




Qu’est-ce qu’une fenêtre de contexte en IA ?

Qu’est-ce qu’une fenêtre de contexte en IA ?
En IA, une fenêtre de contexte définit la quantité de texte que le modèle peut traiter en une seule fois, mesurée en tokens. Comprendre la fenêtre de contexte est crucial, car elle influence la capacité d’un modèle d’IA à générer des réponses précises et cohérentes. Ce guide expliquera ce qu’est une fenêtre de contexte, son importance dans les modèles d’IA, ainsi que les défis liés à la gestion de fenêtres de contexte plus grandes.
Comprendre les tokens
Avant d’aborder la fenêtre de contexte, découvrons d’abord le concept de tokens.
Les tokens sont les plus petites unités de données que les modèles d’IA utilisent pour traiter le texte et apprendre à partir de celui-ci. Il s’agit essentiellement des morceaux d’une phrase — comme des mots individuels ou des signes de ponctuation — qu’un ordinateur utilise pour comprendre et traiter le langage. Lorsqu’un ordinateur lit une phrase, il la divise en plus petites parties (tokens) pour lui donner du sens. Par exemple, dans la phrase « It's sunny! », les tokens seraient « It's », « sunny » et « ! ». Ce processus, appelé tokenisation, aide l’ordinateur à analyser du texte pour des tâches comme la traduction de langues, la détection de spam ou la réponse à des questions.
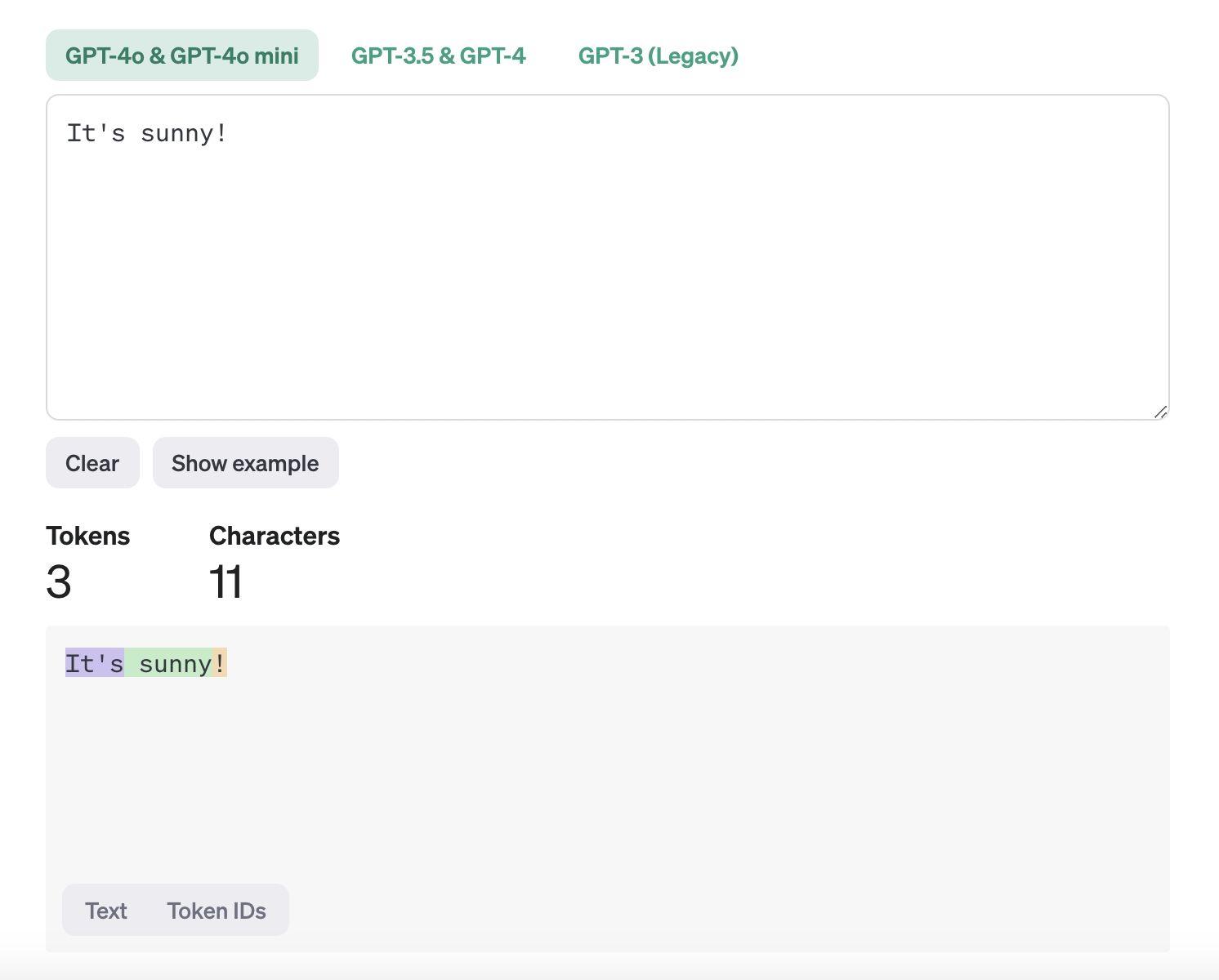 Que sont les tokens.jpeg
Que sont les tokens.jpeg
Qu’est-ce qu’une fenêtre de contexte en IA ?
