




VDBBench、ベクトルデータベース向けのコスト考慮型ベンチマーキングを追加
昨年、私たちは VectorDBBench 1.0 をリリースし、ベクトルデータベースのベンチマークを本番ワークロードにより近づけました。固定されたベンチマークデータでピーク QPS だけをテストするのではなく、VectorDBBench(VDBBench としても知られています)により、チームは自社の本番システムをより忠実に反映したワークロードパターンを使ってベクトルデータベースを評価できます。取り込み、フィルタリング、再現率、レイテンシ、同時実行、カスタムデータセットなどです。
VDBBench の最新リリースでは、新たな次元であるコストが追加されました。
本番チームがベクトルデータベースを選ぶ際、性能だけで判断することはほとんどありません。目標 QPS を達成するのにいくらかかるのか、そのコストモデル下で P99 がどのように振る舞うのか、挿入されたデータがいつ検索可能になるのか、いつ完全にインデックス化されるのか、ペイロードサイズが検索にどう影響するのか、多数のテナントにまたがってシステムがどう振る舞うのか、アイドル状態の後の最初のクエリで何が起きるのかを知る必要があります。これらの問いは、いまや VDBBench の一部です。
これらの新しいコスト考慮型ベンチマークが実際にどのように機能するかを示すため、私たちは一般的に評価対象となる 3 つのマネージドベクトルデータベース製品、Zilliz Cloud、Turbopuffer、Pinecone をテストしました。結果は新しい VDBBench Cost Leaderboard, に公開されており、挿入準備状況、ペイロード検索、マルチテナント検索、コールドレイテンシ、コスト性能のトレードオフを比較するチャートと表が含まれています。
リーダーボードは結果を読むための一つの方法にすぎません。これは、ある時点における 3 つの製品のスナップショットです。VDBBench はオープンソースであるため、チームはこれらのケースを再現したり、リーダーボードに掲載されていない製品をベンチマークしたり、自社の本番環境に近いデータに合わせてワークロードを調整したりすることもできます。
目的は普遍的な勝者を決めることではなく、チームが自分たちのワークロード、性能目標、予算に最も適したベクトルデータベースを選べるよう支援することです。
VDBBench の新機能
今回のリリースでは、ピーク QPS のリーダーボードでは見落とされがちな本番環境での挙動を測定する、クラウド向けの 4 つのベンチマークケースが追加されました。
| ケース | 測定内容 | 重要な理由 |
|---|---|---|
| CloudInsertCase | 挿入完了、検索可能状態、完全にインデックス化された状態、書き込みコスト | RAG、カタログ、エージェントメモリでは鮮度とバックフィルコストが重要 |
| CloudPayloadSearchCase | QPS、P99 レイテンシ、再現率、レスポンスペイロードの形状 | ベクトルやメタデータを返すことで、検索コストの構造が変わる可能性がある |
| MultitenantSearchCase | 多数のテナントまたは名前空間にまたがるスループット | SaaS ワークロードは、単一テナント検索とは異なる形でルーティングとパーティションの挙動に負荷をかける |
| CloudColdLatencyCase | アイドル後の最初のクエリとウォームアップ済みクエリパスの比較 | コールドスタート挙動は、低頻度テナントやエージェントメモリにとって重要 |
これらのケースに加えて、Cost Leaderboard では、各製品の測定済みサービング上限の下で目標 QPS レベルにおける運用コストをモデル化するコスト・パレートビューを追加しています。購買判断は通常、性能とコストが交わる地点に左右されるためです。
VDBBench Cost Leaderboard は、これらのケースを使用してマネージド製品を公開比較します。これらのケースはオープンソースの VDBBench に同梱されているため、チームはリーダーボードに表示されていない製品やワークロードを含め、自社の評価に再利用できます。
テスト対象: Zilliz Cloud vs. Turbopuffer vs. Pinecone
