




Wir stellen DeepSearcher vor: Eine lokale Open-Source-Tiefenforschung
 deep researcher.gif
deep researcher.gif
Im letzten Beitrag, "I Built a Deep Research with Open Source-and So Can You!", haben wir einige der Prinzipien erklärt, die Forschungsagenten zugrunde liegen, und einen einfachen Prototyp gebaut, der detaillierte Berichte zu einem bestimmten Thema oder einer bestimmten Frage erstellt. Der Artikel und das dazugehörige Notebook demonstrierten die grundlegenden Konzepte der Werkzeugverwendung, der Zerlegung von Anfragen, des Reasoning und der Reflexion. Das Beispiel in unserem vorigen Beitrag wurde im Gegensatz zu OpenAIs Deep Research lokal ausgeführt und verwendete nur Open-Source-Modelle und -Tools wie [Milvus] (https://milvus.io/docs) und LangChain. (Ich empfehle Ihnen, den obigen Artikel zu lesen, bevor Sie fortfahren).
In den darauffolgenden Wochen stieg das Interesse am Verständnis und der Reproduktion von OpenAIs Deep Research explosionsartig an. Siehe z. B. Perplexity Deep Research und Hugging Face's Open DeepResearch. Diese Tools unterscheiden sich in ihrer Architektur und Methodik, haben aber ein gemeinsames Ziel: Sie recherchieren iterativ ein Thema oder eine Frage durch Surfen im Internet oder in internen Dokumenten und geben einen detaillierten, fundierten und gut strukturierten Bericht aus. Wichtig ist, dass der zugrundeliegende Agent automatisch entscheidet, welche Maßnahmen bei jedem Zwischenschritt zu ergreifen sind.
In diesem Beitrag bauen wir auf unserem vorherigen Beitrag auf und stellen das Open-Source-Projekt [DeepSearcher] (https://github.com/zilliztech/deep-searcher) von Zilliz vor. Unser Agent demonstriert zusätzliche Konzepte: Query Routing, bedingter Ausführungsfluss und Web Crawling als Werkzeug. Er wird als Python-Bibliothek und Kommandozeilen-Tool und nicht als Jupyter-Notizbuch präsentiert und verfügt über einen größeren Funktionsumfang als unser vorheriger Beitrag. So kann es beispielsweise mehrere Quelldokumente eingeben und das Einbettungsmodell und die verwendete Vektordatenbank über eine Konfigurationsdatei festlegen. Obwohl DeepSearcher noch relativ einfach ist, ist es ein großartiges Beispiel für agentenbasiertes RAG und ein weiterer Schritt in Richtung einer modernen KI-Anwendung.
Außerdem untersuchen wir den Bedarf an schnelleren und effizienteren Inferenzdiensten. Reasoning-Modelle nutzen "Inferenz-Skalierung", d.h. zusätzliche Berechnungen, um ihre Ergebnisse zu verbessern, und dies in Verbindung mit der Tatsache, dass ein einziger Bericht Hunderte oder Tausende von LLM-Aufrufen erfordern kann, führt dazu, dass die Inferenz-Bandbreite der primäre Engpass ist. Wir verwenden das [DeepSeek-R1-Schlussfolgermodell auf der von SambaNova entwickelten Hardware] (https://sambanova.ai/press/fastest-deepseek-r1-671b-with-highest-efficiency), das in Bezug auf die Ausgabe von Token pro Sekunde doppelt so schnell ist wie das nächstbeste Konkurrenzprodukt (siehe Abbildung unten).
SambaNova Cloud bietet auch Inferenz-as-a-Service für andere Open-Source-Modelle wie Llama 3.x, Qwen2.5 und QwQ. Der Inferenzdienst läuft auf einem von SambaNova entwickelten Chip, der rekonfigurierbaren Datenflusseinheit (RDU), die speziell für die effiziente Inferenz von generativen KI-Modellen entwickelt wurde und die Kosten senkt und die Inferenzgeschwindigkeit erhöht. [Weitere Informationen finden Sie auf der Website des Unternehmens (https://sambanova.ai/technology/sn40l-rdu-ai-chip).
