




Почему мы создали Vector Lakebase: переосмысление архитектуры неструктурированных данных для ИИ
Недавно мы запустили Zilliz Vector Lakebase, следующий этап эволюции Zilliz Cloud от чисто векторной системы баз данных к единой, lake-native основе данных для AI-нагрузок. Анонс вызвал большой интерес. Он также почти сразу породил вопросы о том, куда движется Zilliz.
Отходит ли Zilliz от векторных баз данных? Или, если говорить прямо: векторные базы данных уже устаревают?
Я понимаю, почему возникли эти вопросы. На протяжении многих лет Zilliz была известна созданием готовых к production векторных систем баз данных (open-source Milvus и полностью управляемой Zilliz Cloud). Поэтому, когда мы начали говорить об эволюции к lake-native основе данных для AI, некоторые люди естественно задались вопросом, означает ли это смену направления.
Короткий ответ — НЕТ. Абсолютно НЕТ. Во всяком случае, Vector Lakebase — это наш ответ на то, что происходит после успеха векторных баз данных.
За последние несколько лет векторные базы данных стали одним из фундаментальных инфраструктурных слоев AI-стека. Внедрение росло быстрее, чем мы могли представить, когда почти десять лет назад начинали Milvus. Категория реальна, а потребность в семантическом поиске становится только важнее.
Но нам также стало ясно кое-что еще: векторный поиск больше не является всей проблемой.
По мере того как AI-системы переходят от статичных ассистентов к постоянно работающим агентам, предприятия ожидают от своей инфраструктуры неструктурированных данных чего-то более широкого. Им нужна не просто система, способная извлекать информацию. Им нужна система, которая может улучшать данные, реорганизовывать их, анализировать, уточнять и возвращать эти улучшения обратно в production. Это меняет архитектуру.
Этот сдвиг напоминает мне более ранний цикл в истории инфраструктуры: эволюцию баз данных в эпоху мобильного интернета. Детали отличаются, но закономерность знакома. Новый тип приложений создает новый тип нагрузки на данные. Первое поколение инфраструктуры решает непосредственную задачу обслуживания. Затем, по мере роста данных, архитектура должна расширяться.
Думаю, векторные базы данных сейчас вступают в эту следующую стадию.
Мобильный интернет уже однажды прошел через этот цикл
Около 2010 года, когда мобильные приложения стремительно росли, MongoDB стала одним из определяющих инфраструктурных продуктов того периода.
Причина была проста. Мобильные приложения генерировали огромные объемы полуструктурированных данных: пользовательские события, социальную активность, телеметрию устройств, поведенческие сигналы, продуктовые логи. Ничто из этого не укладывалось аккуратно в шаблоны реляционных баз данных, которыми в то время пользовалось большинство команд. Продуктовые команды быстро выпускали новые версии, схемы постоянно менялись, и первой задачей было просто принимать данные, не замедляя работу приложения. MongoDB очень хорошо решила эту непосредственную задачу: сначала загружать данные. Структурирование и анализ могли появиться позже.

Несколько лет спустя индустрия начала задавать другой вопрос. Когда все эти данные уже появились, как бизнес мог реально их использовать? Этот сдвиг помог подъему современных хранилищ данных, таких как Snowflake и Redshift. Фокус сместился с операционного хранения на аналитические инсайты. Компаниям нужны были BI-отчеты, пользовательские когорты, атрибуция, прогнозирование и анализ роста. Данные перестали быть только операционным побочным продуктом и стали бизнес-активом.
Затем возникло еще одно узкое место.
Разделение между транзакционными и аналитическими системами становилось все более болезненным. Конвейеры данных между средами OLTP и OLAP были хрупкими, дорогими и операционно изматывающими. Одни и те же наборы данных многократно копировались между системами, часто с задержками синхронизации и малозаметными несоответствиями.
Это была среда, которая породила архитектуру Lakehouse. Databricks, Iceberg, Hudi и связанные с ними системы сошлись вокруг одной базовой идеи: единая логическая копия данных должна поддерживать несколько вычислительных моделей без необходимости бесконечного перемещения между системами.
Оглядываясь назад, эта эволюция кажется почти неизбежной. Но в то время ничего из этого не было очевидным. Взлет MongoDB не предвещал Snowflake. Snowflake не предвещал Lakehouse. Каждый переход возникал потому, что предыдущее поколение инфраструктуры успешно масштабировалось, а затем выявляло новый класс ограничений.
Этот паттерн важен, потому что инфраструктура ИИ всё больше кажется идущей по похожему пути.
Поиск решил первую проблему, а не последнюю
Когда большие языковые модели получили массовое распространение в 2023 году, векторные базы данных стали одной из первых быстро выросших категорий инфраструктуры. Причина была практической. RAG-системам требовался нативный способ хранить embeddings и выполнять семантический поиск. Большинство традиционных баз данных не были предназначены для высокоразмерного векторного поиска, ANN-индексов, гибридного поиска и низколатентной фильтрации в масштабе.
Во многом векторные базы данных решили проблему того же рода, какую ранее решила MongoDB. Новый паттерн приложений создал новую абстракцию данных, и разработчикам понадобилась инфраструктура, способная её поддерживать. На этот раз абстракцией было семантическое представление: embeddings, сгенерированные из неструктурированных данных нейронными моделями.
Первая фаза внедрения произошла очень быстро. Но всего несколько лет спустя вопросы, которые мы слышим от клиентов, стали гораздо сложнее. Они больше не спрашивают только о том, как эффективно извлекать векторы. Они спрашивают:
- Как нам непрерывно дедуплицировать и улучшать обучающие данные?
- Как нам анализировать миллиарды embeddings на предмет кластеризации и проблем качества?
- Как нам выявлять дрейф, смещения или избыточность в мультимодальных наборах данных?
- Как нам трассировать и оптимизировать истории выполнения агентов?
- Как нам повторно обрабатывать и улучшать данные по мере развития моделей?
- Как нам искать в холодных данных, не поддерживая все вычисления постоянно запущенными?
- Как нам использовать данные, которые уже находятся в Iceberg, Lance, Parquet и объектном хранилище, для нескольких AI-нагрузок?
Это уже не чисто проблемы поиска. Они требуют крупномасштабной офлайн-обработки, итеративных рабочих процессов исследования, управления данными, аналитического изучения и непрерывных циклов обратной связи между онлайн-системами и офлайн-вычислениями. Всё чаще мы замечали нечто важное у продвинутых AI-команд: узким местом была уже не только способность модели. Им была скорость итерации.
