




GenAI 모델에서 논리적 오류를 감지하고 수정하는 방법
소개 ## 소개
대규모 언어 모델(LLM)은 특히 대화형 AI, 텍스트 생성 등 AI 분야를 혁신적으로 변화시켰습니다. LLM은 수십억 개의 매개변수가 포함된 방대한 양의 데이터를 학습하여 인간과 같은 텍스트를 생성합니다. 많은 기업들이 고객 문의 처리, 리뷰 접수, 불만 사항 해결 등을 위해 LLM 기반 챗봇을 개발하고자 합니다. LLM의 사용과 채택이 증가함에 따라 우리는 중요한 문제를 해결해야 합니다: 바로 LLM 출력의 논리적 오류입니다. 이 문제를 해결하고 AI 시스템을 더욱 책임감 있고 신뢰할 수 있게 만드는 것이 중요합니다.
응용 머신러닝, AI 안전 및 평가 분야에서 풍부한 경험을 쌓은 AI 엔지니어인 존 베니언은 최근 [질리즈가 주최한 [비정형 데이터 밋업]에서 논리적 오류를 해결하기 위한 흥미로운 접근 방식에 대해 논의했습니다. 존은 출력의 오류를 해결하기 위한 새로운 접근법을 구현하는 LangChain의 저명한 공헌자입니다.
이 강연에서 Jon은 논리적 오류로 이어질 수 있는 모델 추론의 일반적인 함정에 대해 설명합니다. 또한 이러한 오류를 식별하고 수정하는 전략에 대해 설명하며, 모델 결과를 논리적으로 건전하고 인간과 유사한 추론에 맞추는 것이 중요하다는 점을 강조합니다.
논리적 오류란 무엇인가요?
 논리적 오류란 무엇인가요?.png
논리적 오류란 무엇인가요?.png
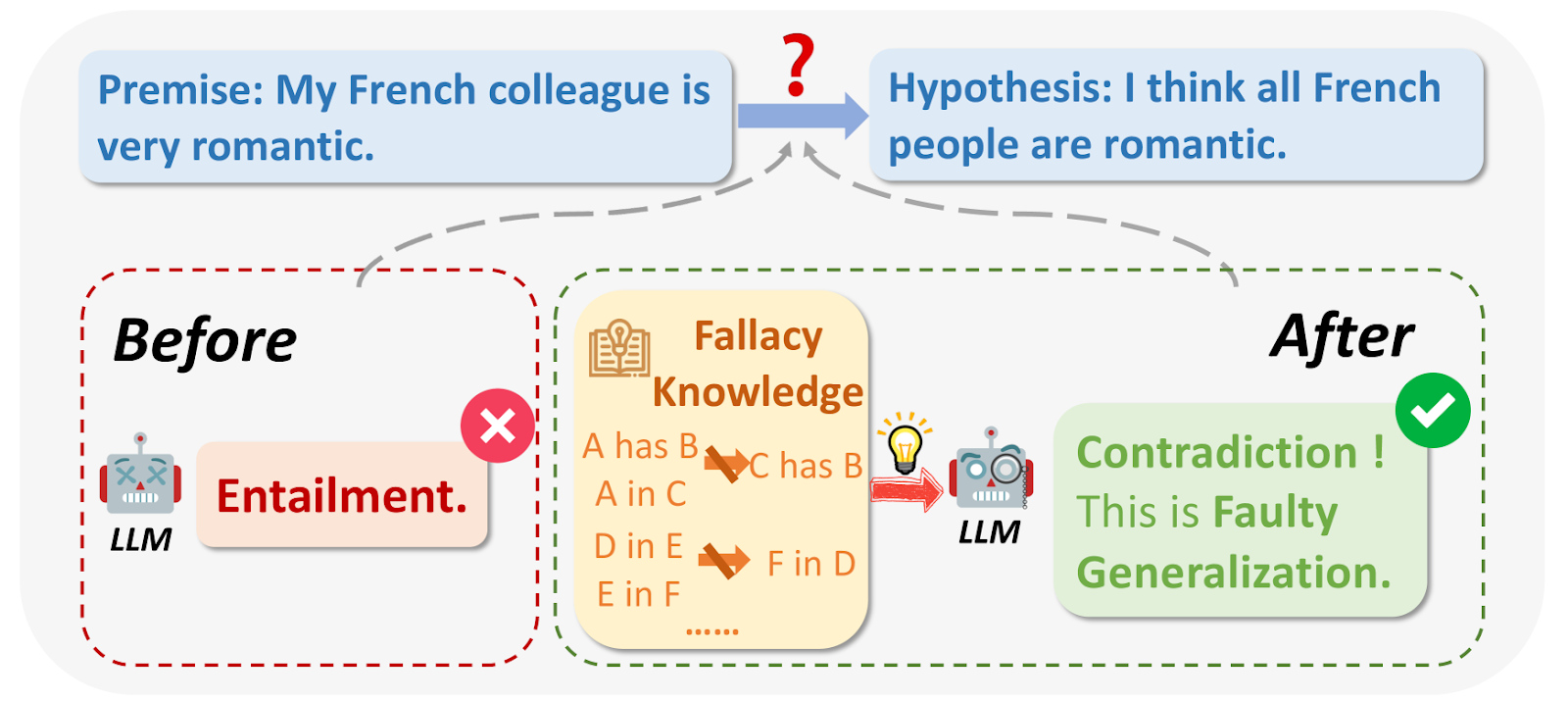
그림 1: 논리적 오류란 무엇인가요?
이미지 출처: https://arxiv.org/html/2404.04293v1/x1.png
LLM을 쿼리하는 동안 논리적으로 결함이 있거나 질문과 무관한 결과가 출력되는 경우가 있습니다. 논리적 오류에는 애드 호미넴, 순환 추론, 권위에의 호소 등이 포함됩니다. 예를 들어, 작은 표본 규모를 바탕으로 광범위한 일반화를 하는 경우가 많습니다: "프랑스에서 온 내 친구가 무례했으니 모든 프랑스인은 무례할 것이다."라는 식입니다.
어떤 경우에는 대중적이라는 이유로 어떤 것이 사실 또는 옳다고 가정할 수도 있습니다.
예시_: "모두가 이 새로운 앱을 사용하고 있으니 최고일 거야." 간혹 LLM이 이전의 전환 세부 정보를 기억하기 어려워 정확한 답변을 제공하지 못하는 경우도 있습니다.
논리적 오류는 왜 발생하나요?
논리적 오류가 발생하는 이유는 여러 가지가 있습니다. 우리 모두 알다시피, 언어 능력은 인간의 뇌가 이해하는 것과 같은 방식으로 모든 상황을 처리하도록 완벽하게 훈련된 것이 아닙니다.
불완전한 학습 데이터
저희가 제공하는 학습 데이터는 인터넷의 다양한 출처에서 가져온 것으로 완벽하지 않습니다. 여기에는 인간의 편견, 불일치, 심지어 엣지 케이스의 잘못된 정보까지 많이 포함되어 있습니다. 학습 과정에서 LLM은 결함이 있고 일관성이 없는 추론에 노출되며 이를 학습하게 됩니다. 학습 데이터에 결함이 있는 인수가 있는 경우 이러한 패턴을 포착하여 응답에서 이를 모방합니다.
작은 컨텍스트 창
강연에서 Jon은 "컨텍스트 창이 작으면 응답에 문제가 발생할 수 있습니다. 많은 팀이 메모리 요구 사항과 성능을 위해 컨텍스트 창을 최적화하는 데 어려움을 겪고 있습니다."라고 말합니다.
컨텍스트 윈도우는 LLM이 한 번에 고려할 수 있는 정보의 양을 의미하며, 이는 고정되어 있습니다. 컨텍스트 윈도우가 작으면 모델이 중요한 세부 정보를 놓칠 수 있고 일관된 답을 도출할 수 없습니다. 이로 인해 성급한 일반화나 잘못된 이분법과 같은 오류가 발생할 수 있습니다.
확률적 특성
LLM은 시퀀스에서 어떤 단어가 나올 확률이 높은지에 따라 텍스트를 생성합니다. 인간처럼 단어의 진정한 의미를 이해할 수는 없습니다. 문맥이 주어지면 국소적 일관성을 달성하도록 모델을 훈련시킵니다. 이 과정에서 더 넓은 맥락을 놓칠 수 있기 때문에 논리적 오류가 발생할 수 있습니다.
논리적 오류는 어떻게 해결하나요?
사용자가 신뢰할 수 있도록 논리에 결함이 있는 응답을 생성하는 LLM을 감지하고 방지하는 것이 중요합니다. Jon이 사람의 피드백, 강화 학습, 프롬프트 엔지니어링 등 이 문제를 해결하는 데 사용되는 일반적인 관행에 대해 간략하게 설명합니다.
이 강연에서 Jon은 논리적 오류를 감지하고 수정하는 흥미로운 접근 방식인 "RLAIF"를 소개합니다. 이 아이디어는 AI를 사용하여 스스로 문제를 해결하는 것입니다.
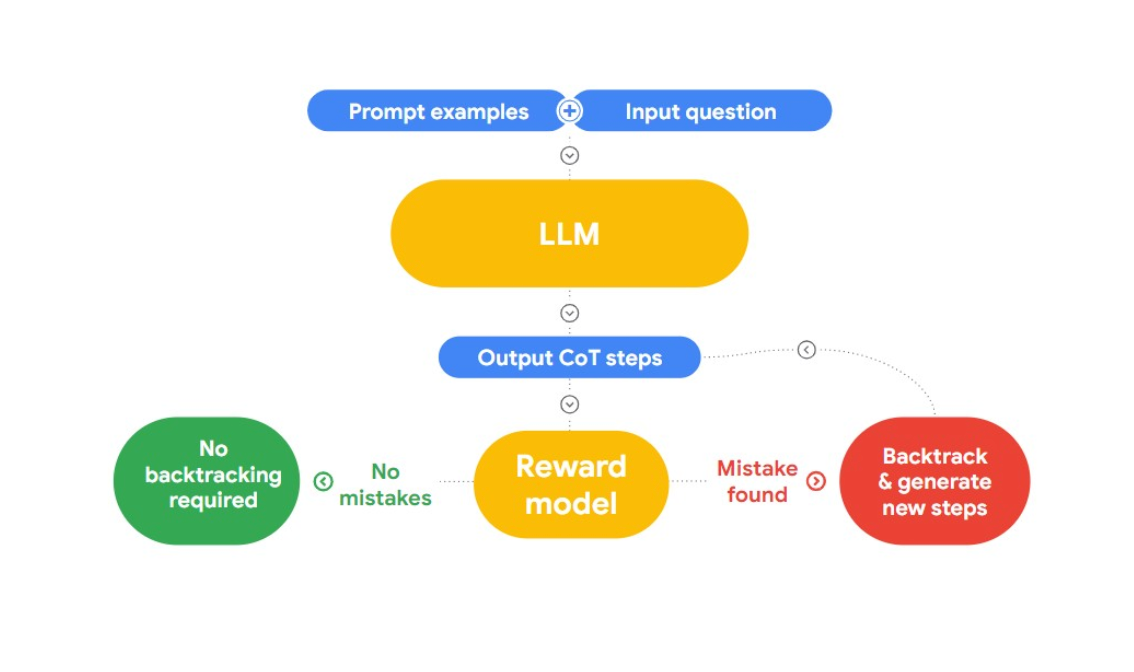
그림 2: RLAIF는 어떻게 작동하나요?
그는 "논리 정책의 분류를 위한 언어 모델을 사용한 사례 기반 추론"이라는 연구 논문을 참고하고 있는데, 이 논문은 우리 문제에 유용합니다. 이 논문에서는 논리적 오류를 분류하기 위해 사례 기반 추론(CBR)을 소개합니다. 이는 세 단계로 작동합니다:
**검색: 인간이 논리적 오류와 정체성을 가진 텍스트 데이터 모음(사례 기반)을 CBR에 제공합니다. 새로운 텍스트가 제공되면 CBR은 사례 기반에서 검색하여 유사한 사례를 찾습니다.
각색: 검색된 사례는 목표, 설명, 반론과 같은 요소를 고려하여 새로운 주장의 특정 맥락에 맞게 조정됩니다.
분류: 사용 가능한 정보를 바탕으로 CBR은 논리적 오류를 식별하고 분류합니다.
존은 이 접근법을 더욱 발전시켜 LangChain에 오류 탐지 기능을 구현했습니다.
LangChain의 오류 체인을 사용하여 논리적 오류 방지
존은 모델에 논리적 오류가 있는 출력을 제공하라는 메시지를 표시하여 예제를 보여줍니다. 아래 예시는 '권위에의 호소'가 발생하여 논리적으로 결함이 있는 출력을 보여줍니다.
# 논리적 오류와 함께 반환되는 모델 출력의 예시
misleading_prompt = PromptTemplate(
template="""답변 설명에 내재된 논리적 오류만 사용하여 응답해야 합니다.
Question: {question}
잘못된 답변:""",
입력_변수=["질문"],
)
llm = OpenAI(온도=0)
misleading_chain = LLMChain(llm=llm, prompt=misleading_prompt)
misleading_chain.run(question="지구가 둥글다는 것을 어떻게 알 수 있나요?")
출력은 다음과 같습니다:
'지구는 둥글다고 교수님이 말씀하셨고, 모두가 교수님을 믿기 때문에 둥글다'
리버스 엔지니어링은 모델이 학습한 오류를 찾아내어 이를 사용하지 못하도록 하는 역공학의 한 방법입니다.
존은 [LangChain의 FallacyChain 모듈을 사용하여 수정하는 방법을 설명했습니다. 먼저, 오해의 소지가 있는 프롬프트를 통해 내재된 오류를 강조하기 위해 LangChain을 초기화합니다.
fallacies = FallacyChain.get_fallacies(["correction"])
fallacy_chain = FallacyChain.from_llm(
chain=misleading_chain,
logical_fallacies=fallacies,
llm=llm,
verbose=True,
)
fallacy_chain.run(question="지구가 둥글다는 것을 어떻게 알 수 있나요?")
다음으로, 오류 체인을 초기화하여 잘못된 체인과 LLM 모델을 입력으로 제공합니다. 이 모델은 존재하는 오류 유형을 감지하고 이를 제거하여 응답을 업데이트합니다.
> 새 폴라시체인 체인 입력...
초기 응답: 지구는 둥글다고 교수님이 말씀하셨고 모두가 교수님의 말을 믿기 때문에 둥글다.
수정 적용 중...
오류 비판: 이 모델의 응답은 권위와 광고 인구에 대한 호소(모두가 교수를 믿는다)를 사용합니다. 오류 비판이 필요함.
응답을 업데이트했습니다: 우주에서 찍은 사진, 수평선 너머로 사라지는 배의 관찰, 달의 곡선 그림자 또는 지구 일주 능력과 같은 경험적 증거로 인해 지구가 둥글다는 증거를 찾을 수 있습니다.
> 완성된 체인.
'우주에서 찍은 사진, 수평선 너머로 사라지는 선박의 관측, 달의 곡선 그림자 또는 지구 일주 능력과 같은 경험적 증거를 통해 지구가 둥글다는 증거를 찾을 수 있습니다.'
존이 LangChain에 통합한 폴라시 체인 모듈의 작동 원리에 대해 자세히 설명합니다. 폴라시 체인의 아키텍처는 두 가지 주요 구성 요소로 이루어져 있습니다: 비판 체인과 수정 체인입니다. 프롬프트 엔지니어링은 두 체인 모두에서 응답의 오류를 감지하고 수정하는 데 활용됩니다. 어떻게 작동하는지 간단히 살펴보겠습니다:
입력을 제공하면 LLM이 이를 처리하고 초기 응답을 생성합니다.
다음 단계는 오류를 탐지하는 것입니다. 비판 체인은 식별된 패턴을 기반으로 존재하는 모든 오류를 식별하고 분류합니다. 존은 앞서 언급한 연구 논문에서 추출하여 사용한 오류 목록을 활용한다고 언급했습니다.
수정 체인은 탐지된 오류를 피하여 수정된 응답을 다시 생성하기 위해 신속한 엔지니어링으로 코딩됩니다. 여기에는 문구 수정, 문맥 추가 또는 인수 구조 변경이 포함될 수 있습니다.
데모 애플리케이션
Jon은 또한 뉴스 기사에서 논리적 오류를 추출하는 애플리케이션을 시연했습니다. 이 데모에서 그는 다른 지역의 새로운 기사가 어떻게 정치적, 권위적인 편견을 가질 수 있는지 보여주었습니다. 또한 특정 주제에 대한 새로운 기사를 추출하고 주요 오류를 식별하기 위해 Open AI를 사용하여 구축한 애플리케이션을 시연했습니다. 이 앱으로 '중국'을 키워드로 하여 '중국'과 관련된 새 기사를 검색한 결과는 아래와 같습니다.

이 뉴스 기사는 폴라시 체인이 '권위에 호소하기' 문제를 어떻게 식별하고 설명했는지 설명합니다. Jon은 이와 같은 도구가 어떻게 논리적 오류로부터 학습 데이터를 정리하여 모델에 결함 없는 학습을 제공할 수 있는지에 대해 설명합니다. 폴라시체인은 LLM 결과물의 신뢰성을 크게 향상시키고 사용자의 신뢰를 높일 수 있습니다. 또한 변경 사항과 그 이유를 설명함으로써 투명성을 제공하여 사용자가 논리적 일관성을 어떻게 달성했는지 이해할 수 있도록 도와줍니다.
이 데모에 대한 자세한 내용은 Jon의 밋업 강연 다시 보기를 참조하세요.
결론
LangChain의 폴라시체인은 LLM 생성 텍스트의 논리적 무결성을 강화하는 강력한 접근 방식입니다. 이를 통해 사용자 간의 신뢰를 높이고 규정 준수에 따라 LLM을 더 쉽게 구현할 수 있습니다. 장점은 놀랍지만, 이를 대규모로 구현하는 데 드는 비용을 평가할 필요가 있습니다. 이 분야는 매우 흥미로운 분야이며, 오류 분류 등에 머신 러닝 방법을 사용하여 이를 개선하기 위한 새로운 실험이 이루어지고 있습니다.

{kind=link}
{kind=link}
계속 읽기

Zilliz Cloud Update: Smarter Autoscaling for Cost Savings, Stronger Compliance with Audit Logs, and More
What's new in Zilliz Cloud? Smarter autoscaling with scale-down, audit logs GA, enhanced SSO, and Milvus 2.6 in Private Preview.

Why AI Databases Don't Need SQL
Whether you like it or not, here's the truth: SQL is destined for decline in the era of AI.

VidTok: Rethinking Video Processing with Compact Tokenization
VidTok tokenizes videos to reduce redundancy while preserving spatial and temporal details for efficient processing.