




De palabras a vectores: Comprender Word2Vec en el procesamiento del lenguaje natural (PLN)
De palabras a vectores: Comprender Word2Vec en el procesamiento del lenguaje natural (PLN)
¿Qué es Word2Vec?
Word2Vec es un modelo de aprendizaje automático que convierte palabras en[ representaciones vectoriales] numéricas (https://zilliz.com/glossary/vector-embeddings) para capturar sus significados basándose en el contexto en el que aparecen. Desarrollado por Tomas Mikolov y su equipo en Google, utiliza grandes conjuntos de datos de texto para comprender las relaciones entre palabras y representar similitudes semánticas y sintácticas. A diferencia de los métodos tradicionales, como la codificación de una sola palabra, Word2Vec crea incrustaciones densas y significativas en las que palabras similares se sitúan más cerca en un espacio vectorial continuo. Word2Vec se utiliza ampliamente en aplicaciones de Procesamiento del Lenguaje Natural como el análisis de sentimientos y los sistemas de recomendación.
¿Por qué necesitamos Word2Vec?
Comprender las relaciones y significados de las palabras es un reto fundamental en el Procesamiento del Lenguaje Natural (PLN). Los métodos tradicionales, como la codificación one-hot, representan las palabras como vectores dispersos de alta dimensión en los que cada palabra es independiente de las demás. Este método no capta las relaciones semánticas o sintácticas entre las palabras. Por ejemplo, en una codificación de un solo punto, los vectores de "rey" y "reina" parecerían completamente independientes, aunque sus significados estén estrechamente relacionados.
Además, estas representaciones dispersas son ineficaces desde el punto de vista informático, sobre todo para vocabularios extensos, y no se generalizan bien a palabras o contextos desconocidos. Esta limitación ha dificultado que las máquinas entiendan realmente el lenguaje, obstaculizando el progreso en tareas como la traducción automática, el análisis de sentimientos y la clasificación de búsquedas.
Word2Vec resuelve estos problemas creando [incrustaciones de palabras] compactas y densas (https://zilliz.com/ai-faq/what-is-word-embedding) que representan las relaciones entre las palabras en función de cómo aparecen en el texto. Al captar tanto el significado de las palabras como su contexto, Word2Vec ha transformado la forma en que las máquinas interpretan y procesan el lenguaje humano, haciéndolo más eficaz y significativo.
¿Cómo funciona Word2Vec?
El núcleo de Word2Vec son las incrustaciones de palabras, que son [vectores densos] de baja dimensión (https://zilliz.com/learn/dense-vector-in-ai-maximize-data-potential-in-machine-learning) que captan las propiedades semánticas y sintácticas de las palabras. Word2Vec analiza grandes volúmenes de texto para aprender las relaciones entre las palabras. En esencia, se trata de una [red neuronal] superficial(https://zilliz.com/learn/Neural-Networks-and-Embeddings-for-Language-Models) que genera representaciones vectoriales de las palabras, capturando sus significados semántico y sintáctico. El modelo identifica patrones en la forma en que las palabras aparecen juntas en las frases y utiliza esta información para situar las palabras relacionadas más cerca unas de otras en un espacio vectorial continuo.
El concepto principal es que los vectores similares representan palabras con significados o contextos de uso similares. Por ejemplo, las palabras "rey" y "reina" tendrán vectores estrechamente relacionados, con diferencias que codifican distinciones semánticas específicas, como el género.
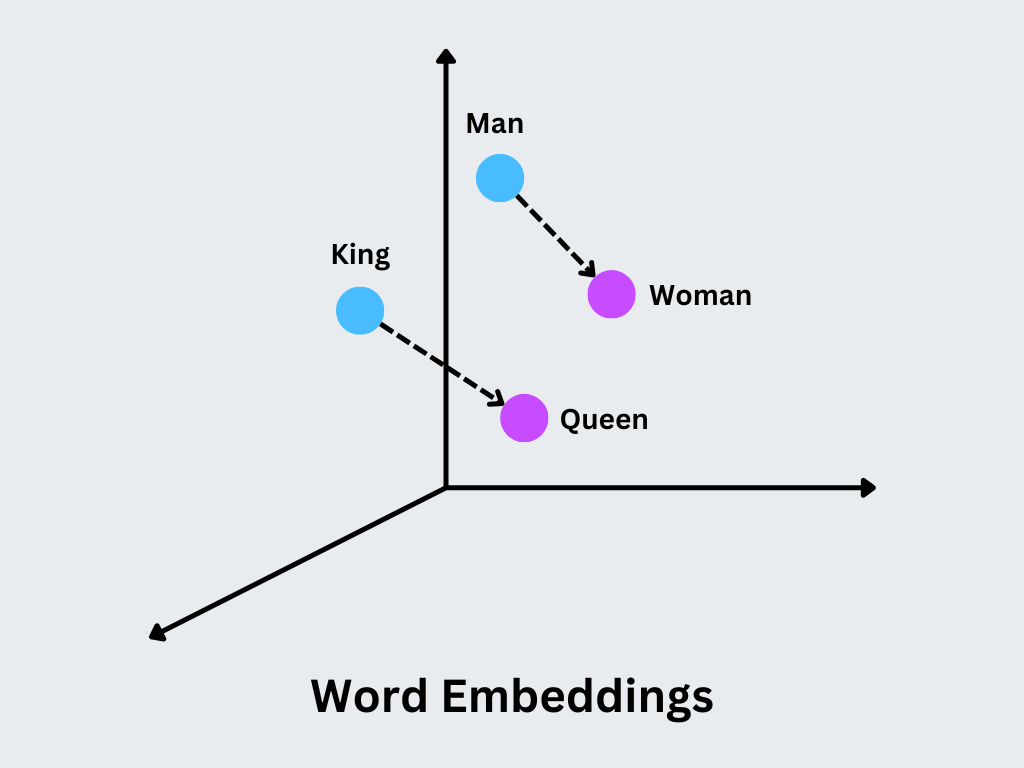 Figura- Word Embeddings.png
Figura- Word Embeddings.png
**Figura:Incrustación de palabras
Word2Vec ofrece dos enfoques para generar incrustaciones, dependiendo de cómo se maneje el contexto:
Bolsa continua de palabras (CBOW)
La [bolsa de palabras] continua (https://zilliz.com/learn/introduction-to-natural-language-processing-tokens-ngrams-bag-of-words-models#Bag-of-Words-Models) se centra en predecir una palabra objetivo basándose en las palabras que la rodean. Por ejemplo, en la frase "Las manzanas son dulces y jugosas", CBOW utiliza las palabras del contexto ("Manzanas", "son", "y" y "jugosas") para predecir la palabra objetivo, como "dulce".
CBOW es eficiente desde el punto de vista computacional porque promedia las palabras del contexto para predecir la palabra objetivo. Sin embargo, funciona mejor con palabras frecuentes y puede tener problemas con términos poco frecuentes.
Caso de uso: CBOW se utiliza habitualmente en aplicaciones como autocompletar y corrección ortográfica, donde es necesario predecir una palabra omitida o la siguiente.
Modelo Skip-Gram
El modelo Skip-Gram invierte el proceso de predicción. En lugar de predecir una palabra objetivo a partir de su contexto, predice las palabras del contexto basándose en una palabra objetivo. Por ejemplo, si la palabra objetivo es "dulce", Skip-Gram predice las palabras de contexto "Manzanas", "son", "y" y "jugosas".
Skip-Gram maneja mejor las palabras raras y es especialmente eficaz para captar relaciones más matizadas cuando se trabaja con grandes conjuntos de datos.
Caso de uso: Skip-Gram es valioso en tareas como la creación de sistemas de recomendación o la agrupación de términos similares en campos especializados.
Figura- CBOW vs Skip-gram.png](https://assets.zilliz.com/Figure_CBOW_vs_Skip_gram_90761e61ca.png)
Figura: CBOW vs Skip-gram
Diferencia entre el modelo CBOW y el Skip-Gram
Aunque tanto el CBOW como el Skip-Gram pretenden representar las palabras de forma significativa, difieren en la forma en que procesan y predicen las palabras en función del contexto. A continuación se ofrece una comparación que pone de relieve las principales diferencias entre estos dos enfoques:
| Feature | Continuous Bag of Words (CBOW) | Skip-Gram |
|---|---|---|
| Objetivo | Determina la palabra objetivo utilizando el contexto circundante. | Predice las palabras del contexto basándose en la palabra objetivo. |
| Eficiencia. Más rápido de entrenar. | Más lento de entrenar. | |
| Trabaja bien con palabras frecuentes. | Maneja eficazmente palabras poco frecuentes. | |
| Complejidad | Más simple y eficiente computacionalmente. | Más complejo e intensivo computacionalmente. |
| Caso de uso | Adecuado para tareas como predicción de palabras y autocorrección. | Ideal para tareas especializadas como los sistemas de recomendación. |
| Ventana de contexto | Considera la media de todas las palabras de contexto. | Evalúa palabras de contexto individuales por separado. |
| Requisito de tamaño del conjunto de datos | Funciona bien con conjuntos de datos pequeños. | Funciona mejor con conjuntos de datos grandes. |
| Ejemplo: Predice "ladrando" a partir de "El perro es ___". | Predice "El", "perro" y "es" a partir de "ladrando". |
Tabla: CBOW vs Skip-Gram
Implementación de Word2Vec en Python
A continuación se muestra la implementación en Python de Word2Vec utilizando los métodos CBOW y Skip-Gram. Este código se entrena en un pequeño conjunto de datos personalizados para aprender incrustaciones de palabras, demostrando cómo funcionan ambos métodos para capturar relaciones entre palabras basadas en su contexto. Ambas secciones del código están diseñadas para comparar cómo CBOW y Skip-Gram aprenden las relaciones entre palabras de forma diferente, pero comparten los mismos parámetros para una comparación justa. Puedes encontrar la implementación más abajo en este cuaderno Kaggle.
Código
from gensim.models import Word2Vec
# Corpus pequeño y específico
corpus = [
["gato", "perro", "ladró"],
["perro", "persiguió", "gato"],
["gato", "se sentó", "estera"],
["perro", "corrió", "rápido"],
["gato", "corrió", "rápido"],
["perro", "se sentó", "colchoneta"]
]
# Entrenar un modelo CBOW
cbow_model = Word2Vec(
frases=corpus,
vector_size=10, # Menor tamaño del vector por simplicidad
window=2, # Tamaño de la ventana de contexto
min_count=1, # Incluir todas las palabras
sg=0 # Establecer sg=0 para CBOW
)
# Entrenar un modelo skipgram
skipgram_model = Word2Vec(
frases=corpus,
vector_size=10, # Menor tamaño del vector por simplicidad
window=2, # Tamaño de la ventana de contexto
min_count=1, # Incluir todas las palabras
sg=1 # Establecer sg=1 para Skip-Gram
)
# Función para mostrar vectores de palabras y palabras similares
def mostrar_modelo_resultados(modelo, nombre_modelo):
print(f"\n--- {nombre_modelo} ---")
para palabra en ["gato", "perro"]:
print(f "Vector de palabras para '{palabra}': {model.wv[palabra][:5]}...") # Mostrar los 5 primeros valores del vector
palabras_similares = model.wv.mas_similares(palabra, topn=3)
print(f "Más parecidas a '{palabra}': {[(w, round(sim, 2)) for w, sim in palabras_similares]}")
# Mostrar los resultados del modelo CBOW
display_model_results(cbow_model, "Modelo CBOW")
# Mostrar los resultados del modelo Skip-Gram
display_model_results(skipgram_model, "Modelo Skip-Gram")
Output:
--- Modelo CBOW ---
Vector de palabras para 'gato': [ 0.07380505 -0.01533471 -0.04536613 0.06554051 -0.0486016 ]... Más similares a 'gato': [('perro', 0.54), ('rápido', 0.33), ('ladró', 0.23)] Vector de palabras para 'perro': [-0.00536227 0.00236431 0.0510335 0.09009273 -0.0930295 ]... Más similares a 'perro': [('gato', 0.54), ('rápido', 0.3), ('corrió', 0.1)]
--- Modelo Skip-Gram ---
Vector de palabras para 'gato': [ 0.07380505 -0.01533471 -0.04536613 0.06554051 -0.0486016 ]... Más similares a 'gato': [('perro', 0.54), ('rápido', 0.33), ('ladró', 0.23)] Vector de palabras para 'perro': [-0.00536227 0.00236431 0.0510335 0.09009273 -0.0930295 ]... Más similares a 'perro': [('gato', 0.54), ('rápido', 0.3), ('corrió', 0.1)]
En la parte CBOW del código:
El modelo se entrena utilizando el parámetro sg=0, que indica a Word2Vec que utilice el método de la bolsa continua de palabras.
CBOW determina una palabra utilizando el contexto de las palabras que la rodean. Por ejemplo, en la frase ["perro", "perseguido", "gato"], el modelo podría utilizar "perro" y "gato" para predecir "perseguido".
El vector_size=10 define el tamaño de las incrustaciones de palabras (cuántos números representan cada palabra).
La ventana=2 especifica la ventana de contexto, lo que significa que considera hasta 2 palabras antes y después de la palabra objetivo.
En la parte Skip-Gram del código:
El modelo se entrena utilizando el parámetro sg=1, que cambia Word2Vec al método Skip-Gram.
Skip-Gram identifica las palabras que rodean a la palabra objetivo. Por ejemplo, si la palabra objetivo es "perseguido", el modelo predice "perro" y "gato" como sus vecinas.
Similar a CBOW:
vector_size=10 define el tamaño de las palabras incrustadas.
window=2 define el rango de palabras contextuales a considerar.
Ventajas de Word2Vec
A continuación se indican algunas ventajas clave que hacen de Word2Vec una técnica fundamental en PNL:
Captura relaciones semánticas**: Word2Vec crea incrustaciones en las que palabras semánticamente similares (por ejemplo, "rey" y "reina") se sitúan cerca unas de otras en el espacio vectorial para analizar y utilizar estas relaciones en tareas de PLN.
Comprensión contextual**: Al analizar la coocurrencia de palabras en grandes corpus, Word2Vec capta las relaciones dependientes del contexto, lo que permite a los modelos comprender mejor el significado de las palabras en contextos específicos.
Representación eficaz**: Las incrustaciones de palabras son densas y de baja dimensión en comparación con las representaciones dispersas como la codificación one-hot, lo que las convierte en una técnica eficiente en términos de memoria y costes computacionales.
Gestión de grandes vocabularios**: A diferencia de las técnicas anteriores, Word2Vec se adapta con eficacia a grandes conjuntos de datos y vocabularios, lo que la hace práctica para aplicaciones del mundo real.
Compatible con el aprendizaje por transferencia**: Las incrustaciones preentrenadas de Word2Vec pueden reutilizarse en múltiples tareas, lo que ahorra tiempo y recursos computacionales a la vez que mejora los resultados.
Aritmética en palabras**: Word2Vec admite la aritmética vectorial significativa para que analogías como "rey - hombre + mujer = reina" puedan calcularse directamente utilizando las incrustaciones.
Casos de uso de Word2Vec
Word2Vec tiene una amplia gama de aplicaciones para tareas de PLN. A continuación se muestran algunos de sus casos de uso prácticos e impactantes:
Traducción automática**: Mejora el mapeo de palabras entre idiomas mediante el uso de incrustaciones para alinear palabras con significados similares con el fin de mejorar la precisión de la traducción.
Análisis de sentimientos**: Identifica el tono del texto analizando las relaciones entre palabras y el contexto para clasificar los sentimientos positivos, negativos o neutros.
Clasificación de búsquedas**: Mejora los motores de búsqueda al comprender la similitud entre las consultas de búsqueda y el contenido indexado, lo que conduce a resultados más relevantes.
Recomendaciones de productos**: Relaciona las preferencias del usuario con productos o servicios analizando descripciones textuales y encontrando artículos similares.
Modelización de temas**: Organiza y analiza grandes conjuntos de datos de texto mediante la agrupación de documentos en clusters basados en la similitud de las palabras incrustadas.
Autocompletado de texto**: Sugiere palabras o frases relevantes mediante la predicción de palabras contextualmente similares, mejorando la experiencia del usuario en herramientas de mecanografía o codificación.
Chatbots**: Permite comprender mejor las entradas del usuario y el contexto, ayudando a los chatbots a generar respuestas precisas y pertinentes.
Limitaciones de Word2Vec
A pesar de sus ventajas, Word2Vec tiene sus limitaciones:
Falta de conocimiento del contexto**: Word2Vec genera una única incrustación para cada palabra, independientemente de su contexto. Por ejemplo, la palabra "banco" tendrá la misma representación vectorial, tanto si se refiere a la ribera de un río como a una entidad financiera.
Dependencia de los datos**: Un entrenamiento eficaz requiere grandes conjuntos de datos de texto de alta calidad. Los conjuntos de datos pequeños o mal elaborados pueden dar lugar a incrustaciones subóptimas.
Tratamiento de palabras raras**: Problemas con palabras poco frecuentes o términos fuera de vocabulario, ya que pueden no aparecer lo suficiente en los datos de entrenamiento como para generar incrustaciones significativas.
Sin representación a nivel de frase**: Word2Vec se centra en las incrustaciones a nivel de palabra y no proporciona representaciones de frases o documentos completos, lo que limita su ámbito de aplicación a tareas específicas de PLN.
Ignora el orden de las palabras**: El modelo tiene en cuenta las palabras dentro de una ventana contextual, pero no su secuencia, lo que puede afectar a la comprensión de la gramática o la estructura de las frases.
Anticuado en comparación con los modelos modernos**: Word2Vec ha sido sustituido principalmente por modelos avanzados como BERT, GLoVE y GPT, que proporcionan incrustaciones contextuales y más robustas.
Salvando las distancias: de Word2Vec a GloVe, BERT y GPT
Los modelos predictivos como Word2Vec crean incrustaciones de palabras centrándose en el contexto local a través de redes neuronales. Sin embargo, su dependencia de los pares de palabras cercanos introduce una limitación: No captan relaciones más amplias y globales en todo un corpus de texto. Por ejemplo, aunque Word2Vec destaca en la identificación de asociaciones de palabras cercanas, a menudo pasa por alto conexiones semánticas más amplias.
Para solucionar este problema, GloVe (Global Vectors for Word Representation) utiliza estadísticas globales de co-ocurrencia para crear incrustaciones de palabras. Analiza la frecuencia con la que las palabras aparecen juntas en todo el corpus para captar tanto el contexto local como las relaciones semánticas más amplias y obtener así una representación más completa del lenguaje.
Más recientemente, modelos como BERT (Bidirectional Encoder Representations from Transformers) y GPT (Generative Pre-trained Transformer) han ido más allá de las incrustaciones estáticas. BERT introdujo incrustaciones contextuales, representando las palabras de forma diferente según su uso en una frase, mientras que GPT se centró en generar texto coherente mediante la comprensión del contexto secuencial. Estos modelos transformaron aún más la PNL al incorporar representaciones dinámicas y conscientes del contexto, subsanando las limitaciones de métodos anteriores como Word2Vec y GloVe.
Word2Vec con Milvus: búsqueda vectorial eficiente para aplicaciones de PLN
Word2Vec permite crear incrustaciones de palabras esenciales para tareas como la búsqueda semántica, la similitud de documentos y los sistemas de recomendación, en los que es fundamental comprender las relaciones entre palabras. Sin embargo, gestionar y consultar colecciones extensas de incrustaciones de forma eficiente puede ser todo un reto.
Aquí es donde entra en juego Milvus, la base de datos vectorial de código abierto desarrollada por Zilliz. Milvus proporciona una solución robusta para almacenar, indexar y consultar incrustaciones Word2Vec o cualquier otro tipo de incrustación a escala para una integración perfecta en los flujos de trabajo NLP. Así es como Word2Vec y Milvus trabajan juntos:
Gestión eficiente de las incrustaciones de palabras: Word2Vec genera incrustaciones de alta dimensión para las palabras del vocabulario, cuyo tamaño puede aumentar significativamente con conjuntos de datos más grandes. Milvus gestiona eficientemente estas incrustaciones:
Almacenamiento escalable**: Almacenamiento de millones de incrustaciones de palabras sin degradación del rendimiento.
Recuperación rápida**: Los algoritmos optimizados garantizan una búsqueda rápida de incrustaciones similares, que son cruciales para las aplicaciones de PNL en tiempo real, como los sistemas de recomendación o los chatbots.
Búsqueda semántica mejorada: Las incrustaciones Word2Vec destacan en la captura de relaciones entre palabras. Cuando se combinan con Milvus, estas incrustaciones pueden potenciar la búsqueda semántica avanzada. Por ejemplo:
Búsqueda de sinónimos o términos relacionados (por ejemplo, la consulta de "rey" recupera incrustaciones como "reina" o "príncipe").
Implementación de sistemas de búsqueda robustos como Retrieval Augmented Generation (RAG), que se basan en la similitud de palabras para obtener mejores resultados.
**Milvus simplifica los flujos de trabajo NLP que implican Word2Vec:
Permitiendo que las incrustaciones de Word2Vec preentrenadas se almacenen y consulten de forma eficiente.
Admite la integración con marcos de aprendizaje automático para la agrupación, la similitud de documentos y la búsqueda en tiempo real.
Conclusión
Word2Vec transformó nuestra forma de trabajar con datos lingüísticos al introducir incrustaciones de palabras que capturan los significados y las relaciones de las palabras. Solucionó muchos problemas de los métodos tradicionales, como la incapacidad de captar similitudes semánticas y sintácticas. Se utiliza en aplicaciones como el análisis de sentimientos, la traducción y los sistemas de recomendación. A pesar de sus limitaciones, Word2Vec ha sentado las bases de muchos avances en este campo y ha influido en el desarrollo de modelos más sofisticados como GLoVE, BERT y GPT.
Preguntas frecuentes sobre Word2Vec
- **¿Qué es Word2Vec y por qué es importante?
Word2Vec es un modelo de aprendizaje automático que crea representaciones vectoriales densas de palabras, denominadas incrustaciones de palabras, basadas en su contexto. Es importante porque captura las relaciones y significados de las palabras para tareas de PLN como el análisis de sentimientos, la traducción y la búsqueda.
- **¿En qué se diferencia Word2Vec de los métodos tradicionales de representación de palabras?
A diferencia de los métodos tradicionales, como la codificación one-hot, que representa las palabras como vectores dispersos sin relaciones inherentes, Word2Vec crea incrustaciones densas que capturan las similitudes semánticas y sintácticas entre las palabras, lo que lo hace mucho más eficiente y significativo.
- **¿Cuáles son las principales arquitecturas utilizadas en Word2Vec?
Word2Vec tiene dos arquitecturas principales: Continuous Bag of Words (CBOW) y Skip-Gram. CBOW determina una palabra objetivo a partir del contexto que la rodea, mientras que Skip-Gram identifica las palabras del contexto a partir de una palabra objetivo dada. Cada una tiene sus ventajas en función del caso de uso y del conjunto de datos.
- ¿Cuáles son los principales casos de uso de Word2Vec??
Word2Vec se utiliza en aplicaciones como el análisis de sentimientos, la traducción automática, los sistemas de recomendación, la clasificación de búsquedas, el modelado de temas y el desarrollo de chatbot. Su capacidad para comprender las relaciones entre palabras lo hace versátil en diversas tareas de PLN.
- **¿Cuáles son las limitaciones de Word2Vec?
Word2Vec tiene varias limitaciones, como su falta de conocimiento del contexto (por ejemplo, no distingue entre los distintos significados de una misma palabra), su dependencia de grandes conjuntos de datos para el entrenamiento y su incapacidad para captar el orden de las palabras o el significado a nivel de frase. Estos inconvenientes han llevado al desarrollo de modelos más avanzados como GloVe, BERT y GPT.
Recursos relacionados
Las 10 técnicas de PNL que todo científico de datos debe conocer](https://zilliz.com/learn/top-10-nlp-techniques-every-data-scientist-should-know)
Las 10 mejores herramientas y plataformas de procesamiento del lenguaje natural](https://zilliz.com/learn/top-10-natural-language-processing-tools-and-platforms)
Entrene su propio modelo de incrustación de texto](https://zilliz.com/learn/training-your-own-text-embedding-model)
20 populares conjuntos de datos abiertos para el procesamiento del lenguaje natural](https://zilliz.com/learn/popular-datasets-for-natural-language-processing)
Descubra la potencia del procesamiento del lenguaje natural: Las 10 mejores aplicaciones reales](https://zilliz.com/learn/top-5-nlp-applications)
GloVe: algoritmo de aprendizaje automático para descodificar conexiones de palabras](https://zilliz.com/glossary/glove)
- ¿Qué es Word2Vec?
- ¿Por qué necesitamos Word2Vec?
- ¿Cómo funciona Word2Vec?
- Implementación de Word2Vec en Python
- Ventajas de Word2Vec
- Casos de uso de Word2Vec
- Limitaciones de Word2Vec
- Salvando las distancias: de Word2Vec a GloVe, BERT y GPT
- Word2Vec con Milvus: búsqueda vectorial eficiente para aplicaciones de PLN
- Conclusión
- Preguntas frecuentes sobre Word2Vec
- Recursos relacionados
Contenido
Comienza Gratis, Escala Fácilmente
Prueba la base de datos vectorial completamente gestionada construida para tus aplicaciones GenAI.
Prueba Zilliz Cloud Gratis