Один опыт сделал это болезненно очевидным. Мы видели команды, пытавшиеся повторно обрабатывать большие векторные наборы данных: заново кластеризовать embeddings, удалять дублирование, регенерировать индексы, заново создавать embeddings для целых корпусов. В некоторых случаях простое перемещение миллиарда векторов из одной системы в другую могло занимать дни. Не часы. Дни.
Тем временем циклы итераций внутри ведущих AI-команд движутся в противоположном направлении. Исследователи хотят экспериментировать непрерывно. Data-инженеры находятся под давлением необходимости быстрее очищать, оценивать и обновлять наборы данных. Модели улучшаются. Embedding-модели меняются. Агенты каждый день создают новые трассы. Но инфраструктурный стек под ними не был спроектирован для непрерывных циклов улучшения неструктурированных данных.
Именно в этот момент мы начали думать, что индустрия формулирует проблему слишком узко.
Инфраструктура неструктурированных данных — это не просто слой поиска. Она становится непрерывно работающей системой.
От систем поиска к непрерывным системам: CS/CD
Внутри компании мы начали описывать эту архитектуру как непрерывный цикл между обслуживанием и исследованием. Со временем мы начали называть это CS/CD: Continuous Serving and Continuous Discovery.
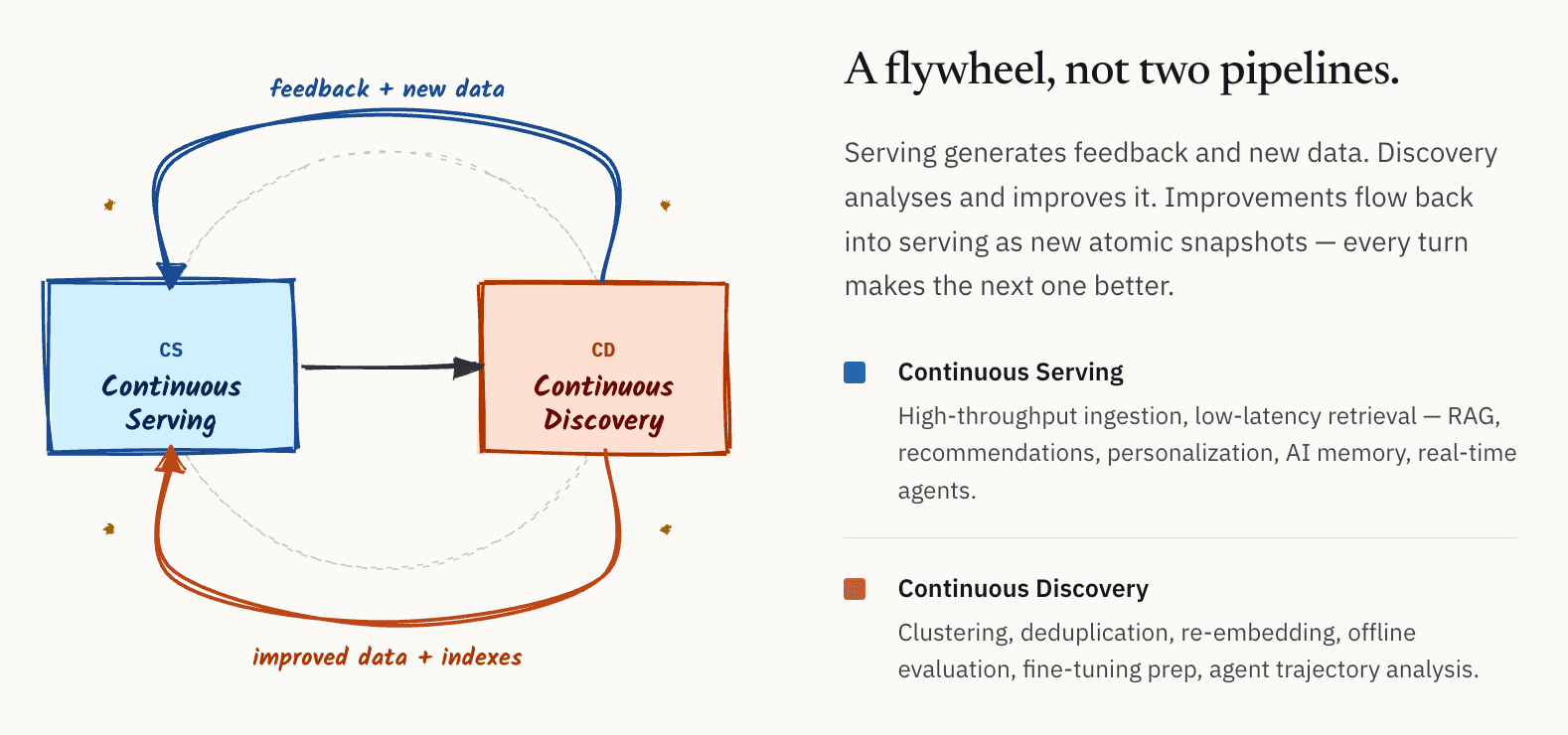
Идея концептуально проста.
- С одной стороны, есть слой обслуживания: высокопроизводительный прием данных, низколатентное извлечение для онлайн-систем RAG, рекомендательных систем, персонализации, памяти ИИ и агентов реального времени.
- С другой стороны, есть слой discovery: кластеризация, дедупликация, повторное построение эмбеддингов, офлайн-оценка, анализ качества, подготовка к дообучению моделей и анализ траекторий агентов.
Важный момент в том, что это не независимые рабочие процессы. Они образуют маховик. Системы обслуживания непрерывно генерируют обратную связь и новые данные. Системы discovery анализируют и улучшают эти данные. Полученные улучшения, включая более качественные эмбеддинги, более чистые наборы данных, улучшенные индексы и уточненные метаданные, затем возвращаются в слой обслуживания.
Каждая итерация должна улучшать следующую. По крайней мере, в теории.
На практике большинство организаций все еще не могут эффективно управлять этим циклом, потому что базовая инфраструктура остается фрагментированной.
