




セマンティック検索をスピード構築
セマンティック検索は、顧客や従業員が正しい商品や情報を見つけるのに役立つ素晴らしいツールです。より良い結果を得るために、インデックス化しにくい情報を表面化することもできる。とはいえ、もしあなたのセマンティックな方法論が迅速に展開されなければ、何の役にも立たないでしょう。顧客や従業員は、システムが彼らのクエリに答えるのに時間をかけている間、ただ座っているわけではありません。
セマンティック検索を高速化するには?遅いセマンティック検索ではだめだ。
幸いなことに、Lucidworksはこのような問題を解決するのが大好きだ。私たちは最近、中規模のクラスタをテストしました。詳細はこちらをご覧ください。その結果、100万以上のドキュメントに対して1500RPS(リクエスト/秒)を達成し、平均レスポンスタイムは約40ミリ秒でした。これはかなりのスピードだ。
セマンティック検索の実装
光速の機械学習マジックを実現するために、Lucidworksはセマンティックベクターサーチアプローチを使用してセマンティック検索を実装しました。2つの重要な部分があります。
セマンティック検索
その1:機械学習モデル
まず、テキストを数値ベクトルにエンコードする方法が必要だ。テキストは商品の説明、ユーザーの検索クエリ、質問、あるいは質問に対する答えである。セマンティック検索モデルは、他のテキストと意味的に似ているテキストが、数値的に「近い」ベクトルにエンコードされるように、テキストをエンコードするように学習される。このエンコーディングステップは、毎秒1,000以上の可能性のある顧客検索やユーザークエリをサポートするために高速である必要があります。
<br
パート2:ベクター検索エンジン
第二に、顧客検索やユーザークエリに最適なものを素早く見つける方法が必要です。モデルはテキストを数値ベクトルにエンコードします。そこから、カタログや質問と回答のリストにあるすべての数値ベクトルと比較し、ベストマッチ、つまりクエリベクトルに「最も近い」ベクトルを見つける必要があります。そのためには、すべての情報を効率的かつ高速に処理できるベクトルエンジンが必要です。エンジンには何百万ものベクトルが含まれている可能性がありますが、本当に必要なのはクエリにベストマッチする20個ほどのベクトルだけです。そしてもちろん、毎秒1000件ほどのクエリーを処理する必要がある。
このような課題に取り組むため、私たちはFusion 5.3リリースでベクトル検索エンジンMilvusを追加しました。Milvusはオープンソースのソフトウェアで、高速です。MilvusはFAISS(Facebook AI Similarity Search)を使用しており、これはFacebookが自社の機械学習の取り組みに本番で使用しているのと同じ技術です。必要に応じて、GPU上でさらに高速に実行することができます。Fusion 5.3(またはそれ以降)が機械学習コンポーネントと一緒にインストールされている場合、Milvusは自動的にコンポーネントの一部としてインストールされるため、これらの機能を簡単にオンにすることができます。
コレクション作成時に指定されたコレクション内のベクトルのサイズは、そのベクトルを生成するモデルによって異なります。たとえば、あるコレクションは、商品カタログのすべての商品説明を(モデルを介して)エンコードして作成されたベクトルを格納することができます。Milvusのようなベクトル検索エンジンがなければ、ベクトル空間全体で類似検索を行うことは不可能である。そのため、類似検索はベクトル空間からあらかじめ選択された候補(例えば500)に限定されることになり、パフォーマンスが低下し、結果の品質も低下する。Milvusは、検索が高速で結果が適切であることを保証するために、複数のベクトルコレクションにまたがる数千億のベクトルを保存することができます。
<br
セマンティック検索の使用
Milvusがなぜ重要なのかが少しわかったところで、セマンティック検索のワークフローに戻ろう。セマンティック検索には3つの段階がある。最初の段階では、機械学習モデルがロードされ、トレーニングされる。その後、データがMilvusとSolrにインデックスされる。最後の段階はクエリーの段階であり、実際の検索が行われる。以下、最後の2つのステージに焦点を当てる。
ミルバスへのインデックス作成
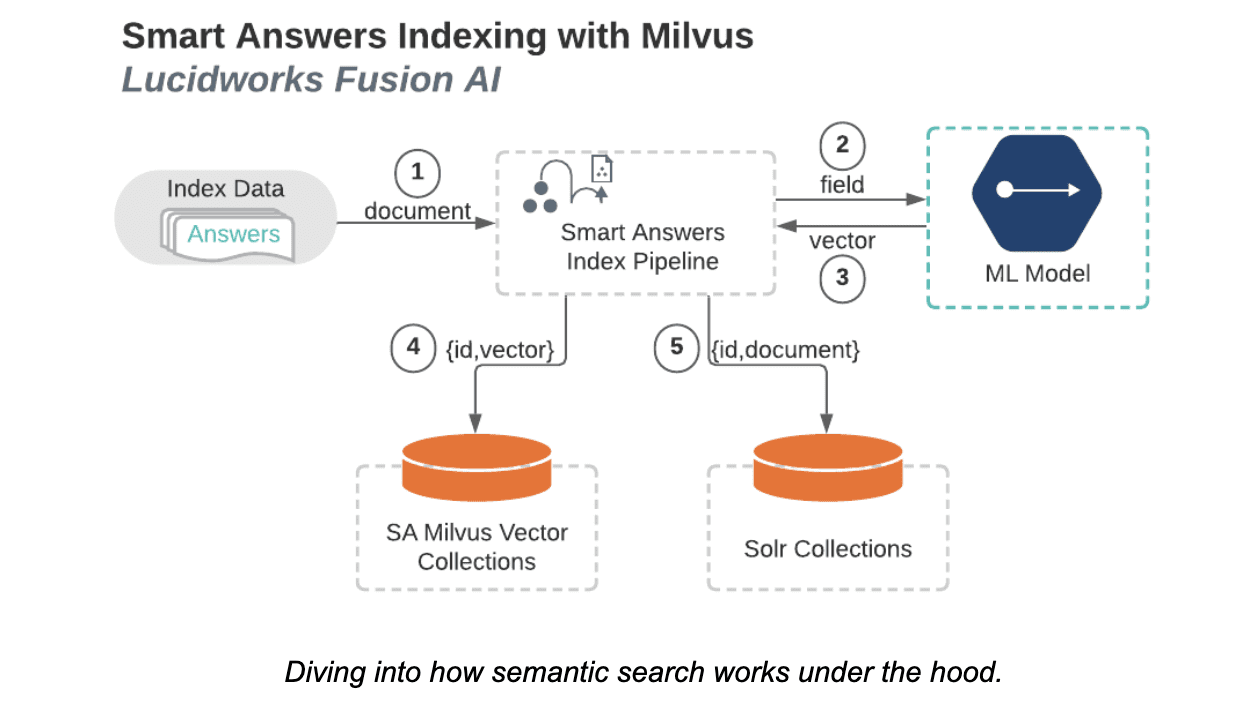 Milvusへのインデックス作成のための構造図
Milvusへのインデックス作成のための構造図
上の図に示すように、クエリの段階はインデックスの段階と同様に始まります。各クエリに対して
