




Benchmark Massivo de Embeddings de Texto (MTEB)
Benchmark Massivo de Embeddings de Texto (MTEB)
Embeddings de texto são frequentemente testados em um pequeno número de conjuntos de dados de apenas uma tarefa, o que não mostra quão bem eles funcionam para outras tarefas. Não está claro se os melhores embeddings para Similaridade Textual Semântica (STS) funcionam igualmente bem para tarefas como agrupamento ou reranqueamento. Isso dificulta enxergar o progresso na área, pois novos modelos e embeddings são comumente avaliados e constantemente propostos sem testes consistentes.
Para lidar com essa questão, pesquisadores criaram o Benchmark Massivo de Embedding de Texto (MTEB). O MTEB abrange 8 tarefas de embedding em 58 conjuntos de dados em 112 idiomas. Os pesquisadores testaram 8 tarefas de embedding cobrindo 33 modelos no MTEB, tornando-o o benchmark mais completo para embeddings de texto até agora.
Eles descobriram que nenhum método único de embedding é o melhor para todas as tarefas. Isso sugere que um método universal de embedding de texto que funcione melhor para todas as tarefas de embedding ainda não foi desenvolvido, mesmo quando ampliado. Isso também destaca a importância de fazer sua diligência devida para escolher os modelos de embedding que melhor atendam aos seus requisitos.
O MTEB vem com código open-source, um ranking público e uma divertida Arena MTEB para votar em coisas como quais modelos recuperam o melhor documento, fazem melhor agrupamento etc., ambos no site da Hugging Face. Este benchmark ajudará a comunidade a testar novos métodos de forma consistente e acompanhar melhorias na tecnologia de embeddings de texto.
Contexto e Motivação
Embeddings de texto se tornaram uma parte fundamental de muitas tarefas de Processamento de Linguagem Natural (NLP). Esses embeddings transformam palavras, frases ou documentos em representações numéricas que capturam seu significado. Eles são usados em várias aplicações, como tradução automática, reconhecimento de entidades nomeadas, respostas a perguntas, análise de sentimento e sumarização.
Ao longo dos anos, pesquisadores criaram muitos conjuntos de dados e benchmarks para testar esses embeddings. Alguns dos mais conhecidos incluem SemEval, GLUE, SuperGLUE, Big-Bench, WordSim353 e SimLex-999. Eles normalmente se concentram em avaliar embeddings de palavras padrão e contextuais.
No entanto, ainda existem algumas lacunas em como os embeddings de texto são avaliados:
Poucos benchmarks abrangem tanto embeddings de palavras quanto de frases.
Muitas avaliações se concentram em tarefas específicas de NLP, não em quão bem os embeddings capturam o significado geral do texto.
Benchmarks existentes muitas vezes não consideram como os embeddings poderiam ser usados em aplicações do mundo real.
Há necessidade de um benchmark abrangente que possa avaliar uma ampla gama de tarefas de compreensão de texto. Esse benchmark deve ser útil tanto para pesquisadores de NLP quanto para pessoas trabalhando em aplicações práticas. O Benchmark Massivo de Embedding de Texto (MTEB) visa preencher essa lacuna.
Embeddings de Texto
Um embedding de texto é uma forma de representar texto como uma lista de números. Esses números podem representar uma única palavra, uma frase ou até mesmo um documento inteiro. A lista geralmente tem centenas de números.
Embeddings de texto são usados em muitas tarefas de NLP. Para palavras, são usados em coisas como verificação ortográfica e identificação de relações entre palavras. Para textos mais longos, são usados em tarefas como descobrir o sentimento de um texto ou gerar novo texto.
Há muitas maneiras diferentes de criar embeddings de texto. Alguns métodos populares incluem:
Métodos baseados em modelos de linguagem como ULMFit, GPT, BERT e PEGASUS
Métodos treinados em várias tarefas de NLP, como ELMo
Métodos baseados em palavras como word2vec e GloVe, que são frequentemente usados em pesquisas de visão computacional
Pesquisadores criaram muitos embeddings diferentes - há pelo menos 165 para comparar. Eles também criaram 15 ferramentas diferentes (como árvores de decisão e Random Forests) para ajudar a entender os pontos fortes e fracos desses embeddings.