Сегодня, если команда хочет выполнить крупномасштабную офлайн-обработку производственных векторных данных, типичный рабочий процесс по-прежнему остается мучительно ручным. Данные сначала нужно экспортировать из векторной базы данных в озеро данных или пакетную среду. Индексы обычно нельзя использовать повторно. Конвейеры синхронизации становятся хрупкими. Инкрементальные обновления затруднены. Обработанные результаты в итоге нужно повторно импортировать в систему обслуживания, часто без какой-либо гарантии атомарной согласованности между новыми данными и новыми индексами.
Результат — медленный, хрупкий и дорогой рабочий процесс. А поскольку его обслуживание настолько дорого, многие организации просто избегают непрерывного discovery. Данные лежат там, доступны для извлечения, но в значительной степени остаются неисследованными.
Это все больше напоминало нам исторический разрыв между системами OLTP и OLAP, только теперь фрагментация существует между онлайн-семантическим извлечением и офлайн-обработкой неструктурированных данных.
Почему существующие архитектуры в итоге упираются в свои ограничения
Мы все больше убеждались в одном: ни одна из сторон текущего инфраструктурного стека не является ошибочной.
Векторные базы данных и Lakehouse-системы обе решают важные задачи. Проблема в том, что каждая архитектура была оптимизирована только под одну половину формирующейся нагрузки.
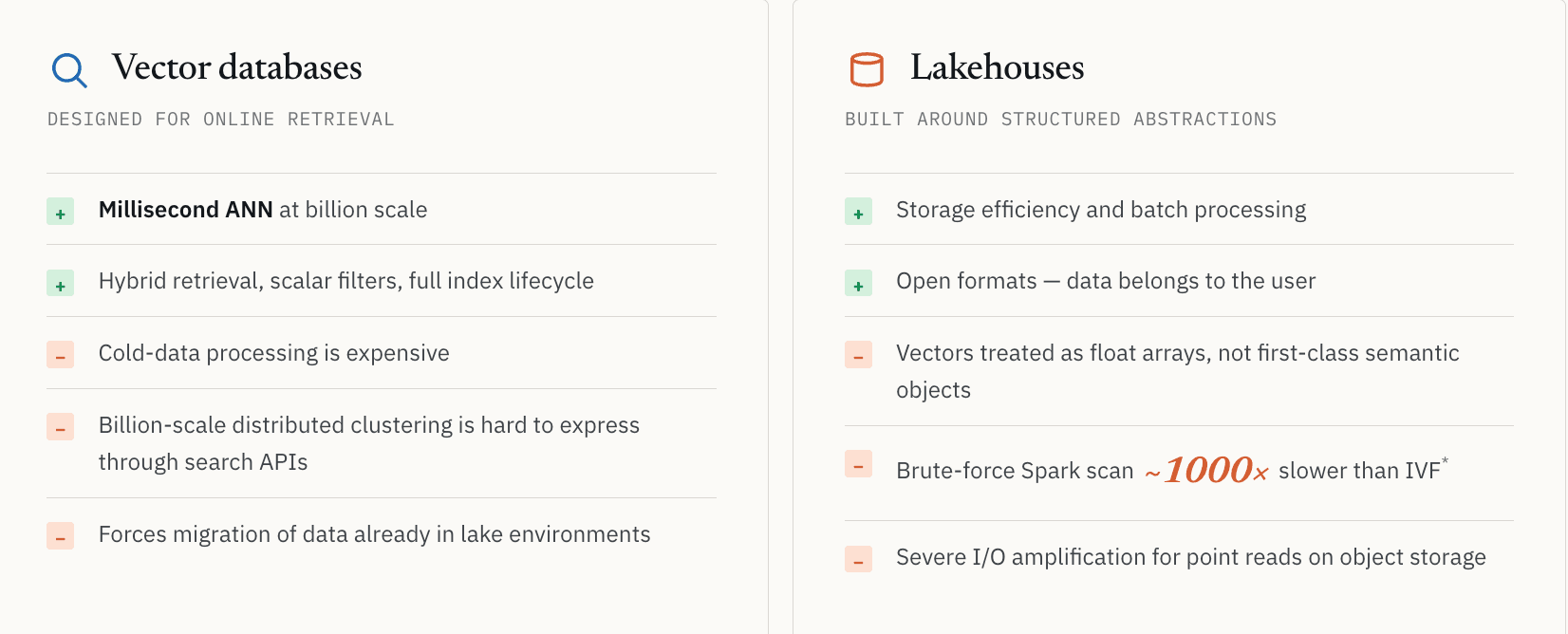
Векторные базы данных были спроектированы в первую очередь для онлайн-извлечения.
Возьмем в качестве примера open-source Milvus. Он исключительно хорошо решает задачу векторного поиска в масштабе. Но когда рабочие нагрузки выходят за рамки обслуживания и переходят к крупномасштабному discovery, проявляются естественные архитектурные границы.
Обработка холодных данных становится дорогой. Распределенную кластеризацию в масштабе миллиардов объектов трудно выразить через API онлайн-поиска. Многие системы предполагают, что данные должны оставаться загруженными в онлайн-инфраструктуру, чтобы оставаться доступными для запросов. Предприятия, которые уже хранят огромные неструктурированные наборы данных в озерных средах, сталкиваются с затратами на миграцию и фрагментацией управления, когда их просят перенести все в специализированную систему извлечения.
Это не ошибки реализации. Это последствия оптимизации под низколатентное онлайн-извлечение.
Lakehouse-системы решают задачи эффективности хранения и пакетной обработки, но были спроектированы вокруг абстракций структурированных данных
Противоположный подход, начинающийся со стороны Lakehouse, вносит другой набор компромиссов.
Lakehouse-системы элегантно решают задачи эффективности хранения и пакетной обработки. Но они были спроектированы вокруг абстракций структурированных данных. В большинстве lake-архитектур векторы по-прежнему рассматриваются как длинные массивы чисел с плавающей точкой, а не как первоклассные семантические объекты. Форматы файлов вроде Parquet не проектировались с учетом ANN-индексов, инвертированных индексов или низколатентных путей семантического извлечения.
Мы увидели это напрямую на примере фармацевтического клиента, выполнявшего поиск молекулярного сходства. Полный перебор Spark по данным в lake был примерно в 1000 раз медленнее, чем извлечение индексированных векторов с использованием поиска на основе IVF. Точное число зависит от распределения данных, параметров индекса и оборудования, но вывод неизменен: без правильного индекса многие семантические нагрузки экономически непрактичны.