La fenêtre de contexte est un concept fondamental en IA, en particulier dans les grands modèles de langage (LLM). Elle désigne la quantité maximale de texte, mesurée en tokens, qu’un modèle d’IA peut mémoriser et utiliser pendant une conversation lorsqu’il génère une réponse.
Considérez une fenêtre de contexte comme la portée de mémoire à court terme du modèle. Par exemple, si un modèle comme ChatGPT possède une fenêtre de contexte de 4 096 tokens, il peut « se souvenir » des informations issues des 4 096 derniers tokens (mots ou signes de ponctuation) qu’il a traités. Cela ressemble à la façon dont une personne ne peut suivre qu’une certaine quantité d’informations lorsqu’elle lit ou écoute. Lorsque cette limite de tokens est atteinte, les informations les plus anciennes commencent à « s’estomper » à mesure que de nouvelles informations arrivent, ce qui affecte la capacité du modèle à se référer aux parties antérieures de la conversation. Ce concept est crucial pour déterminer dans quelle mesure un modèle peut maintenir le contexte sur de longues discussions ou de longs documents.
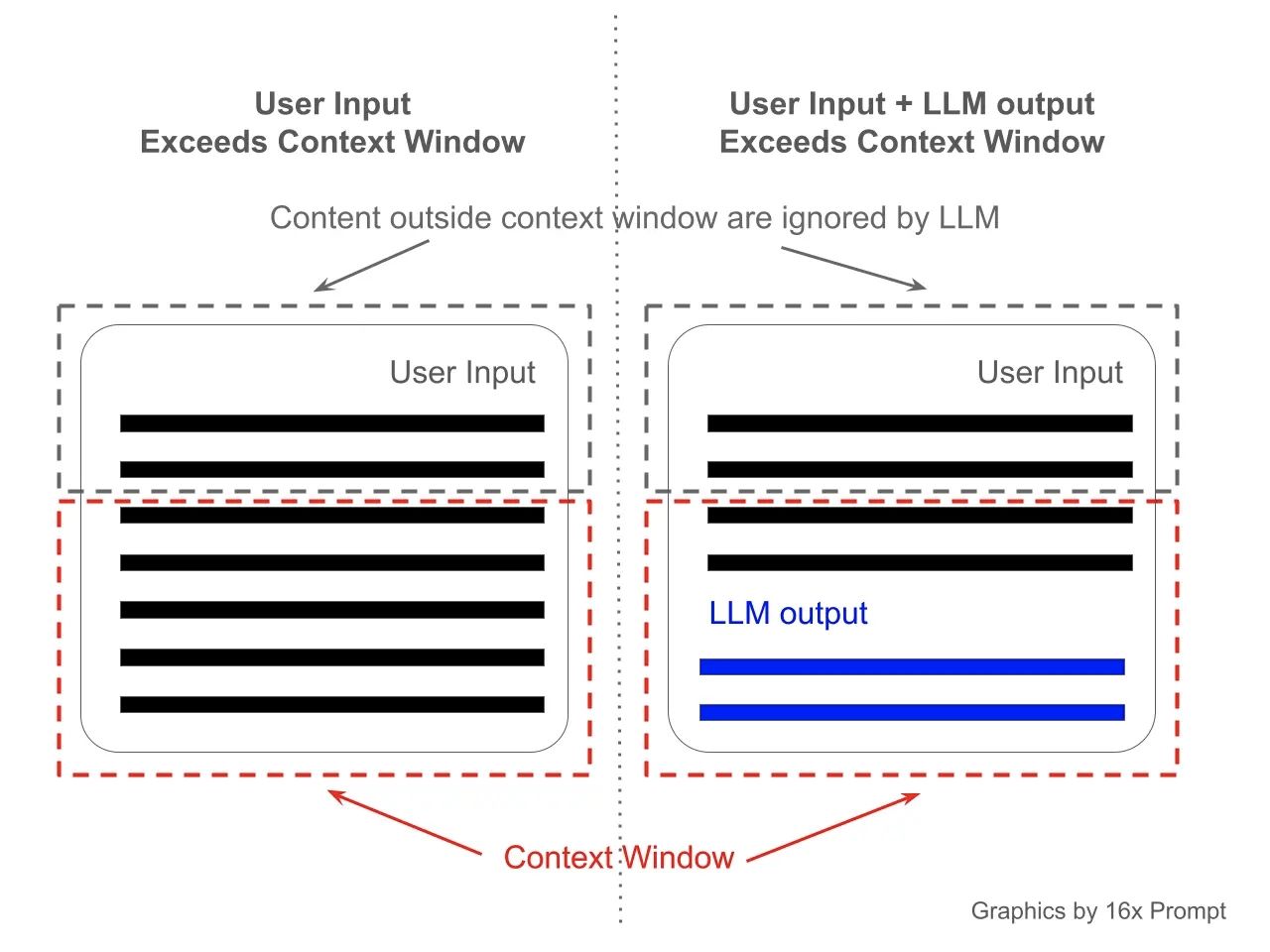 Fenêtre de contexte visualisée, crédit 16x Prompt.jpeg
Fenêtre de contexte visualisée, crédit 16x Prompt.jpeg
La fenêtre de contexte ne s’applique pas seulement à l’entrée ou à l’historique de la conversation en cours, mais aussi aux réponses générées par le modèle. Par exemple, si une réponse contient elle-même 500 tokens, ce nombre est déduit du total des tokens disponibles pour traiter l’historique de la conversation. Par conséquent, si la limite de tokens est proche, les 500 premiers tokens de la conversation peuvent ne pas être pris en compte dans le traitement en cours.
Limites de tokens au sein de la fenêtre de contexte
La taille de la fenêtre de contexte, ou limite de tokens, correspond au nombre total de tokens que le modèle peut prendre en compte à un moment donné. Si la conversation dépasse cette limite, seuls les tokens les plus récents sont conservés et les tokens plus anciens sont supprimés. Par exemple, le modèle avancé GPT-4o d’OpenAI offre une fenêtre de contexte beaucoup plus grande, pouvant atteindre 128 000 tokens, permettant une interaction plus large et plus approfondie avec le texte.
 Fenêtre de contexte et limite de tokens de sortie de GPT-4o.jpeg
Fenêtre de contexte et limite de tokens de sortie de GPT-4o.jpeg
Limites de tokens de sortie et d’entrée
Outre la fenêtre de contexte, les modèles d’IA ont des limites de tokens spécifiques pour les sorties et les entrées :
- Limite de tokens de sortie: Il s’agit du nombre maximal de tokens que le modèle peut générer dans une seule réponse. Par exemple, GPT-4o-mini d’OpenAI possède une limite de tokens de sortie de 16 348 tokens. Si la réponse générée atteint cette limite, le modèle cessera de générer des tokens, ce qui peut tronquer la réponse.
 Limite de tokens de sortie de GPT-4o-mini .jpeg
Limite de tokens de sortie de GPT-4o-mini .jpeg
- Limite de tokens d’entrée : Cela détermine le nombre de tokens de l’entrée pouvant être traités en une seule fois. Dépasser cette limite signifie que le modèle doit segmenter l’entrée en morceaux plus petits, ce qui peut avoir un impact sur la cohérence et la précision de la réponse.
Équilibrer les limites de tokens
Le volume de la limite de tokens influence considérablement les performances d’un modèle, en dictant sa capacité à analyser et à interpréter efficacement des informations complexes. Il est essentiel d’équilibrer le nombre de tokens avec la puissance de traitement du modèle, car des capacités de traitement plus complètes permettent de gérer des idées complexes plus efficacement, bien qu’avec des compromis nécessaires en matière de tokenisation et de stratégies de traitement.
Importance de fenêtres de contexte plus larges dans les modèles d’IA
 Une représentation visuelle de l’importance de fenêtres de contexte plus larges dans l’IA..jpeg
Une représentation visuelle de l’importance de fenêtres de contexte plus larges dans l’IA..jpeg
Des fenêtres de contexte plus larges améliorent considérablement la capacité d’une IA à comprendre et à analyser des documents volumineux, ce qui les rend indispensables dans des domaines comme la recherche juridique et médicale. Par exemple, dans la recherche juridique, l’IA peut extraire efficacement des informations pertinentes à partir de grands ensembles de données, fournissant rapidement des informations précieuses. De même, dans la recherche médicale, de grandes fenêtres de contexte facilitent la synthèse d’articles scientifiques complexes, aidant les chercheurs à en tirer rapidement des enseignements.
La capacité accrue à traiter plus d’un million de tokens permet aux modèles d’IA de gérer efficacement diverses tâches, du traitement des données à la génération de code. Claude 3.5 Sonnet, par exemple, dispose d’une taille de fenêtre de contexte de 200 000 tokens, ce qui lui permet de gérer des instructions complexes et des tâches nuancées avec une précision remarquable. Cette capacité souligne le rôle essentiel des fenêtres de contexte plus larges dans l’amélioration des performances de l’IA.
Cependant, les fenêtres de contexte plus larges dans les modèles d’IA eux-mêmes s’accompagnent de compromis. Elles peuvent entraîner des coûts opérationnels plus élevés et nécessitent des stratégies de données robustes pour garantir l’utilisation efficace des données d’entraînement pertinentes. De plus, la gestion d’une fenêtre de contexte plus large peut entraîner une surcharge d’informations, diminuant l’efficacité du modèle à identifier les points clés. Par conséquent, une approche équilibrée est essentielle pour exploiter tout le potentiel des fenêtres de contexte plus larges tout en atténuant les défis associés.
Dans la section suivante, nous explorerons les défis liés à l’expansion des fenêtres de contexte.
Défis liés à l’expansion des fenêtres de contexte dans les modèles d’IA
L’expansion des fenêtres de contexte dans les modèles d’IA introduit divers compromis qui nécessitent une attention particulière. Autoriser des entrées et des sorties plus longues peut enrichir les réponses générées, mais augmente également la complexité du traitement. L’équilibre entre des fenêtres de contexte plus longues et un traitement efficace est crucial pour atténuer les inconvénients potentiels en matière de performances de l’IA.
Ressources informatiques
À mesure que la taille des fenêtres de contexte augmente, les besoins en puissance de traitement augmentent considérablement, entraînant des temps d’inférence plus lents. La complexité de la mise à l’échelle lors de l’augmentation des fenêtres de contexte provient de l’augmentation quadratique des paramètres, ce qui pose des défis importants. Lorsque la longueur des séquences de texte double, les besoins en mémoire et en calcul quadruplent, soulignant les exigences accrues des fenêtres de contexte plus larges.
Pour relever ces défis, des techniques telles que ring attention ont été mises en œuvre afin d’améliorer l’efficacité des modèles traitant des fenêtres de contexte étendues. Cependant, la théorie de la « Zone proximale de développement » suggère que surcharger les modèles de langage avec des informations dépassant leurs capacités actuelles peut réduire leur efficacité. Ainsi, une attention particulière est nécessaire pour gérer efficacement les ressources informatiques.
Implications en matière de coûts
Des fenêtres de contexte plus longues peuvent entraîner des coûts informatiques et financiers importants, que les organisations doivent gérer efficacement. L’élargissement de la fenêtre de contexte de 4K à 8K tokens peut entraîner une hausse exponentielle des dépenses opérationnelles. Par conséquent, les organisations doivent mettre en balance les avantages d’une amélioration des performances des modèles d’IA avec l’augmentation des coûts liée à des fenêtres de contexte plus longues.
Des stratégies efficaces de gestion des coûts sont essentielles pour les organisations qui envisagent d’élargir les fenêtres de contexte dans les modèles d’IA. La mise en œuvre de ces stratégies aide les organisations à équilibrer des capacités d’IA améliorées avec les implications financières associées, garantissant des opérations d’IA durables et efficaces.
Gestion des données
La gestion de volumes plus importants de données d’entraînement présente des défis majeurs pour les modèles d’IA, en particulier lorsqu’il s’agit d’optimiser les performances sans surcharger le système. Les recherches indiquent que fournir un ensemble ciblé de documents pertinents donne de meilleures performances pour les modèles de langage que de les inonder d’un volume excessif d’informations non filtrées. Cette approche garantit que l’IA peut traiter et répondre efficacement, tout en maintenant la pertinence de ses sorties.
Le filtrage et la gestion du contexte des données d’entraînement sont essentiels pour permettre des réponses précises et des performances de modèle efficaces. La sélection et l’organisation stratégiques des données pertinentes permettent aux modèles d’IA de fournir des sorties contextuellement appropriées et significatives, même avec des fenêtres de contexte plus grandes.
RAG : améliorer les modèles d’IA avec une base de connaissances externe pour une mémoire étendue
Des fenêtres de contexte plus grandes sont cruciales dans les modèles d’IA pour une meilleure compréhension et une meilleure gestion des tâches complexes. Elles permettent aux modèles de conserver et d’exploiter des informations plus étendues, améliorant la continuité et la pertinence des réponses. Cela s’avère particulièrement bénéfique pour traiter des tâches complexes. Cependant, le maintien d’une grande fenêtre de contexte peut accroître les exigences de calcul, les coûts et la complexité de la gestion des données.
Pour doter les modèles d’IA de capacités de mémoire à long terme tout en relevant ces défis, les chercheurs ont exploré des approches innovantes comme la génération augmentée par récupération (RAG). Cette technique améliore la sortie des modèles d’IA en les connectant à une base de connaissances externe hébergée dans une base de données vectorielle. Ce faisant, elle fournit aux modèles un arrière-plan contextuel plus large sans la surcharge associée aux grandes fenêtres de contexte internes. Cette base de connaissances externe agit comme une mémoire étendue, aidant les modèles à accéder dynamiquement à un vaste réservoir d’informations, ce qui est crucial pour le traitement de requêtes complexes et pour améliorer la profondeur et la précision des réponses.
Génération augmentée par récupération (RAG)
La génération augmentée par récupération (RAG) combine la puissance générative des modèles de langage avec la récupération dynamique de documents externes. Cette approche élargit le potentiel des LLM en accédant à un éventail plus large d’informations et en les intégrant, améliorant ainsi la pertinence et la précision des réponses générées.
Un système RAG standard intègre généralement un modèle d’embedding, une base de données vectorielle comme Milvus ou sa version gérée Zilliz Cloud, et un LLM (ou un modèle multimodal), où le modèle d’embedding transforme le texte en embeddings vectoriels, la base de données vectorielle stocke et récupère les informations contextuelles pour les requêtes des utilisateurs, et le LLM génère des réponses sur la base du contexte récupéré.
 Figure- RAG workflow.png
Figure- RAG workflow.png
L’exploitation du RAG permet aux modèles d’IA de récupérer dynamiquement des documents ou des points de données pertinents pendant le processus de génération, garantissant des sorties riches en contexte et alignées sur l’intention de l’utilisateur. Cette technique est particulièrement utile dans les scénarios nécessitant des informations détaillées et précises, comme la recherche juridique ou l’analyse scientifique.
Comparaison des tailles de fenêtres de contexte parmi les modèles populaires
 Un graphique comparatif des tailles de fenêtres de contexte parmi les modèles d’IA populaires
Un graphique comparatif des tailles de fenêtres de contexte parmi les modèles d’IA populaires
Différents LLMs disposent de tailles de fenêtres de contexte variables, adaptées à différentes exigences et tâches. GPT-4o, par exemple, offre une taille de fenêtre de contexte de 128 000 tokens, ce qui améliore considérablement sa capacité à traiter des entrées volumineuses et à générer des réponses contextuellement pertinentes. Pendant ce temps, Gemini 1.5 Pro peut utiliser une fenêtre de contexte de plus de 2 millions de tokens, offrant des avantages substantiels pour la gestion de grands ensembles de données.
Claude 3.5 Sonnet et Llama 3.2 présentent également des tailles de fenêtres de contexte variables, chacune avec ses forces et ses limites. Claude 3.5 Sonnet dispose d’une taille de fenêtre de contexte de 200 000 tokens, ce qui lui permet de gérer de vastes informations en une seule interaction. En revanche, Llama 3.2 prend en charge une fenêtre de contexte de 128 000 tokens.
| Modèle | Fenêtre de contexte | Tokens de sortie max. |
|---|---|---|
| GPT-4o | 128 000 tokens | 16 384 tokens |
| GPT-4-turbo | 128 000 tokens | 4 096 tokens |
| GPT-4 | 8 192 tokens | 8 192 tokens |
| Gemini 1.5 Pro | 2 097 152 tokens | 8 192 tokens |
| Claude 3.5 Sonnet | 200 000 tokens | 8192 tokens |
| Llama 3.2 | 128 000 tokens | 2048 tokens |
Résumé
En conclusion, maîtriser la fenêtre de contexte est essentiel pour faire progresser les capacités de l’IA. Des fenêtres de contexte plus grandes renforcent la capacité de l’IA à traiter et analyser des documents volumineux, ce qui les rend inestimables dans des domaines comme la recherche juridique et médicale. Cependant, l’extension des fenêtres de contexte s’accompagne de défis, notamment des exigences de calcul accrues, des coûts plus élevés et des exigences complexes en matière de gestion des données.
En mettant en œuvre des techniques telles que la génération augmentée par récupération (RAG) et les bases de données vectorielles, les modèles d’IA peuvent optimiser l’utilisation de longues fenêtres de contexte avec une base de connaissances externe alimentée par des bases de données vectorielles, garantissant des réponses contextuellement pertinentes et exactes. Alors que nous nous tournons vers l’avenir, il sera crucial d’équilibrer la taille de la fenêtre de contexte avec l’efficacité et d’explorer des stratégies innovantes pour développer des applications d’IA avancées capables de gérer efficacement des tâches complexes. Le parcours vers la maîtrise des fenêtres de contexte se poursuit, et les possibilités sont infinies.
Foire aux questions
Qu’est-ce qu’une fenêtre de contexte en IA ?
Une fenêtre de contexte en IA est la plage de texte entourant un token cible que le modèle utilise pour générer des réponses, déterminant la quantité d’informations qu’il peut traiter à un moment donné. Comprendre ce concept est crucial pour optimiser les interactions avec l’IA.
Pourquoi les fenêtres de contexte plus grandes sont-elles importantes ?
Les fenêtres de contexte plus grandes sont cruciales, car elles améliorent considérablement la compréhension d’un modèle d’IA et sa capacité à analyser des documents volumineux, ce qui se traduit par des réponses plus cohérentes et contextuellement pertinentes. Cette avancée améliore en fin de compte la qualité globale de l’interaction.
Comment les limites de tokens influencent-elles les modèles d’IA ?
Les limites de tokens affectent de manière critique les modèles d’IA en déterminant la taille maximale d’entrée qu’ils peuvent traiter. Le dépassement de ces limites entraîne des sorties incomplètes ou inexactes, ce qui nécessite de segmenter le texte en parties plus petites.
Quels sont les défis liés à l’élargissement des fenêtres de contexte ?
L’élargissement des fenêtres de contexte pose des défis importants, notamment des exigences de calcul accrues et des coûts opérationnels plus élevés. De plus, il complique la gestion des données, nécessitant une réflexion attentive avant la mise en œuvre.
Comment les modèles d’IA peuvent-ils être améliorés avec de longues fenêtres de contexte ?
Les modèles d’IA peuvent être améliorés avec de longues fenêtres de contexte en utilisant des techniques telles que la génération augmentée par récupération (RAG) et les bases de données integrating vector, qui aident à garantir des réponses contextuellement pertinentes et exactes. Cette approche améliore considérablement les performances du modèle dans le traitement d’informations étendues.
Ressources supplémentaires
- Comprendre les tokens
- Qu’est-ce qu’une fenêtre de contexte en IA ?
- Importance de fenêtres de contexte plus larges dans les modèles d’IA
- Défis liés à l’expansion des fenêtres de contexte dans les modèles d’IA
- RAG : améliorer les modèles d’IA avec une base de connaissances externe pour une mémoire étendue
- Comparaison des tailles de fenêtres de contexte parmi les modèles populaires
- Résumé
- Foire aux questions
- Ressources supplémentaires
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement