




Build AI-powered Search for Every Data Source with Fivetran and Milvus
About this Webinar
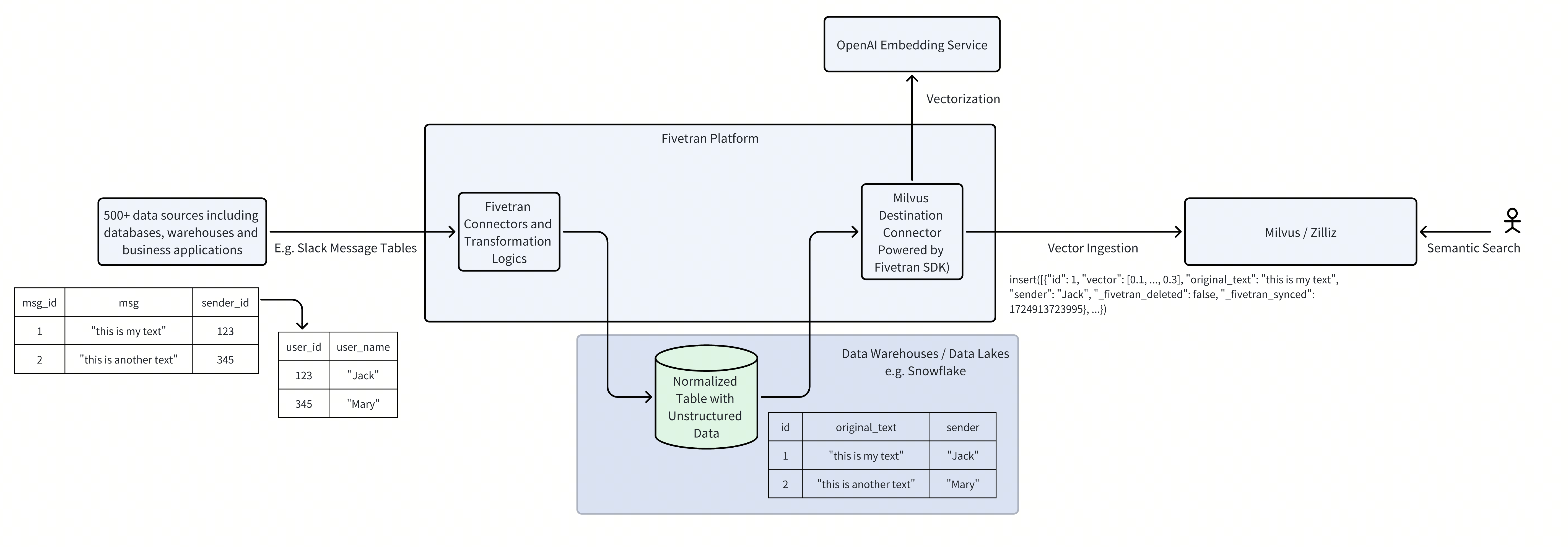
Fivetran now supports Milvus vector database as a destination, making it easier to onboard every data source for RAG and AI-powered search. Fivetran is a cloud-based data movement platform that makes it easy to extract, load, and transform data between a variety of sources and destinations. Fivetran connects over 500 sources, such as databases/warehouses, SaaS applications, ERPs, and files. The newly introduced Fivetran's Milvus Destination further extends the data landscape to make every data source semantic-searchable. By ingesting the source data from a diverse set of database/warehouses and business apps to Milvus vector database, this integration makes the development of AI workflows easier.
In this webinar, we will introduce Fivetran's Milvus Destination and give a live demo on how to use the connector to build a Retrieval-Augmented Generation (RAG) chatbot for GitHub issues with simple configurations.
Topics covered:
- Announcing the launch of Fivetran's Milvus Destination connector
- Demo how to make data from various business apps searchable
- Utilize the information in AI applications such as RAG
So today I'm really pleased to introduce, uh,our session Build AI powered search for every data sourcewith five Tran and Mil. And it is an honor to invite our guest speaker,Aja from Tran, who was a hero behind this integration. Welcome, Aja. Yeah, thank you so much for having me, Jang. Yeah.
Um, so I will, um, do a quick, very quick introductionof VUS and then I'll hand it to you, Aja,and it it will be your stage. Sounds good. Alright. Uh, so my name is Jang. I am, uh, leading the ecosystem and developer relations.
That's why I worked closelywith Five Trend on this integration. Um, so we started the open source vector database productcalled vus because there was a shift in search,the whole search and data paradigm. So in the past two decades,search was mostly about keyword mapping. However, this is very limitedbecause it doesn't really account for the semanticand the essence behind the meaning of the natural languageand, and the keyword that compose it. Uh, for example, if you can't really use keyword search for,you know, image search, um,and sometimes it doesn't account for thingsthat looks very differently,but actually carry the same semanticor, you know, information carried on, um,carried from the visual content like, uh, chartsor like, uh, menusand, uh, even the words that that's, uh, um,that shows up on them.
So this is very limitedand thanks to the fast, uh,the advancement in neural network and deep learning. So now we have the grid tool called inviting model,which can extract the essence from, you know, imagesand textand any other modality so that we can use the outputof the embedding model, which is a vectorto represent the semantic behind any unstructured data. And this is very useful'cause unstructured data nowadays, it accounts for moreand more, um, you know, um, um, portion of thegrowing data in the world. And we have over 80% of the newly generated data in 2025that will be unstructured data. So it's very important for us to have a systematicand efficient way to process and, and comprehendand leverage unstructured data for all kindsof AI applications.
So VUS was designed with this, this, um, this background. And by, uh, and mine side, we want to empower developersto build highly efficientand scalable vector search, which powers their, you know,uh, retrieval augmented generation applicationor image search or product recommendations. And we designed mailbu to be fully distributedcloud native architecture so that it can store indexand manage and use the massive numberof inviting vectors generated by all kinds of workload. Um, and we can, you know, empower developersto focus only on their business logic rather than worry alot about the infrastructures behind this. So right now, VUS is very fortunate to have 20,over 29 K starts on GitHuband over 66 million docker posts.
Thanks a lot for the, um, great research workand, um, you know,all those awesome engineers behind this project. Um, VUS now carries the, um, most high performanceand scalable vector search engine, uh, vector search engine,and we have published a few papers ontop tier database conferences like VLDB, um, you know,sharing about the journey, sharing about the technologythat we have developed, uh, behind,and also, uh, share the takeaways, howto construct a high performanceand scalable vector search system. And, um, thank, uh, andbecause the, there is a growing adoptionof vector search in all kinds of industries and verticals. So that mailbox has been used by thousands of enterprisesand developers in their use cases. So here is just a, an example of some,and it was, uh, is so great and loved by the developersbecause it was designed in, um, um, as a purpose,purpose-built vector database rather than, you know,just adding a plugin to a traditional database sothat this makes this three times fasterand cheaper than the other plugable vector search library.
Um, and also thanks to some, uh,careful design on the storage system sothat it has tier storage. It can put the data, uh, only the most important and,and useful data in the, um,like expensive storage, like memory. And then it use the vector index structureor like memory mapping to, uh,leave the data not frequently accessedto the other cheaper storage. And mul is also cloud native and ES native. So we actually support different deployment modes.
One of them is Kubernetes, which can easily scale to,um, tens of billions of vectors. Um, and then ware, of course, is vector native is designedfor this vector search use cases. Um, but just in addition to this, it also supports a lotof use cases and,and features, um, other than vector search, sothat it will be convenientto use this in your real world application. For example, VU supports hybrid searchwith sparse and dense vector. It supports dynamic schema,or you can directly store a JN inside.
Um, it has the grid securityand privacy features like, um, uh, like rba, uh,and access control and, uh, encryption of data. It also has, um, convenient tools, um, uh,to do, uh, say bulk data import. But today we're gonna talk more about how to use, um, howto import data and extract data in a streaming fashion. And that's where Fiver can play a, a very critical role. And mill can be deployed in various shapes.
Uh, we have mill light, which is great for, uh,local experiment and prototyping. It can be, um, used in, uh, in your laptopor notebook by simply just ping install. We also have on Docker sothat if you have a lightweight small production deploymentand you don't want to touch get, get touch, uh,into Kubernetes, you can use Docker deployment. Of course, we have the Kubernetes, uh,and cloud deployment on Zeus cloud,which is the most performant and scalable option of Millis. And all of these options, they work with the same client co,uh, client side code so that on the client side,you don't need to develop another, you know, pieceof business logic justbecause you have change the shape of the deployment,you just simply need to substitute the, um, networkendpoint from the old deployment to the new deployment.
So that, um, makes it very convenient to migrate things, uh,from different, you know, stagesof the application development lifecycle. And the, um, well, we, um, I I, I will haveto say that the re now the most popular use caseof vector search is retrieval augmented generation. And that's also a central, uh, central topic of today. Um, you know, as you may have seen thisbefore, the retrieval augmented generation usuallyconsists of two parts. One is the on the bottom, that's the offline indexing,where you have all kinds of unstructured data residing, um,in your, you know, databases, business apps,data warehouses,and you want to leverage them bygenerating vector embedding from the deep neural network.
And once you have the vectors, you can importand store them in the vector database for efficient search. And on the top, that's the serving stack. That's the serving workflowwhere a user may ask some questions,and then you use the same embed model that used for, um,offline indexingto generate vector embedding of the search query. And then with the search query, uh, with the search query,uh, with the search vector,you can do a search on vector database. So that will give you semantically similar content.
And with this content, you can prepare your prompt by sub,uh, by filling in the context and the user question. And the large language model can do a much bettergrounded generation auto baseand give you the reliable answer. While this may seem simple,but there's a lot of heavy liftingin the offline indexing part, um, about say,how do I extract the data from various data sources?How do I reliably move them from, uh, one data source to,um, you know, another one vector database?And how do I do the streamlined vector invitinggeneration from this process?So there's a lot of technical challengeswhere five Tran can provide a lot of value, sothat five Tran connects to over 500 data sources,like including all of the business apps and data sourcesand data warehouses, and they can be imported into five Tranand Fiver can automatically movethis in a streaming fashion. Um, and now today with the integration between five Tranand vus, all of the data can be portedto the Vector database destination. Um, so, um, and,and in addition to this, um, thissolution can also streamline the vector inviting generationso that you don't need to, uh, implement business logicto handle this and account for the failures or retries.
Well, without further ado, let's welcome objects from Fiverto give us a more deep dive, uh, overview of, uh, a, a more,uh, detailed overview of this,and then deep dive into the technology behind this. And at the last, we'll have a live demo showing howto build a search for GitHub, for GitHub issueswith five Tri and Milless. Thank you so much, Jang. Uh, love the introduction. Also very interesting to see, you know, all the cooland amazing things BU does.
I feel like, um, just through my experienceof building the integration, I only saw like one thin layerof milus, which is just how Milless stores data,but it's like so interesting to see. There's like a lot more under the hood that just makes itso feature complete, you know, for retrieval and usage. So, awesome, glad, glad that we, uh, did that introduction. Um, so nice to meet a few here. Uh, my name is Abijit.
Uh, I am a staff r and d engineer, uh, here at Five Tran. And today, uh, you know, as, uh, Jiang said, uh,I'll be talking about AI powered search, uh,which we've enabled recently through the integrationbetween Vis and Five Tran built using fiveTran partner, SDK. Just some, uh, brief, uh, details about me. I've been at Five Tran for about, uh,five years now, on and off. Uh, I work in the CTO's office as partof the research and development team.
And, uh, well,my work in the CTO's office is mostly involved in buildingrag applications internally to help our internal teams,you know, our support agents, our HR teams, uh,and our sales teams be able to find knowledge very easily,uh, that they need for their day-to-day jobs. Uh, today we talking about, you know, what is Five Tran,why a good data architecture is important for youto build your RAG app, uh, how VIS can now connectto five Tran and also adjust the demo on, you know,how you can build a searchor a rag application yourself on business data using fiveTran Millis and any other tool. So Five Tran is a automated data movement company. Um, what we do is we move data from point A to point B. It's, uh, as simple as that.
Well, why do we, why do you need five Tran?Um, most of the companies that are trying to, you know,do business analytics, you know, trying to build dashboardsor build reports or even training machine learning models,uh, training AI models. And you know, now more recently, building rag applications,you first have to get all of your data from different, uh,source storages into a central storage layer. Usually the sources are different business applications. You know, few of the examples Jang mentioned earlier,like Salesforce and HubSpot, things like that. Um, GitHub is one example we'll be using in today's demo.
Your data could exist in other, uh, places too,like files like PDFs or Google Docs and Google Drive. It could exist in operational databases likePostgres and MySQL. Um, it could exist in like even streams,you know, like Kafka. Um, and also it could just exist in warehouses themselvesas well, like Snowflake and BigQuery,and usually the destination where you want to put allof this data where you want to centralize all of this databefore you can, um, you know, build your BI or AI model. Downstream is usually a data warehouse or a data lake.
A data warehouse is more apt ifyou're doing business analytics. Uh, data lake is more apt if you're using machine learningand, uh, AI application building. And now, more recently, uh, we support Vector databasesas a destination two. Zillow is the first dedicated vector databasethat Fiver supports as a destination, which meansthat you can very readily using five Tran build, uh,semantic search and rag applications downstream. Uh, in case you've already heard of Five Tran,uh, I won't be surprised.
Uh, we've been here for a while now. We start off in 2012. We got established, uh, a few years later. And since then we've done a whole bunch of, uh, cool stuff. Uh, we've, you know, added a bunch of connectors,bunch of source connectors.
We've added a bunch of different destination supports. We've, um, we've also, uh, you know,know added in multiple strategies to allow youto get the data from these sources into destination. Um, I think in November last year, we crossed the 400 mark,and then very quickly earlier this year,we crossed the 500 mark on the numberof connectors we support. And one of the things we launched, uh,late last year was the partner, SDK,and the partner SDK iswhat enabled this entire integration with VIS to happen. Um, so the partner SDK lets customersor partners of Five Cran come to five Cranand build their own connectors using our GRPC interface.
And that's what Zeus did. Zillow built a mil connector that maps, you know,mil update operations or create tables or create collectionsand create in operations very closelyto the relational operationsthat five Tran usually spits out data in. So using this GRPC interface, um,Millis was successfully ableto create a mil destination for five Tran. Um, and most of the topic that I'll be talking about is how,you know, you need a good data architecturefor building a good rag application. Um, and maybe you've heard this term floating around,you know, shed data, s**t,ai it becomes very true when you start, you start dealingwith like enterprise level workloadswhere you have huge volumes of data that you need to start,you know, maintaining and feeding into Rag app.
And you also have to keep your downstream applicationin sync with the source application. Um, like, 'cause the changes inthe source could be very fast. And you now have to propagate not just the data,but also the changes through the downstream application sothat you know, your, uh, downstream, you know, chat botor copilot or whatever you're building is up to datewith all the knowledge it needs to maintain. Um, in the beginning of this year, uh, I was trying to,I was working on a project where I was tryingto build an automation for our, you know,our customer facing support form. So this is what the support, uh,looks like on the five front dashboard.
In case you've not seen five front before. On the left is how our dashboard looks like. You have a bunch of connectors that you can set up. You have transformations, you can register five frontthat go and modify the dataor model the data based on your requirements. Uh, in case you face any issue with our connectorsor transformations, you can, you know, click on the small,you know, chat icon that's on the bottom right cornerthat pops up a chat window for you.
So right now, this chat is completely manned. Uh, there's, uh, you know, there's a support, uh,or sales agent sitting behind it, uh, from five tryingto answer questions for different customers. And what this means is that our support process is notas fast as it can be. Uh, there's also some downtime, you know,when our support agents are asleepand, you know, customers are workingfrom a different time zone. And we're try and see how we can, uh,help our support agents become more efficientby just giving them better tools to be ableto easily search across the breadth of knowledge.
Five Trend contains, and this is especially importantfor Five Trend 'cause you know, the breadthof Connectors five Trend has is so largethat it is like humanly impossible for, uh, you know,one single agent to be an expert in allof these different connectors or, you know, sourceand destination integrations that we support. So mostof our knowledge is present in these applications that you can see on the left. You know, it's present in chat applications like Slack, uh,which contains internal communication, or Zendeskand Salesforce, which contain communicationbetween five cran employees and externally. Um, or even height. Height is like a project management toolwhere engineers communicate with other departments like,you know, product and, uh, sales and support.
Uh, we also have internal VPsand, you know, technical design documentsand architecture diagramsand things like that present in Google Docs and Slab. And also we have our own public website, you know,tran. com/docs that contains a lotof the troubleshooting steps that are public facing. And also, GitHub contains all of our code of, you know,the issues and pull requestsand things like that, that, uh, explain different issues. They came up and also contain detailsof resolutions to different issues.
So all of this knowledge needs to be easily searchableby our support agents, um, to quickly be able to, you know,find an answer and respond to the customer. And by doing this, our support workflow becomesso much more efficient, uh, withoutand reduces the amount of, you know, downtime that is there,or the amount or the time to respondto the customer becomes like far lessthan it originally was. And in this process, you know,I was building this application internally. Uh, I was also evaluating a few companies externally, um,who were solving the same problem, building a RAG appthat can ingest multiple data sources. And in these discussions, we found out that mostof these companies that were building these applications,uh, they looked like this when you took a peak under thehood, uh, you know, it's, well,they have a Pringle scan trying to run the car.
It's, it's pretty brittle, it's pretty broken. Um, it, it can get the car running,but it's not gonna run for long. The problem is that keeping up with the data, um,the volume, keeping up with the changes, tryingto unify the data model from different sources, making surethat you have I potency in the data movement. And also figuring out like your infrastructure, right,for moving the data. All of these are very hard challenges once you start dealingwith data at scale that end up, you know, requiring youto just like, hire huge engineering teamsto solve those problems,solve the big data movement problem.
But, um, these, well, these, uh, companiesthat are building these AI applications, well,they aren't like data skill data engineerswho are just accustomed to building solutions for this,which means that they want to be ableto spend more time downstream building the AI stuff,you know, actually using, you know, GPT or, uh, PyTorchor, you know, those tools downstream,building very good applicationsand not have to care too much about like,the acquisition of the data. 'cause that is the downstream, you know,solving the AI problem is the really hard problem. And getting the data isn't just, isn't really that hard. It's just very, um, tiresome to do. There's a lot of effort that needs to go into it.
And most of these applications, um, they have architecture,uh, as I'm showing you here on the screen, the bunchof sources where the data originally lives,and you get the data of those places, uh,centralize it into a data warehouse or a data lake. Um, and then once it's there, you can do your, you know,cleaning, your pre-processing any sort of transformationsfor RAG applications. These are specifically concatenating and chunking. I think those are the most common operations you performto be able to do rag. And once you've transformed your data,once you've built your data model that's appropriatefor your application, you can then move the datainto a dedicated vector store.
You'll have to vectorize the data in between using,you know, some embedding model provideror, you know, you can download your own open sourceembedding model and do it yourself,but you have to generate the vectorsbefore it ends up in a vector store, like, uh, VUor, uh, hosted VUS like Zillow. And once it's there, well that's it. You have, you have your data in the storage layerthat you need it to be in,and you can then perform, you know, search or ragor analytics as well downstream of it. And that is like the core problemthat all these comp all the companies that needto spend their effort solving. So, you know, the vis destination connectorthat we built using the five trend partner, SDK,enables this entire architecture.
And it makes it very easy for youto set up this architecture yourself with just a few clicks. Um, just diving into a little more details, you know,what are the different, uh, tools that would,that you would need to use to set this up?So you have your data sources, um, in different places. Um, you would first need to get this data outof these sources into a data repository. And you can use a tool, a data movement tool like five Tranto extract the dataand then load it into your warehouse or your data lake. Five tran supports, uh,multiple data warehouses like Snowflake, BigQuery, Redshift,uh, DA Databricks as well.
And then we also support open table format data lakes. If you don't want to use one of these manageddata warehouses, you can just bring like an AWS accountor Azure account, and we can still landtables in an open table format in these data lakes. Once this data is present in your data repositoryor your data platform,you can then trigger transformations on top of it. Um, you can use, you can just use like Python scripts. You can run sql or you can use frameworksand tools like Coalesceand DBT to help you easily build those transformations.
And once you've gotten your data model ready, well,the next step is moving it into the Vector database, right?Vectorizing your data using an embedding servicelike Open Air Cohere,and then moving it into the Vector database. The problem is that, you know, all of the companies, uh,we've evaluated, well, it's like, you know, well,the second part of it is sort of duct taped together. Uh, they've hacked different pieces to make it happen,which makes it very brittle. So it's like, you know, it's gonna be, it's gonna get you,um, through the POC phase,but to actually make your application production ready,you're gonna end up having to hire a huge engineering teamto just solve that one small piece of the puzzle. Luckily, uh, for us, we have the destination connector.
Now, using the part built, using the partner SDK,that automatically extracts the data from the, you know,data repository, vectorize it in flight,and then puts it into the Vector database, you know, VUSor hosted Mils on Zillow, it puts it automatically. And all you have to do to set this pipeline up isjust a few clicks. Um, you go to a five trend dashboard, you click, you know,here, here, here, two, three buttons, and then that's it. You now have a pipeline that's gonna be extracting your dataand then keeping your vector database, uh, in syncwith your source application. Um, so yeah, that's it, that's all you needto build a semantic search application end to end.
Um, if you wanna take it one step forward, you know, as in,as in the architecture that Giang mentioned,you can build RAG applications too. Rag helps you more,helps you search across the information in a wholemore human-like format. You know where an LLM well, it reads the documentsthat are relevant, and then it sort of processes it, uh,it reasons around the data that's present, it triesto correlate it with the questionand then provides a more human-likeresponse to the end user. So, uh, this is the architecture, um, that, you know,that works best for different companies. And now we have two connectorsand different tools in between that are connected end to endto enable this process seamlessly for different businesses.
And, uh, for the rest of this, uh, you know, webinar,I'll be focusing on presenting a demo application builtusing this architecture. And I'll be choosing just one, one of each type of toolto enable this application. So for the source, I chose GitHub. Um, GitHub you know, is the code managementand code collaboration, uh, tool that many companies use. And GitHub also contains, apart from just just the code,it contains some artifacts that help users collaborate,you know, issues that represent information about what'sgoing wrong with the code or questions just people haveor features they want from your product.
And, you know, issues allow issue comments to be creative,which means that different users can engage in conversationright on the code collaboration tool. So we are gonna use GitHub as the source for this example. That helps, you know, you answer questions about yourdifferent, well d answers,different questions about your product. Um, just from a more technical perspective. Uh, so first step, we set up a five tran connectorto get the data out of GitHub, put it into Snowflake.
Um, you know, five Tran is gonna land the data in its wrongform in a bunch of relational tables. Uh, for this demo, we are gonna be focusing on specspecific tables around the issue entity. So like, you know, comments for different issues,the assignee for different issues, um, different tags addedto the issue, and, you know, just whichrepository the issue belongs to, right?This information, we won't go into other things like theGitHub Wiki or the code,and also, you know, the pullrequests and other things like that. We'll just focus on issues too. Just make this demo simple.
So once you have the raw tables in Snowflake, um,you can use a data transformation tool like DBTto data model this, um, you know,concatenate all the relevant information,do the join across this data,and then build a flat table that then can be searched upon. A flat table is one of the requirements, uh,for building a search application,because usually you want, you know,you wanna build your rec vectorsand one vector would correspond to each row. And that is also the, you know,hard concretely defined input format for vector databases,like, you know, vis. So the DBT transformation helps you get yourtable into this form. And once it's in that form, you can then, you know,use the second stage connector build using the partner SDKto get this data into, uh,vis orus in flight.
Uh, currently this connector supports usingopen AI embedding service. Uh, we do have plans to expand this offering further, uh,to more embedding service, uh, as you know,as the demand grows. But for now, I think most of the customers, well, they,they're okay with using just open eyes embedding service'cause well, so far, uh, from our experience,they have pretty good quality. And also, uh, it's, it isn't like, it isn'tthat expensive in figuring out how to host models yourself. They give you like an API to easily embed data.
So once you set up, you know, the two five D pipelinesand the DBT model in Snowflake, um, you're good to go. You have all of your data then in, uh, vis,and for this example, again,I'll be using hosted VIS on Zillow'cause it just makes it very simple for meto manage the Vector databaseand also demonstrate its capabilities. But as Jang mentioned, you can,you can host VUS in multiple different ways. Um, whatever is appropriate for your business use case. And at the end, to just demonstrate the search capabilities,I built a, well, a, a very simple chat applicationthat uses the semantic search backend to produce answers.
We won't be building this chat application during this demo,but this is just to show you what you could be doing. Once you have, uh, end-to-end Semanticsearch solution set up. There are, there are five steps to get you, um,the system up and running. Uh, first go to five Trend account,set up a Snowflake destination. It is just three steps.
You click on Add Destination,you create a Snowflake connector,and then you plug in your credentials. You then create a GitHub to Snowflake connector, um,where you click on add connector,and then you plug in your credentials. Again, you may be pointedto specific repositories if you don't wantto pull in all your data. And then once that's done,the third step is the DBT transformation. Uh, this again, just requires some configuration.
You plug in your credentialsand you also point to the GitHub repositorywhere your DBT model is, uh, written and stored. I will go into a little more details about this, uh,later in the live demo. And I'll show you, you know, what the models look like,but once you have, you know, your Snowflake destination,your connector and your DBT setup, then you're readyto set up a second stage pipeline. So then you can go and create a VUS destination. Again, as simple as it wasbefore, you just come to five Tran,you click on add destination,plug in your credentials, and you're good to go.
So you now have two destinations. You have one connector, you set up the other connector,the second stage connector that extracts vectorizeand loads data in flight. And again, come to fiver, click on add connector,plug in your credentials for the source,and boom, you're good to go. So five different configuration steps is all you needto get your system running end to end. You don't need to, well write a lot of code.
Um, the only place you would probably needto do custom configurations is in the DBT stepwhere you have to model your data appropriatelyfor your business application. But what,what this system helps you is it takes away the need for youto, you know, um, well write your code to wraparound the source, API, you know, the GitHub's rest, APIor the web, web hook, APIor you know, the VU GRPC interface. You need to program all of that. Anymore of that becomes standardizedand you focus more on just data modeling your datafor your downstream application. So, yeah, uh, I'll switch to a live demo now.
Um, just showing you, you know, the different,just the different screens, uh, I presented. Uh, one of the things I did beforehand, uh, justto save time during the webinar, is I set up someof these connectors alreadyand got them syncing so that, you know,we don't spend too much time doing the setup information,the setup configuration here. So this is the five front dashboard. And as you can see, uh, I have two connectors set up. The first connector is syncing data fromGitHub to Snowflake.
Uh, and the second connector is syncingfrom Snowflake to Zillow. Again, in case you're curious how you can set this upyourself, you can just click on add connector, go here,choose the type of, uh, source you want. So let's say GitHub and then, you know, click on setup, uh,setup and plug in your credentials here. I'm not gonna do this again'cause I already have the connector set up. And to set up a destination, you could just goto destinations on the left side, click on add destination,uh, or here you have, you know, our whole listof destinations and you'll seethat VIS is available is currently in preview.
So you can go and set up a vis destination. Um, you have to name your destination first,so let's call it desk destination. And, uh, or here you just have to plug in your credentials. My internet might, might be a little bit slow today,so this might take a few seconds to show up,but it's, you know, as simple as it was, it iswith setting up the other parts of the system,which is you come here, you plug in your credentials. Um, one of the extra things you need to provideto this destination comparing to other destinations isthat you need an open AI token.
And that's pretty much because cloud currently,we only support open AI as the embedding serviceto generate the vectors in flight. But maybe in due, you know, over time, this, uh,this could be expanded to other models toothat can run locally as well. And you know, this connector says vu, but you can useand VU deployed anywhere. And, you know, uh, VU can be deployed locally. It could be deployed on Kubernetes.
It can also be, you can also be using ahosted mil with some Zillow. So you can just come here and put in your Zillow URL,your Zillow API key, and then, you know, your open AI token,and you should be good to go. You can then go, you know, you have a connector set up. So I have these two connectors, uh, currently thinking, um,the GitHub connector constantly fetches data from,you know, GitHub source. Anytime there's an update to the source application, um,it's gonna pull the data into the downstream application.
Oh, by the way, for, for this example, I am using, um, oneof the open source repositories called tahi. So Tahi is, uh, open source, uh,machine learning framework that lets you processand encode unstructured data very seamlessly. And this is completely open source, which I chose,which is why I chose to use thisfor the example application. It has a bunch of issues. It looks like there are five open issues,and then, you know, a bunch of closed issues, eachof them having conversations talking about, you know,different exceptions that customersor, you know, users came acrossor different features users want,and then some labels assigned to it.
What, what the issue can appropriately be tagged as. And also conversations on the issues, providing resolutionsor providing updates on the issue. So once you have the, you know, five tran connector set upsyncing from GitHub to Snowflake, um, you should be ableto see the data in your, uh, snowflake account immediately. So as you can see here, each sync takes around 35 seconds. And, um, uh, these are incremental syncs.
So your first sync might take a few minutes,but then your incremental syncs, you know,they're very short, they're very fast,and they only pull the datathat was updated since the last sync into your warehouse. And they pa you know, patch the data in the warehouse. So since I have this connector set up, I can goto Snowflake, uh, go to my data,and, you know, uh, in my database I can goand see that, oh yeah, my tables are present. I have all the different tablesthat I can extract from GitHub. And for this, you know, for this example,we'll be focusing on just a few tables around issues.
So if you go and see, you know, our issue table, you'll seethat there is, there is data present in the issue tables. Turns out, um, there are around 2. 7 K issuesor rows that are, you know, uh, probably normalized, uh,versions of the issues. And you have, you know, issues that are open, issuesthat are closed, all the detailspertaining to a specific issue. And similarly, you would have like issue comments too, wherefor each, um, issue you, for each issue comment,you would have the ID of that comment.
But then, you know, the foreign key referencing the originalissue that lets you do the join across these data sets. And then, um, the details that are actually important forbuilding the rag up, which is the bodyor the actual content of the issue comment. And we'll be using, you know, the body from the issue,comment on the issue along with some other metadatato build a vectors on top of it. So yeah, you have this connector running, um,you have this sinking to the warehouseand once every sink happens, uh,we have a transformation set up. So, or here, uh,I've registered a transformation, uh,which creates a table called issue Extended five trendsupports, you know, bringing your own transformationby attaching a GitHub repository Air Code Restore.
But it also supports, um,just providing quick start data models. So quick starts are templatesof these different transformations Five Trend has built. Um, you can take a look at them, uh, on our repository. They're open source right now,but you can use either a modelsor you can build your own models in case you're curious onwhat a data DBT model is,is just a SQL is just a SQL command. So I have some SQL commands written here in my GitHubrepository, which is also open source.
So you can check this out if you want. So oneof the things I'm doing is I'm taking the different fieldsfrom the GitHub data, like, you know, the issue id,the issue number, the state of the issue,whether it's closed or open, the body,which is the actual content of the issue, alongwith some other metadata from other tables like the userwho created the issueor the user who the issue is assigned to. And I'm taking all of this,I'm just shoving it into like a verymarked down like document. And the reason we're doing this is'cause this is like the most understandable form of data forthe downstream, you know, vector embedding, uh, modelsor large language models. They can understand these type of long text very well.
So we sort of take the semi-structured data,we convert it into an unstructured document. And once, you know, once you write the SQL queryand you register it with five,five triggers it every time a syn Chrons. So the GitHub schema contains the source data inits raws form possible with some very light massaging. And then the GitHub for RAG is the DBT model I registered. And you can see that you now have, you know,the concatenated data present here.
So you have your idand then you know, the content,which is the column I created with all of this information. Um, Let's see if I can, if I can, uh,show a more com expanded version of this content,Um, Back from database. Yeah. Okay. Logstar issue.
Okay,So we now have a more, you know,like a more complete version of the issue. This is very similar to how, you know, a human would, um,look at or understand an issue on GitHub. You have the metadata, you have some metadata,you have the description of the issue as, you know,the end user presented it. And then in case there are comments, uh,you probably have some comments too. So I think this one has some comments.
Yeah, so there are a few comments here along with the issuethat shows, you know, all of the informationabout one particular object compressedinto a single document. So once you have that, you know, the data in that form,you can go back to five tran. You can go and set up a second stage pipeline that movesthat data from, you know, snowflakeor whatever data repository you're using to Zillowor vus, uh, hosted anywhere you like. And all you need to do is, you know, just,just set up this connector, uh,by plugging your credentials. Uh, in the schema tab, you can choose which tables you wantto vectorize load vu.
So in my Snowflake instance, I had like a bunchof different tables, but I only want this table,the issue extended table to be vectorized. So I just registered that here in the schema tab. And one thing that is important to note is that, uh,right now VUor the milli connector requires a specific columnto be present in the source table. Um, and the column should be named, uh, let's seewhat the name of that column is. Issue extended.
Um,yeah, so these are the columns for the table. And Millis connector specifically requires a columnnamed original text to be present. And that is the column on which the vectors will be built. And you need to ensure that, you know,while you're selecting your table on the five front side,that table has that column present. And it's also, you know, it's un hashed, it's unblocked,and it it is of string type.
There's another requirement to, so yeah, once you have,you know, the second connector set upand it's syncing all of your, uh,modeled compressed GitHub data to Zillow,um, you're good to go. You have like a semantic search application ready. Uh, so I'm gonna shift to my Zillow instance here,and you can now see, you know, a Zillow, uh,a VUS cluster hosted on Zillow. Um, it's currently hosted on the GCP,but I think you can configure itto host in different clouds too. And I have a collection, you know, this is the collectionthat was automatically created by five Tran.
It has the same schema as the table in Snowflake,or it con includes all of the columnsthat are present in the source GitHub entity. And you'll see that, you know, there's allof this data that's present here. You have all the details about the issues,like the issue number, the issues title, the issues, um,body and things like that. And in case you wanna do just vector searchor just semantic search, you can do it like right herefrom the Zillow dashboard itself. Um, you do need to generate a vector, uh,before you can search for it.
Uh, and since we're using open Eyes embed model,I wrote like a simple script to generate that for me. So, uh, ask a question related to Tau. He, um, let me ask, uh, whatthe, the t he supportmultiple GPUs. I remember reading that question earlier in the repository. Uh, so yeah, let's, let's generate a vector for this.
I'm using the OpenAI embedding model, by the way,to generate this one. Uh, and I'm using text large. Uh, OpenAI supports three embedding models, uh,ada, small and large. I just use text large, um, for this example. But if, you know, you need to save some costs,you can use like a smaller model if you're okaywith some quality loss.
Okay, it created the embedding, I'm gonna put it in hereand, um, I can hit search. And now, uh, I have, you know, the top, top results,uh, relevant to my question. And you can see that, you know, my question,which was related to GPUs is pulling out issues from thesedifferent, uh, from this dataset, uh, that are relatedto like, you know, my question, which is like,does it supportmultiple graphics cards and things like that?Uh, my model also has, uh, URL. So if you go, you know, if you just go, um, to that URL,you can see that you now have the original documentthat you want to look at. So this, you know, this, uh,document talks about a user question.
This issue talks about a user questionwhere he is asking about whether he can support multipleGPUs with Tahi or not. So yeah, now you know,you have an end-to-end semantic search application, uh,built just by using a few clicks. You had to do very minimal click coding. You, you had to do your data modeling yourself,but that's all you need to do. And that's, you know, that's the most important piece of it,which is being able to figure out the right modelfor your downstream application, for the kindof application you are buildingand not being logged into the data model.
Um, you know, you'd find from the source to be ableto search across this data. Um, and yeah, now you know, the limits are endless. You can, you can take this semantic search application,you can build a rag application, you can build a chat bot,you can build a copi, and you can buildsomething more agentic. Yeah, so many things you could do downstream once you haveyour data, and you know, this up,this appropriate storage layer completely indexed to. So that is, that is, uh, most of you know, the workthat we did to, um, build a connectorand enable the system, uh, to just demonstrate, you know,further capabilities of where the system could go.
I built a chat bot, uh, using open source, uh,just frameworks like stream lit and long chain. So this chat bot, um, well,it takes in your Zillow credentials, uh,where your vis is hostedand where, you know, five trying is syncing data to. So let's plug in the Zillow credentials. Um, yeah, so you need your endpoint, you need your,uh, API key, very easyto copy from the Zillow website. You need your open AI key.
So I have my open AI key here. Um, oh, by the way, once you plug in these credentials,this application automatically detects, um,collections in your Zillow that are synced using five Tran. So you don't really have to do more configurationto point to these sources. You can just come here and just select which source you wantto, you know, chat with. Um, and I use the largemodel, not the small one.
And the open AI key is here. I plug this in, and now, um, I have mychat application ready to go. I can go and ask questions, uh, related to my, you know,TAHI repository. Uh, so let's say, let's say ask one state, um,what question can I ask?Okay, so this is, this is another exampleof a specific question that was asked by a tahi user. So he said, uh, can clip modelsupport, local model path,um, turns out, you know, uh, it can support local model pathand then you can support it by using this, um, parameter.
Uh, and, you know, it gives me this answer'cause I was able to find this information from theknowledge base that was provided. And, uh, it looks like, you know,this information is present in one of these different, uh,tickets on GitHub, so let's go take a lookat the most relevant one. So yeah, it seems like, you know,the most relevant one is the user asking this question,you know, how to use local model path. And then you can see that one of therepository maintainers responded saying that, you know,it's a ports checkpoint path. So just through conversations from, you know,around your product, you can askspecific questions about your product.
And this just like alleviates the need for you to goand like, look at different issuesor look at different knowledge sourcesand be able to easily,easily like search across your company datawith just like a natural language interface. Um, you can ask, you know,another question if you're interested. Uh, let's see, what else is interesting from the repository?Ooh, okay, A question about memory leaks. Memory leaks are always interesting. Outof effects, uh, sorry, outof effects,uh, memory leak and audio and embedand pipeline.
Also for this application, I'm, I've limited itto just five sources, um,because I'm using like one of the smaller GPT models,but you can, you can, you know, uh, expand the numberof sources you want the application to look at based onhow powerful of a model you're using on, you know,how much money you're willing to spend as well. So it looks like, you know, I asked, I asked for, um, just ahow to on fixing memory leaks,and it gave me a bunch of steps. It looked up different sources to understand those steps. And if you go take a look at the most relevant source,um, so maybe this is not completely relatedto memory leaks, but I think it picked up a few, a few,you know, things from herebecause of, uh, where like memory and things like that. So, you know, memory, and then maybe something else issomewhere later in the thing,but, oh yeah, this is the one I was looking for.
So this is the issue that's actually relevantto the question being asked,where they're asking about the audio embedding pipelineand how to prevent memory leaks. And, you know, in the conversation, uh, there are stepsthat can help you resolve this issue,and it was able to pick up on all of this informationand provide a natural language response around it. So yeah, you know, the possibilities of you building, uh,rag apps or chat apps are endless once you have the datathat you wanna build the application on. And the, you know, latest five trend connector that,uh, syncsto mill just enables this much more seamlessly for businesses. If you wanna, if you know, if you are, if you goand build this pipeline yourselfand you wanna see if it's working,you can try the chat app yourself too.
Um, it's hosted at this URL five Friends do Streamlet app. Um, you just have go here, um,plug in your Zillow credentials, you know,wherever you set up these five trend pipelines too. And once you have that set up, uh, you should be ableto immediately chat with your dataand also, you know, navigate to the sources, uh,that these applications are citingas sources in the response. So, yeah, that's it. Uh, that's it for me.
Uh, I had a really great time, uh, working on this project. Uh, it was really interesting for me to see, you know, justhow, how easier it is now for companiesto search across their data, including ourself. Uh, I feel like Five Tran is one of the biggest, uh,power users of RAG apps internally just due to the breadthof knowledge we have. And now with, with the Zillow integrationand just with VUS Vector database,this just becomes like a whole lot easierfor us than other companies to build such applications. So yeah, thank you so much Jang,for giving me this opportunity to work on thisand, uh, excited to see, you know, uh, how,how we expand this further.
Well, thank you so much ABJ for the great talk,and I'm really impressed by the demo at the end. Um, and I, I think this technology will allow a lotof interesting applications like chat bot, internal kindof knowledge base and everything, um, powered by ai, um, AIand, and search technologies. Uh, while we do have, uh, a few questions from the audience,um, uh, the first one is,does five Tran offer any free credits?So five trends, uh, free for the first 14 days actually,so you can self service sign up, you can try it out. Um, I think the first, the initial sync is freeand then you get like 14 days free for the entire account. Um, and thenafter that, uh, I think there are chances you can get freecredits if you talk to our sales teamand, you know, discuss whatyou're trying to build at Five Tran.
But the first 14 days is just completely self-service. You come to five Tran, um,I don't even know if you have to put a credit card. Like maybe you don't even have to put a credit card. You can just like try it outand see if it fits your needs. Yeah.
Awesome. Sounds good. Uh, give it the try everybody. Uh, what is the second question? What is the chat app?Uh, I think, uh, the audience was askingfor the link for the chat app. Oh yeah.
So the link is here, it's five trendzRag Stream app. Um, so it's already deployed, so you can try it out. Um, you just need to set up those pipelines first to be ableto feed the data into this application downstream. So yeah, if you are, if you're,if you're already a five front customer,it should be like very familiar to you. If not, uh, you know,you can just follow the steps I've described in thispresentation to set up those pipelines.
Yeah, let's, um, let's just have the, uh, actually I can,I can just send the link, uh, in the chat. Okay, here we go. Um, I think that's all the questions from the audience,and we're right on time. Well, thank you again, abj,for presenting this awesome integration and,and the fancy demo here. Um, and for, you know, anyone interested in this, we have,uh, put the link in the chat, uh,about the integration about the chat app that, uh,ABJ has just shown here.
Um, and also, um,if you are interested in learning more about thistechnology, feel free to reach out to our sales teamsthrough contact sales on ZI or Demo five 20. And we're happy to help you set up the, um, you know,the technology and,and get your, get your bus, uh, get your business powered byAI and Vector Search. Well, thank you again ab just, uh, I thinkthat will be the everything in this webinar. And thank you everybody for being here. Um, you know, with us, we hope that we can hear from you.
Um, and also please check the upcoming events, linkand resources, um, and welcome to our future webinars. Well, thanks everybody. Have a good day. Thanks so much. Bye-Bye bye.

Join the Webinar
Loading...
Meet the Speaker
Join the session for live Q&A with the speaker

Abhijeeth Padarthi
Staff Research and Development Engineer, Fivetran
Abhijeeth Padarthi is a member of the CTO's Office at Fivetran, with over 5 years of experience in building data pipelines and data lakes. He focuses on leveraging AI to help businesses easily search across their datasets, driving innovation in data accessibility and integration.