




LLaVA: Avanço dos modelos de visão-linguagem através da afinação da instrução visual
Os actuais modelos de linguagem de grande dimensão (LLMs) como o ChatGPT, o LLAMA e o Claude Sonnet demonstraram que as instruções baseadas na linguagem humana podem ser uma ferramenta poderosa para melhorar a qualidade das respostas. Utilizando técnicas como a prompt engineering, podemos orientar os LLMs para gerar respostas que se aproximem mais dos nossos casos de utilização específicos.
Inicialmente, as LLM foram concebidas exclusivamente para entradas baseadas em texto. Quando lhes eram dadas instruções textuais, geravam uma resposta correspondente. Embora esta abordagem tenha sido muito bem sucedida, a expansão destas capacidades para entradas visuais é uma progressão natural. Os modelos de base visual aceitam tanto uma instrução de texto como uma imagem como entrada, permitindo tarefas como resumir o conteúdo de uma imagem, extrair informações ou traduzir texto numa imagem.
Neste artigo, vamos explorar o LLaVA (Large Language and Vision Assistant), um dos esforços pioneiros para implementar instruções baseadas em texto para modelos baseados em imagens. Antes de entrarmos em pormenores sobre a sua implementação, vamos dar um passo atrás para compreender a evolução dos modelos baseados na visão e a forma como estão a transformar o campo.
Desenvolvimento de modelos baseados em imagens
Nas suas fases iniciais de desenvolvimento, a maioria dos modelos baseados na visão baseavam-se em arquitecturas baseadas em rede neural convolucional (CNN) para executar tarefas comuns de visão. Na sua forma mais simples, um modelo baseado na visão pode ser construído com um par de camadas CNN para executar uma tarefa simples de classificação de imagens, como determinar se uma determinada imagem é de um cão ou de um gato.
No entanto, para classificar imagens mais complexas com mais classes, é necessário construir modelos mais profundos, compostos por centenas de camadas CNN. Quanto mais profundas forem as camadas do modelo, maior é o risco de se deparar com o problema do gradiente de fuga. O gradiente de desaparecimento refere-se ao fenómeno durante o treino do modelo em que o gradiente se torna tão pequeno que o modelo não consegue aprender nada e atualizar os seus pesos.
Para resolver esta questão, foram implementados algoritmos sofisticados como [ligações residuais] (https://zilliz.com/learn/deep-residual-learning-for-image-recognition) na arquitetura do modelo para evitar problemas de gradiente de fuga que ocorrem habitualmente em modelos de aprendizagem profunda. Este método revelou-se eficaz, levando à criação da ResNet, que subsequentemente alcançou um desempenho de ponta em muitos conjuntos de dados de referência de classificação de imagens.
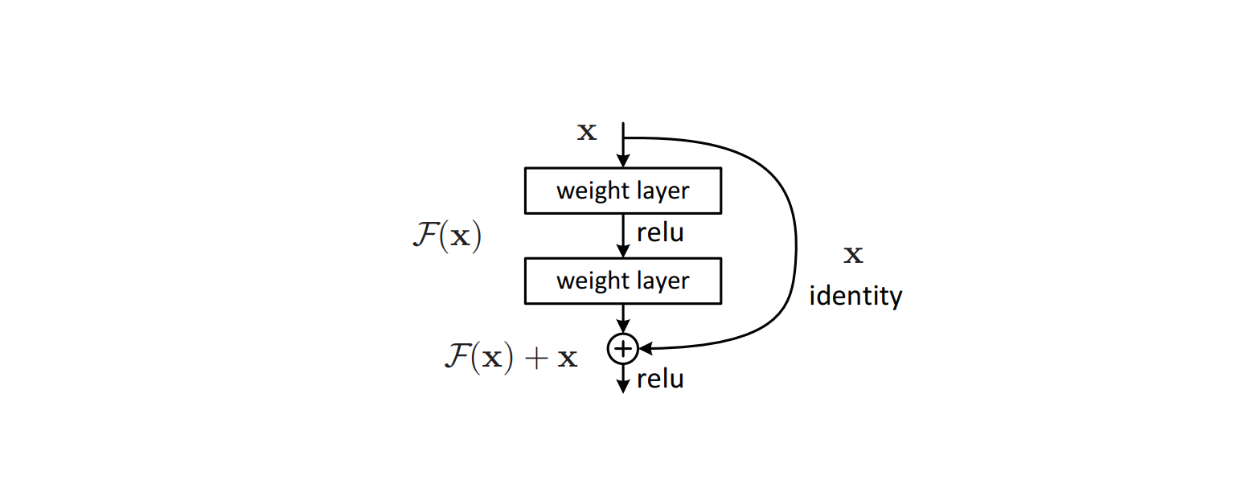
Figura: Bloco de construção de uma ligação residual no interior da arquitetura de um modelo. Fonte._
O sucesso da ResNet inspirou outras arquitecturas de modelos capazes de realizar tarefas de imagem mais complexas. Modelos visuais como o YOLO implementaram ligações residuais na sua arquitetura para realizar tarefas de deteção de objectos. Ao mesmo tempo, a U-Net utilizou uma combinação de arquitetura em forma de U e ligações residuais para realizar tarefas de segmentação de imagens.
