




Massive Text Embedding Benchmark (MTEB)
Massive Text Embedding Benchmark (MTEB)
Gli embedding di testo vengono spesso testati su un numero ridotto di dataset provenienti da un solo task, il che non mostra quanto funzionino bene per altri task. Non è chiaro se i migliori embedding per la Similarità Testuale Semantica (STS) funzionino altrettanto bene per task come il clustering o il reranking. Questo rende difficile vedere i progressi nel settore, poiché nuovi modelli ed embedding vengono comunemente valutati e costantemente proposti senza test coerenti.
Per affrontare questo problema, i ricercatori hanno creato il Massive Text Embedding Benchmark (MTEB). MTEB copre 8 task di embedding su 58 dataset in 112 lingue. I ricercatori hanno testato 8 task di embedding che coprono 33 modelli su MTEB, rendendolo finora il benchmark più completo per gli embedding di testo.
Hanno scoperto che nessun singolo metodo di embedding è il migliore per tutti i task. Questo suggerisce che un metodo universale di embedding del testo che funzioni meglio per tutti i task di embedding non sia ancora stato sviluppato, anche quando viene scalato. Questo evidenzia anche l'importanza di fare la dovuta diligenza per scegliere i modelli di embedding più adatti ai propri requisiti.
MTEB include codice open-source, una leaderboard pubblica e una divertente MTEB Arena per votare su aspetti come quali modelli recuperano il documento migliore, eseguono un clustering migliore ecc., entrambe sul sito web di Hugging Face. Questo benchmark aiuterà la comunità a testare nuovi metodi in modo coerente e a monitorare i miglioramenti nella tecnologia degli embedding di testo.
Contesto e motivazione
Gli embedding di testo sono diventati una parte fondamentale di molti task di Natural Language Processing (NLP). Questi embedding trasformano parole, frasi o documenti in rappresentazioni numeriche che ne catturano il significato. Sono usati in varie applicazioni come la traduzione automatica, il riconoscimento di entità nominate, il question answering, l'analisi del sentiment e la summarization.
Nel corso degli anni, i ricercatori hanno creato molti dataset e benchmark per testare questi embedding. Alcuni di quelli più noti includono SemEval, GLUE, SuperGLUE, Big-Bench, WordSim353, e SimLex-999. Questi in genere si concentrano sulla valutazione degli embedding di parole standard e contestuali.
Tuttavia, ci sono ancora alcune lacune nel modo in cui gli embedding di testo vengono valutati:
Pochi benchmark coprono sia embedding di parole sia embedding di frasi.
Molte valutazioni si concentrano su task NLP specifici, non su quanto bene gli embedding catturino il significato complessivo del testo.
I benchmark esistenti spesso non considerano come gli embedding potrebbero essere usati in applicazioni del mondo reale.
C'è bisogno di un benchmark completo, che possa valutare un'ampia gamma di task di comprensione del testo. Questo benchmark dovrebbe essere utile sia per i ricercatori NLP sia per le persone che lavorano su applicazioni pratiche. Il Massive Text Embedding Benchmark (MTEB) mira a colmare questa lacuna.
Embedding di testo
Un embedding di testo è un modo per rappresentare il testo come un elenco di numeri. Questi numeri possono rappresentare una singola parola, una frase o persino un intero documento. L'elenco è solitamente lungo centinaia di numeri.
Gli embedding testuali sono usati in molti compiti di NLP. Per le parole, sono usati in cose come il controllo ortografico e l'individuazione di relazioni tra parole. Per testi più lunghi, sono usati in compiti come capire il sentiment di un brano scritto o generare nuovo testo.