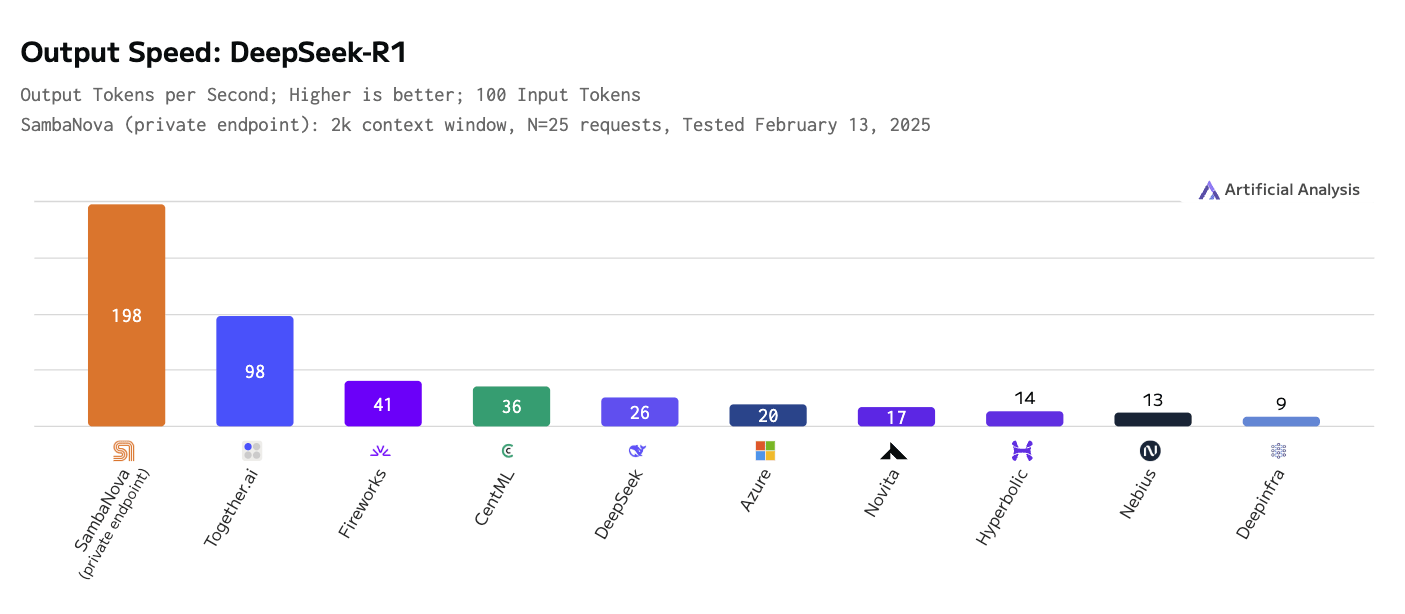 Ausgabegeschwindigkeit - deepseek r1.png
Ausgabegeschwindigkeit - deepseek r1.png
DeepSearcher Architektur
Die Architektur von DeepSearcher folgt unserem vorherigen Beitrag, indem sie das Problem in vier Schritte unterteilt - Frage definieren/verfeinern, recherchieren, analysieren, synthetisieren - obwohl es dieses Mal einige Überschneidungen gibt. Wir gehen jeden Schritt durch und heben dabei die Verbesserungen von DeepSearcher hervor.
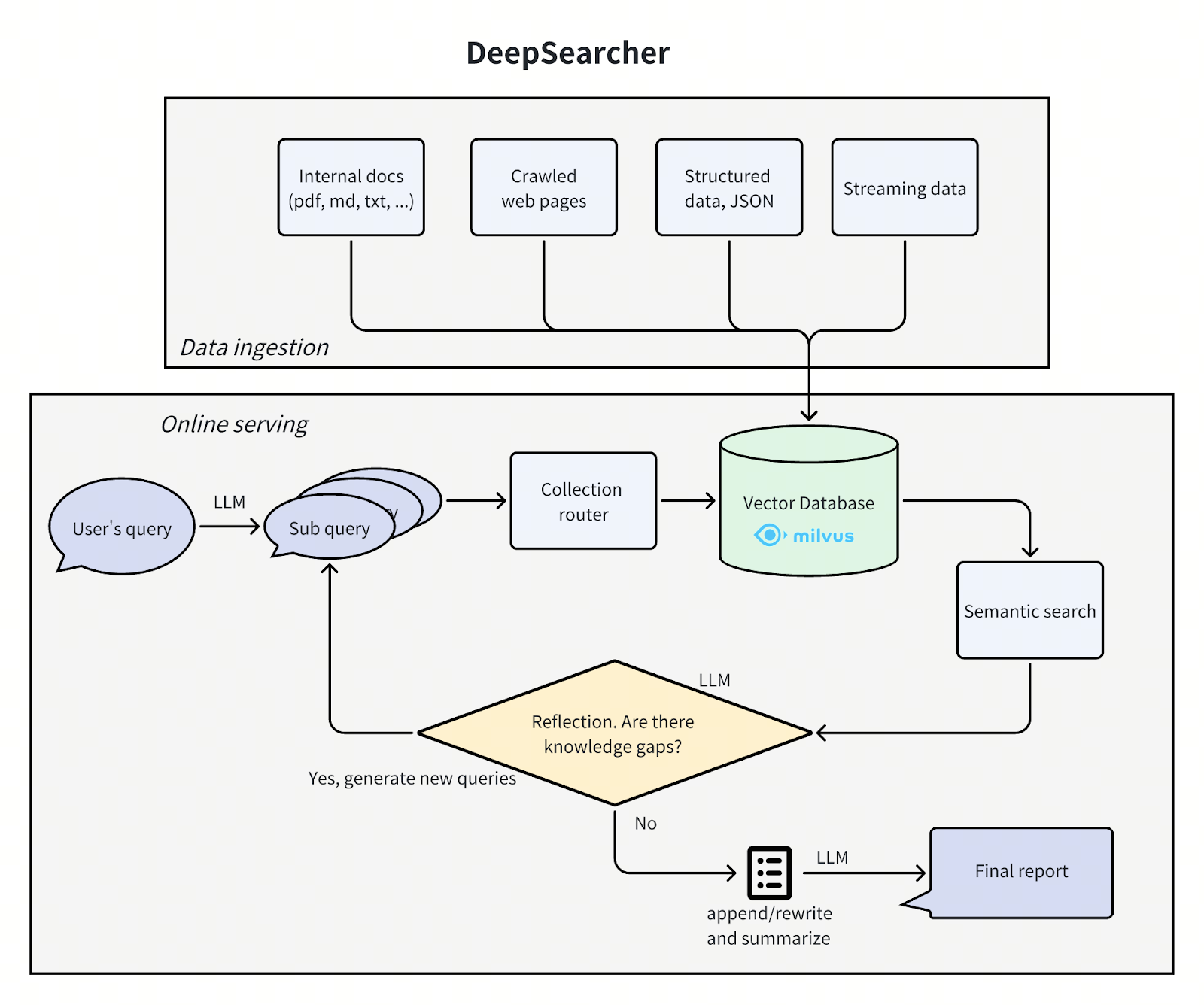 deepsearcher-architektur.png
deepsearcher-architektur.png
Definieren und Verfeinern der Frage
Zerlegen Sie die ursprüngliche Abfrage in neue Unterabfragen: [
'Wie hat sich der kulturelle Einfluss und die gesellschaftliche Relevanz der Simpsons von ihrem Debüt bis heute entwickelt?',
Welche Veränderungen in der Entwicklung der Charaktere, des Humors und des Erzählstils haben sich in den verschiedenen Staffeln der Simpsons ergeben?
Wie hat sich der Animationsstil und die Produktionstechnik der Simpsons im Laufe der Zeit verändert?
Wie haben sich Demografie, Rezeption und Einschaltquoten der Simpsons im Laufe ihrer Laufzeit verändert?"]
Im Design von DeepSearcher sind die Grenzen zwischen der Recherche und der Verfeinerung der Frage fließend. Die ursprüngliche Benutzerabfrage wird in Unterabfragen zerlegt, ähnlich wie im vorherigen Beitrag. Siehe oben für erste Unterabfragen, die aus der Abfrage "Wie haben sich die Simpsons im Laufe der Zeit verändert? In den folgenden Rechercheschritten wird die Frage jedoch je nach Bedarf weiter verfeinert.
