




Change Data Capture: mantenere i tuoi sistemi sincronizzati in tempo reale

Change Data Capture: mantenere i tuoi sistemi sincronizzati in tempo reale
Che cos’è il Change Data Capture (CDC)?
Change Data Capture (CDC) è un metodo utilizzato per identificare e tracciare le modifiche nei dati nel momento in cui avvengono all’interno di un database. Invece di monitorare manualmente o interrogare ripetutamente per individuare aggiornamenti, il CDC acquisisce automaticamente inserimenti, aggiornamenti ed eliminazioni in tempo reale o quasi in tempo reale. Le tecniche di CDC, come i log delle transazioni e i trigger del database, aiutano le organizzazioni a mantenere la coerenza e l’integrità dei dati tra vari sistemi e ambienti di distribuzione. Questo garantisce che i sistemi e le applicazioni a valle—che alimentino analisi tradizionali o modelli di IA basati su vettori—dispongano sempre dei dati più recenti.
Ad esempio, in un database vettoriale, il CDC traccia gli aggiornamenti in tempo reale degli embedding per attività come la ricerca semantica o il rilevamento delle frodi, in cui i dati più recenti sono necessari per risultati accurati.
Evoluzione dell’integrazione dei dati: il ruolo del CDC
In passato, l’elaborazione batch era l’approccio principale per l’integrazione dei dati. Tuttavia, causava ritardi poiché gli aggiornamenti dei dati venivano elaborati in blocco a intervalli programmati, spesso ore o giorni dopo che le modifiche si erano verificate. Questa limitazione lo rendeva inadatto ad applicazioni come la ricerca semantica in tempo reale per chatbot basati sull’IA o sistemi di raccomandazione, che si affidano a database vettoriali per analizzare dati ad alta dimensionalità.
Il CDC risolve questo problema acquisendo le modifiche mentre avvengono e aggiornando i sistemi in tempo reale. Questa tecnica consente alle aziende di sincronizzare i propri database, alimentare dashboard in tempo reale e creare applicazioni reattive. L’ascesa del CDC ha coinciso con la crescita dei moderni sistemi distribuiti e delle architetture cloud-native, in cui la replica e l’integrazione tempestiva dei dati sono fondamentali. Invece di lavorare con dati obsoleti provenienti da aggiornamenti periodici, le organizzazioni possono ora acquisire e agire sulle modifiche nel momento in cui si verificano. Questo cambiamento ha reso il CDC un componente vitale delle moderne strategie dei dati, aiutando le aziende a rimanere reattive e competitive in tempo reale.
Come funziona il Change Data Capture?
