




LLaVA : Faire progresser les modèles vision-langage grâce à l'optimisation des instructions visuelles
Les grands modèles de langage (LLMs) actuels, tels que ChatGPT, LLAMA et Claude Sonnet, ont démontré que les instructions basées sur le langage humain peuvent être un outil puissant pour améliorer la qualité des réponses. En utilisant des techniques telles que l'[ingénierie des messages] (https://zilliz.com/glossary/prompt-as-code-(prompt-engineering)), nous pouvons guider les LLM pour qu'ils génèrent des réponses qui s'alignent plus étroitement sur nos cas d'utilisation spécifiques.
Au départ, les LLM étaient conçus exclusivement pour des entrées textuelles. Lorsqu'ils recevaient des instructions textuelles, ils généraient une réponse correspondante. Bien que cette approche ait été couronnée de succès, l'extension de ces capacités aux entrées visuelles est une progression naturelle. Les modèles visuels prennent en entrée à la fois une instruction textuelle et une image, ce qui permet d'effectuer des tâches telles que le résumé du contenu d'une image, l'extraction d'informations ou la traduction d'un texte dans une image.
Dans cet article, nous allons explorer LLaVA (Large Language and Vision Assistant), l'une des premières tentatives de mise en œuvre d'instructions textuelles pour les modèles visuels. Avant d'entrer dans les détails de sa mise en œuvre, prenons un peu de recul pour comprendre l'évolution des modèles visuels et la manière dont ils transforment le domaine.
Développement des modèles visuels
Au début de leur développement, la plupart des modèles basés sur la vision reposaient sur des architectures basées sur des [réseaux de neurones convolutifs] (https://zilliz.com/glossary/convolutional-neural-network) (CNN) pour effectuer des tâches visuelles courantes. Dans sa forme la plus simple, un modèle basé sur la vision peut être construit avec une paire de couches CNN pour effectuer une tâche de classification d'image simple, comme déterminer si une image donnée est celle d'un chien ou d'un chat.
Cependant, pour classer des images plus complexes avec davantage de classes, nous devons construire des modèles plus profonds composés de centaines de couches CNN. Plus les couches du modèle sont profondes, plus le risque de rencontrer le problème du gradient de fuite est élevé. Le gradient de disparition fait référence au phénomène de formation du modèle où le gradient devient si petit que le modèle est incapable d'apprendre quoi que ce soit et de mettre à jour ses poids.
Pour résoudre ce problème, des algorithmes sophistiqués tels que [residual connections] (https://zilliz.com/learn/deep-residual-learning-for-image-recognition) ont été mis en œuvre dans l'architecture du modèle afin d'éviter les problèmes de gradient de disparition qui se produisent couramment dans les modèles d'apprentissage profond. Cette méthode s'est avérée efficace et a conduit à la création de ResNet, qui a ensuite atteint des performances de pointe dans de nombreux ensembles de données de référence pour la classification d'images.
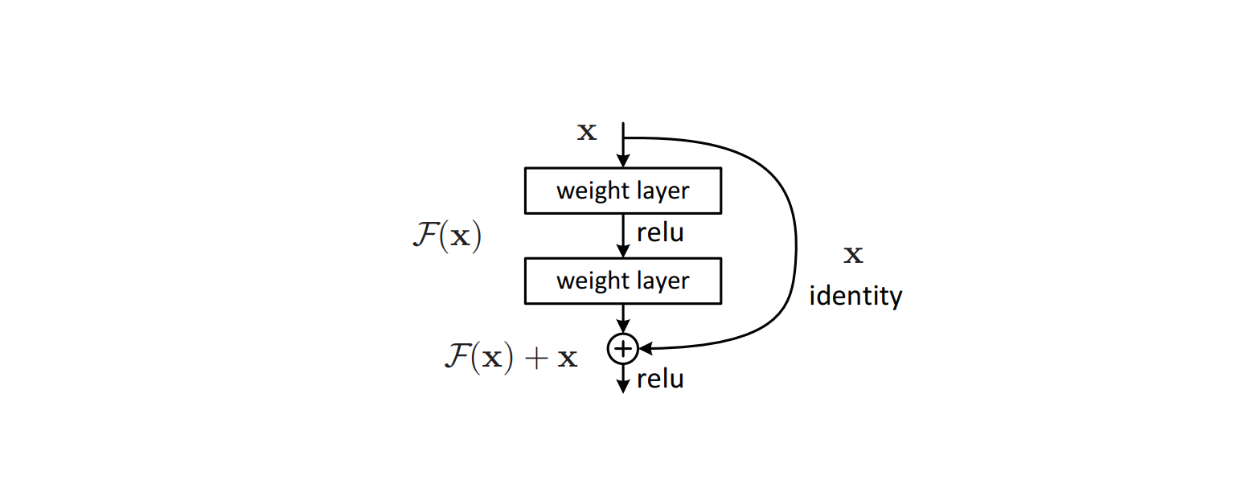
Figure : Bloc de construction d'une connexion résiduelle dans l'architecture d'un modèle _ Source.
Le succès de ResNet a inspiré d'autres architectures de modèles capables d'effectuer des tâches d'image plus complexes. Des modèles visuels tels que YOLO ont mis en œuvre des connexions résiduelles dans leur architecture pour effectuer des tâches de détection d'objets. Parallèlement, U-Net a utilisé une combinaison d'architecture en forme de U et de connexions résiduelles pour effectuer des tâches de segmentation d'images.
Bien que ces modèles visuels puissent effectuer des tâches visuelles, chacun d'entre eux ne peut effectuer qu'une tâche spécifique. Si un modèle a été formé pour la classification d'images, il ne peut être utilisé qu'à cette fin. En outre, si nous demandons au modèle de classer une image très différente de celles des données d'apprentissage, nous pouvons observer un certain caractère aléatoire dans les prédictions du modèle.
L'introduction du célèbre modèle [Transformers] (https://zilliz.com/learn/decoding-transformer-models-a-study-of-their-architecture-and-underlying-principles) en 2017 a déclenché un développement rapide des modèles d'apprentissage profond en général. Les modèles adoptant Transformers dans leur architecture ont significativement surpassé les modèles plus traditionnels. Initialement prévue uniquement pour les modèles basés sur le texte, l'architecture Transformers s'est avérée suffisamment polyvalente pour être également utilisée dans les modèles basés sur la vision.
Les modèles de vision basés sur les transformateurs, tels que [Vision Transformers (ViT)] (https://zilliz.com/learn/understanding-vision-transformers-vit), ont démontré une grande capacité à effectuer des tâches de classification d'images. Par conséquent, ViT est maintenant utilisé par de nombreux modèles de vision textuelle populaires, tels que CLIP, comme architecture de base.
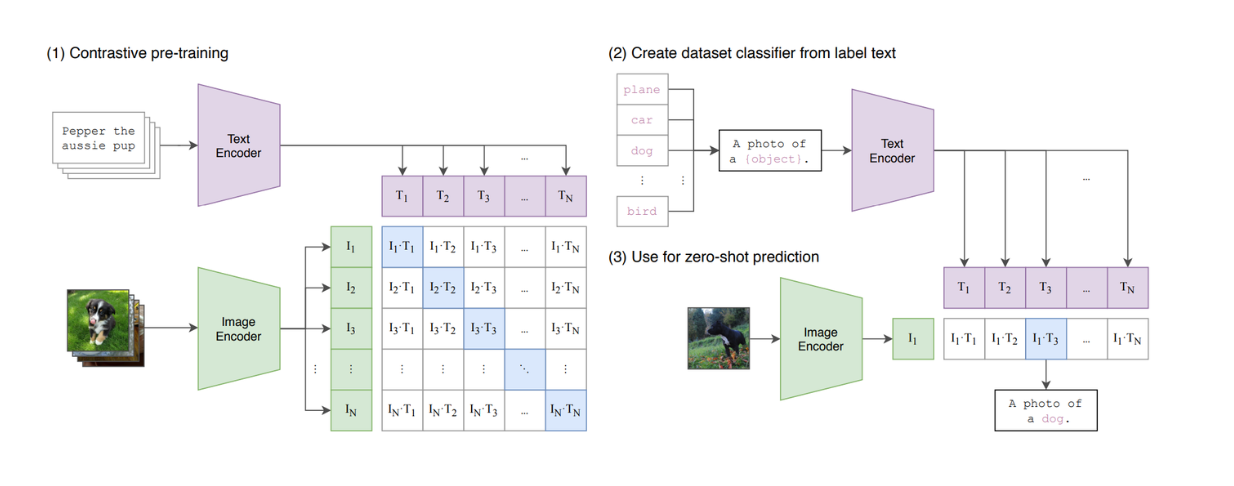
Figure : Résumé du modèle CLIP._ Source.
CLIP est un modèle qui combine ViT et un modèle similaire à BERT dans son architecture. ViT traite l'entrée image, tandis que le modèle de type BERT traite l'entrée textuelle. CLIP a été entraîné à l'aide de l'apprentissage contrastif, ce qui signifie que lorsqu'un texte et une image sont donnés en entrée, CLIP calcule la similarité entre le texte et l'image. Cependant, nous pouvons constater que CLIP est encore limité en termes de capacité à imiter les LLM basés sur le texte, car il ne s'agit pas d'un modèle génératif.
LLaVA est l'un des premiers LLM visuels capables de prendre des instructions textuelles et des images en entrée et de générer une réponse appropriée. Nous aborderons les détails de la LLaVA dans la section suivante.
Qu'est-ce que LLaVa ?
LLaVA (Large Language and Vision Assistant) est un modèle multimodal qui combine des modèles de langage de grande taille (LLM) basés sur le texte avec des capacités de traitement visuel, ce qui lui permet de traiter des entrées de texte et d'image. Il est conçu pour effectuer des tâches telles que résumer un contenu visuel, extraire des informations d'images et répondre à des questions sur des données visuelles.
LLaVA s'appuie sur le succès des LLM en intégrant la compréhension visuelle et en alignant les instructions textuelles sur l'analyse d'images. Cette intégration permet au modèle de traiter des entrées appariées - invites textuelles et images - et de fournir des réponses cohérentes et adaptées au contexte.
Architecture de LLaVA
L'architecture de LLaVA est relativement simple. Elle utilise un LLM pré-entraîné pour traiter les instructions textuelles et le codeur visuel de CLIP pré-entraîné, un modèle ViT, pour traiter les informations d'image.
Parmi plusieurs LLM pré-entraînés disponibles publiquement, les auteurs de LLaVA ont choisi Vicuna comme colonne vertébrale pour traiter les informations textuelles et générer la réponse finale, compte tenu d'une paire d'entrées texte-image.
Comme la plupart des LLM basés sur le texte sont basés sur l'architecture Transformer, le processus de transformation du texte jusqu'à la génération de la réponse est assez simple. Chaque token du texte d'entrée est transformé en un encastrement, puis il passe par plusieurs piles de couches denses et d'attention avant de produire la caractéristique finale de sortie avec une dimension de taille fixe.
Pour traiter l'image d'entrée, LLaVA utilise le modèle ViT pré-entraîné dans CLIP pour transformer l'image d'entrée en une représentation de caractéristiques avec une dimension de taille fixe. Cependant, la dimension de l'élément d'image de CLIP diffère de celle de l'élément de texte de Vicuna. Par conséquent, LLaVA met en œuvre une simple couche dense par la suite pour projeter l'élément d'image afin qu'il ait la même taille que l'élément textuel de Vicuna.
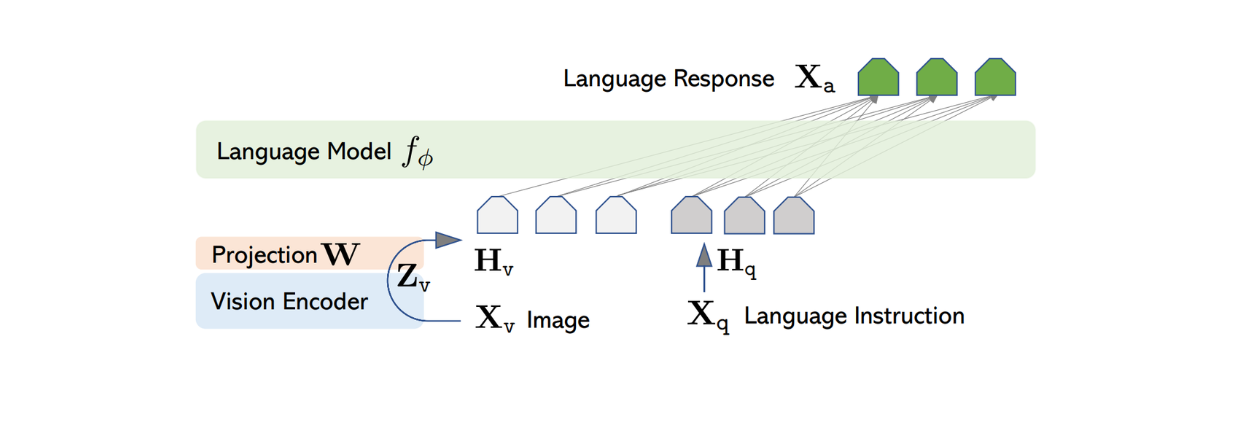
Figure : Architecture de LLaVA. Source.
Maintenant que les caractéristiques d'image et de texte ont la même taille, une approche est nécessaire pour combiner ces deux caractéristiques en une seule. Plusieurs approches sont couramment utilisées à cette fin, comme le simple fait de faire précéder la caractéristique d'image par la caractéristique de jeton ([caractéristique d'image] + [caractéristique de texte]), ou l'utilisation d'algorithmes plus sophistiqués tels que l'attention croisée à porte et le formateur Q. Les caractéristiques combinées de l'image et du texte sont ensuite introduites dans Vicuna, ce qui lui permet de générer une réponse appropriée.
Cependant, en mettant en œuvre l'approche mentionnée ci-dessus, la qualité de la réponse générée par Vicuna ou tout autre LLM similaire peut ne pas être optimale. C'est normal puisque les LLM sont formés uniquement sur des données textuelles. Par conséquent, LLaVA doit être affiné avant de pouvoir générer des réponses cohérentes basées sur une paire d'entrées image-texte. Ce processus de réglage fin est appelé [visual instruction tuning] (https://arxiv.org/abs/1512.03385), que nous aborderons dans les sections suivantes.
Processus de génération de données pour l'ajustement des instructions visuelles
L'ajustement des instructions visuelles est un processus d'entraînement des modèles d'IA multimodale à comprendre et à répondre à des instructions textuelles associées à des entrées visuelles, telles que des images ou des vidéos. Cette technique permet d'aligner la compréhension visuelle sur les capacités de traitement du langage naturel, ce qui permet au modèle d'effectuer des tâches telles que le sous-titrage d'images, la réponse à des questions visuelles, la reconnaissance d'objets et l'extraction d'informations.
L'un des principaux défis de l'optimisation des instructions visuelles est le manque de données publiques sur le suivi des instructions multimodales. Bien qu'il existe plusieurs ensembles de données constitués de paires image-texte, tels que CC et LAION, ils ne sont pas exactement le type d'ensemble de données que nous aimerions utiliser pour affiner les LLM visuels afin qu'ils suivent les instructions de l'utilisateur.
Figure : Exemple d'ensemble de données CC. Source.
D'autre part, la création manuelle d'une quantité massive de données multimodales de suivi des instructions pour ajuster LLaVA nécessiterait beaucoup d'efforts et de temps. Par conséquent, nous pouvons exploiter GPT-4 ou ChatGPT pour accélérer le processus de création de données multimodales de suivi des instructions.
Comme le montre l'exemple de l'image CC ci-dessus, les ensembles de données multimodales courants se composent d'une paire image-texte de légende dans chaque enregistrement de données. Avec ChatGPT, étant donné une image et sa légende, nous pouvons générer un ensemble de questions possibles destinées à demander aux LLM de décrire le contenu de l'image. Le format des données multimodales de suivi des instructions se présentera alors comme suit : Humain : Xq Xv
Cependant, nous savons que les itérations précédentes de ChatGPT n'acceptent que du texte en entrée. Pour l'utiliser afin de dresser une liste de questions concernant une image spécifique, nous devons fournir des informations ou des métadonnées sur l'image. Les auteurs ont utilisé deux approches différentes pour fournir à ChatGPT les informations nécessaires sur toute image d'entrée : les légendes et les boîtes de délimitation. Les légendes consistent généralement en des descriptions détaillées de l'image, tandis que les boîtes de délimitation fournissent à ChatGPT des informations utiles sur l'emplacement exact des objets dans l'image.

Figure : Exemple de légende et de boîtes de délimitation pour capturer des informations visuelles pour le GPT-4 en mode texte. Source.
Les auteurs ont créé trois types d'ensembles de données multimodales sur le suivi des instructions :
Conversation : Il s'agit d'une conversation en va-et-vient entre le LLM et l'utilisateur. Les réponses du LLM sont formulées sur le même ton que s'il regardait l'image et répondait ensuite aux questions de l'utilisateur. Les questions typiques portent sur le contenu visuel de l'image, le comptage des objets dans l'image, les positions relatives des objets dans l'image, etc.
Descriptions détaillées : il s'agit d'une liste de questions destinées à générer des descriptions complètes d'une image.
Raisonnement complexe : il s'agit de questions qui vont au-delà des deux types précédents. Au lieu de simplement décrire le contenu visuel d'une image, ces questions visent à obliger le MLD à expliquer la logique qui sous-tend ses réponses, en exigeant un raisonnement étape par étape.

Figure : Exemple de trois types d'instruction multimodale - ensemble de données de suivi._ Source.
Vous trouverez ci-dessous un exemple d'invite utilisée par les auteurs pour générer un ensemble de données de type conversation :
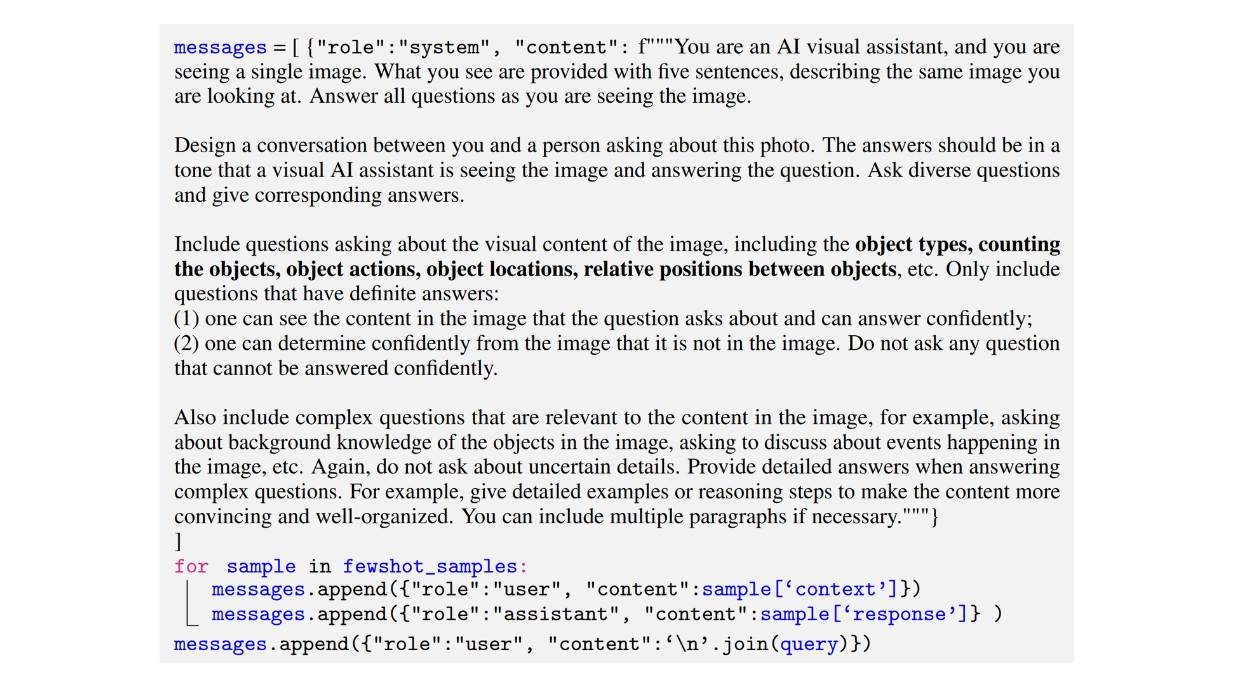
Figure : Exemple d'une invite utilisée pour générer un ensemble de données multimodales de type conversationnel sur le suivi des instructions _ Source.
Il est assez difficile d'obtenir la sortie souhaitée avec le format correct à partir des données de suivi d'instructions multimodales générées par LLM. C'est pourquoi, lorsqu'ils ont demandé à ChatGPT de générer les trois types d'ensembles de données multimodales de suivi d'instructions, les auteurs ont utilisé des échantillons peu nombreux pour tirer parti de la puissance de l'apprentissage en contexte.
Avec ces échantillons, les auteurs ont fourni quelques exemples créés manuellement de conversations entre le MLD et l'utilisateur à côté de l'invite. Ces quelques exemples aident ChatGPT à mieux comprendre la structure des résultats attendus. Vous trouverez ci-dessous un exemple d'échantillon de quelques secondes mis en œuvre par les auteurs dans l'invite pour générer un ensemble de données de conversation.

Figure : Exemple d'un échantillon de quelques secondes à transmettre avec l'invite pour l'apprentissage en contexte Source.
Procédure de formation de LLaVA
L'ensemble des données multimodales de suivi d'instructions générées avec l'approche mentionnée ci-dessus était d'environ 158K. Ensuite, un modèle LLaVA a été affiné avec ces données multimodales.
Dans l'ensemble de données, pour chaque image Xv, il y a des conversations à plusieurs tours entre le MAVL et les utilisateurs (X1q, X1a, - - - , XTq, XTa), où T est le nombre total de tours. Pour chaque tour t, la réponse Xta est considérée comme la réponse du mécanisme d'apprentissage tout au long de la vie et, par conséquent, l'instruction au tour t serait la suivante :
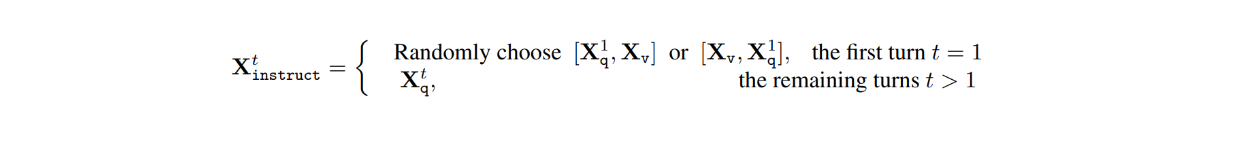
Ensuite, au cours du processus d'ajustement des instructions visuelles, deux étapes ont été menées : le pré-entraînement pour l'alignement des caractéristiques et l'ajustement fin de bout en bout.
Au cours de l'étape de pré-entraînement pour l'alignement des caractéristiques, l'objectif principal est d'entraîner la couche de projection qui fait correspondre la sortie du modèle ViT du codeur CLIP pré-entraîné à une caractéristique visuelle finale qui a la même dimension que la caractéristique du texte. À ce stade, le processus d'entraînement a été effectué à l'aide de l'ensemble de données CC filtré, qui contient 596 000 paires image-texte. Pour chaque image Xv, la question Xq est échantillonnée aléatoirement à partir d'un ensemble de questions, et la question Xc correspondante est utilisée comme étiquette de vérité de base. Par conséquent, les questions échantillonnées pour la formation sont celles qui demandent au LLM de décrire brièvement l'image, comme vous pouvez le voir dans l'image ci-dessous :

Figure : Exemple de questions visant à expliquer brièvement le contenu d'une image _ Source.
Puisque nous n'entraînons que la couche de projection, les poids de ViT et LLM sont gelés à ce stade.
Pendant ce temps, au cours de la deuxième étape, qui est un réglage fin de bout en bout, le modèle LLaVA est réglé avec les 158K données multimodales de suivi d'instructions générées. Dans cette étape, seuls les poids ViT sont gelés, tandis que les poids de la couche de projection et LLM sont mis à jour pendant le processus de réglage fin.
Résultats LLaVA
Pour évaluer la performance de LLaVA, une comparaison avec d'autres modèles de pointe tels que GPT-4 et des modèles visuels tels que BLIP-2 et OpenFlamingo a été effectuée. Pour l'évaluation des résultats, les auteurs ont utilisé le modèle GPT-4 en mode texte pour évaluer la qualité des réponses en fonction de leur utilité, de leur pertinence, de leur précision et de leur niveau de détail.
Pour la première évaluation, 30 images aléatoires de l'ensemble de données COCO-Val-2014 ont été sélectionnées et trois types d'ensembles de données ont été générés à l'aide du processus de génération de données expliqué dans la section précédente. Il en résulte un total de 90 points de données : 30 pour la conversation, 30 pour les descriptions détaillées et 30 pour le raisonnement complexe. Les réponses de LLaVA ont ensuite été comparées à la sortie du modèle GPT-4 textuel qui utilise la description/capture textuelle comme étiquette et les boîtes de délimitation comme entrée visuelle. Les résultats sont les suivants :
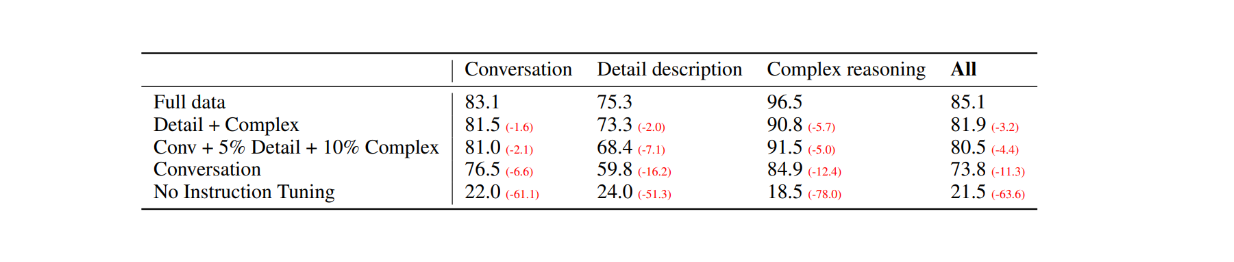
Figure : Comparaison de performance entre LLaVA et GPT-4 textuel sur 30 images aléatoires._ Source.
Avec l'ajustement des instructions visuelles, la capacité du modèle à suivre les instructions a augmenté d'au moins 50 points dans chaque type d'ensemble de données. Parallèlement, le score relatif de LLaVA n'était pas très éloigné de celui du modèle GPT-4 textuel qui utilise les légendes des images comme entrée visuelle, comme le montrent les chiffres entre parenthèses dans chaque catégorie.
La performance de LLaVA a également été comparée aux modèles visuels tels que BLIP-2 et OpenFlamingo en prenant d'abord 24 images aléatoires avec 60 questions au total. Comme le montre le tableau ci-dessous, la performance de LLaVA est de loin supérieure à celle des deux autres modèles visuels. Cela démontre la puissance de l'ajustement des instructions visuelles, car BLIP-2 et OpenFlamingo n'ont pas été ajustés explicitement avec un ensemble de données multimodales de suivi d'instructions.

Figure : Comparaison des performances entre LLaVA et BLIP-2 et OpenFlamingo._ Source.
Examinons maintenant un exemple des réponses des modèles en action. Considérons une image de nuggets de poulet formant une carte du monde et demandons : "Pouvez-vous expliquer ce mème en détail?" Voici les exemples de réponses de LLaVA, GPT-4 en mode texte, BLIP-2 et OpenFlamingo.

Figure : Exemples de réponses de LLaVA, GPT-4, BLIP-2 et OpenFlamingo._ Source.
Comme vous pouvez le constater, les modèles BLIP-2 et OpenFlamingo n'ont pas réussi à suivre l'instruction, car ils n'ont pas été affinés à l'aide d'instructions visuelles. Dans le même temps, LLaVA a démontré sa capacité de raisonnement visuel dans la compréhension de l'humour. Avec GPT-4, elle a pu fournir une réponse concise conformément à l'instruction.
Lors du réglage fin sur l'ensemble de données ScienceQA pour environ 12 époques, LLaVA a également obtenu des résultats très compétitifs par rapport au modèle MM-CoT, qui est le modèle de pointe actuel (SOTA) sur cet ensemble de données. Comme le montre le tableau ci-dessous, LLaVA a atteint une précision globale de 90,92 % sur plusieurs sujets différents, contre 91,68 % pour le modèle MM-CoT. Cependant, lorsque la sortie de LLaVA a été combinée avec GPT-4, la performance a atteint un nouveau SOTA sur l'ensemble de données ScienceQA avec 92,53% de précision.
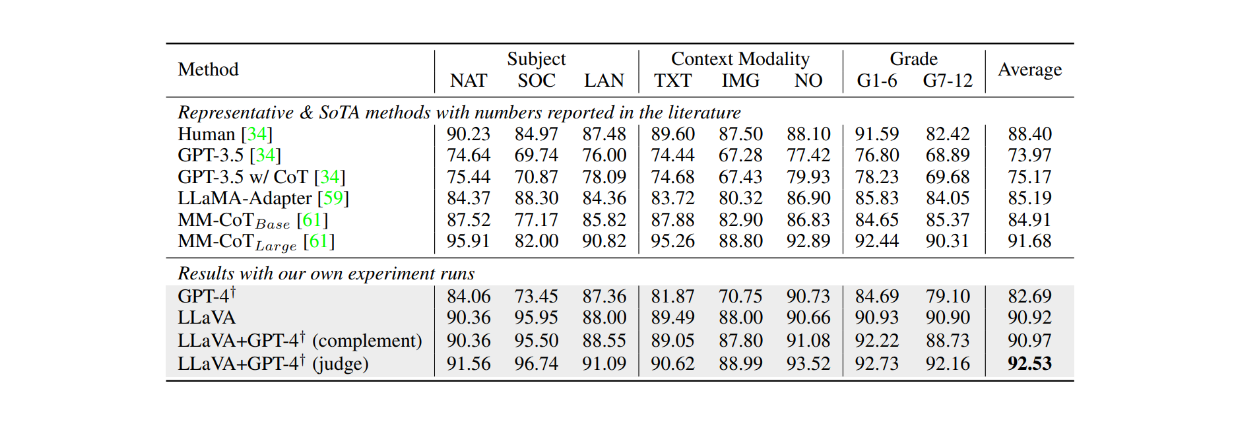
Figure : Précision des LLM sur l'ensemble de données ScienceQA._ Source.
Conclusion
LLaVA représente une première avancée dans le développement de grands modèles de langage (LLM) visuels capables de suivre des instructions textuelles. Le modèle combine un transformateur de vision (ViT) pré-entraîné de CLIP pour le traitement d'images avec Vicuna comme épine dorsale du modèle de langage, en utilisant une couche de projection pour aligner les dimensions des caractéristiques entre les deux composants. Le modèle est ensuite affiné sur 158 000 échantillons de données multimodales de suivi d'instructions.
Grâce à cette approche de réglage des instructions visuelles, LLaVA peut décrire et effectuer un raisonnement complexe sur une image donnée en fonction des instructions contenues dans l'invite. Les résultats de l'évaluation démontrent l'efficacité de l'ajustement des instructions visuelles, car les performances de LLaVA sont systématiquement supérieures à celles de deux autres modèles visuels : BLIP-2 et OpenFlamingo.
Pour en savoir plus
[Le modèle ALIGN expliqué ] (https://zilliz.com/learn/align-explained-scaling-up-visual-and-vision-language-representation-learning-with-noisy-text-supervision)
ColPali : Better Document Retrieval with VLMs and ColBERT Embeddings ](https://zilliz.com/blog/colpali-enhanced-doc-retrieval-with-vision-language-models-and-colbert-strategy)
ColBERT : Un modèle d'intégration et de classement au niveau des jetons
XLNet : NLP amélioré avec un pré-entraînement autorégressif généralisé
Qu'est-ce qu'une base de données vectorielle et comment fonctionne-t-elle ?
Continuer à lire

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

Expanding Our Global Reach: Zilliz Cloud Launches in Azure Central India
Zilliz Cloud expands to Azure Central India. This new region helps customers meet compliance, reduce latency, and optimize cloud costs when building AI applications.

Demystifying the Milvus Sizing Tool
Explore how to use the Sizing Tool to select the optimal configuration for your Milvus deployment.