




Was ist eine Vector Lakebase?
TL;DR
- Eine Vector Lakebase ist eine einheitliche, lake-native Datenarchitektur für KI, die Serving auf dem Niveau einer Vektordatenbank mit offenem Lake-Speicher, wiederverwendbaren Lake-Level-Indizes und einer gemeinsamen semantischen Schicht kombiniert.
- Sie ermöglicht es, dass dieselben unstrukturierten Daten Online-Serving (RAG, Agents, semantische Suche) und Offline-Discovery (Clustering, Deduplizierung, Re-Embedding, Governance) antreiben — ohne Daten zwischen Systemen zu kopieren.
- Zilliz Vector Lakebase ist eine Implementierung dieser Architektur: eine Weiterentwicklung von Zilliz Cloud von einer verwalteten Vektordatenbank zu einer einheitlichen KI-Datenplattform.
Was ist eine Vector Lakebase?
Eine Vector Lakebase ist eine einheitliche, lake-native Datenarchitektur für KI. Sie kombiniert Serving auf dem Niveau einer Vektordatenbank, offenen Lake-Speicher, wiederverwendbare Lake-Level-Indizes und eine gemeinsame semantische Schicht, sodass dieselben unstrukturierten Daten Online-KI-Anwendungen, interaktive Discovery und Offline-Analysen unterstützen können — ohne sie zwischen Systemen zu kopieren. Sie beantwortet eine andere Frage als Retrieval allein: Was passiert, wenn produktive KI-Teams dieselben Daten für Retrieval, Discovery, Analysen, Governance, Feedback und kontinuierliche Verbesserung benötigen?
Sie lässt sich am besten als Erweiterung der Vektordatenbank verstehen, nicht als Ersatz dafür. Die Vektorsuche bleibt der Serving-Pfad mit niedriger Latenz; eine Vector Lakebase platziert diesen Pfad in einer breiteren Grundlage, die auch die Daten um ihn herum speichern, indizieren, verwalten und kontinuierlich verbessern kann.
Warum moderne KI-Workloads eine Vector Lakebase benötigen
Vektordatenbanken haben das erste Datenproblem moderner KI gelöst: schnelle semantische Abfrage im großen Maßstab, die RAG, Agents und semantische Suche antreibt. Dieses Problem ist weiterhin wichtig — mehr denn je, da sich KI-Systeme verbreiten.
Doch produktive KI-Teams benötigen zunehmend mehr als Retrieval aus denselben Daten — Deduplizierung und Clustering für Trainingsdatensätze, Anomalie- und Drift-Erkennung, Re-Embedding bei Modelländerungen, Governance und Lineage sowie Feedback aus dem Produktionsverhalten.
Die meisten Stacks behandeln diese Workflows als separate Systeme: einen Data Lake für Rohdateien, eine Vektordatenbank für Online-Retrieval, Batch-Pipelines für die Vorverarbeitung und separate Jobs für Embeddings und Indizes. Daten werden zwischen ihnen kopiert, Indizes werden neu aufgebaut, und Online-Serving und Offline-Discovery geraten auseinander.
Eine Vector Lakebase beseitigt diese Fragmentierung, indem sie eine einzige logische Datengrundlage für Serving und Discovery bereitstellt. Sie behält den Retrieval-Pfad mit niedriger Latenz bei, für den Vektordatenbanken entwickelt wurden, verbindet ihn jedoch mit einer lake-nativen Grundlage, in der Daten, Vektoren, Indizes, Metadaten und semantischer Kontext gespeichert, verwaltet, versioniert, wiederverwendet und im Laufe der Zeit verbessert werden können. Das Ziel ist nicht, die Vektordatenbank durch den Lake zu ersetzen; es geht darum, Vektorsuche, semantischen Kontext und Verarbeitung unstrukturierter Daten in eine einzige Architektur zu integrieren. (Zum Branchenkontext und zur technischen Umsetzung hinter diesem Wandel siehe Why We Built Vector Lakebase.)
Grundprinzipien des Vector-Lakebase-Designs: One Data, One Index, One Semantic Layer
Eine Vector-Lakebase-Architektur beruht auf drei Prinzipien: One Data, One Index und One Semantic Layer. Sie beschreiben, wo das System of Record liegt, wie Indizes verwaltet werden und wie Bedeutung organisiert ist.

One Data: Der Lake als gemeinsame Datengrundlage
One Data bedeutet, dass offener Lake-Speicher zur gemeinsamen Grundlage für unstrukturierte KI-Daten wird. Rohdateien, bereinigte Daten, Vektoren, skalare Felder, Metadaten, Indexartefakte, semantische Labels, Lineage und Ergebnisse der Offline-Verarbeitung befinden sich alle innerhalb einer einzigen logischen Datengrundlage.
In dieser Architektur ist die Vektordatenbank kein neues Datensilo. Sie wird Teil des Serving-Pfads mit niedriger Latenz. Die autoritativen Daten bleiben lake-nativ, während Online-Systeme bei Bedarf Hot Data und Indizes cachen. Dies reduziert doppelte Speicherung, Governance und systemübergreifende Migration und ermöglicht es, dieselben Daten für Online-Anwendungen, Offline-Verarbeitung, Modelltraining, Evaluation und Governance zu nutzen.