Esistono molti modi diversi per creare embedding testuali. Alcuni metodi popolari includono:
Metodi basati su modelli linguistici come ULMFit, GPT, BERT e PEGASUS
Metodi addestrati su vari compiti di NLP, come ELMo
Metodi basati sulle parole come word2vec e GloVe, che sono spesso usati nella ricerca sulla visione artificiale
I ricercatori hanno creato molti embedding diversi: ce ne sono almeno 165 da confrontare. Hanno anche realizzato 15 strumenti diversi (come alberi decisionali e Random Forest) per aiutare a comprendere i punti di forza e di debolezza di questi embedding.
Tuttavia, non esiste un modo standard per confrontare tutti questi diversi embedding. Questo è un problema che il Massive Text Embedding Benchmark (MTEB) cerca di risolvere.
Progettazione e implementazione del Massive Text Embedding Benchmark
MTEB è stato progettato tenendo presenti diversi obiettivi importanti:
Diversità: MTEB testa i modelli di embedding su molti compiti diversi. Include 8 diversi tipi di compiti, con fino a 15 dataset per ciascuno. Dei 58 dataset totali, 10 funzionano con più lingue, coprendo 112 lingue in totale. Il benchmark testa sia testi brevi (a livello di frase) sia lunghi (a livello di paragrafo) per vedere come i modelli si comportano con lunghezze di testo diverse.
Semplicità: MTEB è facile da usare. Qualsiasi modello che possa prendere un elenco di testi e produrre un elenco di rappresentazioni numeriche (vettori) può essere testato. Questo significa che molti tipi diversi di modelli possono essere confrontati.
Estensibilità: È facile aggiungere nuovi dataset a MTEB. Per i compiti esistenti, devi solo aggiungere un file che descriva il compito e indichi dove sono archiviati i dati su Hugging Face. Aggiungere nuovi tipi di compiti richiede un po' più di lavoro, ma MTEB accoglie i contributi della community per aiutarlo a crescere.
Riproducibilità: MTEB rende facile ripetere gli esperimenti. Tiene traccia delle diverse versioni dei dataset e del software. I risultati nell'articolo MTEB sono disponibili come file JSON, così chiunque può verificarli o usarli.
Queste caratteristiche rendono MTEB uno strumento completo e flessibile per valutare i modelli di embedding testuali su compiti che coprono un'ampia gamma complessiva di compiti e lingue.
Compiti e valutazione nel Massive Text Embedding Benchmark
Massive Text Embedding Benchmark include 8 diversi tipi di compiti per testare i modelli di embedding. Ecco una semplice panoramica di ciascun compito:
Bitext Mining: Trovare frasi corrispondenti in due lingue diverse. La misura principale è il punteggio F1.
Classificazione: Usare gli embedding per ordinare i testi in categorie. La misura principale è l'accuratezza.
Clustering: Raggruppare testi simili. La misura principale è la v-measure.
Classificazione di coppie: Decidere se due testi sono simili o meno. La misura principale è la precisione media.
Reranking: Ordinare un elenco di testi in base a quanto corrispondono a una query. La misura principale è la MAP (Mean Average Precision).
Retrieval: Trovare documenti rilevanti per una determinata query. La misura principale è nDCG@10.
Somiglianza testuale semantica (STS): Misurare quanto sono simili due frasi. La misura principale è la correlazione di Spearman.
Riassunto: Valutare riassunti generati automaticamente rispetto a quelli scritti da esseri umani. La misura principale è anche la correlazione di Spearman.
Per ogni attività, MTEB utilizza il modello di embedding per trasformare i testi in embedding vettoriali. Poi utilizza metodi come la similarità coseno o la regressione logistica per svolgere l'attività e calcolare i punteggi.
MTEB include molti dataset per ciascuna attività, coprendo lingue e lunghezze di testo diverse. Questo aiuta a testare quanto bene i modelli di embedding funzionano in varie situazioni.
Utilizzando queste attività e questi dataset diversificati, il Massive Text Embedding Benchmark offre un modo completo per valutare e confrontare diversi modelli di embedding del testo.
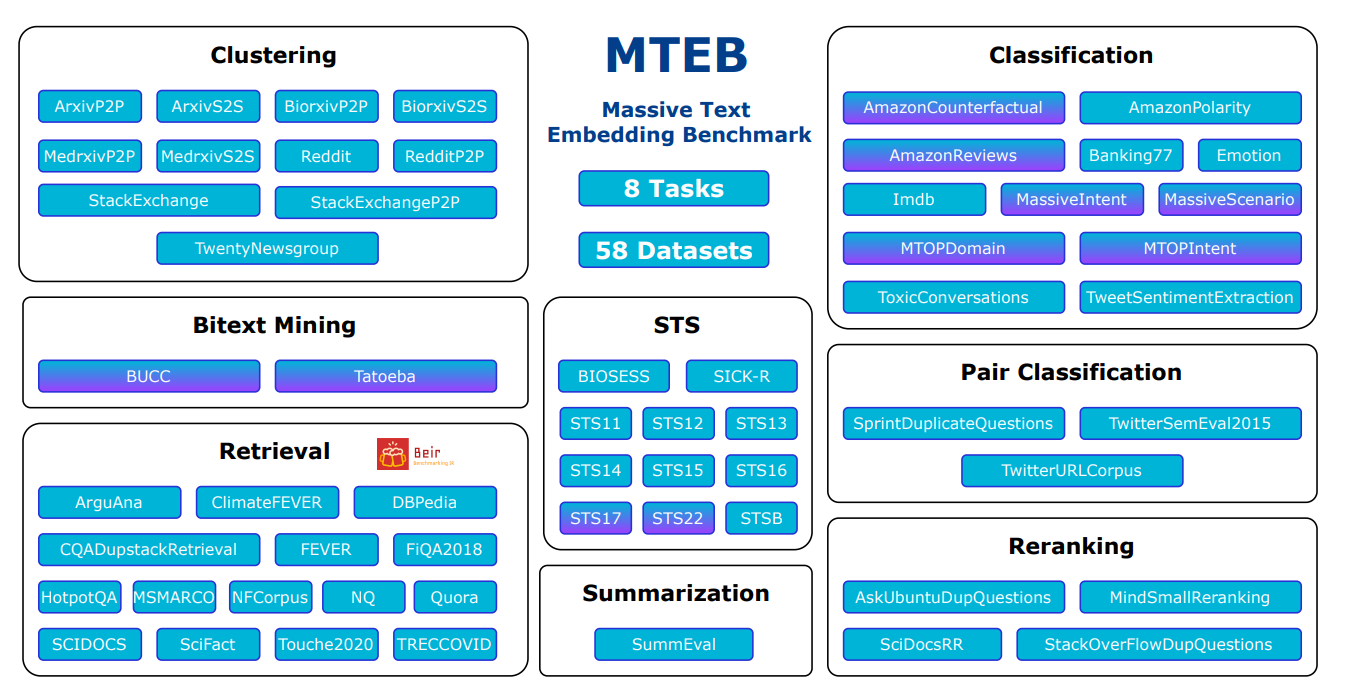 Panoramica delle attività e dei dataset in MTEB
Panoramica delle attività e dei dataset in MTEB
Fonte: MTEB: Massive Text Embedding Benchmark
Dataset nel Massive Text Embedding Benchmark
Il Massive Text Embedding Benchmark utilizza molti dataset diversi per testare particolari metodi e modelli di embedding del testo. Questi dataset sono raggruppati in tre tipi principali in base alla lunghezza dei testi confrontati:
Frase a frase (S2S): Questo avviene quando una frase viene confrontata con un'altra. Ad esempio, nelle attività di similarità testuale semantica, l'obiettivo è capire quanto siano simili due frasi.
Paragrafo a paragrafo (P2P): Questo comporta il confronto di porzioni di testo più lunghe. MTEB non stabilisce un limite sulla loro lunghezza, lasciando ai modelli il compito di gestire testi più lunghi se necessario. Alcune attività, come il clustering, vengono svolte sia come S2S (confrontando solo i titoli) sia come P2P (confrontando titoli e contenuti).
Frase a paragrafo (S2P): Questo viene utilizzato in alcune attività di retrieval, in cui una query breve (frase) viene confrontata con documenti più lunghi (paragrafi).
MTEB include 56 dataset diversi. Alcuni di questi dataset sono simili tra loro:
Alcuni utilizzano gli stessi dati testuali sottostanti (come ClimateFEVER e FEVER).
I dataset per attività simili (come diverse versioni di CQADupstack o STS) tendono a essere simili.
Le versioni S2S e P2P dello stesso dataset sono spesso simili.
I dataset su argomenti simili (come gli articoli scientifici) tendono a essere simili, anche se sono destinati ad attività diverse.
Utilizzando una gamma così ampia di dataset, MTEB può testare quanto bene i modelli di embedding funzionano con diversi tipi di testo e diverse attività. Questo aiuta a fornire un quadro più completo dei punti di forza e di debolezza di ciascun modello.
Modelli nel benchmarking iniziale del Massive Text Embedding Benchmark
Per il primo ciclo di test con MTEB, i ricercatori hanno esaminato modelli che affermano di essere i migliori e quelli popolari su Hugging Face Hub. Questo ha significato testare molti modelli transformer. Hanno raggruppato i modelli in tre tipi per aiutare le persone a scegliere quello migliore per le loro esigenze:
Modelli più veloci: Modelli come Glove sono molto veloci, ma non comprendono bene il contesto. Questo significa che complessivamente non ottengono punteggi così alti su MTEB.
Modelli bilanciati: Modelli come all-mpnet-base-v2 o all-MiniLM-L6-v2 sono un po' più lenti dei più veloci, ma offrono prestazioni molto migliori. Offrono un buon equilibrio tra velocità e qualità.
Modelli con le prestazioni più elevate: I grandi modelli con miliardi di parametri, come ST5-XXL, GTR-XXL o SGPT-5.8B-msmarco, ottengono i migliori risultati su MTEB. Ma possono essere più lenti e richiedere più spazio di archiviazione. Ad esempio, SGPT-5.8B-msmarco crea embedding con 4096 numeri, che occupano più spazio.
È importante notare che le prestazioni di un modello possono cambiare molto a seconda dell'attività e del dataset specifici. I ricercatori suggeriscono di consultare la classifica MTEB per vedere quale modello potrebbe funzionare meglio per una singola attività e per le tue esigenze specifiche.
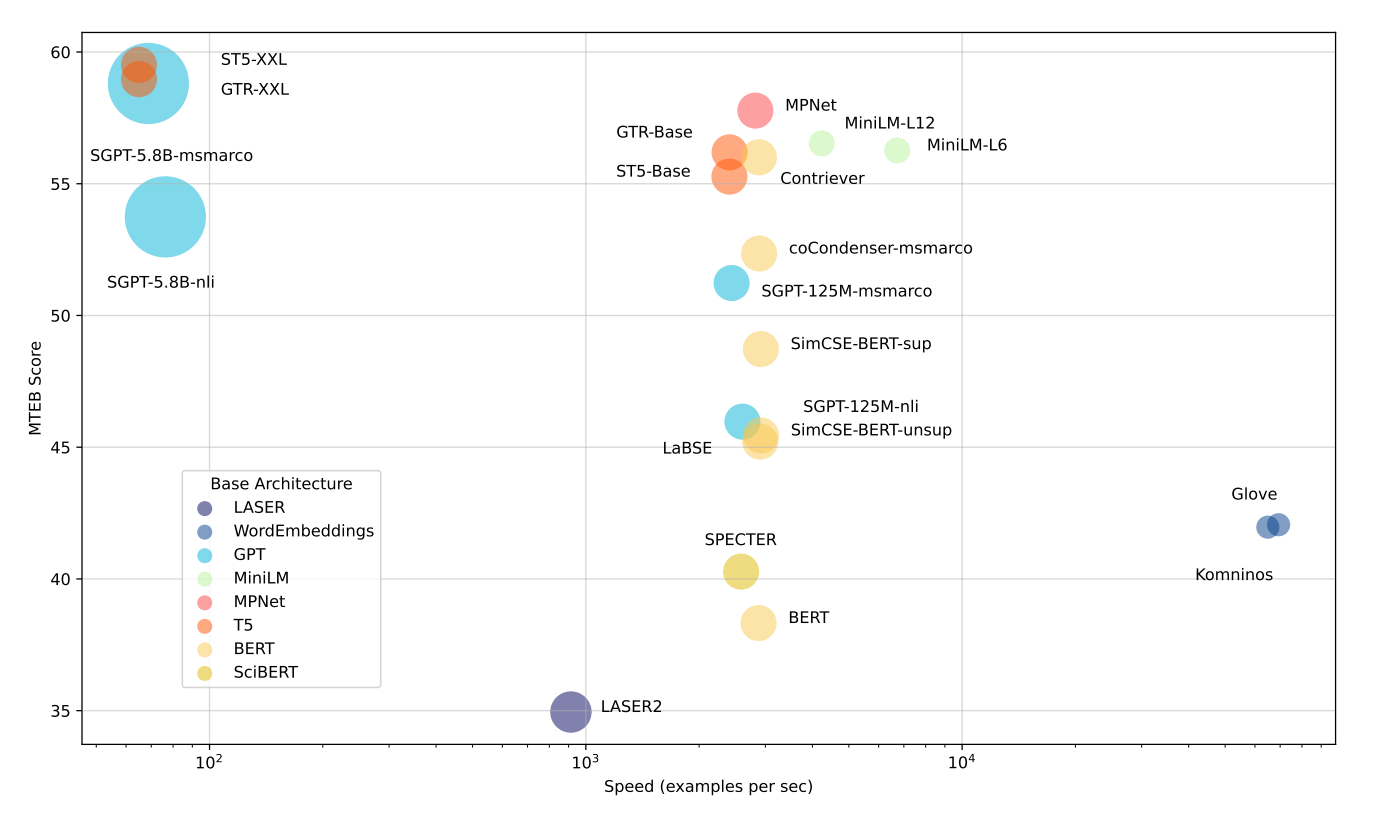 Risultati dei benchmark del test iniziale
Risultati dei benchmark del test iniziale
Fonte: MTEB: Massive Text Embedding Benchmark
Questo approccio ai test offre un quadro chiaro dei compromessi tra velocità e prestazioni nei diversi modelli di embedding, aiutando gli utenti a prendere decisioni informate in base ai loro requisiti specifici. Se vuoi provarlo tu stesso, c'è un ottimo blog su Huggigng Face che ti guida nel benchmarking di qualsiasi modello che produca embedding vettoriali.
Quando usare il Massive Text Embedding Benchmark
MTEB è uno strumento per testare quanto bene funzionano i modelli di embedding testuale su molte attività diverse. È utile in diverse situazioni:
Testare il tuo modello: Se hai creato un nuovo modello di embedding, puoi usare MTEB per vedere come si confronta con altri modelli. Puoi aggiungere i tuoi risultati alla classifica pubblica, il che ti aiuta a vedere come il tuo modello si posiziona rispetto agli altri.
Scegliere il modello giusto: Modelli diversi funzionano meglio per attività diverse. La classifica di MTEB mostra come i modelli si comportano su varie attività, aiutandoti a scegliere il modello migliore per le tue esigenze specifiche.
Aiutare a migliorare MTEB: MTEB è open source e quindi aperto al contributo di chiunque. Se hai creato una nuova attività, un dataset, un modo di misurare le prestazioni o un modello, puoi aggiungerlo a MTEB. Questo aiuta a rendere il benchmark ancora migliore.
Ricerca: Se stai studiando gli embedding testuali, MTEB ti offre un modo approfondito per testare i modelli. Può mostrarti cosa sono in grado di fare i migliori modelli attuali e dove c'è margine di miglioramento.
Fornendo un modo standard per testare i modelli su molte attività, MTEB aiuta ricercatori e sviluppatori a comprendere e migliorare la tecnologia degli embedding testuali. È uno strumento prezioso per chiunque lavori con gli embedding testuali o li studi.
Come usare la classifica del Massive Text Embedding Benchmark
Prima di tutto, non lasciarti fuorviare dai punteggi MTEB!
MTEB è uno strumento utile, ma è importante comprenderne i limiti. Sebbene mostri dei punteggi, non ti dice se le differenze tra i punteggi siano significative. Molti modelli migliori hanno punteggi medi molto vicini, che derivano da molte attività diverse, ma non ci sono informazioni su quanto varino questi punteggi. Il modello in cima potrebbe sembrare migliore, ma la differenza potrebbe non essere importante. Gli utenti possono ottenere i risultati grezzi per verificarlo autonomamente. Alcuni ricercatori hanno scoperto che diversi modelli migliori in determinati benchmark linguistici sono in realtà ugualmente validi, statisticamente parlando. Invece di limitarsi a guardare i punteggi medi, è meglio concentrarsi su come i modelli si comportano in attività simili al caso d'uso previsto. Questo potrebbe fornire maggiori indicazioni su come un modello funzionerà per un'applicazione specifica rispetto al punteggio complessivo. Non è necessario studiare i dataset in dettaglio, ma è utile sapere che tipo di testo contengono. Queste informazioni sono solitamente disponibili dalla descrizione del dataset e da una rapida occhiata ad alcuni esempi. Il Massive Text Embedding Benchmark è uno strumento utile, ma non è perfetto. È importante riflettere criticamente sui risultati e su come si applicano a esigenze specifiche. Piuttosto che scegliere semplicemente il modello con il punteggio complessivo più alto, è meglio approfondire per trovare il modello migliore per l'attività in questione.