No entanto, não há uma forma padrão de comparar todos esses diferentes embeddings. Esse é um problema que o Massive Text Embedding Benchmark (MTEB) tenta resolver.
Design e Implementação do Massive Text Embedding Benchmark
O MTEB foi projetado com vários objetivos importantes em mente:
Diversidade: O MTEB testa modelos de embedding em muitas tarefas diferentes. Ele inclui 8 tipos diferentes de tarefas, com até 15 conjuntos de dados para cada uma. Dos 58 conjuntos de dados no total, 10 funcionam com vários idiomas, cobrindo 112 idiomas no total. O benchmark testa textos curtos (nível de sentença) e longos (nível de parágrafo) para ver como os modelos se comportam em diferentes comprimentos de texto.
Simplicidade: O MTEB é fácil de usar. Qualquer modelo que possa receber uma lista de textos e produzir uma lista de representações numéricas (vetores) pode ser testado. Isso significa que muitos tipos diferentes de modelos podem ser comparados.
Extensibilidade: É fácil adicionar novos conjuntos de dados ao MTEB. Para tarefas existentes, você só precisa adicionar um arquivo que descreva a tarefa e indique onde os dados estão armazenados no Hugging Face. Adicionar novos tipos de tarefas requer um pouco mais de trabalho, mas o MTEB recebe contribuições da comunidade para ajudá-lo a crescer.
Reprodutibilidade: O MTEB facilita a repetição de experimentos. Ele acompanha diferentes versões de conjuntos de dados e software. Os resultados no artigo do MTEB estão disponíveis como arquivos JSON, para que qualquer pessoa possa verificá-los ou usá-los.
Esses recursos tornam o MTEB uma ferramenta abrangente e flexível para avaliar modelos de embedding de texto em tarefas que cobrem uma ampla variedade total de tarefas e idiomas.
Tarefas e Avaliação no Massive Text Embedding Benchmark
O Massive Text Embedding Benchmark inclui 8 tipos diferentes de tarefas para testar modelos de embedding. Aqui está um resumo simples de cada tarefa:
Mineração de Bitextos: Encontre sentenças correspondentes em dois idiomas diferentes. A principal medida é a pontuação F1.
Classificação: Use embeddings para classificar textos em categorias. A principal medida é a acurácia.
Agrupamento: Agrupe textos semelhantes. A principal medida é a v-measure.
Classificação de Pares: Decida se dois textos são semelhantes ou não. A principal medida é a precisão média.
Reclassificação: Ordene uma lista de textos com base em quão bem eles correspondem a uma consulta. A principal medida é MAP (Mean Average Precision).
Recuperação: Encontre documentos relevantes para uma determinada consulta. A principal medida é nDCG@10.
Similaridade Textual Semântica (STS): Meça o quanto duas frases são semelhantes. A principal medida é a correlação de Spearman.
Sumarização: Pontue resumos gerados por máquina em comparação com os escritos por humanos. A principal medida também é a correlação de Spearman.
Para cada tarefa, o MTEB usa o modelo de embedding para transformar textos em embeddings vetoriais. Em seguida, usa métodos como similaridade de cosseno ou regressão logística para executar a tarefa e calcular pontuações.
O MTEB inclui muitos conjuntos de dados para cada tarefa, abrangendo diferentes idiomas e comprimentos de texto. Isso ajuda a testar o quão bem os modelos de embedding funcionam em várias situações.
Ao usar essas diversas tarefas e conjuntos de dados, o Massive Text Embedding Benchmark oferece uma forma abrangente de avaliar e comparar diferentes modelos de embedding de texto.