この最初のコスト考慮型実行では、一般的に評価対象となる 3 つのマネージドベクトルデータベース製品をテストしました。すべての製品は 2026 年 5 月 10 日に AWS US West (us-west-2) でベンチマークされました。運用モデルが異なるため、結果は単一のランキングとしてではなく、ワークロードへの適合性という観点で解釈すべきです。
| 製品 | このベンチマークにおける役割 |
|---|---|
| Zilliz Cloud | Milvus の開発元によるマネージドクラウドベクトルデータベースおよびベクトル lakebase。Tiered 構成と Capacity 構成でテスト |
| Turbopuffer | unpinned モードと pinned モードでテストされたサーバーレスベクトルデータベース |
| Pinecone Serverless | 一般的な本番環境の参照点として使用される、成熟した低運用負荷のサーバーレスベクトルデータベース |
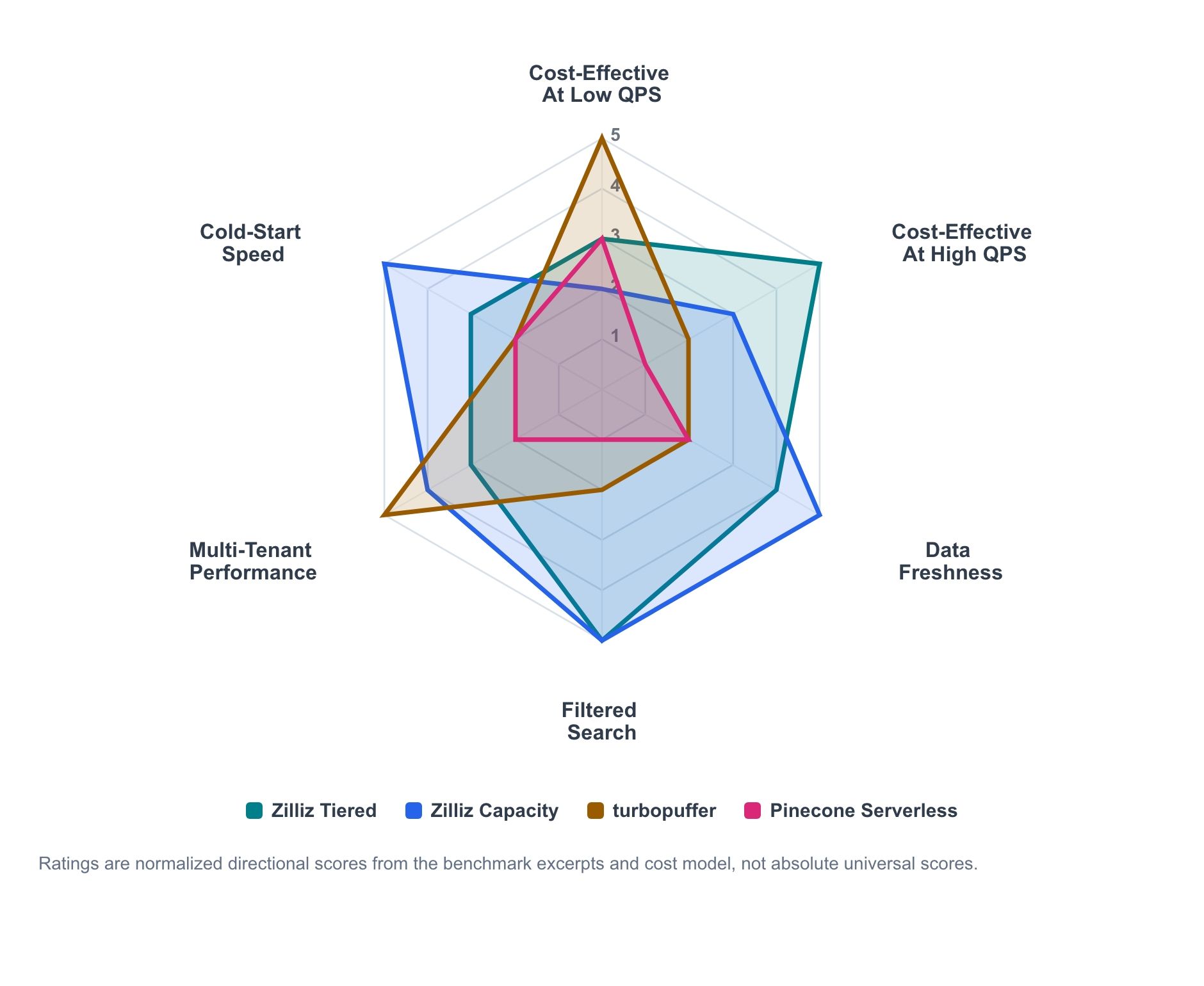
図 1. ベンチマーク抜粋とコストモデリングに基づく、ワークロード適合性の方向性を示す要約。スコアはワークロードの各次元間で比較できるよう正規化されており、普遍的な絶対ランキングとして読むべきではありません。
このレーダーチャートは、ベンチマーク抜粋とコストモデルから得られる方向性のシグナルを要約しています。これは絶対的なスコアカードではなく、各製品がどの領域で強みを発揮しやすいかを示すマップです。
- Zilliz Cloud Tiered は、使用率が上がるにつれてスケールする、経済的なアクティブサービング向けラインです。
- Zilliz Cloud Capacity は、予測可能なサービング、鮮度、コールド時の挙動に対して、より高い制御性を備えたプロファイルです。
- Turbopuffer は、使用量課金のサーバーレス経済性と namespace 指向のスループットがワークロードに合致する場合に最も強みを発揮します。
- Pinecone は、特定のテストでコストパフォーマンスの最前線ではない場合でも、有用な低運用負荷のサーバーレス基準であり続けます。
主なパターンは明確です。サーバーレスの経済性は、低い持続 QPS では魅力的になり得ます。使用率が上がるにつれて、プロビジョンドキャパシティの競争力が高まります。鮮度、フィルタ付き検索、ペイロードサイズ、テナント数、コールド時の挙動はいずれも意思決定を左右し得ます。
データセットとワークロード
コストを考慮したケースでは、2 つのワークロード形状を使用します。
- シングルテナント LAION 100M: 1 億個の 768 次元密ベクトル。これは、ペイロードサイズ、フィルタ、再現率、持続 QPS が重要となる大規模な本番コレクションを表します。
- マルチテナント Cohere 10M: 1,000 テナントにランダムに分割された 1,000 万個の 768 次元密ベクトル — テナントあたりおよそ 10K ベクトル。これは、各テナントのデータセットは小さいものの、システムが多数の namespace またはテナントパーティションを効率的にルーティングして提供する必要がある SaaS 型ワークロードを表します。
以下の抜粋は、調査結果の傾向を示しています。完全なマトリクス、クライアント定義、再現の詳細については、Cost Leaderboard と VectorDBBench リポジトリが引き続き情報源です。
CloudInsertCase: 挿入済みが常に準備完了とは限らない
挿入性能は 1 つの数値ではありません。 マネージドベクトルデータベースは、そのデータが意図したインデックスパスで安全に検索できるようになる前に、クライアントからデータを受け付けることがあります。本番ワークロードでは、チームは挿入操作が完了する時点、データが検索可能になる時点、バックグラウンドのインデックス作成が完全に追いつく時点を知る必要があります。
CloudInsertCase は、書き込みからサービングまでのライフサイクルを測定します。これは、RAG コーパスの更新、製品カタログの更新、エージェントメモリへの書き込み、データのバックフィルに重要です。これらのシステムでは、「挿入が受理された」だけでは不十分です。運用上の問いは、新しく書き込まれたデータを本番性能で確実に検索できるようになるのはいつか、という点です。
| 製品 / モード | バッチサイズ | 挿入時間 | 検索可能までの待機時間 | 完全インデックス化までの待機時間 | 書き込みコスト |
|---|---|---|---|---|---|
| Zilliz Cloud Capacity 12CU | 10,000 | 3.2 hr | 0 ms | 1.9 min | $9.50 |
| Zilliz Cloud Tiered 4CU | 10,000 | 4.1 hr | 0 ms | 10.9 min | $6.34 |
| Turbopuffer (backpressure off) | 10,000 | 1.8 hr | 6.4 hr | 2.0 min | $302 |
| Pinecone Serverless | 10,000 | 72.4 hr | 0 ms | 127 ms | $1,180 |
表 1. LAION 100M バッチ 10k の挿入抜粋。コストとタイミングは現在のリーダーボード実行からのものです。プロビジョンドされた Zilliz 構成では、書き込みコストはロードおよびインデックス作成ウィンドウ中に消費された CU 時間コストです。Turbopuffer と Pinecone では、従量課金の書き込み料金です。タイミングは、inserted、searchable、fully indexed の各状態に対するクライアント定義(VDBBench ソース内でクライアントごとに定義)と併せて読んでください。
バッチサイズによって、製品ごとの数値は変わります。
- Turbopuffer は大きなバッチで強力な生の取り込み性能を示します。特にバックプレッシャーを無効にした場合、これは最もアグレッシブな取り込みモードです。batch-10k パスでは挿入をすばやく完了しますが、検索可能になるまでの待機が、完全な準備完了までの時間枠の大半を占めます。
- Zilliz Cloud はバッチサイズ全体でより安定しています。テストした Capacity および Tiered 構成では、挿入完了後すぐにデータが検索可能になり、残りの完全インデックス化待機は分単位で測定されます。
- Pinecone Serverless は、このテストにおけるより遅い一括取り込みのベースラインです。データが受け入れられると、これらの実行では追加の検索可能待機および完全インデックス化待機は実質的にゼロですが、挿入ステージ自体にははるかに長い時間がかかります。
製品の読み取り結果はワークロードに左右されます。
- Zilliz は、新しいデータを予測可能なコストですばやく検索可能かつインデックス化する必要があるワークフローに適しています。
- Turbopuffer は、ワークロードがより長い準備完了時間枠を許容できる場合の、大規模な受け入れ済みバックフィルに適しています。
- Pinecone は、一括ロード速度やコストよりも運用のシンプルさが重要な、低ボリュームのサーバーレス取り込みパターンに適しています。
一括ロードはコストイベントでもあります。 この LAION 100M 挿入ケースでは、Zilliz 構成は、テストした batch-10k パスの書き込み側コストを 1 桁ドル台に抑えています。Turbopuffer は $302 前後としてモデル化されています。Pinecone Serverless は $1,180 前後としてモデル化されています。これは、ある価格モデルが普遍的に優れているという意味ではありません。つまり、挿入の経済性は、そのワークロードがそのパスをどれだけ頻繁に実行するかに依存するということです。
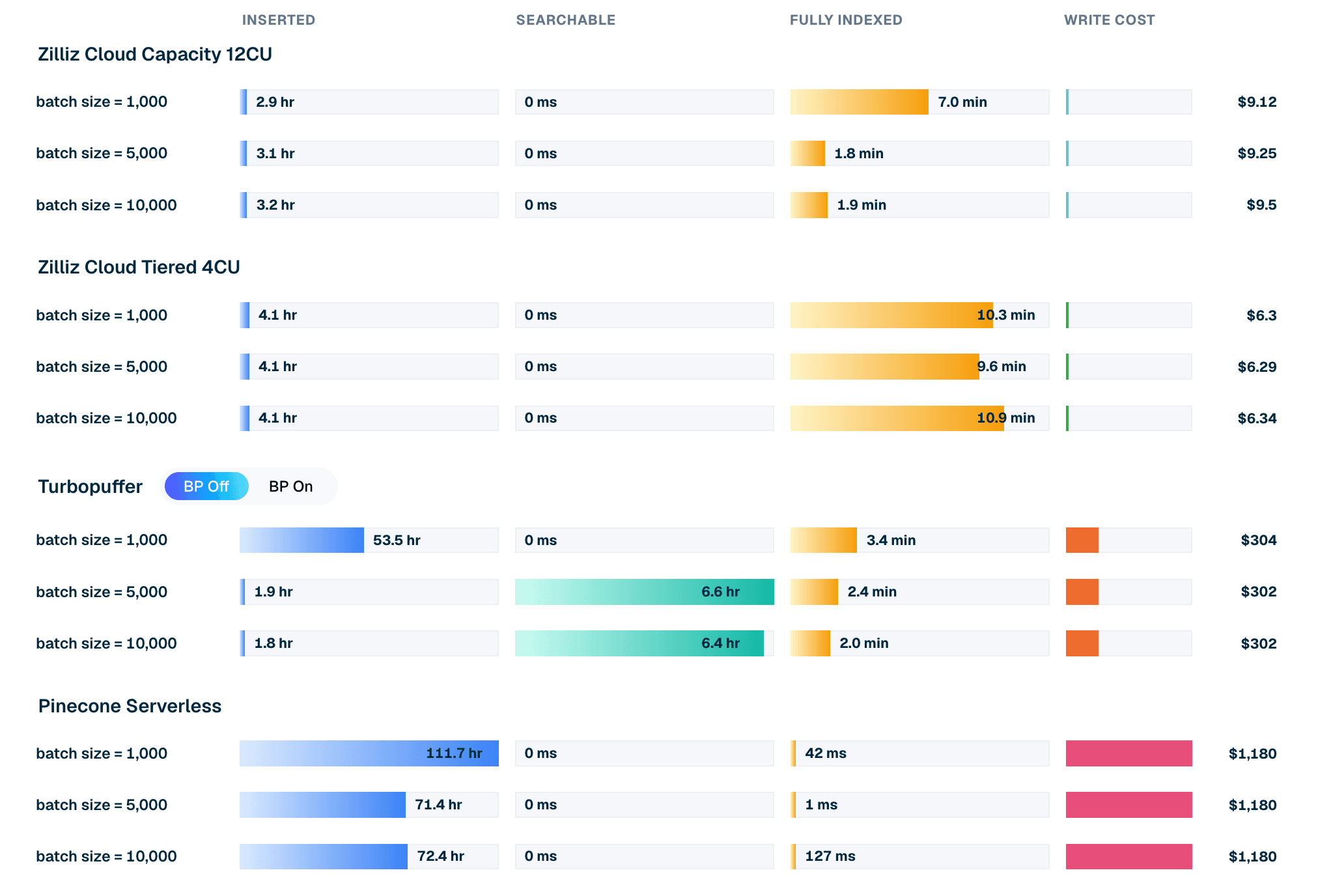
図 2. batch 10k における LAION 100M の挿入ライフサイクル:製品ごとの挿入時間、検索可能待機、完全インデックス化待機、モデル化された書き込みコスト。
CloudPayloadSearchCase: ペイロードが検索面を変える
データが検索可能になると、次の問題はデータベースが 1 秒あたり何クエリを処理できるかだけではありません。レスポンスの形も重要です。ID のみを返すことは、メタデータや生のベクトルを返すこととは大きく異なります。768 次元ベクトルは、各結果に数千バイトを追加する可能性があります。topK=100 では、ペイロードサイズがクエリコストとレイテンシの主要因になり得ます。
CloudPayloadSearchCase は、異なるレスポンスペイロードとフィルター形状の下で、シングルテナントの LAION 100M をテストします。読み取り結果は、最大同時 QPS、その同時実行数での P99 レイテンシ、ペイロードタイプ、および利用可能な場合は recall を組み合わせたものです。
表を読む際の注意点:ここでの P99 は最大同時実行数、つまり各製品のピーク QPS を生み出す飽和点で測定されており、余裕のあるサービスレベルの運用点で測定されたものではありません。これは、構成が測定された限界でどのように振る舞うかを示します。
| 製品 | 最大同時実行時の P99 レイテンシ | 最大 QPS | recall@10 |
|---|---|---|---|
| Zilliz Cloud Capacity 32CU | 158 ms | 786.1 | 0.9728 |
| turbopuffer | 2.34 s | 395.7 | 0.9321 |
| Zilliz Cloud Capacity 12CU | 299 ms | 376.0 | 0.9723 |
| Turbopuffer pinned | 3.30 s | 68.2 | 0.9321 |
| Zilliz Cloud Tiered 4CU | 5.57 s | 49.2 | 0.9510 |
| Pinecone Serverless | 4.85 s | 4.6 | 0.9609 |
表 2. シングルテナント LAION 100M、フィルターなし ID のみ、topK 100。Pinecone に関する注記:このシングルテナントケースでのスループットはサーバー側の読み取りユニットスロットリングによって制限されるため、実行は同時実行数 4〜5 で頭打ちになります。他の製品は 80 です。その行は、飽和結果ではなく、ペース制御されたサーバーレスのベースラインとして読んでください。
構成は重要です。12CU では、この広範な ID のみのケースにおいて Zilliz Capacity と Turbopuffer は生の QPS では近い一方、Zilliz は recall と P99 レイテンシで先行しています。32CU では、Zilliz Capacity はこのシングルテナントワークロードにおけるテスト済みの Turbopuffer 結果を上回ります。
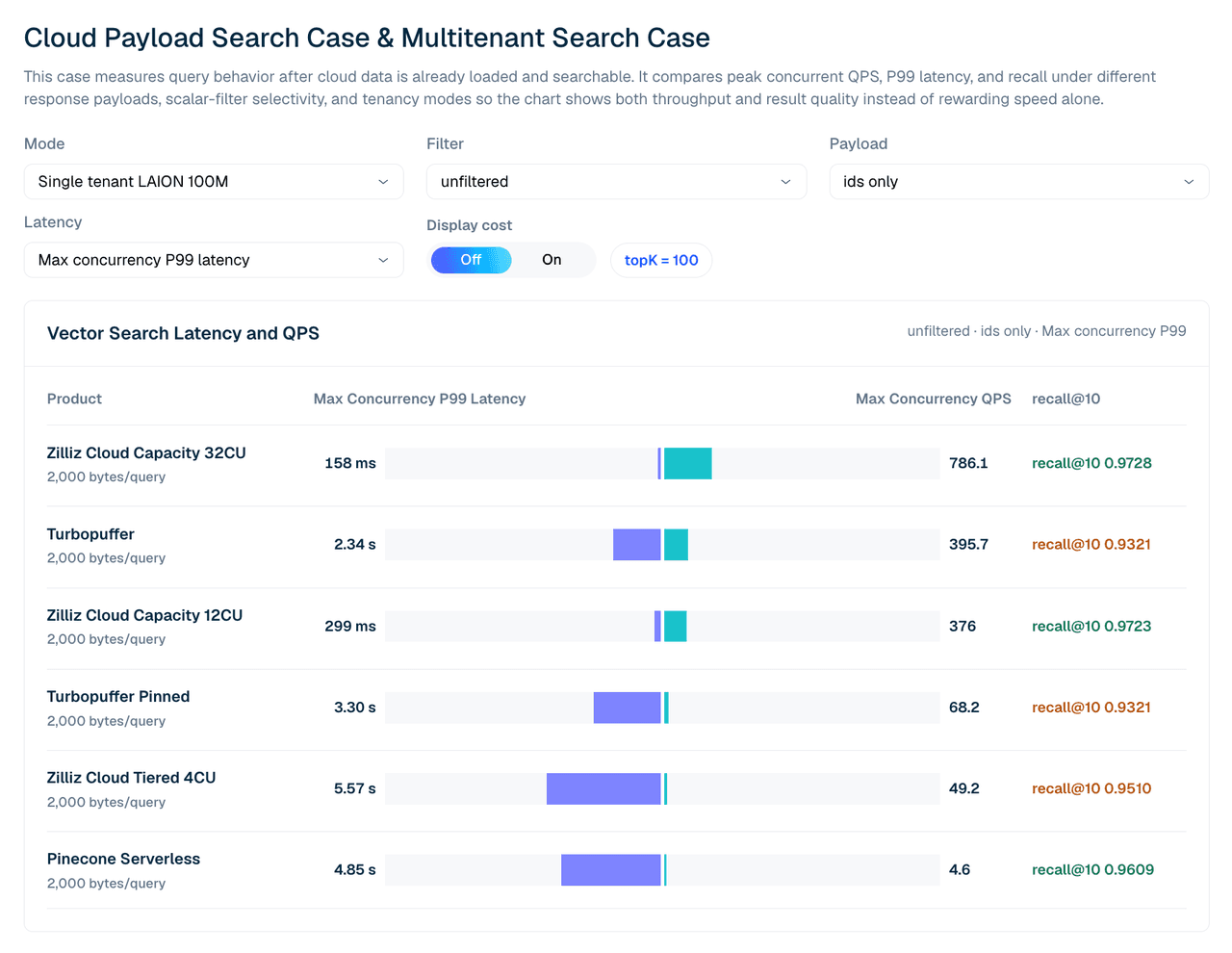
図 3. ID のみのレスポンスを使用したシングルテナント LAION 100M 検索。このビューは、テスト済みのマネージド構成全体で、最大同時 QPS、P99 レイテンシ、recall@10 を比較しています。
問題は、ある1つの構成でどの製品が最速かだけではありません。チームがより多くのキャパシティを購入したり、ペイロードの形状を変更したり、リコール目標を必要としたりしたときに、性能がどのように変化するかです。クエリが生のベクトルペイロードを返す場合、スループットは大きく変わる可能性があります。
| 製品 | IDs-only QPS | ベクトルペイロード QPS | リコール |
|---|---|---|---|
| Zilliz Cloud Tiered 4CU | 49.2 | 44.0 | 0.9510 |
| Zilliz Cloud Capacity 12CU | 376.0 | 229.4 | 0.9723 |
| Zilliz Cloud Capacity 32CU | 786.1 | 531.4 | 0.9728 |
| turbopuffer | 395.7 | 382.2 | 0.9321 |
| Pinecone Serverless | 4.6 | 4.5 | 0.9609 |
表 3. 広範な非フィルタ検索におけるペイロードの抜粋。チームは、IDs-only 検索だけでなく、アプリケーションが実際に返すペイロード形状をベンチマークする必要があります。
フィルタ検索: 選択性が重要になる場面
多くの本番環境のベクトル検索ワークロードは、権限管理またはフィルタが適用されています。サポート用コパイロットは、ユーザーが閲覧を許可されているドキュメントだけを検索するかもしれません。レコメンデーションシステムは、地域、カテゴリ、販売者、在庫状況でフィルタするかもしれません。エンタープライズ検索アプリは、結果をランキングする前に、テナント、アクセス制御、鮮度、ドキュメント種別の制約を適用するかもしれません。
これらのフィルタは見せかけのものではありません。実行経路を変えます。99.9% の整数フィルタとベクトルペイロードのストレスポイントでは、製品の挙動が急激に変化します。
| 製品 | 最大 QPS | リコール | P99 レイテンシ |
|---|---|---|---|
| Zilliz Cloud Tiered 4CU | 955.7 | 0.9423 | 0.16 s |
| Zilliz Cloud Capacity 12CU | 933.0 | 0.9781 | 0.12 s |
| turbopuffer | 45.1 | 0.9436 | 7.03 s |
| Pinecone Serverless | 4.8 | —* | 3.30 s |
表 4. シングルテナントの選択的フィルタのストレスポイント: ベクトルペイロードを伴う 99.9% の整数フィルタ。このストレスポイントにおける Pinecone Serverless の実行のリコールは、公開時点ではまだ利用できませんでした。その QPS とレイテンシは測定された実行結果に基づいています。
これは、コストを意識した評価に複数のワークロード形状が必要である理由を示す最も明確な例の1つです。広範な非フィルタ検索で良好に動作する製品が、選択的フィルタ検索に最適とは限りません。権限付き検索、アクセス制御が重い RAG、またはフィルタ選択性の高いワークロードでは、非フィルタ行よりもフィルタ行の方が重要になる場合があります。
MultitenantSearchCase: 多数の小規模テナントは異なる挙動を示す
シングルテナントのベンチマークは、すべてのクラウドワークロードを捉えられるわけではありません。
多くの AI アプリケーションは SaaS 型です。1つの製品が、より小さなデータセットを持つ何千ものテナントにサービスを提供することがあります。運用上の課題は、単一の大規模コレクション内でのベクトル検索だけではありません。ルーティング、分離、名前空間管理、そして多数の小さなパーティション全体でスループットを維持することです。
マルチテナントケースでは、Cohere 10M データセットを 1,000 テナントに分割して使用します。クエリ形状は topK 50 を使用し、IDs-only、ベクトルペイロード、フィルタ行を比較します。
この表の読み方には、2つの構成上の注意点があります。
まず、ここでの Zilliz 構成は意図的に小さく、Tiered 1CU と Capacity 2CU であり、Cohere 10M データセットを保持するのにちょうど十分なサイズです。上記のシングルテナントケースでは、Zilliz の QPS が CU 数に応じてスケールすることがすでに示されています。このケースが問うているのは、ピークスループットではなく、データに合わせたサイズの構成におけるコスト効率です。
次に、Pinecone の列は切り離された低並行度実行(concurrency 4)であり、より高い並行度の行に対して正規化されていないため、直接比較ではなく文脈情報として扱ってください。
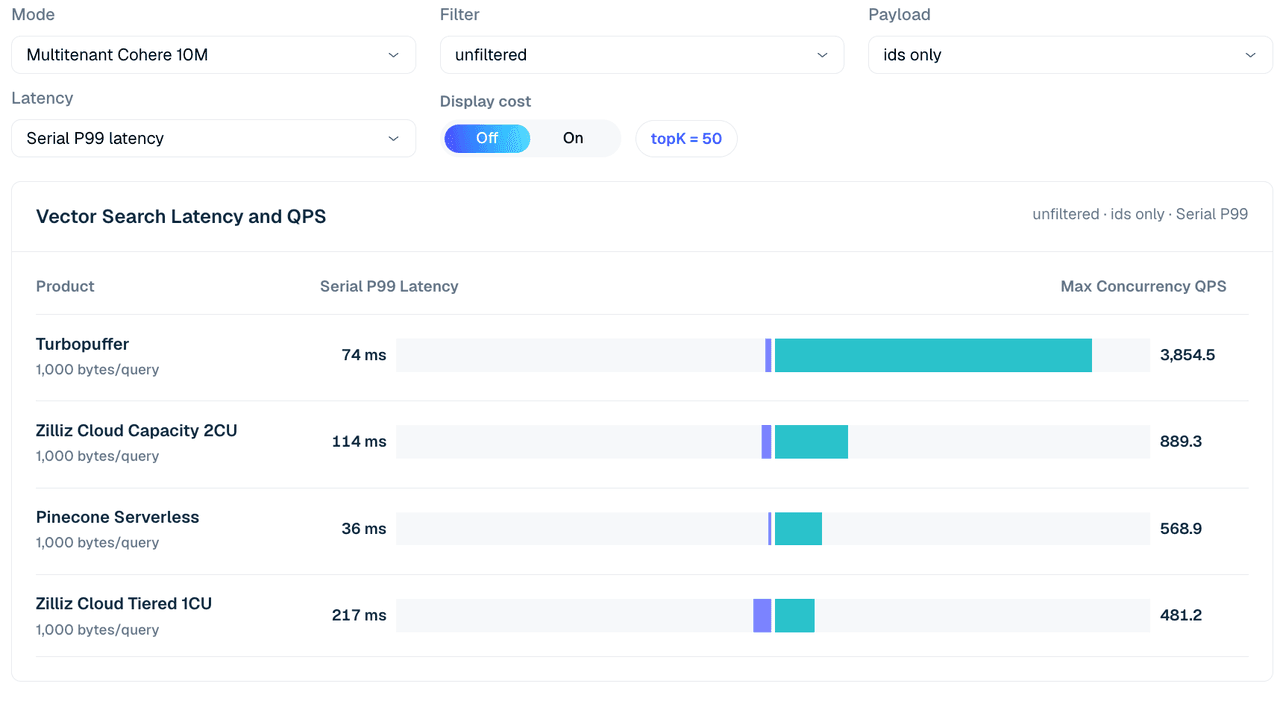
図 4. 1,000 テナントにわたるマルチテナント Cohere 10M 検索、非フィルタ IDs-only、topK 50。このビューは、テストされた構成全体でシリアル P99 レイテンシと最大同時 QPS を比較しています。下の表では、ペイロードとフィルタのバリエーションを追加しています。
| ケース | Zilliz Tiered 1CU | Zilliz Capacity 2CU | turbopuffer | Pinecone (c4 run) |
|---|---|---|---|---|
| フィルターなし、IDのみ | 481 | 889 | 3,855 | 569 |
| フィルターなし、ベクトル | 34 | 371 | 1,775 | 542 |
| 整数フィルター 99.9%、ベクトル | 625 | 1,307 | 3,835 | 526 |
| スカラーラベル 1%、ベクトル | 152 | 588 | 1,767 | 600 |
| スカラーラベル 50%、ベクトル | 29 | 317 | 1,760 | 562 |
表 5. 1,000 テナント、topK 50 におけるマルチテナント検索の抜粋。
このモードでは、Turbopuffer は全般的に強力です。フィルターなしの ID のみの検索で 3,855 QPS、選択的な整数フィルター/ベクトルの行で 3,835 QPS に達しています。Zilliz Cloud Capacity 2CU は、この抜粋において引き続きより強力な Zilliz プロファイルであり、フィルターなしの ID のみで 889 QPS、99.9% 整数フィルター/ベクトルの行で 1,307 QPS に達しています。
プロダクトの見方は、ここでもワークロードの形に左右されます。Turbopuffer は、多数の軽量テナントや namespace 指向のスループットに適しています。Zilliz は、ワークロードがフィルター付き、権限付き、recall に敏感、またはテナントあたりでより重い場合により強く、特にチームが配信目標に合った Zilliz Capacity 構成を選択できる場合に有利です。
CloudColdLatencyCase: アイドル後の最初のクエリ
ウォーム状態のベンチマークループは、コールド時の挙動を隠すことがあります。多くの本番 AI アプリケーション、特にエージェントメモリ、ロングテール RAG、低頻度のテナントワークロードでは、アイドル後の最初のクエリが重要です。システムはウォームアップ後には高速に見えても、コールド状態のコレクション、namespace、またはキャッシュ経路に再びアクセスされると、数秒のレイテンシを追加することがあります。
CloudColdLatencyCase はその挙動を切り分けます。少なくとも 24 時間アイドル状態だったコレクションに対する最初のクエリを測定します。これは、キャッシュと配信経路が現実的に到達し得る限りコールドになるのに十分な長さです。そして、同じ実行から得られるウォーム状態の経路での最初のクエリと比較します。
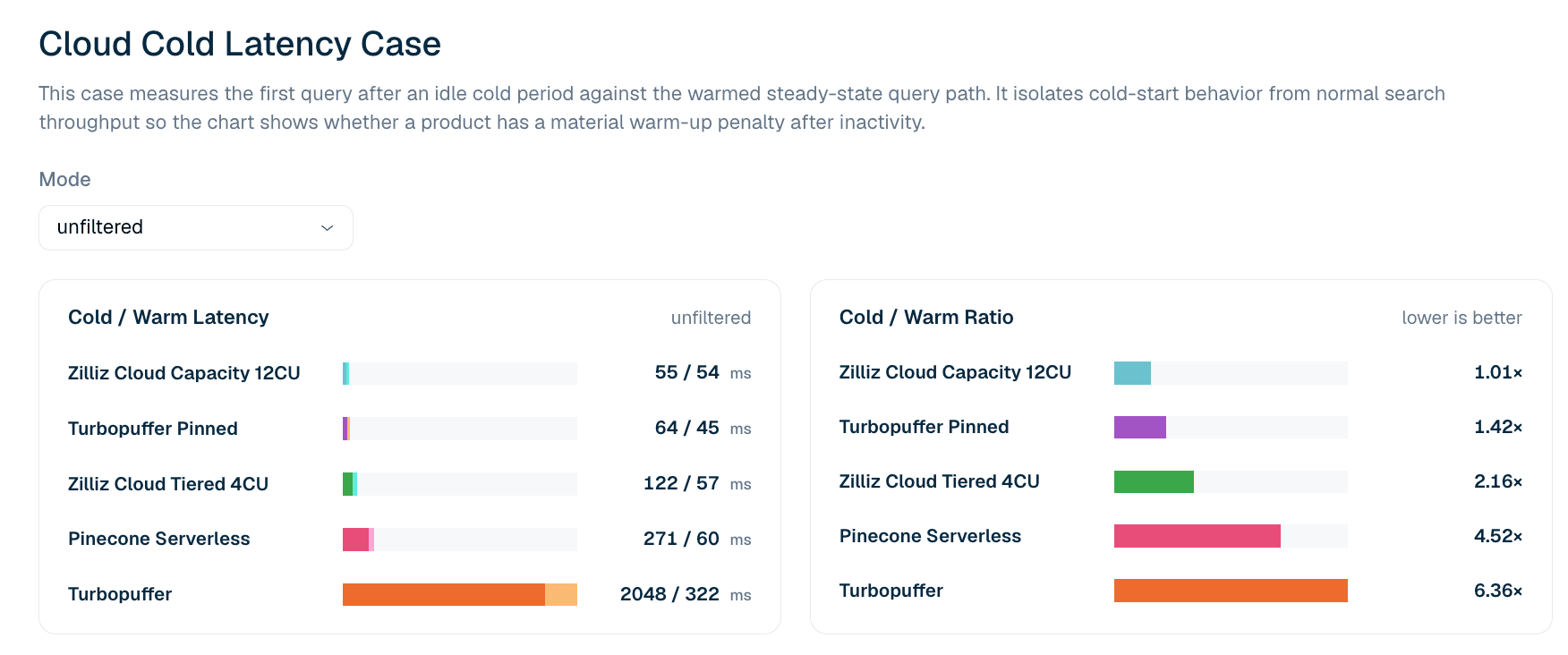
図 5. フィルターなしの LAION 100M 検索における、アイドル後の最初のクエリレイテンシとウォーム状態のクエリ経路の比較。コールド/ウォーム比は、プロダクトがアイドル後に実質的な最初のクエリペナルティを持つかどうかを示します。
| プロダクト | アイドル後の最初のクエリ | 最初のウォームクエリ | コールド/ウォーム比 |
|---|---|---|---|
| Zilliz Cloud Capacity 12CU | 55 ms | 54 ms | 1.01x |
| Turbopuffer pinned | 64 ms | 45 ms | 1.42x |
| Zilliz Cloud Tiered 4CU | 122 ms | 57 ms | 2.16x |
| Pinecone Serverless | 271 ms | 60 ms | 4.52x |
| turbopuffer | 2,048 ms | 322 ms | 6.36x |
表 6. フィルターなしの LAION 100M におけるコールドおよびウォームの最初のクエリレイテンシ抜粋。このケースでは、テールパーセンタイルではなく最初のクエリレイテンシを報告しています。P99 におけるコールド/ウォーム比は、後続クエリのネットワークノイズを拾いがちで、確実には再現されないため、リーダーボードではより厳格な最初のクエリ定義を使用しています。
現在のフィルターなしのコールドレイテンシケースでは、Zilliz Cloud Capacity 12CU が最もタイトなコールド対ウォームのプロファイルを示しています。コールド 55 ms、ウォーム 54 ms、すなわち 1.01x の比率です。Turbopuffer pinned も、コールド 64 ms、ウォーム 45 ms と強力なプロファイルです。Unpinned Turbopuffer はより大きなコールドペナルティを示しており、コールド 2,048 ms、ウォーム 322 ms、すなわち 6.36x の比率です。
コールドレイテンシは常にコストと合わせて読むべきです。Pinned replicas や provisioned capacity は最初のアクセス時のペナルティを低減できますが、経済モデルを変えます。プロダクトは、より多くの熱を保持しているために優れたコールド挙動を示す場合があります。それはインタラクティブなアプリケーションにとって適切なトレードオフになり得ますが、その経路を維持するコストから切り離して考えるべきではありません。
コストのパレートライン: 価格モデルが交差する場所
価格表だけでは不十分です。プロダクトが目標 QPS に到達できない場合、低い単価は役に立ちません。高スループット構成であっても、同じレイテンシ、recall、ペイロード要件を満たす別のプロダクトよりコストが高ければ魅力的ではありません。
Cost Pareto ビューは、測定されたベンチマークの境界と価格モデルを組み合わせたものです。LAION 100M のクエリのみの設定では、各製品ラインはベンチマークで観測された最大 QPS で停止します。その後、チャートは目標 QPS レベルでの運用コストを推定し、測定された制約下でのパレート最適な選択肢を示します。
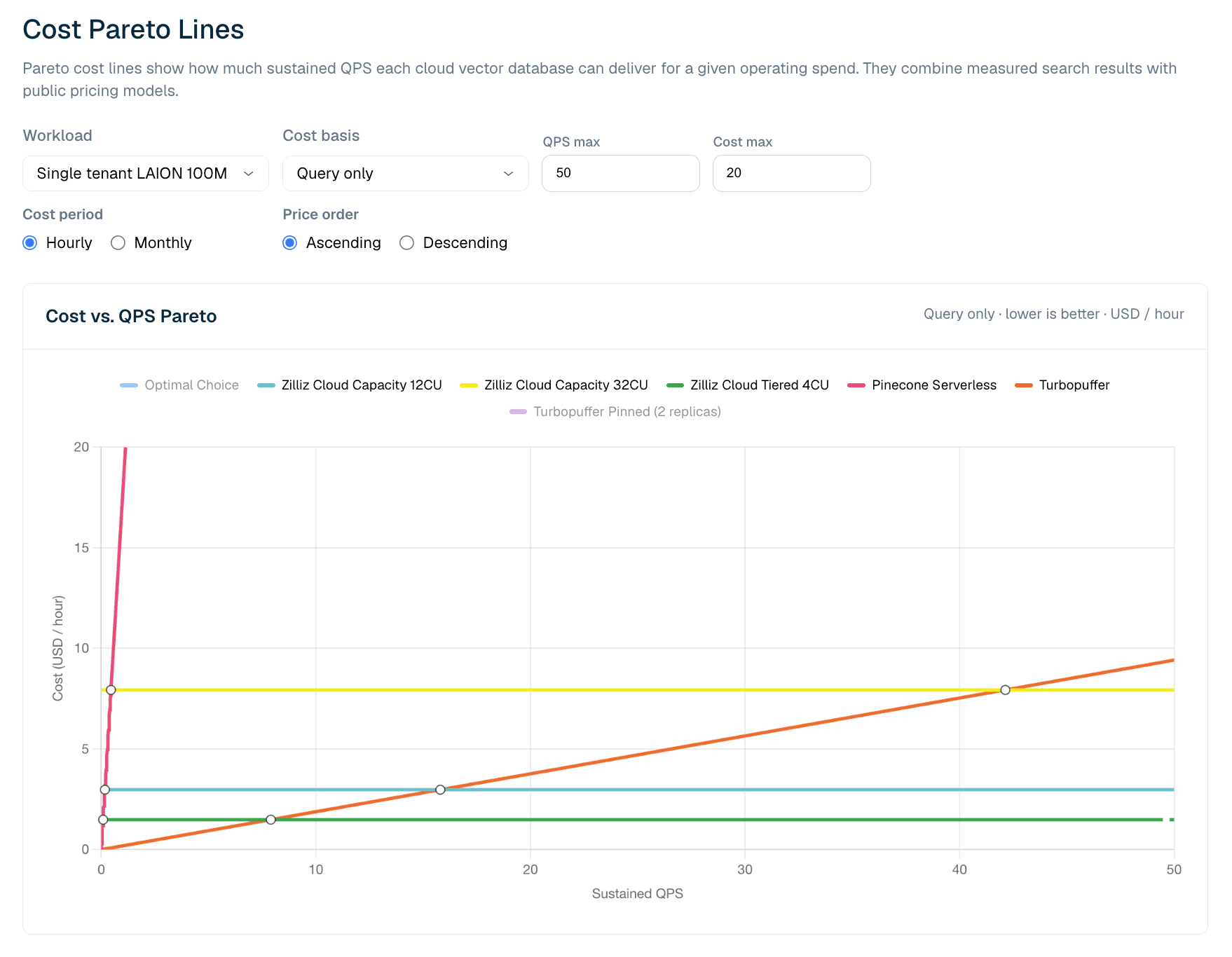
図 6. LAION 100M のクエリのみのワークロードにおけるコストと持続 QPS の関係。Pareto ビューは、低 QPS ではサーバーレス価格がより効率的であり、利用率が上がるにつれてプロビジョニングされた Zilliz 構成がよりコスト効率に優れるようになる地点を示しています。
現在の LAION 100M クエリのみのモデルでは、非常に低い持続 QPS において Turbopuffer が優位です。測定されたクロスオーバーはおよそ 8 QPS 付近にあります。それより低い場合、turbopuffer の使用量課金型クエリ価格がより安価なラインとなり、それを超えると Zilliz Cloud Tiered 4CU の方が安くなります。これは、プロビジョニング後の CU 時間あたりのサービングコストがほぼ固定であるためです。QPS が上昇すると、利用率が改善し、プロビジョニングされた容量のコスト効率が高まります。
これは、サーバーレスが劣っているという意味ではありません。サーバーレスとプロビジョニング型の経済性が交差するという意味です。低く、スパイクがあり、または予測しにくいワークロードでは、使用量課金型サーバーレスが最適な場合があります。持続的な本番トラフィックでは、利用率がクロスオーバーポイントを超えると、固定 CU 時間モデルの方が安くなる可能性があります。より強力なサービング範囲、コールド時の挙動、または運用上の制御を必要とするチームにとっては、Tiered が低コストのラインであっても、Zilliz Capacity が適切なプロファイルとなる場合があります。
Zilliz Cloud vs. Turbopuffer vs. Pinecone: ワークロード別の最適な適合
| ワークロードの形態 | 最も強いシグナル | 理由 |
|---|---|---|
| 非常に低い持続 QPS | turbopuffer | 低 QPS のクロスオーバー前では、使用量課金型サーバーレスの経済性が魅力的 |
| クロスオーバーを超える持続 QPS(このモデルでは約 8 QPS) | Zilliz Cloud Tiered | 利用率が上がるにつれて固定 CU 時間の経済性が向上 |
| 新鮮なデータまたは頻繁な更新 | Zilliz Cloud Capacity / Tiered | LAION 100M の挿入ケースでは、挿入から検索までと完全にインデックス化された準備状態が強い |
| 大規模なフルロードのコスト感度 | Zilliz Cloud Capacity / Tiered | テストされた LAION 100M の一括ロードパスでは、書き込み側コストが大幅に低い |
| 広範なフィルターなしペイロード検索 | Turbopuffer and Zilliz Capacity 32CU | Turbopuffer は広範な取得に強く、Zilliz はより多くの容量でスケールする |
| 選択的フィルターまたは権限付き検索 | Zilliz Cloud Capacity / Tiered | Zilliz は 99.9% フィルターストレスポイントで、はるかに高い QPS と低い P99 レイテンシを示す |
| 多数の軽量テナント | turbopuffer | 1,000 テナントの抜粋で最も強い生の QPS |
| コールドスタートに敏感な対話型アプリ | Zilliz Cloud Capacity; Turbopuffer pinned | 両者とも初回クエリのペナルティを低減するが、コストモデルは異なる |
| 低運用負荷のサーバーレスベースライン | Pinecone Serverless | このワークロードで最先端でない場合でも、成熟したサーバーレスの基準点 |
これらのベンチマーク結果の使い方
VDBBench とその Cost Leaderboard は、ベクトルデータベース評価を、チームが実際にマネージドクラウド製品を購入し運用する方法により近づけるよう設計されています。ピーク QPS は依然として重要ですが、それだけではもはや十分ではありません。より有用な問いは、製品がレイテンシ、リコール、鮮度、ペイロード、テナンシー、コストに関するワークロードの要件を同時に満たせるかどうかです。
実践的な評価フローは次のようになります。
- Performance Leaderboard を使用して、制御されたベンチマーク条件下での生のサービング能力を理解する。
- Cost Leaderboard を使用して、マネージドクラウド製品とワークロード形態全体のコストパフォーマンスのトレードオフを理解する。
- VDBBench 自体を使用して、ケースを再現し、他の製品をテストし、または本番環境に近いデータとクエリ分布に対してベンチマークを実行する。
現在の結果は、いくつかの注意点を踏まえて読む必要があります。
- 製品は2026年5月10日にベンチマークされ、コストモデルは同日時点の AWS us-west-2 の料金を使用しています。料金は日付やリージョンによって変わる可能性があります。
- 固定モード、プロビジョニング済み容量、スケーリング制御、サーバーレスのスロットリングなどの設定選択は、結果に影響を与える可能性があります。
- 準備完了状態は常に同じ方法で公開されるとは限らないため、挿入済み、検索可能、完全にインデックス済みの定義はクライアントごとに確認する必要があります。
- 最後に、ワークロードは意図的に具体的なものになっています。コストのパレート結果は、レイテンシ、リコール、ペイロード形状、測定されたサービング上限と常に併せて読む必要があります。
自分のワークロードをベンチマークする
Cost Leaderboard は現在の結果の公開スナップショットですが、より重要な変化は VDBBench 自体にあります。現在では、チームがワークロード固有の制約(鮮度、ペイロードサイズ、テナント形状、コールド時の挙動、運用モデル)に照らして、パフォーマンスとコストを一緒に評価できるようになっています。
サーバーレス製品は、持続的な QPS が低い場合に適しているかもしれません。プロビジョニング済み容量は、利用率が上がるとよりコスト効率が高くなる可能性があります。あるシステムは広範な検索で優位に立つ一方、別のシステムは選択的フィルター、頻繁な更新、またはコールドスタートに敏感なワークロードでより優れた性能を発揮するかもしれません。
目標は、見出しになる最良の数値ではありません。あなたのワークロードに最も適したものです。
- 現在の結果を見る: VDBBench Cost Leaderboard
- これらのケースを再現する、または自分の候補をベンチマークする: VectorDBBench on GitHub
- 質問や共有したい結果がありますか? GitHub で issue を開くか、Discord の会話に参加してください。

読み続けて

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.

How to Use Anthropic MCP Server with Milvus
MCP + Milvus: Streamline AI agent development with standardized data access, eliminating integration hassles while enhancing context and flexibility.

DeepSeek Always Busy? Deploy It Locally with Milvus in Just 10 Minutes—No More Waiting!
Learn how to set up DeepSeek-R1 on your local machine using Ollama, AnythingLLM, and Milvus in just 10 minutes. Bypass busy servers and enhance AI responses with custom data.