Immagina di tracciare le interazioni di un cliente su una piattaforma di e-commerce. Ogni interazione, come navigare, aggiungere al carrello o acquistare, genera nuovi dati. Il CDC trasmette questi dati modificati a un database vettoriale come Milvus in tempo reale, dove le loro rappresentazioni vettoriali, note anche come embedding vettoriali, possono essere aggiornate per attività come raccomandazioni personalizzate o prevenzione delle frodi.
Scomponiamolo nei componenti e meccanismi chiave per capire come funziona il CDC.
Componenti chiave del CDC
Per rendere funzionale il CDC, diversi componenti lavorano insieme. Il diagramma seguente illustra il processo CDC.
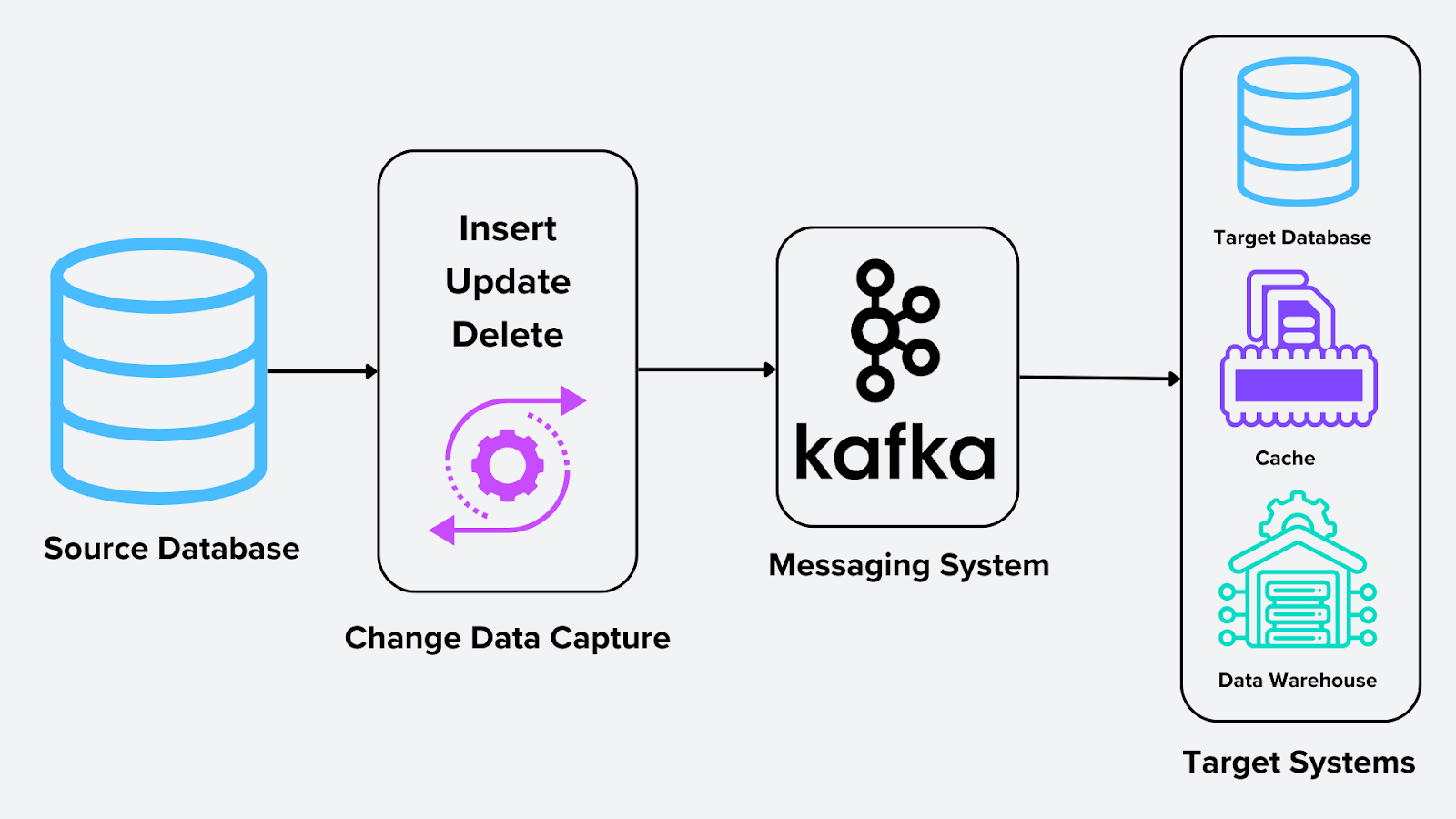 Figura- Processo di Change Data Capture .png
Figura- Processo di Change Data Capture .png
Figura: Processo di Change Data Capture
Origine: Il sistema in cui hanno origine le modifiche, che potrebbero essere database relazionali, sistemi NoSQL o database vettoriali. Nel caso di un database vettoriale come Milvus, l’origine potrebbe essere costituita da embedding generati da modelli di deep learning o modelli di riconoscimento delle immagini.
Motore CDC: Il processo centrale che acquisisce e formatta le modifiche. Per i database vettoriali, questo potrebbe significare aggiornare gli embedding archiviati in Milvus utilizzando strumenti come Milvus-CDC o Confluent Kafka Connect.
Sistema di messaggistica: Un sistema di messaggistica come Apache Kafka funge da spina dorsale per distribuire le modifiche in tempo reale. Agisce come intermediario che archivia e trasmette in streaming le modifiche acquisite a uno o più sistemi di destinazione. Ciò garantisce scalabilità e affidabilità nella pipeline di dati.
Sistemi di destinazione: Le destinazioni a cui vengono inviate le modifiche dei dati elaborati. Esempi includono:
Data warehouse (ad es., Snowflake, BigQuery) per l’analisi.
Cache per risposte alle query più rapide.
Database per la replica e la sincronizzazione tra sistemi.
Panoramica dei meccanismi CDC
Esistono tre modi principali in cui il CDC può acquisire le modifiche da un database. Negli esempi seguenti, useremo database SQL per dimostrarlo.
1. CDC basato su log
Questo metodo si basa sul log delle transazioni del database, una funzionalità a livello di sistema che registra tutte le modifiche del database (inserimenti, aggiornamenti ed eliminazioni). Il motore CDC legge questi log ed estrae le modifiche rilevanti per l’uso a valle. Nei database vettoriali, ciò potrebbe significare acquisire gli aggiornamenti ai vettori di embedding mentre vengono inseriti o modificati in Milvus.
Come funziona:
Il log delle transazioni è l’unica fonte di verità per tutte le operazioni del database.
Lo strumento CDC monitora il log e identifica e acquisisce continuamente le modifiche senza influire sul database primario.