Embora estes modelos visuais possam executar tarefas baseadas na visão, cada um deles só pode executar uma tarefa específica. Se um modelo tiver sido treinado para a classificação de imagens, só pode ser utilizado para esse fim. Além disso, se pedirmos ao modelo para classificar uma imagem significativamente diferente das que constam dos dados de treino, podemos observar alguma aleatoriedade nas previsões do modelo.
A introdução do famoso modelo Transformers em 2017 despoletou um rápido desenvolvimento dos modelos de aprendizagem profunda em geral. Os modelos que adoptam Transformers na sua arquitetura superaram significativamente os modelos mais tradicionais. Originalmente destinada apenas a modelos baseados em texto, a arquitetura Transformers revelou-se suficientemente versátil para ser utilizada também em modelos baseados em visão.
Os modelos de visão baseados em transformadores, como o Vision Transformers (ViT), demonstraram uma elevada capacidade de execução de tarefas de classificação de imagens. Consequentemente, o ViT é agora utilizado por muitos modelos populares de visão de texto, como o CLIP, como arquitetura de base.
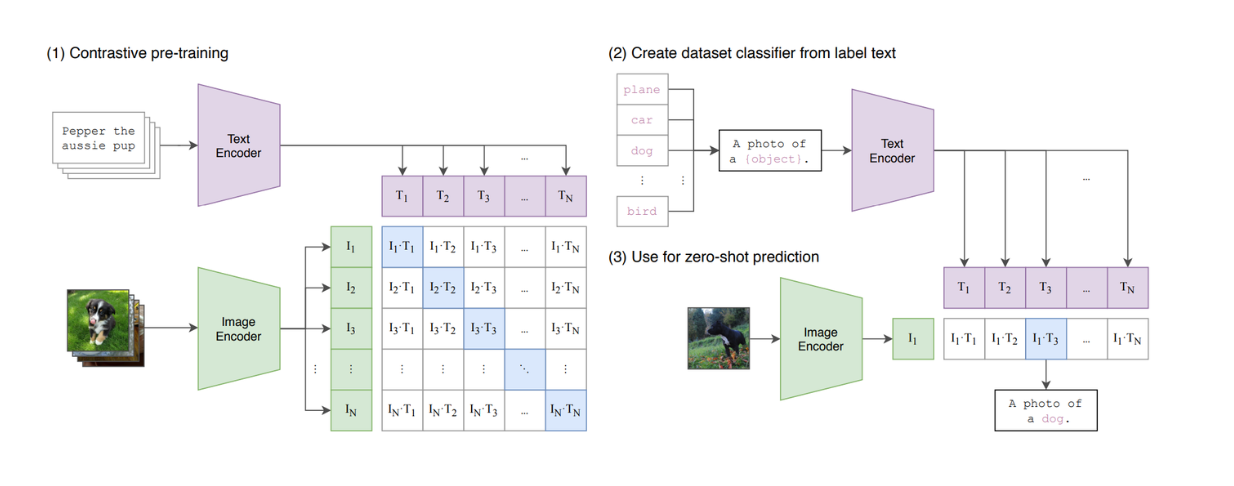
Figura: Um resumo do modelo CLIP. Fonte._
O CLIP é um modelo que combina o ViT e um modelo do tipo BERT na sua arquitetura. O ViT processa a entrada de imagens, enquanto o modelo do tipo BERT processa a entrada de texto. O CLIP foi treinado utilizando a aprendizagem contrastiva, segundo a qual, quando é dado um texto e uma imagem como par de entrada, o CLIP calcula a semelhança entre o texto e a imagem. No entanto, podemos ver que o CLIP ainda é limitado em termos da sua capacidade de imitar LLMs baseados em texto, uma vez que não é um modelo generativo.
O LLaVA é um dos primeiros LLM de base visual capaz de receber instruções e imagens baseadas em texto e gerar uma resposta adequada. Discutiremos os detalhes do LLaVA na próxima secção.
O que é LLaVa?
O LLaVA (Large Language and Vision Assistant) é um modelo multimodal que combina modelos de linguagem grandes baseados em texto (LLMs) com capacidades de processamento visual, permitindo-lhe lidar com entradas de texto e imagem. Foi concebido para executar tarefas como resumir conteúdos visuais, extrair informações de imagens e responder a perguntas sobre dados visuais.
O LLaVA baseia-se no sucesso dos LLMs, incorporando a compreensão visual e alinhando as instruções baseadas em texto com a análise de imagens. Esta integração permite que o modelo processe entradas emparelhadas - instruções de texto e imagens - dando respostas coerentes e contextualmente relevantes.
Arquitetura LLaVA
A arquitetura do LLaVA é relativamente simples. Utiliza um LLM pré-treinado para processar instruções textuais e o codificador visual do CLIP pré-treinado, um modelo ViT, para processar informações de imagem.
Entre vários LLMs pré-treinados publicamente disponíveis, os autores do LLaVA escolheram o Vicuna como a espinha dorsal para processar a informação textual e gerar a resposta final, dado um par de entrada texto-imagem.
Como a maioria dos LLMs baseados em texto se baseia na arquitetura Transformer, o processo de transformação do texto até à geração da resposta é bastante simples. Cada token no texto de entrada é transformado numa incorporação e, em seguida, passa por várias pilhas de camadas de atenção e densas antes de produzir a caraterística final de saída com uma dimensão de tamanho fixo.
Para processar a imagem de entrada, o LLaVA usa o modelo ViT pré-treinado dentro do CLIP para transformar a imagem de entrada numa representação de caraterísticas com uma dimensão de tamanho fixo. No entanto, a dimensão da caraterística de imagem do CLIP difere da caraterística de texto do Vicuna. Por isso, o LLaVA implementa uma camada densa simples para projetar a imagem para ter o mesmo tamanho que a imagem textual da Vicuna.
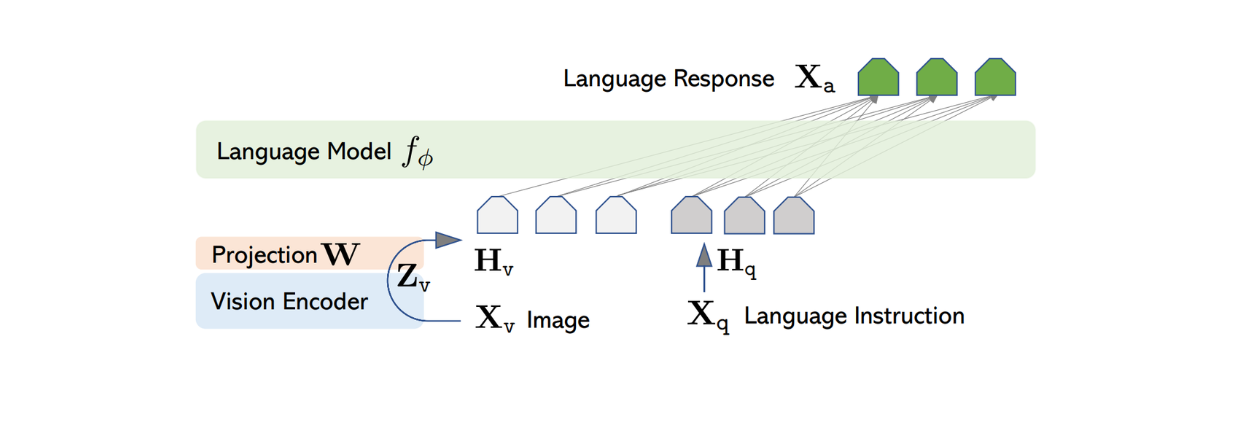
Figura: Arquitetura do LLaVA. Fonte.