Beispielsweise kann ein Dokument, das in einem RAG-System verwendet wird, auch Teil eines Offline-Clustering-Jobs, eines Workflows zur Exploration von Trainingsdaten, einer Compliance-Prüfung und eines zukünftigen Re-Embedding-Prozesses sein. In einer fragmentierten Architektur erstellt jeder Workflow seine eigene Kopie oder abgeleitete Repräsentation. In einer Vector Lakebase arbeiten diese Workflows auf derselben logischen Datengrundlage.
One Index: Indizes werden zu Assets auf Lake-Ebene
One Index bedeutet, dass Indizes nicht in einer einzelnen Online-Serving-Engine eingeschlossen sind. Sie werden zu Datenassets, die über verschiedene Compute-Modi hinweg erstellt, versioniert, wiederverwendet und bereitgestellt werden können. Das ist wichtig, weil Indizes teuer und operativ wichtig sind — sie kodieren, wie ein System Daten abruft und organisiert. Wenn jeder Workflow seinen eigenen Index erstellen muss, verschwenden Teams Rechenleistung, erzeugen inkonsistentes Retrieval-Verhalten und erschweren Governance.
In einer Vector Lakebase kann ein logischer Index je nach Zugriffsmuster und Kosten verschiedenen Serving-Formen zugeordnet werden. Hot Indexes unterstützen Online-Retrieval im Millisekundenbereich; Warm Data wird über Cache oder Tiered Storage bereitgestellt; Cold Data verbleibt im Lake für Exploration, Governance und Offline-Analyse. Dieselbe Index-Lineage kann RAG-Serving, semantische Suche, Agent Memory, Datenexploration und Batch-Verarbeitung unterstützen — sodass Teams das richtige Latenz- und Kostenprofil wählen können, ohne das Datenmodell zu durchbrechen.
One Semantic Layer: Bedeutung wird zu einer gemeinsamen Systemschicht
One Semantic Layer bedeutet, dass das System mehr als Embeddings verwaltet. Ein Embedding ist nur eine Repräsentation des zugrunde liegenden Assets. Eine nützliche KI-Datengrundlage benötigt außerdem Entitäten, Labels, Zusammenfassungen, Themen, Kontextfragmente, Quelleninformationen, Modellversionen, Zugriffsrichtlinien, Lineage und Feedbacksignale. Diese semantische Schicht ermöglicht es Teams, unstrukturierte Daten nach Bedeutung zu organisieren statt allein nach Dateipfad, Tabelle, Bucket oder Collection.
Ein RAG-System kann vertrauenswürdigen Kontext aus der semantischen Schicht abrufen. Ein KI-Agent kann frühere Aufgaben, Erinnerungen und Tool-Call-Ergebnisse verstehen. Ein Trainingsdaten-Workflow kann Abdeckungslücken, Duplikate, Ausreißer und Bias entdecken. Ein Governance-System kann eine Antwort, ein Feature oder ein Sample bis zu den Quelldaten und der Modellversion zurückverfolgen, die es erzeugt haben.
Die semantische Schicht ist außerdem das Zentrum des Data Flywheel: Online-Anwendungen generieren Abfragen, Klicks, Zitate, Korrekturen und Feedback; Offline Discovery verwandelt diese Signale in bessere Metadaten, sauberere Datensätze, verbesserte Indizes und stärkeren Kontext; und diese Verbesserungen fließen zurück ins Serving. In dieser Schleife wird eine Vector Lakebase zu mehr als nur Speicherung plus Retrieval.