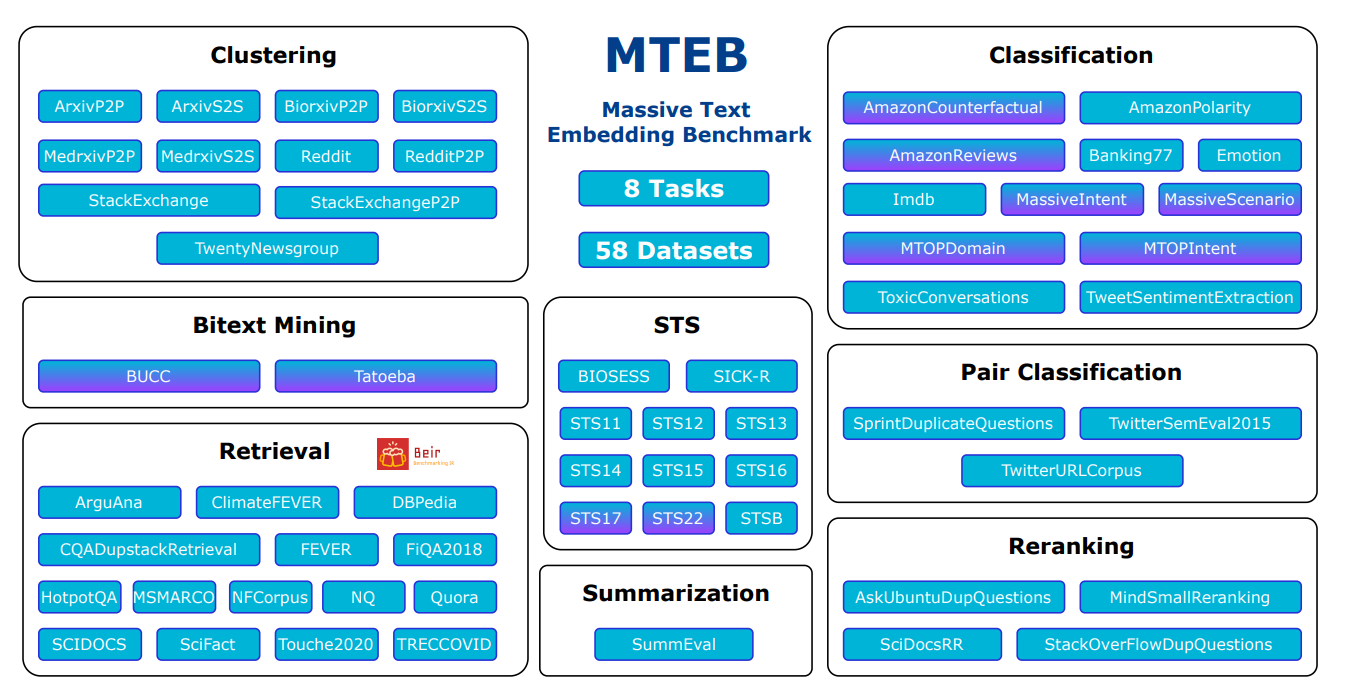 Visão geral das tarefas e conjuntos de dados no MTEB
Visão geral das tarefas e conjuntos de dados no MTEB
Fonte: MTEB: Massive Text Embedding Benchmark
Conjuntos de dados no Massive Text Embedding Benchmark
O Massive Text Embedding Benchmark usa muitos conjuntos de dados diferentes para testar métodos e modelos específicos de embedding de texto. Esses conjuntos de dados são agrupados em três tipos principais com base no comprimento dos textos comparados:
Sentence to Sentence (S2S): Isso ocorre quando uma frase é comparada a outra. Por exemplo, em tarefas de Similaridade Textual Semântica, o objetivo é descobrir o quão semelhantes duas frases são.
Paragraph to Paragraph (P2P): Isso envolve comparar trechos de texto mais longos. O MTEB não define um limite para o quão longos eles podem ser, deixando a cargo dos modelos lidar com textos mais longos, se necessário. Algumas tarefas, como clustering, são realizadas tanto como S2S (comparando apenas títulos) quanto como P2P (comparando títulos e conteúdo).
