов.
(1) Эмбеддинги графов знаний и нейронная интеграция
Продвинутые стратегии кодирования устраняют структурные ограничения с помощью эмбеддингов графов знаний, которые преобразуют сущности и связи в числовые векторы, обеспечивая эффективную обработку в архитектурах языковых моделей.
Графовые нейронные сети улавливают сложные связи между сущностями, облегчая многошаговое рассуждение по структурам графов знаний с помощью специализированных архитектур, таких как GraphFormers, которые встраивают компоненты GNN наряду с блоками трансформеров.
(2) Вербализация
Один из распространенных подходов — преобразовать структурированные данные, такие как графы знаний, таблицы или записи баз данных, в текст на естественном языке, чтобы их можно было напрямую использовать существующими языковыми моделями без изменения их архитектуры. Другие методы реорганизуют входной текст в структурированные слои на основе лингвистических связей или извлекают ключевую информацию и явно представляют ее в виде графов, таблиц или реляционных схем.
В некоторых случаях представление структурированных данных с помощью языков программирования работает лучше, чем естественный язык. Например, использование кода Python для графов знаний или SQL для баз данных часто приводит к более высокой производительности в задачах сложного рассуждения, потому что эти форматы более четко сохраняют структуру. Существуют также ресурсоэффективные подходы, которые используют компактные матричные представления для обработки структурированных данных с меньшим числом параметров при сохранении хорошей производительности.
(3) Гибридные архитектуры
Чтобы работать со структурированными данными со сложными связями, такими как таблицы и графы знаний, исследователи изучали гибридные архитектуры, которые объединяют большие языковые модели с компонентами, предназначенными для графово-структурированных данных, такими как графовые нейронные сети.
Используется несколько практических подходов. GraphToken делает связи явными, добавляя специальные токены, что помогает моделям рассуждать по графам. Heterformer обрабатывает текст и структуру графа совместно в единой среде, сохраняя информацию о связях и одновременно контролируя вычислительные затраты.
Другие методы интегрируют знания по-разному. K-BERT добавляет информацию из графа знаний во время обучения, чтобы модель заранее усвоила эти связи. KAPING извлекает релевантные знания во время инференса без дообучения. Более продвинутые решения используют адаптеры и внимание, чтобы напрямую смешивать графовую информацию с моделью, обеспечивая более тесную интеграцию.
Заключение
Контекстная инженерия предлагает полезный способ понять, как LLM-системы работают в продакшене. В целом она включает три основных процесса: извлечение и генерацию контекста, обработку контекста и управление контекстом. Вместе эти этапы определяют, как информация собирается, подготавливается и передается модели.
Среди них обработка контекста особенно важна, поскольку она определяет, как извлеченная информация очищается, организуется и сжимается перед тем, как попасть в модель. Из-за ограничений по объему эта статья в основном сосредоточилась на этой части и рассмотрела несколько подходов, используемых в реальных системах. Извлечение и управление контекстом также являются важными областями и могут быть подробнее рассмотрены в будущих обсуждениях.
Если вы создаёте RAG или агентные системы и сталкиваетесь с производственными проблемами, связанными с контекстом, стоимостью или задержками, присоединяйтесь к нашему Slack Channel, чтобы обсудить инжиниринг контекста с другими инженерами. Вы также можете забронировать короткую индивидуальную сессию, чтобы получить практические рекомендации по переходу от демо к готовым к продакшену системам через Milvus Office Hours.
Читать далее

Zilliz Cloud Now Available in AWS Asia Pacific (Seoul)
Zilliz Cloud is now available in AWS Seoul — low-latency vector search, in-country data residency, and one-step migration for Korean AI teams. 31 regions across 5 clouds.

How Zilliz Saw the Future of Vector Databases—and Built for Production
An inside look at how Zilliz built vector databases for real-world use, focusing on scalability, stability, and running them reliably at scale.

Zilliz Cloud Enterprise Vector Search Powers High-Performance AI on AWS
Zilliz Cloud on AWS powers secure, scalable, ultra-fast vector search for enterprise AI apps, with BYOC, sub-10ms latency, and zero-DevOps simplicity.