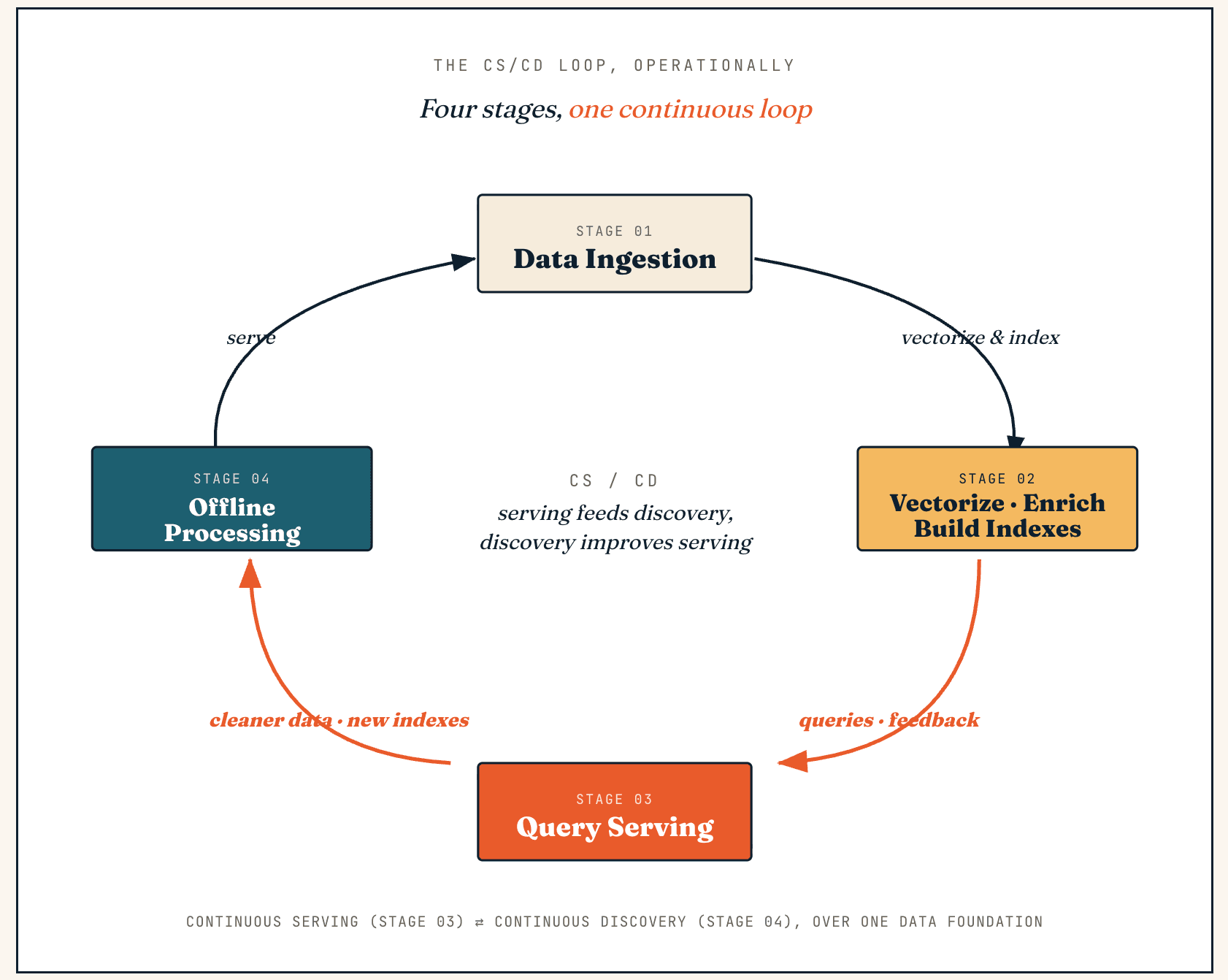
Wie Vector Lakebase funktioniert: das CS/CD-Flywheel in vier Phasen
Eine Vector Lakebase läuft als kontinuierliche Schleife zwischen Serving und Discovery — wir nennen dies CS/CD (Continuous Serving and Continuous Discovery). Serving generiert Feedback und neue Daten, Discovery verwandelt sie in sauberere Daten und bessere Indizes, und diese Verbesserungen fließen zurück ins Serving.
Operativ durchläuft dieselbe Schleife vier Phasen: Datenaufnahme, Vektorisierung und Anreicherung, Query Serving und Offline-Verarbeitung.
Datenaufnahme
Daten können über eine Vektordatenbank-API, eine Dokumentenpipeline, Object Storage oder ein bestehendes offenes Lake-Format in das System gelangen. Die Daten können Dokumente, Vektoren, skalare Felder, Geschäftsmetadaten, Bilder, Audio, Video, Code, Logs, Konversationen, Support-Tickets oder Agent Traces enthalten.
Mit dem Wachstum unstrukturierter Daten muss die Ingestion auch Bereinigung, Normalisierung, Zugriffskontrolle, Quellenverfolgung und Lineage unterstützen. Das System muss nicht nur wissen, was die Daten sind, sondern auch, woher sie stammen, welches Modell sie verarbeitet hat, wer darauf zugreifen kann und wie sie verwendet werden dürfen. Dies ist besonders wichtig für Enterprise AI. Ein RAG-System oder Agent kann nicht jedes abgerufene Datenelement als gleichermaßen vertrauenswürdig behandeln. Kontext benötigt Quellenbewusstsein, Berechtigungsbewusstsein, Aktualität und manchmal geschäftsspezifische Governance-Regeln.
Vektorisierung, Anreicherung und Indexaufbau
Nach der Ingestion erzeugt das System mithilfe von Embedding-Modellen und Datenverarbeitungsjobs Vektorrepräsentationen. Außerdem reichert es die Daten mit Metadaten an — Entitäten, Labels, Zusammenfassungen, Themen, Quelleninformationen, Berechtigungen, Zeitstempel und Modellversionen. Anschließend erstellt es Abfragestrukturen über den Lake-Daten: Vektorindizes, Keyword-Indizes, Volltextindizes, JSON-Indizes, skalare Indizes und andere Strukturen, die für hybrides Retrieval benötigt werden.
Architektonisch ist dies der entscheidende Punkt: Indizes sind nicht an eine einzelne Serving Engine gebunden. Sie können versioniert, veröffentlicht, wiederverwendet und auf den Daten-Snapshot zurückgeführt werden, aus dem sie erstellt wurden — wodurch das Index-Lifecycle-Management Teil der Datengrundlage wird und kein Implementierungsdetail, das in einer einzelnen Anwendung verborgen ist.
Query Serving
Eine Vector Lakebase bietet Retrieval-Pfade für RAG, agentische Suche, semantische Suche, multimodales Retrieval, AI Memory, Empfehlungen und andere Workloads von AI-Anwendungen. Der Abfragepfad kann eine Vektordatenbank oder Cache-Schicht für Hot Data verwenden, die niedrige Latenz erfordern, und auf lake-native Daten und Indizes für kältere oder weniger häufige Workloads zugreifen.
Eine Abfrage kann Vektorsuche, Keyword-Suche, Volltextsuche, Metadatenfilterung, skalare Prädikate, Berechtigungen und hybrides Ranking kombinieren — denn Retrieval für Produktions-AI basiert selten allein auf Vektorähnlichkeit. Ein gutes Ergebnis hängt oft von semantischer Relevanz, Aktualität, Zugriffsrechten, Quellenqualität, Geschäftsmetadaten und Benutzerintention ab.
Offline-Verarbeitung
Offline-Verarbeitung umfasst Clustering, Deduplizierung, Anomalieerkennung, Datenqualitätsanalyse, Exploration von Trainingsdaten, Schemaentwicklung, Re-Embedding, Evaluation und Index-Neuaufbau. Diese Workflows laufen auf großen Datenbatches und erfordern nicht immer Millisekunden-Latenz, benötigen aber Zugriff auf dieselben Vektoren, Metadaten, Indizes und denselben semantischen Kontext, die von Online-Anwendungen genutzt werden.
Ihre Ausgabe wird zurück in den Lake, das Indexsystem und die semantische Schicht geschrieben — bereinigtere Datensätze, bessere Labels, verbesserte Kontextfragmente, neue Indexversionen oder aktualisierte Feedbacksignale — und als atomarer Snapshot veröffentlicht, damit die Produktion niemals halb fertige Indizes liest. Dies ist die zentrale operative Schleife: Serving erzeugt Feedback, Discovery verbessert die Daten, und die verbesserten Daten kehren zum Serving zurück.
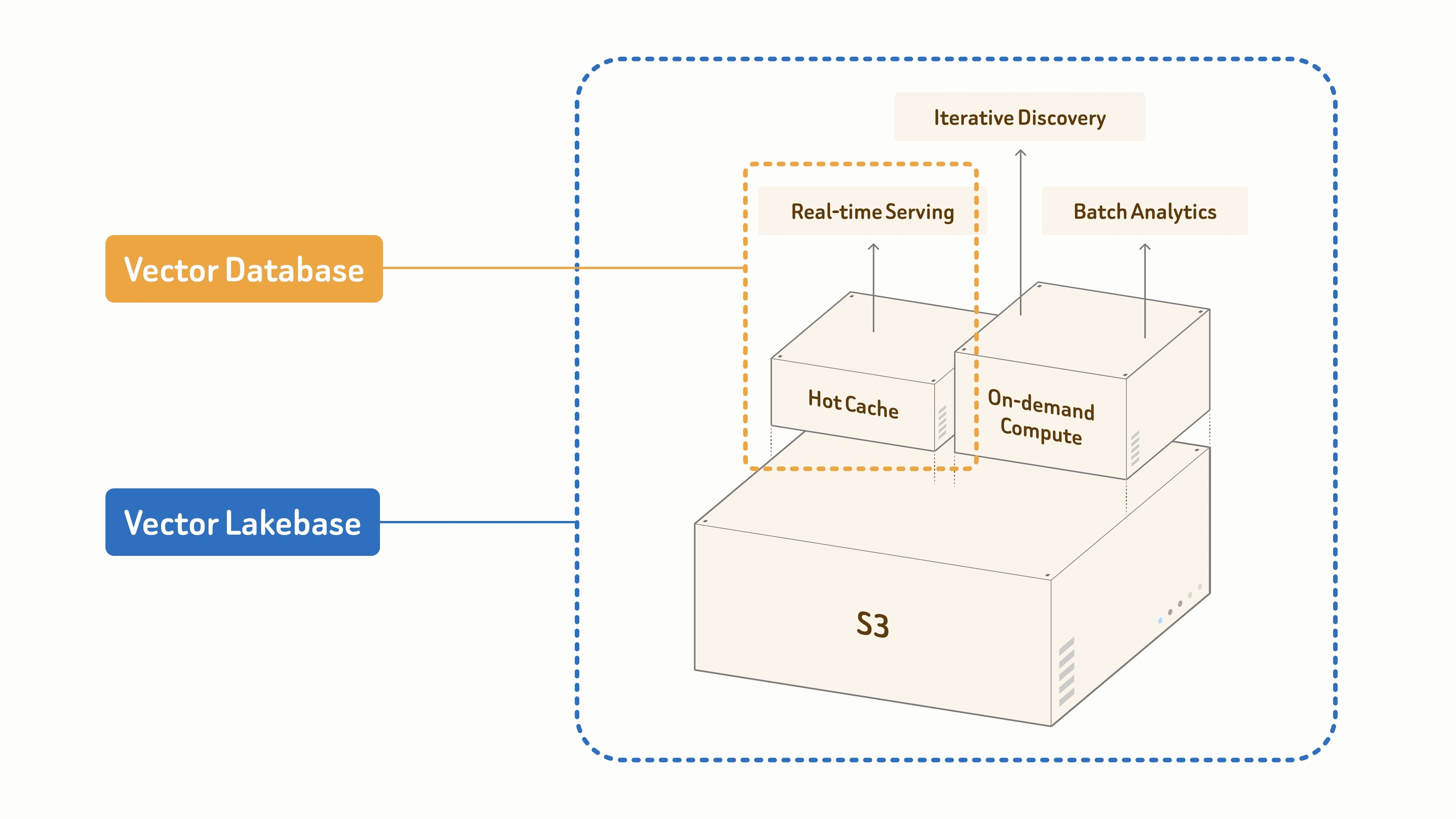
Drei Workload-Formen für Vector Lakebases
AI-Daten-Workloads haben nicht nur eine Form. Einige benötigen den ganzen Tag über Serving im Millisekundenbereich. Einige benötigen eine interaktive Suche für eine kurze Analysesitzung. Einige benötigen große Offline-Verarbeitungsjobs, die ausgeführt werden, Ergebnisse veröffentlichen und wieder verschwinden. Ein einzelnes Always-on-Online-Speichermodell kann all dies nicht effizient abdecken.
Eine traditionelle Vektordatenbank ist primär für die erste Workload-Form optimiert. Eine Vector Lakebase ist für alle drei über einen logischen Datensatz hinweg konzipiert.
In Zilliz Vector Lakebase ordnen sich diese Workloads drei Compute-Modi zu — long-running (resident, Serving im Millisekundenbereich), on-demand (interaktiv, minutengenau abgerechnet, die Brücke zwischen Serving und Discovery) und offline batch (große Jobs, die ihre Compute-Ressourcen freigeben, wenn sie abgeschlossen sind).
| Workload-Typ | Typische Beispiele | Compute-Muster |
|---|---|---|
| Echtzeit-Bereitstellung | Produktions-RAG, Agenten-Gedächtnis, semantische Suche, Empfehlung, Personalisierung, KI-Suche | Lang laufende Serving-Cluster mit heißen Indizes, warmen Caches und vorhersehbarer Latenz |
| Interaktive Exploration | Feedback-Analyse, Inspektion von Agenten-Traces, Anomaliesuche, Abruf kalter Daten, semantische Exploration | On-Demand-Compute, der bei Bedarf startet und Ressourcen freigibt, wenn die Sitzung endet |
| Batch-Analytik | Korpus-Deduplizierung, Clustering, vollständiges Re-Embedding, Vorbereitung von Trainingsdaten, Index-Neuaufbau | Batch-Compute für große Jobs, die laufen, Ergebnisse veröffentlichen und verschwinden |
Häufige Anwendungsfälle von Vector Lakebases
Da eine Vector Lakebase Serving und Exploration auf einer einzigen Grundlage vereint, fallen ihre Anwendungsfälle in zwei Gruppen.
 图片12
图片12
Retrieval-Anwendungsfälle (gemeinsam mit einer Vektordatenbank, nun auf einer verwalteten Grundlage):
- RAG — Dokumente, Wissensdatenbanken, Code und Logs als durchsuchbarer Kontext, aktuell gehalten, berechtigt und bei Modelländerungen neu indizierbar.
- KI-Agenten-Gedächtnis und Tool-Nutzung — Agenten-Gedächtnis speichern und abrufen, dann offline analysieren und Erkenntnisse zurückführen.
- Agentische und multimodale Suche — Vektor-, Keyword-, Volltext- und Metadatensuche über Text, Bilder, Audio, Video und Entitäten hinweg.
- Empfehlungssysteme und mehr.
Anwendungsfälle im Datenlebenszyklus (über das hinaus, was eine Vektordatenbank allein abdeckt):
- Feature- und Kontext-Engineering — Entitäten, Zusammenfassungen, Themen, Labels und Cluster ableiten, gespeichert neben den Daten, aus denen sie stammen.
- Exploration von Trainingsdaten — Stichproben clustern, Near-Duplicates finden, Ausreißer inspizieren und Beispiele bis zur Quelle zurückverfolgen.
- Vorverarbeitung unstrukturierter Daten — Deduplizierung, Anomalieerkennung, Anreicherung und Qualitätsfilterung, zurück in den Lake geschrieben.
