




Milvus en la GPU con NVIDIA RAPIDS cuVS
Introducción
El rendimiento en producción es un factor crítico para el éxito de nuestra aplicación de IA. Cuanto más rápido podamos devolver resultados al usuario, mejor. Esta urgencia impulsa la necesidad de optimización.
Consideremos un ejemplo real: una aplicación Retrieval Augmented Generation (RAG). En un sistema RAG, la búsqueda vectorial es el motor que impulsa la experiencia del usuario, proporcionando resultados relevantes basados en sus consultas. Sin embargo, todos somos conscientes de que la búsqueda vectorial es una tarea que consume muchos recursos. Cuantos más datos almacenamos, más caro y lento resulta el cálculo.
Es necesario encontrar una solución para optimizar el rendimiento de nuestras aplicaciones de IA en estos casos. En una charla reciente en el Unstructured Data Meetup organizado por Zilliz, Corey Nolet, Ingeniero Principal de NVIDIA, habló sobre los últimos avances de NVIDIA para resolver este problema, que analizaremos en este artículo. También puedes ver la charla de Corey en YouTube.
En concreto, nos centraremos en cuVS, una librería desarrollada por NVIDIA que contiene varios algoritmos relacionados con la búsqueda vectorial y aprovecha la capacidad de aceleración de las GPU. Veremos cómo esta librería puede mejorar el rendimiento de las operaciones de búsqueda vectorial y optimizar los costes operativos generales. Así que, sin más preámbulos, ¡entremos en materia!
La búsqueda vectorial y el papel de la base de datos vectorial en ella
La búsqueda vectorial es un método de recuperación de información en el que tanto la consulta del usuario como los documentos que se buscan se representan como vectores. Para realizar una búsqueda vectorial, tenemos que transformar la consulta y los documentos (que pueden ser imágenes, textos, etc.) en vectores.
Un vector tiene una dimensión específica, que depende del método utilizado para generarlo. Por ejemplo, si utilizamos un modelo HuggingFace llamado all-MiniLM-L6-v2 para transformar nuestra consulta en un vector, obtendremos un vector con una dimensión de 384. Los vectores transmiten el significado semántico de los datos o documentos que representan. Por lo tanto, si dos datos son similares entre sí, sus vectores correspondientes se sitúan cerca uno del otro en el espacio vectorial.
Semejanza semántica entre vectores en un espacio vectorial..png](https://assets.zilliz.com/Semantic_similarity_between_vectors_in_a_vector_space_d101dec8f6.png)
Similitud semántica entre vectores en un espacio vectorial.
El hecho de que cada vector conlleve el significado semántico de los datos que representa nos permite calcular la similitud entre cualquier par aleatorio de vectores. Si son similares, la puntuación de similitud será alta, y viceversa. El objetivo principal de la búsqueda vectorial es encontrar los vectores más parecidos al vector de nuestra consulta.
La implementación de la búsqueda vectorial es relativamente sencilla cuando se trata de unos pocos documentos. Sin embargo, la complejidad aumenta a medida que tenemos más documentos y necesitamos almacenar más vectores. Cuantos más vectores tengamos, más tiempo se tarda en realizar una búsqueda vectorial. Además, el coste operativo aumenta significativamente a medida que almacenamos más vectores en la memoria local. Así pues, necesitamos una solución escalable, que es donde entran en juego las bases de datos vectoriales.
Las bases de datos vectoriales ofrecen una solución eficaz, rápida y escalable para almacenar una enorme colección de vectores. Proporcionan métodos de indexación avanzados para una recuperación más rápida durante las operaciones de búsqueda de vectores, así como fácil integración con marcos de IA populares para simplificar el proceso de desarrollo de nuestras aplicaciones de IA. En bases de datos vectoriales como Milvus y Zilliz Cloud (la Milvus gestionada), también podemos almacenar los metadatos de los vectores y realizar procesos de filtrado avanzados durante las operaciones de búsqueda.
Flujo de trabajo completo de una operación de búsqueda de vectores..png](https://assets.zilliz.com/Complete_workflow_of_a_vector_search_operation_41a8cf807f.png)
Flujo de trabajo completo de una operación de búsqueda vectorial.
Para almacenar una colección de vectores en una base de datos vectorial como Milvus, el primer paso es realizar un preprocesamiento de los datos, dependiendo de nuestro tipo de datos. Por ejemplo, si nuestros datos son una colección de documentos, podemos dividir el texto de cada documento en trozos. A continuación, transformamos cada trozo en un vector utilizando un modelo de incrustación de nuestra elección. A continuación, incorporamos todos los vectores a nuestra base de datos vectorial y creamos un índice sobre ellos para agilizar la recuperación durante las operaciones de búsqueda vectorial.
Cuando tenemos una consulta y queremos realizar una operación de búsqueda vectorial, transformamos la consulta en un vector utilizando el mismo modelo de incrustación utilizado anteriormente y, a continuación, calculamos su similitud con los vectores de la base de datos. Por último, se nos devuelven los vectores más similares.
Operación de búsqueda vectorial en la CPU
Las operaciones de búsqueda de vectores requieren un cálculo intensivo, y el coste de cálculo aumenta a medida que almacenamos más vectores dentro de una base de datos de vectores. Hay varios factores que afectan directamente al coste computacional, como la construcción del índice, el número total de vectores, la dimensionalidad del vector y la calidad deseada del resultado de la búsqueda.
Las CPU son las unidades de procesamiento habituales para las operaciones de búsqueda vectorial debido a su rentabilidad y fácil integración con otros componentes en las aplicaciones de IA. Muchos algoritmos de búsqueda vectorial están totalmente optimizados para CPU, siendo Hierarchical Navigable Small World (HNSW) el más popular.
En esencia, HNSW combina los conceptos de listas de salto y Mundo Pequeño Navegable (NSW). En un algoritmo NSW, el grafo se construye primero barajando aleatoriamente los puntos de datos. A continuación, los puntos de datos se insertan uno a uno, y cada punto se conecta a sus vecinos más cercanos mediante un número predefinido de aristas.
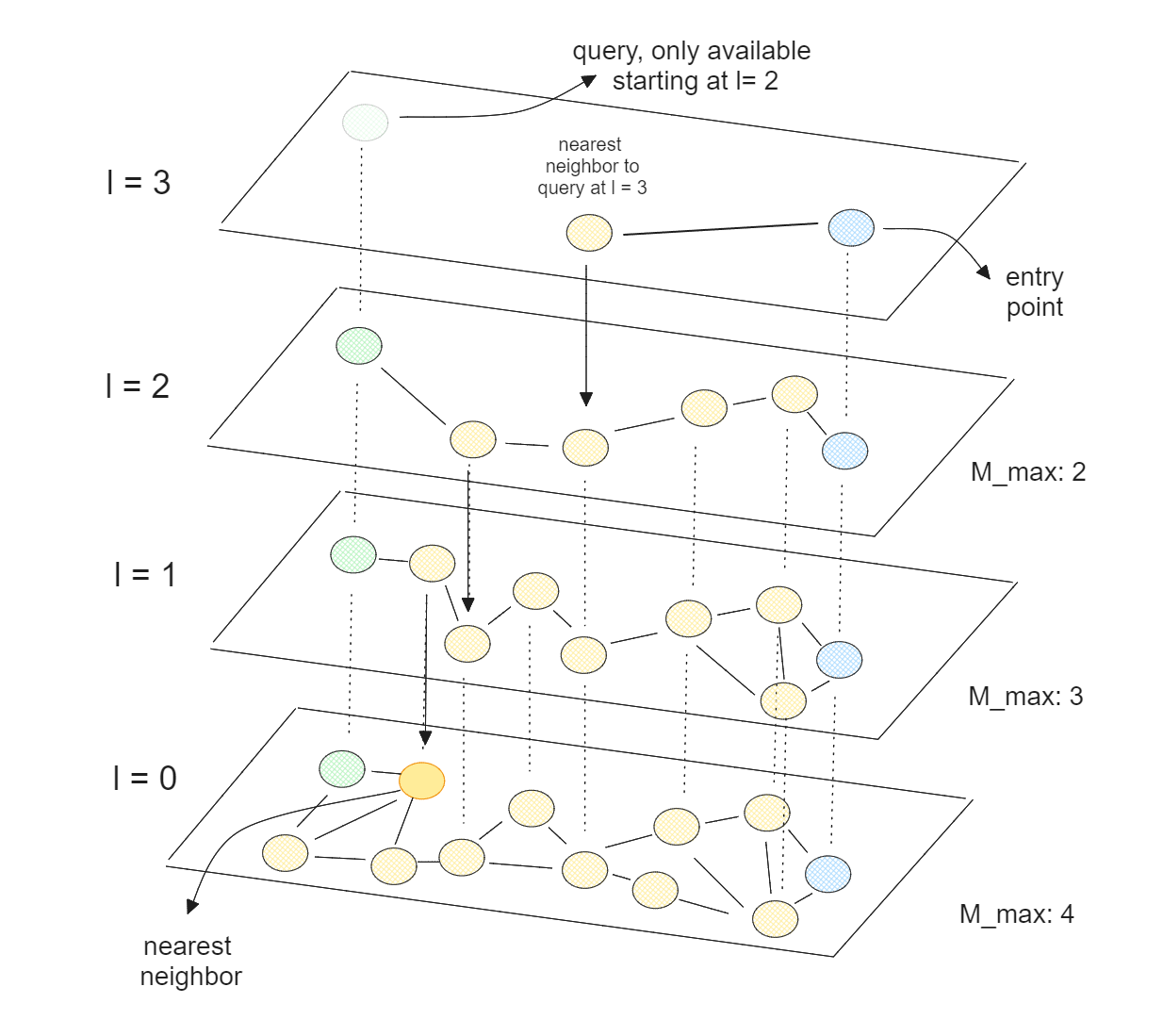 Búsqueda vectorial con HNSW..png
Búsqueda vectorial con HNSW..png
Búsqueda vectorial con HNSW.
HNSW es un NSW multicapa, donde la capa más baja contiene todos los puntos de datos, y la capa más alta contiene sólo un pequeño subconjunto de nuestros puntos de datos. Esto significa que cuanto más alta sea la capa, más puntos de datos omitiremos, lo que se corresponde con la teoría de las listas de omisión.
Con HNSW, tenemos un grafo en el que se puede llegar a la mayoría de los nodos desde cualquier otro nodo mediante un pequeño número de iteraciones. Esta propiedad permite a HNSW navegar rápidamente por el grafo para encontrar a los vecinos más próximos. Como HNSW está optimizado para CPU, también podemos paralelizar su ejecución en varios núcleos de CPU para acelerar aún más el proceso de búsqueda vectorial.
Sin embargo, el tiempo de cálculo de HNSW sigue siendo menor a medida que almacenamos más datos en la base de datos vectorial. Puede llegar a ser incluso peor si la dimensionalidad de nuestros vectores es muy alta. Por lo tanto, necesitamos otra solución para los casos en los que tenemos un gran número de vectores con alta dimensionalidad.
Operación de búsqueda de vectores en la GPU
Una solución para mejorar el rendimiento de la búsqueda vectorial cuando tratamos con un número enorme de vectores de alta dimensionalidad es operar en una GPU. **Para ello, podemos utilizar RAPIDS cuVS de NVIDIA, una librería que contiene varias implementaciones de búsqueda vectorial optimizadas para la GPU y que simplifica el uso de la GPU tanto para las operaciones de búsqueda vectorial como para la creación de índices.
cuVS ofrece varios algoritmos de vecino más próximo entre los que elegir, entre los que se incluyen:
Brute-force**: Una búsqueda exhaustiva de vecinos más cercanos en la que la consulta se compara con cada vector de la base de datos.
IVF-Flat**: Algoritmo de aproximación al vecino más próximo (ANN) que divide los vectores de la base de datos en varias particiones que no se intersectan. A continuación, la consulta sólo se compara con los vectores de las mismas particiones (y, opcionalmente, con los vectores vecinos).
IVF-PQ**: Una versión cuantificada de IVF-Flat que reduce la huella de memoria de los vectores almacenados en la base de datos.
CAGRA](https://zilliz.com/blog/Milvus-introduces-GPU-index-CAGRA): Un algoritmo nativo de GPU similar a HNSW.
Construcción de grafos CAGRA. .png](https://assets.zilliz.com/CAGRA_graph_construction_66cac84208.png)
Construcción de grafos CAGRA. Fuente._
Entre estos algoritmos de vecino más próximo, nos centraremos en CAGRA.
CAGRA es un algoritmo basado en grafos introducido por NVIDIA para realizar búsquedas aproximadas de vecinos más próximos de forma rápida y eficiente, aprovechando la capacidad de procesamiento paralelo de las GPU.
El grafo de CAGRA puede construirse utilizando el método IVF-PQ o el método NN-DESCENT:
Método IVF-PQ**: Utiliza un índice para crear un grafo inicial eficiente en memoria conectando cada punto a muchos vecinos.
Método NN-DESCENT**: Utiliza un proceso iterativo para construir un grafo ampliando y refinando las conexiones entre puntos.
En comparación con HNSW, los métodos de construcción de grafos de CAGRA son más fáciles de paralelizar y contienen menos interacción de datos entre tareas, lo que mejora significativamente el tiempo de construcción de grafos o índices. Si desea conocer más detalles sobre CAGRA, consulte su documento oficial o el artículo sobre CAGRA.
CAGRA ha establecido un rendimiento puntero en las operaciones de búsqueda vectorial. Para demostrarlo, compararemos su rendimiento con el de HNSW en la siguiente sección.
Comparación del rendimiento de CAGRA y HNSW
Hay dos operaciones críticas en la búsqueda vectorial en las que el rendimiento es crucial: la construcción del índice y la búsqueda propiamente dicha. Compararemos el rendimiento de CAGRA y HNSW en estas dos operaciones.
Empecemos por la creación de índices.
Comparación del tiempo de creación de índices entre CAGRA y HNSW..png](https://assets.zilliz.com/Index_building_time_comparison_CAGRA_vs_HNSW_f6fcb14b30.png)
Comparación del tiempo de creación de índices entre CAGRA y HNSW.
En la visualización anterior, comparamos el tiempo de creación de índices de CAGRA y HNSW en dos escenarios diferentes. En primer lugar, tenemos 10 millones de vectores de 128 dimensiones almacenados en una base de datos vectorial y, en segundo lugar, tenemos 1 millón de vectores de 768 dimensiones. El primer escenario utiliza AMD Graviton2 como CPU para HNSW y GPU A10G para CAGRA, mientras que el segundo escenario utiliza Intel Xeon Ice Lake como CPU para HNSW y GPU A10G para CAGRA.
Comparamos el tiempo de creación del índice con cuatro valores de recall diferentes, que van del 80% al 99%. Como ya sabrás, cuanto mayor es la recuperación, más intensivo es el cálculo necesario.
Esto se debe a que en una búsqueda vectorial basada en grafos, podemos ajustar dos factores: el número de vecinos considerados para encontrar al vecino más cercano en cada capa y el número de vecinos más cercanos a considerar como punto de entrada en cada capa. Cuanto mayor sea el recall, más vecinos se considerarán, lo que se traduce en una mayor precisión de la recuperación, pero también en un mayor coste computacional.
De la visualización anterior se desprende que el uso de la GPU es más útil cuando queremos obtener resultados con una alta recuperación. Además, la velocidad que se obtiene al utilizar la GPU aumenta a medida que incrementamos el número de vectores de alta dimensión almacenados en nuestra base de datos vectorial.
A continuación, vamos a comparar el rendimiento de HNSW y CAGRA utilizando dos métricas habituales en la búsqueda vectorial:
Rendimiento total**: el número de consultas que pueden completarse en un intervalo de tiempo específico.
Latencia**: el tiempo que necesita el algoritmo para completar una consulta.
Comparación de rendimiento y latencia entre CAGRA y HNSW..png](https://assets.zilliz.com/Throughput_and_latency_comparisons_CAGRA_vs_HNSW_42e9e78b44.png)
Comparación de rendimiento y latencia entre CAGRA y HNSW.
Para evaluar el rendimiento, observamos el número de consultas que pueden completarse en un segundo. Los resultados muestran que la velocidad de CAGRA en la GPU aumenta a medida que necesitamos resultados con valores de recall más altos. La misma tendencia se observa en el caso de la latencia, donde la velocidad aumenta a medida que se incrementa el valor de recall. Esto confirma que el valor de utilizar la GPU aumenta a medida que buscamos resultados más precisos en la búsqueda vectorial.
Sin embargo, a veces seguimos queriendo utilizar la CPU durante la búsqueda vectorial por su sencillez y fácil integración con otros componentes de nuestra aplicación de IA. En este caso, la implementación de algoritmos de vecinos más cercanos con CAGRA sigue siendo útil porque podemos realizar la búsqueda vectorial tanto en la GPU como en la CPU después.
Comparación de rendimiento entre el gráfico nativo HNSW y el gráfico CAGRA utilizado en la búsqueda HNSW..png](https://assets.zilliz.com/Throughput_comparison_between_HNSW_native_vs_CAGRA_graph_used_in_HNSW_search_c44ecbf71d.png)
Comparación de rendimiento entre el gráfico nativo HNSW y el gráfico CAGRA utilizado en la búsqueda HNSW.
La idea es utilizar la potencia de aceleración de CAGRA y la GPU durante la creación de índices y, a continuación, cambiar a HNSW durante la búsqueda vectorial. Este método es posible porque el algoritmo HNSW puede realizar una búsqueda utilizando un grafo construido por CAGRA, y su rendimiento es incluso mejor que el grafo construido con HNSW a medida que aumenta la dimensión del vector.
CAGRA también ofrece un método de cuantización llamado CAGRA-Q para comprimir aún más la memoria de los vectores almacenados. Esto es particularmente útil para hacer más eficiente la asignación de memoria y nos permite almacenar vectores cuantizados en una memoria de dispositivo más pequeña para una recuperación más rápida.
Supongamos que tenemos una memoria de dispositivo de menor tamaño que la memoria host. Las pruebas de rendimiento iniciales de NVIDIA mostraron que los vectores cuantificados almacenados en la memoria del dispositivo con el gráfico almacenado en la memoria host tendrán un rendimiento similar en comparación con los vectores originales sin cuantificar y el gráfico almacenado en la memoria del dispositivo a tasas de recuperación más altas.
Flujo de trabajo de búsqueda vectorial utilizando memoria de dispositivo y CAGRA-Q..png](https://assets.zilliz.com/Vector_search_workflow_by_utilizing_device_memory_and_CAGRA_Q_f299b007be.png)
Flujo de trabajo de búsqueda de vectores utilizando memoria de dispositivo y CAGRA-Q.png
Milvus en la GPU con CuVS
Milvus** soporta la integración con la biblioteca cuVS, lo que nos permite combinar Milvus con CAGRA para crear aplicaciones de IA. La arquitectura de Milvus consta de varios nodos, como nodos de índice, nodos de consulta y nodos de datos. cuVS optimiza el rendimiento de Milvus acelerando los procesos dentro de los nodos de consulta y los nodos de índice.
cuVS es compatible con los nodos de consulta e índice de la arquitectura Milvus..png](https://assets.zilliz.com/cu_VS_supports_both_query_and_index_nodes_of_Milvus_architecture_811a8ae3e3.png)
cuVS es compatible con los nodos de consulta e índice de la arquitectura Milvus.
Como ya sabrá, los nodos de índice son responsables de la creación de índices, mientras que los nodos de consulta procesan las consultas de los usuarios, realizan búsquedas vectoriales y devuelven los resultados al usuario. En la sección anterior hemos visto cómo CAGRA mejora todos estos aspectos en comparación con algoritmos nativos de CPU como HNSW.
Ahora, examinemos el rendimiento de la creación de índices con cuVS y Milvus on-premise. Específicamente, veremos el tiempo de construcción del índice utilizando CAGRA e IVF-PQ a través de diferentes números de vectores: 10, 20, 40 y 80 millones.
Escalado cuVS del tiempo de creación de índices con diferentes algoritmos de vecinos más cercanos..png](https://assets.zilliz.com/cu_VS_scaling_of_index_building_time_across_different_nearest_neighbors_algorithms_45eb5f8aec.png)
Escala cuVS del tiempo de creación de índices en diferentes algoritmos de vecinos más cercanos.
Como era de esperar, el tiempo de ingesta aumenta a medida que aumenta el número de vectores almacenados. Sin embargo, el tiempo de construcción del índice se mantiene constante a medida que añadimos más GPU de forma lineal en función del número de vectores almacenados. Esto nos permite escalar y comparar el tiempo de creación de índices entre distintos algoritmos de vecino más próximo con cuVS.
Sabemos que las GPU ofrecen operaciones de cálculo más rápidas que las CPU. Sin embargo, el coste operativo de utilizar GPUs también es mayor. Por lo tanto, tenemos que comparar la relación coste-rendimiento del uso de GPUs y CPUs con Milvus, como se muestra a continuación.
Comparación del tiempo de creación de índices de Milvus entre GPU y CPU..png](https://assets.zilliz.com/Milvus_index_building_time_comparison_between_GPU_and_CPU_3bb7e13b41.png)
Comparación del tiempo de creación de índices de Milvus entre GPU y CPU.
El tiempo de creación de índices utilizando la GPU es significativamente más rápido que el de la CPU. En este caso de uso, Milvus acelerado en la GPU ofrece una velocidad 21 veces superior a la de su homólogo en la CPU. Sin embargo, el coste operativo de las GPU también es más caro que el de las CPU. La GPU cuesta 16,29 dólares por hora, mientras que la CPU cuesta 9,68 dólares por hora.
Cuando normalizamos la relación coste-rendimiento de las GPU y las CPU, el uso de las GPU para la construcción de índices sigue dando mejores resultados. Con el mismo coste, el tiempo de creación de índices es 12,5 veces más rápido utilizando las GPU.
En otra prueba comparativa, construimos un índice para 635 millones de vectores de 1024 dimensiones. Utilizando 8 GPUs DGX H100, el tiempo de creación del índice con el método IVF-PQ es de unos 56 minutos. En cambio, utilizar una CPU para realizar la misma tarea llevaría aproximadamente 6,22 días.
Comparación del tiempo de creación de índices de Milvus a gran escala entre GPU y CPU..png](https://assets.zilliz.com/Large_scale_Milvus_index_building_time_comparison_between_GPU_and_CPU_c987afe852.png)
Comparación del tiempo de creación de índices de Milvus a gran escala entre GPU y CPU.
Conclusión
Los avances en la búsqueda vectorial acelerada en la GPU a través de la librería cuVS de NVIDIA y el algoritmo CAGRA son muy beneficiosos para optimizar el rendimiento de las aplicaciones de IA en producción. En concreto, las GPU ofrecen mejoras significativas con respecto a las CPU en casos que implican altos valores de recall, alta dimensionalidad de los vectores y un gran número de vectores.
Gracias a las capacidades de integración de Milvus, ahora podemos incorporar fácilmente cuVS a nuestra base de datos de vectores de Milvus". Aunque las GPU tienen costes operativos más elevados que las CPU, la relación rendimiento-coste suele seguir favoreciendo a las GPU en aplicaciones a gran escala, tal y como demuestran los benchmarks anteriores. Si desea obtener más información sobre cuVS, puede consultar la documentación completa proporcionada por el equipo de NVIDIA.
Otros recursos
¿Qué es RAG? ](https://zilliz.com/learn/Retrieval-Augmented-Generation)
¿Qué son las bases de datos vectoriales y cómo funcionan?](https://zilliz.com/learn/what-is-vector-database)
Cómo mejorar el rendimiento de su canalización RAG](https://zilliz.com/learn/how-to-enhance-the-performance-of-your-rag-pipeline)
Búsqueda vectorial eficiente en RecSys con Milvus y NVIDIA Merlin](https://zilliz.com/blog/efficient-vector-similarity-search-recommender-workflows-using-milvus-nvidia-merlin)
Generative AI Resource Hub | Zilliz](https://zilliz.com/learn/generative-ai)
Sigue leyendo

Zilliz Named "Highest Performer" and "Easiest to Use" in G2's Summer 2025 Grid® Report for Vector Databases
Zilliz shines in G2's Summer 2025 Grid® Report as both "Highest Performer" and "Easiest to Use," solving the performance-usability dilemma.

Build for the Boom: Why AI Agent Startups Should Build Scalable Infrastructure Early
Explore strategies for developing AI agents that can handle rapid growth. Don't let inadequate systems undermine your success during critical breakthrough moments.

Why Deepseek is Waking up AI Giants Like OpenAI And Why You Should Care
Discover how DeepSeek R1's open-source AI model with superior reasoning capabilities and lower costs is disrupting the AI landscape and challenging tech giants like OpenAI.