Sentence to Paragraph (S2P): Isso é usado em algumas tarefas de recuperação, nas quais uma consulta curta (frase) é comparada a documentos mais longos (parágrafos).
O MTEB inclui 56 conjuntos de dados diferentes. Alguns desses conjuntos de dados são semelhantes entre si:
Alguns usam os mesmos dados de texto subjacentes (como ClimateFEVER e FEVER).
Conjuntos de dados para tarefas semelhantes (como diferentes versões de CQADupstack ou STS) tendem a ser parecidos.
As versões S2S e P2P do mesmo conjunto de dados costumam ser semelhantes.
Conjuntos de dados sobre tópicos semelhantes (como artigos científicos) tendem a ser parecidos, mesmo que sejam para tarefas diferentes.
Ao usar uma variedade tão ampla de conjuntos de dados, o MTEB pode testar o quão bem os modelos de embedding funcionam com diferentes tipos de texto e diferentes tarefas. Isso ajuda a fornecer uma visão mais completa dos pontos fortes e fracos de cada modelo.
Modelos no benchmarking inicial do Massive Text Embedding Benchmark
Para a primeira rodada de testes com o MTEB, os pesquisadores analisaram modelos que afirmam ser os melhores e aqueles que são populares no Hugging Face Hub. Isso significa que eles testaram muitos modelos transformer. Eles agruparam os modelos em três tipos para ajudar as pessoas a escolher o melhor para suas necessidades:
Modelos mais rápidos: Modelos como Glove são muito rápidos, mas não entendem bem o contexto. Isso significa que eles não obtêm pontuações tão altas no MTEB como um todo.
Modelos equilibrados: Modelos como all-mpnet-base-v2 ou all-MiniLM-L6-v2 são um pouco mais lentos do que os mais rápidos, mas têm desempenho muito melhor. Eles oferecem uma boa combinação de velocidade e qualidade.
Modelos de melhor desempenho: Modelos grandes com bilhões de parâmetros, como ST5-XXL, GTR-XXL ou SGPT-5.8B-msmarco, têm o melhor desempenho no MTEB. Mas eles podem ser mais lentos e precisar de mais armazenamento. Por exemplo, o SGPT-5.8B-msmarco cria embeddings com 4096 números, o que ocupa mais espaço.