Wie eine Vector Lakebase mit Vektordatenbanken und Lakebases zusammenhängt
Eine Vector Lakebase steht mit zwei Architekturen in Beziehung: Vektordatenbanken und Lakebase. Sie ist kein Ersatz für eine von beiden. Die folgende Tabelle bietet einen schnellen Überblick; die anschließenden Abschnitte erklären die jeweilige Beziehung.
| Vektordatenbank | Vector Lakebase | Lakebase | |
|---|---|---|---|
| Primäre Daten | Vektor-Embeddings + zugehörige unstrukturierte Daten | Unstrukturierte & multimodale Daten sowie der gesamte Lebenszyklus darum herum | Strukturierte / transaktionale Anwendungsdaten |
| Kernaufgabe | Semantischer Abruf mit niedriger Latenz | Online-Serving und Offline-Exploration über eine gemeinsame Grundlage vereinen | Datenbankfähigkeiten (OLTP) in offenen Lake-Speicher bringen |
| Indizes | Im Serving-Engine erstellt und gehalten | Lake-Level-Assets: erstellt, versioniert, über Compute-Modi hinweg wiederverwendet | Tabellen- / SQL-Indizes |
| Compute | Always-on-Serving | Lang laufend + On-Demand + Offline-Batch | Transaktional |
| Storage of Record | Oft an die Engine gekoppelt | Offener Lake-Speicher | Offener Lake-Speicher |
| Best Fit | Schnelle Vektorsuche für Online-Anwendung | Unstrukturierte Daten im großen Maßstab bereitstellen und kontinuierlich verbessern | Transaktionale App-Daten im Lake |
| Beziehung zu Vector Lakebase | Wird zur Serving-Engine innerhalb einer Vector Lakebase | - | Das strukturierte-Daten-Gegenstück derselben lake-nativen Idee |
Vector Lakebase vs. Vektordatenbanken
Eine Vector Lakebase ersetzt Vektordatenbanken nicht. Wenn eine Organisation nur Vektorsuche mit niedriger Latenz für eine einzelne Anwendung benötigt, kann eine Vektordatenbank ausreichend sein — sie bleibt das richtige System für Produktions-Retrieval, wenn Latenz, Skalierung, Filterung und betriebliche Zuverlässigkeit wichtig sind. Milvus ist beispielsweise für diese Art von Produktions-Vektorsuche entwickelt.
Die Rechnung ändert sich, wenn eine Organisation dieselben unstrukturierten Daten, Embeddings, Indizes und semantischen Kontexte über viele Teams, Modelle, Anwendungen und Verarbeitungsworkflows hinweg wiederverwenden muss.
In dieser Welt sollte die Vektordatenbank nicht der einzige Ort sein, an dem Daten und Indizes liegen; sie wird zur Serving-Engine innerhalb einer umfassenderen Architektur für unstrukturierte Daten. Ihre Rolle wird spezifischer und wichtiger — sie stellt den Serving-Pfad bereit, den KI-Anwendungen benötigen, während die Vector Lakebase die breitere Datengrundlage um diesen Pfad herum bereitstellt. Das Ergebnis ist nicht weniger Vektorsuche; es ist Vektorsuche, die mit dem vollständigen Lebenszyklus unstrukturierter Daten verbunden ist.
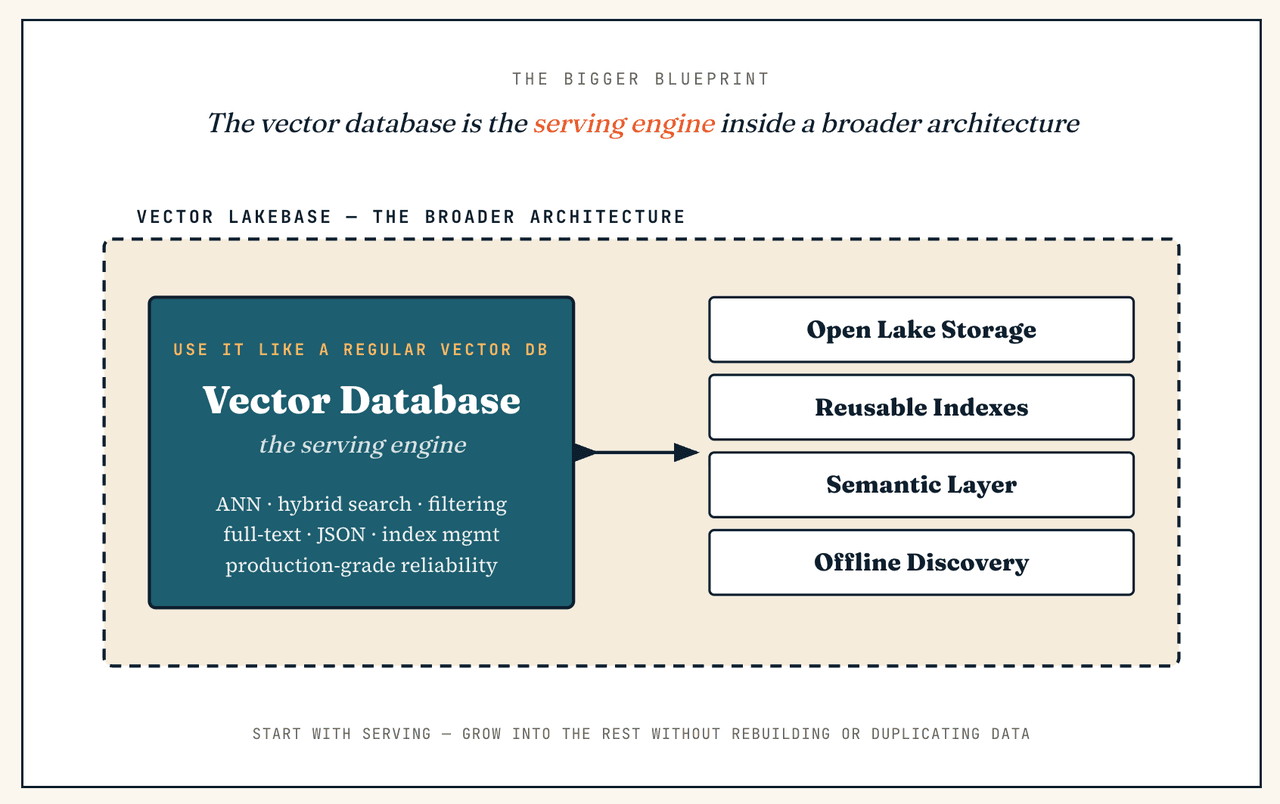
Wenn ich nur eine Vektordatenbank benötige, ist Vector Lakebase trotzdem eine gute Wahl?
Das ist ein vollkommen guter Ausgangspunkt — denn die Vektordatenbank ist bereits Teil einer Vector Lakebase. Sie können die Serving-Cluster-Schicht genau wie eine eigenständige Vektordatenbank verwenden (ANN-Suche mit niedriger Latenz, hybride Suche, Metadatenfilterung, Volltextsuche, JSON-Filterung, Indexverwaltung, Produktionszuverlässigkeit) und am ersten Tag interaktive Erkundung oder Batch-Analysen überhaupt nicht anfassen. Der Unterschied besteht darin, dass Sie nicht in eine reine Retrieval-Architektur eingeschlossen sind: Wenn sich die Workload später auf Suche in kalten Daten, groß angelegte Deduplizierung, Re-Embedding, Vorbereitung von Trainingsdaten oder semantische Governance ausweitet, ist die breitere Architektur bereits vorhanden — kein Neuaufbau, keine duplizierten Daten.
Vector Lakebase vs. Lakebase
Eine Vector Lakebase ist mit einer Lakebase verwandt, aber sie ist nicht einfach nur "Lakebase plus Vektoren."

Eine Lakebase-artige Architektur bringt datenbankähnliche Fähigkeiten in offenen Lake-Speicher für strukturierte Anwendungsdaten — strukturierte Datensätze, Transaktionen, Schemas, elastische Rechenleistung und einheitliche Governance, abgefragt über bekannte Felder und Beziehungen.
Eine Vector Lakebase adressiert einen anderen Schwerpunkt: unstrukturierte und multimodale Daten für KI. Das Problem besteht nicht darin, Anwendungszustand in einem Lake zu speichern; es besteht darin, semantische Repräsentationen, Vektorindizes, Metadaten, Kontext, Feedback und Offline-Erkundungsworkflows über unstrukturierte Daten hinweg zu verwalten — was semantische Interpretation, Retrieval, Verfeinerung und Feedback erfordert statt Lookups über bekannte Felder. Sie lässt sich am besten nicht als Ersatz für die Lakebase beschreiben, sondern als Erweiterung der Lakebase-Idee in das Zeitalter von Vektoren, Indizes und semantischem Kontext.
| Dimension | Lakebase | Vector Lakebase |
|---|---|---|
| Primäre Daten | Strukturierte Anwendungsdaten, transaktionale Datensätze, Anwendungszustand | Dokumente, Bilder, Audio, Video, Logs, Code, Gespräche, Vektoren, Metadaten und semantischer Kontext |
| Kernabstraktionen | Tabellen, Transaktionen, Schemas, Branches, Klone | Vektoren, Indizes, Chunks, Entitäten, Labels, Zusammenfassungen, Berechtigungen, Feedback und semantische Beziehungen |
| Haupt-Workloads | Lese- und Schreibvorgänge von Anwendungen, Transaktionen, Echtzeitanalysen | RAG, Agentengedächtnis, agentische Suche, multimodales Retrieval, Erkundung, Context Engineering, Workflows für Trainingsdaten |
| Abfragemodell | SQL, transaktionale Abfragen, analytische Abfragen | Vektorsuche, hybride Suche, Volltextsuche, JSON-Filterung, multimodales Retrieval, semantische Erkundung |
| Semantisches Modell | Geschäftliche Bedeutung hauptsächlich durch Schema ausgedrückt | Bedeutung ausgedrückt durch Embeddings, Metadaten, Entitäten, Zusammenfassungen, Modellversionen, Lineage und Feedback |
| KI-Wert | Bringt datenbankähnliche Fähigkeiten in offenen Lake-Speicher | Bringt KI-Kontext, Vektorindizierung, semantisches Retrieval und Offline-Erkundung in lake-native unstrukturierte Daten |
Was eine Vector Lakebase nicht ist
Da Vector Lakebase ein neues Architekturmuster ist, lohnt es sich, klarzustellen, was sie nicht ist.
- Es ist nicht einfach nur ein Data Lake mit Embeddings, die in einer Spalte gespeichert sind. Das Speichern von Embeddings in einer Lake-Tabelle bewahrt die Vektoren, bietet aber nichts von der Indexierung, Bereitstellung, semantischen Metadaten, hybriden Suche, Feedback-Schleife oder dem Abrufpfad mit niedriger Latenz, den produktive KI-Systeme benötigen. Vektoren sind nützlich, wenn sie durchsucht, verwaltet, versioniert, gefiltert, mit Quelldaten verbunden und im Laufe der Zeit verbessert werden können — nicht bloß gespeichert.
- Es ist nicht einfach nur eine Vektordatenbank, die mit Object Storage verbunden ist. Object Storage hinter eine Vektordatenbank zu setzen, kann die Speicherkosten senken, löst aber nicht die Wiederverwendung von Indizes, Offline-Discovery, Governance, Versionierung oder Konsistenz zwischen verarbeiteten und bereitgestellten Daten. Der schwierige Teil ist nicht, wo die Bytes liegen; sondern wie Daten, Indizes, Metadaten, semantische Signale und Compute-Modi als ein operatives System zusammenarbeiten.
- Es ist kein Offline-Analysesystem. Offline-Discovery ist nur eine Seite der Architektur. Eine Vector Lakebase bedient auch Produktions-Traffic, unterstützt Hot-Retrieval-Pfade, verwaltet Indizes, setzt Zugriffskontrollen durch und liefert relevanten Kontext an Anwendungen und Agenten zurück. Es geht nicht darum, zwischen Serving und Analytics zu wählen — sondern darum, sie zu verbinden.
- Es ist keine Abkehr von Vektordatenbanken. Dies ist vielleicht der wichtigste Punkt, den wir wiederholt erwähnt haben. Vector Lakebase macht Vektordatenbanken nicht weniger relevant. Es gibt ihnen eine breitere Architektur, in der sie arbeiten können.
Zilliz Vector Lakebase ist als Public Preview verfügbar
Wir haben die Public Preview von Zilliz Vector Lakebase gestartet — eine bedeutende Weiterentwicklung von Zilliz Cloud von einer reinen verwalteten Vektordatenbank zu einer einheitlichen semantischen Datenplattform, die Vektor-Serving mit niedriger Latenz mit der Offenheit, Skalierbarkeit und Wirtschaftlichkeit eines Data Lakes kombiniert.
Kernfunktionen von Zilliz Vector Lakebase:
- Gestuftes Serving, optimiert für unterschiedliche Echtzeit-Kompromisse zwischen Leistung und Kosten
- On-Demand-Suche für großskalige oder explorative Workloads ohne Always-on-Compute
- Suche in externen Data Lakes — direktes Indexieren und Suchen über Ihre bestehenden Lake-Daten
- KI-Suche über das gesamte Spektrum hinweg über Vektoren, Text, JSON und Geodaten mit hybrider Suche und Reranking
- Einheitlicher lake-nativer Speicher auf Basis von Vortex, einem offenen Format mit schnelleren und günstigeren Random Reads als Lance oder Parquet
Wenn Ihr aktueller Stack Serving und Discovery in separate Systeme aufteilt, könnte Vector Lakebase einen Blick wert sein. Probieren Sie es auf Zilliz Cloud aus — neue Registrierungen mit geschäftlicher E-Mail-Adresse erhalten $100 kostenlose Credits — oder sprechen Sie mit uns über Ihren Anwendungsfall.
Erfahren Sie mehr über Vector Lakebases
- Von der Vektordatenbank zur Vector Lakebase
- Wir haben 8 Jahre damit verbracht, Vektorsuche schneller zu machen. Dann veränderte KI das Compute-Modell
- Warum wir Vector Lakebase entwickelt haben: Unstrukturierte Datenarchitektur für KI neu denken
- Vector Lakebase: Das KI-Datensilo beenden
- Zilliz Cloud On-Demand Compute: Bezahlen Sie nur für das, was Sie nutzen
- Notions Vektorsuche ist ausgezeichnet. Ihr nächstes Problem ist schwieriger.
Weiterlesen

Expanding Our Global Reach: Zilliz Cloud Launches in Azure Central India
Zilliz Cloud expands to Azure Central India. This new region helps customers meet compliance, reduce latency, and optimize cloud costs when building AI applications.

How to Build RAG with Milvus, QwQ-32B and Ollama
Hands-on tutorial on how to create a streamlined, powerful RAG pipeline that balances efficiency, accuracy, and scalability using the QwQ-32B and Milvus.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.