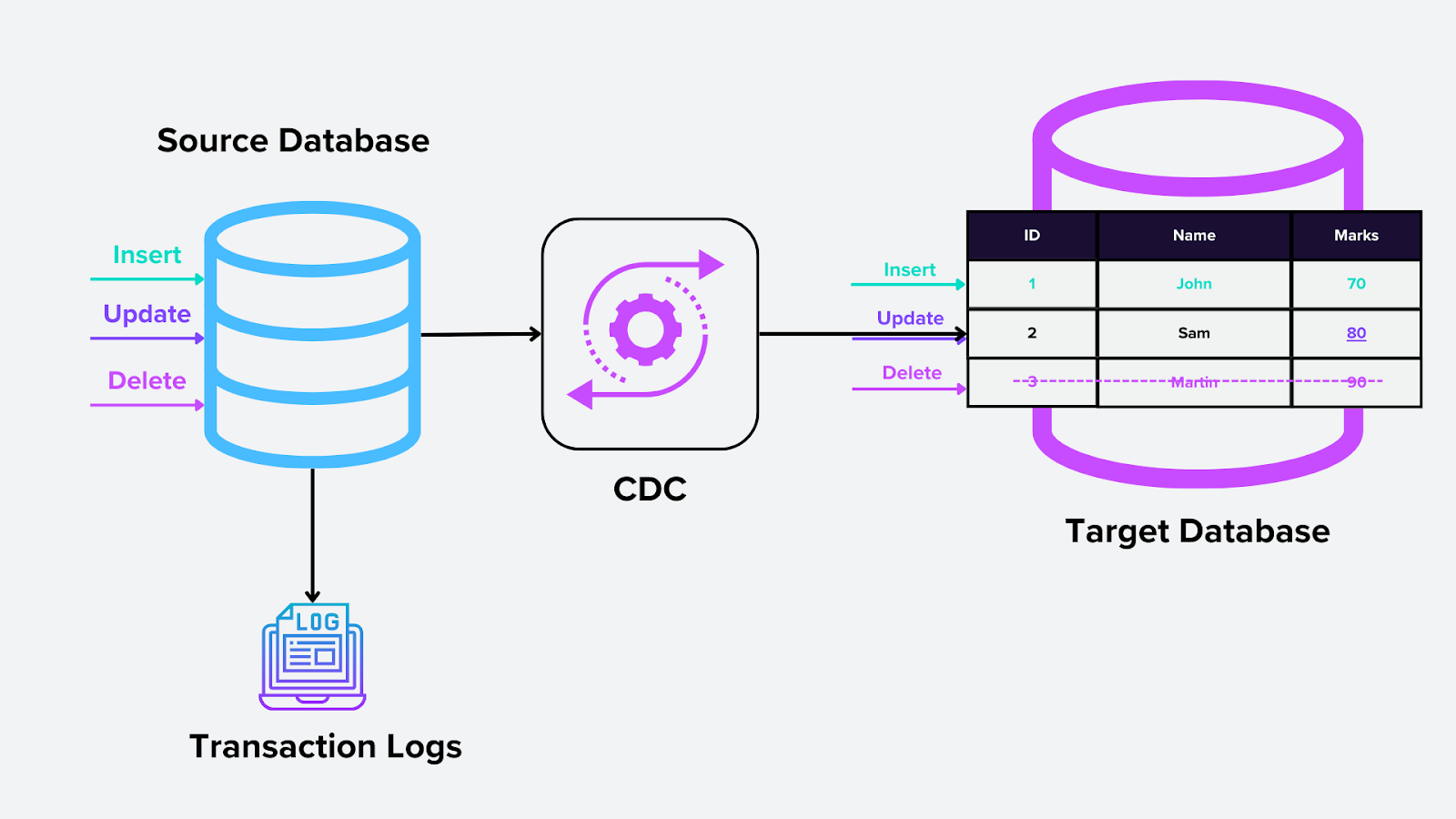 Figura- CDC basato su log.png
Figura- CDC basato su log.png
Figura: CDC basato su log
Pro:
Prestazioni elevate: Impatto minimo sul database, poiché legge direttamente dai log.
Completo: Acquisisce tutte le modifiche, inclusi trigger, stored procedure o altri metodi indiretti.
Scalabile: Funziona bene con sistemi ad alto volume di transazioni.
Contro:
Complessità: Richiede una profonda integrazione con la struttura interna dei log del database, che può variare in base al tipo di database.
Compatibilità: Non tutti i database espongono i log delle transazioni per l’accesso esterno.
2. CDC basato su trigger
Questo approccio utilizza trigger del database, ovvero logica personalizzata che viene eseguita automaticamente quando si verifica una modifica specifica (ad es., inserimento, aggiornamento o eliminazione) in una tabella. Ad esempio, i trigger potrebbero aggiornare automaticamente un indice vettoriale Milvus quando vengono aggiunti nuovi embedding.
Come funziona:
I trigger vengono aggiunti alle tabelle di interesse nel database.
Quando si verificano modifiche, il trigger le acquisisce e invia le informazioni a una posizione o tabella specificata per l’elaborazione a valle.