É importante observar que o desempenho de um modelo pode mudar muito dependendo da tarefa e do conjunto de dados específicos. Os pesquisadores sugerem verificar o ranking do MTEB para ver qual modelo pode funcionar melhor para uma única tarefa e suas necessidades específicas.
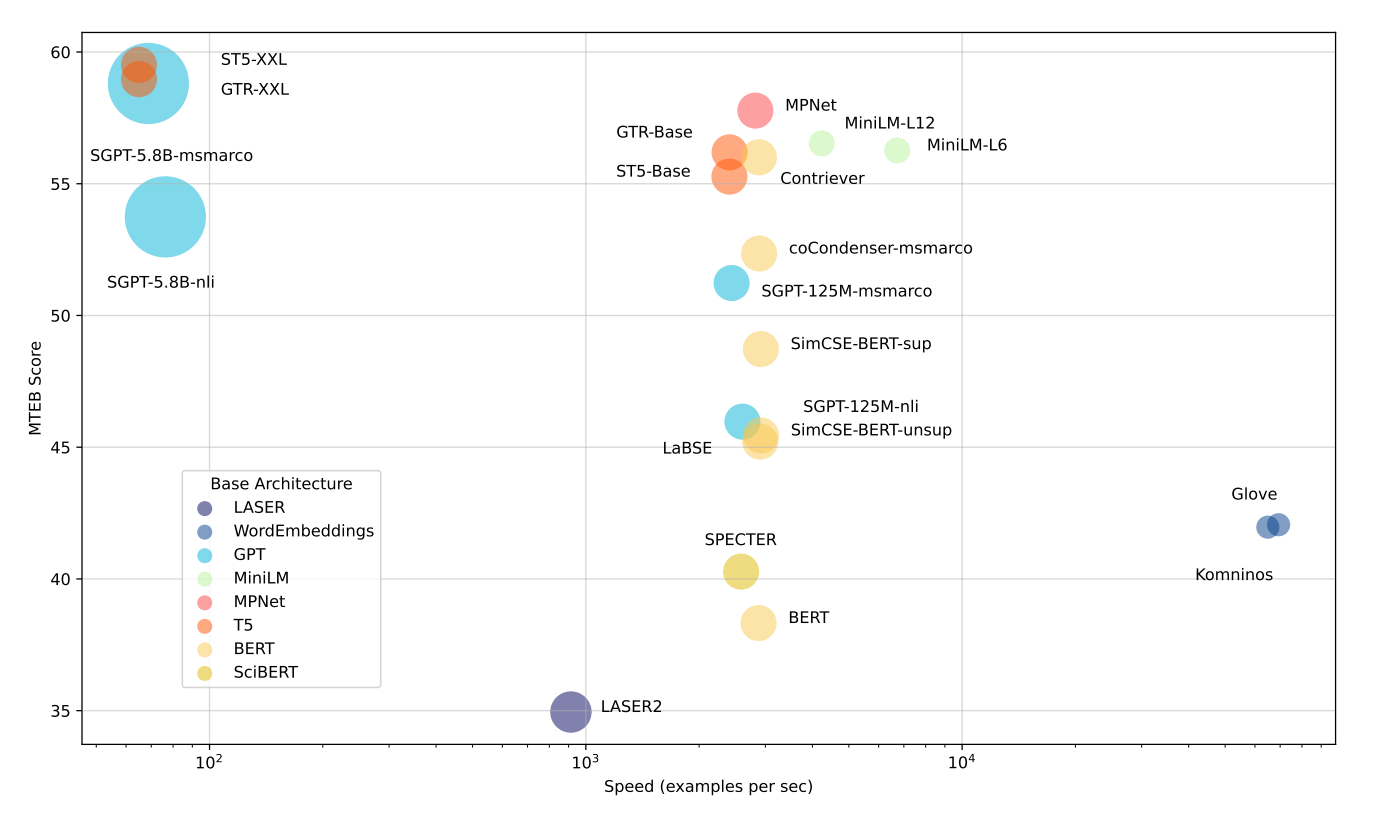 Resultados dos benchmarks do teste inicial
Resultados dos benchmarks do teste inicial
Fonte: MTEB: Massive Text Embedding Benchmark
Essa abordagem de teste oferece uma visão clara das compensações entre velocidade e desempenho em diferentes modelos de embeddings, ajudando os usuários a tomar decisões informadas com base em seus requisitos específicos. Se você quiser experimentar por conta própria, há um ótimo blog no Huggigng Face que orienta você no benchmarking de qualquer modelo que produza embeddings vetoriais.
Quando usar o Massive Text Embedding Benchmark
MTEB é uma ferramenta para testar o quão bem os modelos de embeddings de texto funcionam em muitas tarefas diferentes. É útil em várias situações:
Testando Seu Modelo: Se você criou um novo modelo de embeddings, pode usar o MTEB para ver como ele se compara a outros modelos. Você pode adicionar seus resultados ao ranking público, o que ajuda a ver como seu modelo se posiciona em relação aos outros.
Escolhendo o Modelo Certo: Modelos diferentes funcionam melhor para tarefas diferentes. O ranking do MTEB mostra como os modelos se desempenham em várias tarefas, ajudando você a escolher o melhor modelo para suas necessidades específicas.
Ajudando a Melhorar o MTEB: O MTEB é open source e, portanto, aberto para qualquer pessoa contribuir. Se você criou uma nova tarefa, conjunto de dados, forma de medir desempenho ou modelo, pode adicioná-lo ao MTEB. Isso ajuda a tornar o benchmark ainda melhor.