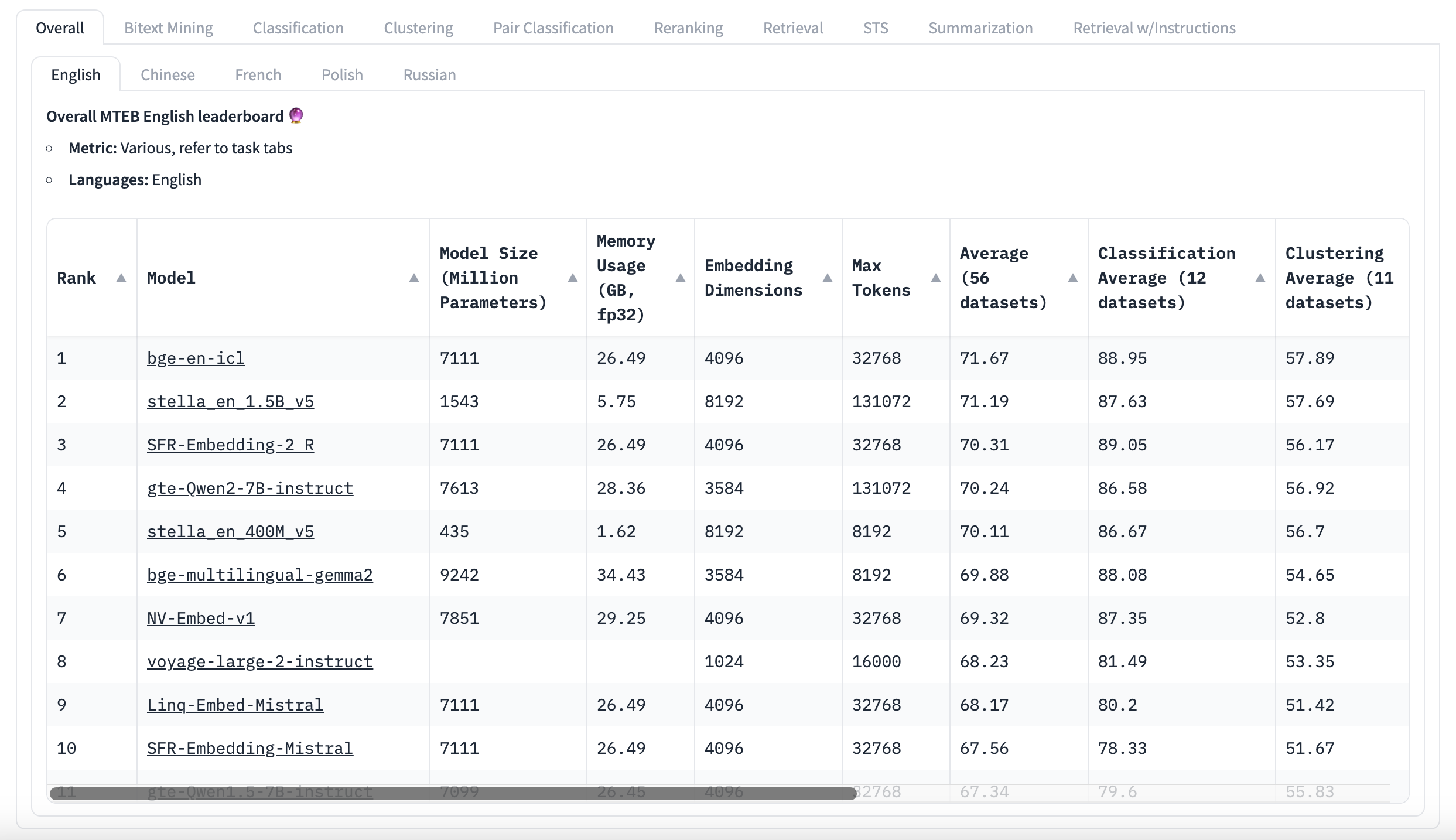 MTEB Leaderboard English
MTEB Leaderboard English
Ricorda di considerare le esigenze della tua applicazione
Non esiste un modello valido per ogni attività. Ecco perché esiste il Massive Text Embedding Benchmark: per aiutarti a scegliere il modello giusto per le tue esigenze specifiche. Quando guardi la classifica del Massive Text Embedding Benchmark, è importante pensare a ciò che richiede la tua applicazione. Ecco alcune cose da considerare:
Lingua: Il modello supporta la lingua con cui stai lavorando?
Vocabolario specializzato: Se stai lavorando con testi finanziari o legali, avrai bisogno di un modello che comprenda termini specifici del settore.
Dimensione del modello: Pensa a dove eseguirai il modello. Dovrà stare su un laptop?
Uso della memoria: Quanta memoria del computer puoi destinare al modello?
Lunghezza massima dell'input: Quanto sono lunghi i testi con cui lavorerai?
Una volta che sai cosa è importante per il tuo compito, puoi ordinare vari modelli nella leaderboard MTEB in base a queste caratteristiche. Questo rende più facile trovare un modello che non solo abbia buone prestazioni, ma soddisfi anche i tuoi requisiti pratici.
Considerando sia le prestazioni sia le esigenze pratiche, puoi scegliere un modello che funzioni al meglio per la tua situazione specifica.
La risorsa Zilliz AI Model
Ora che hai scelto il tuo modello di text embedding dal Massive Text Embedding Benchmark, mettiamolo al lavoro per creare text embedding da archiviare e recuperare in Milvus open source o Zilliz Cloud. Sul sito web di Zilliz, puoi trovare la pagina AI Models che elenca alcuni dei modelli multimodali e di text embedding più popolari.
 Pagina Zilliz AI Model
Pagina Zilliz AI Model
Una volta selezionato un modello in questa pagina, puoi vedere che ci sono alcune istruzioni dettagliate su come creare gli embedding vettoriali utilizzando i vari SDK, PyMilvus, e altro ancora.
Conclusione
Il Massive Text Embedding Benchmark (MTEB) rappresenta un importante passo avanti nella valutazione dei modelli di text embedding. Affronta i limiti dei benchmark precedenti coprendo un'ampia gamma di attività, lingue e lunghezze di testo. Il design di MTEB si concentra su diversità, semplicità, estensibilità e riproducibilità, rendendolo uno strumento prezioso sia per i ricercatori sia per i professionisti nel campo del Natural Language Processing.
L'approccio di benchmark più completo di MTEB, che testa i modelli su 8 attività diverse e 58 dataset, fornisce un quadro più completo delle capacità di un modello rispetto ai benchmark precedenti. Rivela che nessun singolo metodo di embedding eccelle in tutte le attività, evidenziando l'importanza di scegliere il modello giusto per applicazioni specifiche.
Quando si utilizza MTEB, è fondamentale guardare oltre i punteggi complessivi e considerare le esigenze specifiche della tua applicazione. Fattori come supporto linguistico, vocabolario specializzato, dimensione del modello, uso della memoria e lunghezza massima dell'input dovrebbero tutti svolgere un ruolo nel processo decisionale.
Sebbene MTEB sia uno strumento potente, è importante usarlo in modo critico. Le differenze nei punteggi tra i modelli migliori potrebbero non essere sempre statisticamente significative, e le prestazioni possono variare notevolmente a seconda dell'attività e del dataset specifici.
In quanto progetto open-source, MTEB accoglie contributi dalla community, permettendogli di crescere e adattarsi alle esigenze in evoluzione del settore. Questo approccio collaborativo garantisce che MTEB continuerà a essere una risorsa rilevante e preziosa per valutare e migliorare la tecnologia di text embedding.
Fornendo un modo standardizzato per valutare i modelli di text embedding su un'ampia gamma di attività e lingue, MTEB sta aiutando a promuovere il progresso nel settore, portando in ultima analisi a modelli di text embedding migliori e più versatili per varie applicazioni.
Riferimenti
Muennighoff, Niklas and Tazi, Nouamane and Magne, Lo{\"\i}c and Reimers, Nils. "MTEB: Massive Text Embedding Benchmark" arXiv 2022
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff. "C-Pack: Packaged Resources To Advance General Chinese Embedding" arXiv 2023
Michael Günther, Jackmin Ong, Isabelle Mohr, Alaeddine Abdessalem, Tanguy Abel, Mohammad Kalim Akram, Susana Guzman, Georgios Mastrapas, Saba Sturua, Bo Wang, Maximilian Werk, Nan Wang, Han Xiao. "Jina Embeddings 2: 8192-Token General-Purpose Text Embeddings for Long Documents" arXiv 2023
Silvan Wehrli, Bert Arnrich, Christopher Irrgang. "Benchmark di clustering di embedding di testo in tedesco" arXiv 2024
Orion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Benjamin Van Durme, Dawn Lawrie, Luca Soldaini. "FollowIR: valutare e insegnare ai modelli di recupero delle informazioni a seguire istruzioni" arXiv 2024
Dawei Zhu, Liang Wang, Nan Yang, Yifan Song, Wenhao Wu, Furu Wei, Sujian Li. "LongEmbed: estendere i modelli di embedding per il recupero in contesti lunghi" arXiv 2024
Kenneth Enevoldsen, Márton Kardos, Niklas Muennighoff, Kristoffer Laigaard Nielbo. "I benchmark scandinavi di embedding: valutazione completa dell’embedding di testo multilingue e monolingue" arXiv 2024
- Contesto e motivazione
- Embedding di testo
- Progettazione e implementazione del Massive Text Embedding Benchmark
- Quando usare il Massive Text Embedding Benchmark
- Come usare la classifica del Massive Text Embedding Benchmark
- La risorsa Zilliz AI Model
- Conclusione
- Riferimenti
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente