




Zilliz Skills Breakdown: Wie KI-Agenten Vektordatenbanken meistern
Ursprünglich von ShugeX, einem unabhängigen AI-Ops-Praktiker und aktiven Mitwirkenden der Milvus-Community. Mit Genehmigung übersetzt und erneut veröffentlicht.
Stell dir vor, du verwendest Claude Code, um eine RAG-App mit Milvus zu bauen. Jeder Schritt — eine Collection erstellen, ein Schema definieren, Vektoren einfügen, hybride Suche ausführen — lässt dich durch die pymilvus-Dokumentation blättern, um die richtige API zu finden, und dann zurück in den Editor wechseln, um sie einzubauen. Und wenn du Zilliz Cloud nutzt, springst du außerdem in den Browser, um dich in der Konsole für Cluster-Management, Monitoring und Backup-Konfiguration anzumelden. Die Entwicklungsumgebung und die Betriebsumgebung sind zwei verschiedene Welten.
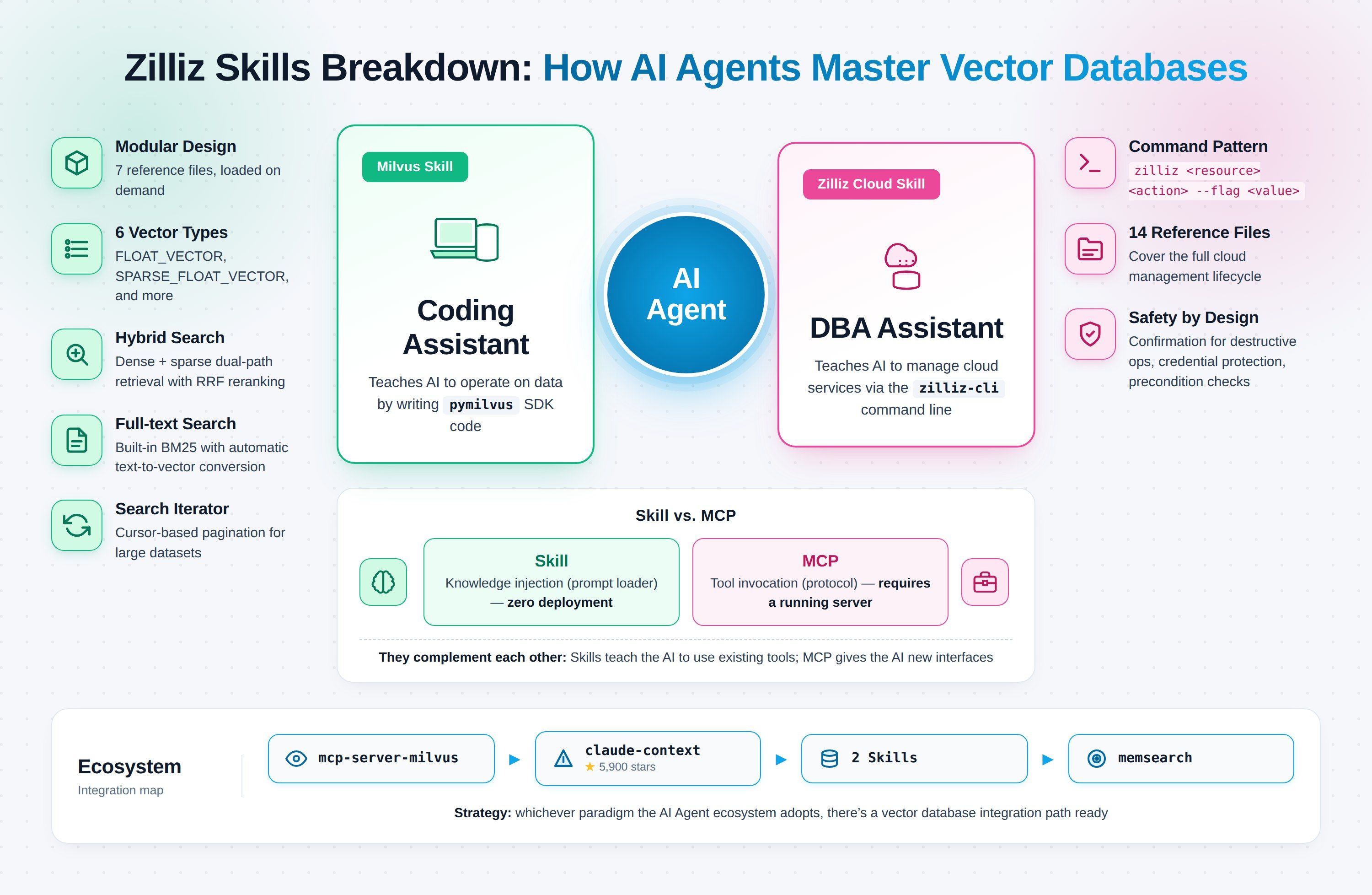
Die zwei jüngsten Claude Code Skills von Zilliz zielen genau auf diese Bruchstelle ab. Milvus Skill bringt dem Agenten bei, die Vektordatenbank über das Python SDK zu bedienen. Zilliz Cloud Skill bringt dem Agenten bei, alles auf der Cloud-Seite über zilliz-cli zu verwalten. Jeder Skill behandelt eine Domäne; zusammen verwandeln sie Entwicklung und Betrieb in eine durchgehende Claude Code-Sitzung.
Nachdem ich den Quellcode beider Skills vollständig durchgelesen hatte, fand ich vieles, das es sich aufzuschlüsseln lohnt — modulares Design, Sicherheitsmuster und wo Skill neben MCP passt. Dieser Artikel geht auf jedes davon ein.
Was Milvus Skill und Zilliz Cloud Skill jeweils tun
Die zwei Skills sind nicht zwei Versionen derselben Sache. Sie zielen auf zwei unterschiedliche Korrektheitsfehler ab.
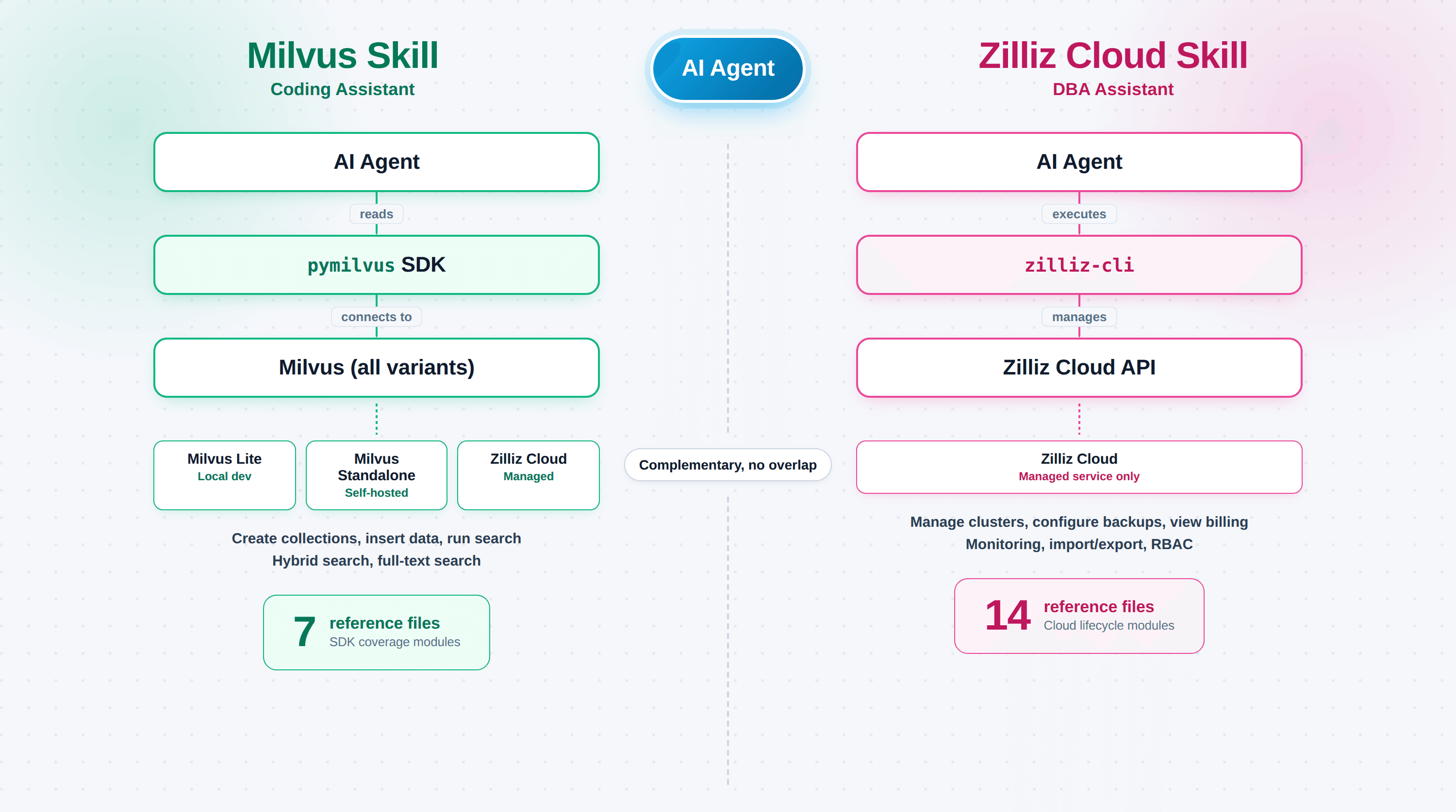
Milvus Skill (zilliztech/milvus-skill) bringt dem Agenten pymilvus bei, das Python SDK zum Verbinden, Erstellen von Collections, Einfügen von Vektoren und Ausführen von Suchen. Es ist ein Coding Assistant und funktioniert mit jeder Milvus-Bereitstellung: Milvus Lite, self-hosted Standalone/Cluster oder Zilliz Cloud. Der Fehler, den es behebt: pymilvus-Code, der kompiliert, aber nicht das tut, was du verlangt hast, weil der Agent eine veraltete API-Struktur verwendet hat.
Zilliz Cloud Skill (zilliztech/zilliz-skill) bringt dem Agenten zilliz-cli bei, das Kommandozeilentool, das Cluster, Backups, Monitoring und Abrechnung abdeckt. Es ist ein DBA Assistant und funktioniert nur mit Zilliz Cloud (self-hosted Milvus hat keine Control Plane). Der Fehler, den es behebt: halluzinierte Befehle gegen ein laufendes Produktionssystem, bei dem ein falsches zilliz cluster delete mehr kostet als ein Kompilierungsfehler.
Einzeiler:
- Milvus Skill → Agent schreibt Code, der Daten verarbeitet
- Zilliz Cloud Skill → Agent führt Befehle aus, die Services verwalten
| Dimension | Milvus Skill | Zilliz Cloud Skill |
|---|---|---|
| Schnittstelle | Python (pymilvus) | CLI (zilliz-cli) |
| Rolle | Coding Assistant | DBA Assistant |
| Funktioniert mit | Allen Milvus-Bereitstellungen + Zilliz Cloud | Nur Zilliz Cloud |
| Dateien | 7 Referenzmodule | 14 Sub-Skills |
| Korrektheitsziel | Veraltete SDK-APIs | Unzureichend dokumentierte Ops-Befehle |
| Typische Aufgabe | Collection bauen, einfügen, suchen | Cluster bereitstellen, Backup konfigurieren, Abrechnung prüfen |
Milvus Skill: Dem Agenten beibringen, zuverlässiges pymilvus zu schreiben
Der references/-Ordner von Milvus Skill enthält sieben Dateien, die jeweils einem unabhängigen pymilvus-Fähigkeitsbereich zugeordnet sind. Wenn der Agent eine bestimmte Aufgabe bearbeitet, lädt er nur die relevante Datei, statt jede Dokumentation in den Kontext zu kippen:
| Datei | Behandelt |
|---|---|
collection.md | Datentypen, Felddefinitionen, Collection-Operationen |
vector.md | Vektor-CRUD, hybride Suche, Volltextsuche, Iteratoren |
index.md | Indextypen, Metriktypen, Indexverwaltung |
partition.md | Partitionsverwaltung |
database.md | Datenbankverwaltung |
user-role.md | RBAC |
patterns.md | Gängige Muster (RAG, hybride Suche usw.) |
Ein Schema erstellen? Der Agent zieht collection.md. Eine Suche ausführen? Er zieht vector.md. Der Rest bleibt außen vor. Kontextfenster sind begrenzt; Laden bei Bedarf ist besser, als alles hineinzukippen.
Unterstützte Datentypen: Umfangreicher, als man erwarten würde
Beim Überfliegen von collection.md fällt auf, dass Milvus mehr Vektortypen unterstützt, als den meisten Devs bewusst ist:
- Skalare:
BOOL,INT8/16/32/64,FLOAT,DOUBLE,VARCHAR,JSON,ARRAY - Vektoren:
FLOAT_VECTOR— 32-Bit-Float, der StandardFLOAT16_VECTOR— Halbpräzision, spart SpeicherBFLOAT16_VECTOR— BF16, verbreitet in Deep-Learning-PipelinesBINARY_VECTOR— binärSPARSE_FLOAT_VECTOR— dünn besetzt, für VolltextsucheINT8_VECTOR— quantisiert, weitere Komprimierung
Hybride Suche: Die bemerkenswerteste Funktion, die diese Skills abdecken
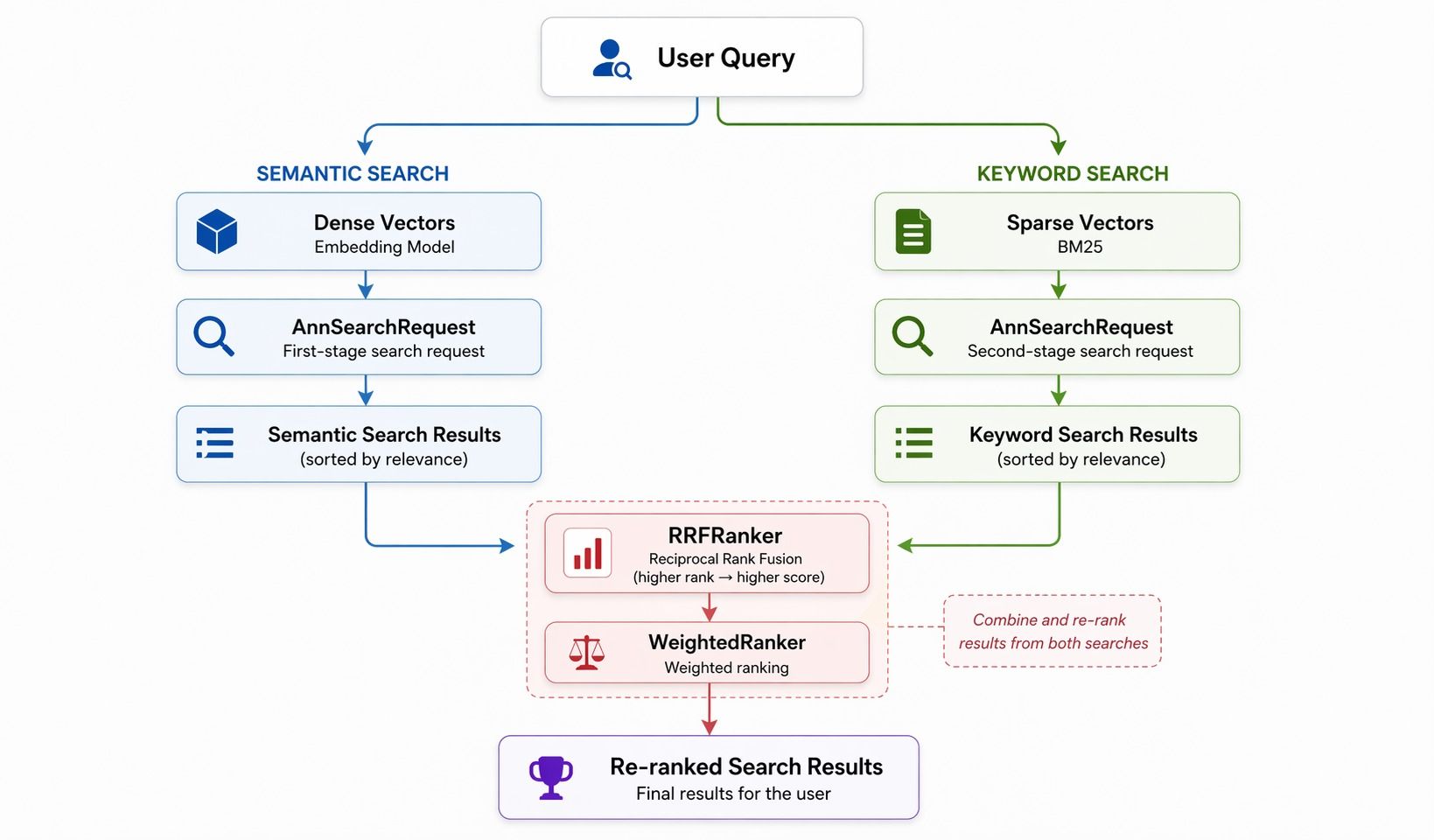
patterns.md dokumentiert vier gängige Muster. Hybride Suche hat die meisten Bestandteile. Suche mit dichten Vektoren (semantisch) und Suche mit dünn besetzten Vektoren (Keyword) laufen parallel, dann führt RRF (Reciprocal Rank Fusion) oder gewichtetes Ranking die beiden Listen zusammen.
Drei Bausteine:
AnnSearchRequest— einer pro SuchzweigRRFRanker/WeightedRanker— FusionsstrategieSPARSE_FLOAT_VECTOR— das Feld für dünn besetzte Vektoren
RRF ist einfach: Für jedes Ergebnis gilt: Score = 1/Rang, summiert über die Zweige hinweg. Höher platzierte Einträge gewinnen. WeightedRanker ist eine gewichtete Summe pro Zweig. Der Skill erklärt das, sodass der Agent brauchbaren Code für hybride Suche erzeugt, ohne dass der Entwickler das RRF-Paper lesen muss.
Milvus' integrierte BM25-Volltextsuche
Der Milvus Skill kodiert außerdem: Milvus 2.5s integrierte Sparse-BM25-Volltextsuche. Kombiniert mit Function und FunctionType.BM25 wandelt Milvus Rohtext intern in dünn besetzte Vektoren um und überspringt externe Embedding-Modelle sowie manuelle TF-IDF-Pipelines.
Vor 2.5 bedeutete Volltextsuche, dass man einen Tokenizer handhaben, TF-IDF von Hand berechnen und den Sparse Vector selbst erzeugen musste. Jetzt teilt man dem Agenten mit, was man will, und der Skill leitet ihn an, die Collection mit korrekt verdrahteter BM25-Function zu erzeugen.
Search Iterators: Pagination für Collections mit Millionen Zeilen
vector.md behandelt auch search_iterator und query_iterator, cursorartige Pagination für Collections mit Millionen oder Milliarden Zeilen. Ein einfaches search gibt eine Ergebnismenge fester Größe zurück. Iteratoren blättern ohne Auslassungen oder Duplikate durch, genau das, was vollständige Enumeration braucht.
Zilliz Cloud Skill: Dem Agenten beibringen, Ihr Cloud-DBA zu sein
Die Aufgabe des Zilliz Cloud Skill unterscheidet sich von der des Milvus Skill. Statt Python zu schreiben, setzt der Agent CLI-Aufrufe gegen eine Live-Control-Plane zusammen — und weil ein falscher Befehl die Produktion löschen kann, versieht der Skill diese Aufrufe mit Sicherheitsregeln.
Befehlsmodus: Wie der Agent CLI-Aufrufe zusammensetzt
Der Skill kodiert eine konsistente Befehlsform:
zilliz <resource> <action> --flag <value>
Beispiele:
zilliz cluster list— alle Cluster auflistenzilliz collection create --name my_collection— eine Collection erstellenzilliz backup create --name daily-backup— ein Backup erstellen
Drei Ausgabeformate: json (maschinenlesbar), table (menschenfreundlich), text (einfach). Der Agent wählt, was jeweils passt.
14 Sub-Skills, die den gesamten Cloud-Lebenszyklus abdecken
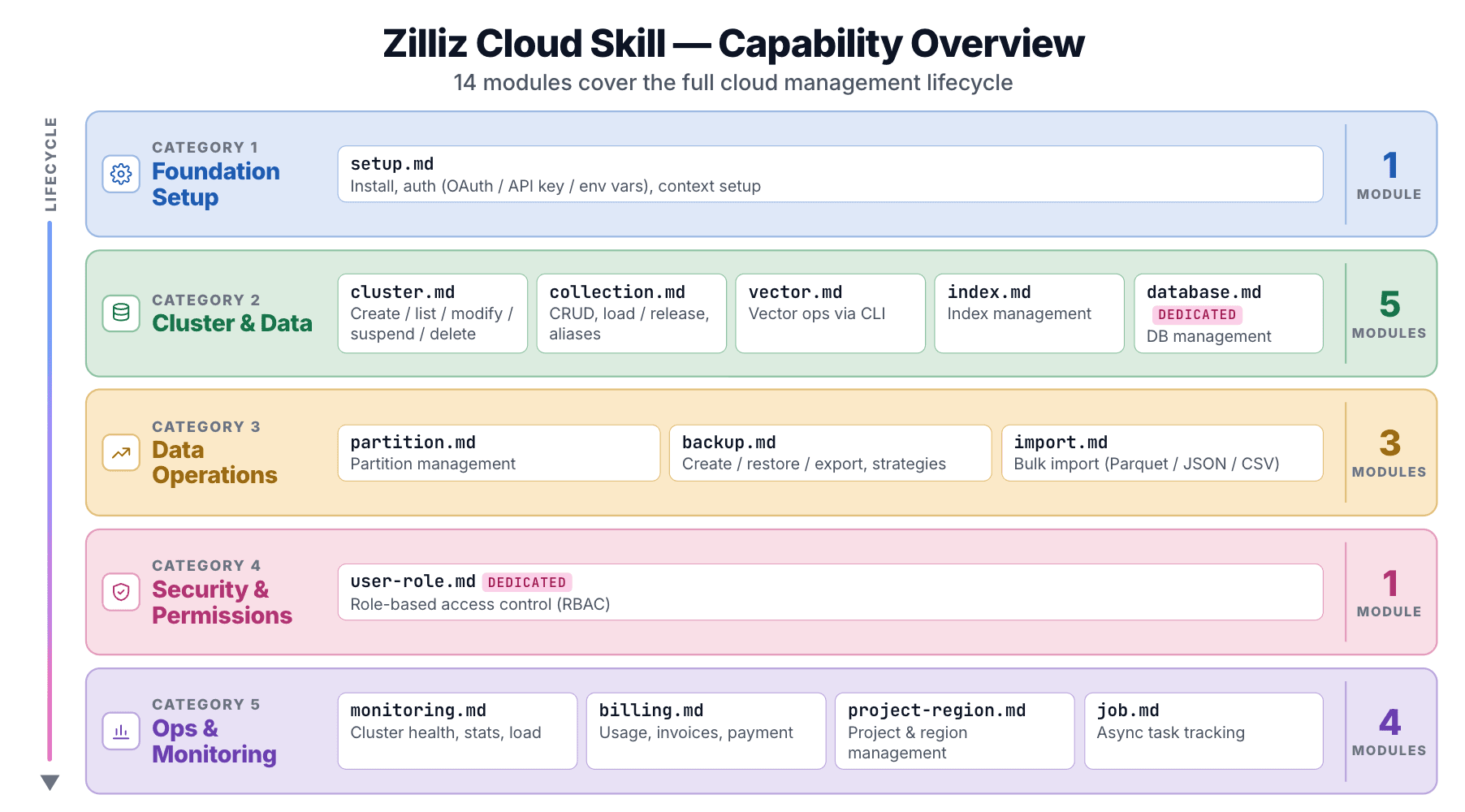
Das zilliz-plugin-Repo liefert 14 Sub-Skills, jeder unter skills/<name>/SKILL.md:
| Modul | Abdeckt |
|---|---|
setup | Installation, Authentifizierung (OAuth / API-Schlüssel / Umgebungsvariable), Kontext-Einrichtung |
cluster | Erstellen, auflisten, ändern, pausieren, fortsetzen, löschen |
collection | Collection-CRUD, Laden/Freigeben, Aliase |
vector | Vektor-Operationen über CLI |
index | Indexverwaltung |
database | Datenbankverwaltung (nur Dedicated) |
partition | Partitionsverwaltung |
user-role | RBAC (nur Dedicated) |
backup | Erstellen, wiederherstellen, exportieren, Backup-Richtlinien |
import | Massenimport aus Cloud-Speicher (Parquet / JSON / CSV) |
billing | Nutzung, Rechnungen, Zahlungsmethoden |
monitoring | Cluster-Status, Statistiken, Ladezustände |
project-region | Projekt- und Regionsverwaltung |
job | Nachverfolgung asynchroner Aufgaben |
Einen Cluster hochfahren, Backup-Aufbewahrung konfigurieren, eine Rechnung prüfen: 14 Module decken jeden Vorgang der Zilliz-Cloud-Konsole ab.
Tier-Bewusstsein ist integriert. database und user-role sind als nur Dedicated gekennzeichnet. Der Skill weiß, dass Free-, Serverless- und Dedicated-Tiers unterschiedliche Funktionen haben, sodass der Agent keine Operationen versucht, die ein Cluster-Tier nicht unterstützt.
Drei Sicherheitsregeln, eine in jedem Modul
Das Sicherheitsdesign von Zilliz Cloud Skill geht mehrere Ebenen tiefer als das von Milvus Skill. Drei Kernregeln tauchen in den einzelnen SKILL.md-Dateien auf:
- Destruktive Operationen erfordern eine ausdrückliche Bestätigung des Benutzers. Die Anleitung des Cluster-Moduls lautet: "Before deleting a cluster, always confirm with the user — this is irreversible." Jede destruktive Operation (Collections, Backups, Datenbanken, Benutzer) enthält dieselbe Anweisung.
- Sensible Befehle laufen im eigenen Terminal des Benutzers. Das
setup-Modul ist eindeutig: "Login commands (zilliz login, zilliz configure) require an interactive terminal and CANNOT run inside Claude Code. Always instruct the user to run these in their own terminal." Zugangsdaten fließen nicht durch den Agenten. - Zugangsdaten werden niemals offengelegt. Authentifizierung läuft über einen OAuth-Browser-Flow, einen API-Schlüssel aus der Konsole oder eine
ZILLIZ_API_KEY-Umgebungsvariable. Der Skill gibt niemals Secrets aus.
Das klingt grundlegend, aber ein Agent mit Cloud-Zugangsdaten und ohne Bestätigungsebene könnte "räum die Test-Cluster auf" nehmen und die Produktion löschen. Der Skill schließt diese Lücke auf der Anweisungsebene, bevor ein destruktiver Befehl die API erreicht.
Das Prereq-Gate: Drei Prüfungen, bevor ein Befehl ausgeführt wird
Jeder Sub-Skill führt eine dreistufige Prüfung aus, definiert in skills/setup/SKILL.md:
zilliz-cliinstalliert? Falls nicht, installieren.- Benutzer angemeldet? Falls nicht, zur Authentifizierung leiten.
- Cluster-Kontext gesetzt? Falls nicht, Auswahl abfragen.
Das Gate stellt sicher, dass die Umgebung bereit ist, bevor ein Befehl ausgelöst wird. Das ist zuverlässiger, als blind loszulegen und Fehler anschließend zu debuggen.
Warum sind es Zilliz Skills und nicht einfach MCP?
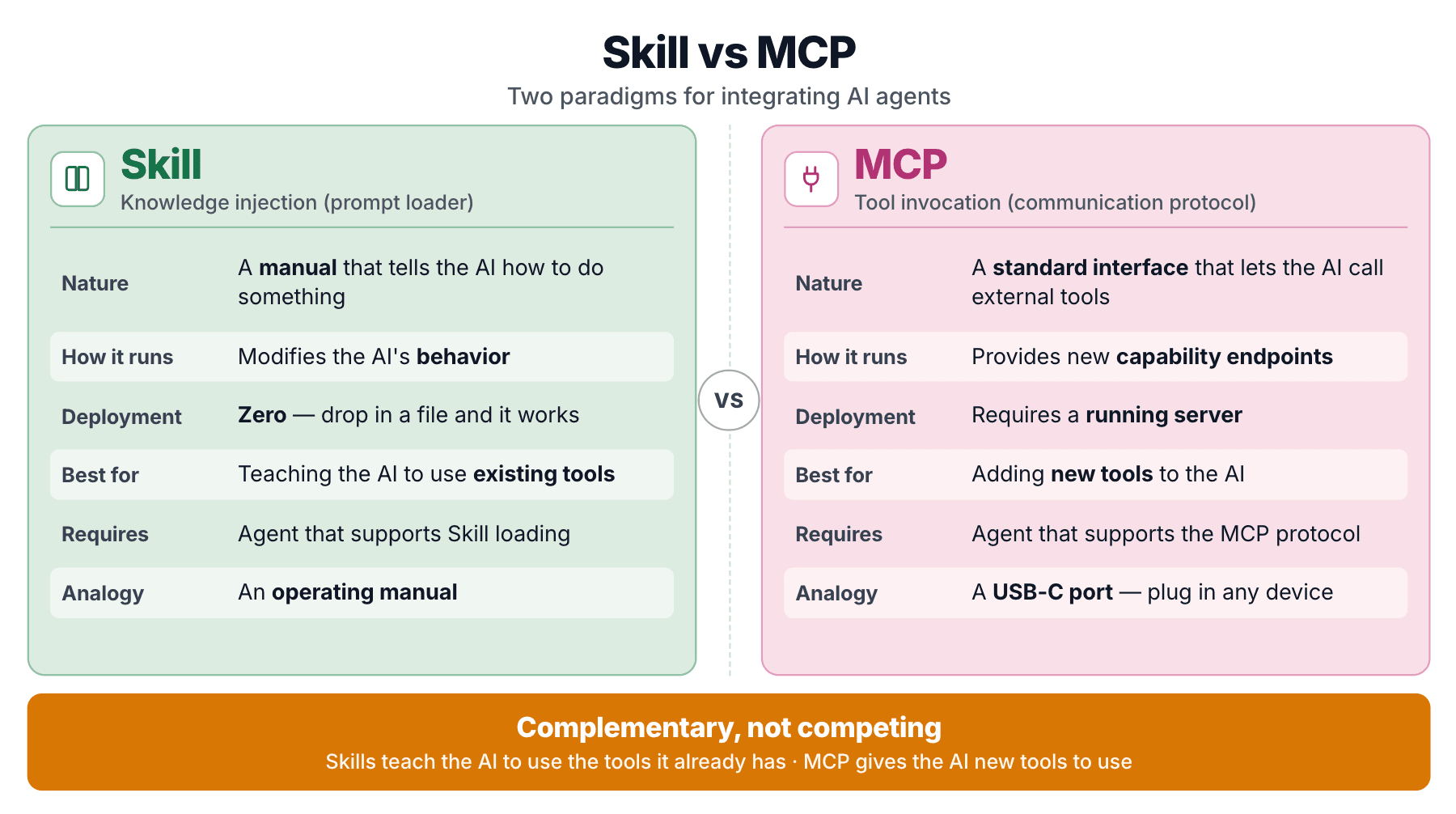
Zilliz liefert beides, weil sie unterschiedliche Probleme lösen. Ein Skill injiziert Wissen, das der Agent beim Schreiben von Code konsultiert. Ein MCP-Server stellt aufrufbare Endpunkte bereit, die der Agent ausführen kann. mcp-server-milvus ist der MCP-Arm; Milvus Skill ist der Wissensarm. Sie ergänzen sich, statt zu konkurrieren.
Skill ist ein Prompt-Loader
Der minimale Skill ist ein Ordner und eine SKILL.md:
my-skill/
├── SKILL.md # instructions + metadata
├── references/ # reference docs (optional)
├── scripts/ # executable scripts (optional)
└── assets/ # templates, resources (optional)
SKILL.md ist ein Anweisungshandbuch. Es sagt dem Agenten, wie er eine bestimmte Aufgabe behandeln soll. Kein ausführbarer Code, kein Serverprozess. Nur strukturiertes Wissen, das bei Bedarf in den Kontext des Modells injiziert wird.
Ein Skill ist ein Prompt-Loader. Domänenwissen, verpackt als strukturierter Prompt, dynamisch geladen.
MCP ist ein Tool-Protokoll
MCP (Model Context Protocol) nimmt eine andere Form an. Es ist ein standardisiertes Protokoll, mit dem ein Agent externe Tools über eine einheitliche Schnittstelle aufrufen kann. mcp-server-milvus ist ein MCP-Server, der Tool-Endpunkte wie milvus_text_search, milvus_create_collection und so weiter bereitstellt.
MCP wurde als „der USB-C-Anschluss für KI-Agenten“ beschrieben. Es löst das Problem der Standardisierung von Tool-Schnittstellen.
Zilliz Skill vs zilliz MCP
| Dimension | Skill | MCP |
|---|---|---|
| Wesen | Wissensinjektion (Prompt) | Tool-Aufruf (Protokoll) |
| Was es tut | Verändert, wie sich der Agent verhält | Gibt dem Agenten eine neue Fähigkeit |
| Bereitstellungsaufwand | Dateien ablegen, fertig | Serverprozess erforderlich |
| Passt zu | Dem Agenten beibringen, Tools zu verwenden, die er bereits hat | Dem Agenten Tools geben, die er nicht hat |
| Abhängigkeit | Agent unterstützt das Laden von Skills | Agent unterstützt MCP |
Der tragende Unterschied: Milvus Skill bringt dem Agenten bei, pymilvus zu verwenden. pymilvus existiert bereits. Der Skill fügt keine Fähigkeit hinzu. Er verbessert die Korrektheit für eine Fähigkeit, die der Agent bereits hat. MCP hingegen gibt dem Agenten aufrufbare Endpunkte, die er sonst nicht erreichen könnte.
Ein Skill ist eine Bedienungsanleitung für eine Maschine, die du bereits besitzt. MCP ist eine Fernbedienung, die eine neue Maschine in Bewegung setzt. Zilliz hat dies direkt in "Is MCP Dead? MCP vs CLI vs Agent Skills Compared" gesagt: Beide Muster bestehen fort.
Allerdings setzen sich Skills schnell durch. Community-Tracker beziffern die Anzahl auf über 700.000 Pakete über Registries hinweg, wobei ClawHub allein über 5.700 Skills listet. Ein Skill-Paket-Projekt auf GitHub erhielt im April 2026 innerhalb von fünf Tagen 6.600 Sterne.
Praxisszenarien: Wie Entwickler sie tatsächlich verwenden
Szenario 1: Erstellen einer RAG-Anwendung
Du baust eine RAG-App. Mit installiertem Milvus Skill sagst du:
"Erstelle eine Dokumenten-Retrieval-Collection: 768-dimensionale Vektoren, BM25-Volltextsuche, Felder für Titel, Textkörper und Embedding."
Der Agent zieht collection.md und patterns.md heran und schreibt:
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(uri="<URI>", token="<TOKEN>")
schema = client.create_schema(auto_id=True)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("title", DataType.VARCHAR, max_length=512)
schema.add_field("body", DataType.VARCHAR, max_length=4096, enable_analyzer=True)
schema.add_field("embedding", DataType.FLOAT_VECTOR, dim=768)
schema.add_field("body_sparse", DataType.SPARSE_FLOAT_VECTOR)
# Wire BM25 full-text search
schema.add_function(Function(
name="body_bm25",
input_field_names=["body"],
output_field_names=["body_sparse"],
function_type=FunctionType.BM25,
))
index_params = client.prepare_index_params()
index_params.add_index(field_name="embedding", index_type="AUTOINDEX", metric_type="COSINE")
index_params.add_index(field_name="body_sparse", index_type="AUTOINDEX", metric_type="BM25")
client.create_collection("documents", schema=schema, index_params=index_params)
enable_analyzer=True, die BM25-Function-Verdrahtung, die AUTOINDEX-mit-BM25-Metrik-Kombination: Nichts davon sind Dinge, bei denen man möchte, dass der Agent rät. Der Skill kodiert sie.
Szenario 2: Verwalten eines Zilliz Cloud-Clusters
"Erstelle einen Serverless-Cluster in us-east-1 und erstelle dann eine Collection mit 768-dimensionalen Vektoren."
Der Agent führt die Voraussetzungsprüfung aus und gibt dann die CLI-Befehle der Reihe nach aus. Oder:
"Zeig mir den Status und die Ressourcennutzung all meiner Cluster."
Der Agent führt zilliz cluster list und die passenden zilliz monitoring-Befehle aus und fasst dann zusammen. Anmeldedaten verlassen niemals dein Terminal.
Szenario 3: Backups und Datenmigration
"Richte eine tägliche Backup-Richtlinie für die Produktion ein, 7 Tage aufbewahren."
backup.md dokumentiert die vollständige Richtliniensyntax. Der Agent konfiguriert die Richtlinie direkt.
"Exportiere die orders-Collection vom Test-Cluster nach S3."
import.md behandelt Massenimport und -export aus Cloud-Speicher, einschließlich der unterstützten Formate (Parquet, JSON, CSV).
Szenario 4: Upgrade auf hybride Suche
"Upgrade my search to dense + sparse hybrid with RRF."
Der Agent zieht die Notizen aus vector.md zu AnnSearchRequest und RRFRanker heran und schreibt den Hybrid-Suchcode. Sie müssen RRF-Parameter nicht studieren.
Zilliz's Agent Stack: Wo die zwei Skills hineinpassen
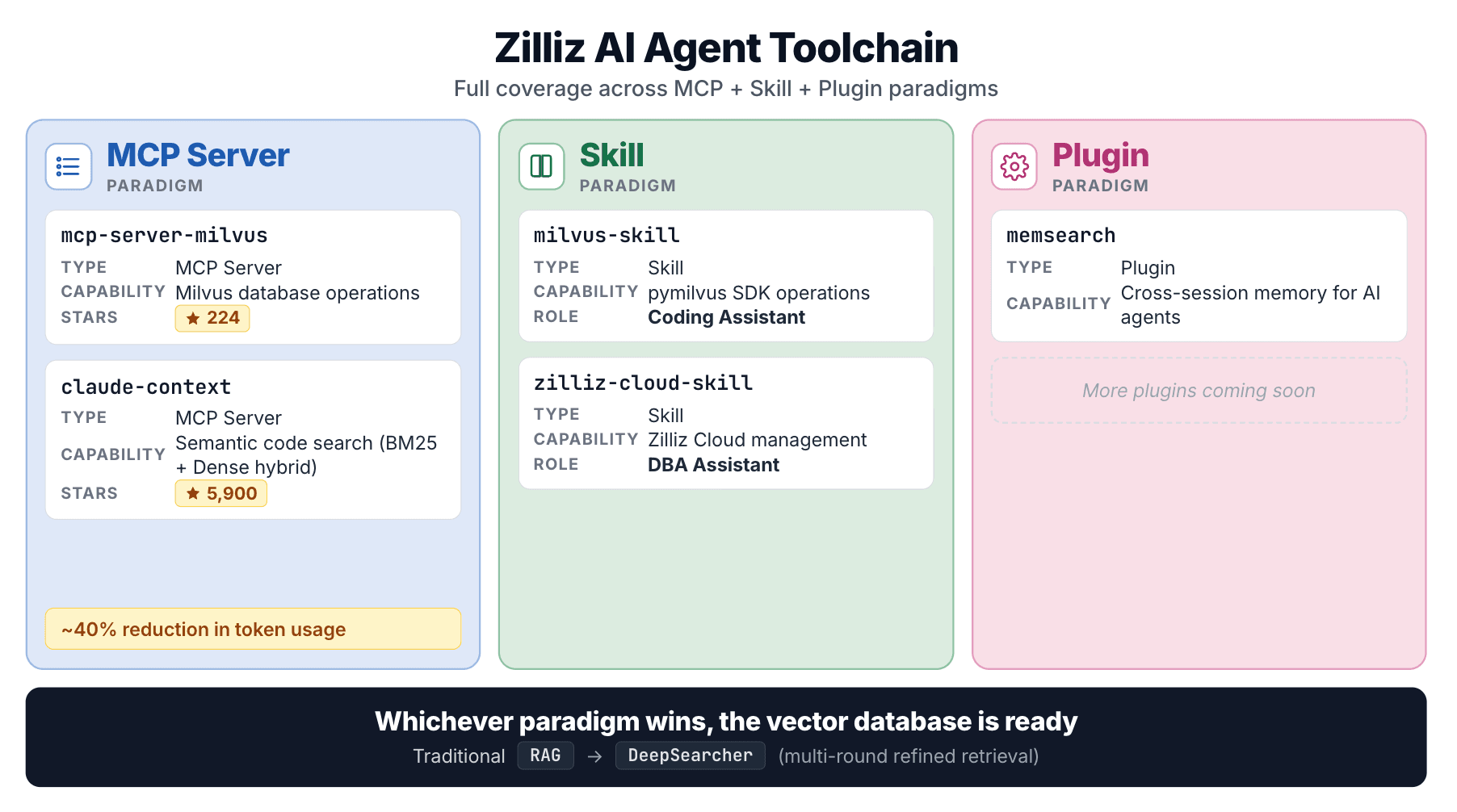
Diese zwei Skills sind Teil einer umfassenderen Zilliz-Initiative über jedes Agent-Integrationsmuster hinweg:
| Projekt | Typ | Deckt ab |
|---|---|---|
| mcp-server-milvus | MCP Server | Milvus-Datenbank-Ops |
| claude-context | MCP Server | Semantische Codesuche |
| milvus-skill | Skill | pymilvus SDK |
| zilliz-skill | Skill | Zilliz Cloud-Verwaltung |
| DeepSearcher | Agent framework | Mehrstufiges agentisches RAG |
claude-context sticht hervor. Es indexiert eine Codebasis in einer Vektordatenbank, ruft relevanten Code bei Bedarf mit hybrider (BM25 + dense) Suche ab und meldet ~40% Token-Reduktion bei gleichwertiger Retrieval-Qualität.
Von MCP über Skill bis hin zu Codesuche und Agent-Frameworks ist Zilliz's Strategie konsistent: Welches Agent-Integrationsmuster auch gewinnt, eine Vektordatenbank sollte einen erstklassigen Einstiegspunkt haben. Die zwei Skills sind Zilliz's Einstieg in diese Richtung.
Fazit
Milvus Skill und Zilliz Cloud Skill stützen sich gemeinsam auf vier Designentscheidungen:
- Die zwei Skills haben klare, nicht überlappende Rollen. Milvus Skill übernimmt die SDK-Coding-Ebene; Zilliz Cloud Skill übernimmt die CLI-Ops-Ebene. Zusammen decken sie den gesamten Lebenszyklus einer Vektordatenbank ab, ohne sich gegenseitig in die Quere zu kommen.
- Modulares Laden von Wissen hält den Kontext schlank. Die Aufteilung des Wissens auf 7 und 14 Referenzdateien ermöglicht es dem Agenten, nur die Datei zu laden, die zur aktuellen Aufgabe passt, statt das Kontextfenster mit jeder Dokumentation zu überfluten.
- Zilliz Cloud Skill baut Sicherheit in die Instruktionsebene ein. Bestätigung destruktiver Operationen, Schutz von Zugangsdaten und Prüfung von Voraussetzungen zeigen, dass das Team sorgfältig darüber nachgedacht hat, was ein Agent mit Cloud-Schlüsseln mit einer Live-Datenbank tun kann.
- Zilliz sichert sich über Paradigmen hinweg ab, statt einen Gewinner zu wählen. Durch die Bereitstellung sowohl von MCP- als auch Skill-Implementierungen ist Zilliz abgedeckt, unabhängig davon, in welche Richtung sich das Agent-Integrationsökosystem bewegt.
Wenn Sie Agents gegen eine Vektordatenbank bauen, installieren Sie beide Skills, wenn Sie das nächste Mal eine RAG-App starten oder einen Cluster verwalten.
Loslegen
Installieren Sie die zwei Skills in Ihrer nächsten Claude Code-Sitzung:
- Milvus Skill — pymilvus-Korrektheit. Funktioniert mit Milvus Lite, selbst gehostetem Standalone/Cluster und Zilliz Cloud.
- Zilliz Cloud Skill — Live-Cluster-Verwaltung über
zilliz-cli. Installieren Sie die CLI zusätzlich.
Wenn Sie noch keinen Cluster haben, registrieren Sie sich für Zilliz Cloud (neue Konten mit Arbeits-E-Mail erhalten kostenlose Credits) oder melden Sie sich an, fügen Sie dann den Skill in Claude Code ein, und der Agent übernimmt ab dort.
Weiterführende Lektüre
- "Ist MCP tot?" — Zilliz' Einordnung, wo CLIs und Skills neben MCP stehen.
- Milvus SDK Code Helper — MCP-Pendant zu Milvus Skill, dasselbe Problem mit veraltetem pymilvus aus einem anderen Blickwinkel.
claude-context— semantische Codebase-Suche mit einer gemeldeten Token-Reduktion von ~40 %.- Milvus-Dokumentation und Zilliz Cloud für die gesamte Produktoberfläche.
Weiterlesen

Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Notion solved vector search scaling in two years. The next bottleneck — offline context engineering, unified data, and the real-time/offline gap — is harder.

Milvus WebUI: A Visual Management Tool for Your Vector Database
Explore Milvus WebUI to monitor, manage, and optimize your vector database with real-time insights, performance tracking, and system health monitoring.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.