Pesquisa: Se você está estudando embeddings de texto, o MTEB oferece uma forma abrangente de testar modelos. Ele pode mostrar o que os melhores modelos atuais conseguem fazer e onde há espaço para melhoria.
Ao fornecer uma forma padrão de testar modelos em muitas tarefas, o MTEB ajuda pesquisadores e desenvolvedores a entender e melhorar a tecnologia de embeddings de texto. É uma ferramenta valiosa para qualquer pessoa que trabalhe com ou estude embeddings de texto.
Como usar o ranking do Massive Text Embedding Benchmark
Antes de tudo, não se deixe enganar pelas pontuações do MTEB!
O MTEB é uma ferramenta útil, mas é importante entender suas limitações. Embora mostre pontuações, ele não informa se as diferenças entre elas são significativas. Muitos modelos de ponta têm pontuações médias muito próximas, que vêm de muitas tarefas diferentes, mas não há informações sobre o quanto essas pontuações variam. O modelo no topo pode parecer melhor, mas a diferença pode não ser importante. Os usuários podem obter os resultados brutos para verificar isso por conta própria. Alguns pesquisadores descobriram que vários modelos de ponta em certos benchmarks de linguagem são, na verdade, igualmente bons, estatisticamente falando. Em vez de apenas olhar para as pontuações médias, é melhor focar em como os modelos se desempenham em tarefas semelhantes ao caso de uso pretendido. Isso pode fornecer mais insights sobre como um modelo funcionará para uma aplicação específica do que a pontuação geral. Não é necessário estudar os conjuntos de dados em detalhes, mas saber que tipo de texto eles contêm é benéfico. Essa informação geralmente está disponível na descrição do conjunto de dados e em uma rápida olhada em alguns exemplos. O Massive Text Embedding Benchmark é uma ferramenta útil, mas não é perfeita. É importante pensar criticamente sobre os resultados e como eles se aplicam a necessidades específicas. Em vez de simplesmente escolher o modelo com a maior pontuação geral, é melhor analisar mais a fundo para encontrar o melhor modelo para a tarefa em questão.
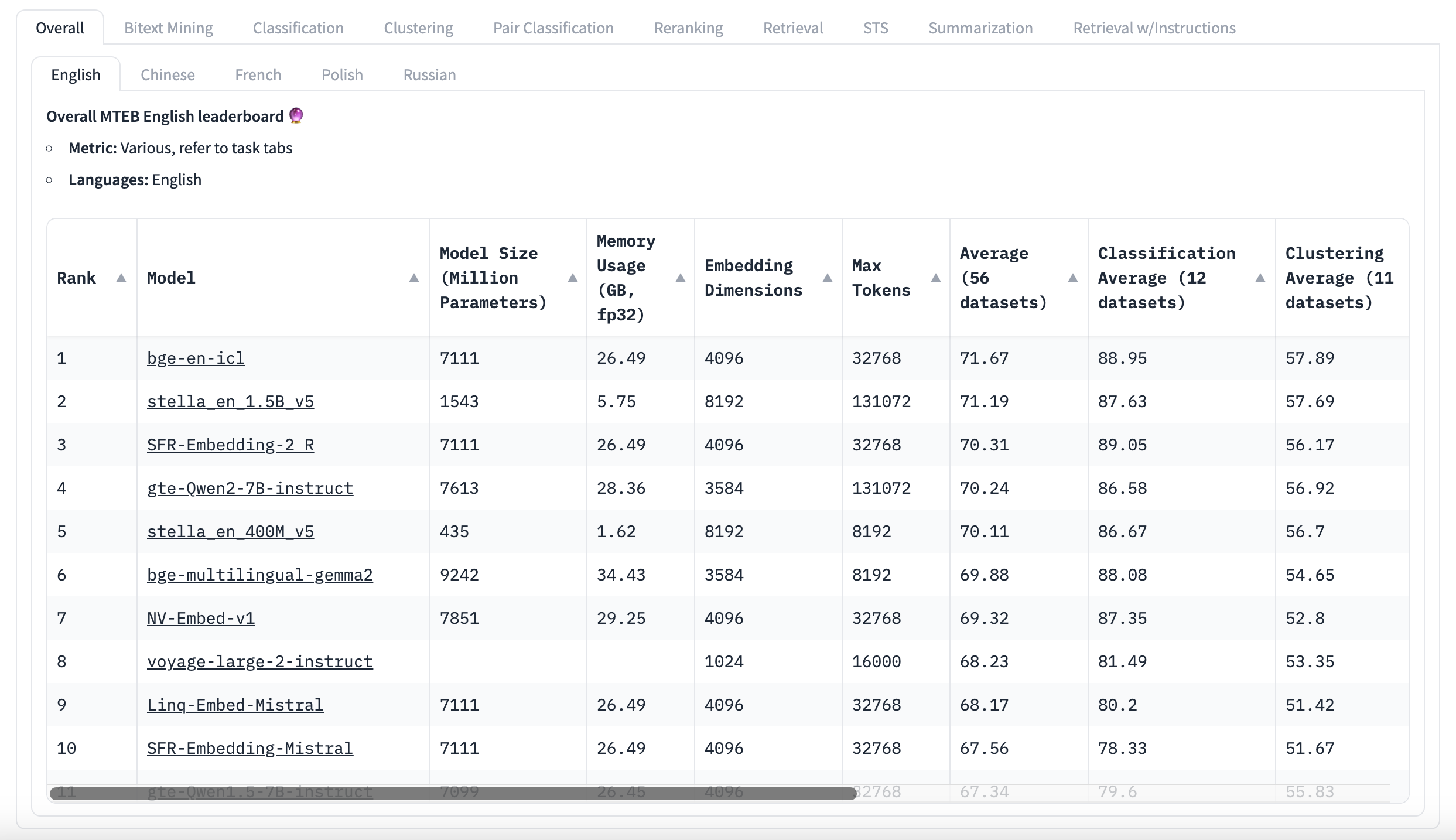 Ranking MTEB em Inglês
Ranking MTEB em Inglês
Lembre-se de Considerar as Necessidades da Sua Aplicação
Não existe um modelo único que sirva para todas as tarefas. É por isso que o Massive Text Embedding Benchmark existe — para ajudar você a escolher o modelo certo para suas necessidades específicas. Ao analisar o ranking do Massive Text Embedding Benchmark, é importante pensar no que sua aplicação exige. Aqui estão algumas coisas a considerar:
Idioma: O modelo oferece suporte ao idioma com o qual você está trabalhando?
Vocabulário especializado: Se você está trabalhando com textos financeiros ou jurídicos, precisará de um modelo que entenda termos específicos da área.
Tamanho do modelo: Pense em onde você executará o modelo. Ele precisará caber em um laptop?
Uso de memória: Quanta memória do computador você pode reservar para o modelo?
Comprimento máximo de entrada: Qual é o tamanho dos textos com os quais você trabalhará?
Depois de saber o que é importante para sua tarefa, você pode classificar vários modelos no leaderboard do MTEB com base nesses recursos. Isso facilita encontrar um modelo que não apenas tenha bom desempenho, mas também atenda aos seus requisitos práticos.
Ao considerar tanto o desempenho quanto as necessidades práticas, você pode escolher um modelo que funcione melhor para sua situação específica.
O recurso Zilliz AI Model
Agora que você escolheu seu modelo de embedding de texto a partir do Massive Text Embedding Benchmark, vamos colocá-lo em prática para criar embeddings de texto para armazenar e recuperar no Milvus de código aberto ou no Zilliz Cloud. No site da Zilliz, você pode encontrar a página AI Models, que lista alguns dos modelos multimodais e de embedding de texto mais populares.
 Página Zilliz AI Model
Página Zilliz AI Model
Depois de selecionar um modelo nessa página, você verá que há algumas instruções detalhadas sobre como criar os embeddings vetoriais usando os vários SDKs, PyMilvus e muito mais.