Agora que as caraterísticas de imagem e de texto têm o mesmo tamanho, é necessária uma abordagem para combinar estas duas caraterísticas numa só. Há várias abordagens habitualmente utilizadas para o fazer, como a simples prefixação do elemento de imagem à frente do elemento de texto ([elemento de imagem] + [elemento de texto]), ou a utilização de algoritmos mais sofisticados, como o gated cross-attention e o Q-former. As caraterísticas textuais e de imagem combinadas são então introduzidas no Vicuna, permitindo-lhe gerar uma resposta adequada.
No entanto, ao implementar a abordagem acima mencionada, a qualidade da resposta gerada pelo Vicuna ou por qualquer outra LLM semelhante pode não ser óptima. Este facto é esperado, uma vez que as LLM são treinadas exclusivamente com base em dados textuais. Por conseguinte, a LLaVA precisa de ser afinada antes de poder gerar respostas coerentes com base num par de entradas imagem-texto. Este processo de afinação é designado por [visual instruction tuning] (https://arxiv.org/abs/1512.03385), que discutiremos nas secções seguintes.
Processo de geração de dados para afinação de instruções visuais
O Ajuste de Instruções Visuais é um processo de treino de modelos de IA multimodais para compreender e responder a instruções baseadas em texto emparelhadas com entradas visuais, tais como imagens ou vídeos. Esta técnica alinha a compreensão visual com as capacidades de processamento de linguagem natural, permitindo que o modelo execute tarefas como legendas de imagens, resposta a perguntas visuais, reconhecimento de objectos e extração de informações.
Um dos principais desafios da afinação de instruções visuais é a falta de dados multimodais de acompanhamento de instruções disponíveis publicamente. Embora existam vários conjuntos de dados que consistem em pares imagem-texto, como o CC e o LAION, não são exatamente o tipo de conjunto de dados que gostaríamos de utilizar para afinar os LLM de base visual para seguir as instruções do utilizador.
Figura: Exemplo de um conjunto de dados CC. Fonte.
Por outro lado, a criação manual de uma grande quantidade de dados multimodais de seguimento de instruções para afinar o LLaVA exigiria um esforço e tempo significativos. Por isso, podemos aproveitar o GPT-4 ou o ChatGPT para acelerar o processo de criação de dados multimodais de seguimento de instruções.
Como se viu no exemplo da imagem CC acima, os conjuntos de dados multimodais comuns consistem num par de texto imagem-legenda em cada registo de dados. Com o ChatGPT, dada uma imagem e a sua legenda, podemos gerar um conjunto de possíveis perguntas destinadas a instruir os LLMs a descrever o conteúdo da imagem. O formato dos dados multimodais de seguimento de instruções será então o seguinte Humano: Xq Xv
No entanto, sabemos que as iterações anteriores do ChatGPT só aceitam texto como entrada. Para usá-lo para selecionar uma lista de perguntas sobre uma imagem específica, precisamos fornecer informações ou metadados sobre a imagem. Os autores usaram duas abordagens diferentes para dar ao ChatGPT as informações necessárias sobre qualquer imagem de entrada: legendas e caixas delimitadoras. As legendas consistem normalmente em descrições detalhadas da imagem, enquanto as caixas delimitadoras fornecem ao ChatGPT informações úteis sobre a localização exacta dos objectos na imagem.

Figura: Exemplo de legenda e caixas delimitadoras para capturar informações visuais para o GPT-4 somente de texto. Fonte.
Os autores criaram três tipos de conjuntos de dados multimodais de seguimento de instruções:
Conversação: Consiste em uma conversa entre o LLM e o usuário. As respostas do utilizador são dadas como se ele estivesse a olhar para a imagem e depois a responder às perguntas do utilizador. As perguntas típicas incluem o conteúdo visual da imagem, a contagem de objectos na imagem, as posições relativas dos objectos na imagem, etc.
Descrições pormenorizadas: consiste numa lista de perguntas destinadas a gerar descrições exaustivas de uma imagem.
Raciocínio complexo: consiste em perguntas que ultrapassam os dois tipos anteriores. Em vez de se limitarem a descrever o conteúdo visual de uma imagem, estas perguntas têm como objetivo obrigar o MLT a explicar a lógica subjacente às suas respostas, exigindo um raciocínio passo a passo.

Figura: Exemplo de três tipos de conjunto de dados multimodais de seguimento de instruções. Fonte._
Abaixo está um exemplo de um pedido utilizado pelos autores para gerar um conjunto de dados do tipo conversação:
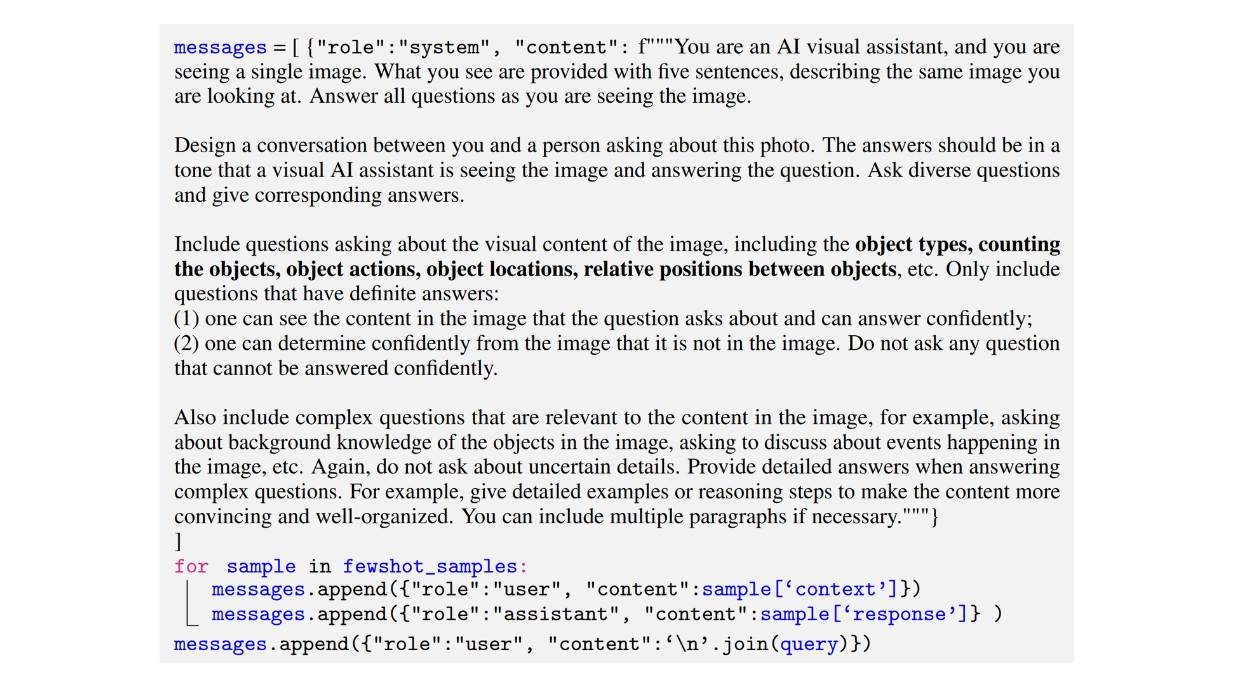
Figura: Exemplo de um prompt utilizado para gerar um conjunto de dados de seguimento de instruções multimodais do tipo conversação Fonte._
Obter o resultado desejado com o formato correto a partir dos dados de seguimento de instruções multimodais gerados pelo LLM é bastante complicado. Por isso, ao pedir ao ChatGPT para gerar os três tipos de conjuntos de dados multimodais de seguimento de instruções, os autores usaram amostras de poucos disparos para aproveitar o poder da aprendizagem em contexto.
Com as amostras de poucos disparos, os autores forneceram alguns exemplos criados manualmente de conversas entre o LLM e o utilizador, juntamente com o prompt. Estes exemplos de poucas imagens ajudam o ChatGPT a compreender melhor a estrutura do resultado esperado. Abaixo está um exemplo de uma amostra de poucas imagens implementada pelos autores no prompt para gerar um conjunto de dados de conversação.

Figura: Exemplo de um exemplo de poucas imagens a transmitir juntamente com o prompt para aprendizagem em contexto. Fonte._
Procedimento de treino do LLaVA
O total de dados multimodais de seguimento de instruções gerados com a abordagem acima mencionada foi de aproximadamente 158K. De seguida, um modelo LLaVA foi afinado com estes dados multimodais.
No conjunto de dados, para cada imagem Xv, há conversas de várias voltas entre o LLM e os utilizadores (X1q, X1a, - - - , XTq, XTa), em que T é o número total de voltas. Para cada turno t, a resposta Xta é tratada como a resposta do LLM, e portanto, a instrução no turno t seria:
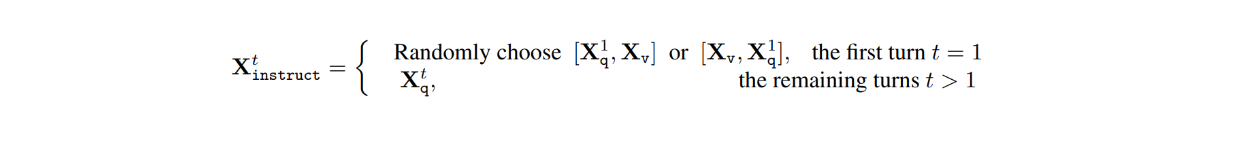
De seguida, durante o processo de afinação da instrução visual, foram conduzidas duas fases: pré-treino para alinhamento de caraterísticas e afinação de ponta a ponta.
Durante a fase de pré-treino para alinhamento de caraterísticas, o principal objetivo é treinar a camada de projeção que mapeia a saída do modelo ViT do codificador CLIP pré-treinado numa caraterística visual final que tem a mesma dimensão que a caraterística de texto. Nesta fase, o processo de treino foi efectuado utilizando o conjunto de dados CC filtrado, que contém 596 mil pares imagem-texto. Para cada imagem Xv, a pergunta Xq é amostrada aleatoriamente a partir de um conjunto de perguntas, e a Xc correspondente é utilizada como etiqueta de verdade. Portanto, as perguntas amostradas para o treinamento são aquelas que pedem ao LLM para descrever a imagem brevemente, como você pode ver na imagem abaixo:

Figura: Exemplo de pedidos para explicar brevemente o conteúdo de uma imagem Fonte._
Uma vez que só estamos a treinar a camada de projeção, os pesos de ViT e LLM estão congelados nesta fase.
Entretanto, durante a segunda fase, que é a afinação de ponta a ponta, o modelo LLaVA é afinado com os 158K dados multimodais de seguimento de instruções gerados. Nesta fase, apenas os pesos do ViT são congelados, enquanto os pesos da camada de projeção e do LLM são actualizados durante o processo de afinação.
Resultados do LLaVA
Para avaliar o desempenho do LLaVA, foi efectuada uma comparação com outros modelos de última geração, como o GPT-4, e modelos baseados na visualização, como o BLIP-2 e o OpenFlamingo. Para a avaliação dos resultados, os autores utilizaram o GPT-4, que é apenas texto, como juiz para classificar a qualidade das respostas com base na utilidade, relevância, exatidão e nível de detalhe.
Como primeira avaliação, foram selecionadas 30 imagens aleatórias do conjunto de dados COCO-Val-2014 e, utilizando o processo de geração de dados explicado na secção anterior, foram gerados três tipos de conjuntos de dados. Isto resultou num total de 90 pontos de dados: 30 para conversação, 30 para descrições pormenorizadas e 30 para raciocínios complexos. As respostas do LLaVA foram então comparadas com os resultados do modelo GPT-4 só de texto, que utiliza a descrição/capítulo textual como etiqueta e as caixas delimitadoras como entrada visual. Os resultados são os seguintes:
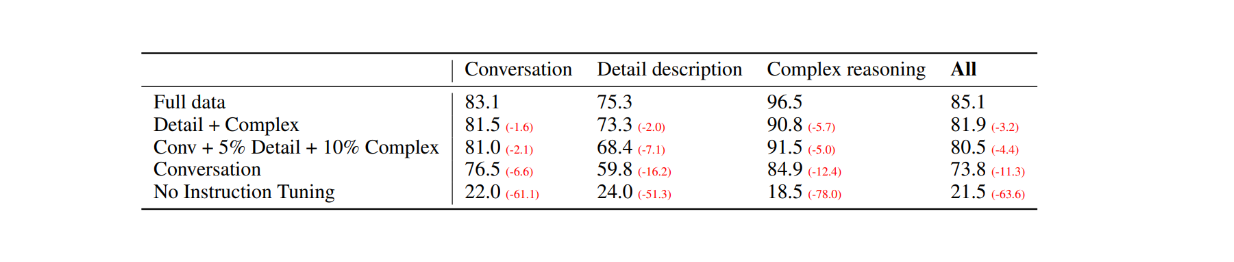
Figura: Comparação de desempenho entre LLaVA e GPT-4 só de texto em 30 imagens aleatórias. Fonte._
Com o ajuste das instruções visuais, a capacidade do modelo para seguir instruções aumentou pelo menos 50 pontos em cada tipo de conjunto de dados. Entretanto, a pontuação relativa do LLaVA não ficou muito longe em comparação com o modelo GPT-4 só de texto que utiliza legendas de imagens como entrada visual, como mostram os números entre parênteses em cada categoria.
O desempenho do LLaVA também foi comparado com modelos de base visual, como o BLIP-2 e o OpenFlamingo, começando por obter 24 imagens aleatórias com 60 perguntas no total. Como se pode ver na tabela abaixo, o desempenho do LLaVA é muito superior ao dos outros dois modelos de base visual. Isto demonstra o poder da afinação de instruções visuais, uma vez que o BLIP-2 e o OpenFlamingo não foram afinados explicitamente com um conjunto de dados de seguimento de instruções multimodais.

Figura: Comparação de desempenho entre LLaVA e BLIP-2 e OpenFlamingo. Fonte.
Vamos agora examinar um exemplo das respostas dos modelos em ação. Consideremos uma imagem de nuggets de frango formando um mapa-mundo e perguntamos: "Pode explicar este meme em pormenor?" Abaixo estão os exemplos de respostas do LLaVA, GPT-4 só de texto, BLIP-2 e OpenFlamingo.

Figura: Exemplos de respostas do LLaVA, GPT-4, BLIP-2 e OpenFlamingo. Fonte.
Como se pode ver, os modelos BLIP-2 e OpenFlamingo não seguiram a instrução, uma vez que não foram afinados com a afinação de instruções visuais. Entretanto, o LLaVA demonstrou a sua capacidade de raciocínio visual na compreensão do humor. Juntamente com o GPT-4, foi capaz de dar uma resposta concisa de acordo com a instrução.
Quando ajustado no conjunto de dados ScienceQA durante aproximadamente 12 épocas, o LLaVA também obteve resultados muito competitivos em comparação com o modelo MM-CoT, que é o atual modelo de ponta (SOTA) neste conjunto de dados. Como mostra a tabela abaixo, o LLaVA alcançou 90,92% de precisão geral em vários assuntos diferentes, em comparação com 91,68% do modelo MM-CoT. No entanto, quando a saída do LLaVA foi combinada com o GPT-4, o desempenho atingiu um novo SOTA no conjunto de dados ScienceQA com 92,53% de exatidão.
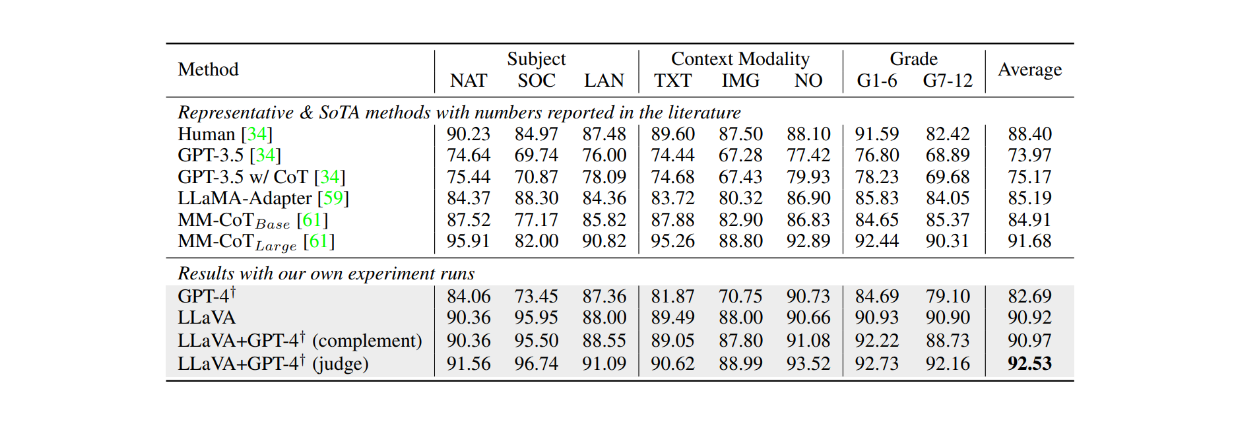
Figura: Precisão dos LLMs no conjunto de dados ScienceQA. Fonte.
Conclusão
O LLaVA representa um avanço inicial no desenvolvimento de Modelos de Linguagem de Grande Porte (LLMs) de base visual, capazes de seguir instruções textuais. O modelo combina um Vision Transformer (ViT) pré-treinado do CLIP para o processamento de imagens com o Vicuna como espinha dorsal do modelo de linguagem, utilizando uma camada de projeção para alinhar as dimensões das caraterísticas entre os dois componentes. O modelo é então afinado em 158K amostras de dados multimodais de seguimento de instruções.
Graças a esta abordagem de afinação de instruções visuais, o LLaVA pode descrever e realizar raciocínios complexos numa determinada imagem, de acordo com as instruções do prompt. Os resultados da avaliação demonstram a eficácia da afinação de instruções visuais, uma vez que o desempenho da LLaVA supera consistentemente o de dois outros modelos de base visual: BLIP-2 e OpenFlamingo.
Leitura adicional
[Modelo ALIGN explicado] (https://zilliz.com/learn/align-explained-scaling-up-visual-and-vision-language-representation-learning-with-noisy-text-supervision)
ColPali: Melhor Recuperação de Documentos com VLMs e ColBERT Embeddings
Mamba: um potencial substituto do transformador ](https://zilliz.com/learn/mamba-architecture-potential-transformer-replacement)
ColBERT: Um modelo de classificação e incorporação de nível de token ](https://zilliz.com/learn/explore-colbert-token-level-embedding-and-ranking-model-for-similarity-search)
XLNet: PNL melhorada com pré-treino autorregressivo generalizado](https://zilliz.com/learn/xlnet-explained-generalized-autoregressive-pretraining-for-enhanced-language-understanding)
Continue lendo

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.