




Clasificación en aprendizaje automático: Todo lo que debe saber

Clasificación en aprendizaje automático: Todo lo que debe saber
¿Qué es la clasificación?
La clasificación es un enfoque de aprendizaje automático supervisado que clasifica los datos en clases predefinidas. Dada una entrada, un modelo de clasificación predice la categoría o etiqueta a la que pertenece la entrada. Es una de las tareas más comunes en el aprendizaje automático y se utiliza en muchas aplicaciones del mundo real, desde la detección de spam de correo electrónico a los diagnósticos médicos.
Por ejemplo, si tiene un conjunto de datos de correos electrónicos, un modelo de clasificación puede aprender a etiquetar cada correo como "spam" o "no spam".
¿Cómo funciona la clasificación?
En la clasificación, un modelo de aprendizaje automático se entrena en un conjunto de datos para clasificar los datos en clases predefinidas en función de las características de entrada. El modelo se entrena utilizando un conjunto de datos etiquetados, donde cada entrada se asocia con una etiqueta de salida. El modelo aprende los patrones de los datos durante el entrenamiento y los utiliza para predecir las etiquetas de datos nuevos que no se han visto.
Por ejemplo, imagina que tienes que clasificar un correo electrónico para saber si es spam. Durante la fase de entrenamiento, el modelo recibe correos electrónicos con sus etiquetas ("spam" o "no spam"). Analiza características como la presencia de determinadas palabras clave o la dirección del remitente para identificar patrones. Una vez entrenado el modelo, analiza las mismas características y predice si pertenece a la categoría "spam" o "no spam" cuando llega un nuevo correo electrónico.
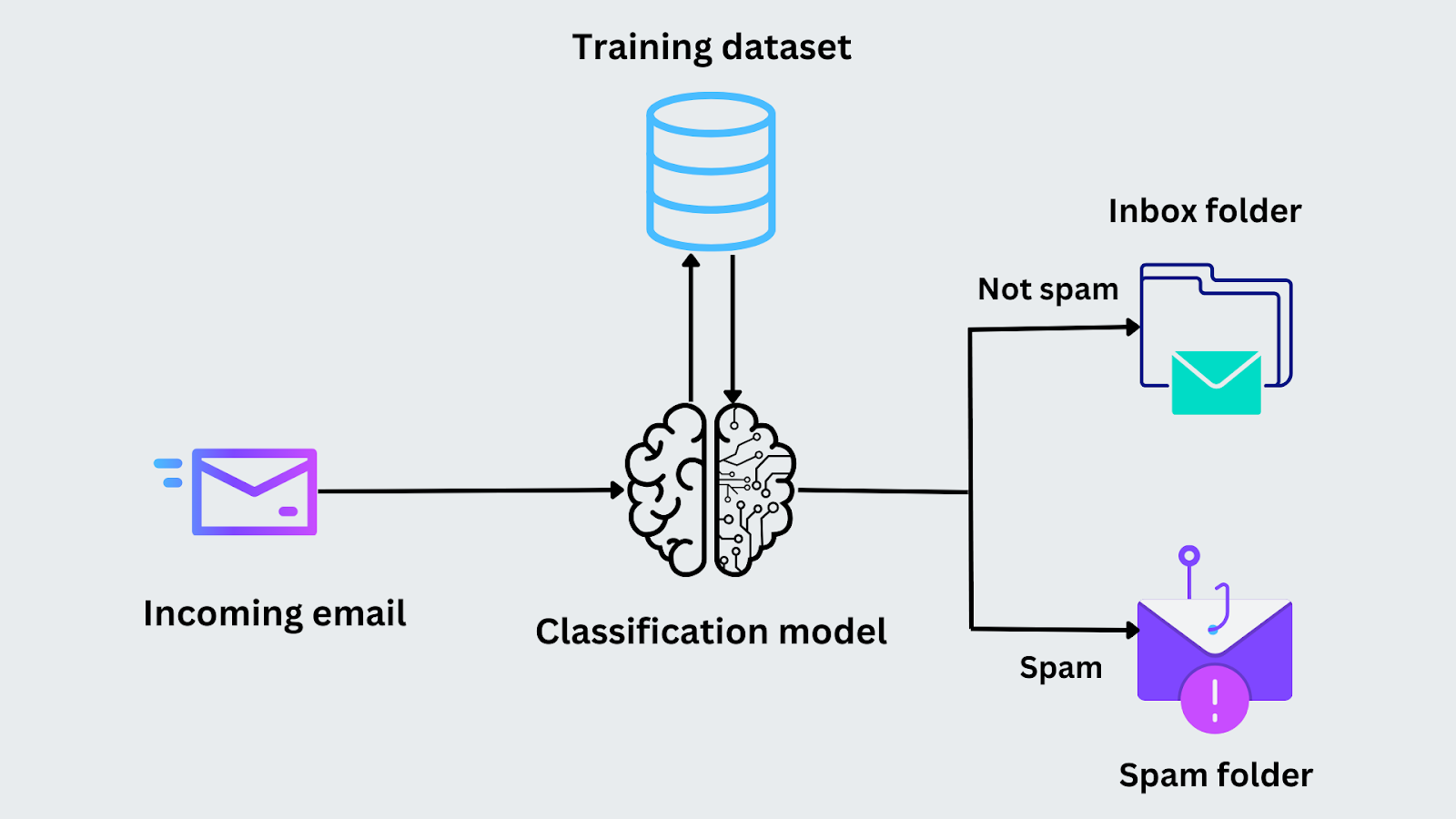 Figura- Proceso de clasificación de correos electrónicos.png
Figura- Proceso de clasificación de correos electrónicos.png
Figura: Proceso de clasificación del correo electrónico
Tipos de clasificación
Los problemas de clasificación se presentan de diferentes formas dependiendo de la naturaleza de los datos y del número de clases. Éstos son los tipos más comunes:
Clasificación binaria
La clasificación binaria se produce cuando sólo hay dos clases o resultados posibles. El modelo predice a cuál de las dos categorías pertenece la entrada. Un ejemplo clásico es la detección de correo basura. El modelo debe decidir si un correo electrónico entrante es "spam" o "no spam". Como sólo hay dos opciones, se trata de una tarea de clasificación binaria.
Clasificación multiclase
En la clasificación multiclase, el modelo predice una etiqueta de entre más de dos categorías posibles. Cada entrada se asigna exactamente a una clase. Un buen ejemplo es el reconocimiento de imágenes, donde el modelo puede clasificar una imagen como "gato", "perro" o "pájaro". A diferencia de la clasificación binaria, el modelo trata con varias clases distintas y debe identificar la correcta para cada entrada.
Clasificación Multilabel
La clasificación multietiqueta es aquella en la que cada entrada puede pertenecer a varias clases simultáneamente. Por ejemplo, al etiquetar una foto, podría etiquetarse simultáneamente con "puesta de sol", "playa" y "gente". Cada etiqueta representa una clase diferente, y el modelo aprende a predecir todas las etiquetas relevantes para una entrada. Esto difiere de la clasificación multiclase porque se pueden asignar varias etiquetas a la misma entrada.
Figura- Tipos de clasificación.png](https://assets.zilliz.com/Figure_Types_of_classification_ba07b30407.png)
Figura: Tipos de clasificación
Aprendices en algoritmos de clasificación
En el aprendizaje automático, los algoritmos de clasificación se pueden clasificar en función de cómo generalizan a partir de los datos de entrenamiento. Se trata de Lazy Learners y Eager Learners. La distinción entre estos dos tipos radica en cuándo y cómo procesan los datos para hacer predicciones.
Aprendices perezosos
Los aprendices perezosos son algoritmos que retrasan la generalización hasta que reciben una consulta de predicción. No construyen un modelo durante la fase de entrenamiento, sino que almacenan los datos de entrenamiento y sólo realizan cálculos cuando es necesario clasificar una nueva entrada.
Algoritmos de ejemplo: k-Nearest Neighbors (k-NN), Razonamiento basado en casos (CBR).
Eager Learners
Los aprendices ávidos, por el contrario, intentan construir un modelo general inmediatamente durante la fase de entrenamiento. Analizan los datos de entrenamiento, aprenden los patrones subyacentes y, a continuación, descartan los datos de entrenamiento. Una vez construido el modelo, puede predecir rápidamente nuevos datos.
Algoritmos de ejemplo: Árboles de decisión, Bosque aleatorio, Máquinas de vectores de apoyo (SVM), Regresión logística.
| Aprendices perezosos. Aprendices ansiosos. | ||
| Creación de modelos | No construye ningún modelo durante el entrenamiento; memoriza los datos. | Generaliza los datos en un modelo durante el entrenamiento. |
| Tiempo de entrenamiento | Tiempo de entrenamiento corto; no construye un modelo. | Tiempo de entrenamiento más largo; construye un modelo basado en datos. |
| Tiempo de predicción | Realiza predicciones más lentas, ya que procesa los datos en el momento de la consulta. | Predicciones más rápidas, ya que el modelo está preconstruido. |
| Requerimiento de memoria | Mayor requerimiento de memoria; almacena todo el conjunto de datos. | Requiere menos memoria; sólo almacena los parámetros del modelo. |
| Algoritmos de ejemplo: k-NN, razonamiento basado en casos, árboles de decisión, regresión logística, bosque aleatorio. |
**Tabla: Aprendices perezosos frente a Aprendices ansiosos
Algoritmos de clasificación
Analicemos ahora algunos de los algoritmos de clasificación más utilizados.
Regresión Logística
La regresión logística utiliza sólo la probabilidad para predecir la etiqueta en una tarea de clasificación binaria. A diferencia de la regresión lineal, que predice valores continuos, la regresión logística predice probabilidades para dos clases asignando salidas a un rango entre 0 y 1 utilizando la función logística (sigmoid). Se utiliza mucho para casos con resultados binarios, como sí/no o escenarios 0/1.
Figura- Regresión logística en funcionamiento.png](https://assets.zilliz.com/Figure_Logistic_regression_working_0b2ce2b99c.png)
Figura - Funcionamiento de la regresión logística
Árboles de decisión
Un árbol de decisión es un modelo que divide los datos en función de los valores de las características, creando ramas para cada posible decisión. Cada nodo representa una característica, y las ramas representan decisiones basadas en el valor de esa característica. El proceso continúa hasta que el algoritmo decide los nodos hoja de la clase predicha. Los árboles de decisión son fáciles de interpretar y pueden manejar tareas de clasificación binarias y multiclase.
Figura- Estructura del árbol de decisión.png](https://assets.zilliz.com/Figure_Decision_tree_structure_09ec70a8f3.png)
Figura: Estructura del árbol de decisión
Random Forest
El bosque aleatorio mejora los árboles de decisión construyendo múltiples árboles y combinando sus predicciones. Cada árbol del bosque se construye a partir de un subconjunto aleatorio de datos y características. La predicción final se realiza promediando los resultados (para tareas de regresión) o por mayoría (para tareas de clasificación). Esto ayuda a reducir el sobreajuste y aumenta la precisión.
Figura - Funcionamiento del bosque aleatorio.png](https://assets.zilliz.com/Figure_Random_forest_working_075a5d306f.png)
Figura: Funcionamiento del bosque aleatorio
Máquinas de vectores soporte (SVM)
Las máquinas de vectores soporte funcionan encontrando el hiperplano óptimo que separa los puntos de datos de diferentes clases. Este hiperplano es una línea en dos dimensiones, pero las SVM también pueden manejar datos de alta dimensión. La idea clave es maximizar el margen entre los puntos de datos más cercanos de cada clase (vectores de soporte). Las SVM funcionan bien para problemas de clasificación binaria y multiclase, especialmente cuando los datos no son linealmente separables.
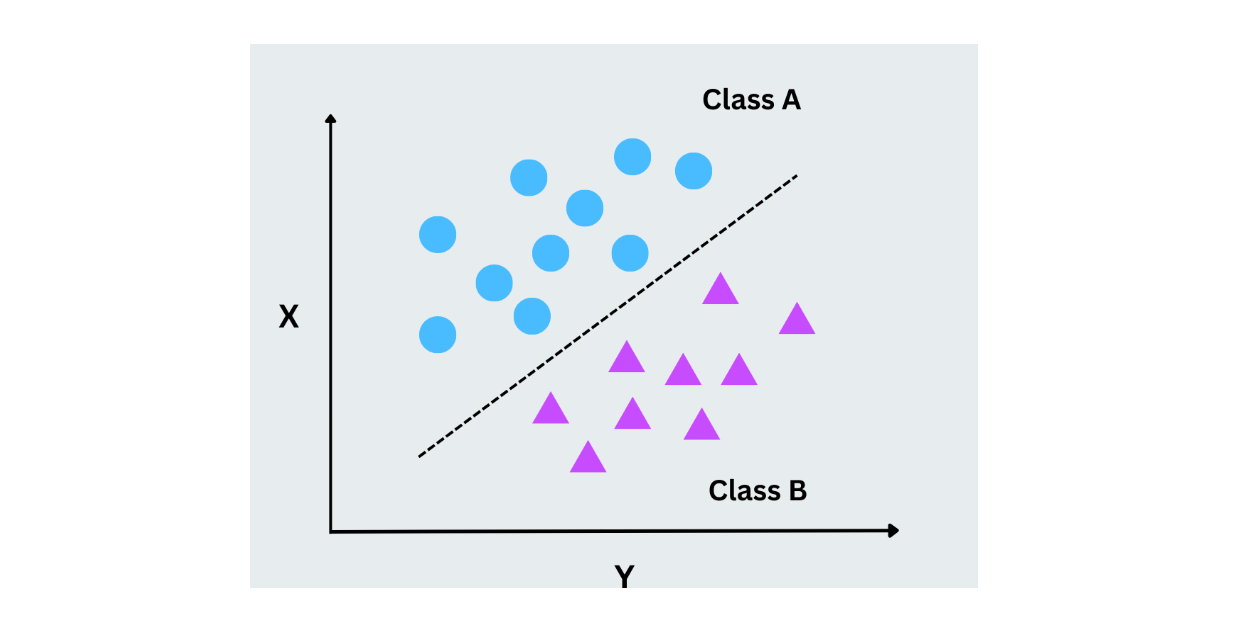 Figura- SVM funcionando.png
Figura- SVM funcionando.png
Figura - SVM en funcionamiento
k-Nearest Neighbors (k-NN)
El algoritmo k-NN clasifica los puntos de datos en función de las clases de los k vecinos más próximos. Al introducir un nuevo punto de datos, el algoritmo examina los k puntos más cercanos (basándose en una métrica de similitud como la distancia euclídea) y asigna al nuevo punto la clase mayoritaria. Se trata de un algoritmo de aprendizaje sencillo, basado en instancias y útil para conjuntos de datos pequeños.
Figura - Algoritmo kNN en funcionamiento.png](https://assets.zilliz.com/Figure_k_NN_algorithm_working_1d62f3af14.png)
Figura: Algoritmo kNN en funcionamiento
Naive Bayes
Naive Bayes se basa en el Teorema de Bayes y asume que las características de los datos son independientes entre sí (de ahí el término "naive"). A pesar de esta suposición, funciona bien en varias tareas del mundo real, especialmente cuando los datos tienen características categóricas. Funciona calculando la probabilidad de cada clase dada la entrada y asignando la clase con la probabilidad más alta.
P(C|X) = P(X|C) . P(C)P(X))
Aquí, P(C∣X) es la probabilidad posterior de la clase dada la entrada, P(X∣C) es la probabilidad de la entrada dada la clase, P(C) es la probabilidad a priori de la clase y P(X) es la probabilidad de la entrada. Naive Bayes selecciona la clase con la probabilidad posterior más alta para la clasificación basada en las características observadas.
Figura - Funcionamiento del algoritmo Naive Bayes.png](https://assets.zilliz.com/Figure_Naive_Bayes_algorithm_working_ea0a5ca81f.png)
Figura: Algoritmo Naive Bayes en funcionamiento
Métricas de evaluación en clasificación
Precisión
La precisión es la métrica más sencilla y mide la frecuencia con la que las predicciones del modelo son correctas. Se determina dividiendo el número de casos predichos correctamente por el número total de casos.
Fórmula:
Precisión = (Verdaderos positivos + Verdaderos negativos)/Número total de casos
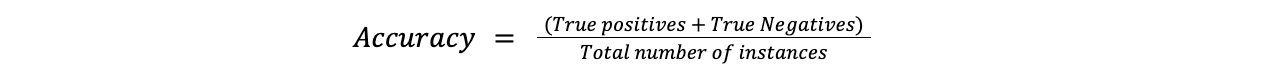 accuracy.png
accuracy.png
Precisión
La precisión mide cuántos de los casos positivos predichos son realmente positivos. La precisión es importante en situaciones en las que los falsos positivos son costosos. Por ejemplo, predecir una transacción normal como fraudulenta en la detección de fraudes puede provocar la insatisfacción del cliente.
**Fórmula
Precisión = Verdaderos positivos/(Verdaderos positivos + Falsos positivos)
 precision.png
precision.png
Recall
La recuperación mide la proporción de casos positivos identificados correctamente como positivos. La recuperación es útil en los casos en los que omitir un caso positivo es costoso. Por ejemplo, omitir un diagnóstico (falso negativo) es mucho más problemático en la detección de enfermedades que una falsa alarma.
**Fórmula
Recall = Verdaderos positivos/(Verdaderos positivos + Falsos negativos)
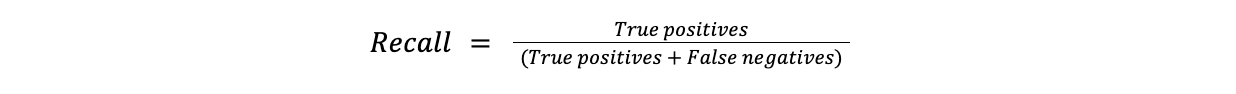 recall.png
recall.png
Puntuación F1
La puntuación F1 es la media armónica de la precisión y la recuperación. Resulta útil cuando es necesario equilibrar la precisión y la recuperación, concretamente cuando una es más importante que la otra.
**Fórmula
Puntuación F1 = 2x(Precisión x Recuperación)/(Precisión + Recuperación)
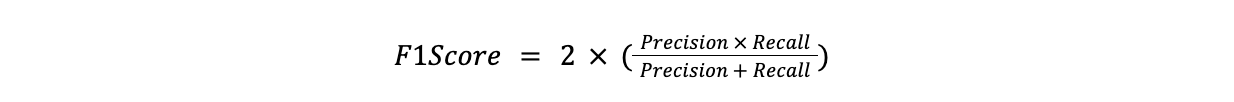 FI score.png
FI score.png
Casos reales de uso de la clasificación
Los modelos de clasificación se utilizan ampliamente en diversos sectores para resolver problemas del mundo real. He aquí algunos ejemplos prácticos:
Diagnóstico médico: Los modelos de aprendizaje automático ayudan a los médicos a clasificar los datos de los pacientes como "enfermedad" o "sin enfermedad". Por ejemplo, los modelos se utilizan para predecir si un paciente tiene diabetes basándose en los historiales médicos.
Análisis de sentimientos: Las empresas utilizan el análisis de sentimientos para comprender los comentarios de los clientes. Por ejemplo, un modelo puede analizar reseñas de productos y clasificarlas como positivas, negativas o neutras, lo que ayuda a las empresas a mejorar sus ofertas basándose en el sentimiento de los clientes.
**Los bancos y las instituciones financieras utilizan modelos de clasificación para detectar transacciones fraudulentas. El modelo aprende patrones a partir de los datos de las transacciones y clasifica cada una como "fraudulenta" o "legítima" para evitar pérdidas financieras.
Reconocimiento de objetos en imágenes: Los modelos de reconocimiento de objetos identifican elementos específicos de imágenes en sectores como la fabricación y la seguridad. Por ejemplo, un modelo puede clasificar imágenes de productos en una cadena de montaje, garantizando que sólo pasen la inspección los artículos correctamente ensamblados.
**Los sistemas de reconocimiento facial se utilizan en seguridad y autenticación. Estos modelos clasifican imágenes de rostros para identificar o verificar la identidad de una persona, y se utilizan habitualmente para desbloquear teléfonos inteligentes, sistemas de asistencia digital o controles de seguridad en aeropuertos.
Reconocimiento de voz: Los modelos de reconocimiento de voz convierten el lenguaje hablado en texto u órdenes. Por ejemplo, los asistentes virtuales como Siri o Alexa clasifican las palabras habladas en comandos para que los usuarios puedan interactuar con los dispositivos a través de la voz.
Pruebas de diagnóstico médico: Los modelos de aprendizaje automático ayudan a interpretar pruebas de diagnóstico como radiografías o resonancias magnéticas. Clasifican las imágenes médicas como "normales" o "anormales", ayudando a los radiólogos a realizar diagnósticos más rápidos y precisos.
**Las plataformas de comercio electrónico utilizan modelos de clasificación para predecir el comportamiento de los clientes. Estos modelos clasifican a los usuarios como "propensos a comprar" o "poco propensos a comprar" para hacer recomendaciones personalizadas de marketing y productos.
Categorización de productos: Los minoristas utilizan el aprendizaje automático para clasificar automáticamente productos como "electrónica", "ropa" o "artículos para el hogar" basándose en sus descripciones. Esto agiliza la gestión del inventario y mejora las experiencias de búsqueda de los clientes.
**En ciberseguridad, los modelos de clasificación detectan y clasifican el malware. Mediante el análisis de patrones en el comportamiento del software, estos modelos clasifican los programas como "seguros" o "maliciosos" para proteger los sistemas de las ciberamenazas.
Desafíos comunes en la clasificación
Cuando se construyen modelos de clasificación, pueden surgir varios retos que afectan al rendimiento del modelo. He aquí tres problemas comunes:
Sobreajuste
Sobreajuste significa que un modelo funciona bien con los datos de entrenamiento pero no consigue generalizar con datos nuevos que no se han visto. Esto ocurre cuando el modelo se vuelve demasiado complejo y empieza a captar el ruido o detalles específicos del conjunto de entrenamiento en lugar de los patrones subyacentes.
Desequilibrio de datos
El desequilibrio de datos se produce cuando una clase supera significativamente a otras. Por ejemplo, en la detección de fraudes, las transacciones fraudulentas pueden representar sólo el 1% de los datos, lo que hace que el modelo se incline en gran medida hacia la clase mayoritaria. Esto puede dar lugar a una mala detección de la clase minoritaria.
Ruido en los datos
El ruido se refiere a errores aleatorios o información irrelevante en los datos que pueden confundir al modelo. Los datos ruidosos pueden incluir ejemplos mal etiquetados, valores atípicos o características irrelevantes que no contribuyen a la tarea de clasificación. La presencia de ruido puede reducir el rendimiento del modelo y dificultar la detección de patrones.
Clasificación frente a regresión
La clasificación y la regresión son dos tipos de algoritmos de aprendizaje supervisado, pero se utilizan para distintos tipos de tareas. A continuación se presenta una comparación entre clasificación y regresión basada en varios aspectos:
| Aspecto: Clasificación: Regresión. | ||
| Propósito Predice etiquetas o categorías discretas. | Predecir valores numéricos continuos. | |
| Salida | Categóricos: clases como "spam" o "no spam". | Continuos: valores como "precio" o "temperatura". |
| Ejemplo Tarea | Clasificar correos electrónicos como "spam" o "no spam". | Predecir el precio de la vivienda basándose en sus características. |
| Algoritmos utilizados | Regresión logística, árboles de decisión, bosque aleatorio, etc. | Regresión lineal, regresión Ridge, regresión polinómica, etc. |
| Métricas de evaluación: exactitud, precisión, recuperación, puntuación F1, ROC-AUC, etc. | Error cuadrático medio (MSE), R-cuadrado, Error absoluto medio (MAE). | |
| Naturaleza de la variable objetivo El objetivo es categórico (por ejemplo, etiquetas de clase). | El objetivo es continuo (por ejemplo, números reales). | |
| Límites de salida Tiene límites de clase fijos (por ejemplo, 0 ó 1 para binario). | La salida es un rango de números reales. | |
| Casos de uso en el mundo real Detección de spam, detección de fraudes, clasificación de enfermedades. | Predicción de ventas, precios de acciones y predicción meteorológica. | |
| Modelado ComplexiIt can | Puede manejar tanto salidas binarias como multiclase. | Suele ser más sencillo cuando se predice un valor continuo. |
Tabla: Clasificación vs Regresión
¿Cómo ayuda Milvus en las tareas de clasificación?
A medida que aumentan el volumen y la complejidad de los datos, los métodos tradicionales de gestión y consulta de grandes conjuntos de datos pueden volverse lentos e ineficaces. Aquí es donde Zilliz, con su base de datos vectorial de código abierto y alto rendimiento Milvus, desempeña un papel fundamental.
Las tareas de clasificación, como el reconocimiento de imágenes, la detección de objetos, la búsqueda de similitudes en vídeo, la detección de spam y los sistemas de recomendación, suelen requerir el manejo de representaciones de alta dimensión de datos no estructurados, como incrustaciones de texto, características de imágenes o vectores de audio. Milvus se ha diseñado específicamente para gestionar y buscar de forma eficiente en estos grandes volúmenes de datos vectoriales.
Ventajas de Milvus para la clasificación
Manejo de datos de alta dimensión: En clasificación, los modelos a menudo se basan en datos vectorizados (por ejemplo, incrustaciones de palabras o vectores de características de imagen) para hacer predicciones. Milvus está optimizado para almacenar y gestionar estos vectores para acceder rápidamente a grandes conjuntos de datos durante el entrenamiento del modelo y la inferencia.
Búsqueda rápida de similitudes: Los modelos de clasificación necesitan con frecuencia encontrar los puntos de datos más parecidos en un conjunto de datos. Milvus acelera este proceso realizando rápidas búsquedas de similitud en los datos vectoriales, lo que facilita la clasificación de nuevas entradas basándose en sus vecinos más cercanos.
Escalabilidad para grandes conjuntos de datos: Milvus garantiza que el rendimiento siga siendo rápido y eficiente a medida que crecen los conjuntos de datos de clasificación. Milvus se escala sin problemas para que las tareas de clasificación se ejecuten sin problemas incluso con grandes cantidades de datos, ya sean millones de vectores de productos, incrustaciones de imágenes o miles de incrustaciones de imágenes.
Conclusión
La clasificación es una técnica de aprendizaje automático para predecir etiquetas o categorías de datos en diversas aplicaciones del mundo real, desde la detección de fraudes hasta el reconocimiento de imágenes. Construir y desplegar con éxito modelos de clasificación requiere manejar grandes cantidades de datos, a menudo vectores de alta dimensión. Milvus proporciona almacenamiento eficiente, recuperación rápida y escalabilidad para datos vectoriales. Mejora el rendimiento de las tareas de clasificación mediante rápidas búsquedas de similitudes y se adapta sin problemas a medida que crecen los conjuntos de datos. Con Milvus, los desarrolladores pueden afrontar fácilmente los retos de las tareas de clasificación a gran escala, lo que la convierte en una potente herramienta en el panorama del aprendizaje automático.
Preguntas frecuentes sobre clasificación
¿Qué es la clasificación en el aprendizaje automático?
La clasificación en el aprendizaje automático es el proceso de predecir una categoría o etiqueta para una entrada dada basándose en sus características. Un modelo se entrena utilizando datos etiquetados para aprender patrones y luego clasificar nuevos datos no vistos en clases predefinidas, como "spam" o "no spam".
¿En qué se diferencia un algoritmo de clasificación de uno de regresión?
Los algoritmos de clasificación predicen resultados categóricos (como clases o etiquetas), mientras que los algoritmos de regresión predicen valores numéricos continuos. Por ejemplo, la clasificación puede determinar si un correo electrónico es spam, mientras que la regresión podría predecir el precio de una casa.
¿Por qué es importante la preparación de los datos en las tareas de clasificación?
La preparación de datos garantiza que los datos de entrada estén limpios, estructurados y listos para que el modelo los procese. Maneja los valores que faltan, normaliza los datos y selecciona las características más relevantes. Una preparación adecuada mejora la precisión y el rendimiento del modelo.
¿Cómo ayuda Milvus en las tareas de clasificación?
Milvus** es una base de datos vectorial de código abierto que almacena y busca eficazmente datos de alta dimensión, como imágenes o texto. Acelera la clasificación gracias a su eficaz búsqueda de similitudes, que facilita el manejo de grandes conjuntos de datos en tareas como el reconocimiento de imágenes y los sistemas de recomendación.
¿Cuáles son los retos habituales de la clasificación y cómo pueden resolverse?
Entre los problemas más comunes se encuentran el sobreajuste, el desequilibrio de datos y el ruido en los datos. Estos problemas pueden abordarse mediante técnicas como la regularización, métodos de remuestreo (por ejemplo, SMOTE), estrategias de reducción del ruido e infraestructuras escalables como Milvus para gestionar grandes conjuntos de datos de forma eficiente.
Recursos relacionados
Qué es la detección de objetos: guía completa](https://zilliz.com/learn/what-is-object-detection)
Qué es el algoritmo K-Nearest Neighbors (KNN) en el aprendizaje automático](https://zilliz.com/blog/k-nearest-neighbor-algorithm-for-machine-learning)
Vecinos Cercanos Aproximados Oh Yeah (Molesta)](https://zilliz.com/learn/approximate-nearest-neighbor-oh-yeah-ANNOY)
¿Qué son las bases de datos vectoriales y cómo funcionan? ](https://zilliz.com/learn/what-is-vector-database)
¿Qué es la RAG? ](https://zilliz.com/learn/Retrieval-Augmented-Generation)
Comprender la visión por ordenador ](https://zilliz.com/learn/what-is-computer-vision)
- ¿Qué es la clasificación?
- ¿Cómo funciona la clasificación?
- Tipos de clasificación
- Aprendices en algoritmos de clasificación
- Algoritmos de clasificación
- Métricas de evaluación en clasificación
- Casos reales de uso de la clasificación
- Desafíos comunes en la clasificación
- Clasificación frente a regresión
- ¿Cómo ayuda Milvus en las tareas de clasificación?
- Conclusión
- Preguntas frecuentes sobre clasificación
- Recursos relacionados
Contenido
Comienza Gratis, Escala Fácilmente
Prueba la base de datos vectorial completamente gestionada construida para tus aplicaciones GenAI.
Prueba Zilliz Cloud Gratis