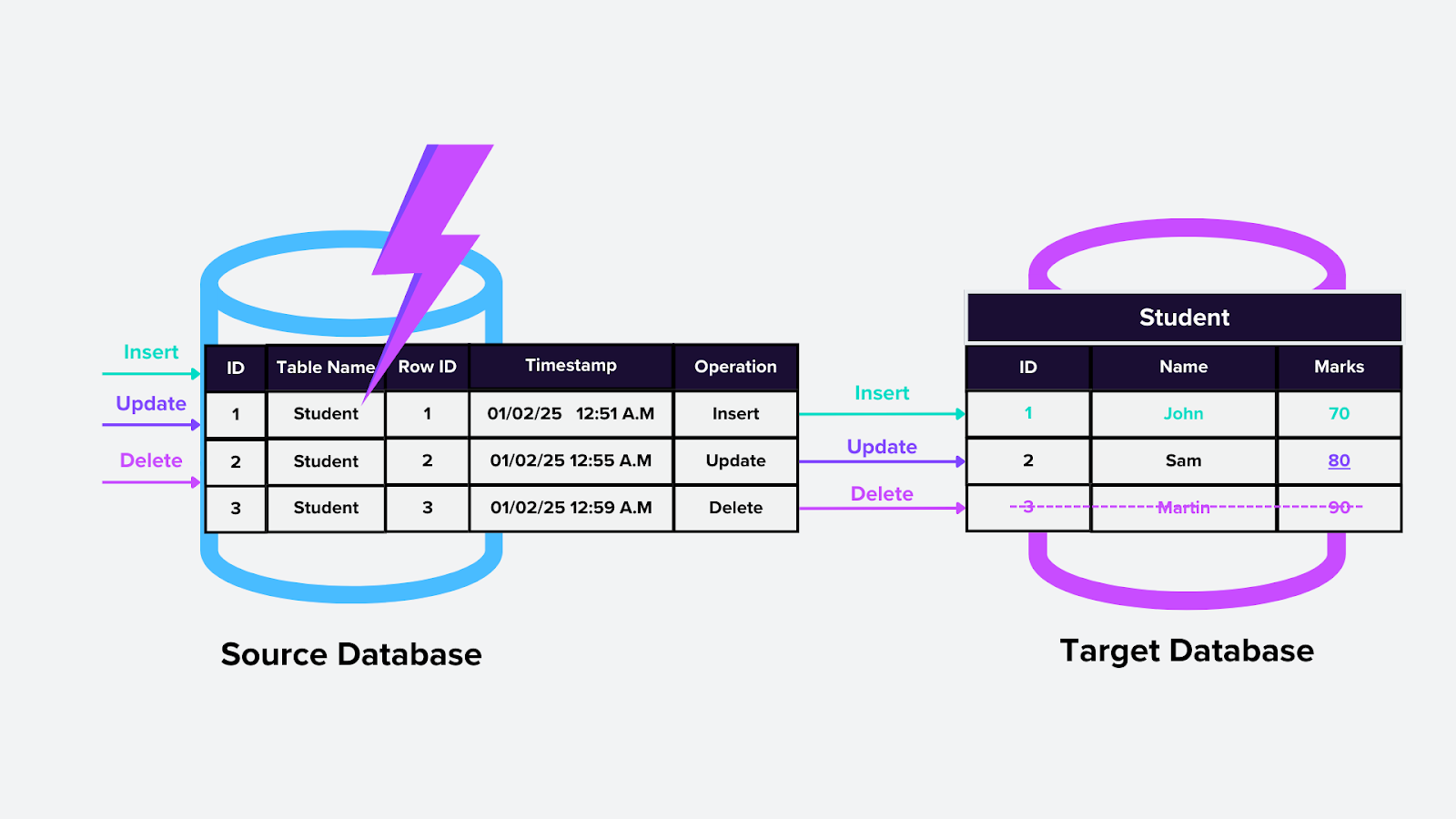 Figura- CDC basato su trigger.png
Figura- CDC basato su trigger.png
Figura: CDC basato su trigger
Pro:
Flessibile: Può essere personalizzato per tracciare le modifiche per casi d’uso specifici.
Ampiamente supportato: Quasi tutti i database relazionali supportano i trigger.
Contro:
Impatto sulle prestazioni: I trigger aggiungono overhead al database, soprattutto per transazioni ad alta frequenza.
Sfide di manutenzione: Gestire e aggiornare i trigger su più tabelle può diventare difficile.
Soggetto a errori: Trigger scritti male possono causare colli di bottiglia nelle prestazioni o non riuscire ad acquisire casi limite.
3. CDC basato su query
Questo metodo prevede l’esecuzione di query periodiche sul database per rilevare le modifiche. Le query in genere confrontano timestamp o versioni per identificare i record appena modificati, come il polling di un database vettoriale per embedding aggiornati.
Come funziona:
Il motore CDC esegue query a intervalli pianificati e identifica le modifiche in base a criteri specifici (ad es., data dell’ultima modifica).
Le modifiche rilevate vengono quindi inviate a valle.
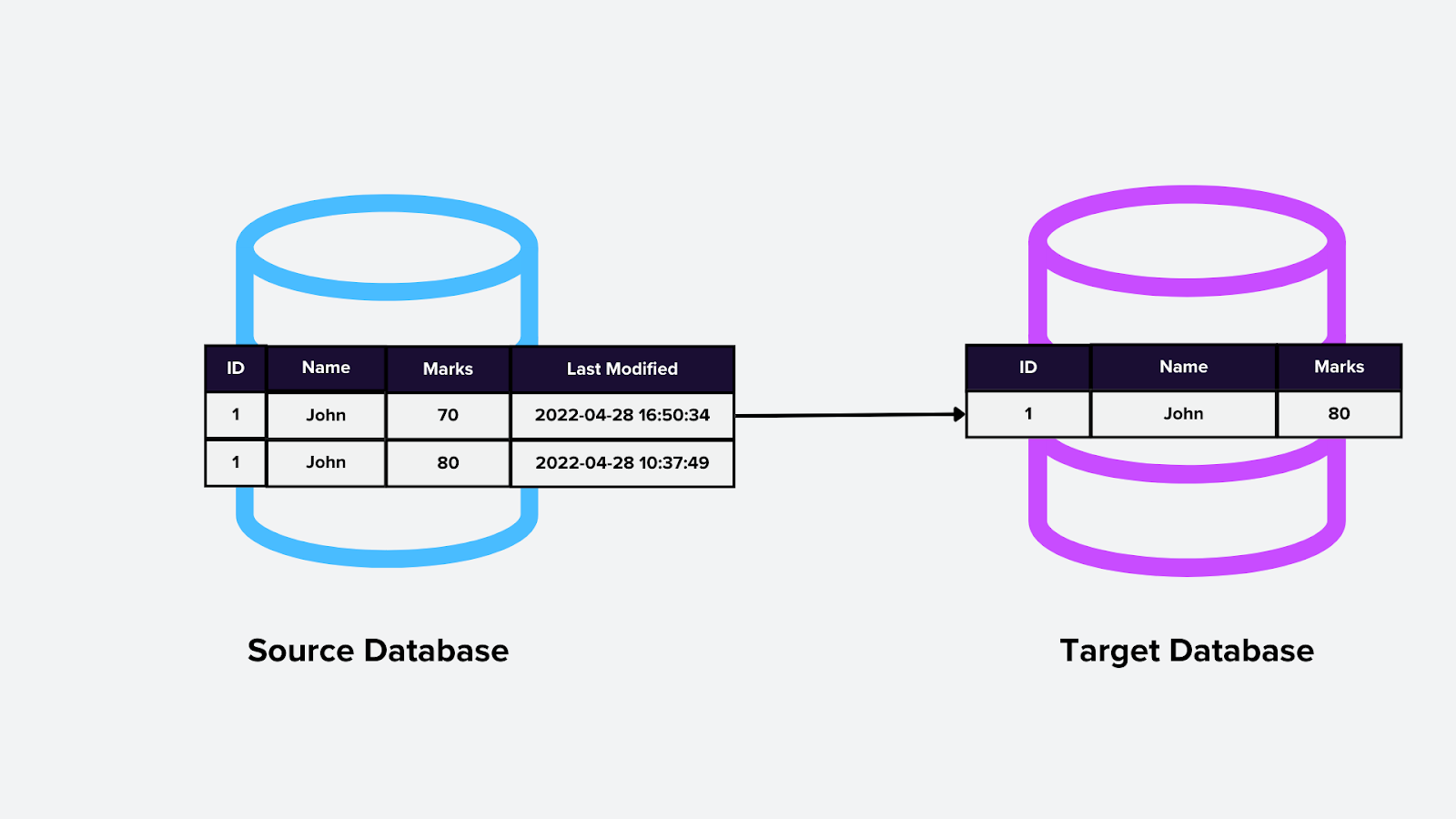 Figura- CDC basato su query.png
Figura- CDC basato su query.png
Figura: CDC basato su query
Pro:
Configurazione semplice: Non richiede integrazione o modifica profonda del database.
Agnostico rispetto al database: Funziona con quasi tutti i database che supportano le query.
Contro:
Latenza: Non è in tempo reale, poiché dipende dalla pianificazione delle query.
Sovraccarico delle prestazioni: Query frequenti possono mettere sotto stress il database.
Accuratezza limitata: Può perdere modifiche se le modifiche ai dati si verificano tra gli intervalli di query.
Confronto dei meccanismi CDC
La tabella seguente fornisce rapide informazioni su diversi meccanismi CDC e sui loro casi d'uso:
| Meccanismo | Tempo reale | Impatto sulle prestazioni | Facilità di configurazione | Idoneità al caso d'uso |
| Basato su log | Sì | Basso | Medio | Sistemi transazionali ad alto volume |
| Basato su trigger | Sì | Medio-Alto | Basso-Medio | Casi d'uso che richiedono logica di modifica personalizzata |
| Basato su query | No | Alto | Alto | Configurazioni semplici con modifiche a bassa frequenza |
Tabella: Confronto dei meccanismi CDC
CDC con Milvus: integrazione dei dati in tempo reale per database vettoriali
Milvus, un database vettoriale open-source (sviluppato dagli ingegneri di Zilliz) progettato per gestire dati non strutturati come embedding vettoriali provenienti da modelli di machine learning, dispone del proprio strumento CDC, Milvus-CDC, progettato esplicitamente per gestire attività di replica e sincronizzazione dei dati all'interno delle istanze Milvus. Milvus-CDC acquisisce modifiche incrementali ai dati per una sincronizzazione senza interruzioni tra istanze Milvus di origine e di destinazione. Ciò supporta attività come backup incrementale, disaster recovery e replica persistente dei dati, mantenendo al contempo l'integrità e la coerenza dei dati. Milvus-CDC include due componenti principali: il server HTTP, che gestisce le richieste degli utenti, esegue attività e mantiene i metadati delle attività, e Corelib, che gestisce la sincronizzazione delle attività, con un reader che estrae i dati dall'istanza Milvus di origine e dalla coda di messaggi e un writer che elabora queste modifiche e le invia all'istanza Milvus di destinazione.
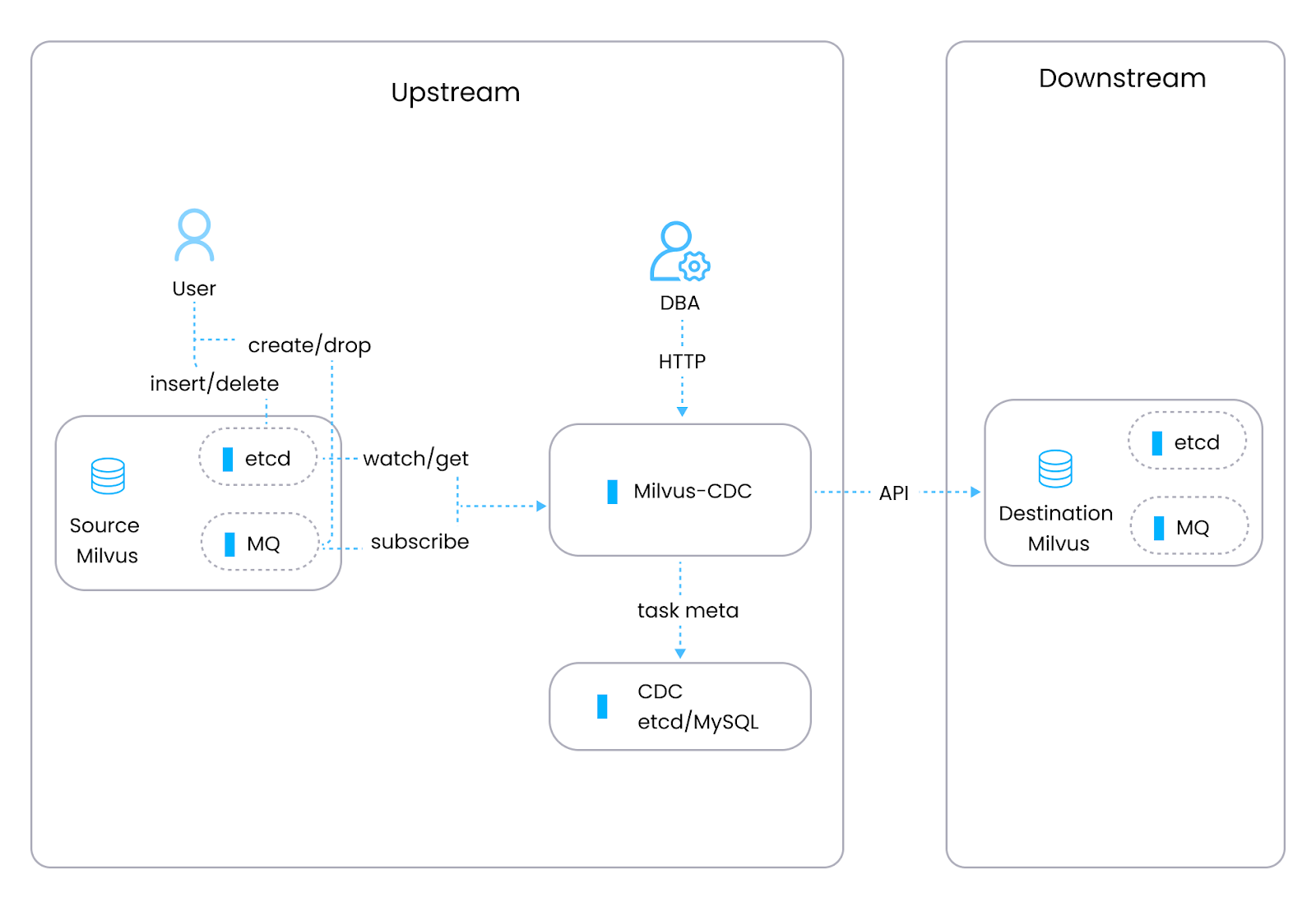 Figure- The Milvus-CDC architecture.png
Figure- The Milvus-CDC architecture.png
Figura: L'architettura di Milvus-CDC
Milvus-CDC: funzionalità principali
Sincronizzazione sequenziale dei dati: Garantisce che le modifiche siano applicate per preservare la coerenza dei dati tra le istanze Milvus.
Replica incrementale dei dati: Acquisisce e replica modifiche, come inserimenti ed eliminazioni, dall'istanza Milvus di origine a quella di destinazione.
Gestione delle attività: Gli utenti possono creare, gestire ed eliminare attività CDC utilizzando OpenAPI per integrarsi con vari workflow.
Integrazione con sistemi futuri: Sono previsti piani per espandere il supporto all'integrazione con sistemi di elaborazione stream.