1.クエリはSmart Answersインデックスパイプラインに送られる。 2.クエリはMLモデルに送られる。 3.MLモデルは(クエリから暗号化された)数値ベクトルを返します。ここでも、モデルの種類によってベクトルのサイズが決まります。 4.ベクトルはMilvusに送られ、Milvusは指定されたMilvusコレクションの中で、提供されたベクトルに最もマッチするベクトルを決定する。 5.Milvusは、ステップ4で決定されたベクトルに対応する一意のIDと距離のリストを返す。 6.これらのIDと距離を含むクエリがSolrに送信される。 7.Solrは、それらのIDに関連する文書の順序付きリストを返す。
スケールテスト
我々のセマンティック検索フローが顧客に要求する効率で実行されていることを証明するため、Google Cloud Platform上でGatlingスクリプトを使い、MLモデルの8つのレプリカ、クエリサービスの8つのレプリカ、Milvusのシングルインスタンスを持つFusionクラスタを使ってスケールテストを実行した。テストはMilvusのFLATインデックスとHNSWインデックスを用いて実行された。FLATインデックスは100%の再現率を持つが、データセットが小さい場合を除き、効率は低い。HNSW (Hierarchical Small World Graph) インデックスは依然として高品質な結果を示し、より大きなデータセットでは性能が向上した。
それでは、我々が最近実行した例からいくつかの数字を見てみよう:
小さなデータセットにおけるMilvus FLATとHNSWインデックスのパフォーマンス](https://assets.zilliz.com/Lucidworks_2_3162113560.png)
中規模データセットにおけるMilvus FLATとHNSWインデックスのパフォーマンス](https://assets.zilliz.com/Lucidworks_3_3dc17f0ed8.png)
大規模データセットにおけるMilvus FLATとHNSWインデックスの性能](https://assets.zilliz.com/Lucidworks_4_8a6edd2f59.png)
はじめに
Smart Answers](https://lucidworks.com/products/smart-answers/) パイプラインは使いやすく設計されています。Lucidworksには、導入が簡単な事前トレーニング済みモデルがあり、一般的に良い結果が得られますが、事前トレーニング済みモデルと並行して独自のモデルをトレーニングすることで、最良の結果が得られます。このような取り組みを検索ツールに導入することで、より効果的で楽しい検索結果を得ることができます。
このブログは https://lucidworks.com/post/how-to-build-fast-semantic-search/?utm_campaign=Oktopost-Blog+Posts&utm_medium=organic_social&utm_source=linkedin から転載しました。
読み続けて

Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Notion solved vector search scaling in two years. The next bottleneck — offline context engineering, unified data, and the real-time/offline gap — is harder.

Optimizing Embedding Model Selection with TDA Clustering: A Strategic Guide for Vector Databases
Discover how Topological Data Analysis (TDA) reveals hidden embedding model weaknesses and helps optimize vector database performance.

DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Explore DeepSeek-VL2, the open-source MoE vision-language model. Discover its architecture, efficient training pipeline, and top-tier performance.