Существует и более базовая проблема хранения. Объектное хранилище может приводить к серьезному усилению I/O для нагрузок, ориентированных на извлечение. Семантический поиск часто находит небольшое количество ID, но приложению всё равно нужны полные записи, стоящие за этими ID. При использовании традиционных колоночных форматов извлечение нескольких небольших записей может требовать чтения больших блоков хранилища. Это нормально для сканирования. Но плохо подходит для низколатентного обслуживания.
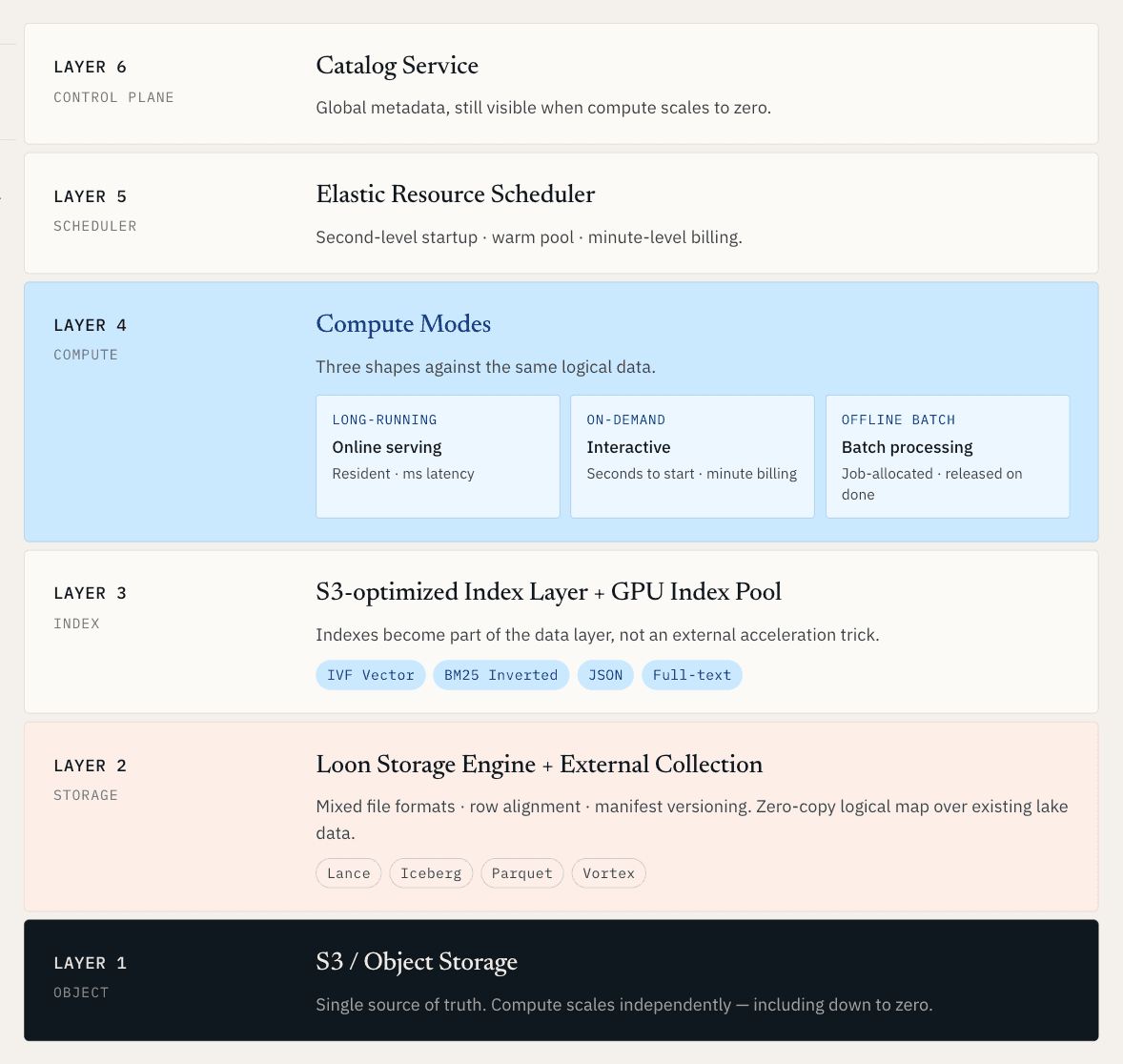
Со временем наш вывод стало трудно игнорировать: отрасль не должна выбирать между векторными базами данных и lake-архитектурами. Ей нужна архитектура, в которой извлечение и крупномасштабное обнаружение являются нативными частями одной и той же операционной системы.
Что мы подразумеваем под Vector Lakebase
Это осознание привело нас к тому, что мы теперь называем Vector Lakebase. Основная идея — это не «векторная база данных плюс data lake». Я считаю, что такая формулировка упускает более глубокий архитектурный смысл.
Цель — создать единый операционный слой для неструктурированных данных, в котором online serving, offline discovery и эластичные вычисления работают на одной и той же логической основе данных.
Для сырых данных это означает, что векторы, документы, метаданные, логи и индексы управляются вместе в lake-native хранилище. Для данных, которые уже находятся в Iceberg, Lance, Parquet или объектном хранилище, это означает, что система может отображать и индексировать эти данные без необходимости полной миграции.
Если исходить из этого требования, архитектура должна решать сразу несколько сложных задач. Вычисления должны масштабироваться независимо от хранилища. Индексы должны стать частью слоя данных, а не внешним трюком для ускорения. Новые данные и новые индексы должны публиковаться вместе как согласованные снимки. А существующие данные в lake должны становиться доступными для поиска без создания еще одной копии.
Эти идеи звучат просто. Заставить их работать, сохранив производительность, которую люди ожидают от векторной базы данных, — вот сложная часть. Именно здесь начинают иметь значение низкоуровневые инженерные решения.
Цена разделения хранилища и вычислений и как мы с этим справляемся
Разделение хранилища и вычислений необходимо для цикла CS/CD, но оно не бесплатно.
Медленный холодный старт
Если вычисления могут масштабироваться до нуля, первый запрос в on-demand или offline рабочем процессе может попасть в полностью холодные данные. У узла нет локального индекса, нет прогретого кэша и нет резидентных данных. Всё должно поступать из объектного хранилища.
Для небольших наборов данных это управляемо. Для больших векторных нагрузок это быстро становится неприемлемым. Рассмотрим один миллиард 768-мерных векторов. Обычный индекс HNSW может занимать около 340 ГБ. Загрузка всего этого индекса из S3 может занять более четырех минут. Никто не хочет ждать четыре минуты, прежде чем поиск сможет начаться.
Наш ответ — сделать cold path намного меньше. Используя 1+3-битное квантование в стиле RaBitQ, мы можем сжать этот индекс примерно с 340 ГБ до примерно 13 ГБ. Поиск выполняется в два этапа. Первый этап использует 1-битное представление для грубой фильтрации, с recall примерно 85–90 процентов, при этом уменьшая размер данных примерно до одной тридцатой от исходного. Второй этап использует 1+3-битное представление для rerank и уточнения результатов примерно до 95 процентов recall. Это сокращает холодный старт с минут примерно до 5–10 секунд.
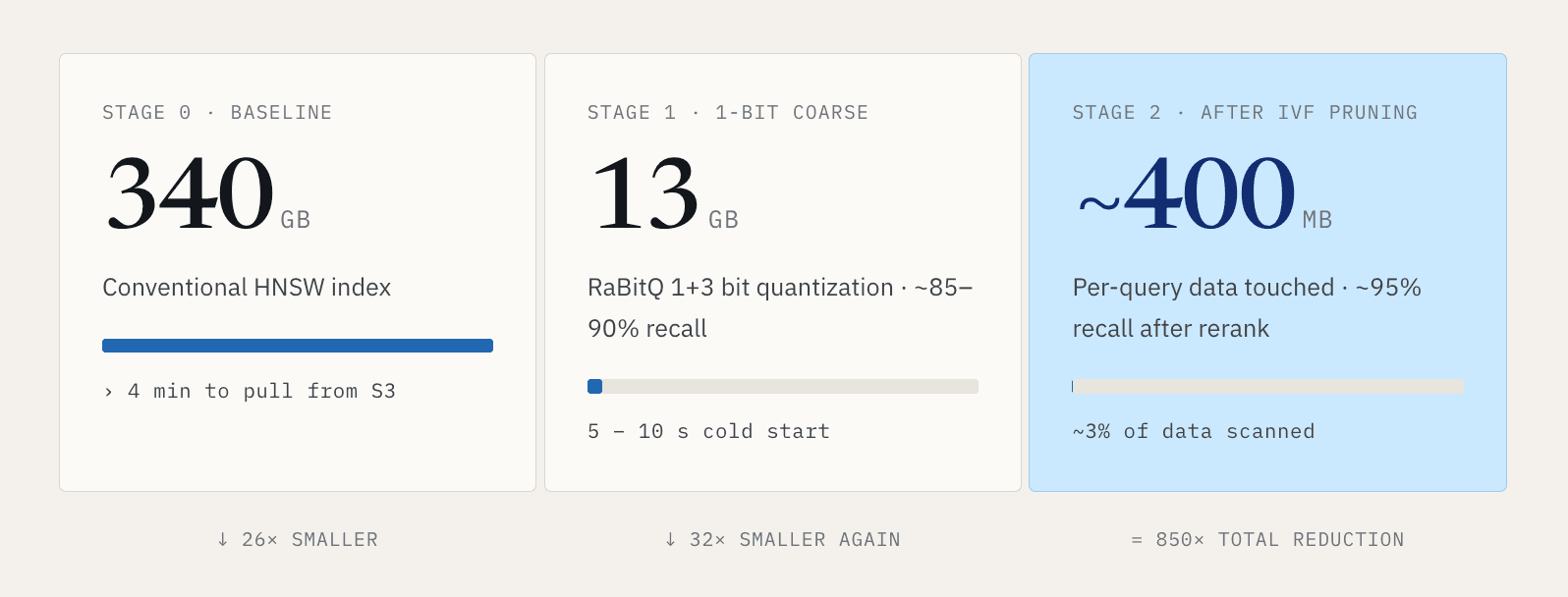
Затем мы используем IVF-кластеризацию, чтобы сократить объем данных, затрагиваемых каждым запросом. В репрезентативной конфигурации каждый запрос сканирует около 3 процентов данных. Путь становится таким: 340 ГБ обычного индекса, сжатые до 13 ГБ, при этом один запрос после отсечения затрагивает примерно 400 МБ.
В этом и заключается разница между эластичным векторным поиском как идеей и эластичным векторным поиском как пригодной к использованию системой.
Амплификация I/O
Холодный старт — лишь одна сторона проблемы. Другая сторона — доступ к записям.
Векторный поиск возвращает ID. Но приложениям нужны полные записи: текстовые фрагменты, метаданные, указатели на документы, разрешения, временные метки, атрибуты изображений или другие поля. В стандартной разметке Parquet небольшое точечное чтение может заставить систему загрузить большую группу строк. Запросу может понадобиться всего несколько килобайт полезных данных, но в итоге он вытянет десятки мегабайт из объектного хранилища. Уменьшение групп строк помогает точечным чтениям, но ухудшает сжатие и эффективность сканирования.
Именно поэтому мы создали Loon, переработанный движок хранения, лежащий в основе Zilliz Vector Lakebase.
Loon использует смешанные файловые форматы, выравнивание строк и версионирование на основе манифестов. Скалярные поля могут использовать колоночные разметки, которые остаются эффективными для фильтрации и сканирования. Векторные поля и данные с большим количеством точечных запросов могут использовать разметки, лучше подходящие для низколатентного извлечения. Группы колонок выравнивают ID строк, чтобы система могла получать нужные ей поля, не протаскивая через сеть большие несвязанные блоки.
Под капотом Loon использует Vortex, файловый формат с открытым исходным кодом под эгидой Linux Foundation. Vortex поддерживает гибкие разметки и вложенные кодировки, включая точечные запросы без распаковки больших нерелевантных блоков.
В одном внутреннем тесте с 3 миллионами строк, 128-мерными векторами, хранилищем S3 и 256 параллельными читателями точечные чтения Parquet загружали около 9,4 МБ на чтение. Vortex загружал около 0,07 МБ. Это сокращение загружаемых данных в 135 раз. Пропускная способность полного сканирования в этой конфигурации также была выше.
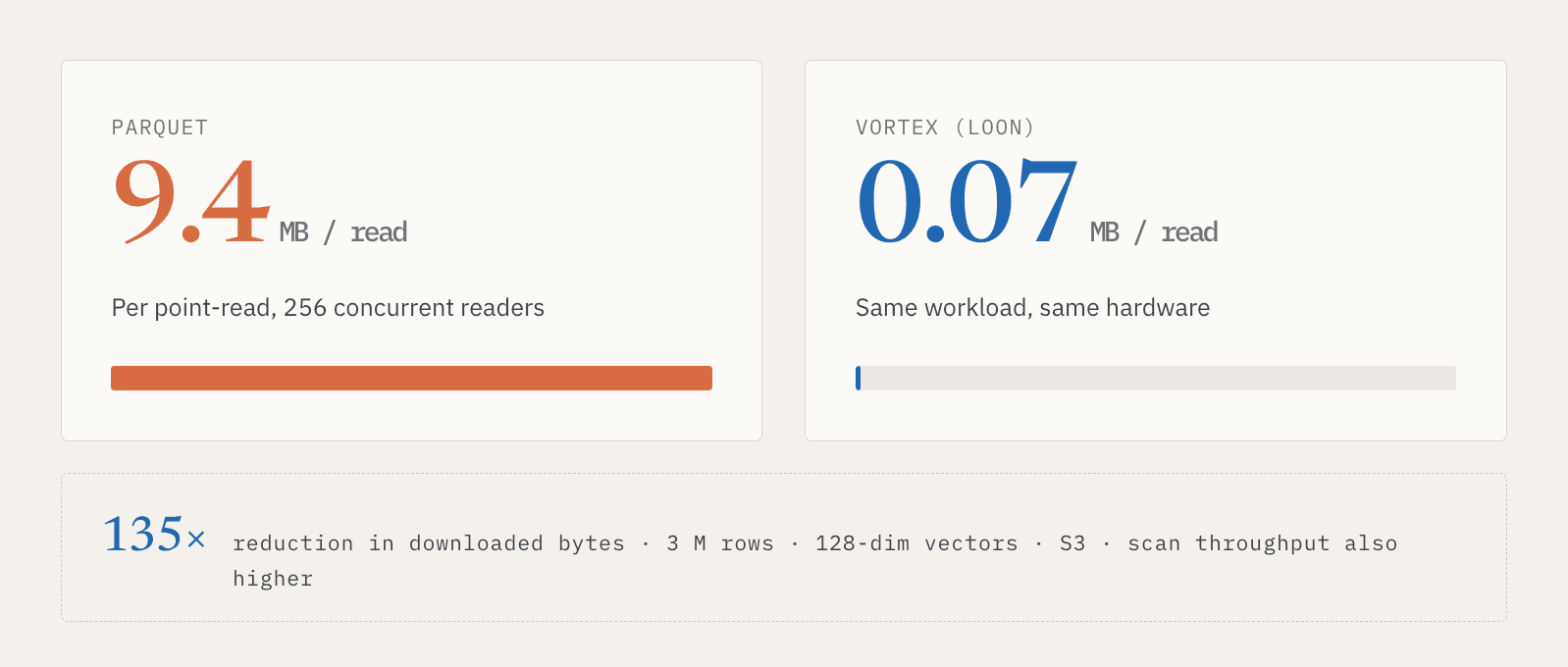
Суть не только в том, что один формат быстрее в одном бенчмарке. Суть в том, что обслуживание и исследование требуют разных шаблонов доступа к одним и тем же логическим данным. Онлайн-системам нужны быстрые точечные чтения. Пакетным системам нужны эффективные сканирования. Vector Lakebase должен поддерживать и то и другое, не заставляя пользователей поддерживать две копии данных.
Vector Lakebase: единая основа данных, несколько режимов вычислений
После того как слой данных становится общим, вычисления не могут быть универсальными.
Разные AI-нагрузки имеют очень разные формы. Некоторым нужна предсказуемая низкая задержка в течение всего дня. Некоторым нужна интерактивная поисковая сессия на десять минут. Некоторым нужна большая пакетная задача, которая выполняется ночью, а затем исчезает.
Именно поэтому Zilliz Vector Lakebase поддерживает три режима вычислений.
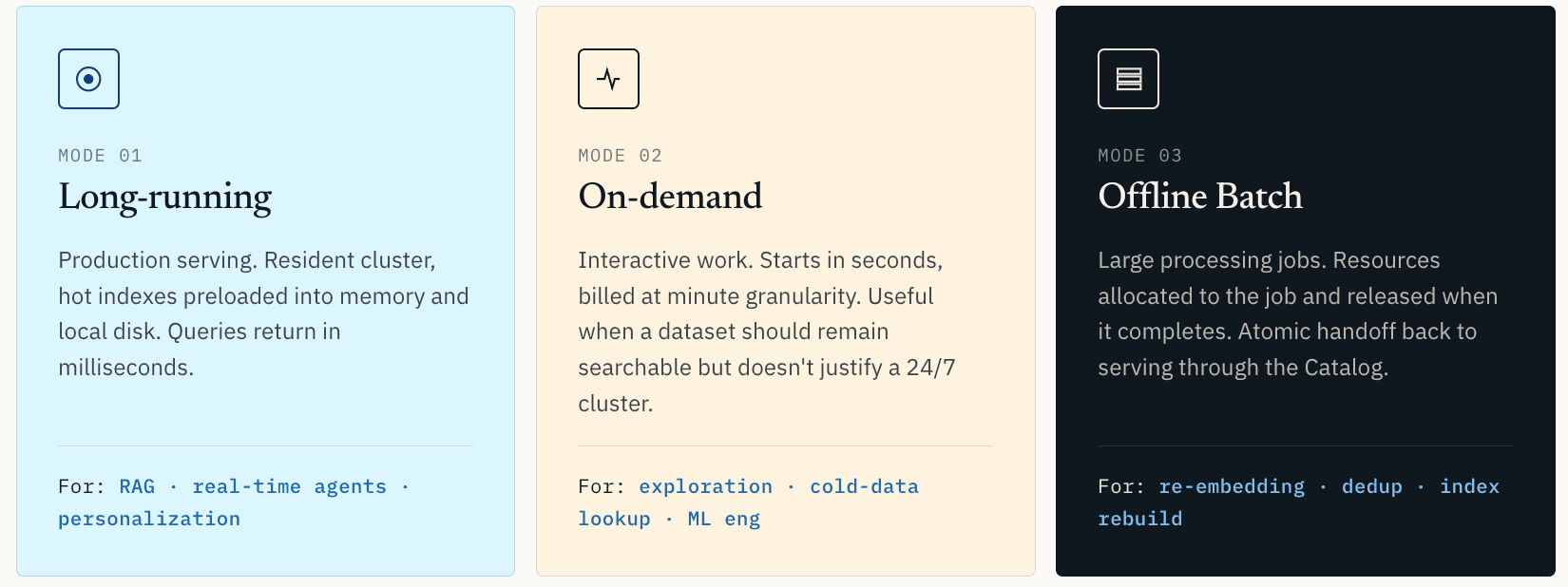
- Long-running compute предназначен для продакшен-обслуживания. Кластер остается постоянно запущенным. Горячие индексы и данные предварительно загружаются в память и на локальный диск. Запросы возвращаются за миллисекунды. Это правильный режим для продакшен-RAG, рекомендаций в реальном времени, персонализации, онлайн-агентов и любой нагрузки, где задержка является частью пользовательского опыта.
- On-demand compute предназначен для интерактивной работы. Он запускается за секунды и тарифицируется с поминутной гранулярностью. Это полезно для исследования сходства, проверки аномалий, извлечения холодных данных или рабочих процессов ML-инжиниринга, где набор данных должен оставаться доступным для поиска, но не оправдывает кластер 24/7.
- Offline Batch compute предназначен для крупных задач обработки: векторной кластеризации, дедупликации обучающих данных, полного повторного эмбеддинга, перестроения индексов и проверок качества данных. Ресурсы выделяются задаче и освобождаются после ее завершения.
Передача обратно в serving происходит через Catalog как новый снимок. Serving продолжает читать старый снимок, пока новые данные и индексы не будут готовы. Затем новая версия становится видимой атомарно. Этот атомарный переключатель важен. Discovery полезен только в том случае, если улучшения могут возвращаться в production без раскрытия недостроенных индексов или несогласованных данных.
 architecture.png
architecture.png
Один пример клиента показывает, почему это различие важно. У клиента из сферы автономного вождения был один миллиард 768-мерных векторов, но ему требовалось всего около 20 минут времени онлайн-запросов в день. Выполнение рабочей нагрузки как долго работающего кластера стоило примерно $7,000 в месяц. Перенос в режим on-demand снизил ежемесячную стоимость примерно до $500. У того же клиента был рабочий процесс дедупликации, который ранее тратил около 70 часов, выполняя ANN-поиски один за другим. Переработка его в офлайн-пакетное задание сократила время вычислений примерно до 10 часов на том же классе ресурсов.

Урок не в том, что один режим вычислений лучше другого. Урок в том, что рабочие нагрузки данных ИИ не имеют одной формы, и архитектура не должна заставлять их принимать одну.
Планирование ресурсов становится частью Vector Lakebase
Три режима вычислений работают только в том случае, если планирование ресурсов так же эластично, как и сами вычисления.
Традиционные планировщики баз данных обычно предполагают фиксированный пул машин. Имея эти узлы, система решает, где размещать данные и как балансировать нагрузки. Такая модель хорошо работает, когда рабочая нагрузка стабильна. Она плохо подходит для рабочих нагрузок ИИ, которые возникают всплесками: сеанс on-demand поиска, короткая проверка холодных данных, ночное задание дедупликации, затем часы простоя.
В таком мире более правильный вопрос заключается не только в том, где должны выполняться данные. Вопрос в том, должны ли вычисления вообще выполняться.
Именно поэтому Vector Lakebase должен планировать данные и ресурсы вместе. На практике это означает поддержание Warm Pool подготовленных узлов, быстрое подключение данных при появлении работы, кратковременное сохранение ресурсов в прогретом состоянии после запроса и их освобождение, когда они больше не полезны.
Это также меняет экономику. Это не то же самое, что serverless-ценообразование за запрос, и не то же самое, что выделенная месячная емкость. Для многих рабочих нагрузок данных ИИ более естественной единицей является поминутное использование: платить за вычисления, пока цикл выполняется, а затем позволить им исчезнуть.
За этим стоит более крупный архитектурный сдвиг: от control plane, управляющего в основном статическим ядром, к ядру, которое понимает ресурсы, состояние кэша, снимки и стоимость. Это заслуживает отдельной публикации. Для этой статьи важный момент проще: без этой ресурсной модели Long-running, On-demand и Offline Batch были бы тремя отдельными вариантами развертывания, а не тремя частями одной эластичной системы данных.
External Collection: встречать данные там, где они уже находятся
Есть еще одна реальность, для которой нам пришлось проектировать.
У большинства предприятий уже есть большие объемы неструктурированных данных в lake-средах: таблицы Lance, таблицы Iceberg, наборы данных Parquet и директории объектного хранилища. Просить их перенести все в новую систему, прежде чем они смогут этим воспользоваться, нереалистично.
Именно поэтому мы создали External Collection в Zilliz Vector Lakebase. External Collection — это не только zero-copy mapping. Она строит независимый индексный слой поверх внешних данных. Исходные данные остаются там, где они находятся, и продолжают управляться существующей платформой клиента, тогда как Zilliz строит и управляет векторными индексами, инвертированными индексами и JSON-индексами, необходимыми для того, чтобы сделать эти данные доступными для поиска через тот же путь retrieval, что и нативные данные.
Наш внутренний принцип стал простым: One Data. One Index. Без дублированного хранения. Без dual-write pipelines. Без фрагментированных путей discovery.
Это означает, что цикл CS/CD может охватывать больше, чем данные, уже импортированные в векторную базу данных. Он может включать неструктурированные активы данных, которые у предприятий уже есть в их озерах.
Что определяет первое поколение Vector Lakebase
Эти идеи — не просто архитектура на бумаге. Мы уже поставляем их в Zilliz Vector Lakebase, и процесс его создания сделал наше понимание этой категории гораздо более конкретным.
Vector Lakebase первого поколения должен правильно сочетать несколько вещей одновременно.

- Во-первых, разделение хранения и вычислений с многоуровневым кэшированием. Данные находятся в объектном хранилище, а вычисления могут масштабироваться независимо, в том числе до нуля. Но одного разделения недостаточно. Онлайн-поиск по векторам все равно требует памяти, локального диска, прогретых узлов и выполнения с учетом кэша, чтобы горячие запросы оставались быстрыми на уровне миллисекунд.
- Во-вторых, единое управление мультимодальными неструктурированными данными. Система должна управлять не только векторами, но и исходными документами, изображениями, аудио, видео, эмбеддингами, скалярными метаданными, разрешениями и индексами. Система, которая хранит только векторы, — это сервис индексации, а не фундамент данных.
- В-третьих, нативные возможности векторной базы данных. Миллисекундный ANN-поиск, управление жизненным циклом индексов, гибридный поиск, скалярная фильтрация, полнотекстовый поиск, фильтрация JSON и несколько метрик сходства должны быть встроены. Подключение Lakehouse к внешней векторной базе данных не устраняет фрагментацию. Оно просто создает еще один конвейер.
- В-четвертых, несколько режимов вычислений. Онлайн-обслуживание, взаимодействие по требованию и офлайн-пакетная обработка должны работать с одними и теми же логическими данными. Вычисления по требованию особенно важны, потому что они становятся мостом между производственным обслуживанием и крупномасштабной офлайн-обработкой.
- В-пятых, открытые форматы и отсутствие принудительной миграции. Уровень хранения должен быть читаем внешними движками, такими как Spark, Ray и Daft. Существующие таблицы Iceberg, наборы данных Lance и файлы Parquet должны иметь возможность подключаться к системе без ненужного копирования. Данные принадлежат пользователю, а не движку.
- В-шестых, ресурсы должны следовать за данными. Вычисления могут исчезать, когда они не нужны, в то время как метаданные остаются видимыми и доступными для запросов. Запрос может вернуть ресурсы за считанные секунды. Неактивные арендаторы не должны платить за выделенные вычислительные ресурсы, которыми они не пользуются. Это не просто автомасштабирование; это требует, чтобы движок принимал решения о ресурсах совместно с решениями о данных.
Это наши текущие убеждения, а не окончательный ответ. Мы будем продолжать пересматривать их по мере зрелости системы. Но одно давление, похоже, вряд ли изменится: неструктурированные данные будут продолжать расти, тогда как бюджеты на инфраструктуру не будут расти теми же темпами. Это означает, что AI-системы должны становиться более итеративными, более эффективными и более непрерывно адаптивными.
Векторные базы данных не исчезают
Итак, возвращаясь к исходному вопросу: означает ли это, что векторные базы данных уходят? Вовсе нет.
Наоборот, семантический поиск становится более важным в этой архитектуре. Но его роль меняется.
Векторные базы данных становятся обслуживающим движком внутри более крупной системы неструктурированных данных, подобно тому как транзакционные базы данных остались важными внутри более широкой эпохи Lakehouse. OLTP-системы не были заменены Lakehouse. Они стали одним слоем внутри более крупного архитектурного стека. Я считаю, что векторные базы данных сейчас проходят тот же переход.
Более широкий сдвиг, происходящий в основе AI-инфраструктуры, касается не просто поиска. Он касается построения непрерывных операционных циклов вокруг самих неструктурированных данных. Обслуживание генерирует обратную связь. Обнаружение улучшает качество данных. Эти улучшения возвращаются в продакшен. Каждый виток цикла делает систему лучше.
Всё остальное, включая форматы хранения, иерархии кэширования, системы индексирования, эластичные модели вычислений и планирование ресурсов, существует для того, чтобы сделать этот маховик экономически жизнеспособным в масштабе.
Мы всё ещё не знаем точно, чем Vector Lakebase станет в следующие пять лет. Когда мы начали Milvus почти десять лет назад, мы тоже не могли предсказать, куда приведут сами векторные базы данных.
Но сейчас одно кажется ясным. Неструктурированные данные продолжат расти. Модели продолжат меняться. Агенты будут генерировать больше трасс, обратной связи и состояния. Командам нужно будет быстрее улучшать свои данные, не позволяя стоимости инфраструктуры расти без ограничений.
Успешными станут те системы, которые сделают непрерывное обслуживание и непрерывное обнаружение похожими на части одной машины. Именно в этом направлении мы строим.
Zilliz Vector Lakebase доступен в публичной предварительной версии
Мы запустили публичную предварительную версию Zilliz Vector Lakebase — важную эволюцию Zilliz Cloud от управляемой векторной базы данных к единой семантической платформе данных, сочетающей низколатентное векторное обслуживание с открытостью, масштабируемостью и экономикой озера данных.
Ключевые возможности Zilliz Vector Lakebase:
- Многоуровневое обслуживание, оптимизированное под разные компромиссы между производительностью в реальном времени и стоимостью
- Поиск по запросу для крупномасштабных или исследовательских рабочих нагрузок без постоянно включённых вычислительных ресурсов
- Поиск во внешнем озере данных — индексируйте и ищите напрямую по вашим существующим данным в озере
- Полноспектральный поиск по векторам, тексту, JSON и геопространственным данным с гибридным извлечением и переранжированием
- Унифицированное lake-native-хранилище на базе Vortex, открытого формата с более быстрым и дешёвым произвольным чтением, чем Lance или Parquet
Если ваш текущий стек разделяет обслуживание и обнаружение на отдельные системы, возможно, стоит присмотреться к Vector Lakebase. Попробуйте его в Zilliz Cloud — новые регистрации с рабочей электронной почтой получают $100 бесплатных кредитов — или свяжитесь с нами, чтобы обсудить ваш сценарий использования.
Примечание: показатели производительности и стоимости в этой статье получены из результатов open source VectorDB Benchmark, внутреннего тестирования и анонимизированных клиентских сценариев. Фактические результаты зависят от масштаба данных, распределения, параметров индекса, характера рабочей нагрузки и конфигурации ресурсов.

Читать далее

From Vector Database to Vector Lakebase
Zilliz offers a fully managed Vector Lakebase powered by Milvus, unifying real-time vector search, lake-scale discovery, and Al data operations.

How to Install and Run OpenClaw (Previously Clawdbot/Moltbot) on Mac
Turn your Mac into an AI gateway for WhatsApp, Telegram, Discord, iMessage, and more — in under 5 minutes.

What is the K-Nearest Neighbors (KNN) Algorithm in Machine Learning?
KNN is a supervised machine learning technique and algorithm for classification and regression. This post is the ultimate guide to KNN.