CDC su Milvus utilizzando Kafka
Sebbene Milvus-CDC sia pensato esplicitamente per Milvus, integrare Milvus con Apache Kafka offre un altro approccio al CDC. Kafka è un hub centrale che acquisisce e propaga le modifiche ai dati da varie fonti utilizzando strumenti CDC come Kafka Sink connector. Queste modifiche vengono poi ingerite in Milvus per mantenere il database vettoriale aggiornato con gli embedding o i vettori di caratteristiche più recenti.
Per connettere Kafka con Milvus, puoi seguire questa guida: Connettere Kafka con Milvus.
Ruolo del CDC nei database distribuiti e nelle applicazioni cloud-native
Man mano che le organizzazioni adottano database distribuiti e applicazioni cloud-native per gestire workload su larga scala e distribuiti geograficamente, il CDC svolge un ruolo fondamentale nella sincronizzazione senza interruzioni dei dati tra questi sistemi complessi.
Sincronizzazione dei dati tra sistemi distribuiti: Nei database distribuiti, i dati sono spesso distribuiti su più nodi o regioni per migliorare prestazioni e scalabilità. Il CDC propaga immediatamente agli altri nodi le modifiche apportate su un nodo per mantenere la coerenza in tutto il sistema.
Condivisione dei dati in tempo reale nelle architetture cloud-native: Le applicazioni cloud-native spesso si basano su microservizi, ciascuno con il proprio storage dei dati. Il CDC consente a questi servizi di condividere aggiornamenti in tempo reale senza fare affidamento su pesanti processi batch per supportare architetture basate sugli eventi.
Replica per alta disponibilità e disaster recovery: I sistemi distribuiti spesso utilizzano la replica dei dati per l'alta disponibilità. Il CDC acquisisce e replica le modifiche su nodi di backup o sistemi di failover.
Ottimizzazione delle pipeline di dati: In ambienti in cui più sistemi dipendono da dataset condivisi, il CDC fornisce un meccanismo per alimentare modifiche in tempo reale in piattaforme di analytics, data lake o code di messaggi.
Applicazioni del CDC nei database vettoriali
Ecco casi d'uso specifici del CDC, soprattutto nelle applicazioni di IA che lavorano con un database vettoriale:
Ricerca semantica: Il CDC aggiorna il database vettoriale con gli embedding più recenti, consentendo ai sistemi di ricerca semantica di fornire risultati accurati e pertinenti. Ad esempio, un motore di ricerca aziendale può fornire risposte precise basate su aggiornamenti in tempo reale degli embedding di documenti o query.
Sistemi di raccomandazione: I database vettoriali utilizzano gli embedding per generare raccomandazioni personalizzate. Il CDC trasmette in streaming modifiche in tempo reale, come nuovi comportamenti degli utenti o aggiornamenti dei prodotti, così i sistemi di raccomandazione si adattano rapidamente all'evoluzione dei dati.
Rilevamento delle frodi: Nei sistemi finanziari, gli embedding dei dati transazionali vengono aggiornati continuamente in un database vettoriale. Il CDC garantisce che questi aggiornamenti vengano trasmessi in streaming in tempo reale per rilevare istantaneamente attività insolite e segnalare potenziali frodi.
Riconoscimento di immagini e video: Per applicazioni come il tagging o la ricerca di contenuti visivamente simili, il CDC mantiene aggiornati nel database gli embedding vettoriali generati da immagini o video. Ciò consente risultati accurati e rapidi per casi d'uso in tempo reale, come la moderazione sui social media o la ricerca visuale nell'e-commerce.
Chatbot e assistenti virtuali: Il CDC aiuta i chatbot basati su RAG e LLM a fornire risposte accurate e in tempo reale. Ad esempio, gli embedding che rappresentano interazioni live degli utenti o knowledge base aggiornate vengono acquisiti e aggiornati istantaneamente, migliorando le prestazioni del chatbot.
Rilevamento delle anomalie: Il CDC è utile nella cybersecurity, dove pattern insoliti nel traffico di rete o nei log di sistema richiedono attenzione immediata.
Vantaggi del CDC
Il CDC offre vantaggi significativi alle moderne architetture dati per operare in modo efficiente e prendere decisioni informate. Ecco i principali vantaggi:
Insight in tempo reale: Il CDC fornisce i dati più aggiornati per supportare decisioni rapide. Pertanto, le aziende possono monitorare istantaneamente prestazioni e tendenze.
Latenza dei dati ridotta: Elimina i ritardi causati dall'elaborazione batch tradizionale. Poiché le modifiche si riflettono nei sistemi quasi immediatamente, migliorano la reattività nelle applicazioni che dipendono da dati sincronizzati.
Scalabilità nei sistemi di grandi dimensioni: Gestisce elevati volumi di modifiche dei dati, rendendolo adatto a database su larga scala e ambienti distribuiti.
Replica e migrazione dei dati senza interruzioni: Questa funzionalità facilita la replica dei dati in tempo reale tra sistemi per alta disponibilità, disaster recovery e bilanciamento del carico. Semplifica inoltre le migrazioni di database utilizzando dati sincronizzati durante le transizioni con tempi di inattività minimi.
Supporto per architetture event-driven: Alimenta applicazioni event-driven attivando workflow o processi downstream in base alle modifiche dei dati. Pertanto, migliora l'automazione e la reattività nelle operazioni aziendali.
Accuratezza e coerenza dei dati: Tutti i sistemi connessi dispongono di dati coerenti e accurati, riducendo errori e incoerenze. Pertanto, fornisce una base affidabile per creare solide soluzioni data-driven.
Sfide dell'implementazione di CDC
L'implementazione di CDC può essere complessa e le organizzazioni devono affrontare diverse sfide per operazioni efficienti e affidabili. I principali ostacoli includono:
Overhead delle prestazioni: L'acquisizione e l'elaborazione delle modifiche in tempo reale possono aggiungere un carico supplementare sul database che influisce sulle prestazioni delle applicazioni primarie. Inoltre, metodi ad alta intensità di risorse come trigger o query frequenti possono degradare i tempi di risposta del database. Bilanciare velocità con accuratezza e affidabilità richiede una progettazione ottimizzata della pipeline.
Gestione delle modifiche allo schema: Le modifiche allo schema del database, come l'aggiunta di colonne, la modifica dei tipi di dati o l'alterazione delle strutture delle tabelle, possono interrompere le pipeline CDC.
Considerazioni su rete e storage: Lo streaming continuo dei dati in CDC richiede una capacità di storage sufficiente e tecniche di compressione efficienti per evitare costi a spirale. Gli aumenti del traffico di rete possono mettere sotto pressione la larghezza di banda, soprattutto in sistemi geograficamente distribuiti.
Integrità dei dati nella pipeline CDC: Errori o incoerenze nella pipeline possono compromettere l'accuratezza dei sistemi downstream. La gestione di eventi fuori ordine e la risoluzione dei conflitti in ambienti distribuiti possono aggiungere complessità.
Compatibilità degli strumenti e vendor lock-in: Alcune soluzioni CDC sono legate a database o tecnologie specifici, limitando la flessibilità in ambienti eterogenei. Cambiare strumenti o aggiornare sistemi può richiedere la riprogettazione dei processi CDC.
Rischi di sicurezza e conformità: Lo streaming di dati sensibili in tempo reale richiede crittografia robusta e controlli di accesso per prevenire accessi non autorizzati. La conformità alle normative sulla protezione dei dati come GDPR o CCPA può complicare l'implementazione di CDC.
Strumenti e framework per CDC
Sono disponibili diversi strumenti e framework per implementare CDC, ciascuno con funzionalità uniche adattate a casi d'uso specifici. Ecco un elenco di opzioni popolari:
Debezium**: Una piattaforma CDC open-source basata su Apache Kafka, Debezium supporta vari database, come MySQL, PostgreSQL, MongoDB e SQL Server. È ideale per lo streaming di dati in tempo reale e l'integrazione con architetture event-driven.
Oracle GoldenGate: Una soluzione CDC robusta ed enterprise-grade di Oracle, GoldenGate supporta la replica dei dati ad alte prestazioni e l'integrazione in tempo reale tra database eterogenei. È ampiamente utilizzata per disaster recovery e migrazione.
AWS Database Migration Service (DMS): ****Un servizio completamente gestito di Amazon che supporta CDC per vari database, sia on-premises sia nel cloud. Semplifica la migrazione e la replica dei dati senza richiedere overhead significativi.
Qlik Replicate: Precedentemente noto come Attunity Replicate, Qlik Replicate supporta CDC per un'ampia gamma di database e file system. È progettato per una replica dei dati rapida e scalabile e per l'integrazione in piattaforme di analytics.
Confluent Kafka Connect: Parte dell'ecosistema Confluent, Kafka Connect offre funzionalità CDC per lo streaming delle modifiche dei dati in topic Kafka. Inoltre, si integra perfettamente con la piattaforma Kafka per l'elaborazione di eventi in tempo reale.
Conclusione
CDC svolge un ruolo fondamentale nei moderni sistemi di dati attraverso aggiornamenti in tempo reale e integrazione tra piattaforme. Affrontando i limiti dell’elaborazione batch, CDC supporta analisi in tempo reale, architetture guidate dagli eventi e sincronizzazione dei dati senza interruzioni. Strumenti come Apache Kafka potenziano ulteriormente CDC ottimizzando le modifiche nei sistemi downstream, inclusi database vettoriali come Milvus. Questo aiuta le aziende a gestire dati non strutturati, scalare le operazioni e creare applicazioni reattive.
Risorse correlate
- Che cos’è il Change Data Capture (CDC)?
- Evoluzione dell’integrazione dei dati: il ruolo del CDC
- Come funziona il Change Data Capture?
- CDC con Milvus: integrazione dei dati in tempo reale per database vettoriali
- Ruolo del CDC nei database distribuiti e nelle applicazioni cloud-native
- Applicazioni del CDC nei database vettoriali
- Vantaggi del CDC
- Sfide dell'implementazione di CDC
- Strumenti e framework per CDC
- Conclusione
- Risorse correlate
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente