




Zilliz Cloud On-Demand-Computing: Zahlen Sie nur für das, was Sie nutzen
Im letzten Quartal haben wir einen Abrechnungsfall mit einem Kunden aus dem Bereich autonomes Fahren bearbeitet. Dessen Analytics-Team benötigte Vektorsuche auf einer Sammlung mit 1 Milliarde Zeilen. Wir dimensionierten sie auf einem Dedicated cluster: $7.000/Monat. Wir testeten Serverless: $10.800. Die eigentliche Analytics-Arbeit umfasste nur wenige Stunden pro Monat.
Beide Rechnungen waren korrekt. Beide Produkte taten genau das, wofür sie entwickelt wurden. Das Problem war, dass der Workload dieses Kunden — sporadische Analytics, die sich einen Datensatz mit zwei anderen Produktions-Workloads teilten — nicht zu dem passte, wofür eines der beiden Produkte entwickelt wurde.
Dieser Fall ist der Grund, warum wir Zilliz Cloud On-Demand Search entwickelt haben — eine der neuen Funktionen, die wir mit dem Launch der Zilliz Vector Lakebase ausgeliefert haben. Derselbe Workload, unter $500/Monat. Im Folgenden geht es darum, was nicht passte, was wir geändert haben, wo On-Demand das falsche Tool ist und wie es am Ende wieder in Vector Lakebase hineinpasst.
Der Kundenfall
Die Sammlung — etwa 1 Milliarde Datensätze — wurde bereits von zwei Produktions-Workloads genutzt:
- Ein Online-Retrieval-Service, der Echtzeit-Traffic bedient.
- Eine Model-Training-Pipeline, die Szenariodaten für Regression-Jobs abruft (betrieben von einem separaten Team).
Analytics war ein dritter Workload, der zusätzlich auf dieselben Daten aufgesetzt wurde. Das Zugriffsmuster: Analysten führten Suchen nur dann aus, wenn sie eine konkrete Frage hatten, in kurzen iterativen Schüben, getrieben durch die aktuelle Untersuchung. In der übrigen Zeit trafen keine analytischen Abfragen auf den Cluster.
Das ist ein recht typischer Zilliz-Anwendungsfall bei einer recht typischen Datengröße. Schwierig wurde es dadurch, dass alle drei Workloads aus derselben zugrunde liegenden Sammlung lesen mussten und jeder davon einen ganz anderen Takt hatte.
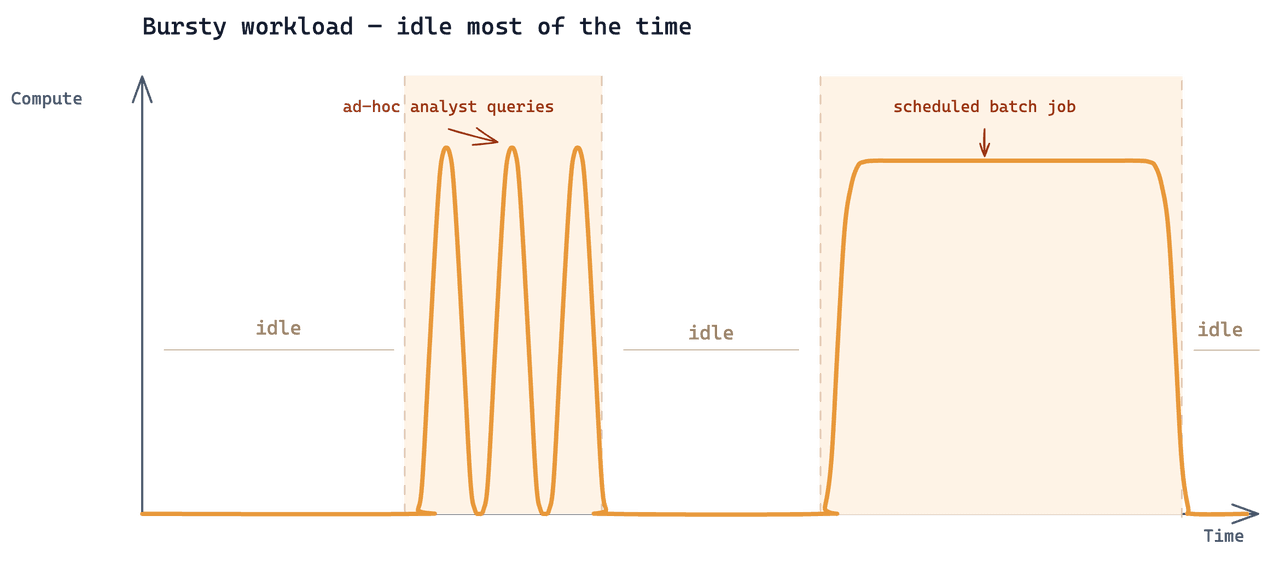
Warum der Dedicated Cluster nicht passte
Das bestehende Setup war ein Zilliz Cloud Tiered-Cluster mit 24 CU. Das Hinzufügen des Analytics-Workloads dazu lag preislich bei ~$7.000/Monat. Der Cluster wird für jede Stunde abgerechnet, in der er existiert: 24 × 30 = 720 Stunden/Monat. Die eigentliche Analytics-Arbeit verbrauchte 2–3 Stunden. Die übrigen 717 Stunden wurden für Leerlauf abgerechnet — 99,6 % der Gesamtausgaben entfielen auf Kapazität, die niemand nutzte.
Sie können einen Dedicated Cluster zwischen Sitzungen stoppen, um Leerlaufstunden zu vermeiden. Wir haben das in Betracht gezogen. Es funktioniert aus zwei Gründen nicht.
Erstens dauert ein Kaltstart auf Dedicated bei analytischen Kaltabfragen auf einem Datensatz dieser Größe mehr als 10 Minuten. Das Denkmodell von Dedicated ist, dass alle erforderlichen Daten im lokalen Speicher liegen müssen, bevor Abfragen ausgeführt werden. Daher lädt es den gesamten Working Set vor — typischerweise ein Vielfaches von zehn bis hundert der Datenmenge, die eine einzelne Kaltabfrage tatsächlich berührt. Derselbe Ladevorgang muss außerdem den Zustand für Nicht-Abfrage-Arbeiten herstellen, die der Cluster unterstützt, wie DDL und Löschvorgänge. Dieser Overhead besteht unabhängig davon, ob die nächste Abfrage ihn benötigt oder nicht.
Zweitens rundet die Abrechnung auf die Stunde auf. Selbst wenn der Analyst also bereit wäre, mehr als 10 Minuten zu warten, bis der Cluster aufgewärmt ist, beträgt die Rechnung für eine einzelne Abfrage dennoch eine Stunde plus den Ladevorgang. Da Analysten in kurzen iterativen Schüben arbeiten, bleiben die Kosten pro nützlicher Abfrage hoch, egal wie diszipliniert das Start/Stop-Verfahren ist.
Warum der Serverless Cluster nicht passte
Serverless war die nächste Option, die wir ausprobierten. Auf dem Papier ist es die richtige Form für dieses Zugriffsmuster: zustandslos, Pay-per-Query, keine Leerlauf-Compute-Kosten. Für den Analytics-Workload allein hätte es funktionieren können.
Der Haken ist, dass Serverless auf diesem Datensatz den Analytics-Workload nicht isoliert bepreist. Es bepreist alles, was auf die Sammlung zugreift. Sobald wir die bestehenden Workloads einbezogen, kippten drei Posten die Rechnung:
- Abfragen: ~$6.000/Monat. Der größte Teil davon stammt von den zweiwöchentlichen Regressionsjobs des Modelltraining-Teams — 100 QPS für 3 Stunden, alle zwei Wochen. Serverless-Einheitspreise enthalten einen Aufschlag für Cold Queries, der bei jeder Abfrage bezahlt wird, selbst wenn die Abfrage hot ist. Sobald das Abfragevolumen nicht mehr trivial niedrig ist, geht die Rechnung nicht mehr auf.
- Speicher: $1.700/Monat. Separat gemessen, weil Serverless keine Compute-Stunden-Gebühr hat, in die Speicher eingepreist werden könnte.
- Schreibvorgänge: $3.000/Monat. Aus demselben Grund — keine Compute-Stunde, in die sie eingepreist werden könnten.
Gesamt: $10.784/Monat, höher als der Dedicated-Cluster, dem wir entkommen wollten.
Hinter jedem dieser Aufschläge steht ein struktureller Grund.
Abfragen tragen einen Cold-Query-Aufschlag. Aus Sicht des Nutzers ist Serverless zustandslos. Aus Sicht der Plattform müssen Daten trotzdem auf bestimmte Maschinen geladen werden, um ausgeführt zu werden. Abfragen teilen sich in hot (Daten bereits auf der Maschine) und cold (zuerst Abruf aus dem Objektspeicher). Hot Queries sind günstig; Cold Queries sind teuer. Die Plattform kann nicht vorhersagen, welche Abfragen für einen bestimmten Nutzer cold sein werden, also verteilt sie die Cold-Query-Kosten auf den Einheitspreis jeder Abfrage. Workloads mit überwiegend hot Queries zahlen am Ende für die cold Queries aller anderen.
Speicher wird über den Grenzkosten bepreist. Bei Dedicated laufen Speicher- und Schreibkosten unsichtbar über die Compute-Stunden-Gebühr mit. Serverless hat keine Compute-Stunden-Gebühr, hinter der sich diese Kosten verstecken könnten, also wird Speicher explizit berechnet. Dieser explizite Preis muss Daten abdecken, die gespeichert, aber nie abgefragt werden — die Plattform kann sie nicht in einen wirklich kalten Speicher verschieben, weil Daten jederzeit abfragebereit bleiben müssen. Diese Bereitschaft aufrechtzuerhalten erfordert zusätzlichen Zustand, und seine Kosten werden letztlich auf die Speichergröße umgelegt, die tatsächlich nicht dem realen Verbrauch entspricht.
Schreibvorgänge werden ebenfalls über den Grenzkosten bepreist. Schreibvorgänge werden separat gemessen, um Nutzer davon abzuhalten, hochfrequente Updates auszuführen, die viele Schreibkosten verursachen, ohne den Datensatz wachsen zu lassen (wodurch die Plattform andernfalls die Kosten tragen müsste). Dieselbe Dynamik wie beim Speicher: Die Kosten des Bereitschaftszustands fließen in den Einheitspreis pro Schreibvorgang ein.
Das tiefere Problem ist, dass Serverless die Abstraktion der „Compute-Ressource“ vor dem Nutzer verbirgt. Der Nutzer sieht eine zustandslose Schnittstelle; die Plattform muss trotzdem für unvorhersehbare Zugriffsmuster im Hintergrund zahlen — hot/cold Daten, sprunghafter Traffic, ungenutzter Speicher, der abfragebereit bleiben muss. Diese Kosten können bestimmten Nutzern nicht präzise zugeordnet werden, also werden sie auf die Einheitspreise von Abfragen, Speicher und Schreibvorgängen umgelegt. Jede abrechenbare Aktion liegt am Ende eine Stufe über ihren realen Grenzkosten.
Dies ist ein „Shared-Risk“-Modell: Jeder Posten enthält einen Aufschlag, um die Cold Queries, Bursts oder den ungenutzten Speicher anderer abzudecken. Die Workloads, die für diese Varianz am wenigsten verantwortlich sind — stabile, hochfrequente, vorhersehbare hot Queries — zahlen den größten Anteil des Aufschlags. Je stabiler dein Workload, desto mehr subventionierst du am Ende.
Was der Kunde tatsächlich brauchte
Mit etwas Abstand betrachtet war die Anforderung des Kunden nicht exotisch. Ein Datensatz, mehrere Zugriffskadenzen, wobei die Rechnung nur der Compute-Leistung folgt, die jede Kadenz tatsächlich genutzt hat.
- Online-Abruf: kontinuierlich, niedrige Latenz, vorhersehbar. Dedicated ist dafür richtig.
- Modelltraining: sprunghaft, aber vorhersehbar — 3 Stunden alle zwei Wochen.
- Analytics: selten und unvorhersehbar — jeweils ein paar Minuten, mit langen Pausen.
Dedicated konnte das nicht liefern. Es rechnet bereitgestellte Kapazität ab, nicht Verbrauch. Serverless konnte es ebenfalls nicht: Sein Einheitspreis pro Abfrage muss Cold Queries, ungenutzten Speicher und Burst-Kapazitätsreserven über alle Nutzer der Plattform hinweg subventionieren, sodass stabile Workloads am Ende für Varianz zahlen, die sie nicht verursachen.
Was wir brauchten, war ein drittes Compute-Modell — eines, das sich an dieselben Daten wie Dedicated anbinden, schnell genug hochfahren konnte, um eine Abrechnung pro Abfrage realistisch zu machen, und nur dann abgerechnet wird, wenn es tatsächlich läuft.
Was wir geändert haben
On-Demand ist ein separates Compute-Modell auf Zilliz Cloud, das neben Dedicated und Serverless existiert. Im Vergleich zu beiden ändert es drei Dinge:
- Kaltstart. Es werden nur die Chunks geladen, die die aktuelle Abfrage berührt, nicht der vollständige Working Set. Sinkt von über 10 Minuten auf Sekunden.
- Abrechnung. Pro Minute der tatsächlichen Compute-Laufzeit. Schreibvorgänge ebenfalls. Keine Mindeststunde, kein Cold-/Hot-Aufschlag pro Abfrage.
- Isolation. Jede Workload wird über ihre eigene Compute-Ressourcengruppe an eine Collection angebunden. Dieselben Daten, keine Konkurrenz.
Die nächsten drei Abschnitte gehen auf jeden Punkt ein.
Weniger Daten laden, schneller
Der 10-minütige Kaltstart bei Dedicated existiert, weil der Cluster den vollständigen Working Set in den lokalen Speicher ziehen muss, bevor er Abfragen bedienen kann. Bei einer Collection mit 1 Mrd. Zeilen sind das zehn- bis hundertmal mehr Daten, als eine einzelne Abfrage tatsächlich benötigt. Den Kaltstart auf Sekunden zu verkürzen bedeutet, diese Annahme fallen zu lassen: Es wird nur geladen, was die aktuelle Abfrage berührt.
Das klingt nach einem Satz; in der Praxis erforderte es die Neugestaltung von drei Ebenen — was gelesen wird, wo es abgelegt wird und wie es hochgefahren wird.
Indizes, die teilweise geladen werden.
Auf der skalaren Seite ist Predicate Pushdown Standardpraxis. Die Engine eliminiert Blöcke, die nicht zum Prädikat passen können, und überspringt deren Abruf. Wir nutzen dies bei invertierten Indizes: Jede Posting-Liste wird als Block geladen, und jede Liste enthält Min-/Max-Statistiken, die die Engine vor dem Abrufen prüfen kann.
Der schwierigere Teil bestand darin, der Vektorseite eine vergleichbare Fähigkeit zum „Lesen einer Teilmenge“ zu geben. Graph-Indizes — die leistungsstärkere Option für QPS im stabilen Betrieb — degradieren bei teilweisem Laden nicht elegant: Die Struktur muss vollständig geladen werden, um nützlich zu sein, daher sind die Kosten für das Cold Loading hoch.
On-Demand verwendet stattdessen die IVF-Familie. IVF clustert Vektoren zur Indexierungszeit in Buckets, und zur Abfragezeit werden nur die Buckets abgerufen, die der Abfrage am nächsten liegen. Das gibt der Vektorseite etwas, das Predicate-Pushdown-Semantik nahekommt: Kalte Abfragen ziehen einen kleinen Bruchteil des Index, nicht den gesamten Index.
Dies ist ein bewusster Kompromiss. Wir verlieren die Steady-State-Performance von Graph-Indizes, was der Hauptgrund dafür ist, dass On-Demand nicht für High-QPS-Serving geeignet ist (mehr dazu weiter unten). Für spärliche und stoßweise Workloads lohnt sich dieser Kompromiss.
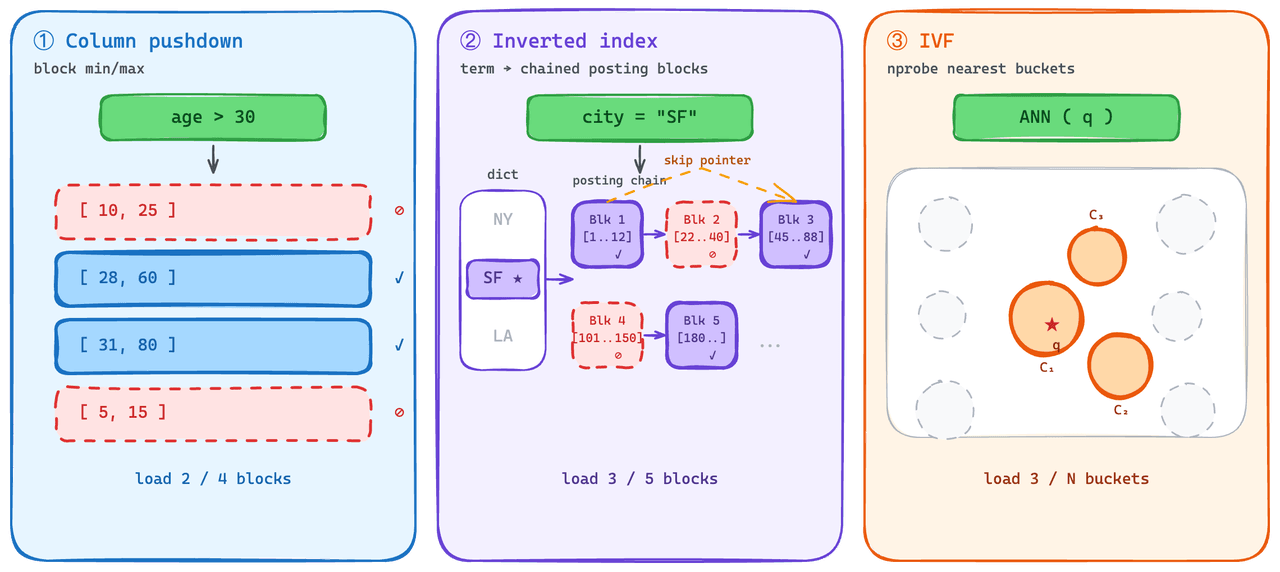
Ein dreistufiger Datenpfad.
Sobald wir wissen, was gelesen werden muss, ist die nächste Frage, wo es gehalten werden soll. Chunks bewegen sich frei zwischen S3, lokaler Festplatte und Speicher, und der Cache-Lebenszyklus wird zwischen Abfragen pro Chunk verwaltet: Chunks, die die aktuelle Abfrage benötigt, werden hochgezogen; Chunks, die lange genug inaktiv bleiben, werden verworfen. Derselbe Datensatz kann in sehr unterschiedlichen Takten abgefragt werden, und keiner davon zahlt die Kosten für das Laden von Daten, die er nicht berührt.
Jede Ebene hat ihr eigenes Datenlayout und ihre eigene Granularität, angepasst an die IO-Eigenschaften des Mediums — die Ausrichtung, die für Objektspeicher funktioniert, ist nicht die Ausrichtung, die für lokale Festplatten funktioniert, und keine von beiden entspricht dem, wogegen die Engine im Speicher ausführt.
Async IO durchgehend.
Die IO-Kette ist vollständig asynchron. Compute und IO werden durchgängig per Pipeline verarbeitet, sodass die CPU nicht auf einen Abruf wartet und die IO-Bandbreite nicht auf Compute wartet.
In Summe reduzieren chunked + tiered + async die Cold-Query-Payload auf unter 1–2% des vollständigen Datensatzes und den End-to-End-Cold-Path auf Sekunden.
Abrechnung pro Minute
Mit Kaltstart auf Sekundenebene funktioniert „Compute hochfahren, wenn eine Abfrage eintrifft, und freigeben, wenn sie endet“ als tatsächlicher Produktmechanismus — nicht nur als Designziel. Zwei Teile der Control Plane leisten die Hauptarbeit.
Ein Standby-Node-Pool. Image-Pulls erhöhen die Latenz beim Hochfahren eines frischen Node. Wir halten einen kleinen Pool vorab geladener Nodes bereit, sodass das Hochfahren aus dem Pool erfolgt, statt von Grund auf neu zu starten.
TTL-basierte Freigabe. Jede Sitzung hat ein konfigurierbares Idle-Timeout. Compute-Ressourcen werden automatisch freigegeben, wenn das Timeout auslöst, die Query-Workload endet oder die Sitzung geschlossen wird. Der gesamte Lebenszyklus wird von der Plattform geplant — kein „Ich habe vergessen, meinen Cluster zu stoppen“-Modus, kein manueller Betrieb.
Da der Lebenszyklus feingranular ist, sinkt die Abrechnungsgranularität entsprechend. Compute wird pro Minute tatsächlicher Uptime abgerechnet — keine Mindeststunde, keine Mindestgebühr pro Query. Schreibvorgänge werden auf die gleiche Weise gemessen: tatsächliche Ressourcennutzung, pro Minute.
Die Präzision der Kostenzuordnung ist der Grund, warum On-Demand den Storage-Aufschlag vermeiden kann, den Serverless berechnen muss. Serverless bepreist Storage über den Grenzkosten, weil seine Compute-Schicht keine Möglichkeit hat, nicht zugeordnete Kosten aufzufangen — jeder Dollar, den die Plattform ausgibt, muss irgendwo auf der Rechnung landen, daher werden Storage und Schreibvorgänge zum Auffangbecken für das, was anderswo nicht zugeordnet werden kann. Wenn On-Demand jede Minute Compute einer bestimmten Sitzung in Rechnung stellt, gibt es keinen nicht zugeordneten Pool. Storage auf On-Demand folgt den Zilliz Cloud pricing zu Dedicated-Tarifen — etwa 1/10 des typischen Serverless-Storage.
Workload-Isolierung auf gemeinsamen Daten
Die dritte Änderung besteht darin, die Compute-Schicht explizit zu machen. Bei Dedicated ist die Compute-Schicht der Cluster — für den Benutzer unsichtbar, außer als einzelner Größenparameter. Bei Serverless ist die Compute-Schicht vollständig verborgen. On-Demand macht sie sichtbar.
Jede Workload verbindet sich über eine Compute-Ressourcengruppe mit einer Collection. Neue Gruppen werden über Sitzungen hochgefahren — oder bestehende wiederverwendet. Unterschiedliche Gruppen sind voneinander isoliert, und die Rechnung jeder Gruppe spiegelt nur ihren eigenen Verbrauch wider.
Für den Autonomous-Driving-Anwendungsfall erhält die Analytics-Workload so ihre eigene Anbindung an die Daten: eine On-Demand-Ressourcengruppe, die für Ad-hoc-Queries hochfährt und bei Inaktivität freigegeben wird, ausgeführt auf derselben Milvus collection, denselben Indizes und denselben Metadaten wie die bestehenden Workloads für Online-Retrieval und Modelltraining. Storage-Compute-Trennung bedeutet, dass keine von ihnen Daten kopieren oder synchronisieren muss, um sie zu nutzen. Keine Quersubventionierung, keine Scheduling-Konflikte, keine operative Abstimmung zwischen Teams über die Cluster-Form.
Dies ist dasselbe architektonische Muster wie bei einem Data Lake, angewendet auf Vektorsuche: Storage ist das gemeinsame Substrat, und Compute wird in der Form angebunden, die jede Workload benötigt.
Die Rechnung, danach
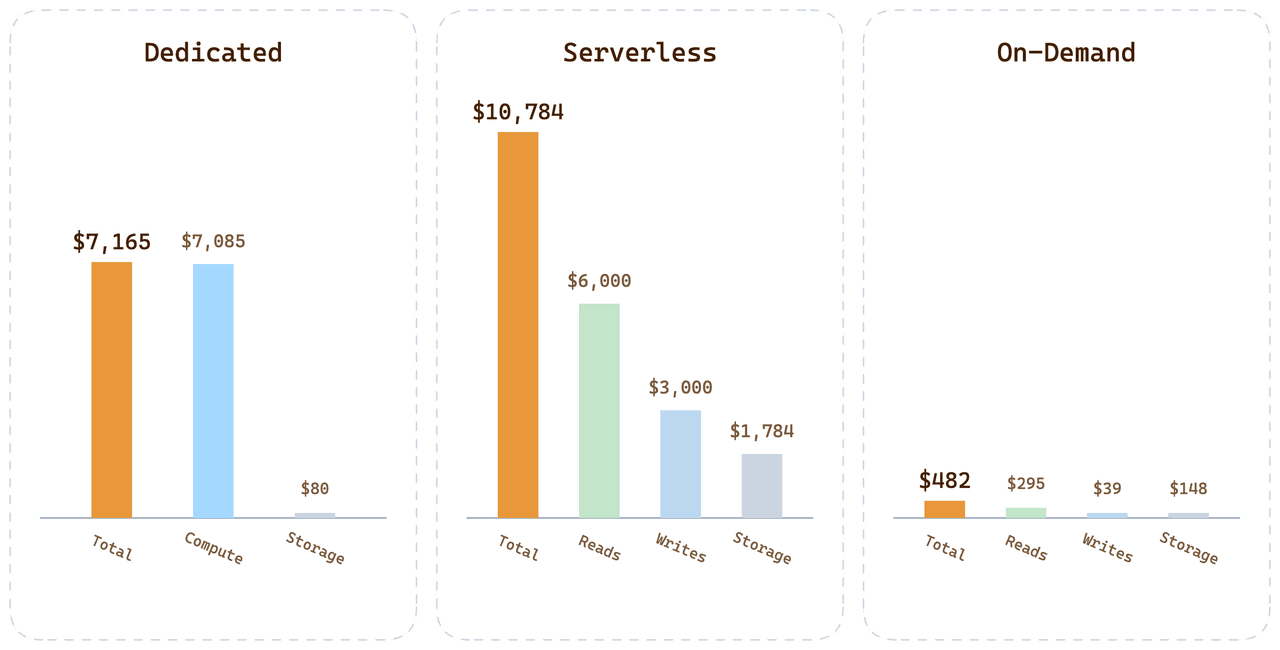
Für dieselbe Kunden-Workload über alle drei Optionen hinweg:
| Option | Monatliche Rechnung | Wohin das Geld fließt |
|---|---|---|
| Dedicated (24 CU Tiered) | $7,165 | 99,6% des Compute bezahlt, aber idle |
| Serverless | $10,784 | Query-Aufschlag + $1,700 Storage + $3,000 Schreibvorgänge |
| On-Demand | < $500 | Compute pro Minute + Storage zu Dedicated-Tarifen |
On-Demand liegt für diese Workload bei unter 1/20 der Serverless-Rechnung. Die Differenz ist kein Preistrick; sie ist die direkte Folge davon, Kosten dem tatsächlichen Verbrauch zuzuordnen, statt die Varianz anderer Benutzer in jeden Stückpreis einzupreisen.
Wo On-Demand das falsche Werkzeug ist
On-Demand ist kein universeller Ersatz für Dedicated oder Serverless. Dieselben Designentscheidungen, die es für spärliche, bursty Workloads günstig machen, machen es für andere zur falschen Wahl. Das Diagramm unten zeigt die monatlichen Kosten in Abhängigkeit vom Query-Druck für die Workload dieses Kunden über alle drei Optionen hinweg.
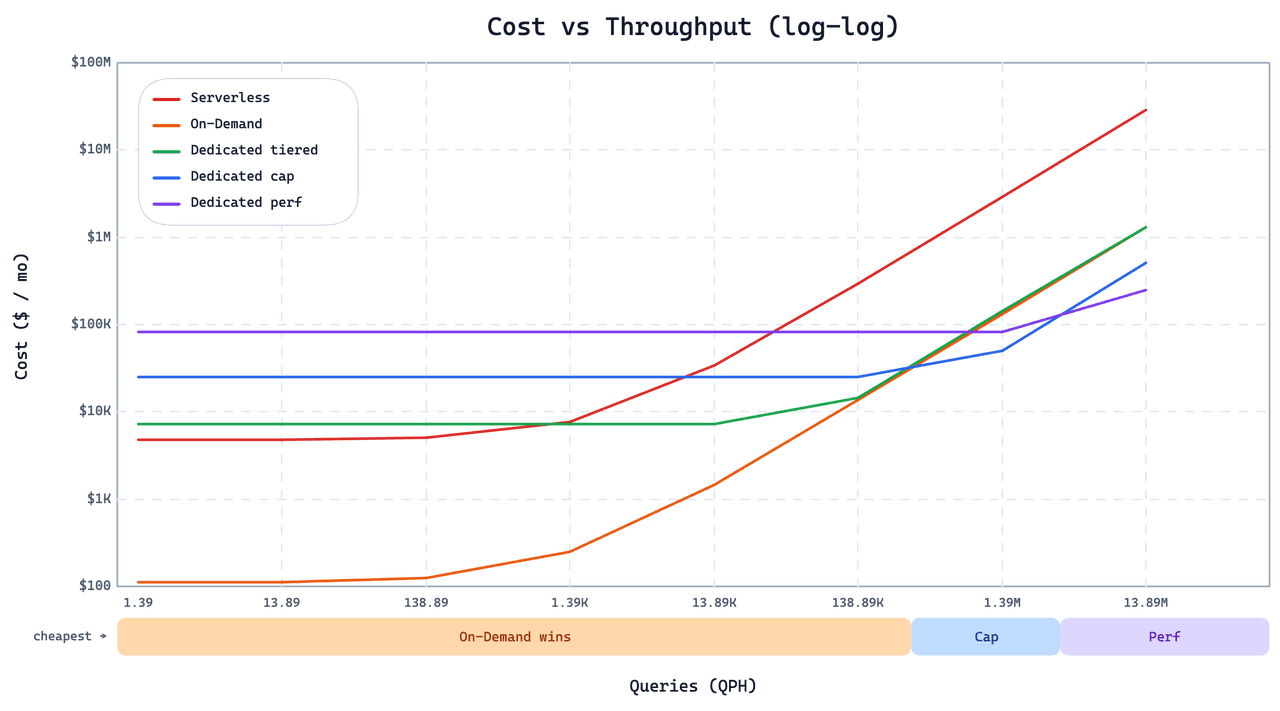
Unterhalb des Schnittpunkts ist On-Demand deutlich günstiger. Sobald QPS in den zweistelligen Bereich steigt, werden Dedicated Cap or Perf instances sowohl günstiger als auch schneller. Zwei Designentscheidungen erklären den Schnittpunkt:
Kein Graph-Index. Um das Laden von Cold Queries kostengünstig zu halten, verwendet On-Demand IVF statt Graph-Indizes. Graph-Indizes liefern bei Skalierung einen höheren Steady-State-QPS, aber ihre Cold-Load-Kosten sind hoch. Ab einigen Dutzend QPS überwiegt der Steady-State-Vorteil deutlich. Für Serving mit hohem QPS verwenden Sie Dedicated.
Höhere Tail-Latenz bei Cold Queries. On-Demand lädt Daten nicht vor, daher muss eine Cold Query einen zusätzlichen Abruf durchführen, bevor sie ausgeführt werden kann. Warm Queries sind schnell; Cold Queries sind spürbar langsamer, und die Tail-Latenzverteilung ist breiter als bei Dedicated oder Serverless. Wenn Ihre Anwendung gelegentliche Antwortzeiten im Sekundenbereich (oder schlimmer, im Minutenbereich) nicht tolerieren kann, ist On-Demand nicht das Richtige. Für diese Workloads reduziert Smart Autoscaling on Dedicated Leerlaufkapazität, ohne die Warm-State-Latenz zu beeinträchtigen.
Wofür On-Demand das richtige Werkzeug ist: spärlicher Zugriff, analytische Iteration und Batch-Mining auf großen Datensätzen — Workloads, bei denen hohe Nebenläufigkeit und strikte Latenzkonsistenz nicht die primären Anforderungen sind.
Wo dies in Zilliz Vector Lakebase hineinpasst
Der Kundenfall in diesem Beitrag ist ein Ausschnitt eines größeren Musters: derselbe Datensatz, der von verschiedenen Workloads in unterschiedlichen Takten genutzt wird und nur dann richtig dimensioniert ist, wenn jede Workload die Compute-Form erhält, die sie tatsächlich benötigt. On-Demand ist eine dieser Compute-Formen. Zilliz Vector Lakebase ist die Architektur, die den Rest möglich macht.
Eine Vector Lakebase ist eine lake-native Datenplattform für KI-Workloads. Daten liegen auf S3, Indizes sind von Compute entkoppelt, und verschiedene Compute-Formen greifen über Zero-Copy-Zugriff auf dieselbe Collection zu. Sie behandelt drei Workload-Modi als First-Class-Fähigkeiten — Echtzeit-Retrieval, iterative Discovery und Batch-Analytics — jeweils bereitgestellt durch die Compute-Form, die zum jeweiligen Zugriffsmuster passt. Vector Retrieval war auf Zilliz Cloud schon immer eine First-Class-Workload; mit dem Start von Vector Lakebase kommen Compute-Formen für iterative Discovery und Batch-Analytics auf derselben Datengrundlage hinzu.
On-Demand ist die Compute-Form, die für analytische und bursty Workloads entwickelt wurde. Die anderen vier Fähigkeiten decken die übrigen Modi ab:
- Tiered Serving Solutions für Echtzeit-Retrieval — Performance-Optimized (1000+ QPS, einstellige ms-Latenz, vollständig im Arbeitsspeicher), Capacity-Optimized (100–500 QPS bei unter 100 ms Latenz auf Arbeitsspeicher + lokalem NVMe) und Tiered-Storage (10–50 QPS bei ~100 ms Latenz über Arbeitsspeicher, NVMe und Object Store hinweg). Verschiedene Punkte auf der Performance-/Kostenkurve, derselbe Serving-Modus.
- External Data Lake Search zum Indexieren und Durchsuchen von Daten, die bereits in Lance, Iceberg oder anderen Lake-Formaten liegen — ohne sie in einen separaten Store zu kopieren.
- Full-Spectrum Search für Vektoren, Text, JSON und Geodaten auf einer einzigen Query-Ebene, mit Hybrid Retrieval, Filtering und Reranking auf einem Wide-Table-Datenmodell.
- Unified Lake-Native Storage auf Basis von Vortex, einem Open-Columnar-Format der nächsten Generation mit schnelleren Random Reads als Lance oder Parquet sowie formatbezogener Flexibilität pro Spalte.
Zilliz Vector Lakebase ist jetzt in der Public Preview auf Zilliz Cloud. Für die vollständige Architektur und die übrigen Fähigkeiten ist der Vector Lakebase deep-dive die maßgebliche Lektüre.
Um On-Demand mit Ihrer eigenen Workload auszuprobieren, registrieren Sie sich bei Zilliz Cloud und starten Sie über die Konsole oder CLI einen On-Demand-Cluster. Wenn die Zahlen in diesem Beitrag zu etwas passen, das Sie betreiben, geht das Zilliz-Team Ihre Workload gerne mit Ihnen durch, bevor Sie bauen.

Weiterlesen

How to Improve Retrieval Quality for Japanese Text with Sudachi, Milvus/Zilliz, and AWS Bedrock
Learn how Sudachi normalization and Milvus/Zilliz hybrid search improve Japanese RAG accuracy with BM25 + vector fusion, AWS Bedrock embeddings, and practical code examples.

How to Build RAG with Milvus, QwQ-32B and Ollama
Hands-on tutorial on how to create a streamlined, powerful RAG pipeline that balances efficiency, accuracy, and scalability using the QwQ-32B and Milvus.

DeepSeek Always Busy? Deploy It Locally with Milvus in Just 10 Minutes—No More Waiting!
Learn how to set up DeepSeek-R1 on your local machine using Ollama, AnythingLLM, and Milvus in just 10 minutes. Bypass busy servers and enhance AI responses with custom data.