Conclusão
O Massive Text Embedding Benchmark (MTEB) é um avanço significativo na avaliação de modelos de embedding de texto. Ele aborda as limitações dos benchmarks anteriores ao cobrir uma ampla variedade de tarefas, idiomas e comprimentos de texto. O design do MTEB foca em diversidade, simplicidade, extensibilidade e reprodutibilidade, tornando-o uma ferramenta valiosa tanto para pesquisadores quanto para profissionais da área de Processamento de Linguagem Natural.
A abordagem de benchmark mais abrangente do MTEB, testando modelos em 8 tarefas diferentes e 58 conjuntos de dados, fornece uma visão mais completa das capacidades de um modelo do que benchmarks anteriores. Ela revela que nenhum método de embedding único se destaca em todas as tarefas, destacando a importância de escolher o modelo certo para aplicações específicas.
Ao usar o MTEB, é crucial olhar além das pontuações gerais e considerar as necessidades específicas da sua aplicação. Fatores como suporte a idiomas, vocabulário especializado, tamanho do modelo, uso de memória e comprimento máximo de entrada devem todos desempenhar um papel no processo de tomada de decisão.
Embora o MTEB seja uma ferramenta poderosa, é importante usá-lo de forma crítica. As diferenças nas pontuações entre os melhores modelos podem nem sempre ser estatisticamente significativas, e o desempenho pode variar muito dependendo da tarefa e do conjunto de dados específicos.
Como um projeto de código aberto, o MTEB recebe contribuições da comunidade, permitindo que ele cresça e se adapte às necessidades em evolução da área. Essa abordagem colaborativa garante que o MTEB continue sendo um recurso relevante e valioso para avaliar e melhorar a tecnologia de embedding de texto.
Ao fornecer uma forma padronizada de avaliar modelos de embedding de texto em uma ampla variedade de tarefas e idiomas, o MTEB está ajudando a impulsionar o progresso na área, levando, em última instância, a modelos de embedding de texto melhores e mais versáteis para diversas aplicações.
Referências
Muennighoff, Niklas and Tazi, Nouamane and Magne, Lo{\"\i}c and Reimers, Nils. "MTEB: Massive Text Embedding Benchmark" arXiv 2022
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff. "C-Pack: Packaged Resources To Advance General Chinese Embedding" arXiv 2023
Michael Günther, Jackmin Ong, Isabelle Mohr, Alaeddine Abdessalem, Tanguy Abel, Mohammad Kalim Akram, Susana Guzman, Georgios Mastrapas, Saba Sturua, Bo Wang, Maximilian Werk, Nan Wang, Han Xiao. "Jina Embeddings 2: 8192-Token General-Purpose Text Embeddings for Long Documents" arXiv 2023
Silvan Wehrli, Bert Arnrich, Christopher Irrgang. "Benchmark de Agrupamento de Embeddings de Texto em Alemão" arXiv 2024
Orion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Benjamin Van Durme, Dawn Lawrie, Luca Soldaini. "FollowIR: Avaliando e Ensinando Modelos de Recuperação de Informações a Seguir Instruções" arXiv 2024
Dawei Zhu, Liang Wang, Nan Yang, Yifan Song, Wenhao Wu, Furu Wei, Sujian Li. "LongEmbed: Estendendo Modelos de Embedding para Recuperação de Contexto Longo" arXiv 2024
Kenneth Enevoldsen, Márton Kardos, Niklas Muennighoff, Kristoffer Laigaard Nielbo. "Os Benchmarks Escandinavos de Embedding: Avaliação Abrangente de Embedding de Texto Multilíngue e Monolíngue" arXiv 2024
- Contexto e Motivação
- Embeddings de Texto
- Design e Implementação do Massive Text Embedding Benchmark
- Quando usar o Massive Text Embedding Benchmark
- Como usar o ranking do Massive Text Embedding Benchmark
- O recurso Zilliz AI Model
- Conclusão
- Referências
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis