




Мультимодальный RAG локально с CLIP и Llama3
С недавним выходом GPT-4o и Gemini мультимодальность стала горячей темой в последнее время. Еще одна тема, которая была на вершине освещения, - Retrieval Augmented Generation (RAG) в течение последнего года, но она была в основном ориентирована на текст. В этом уроке вы узнаете, как создать мультимодальную систему RAG.
Используя мультимодальную RAG, вам не обязательно использовать только текст; вы можете использовать различные типы данных, такие как изображения, аудио, видео и, конечно же, текст. Также можно возвращать различные типы данных; если вы используете текст в качестве входных данных для вашей системы RAG, это не значит, что вы должны возвращать текст в качестве выходных данных. Мы продемонстрируем это в этом уроке.
Предварительные условия
Прежде чем приступить к настройке различных компонентов нашего учебника, убедитесь, что в вашей системе есть все необходимое:
Docker & Docker-Compose - Убедитесь, что Docker и Docker-Compose установлены в вашей системе.
Milvus Standalone-Для наших целей мы будем использовать эффективный Milvus Standalone, который легко управляется через Docker Compose; изучите нашу документацию по установке руководство.
OllamaУстановите Ollama в вашей системе. Это позволит нам использовать Llama3 на нашем ноутбуке. Посетите их веб-сайт для получения последнего руководства по установке.
OpenAI CLIP
Основная идея модели CLIP (Contrastive Language-Image Pretraining) заключается в том, чтобы понять связь между картинкой и текстом. Это фундаментальная модель ИИ, обученная на парах текст-изображение. Затем она учится создавать точку в векторном пространстве для текста и изображения. В этом пространстве похожие текстовые описания будут находиться рядом с соответствующими изображениями, и наоборот.
CLIP можно использовать в различных приложениях, в том числе:
Поиск изображений: Представьте себе поиск изображений по текстовому описанию или поиск идеальной подписи к изображению.
Мультимодальное обучение: сильные стороны CLIP в соединении текста и изображений делают его идеальным строительным блоком для таких систем, как мультимодальный RAG, которые работают с информацией в разных форматах.
Это позволяет нашей системе RAG понимать и отвечать на запросы, которые могут включать как текст, так и изображения.
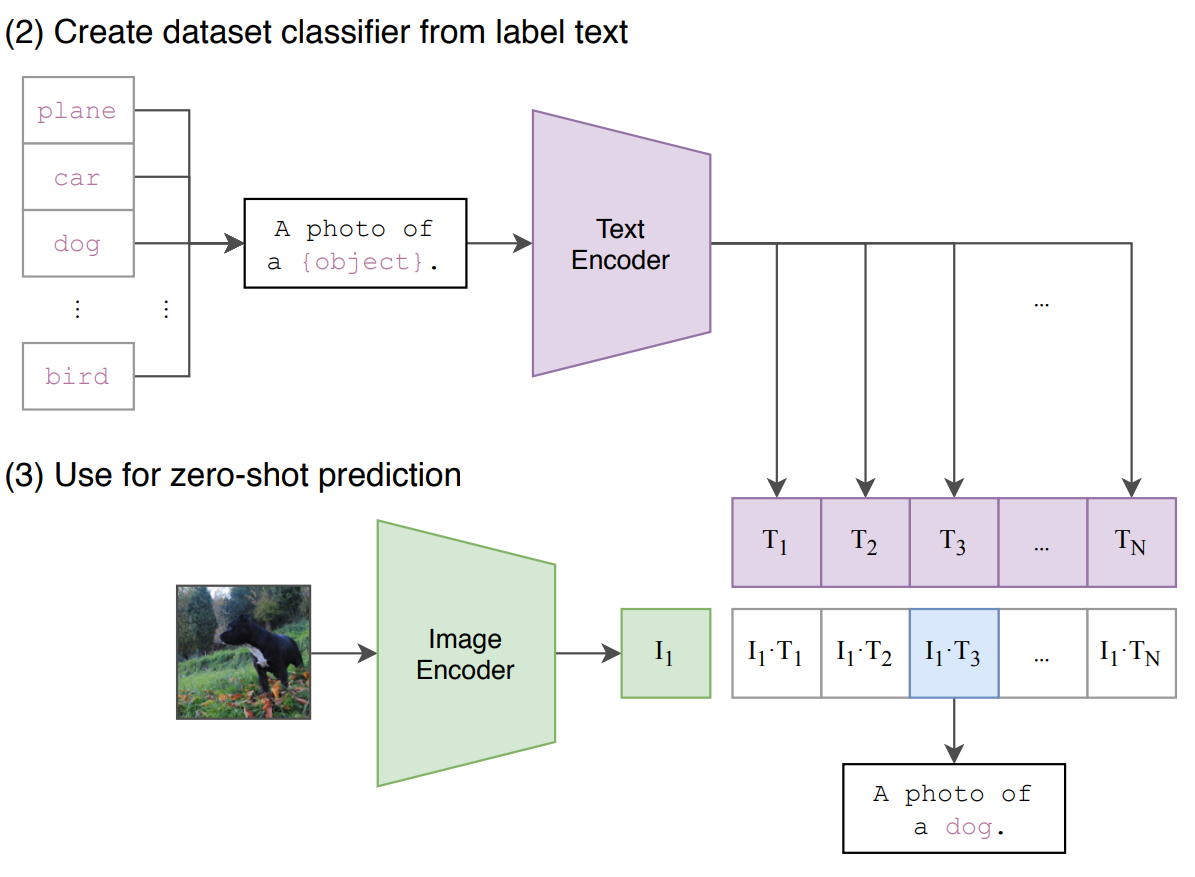 Рис1: Архитектура OpenAI CLIP
Рис1: Архитектура OpenAI CLIP
Мультимодальные вкрапления
**Что такое вкрапления? ** Проще говоря, вкрапления - это сжатые представления данных. CLIP принимает на вход изображение или текст и преобразует его в числовой код, отражающий его ключевые особенности.
Прелесть CLIP в том, что он работает как с текстом, так и с изображениями. Вы можете предоставить ему изображение, и он сгенерирует вставку, передающую его визуальный контент. Однако вы также можете предоставить текст, и CLIP сгенерирует вставку, отражающую смысл текста.
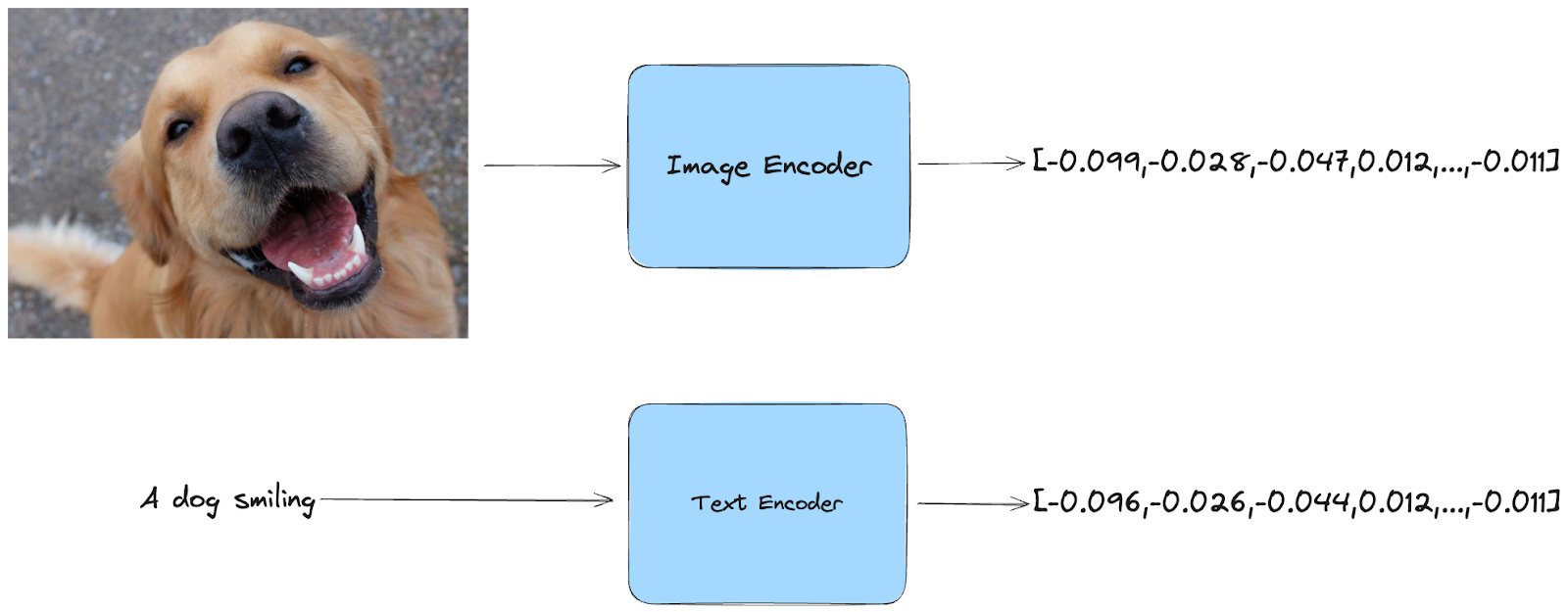 Multimodal Embeddings
Multimodal Embeddings
Если представить себе проекцию в векторном пространстве, то вкрапления с похожими значениями окажутся рядом друг с другом. Например, текст "Собака с улыбкой" и изображение собаки, которая, кажется, улыбается, находятся близко друг к другу.
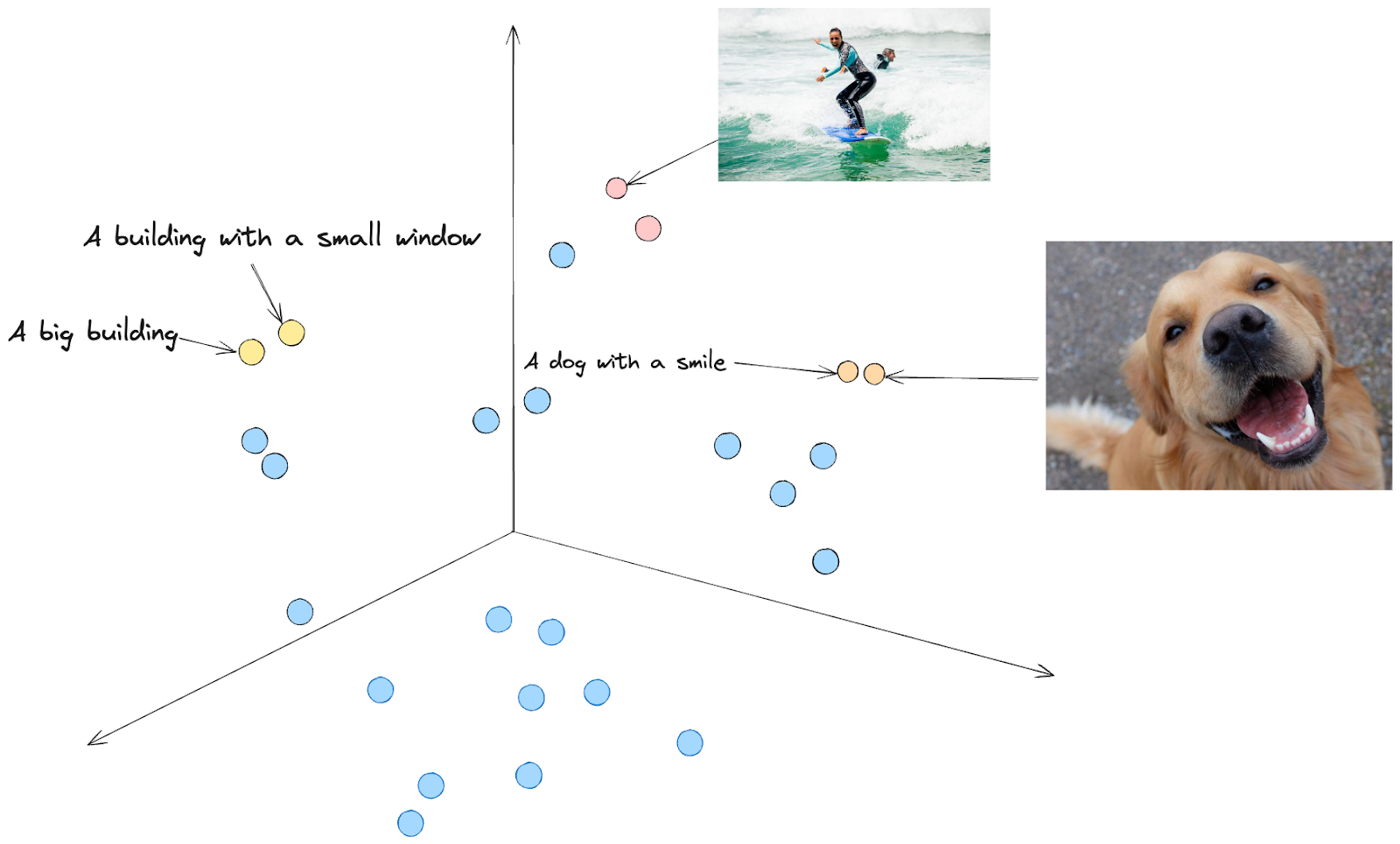 Рис2. Представление в векторном пространстве
Рис2. Представление в векторном пространстве
Построение мультимодальной RAG
Мы будем использовать данные из Википедии, загружать текстовые данные, связанные с тем, о чем мы хотим узнать больше, и делать то же самое с изображениями.
Мы будем генерировать вкрапления с помощью модели CLIP ViT-B/32 и использовать Llama3 в качестве LLM.
Мы храним эмбеддинги в Milvus, который предназначен для управления крупными эмбеддингами, чтобы мы могли осуществлять быстрый и эффективный поиск.
LlamaIndex используется в качестве механизма запросов в сочетании с Milvus в качестве хранилища векторов.
Весь код довольно длинный, так как нам нужно просмотреть Википедию, обработать текст и изображения, а затем создать RAG-приложение. Тем не менее, он полностью доступен на Github, так что вам обязательно стоит его посмотреть!
После того, как все заработает, вы сможете выполнять запросы, похожие на следующие:
# https://en.wikipedia.org/wiki/Helsinki
query2 = "Какие популярные туристические достопримечательности есть в Хельсинки?"
# генерировать результаты поиска изображений
image_query(query2)
# генерировать результаты текстового поиска
text_retrieval_results = text_query_engine.query(query2)
print("Результаты поиска текста: \n" + str(text_retrieval_results))
В результате должно получиться что-то похожее на
Среди популярных туристических достопримечательностей Хельсинки - Суоменлинна (Свеаборг), остров-крепость с богатой историей, и зоопарк Коркеасаари, расположенный на одном из главных островов Хельсинки. Кроме того, в городе много природных заповедников, в том числе Ванханкаупунгинселькя, который является самым большим заповедником в Хельсинки.

Таким образом, вы получите мультимодальное приложение RAG, которое может обрабатывать изображения или текст, а также возвращать изображения или текст.
Вы можете получить доступ к коду на Github, задавать вопросы в Discord и ставить нам звезды на Github.

Читать далее

Why Context Engineering Is Becoming the Full Stack of AI Agents
Discover how context engineering unifies prompts, RAG, and tools to build smarter, production-ready AI agents powered by Milvus.
Milvus/Zilliz + Surveillance: How Vector Databases Transform Multi-Camera Tracking
See how Milvus vector database enhances multi-camera tracking with similarity-based matching for better surveillance in retail, warehouses and transport hubs.

AI Integration in Video Surveillance Tools: Transforming the Industry with Vector Databases
Discover how AI and vector databases are revolutionizing video surveillance with real-time analysis, faster threat detection, and intelligent search capabilities for enhanced security.