Recherchieren und Analysieren
Nachdem die Anfrage in Teilfragen zerlegt wurde, beginnt der Rechercheteil des Agenten. Er besteht, grob gesagt, aus vier Schritten: Routing, Suche, Reflexion und bedingte Wiederholung.
Weiterleitung
Unsere Datenbank enthält mehrere Tabellen oder Sammlungen aus verschiedenen Quellen. Es wäre effizienter, wenn wir unsere semantische Suche auf die Quellen beschränken könnten, die für die jeweilige Anfrage relevant sind. Ein Abfrage-Router veranlasst einen LLM zu entscheiden, aus welchen Sammlungen Informationen abgerufen werden sollen.
Hier ist die Methode, um die Abfrage-Routing-Aufforderung zu bilden:
def get_vector_db_search_prompt(
Frage: str,
collection_names: List[str],
collection_descriptions: List[str],
context: List[str] = None,
):
sections = []
# common prompt
common_prompt = f"""Sie sind ein fortgeschrittener KI-Problemanalytiker. Nutzen Sie Ihr logisches Denkvermögen und historische Gesprächsinformationen auf der Grundlage aller vorhandenen Datensätze, um absolut genaue Antworten auf die folgenden Fragen zu erhalten, und generieren Sie eine passende Frage für jeden Datensatz entsprechend der Datensatzbeschreibung, die mit der Frage in Verbindung stehen könnte.
Frage: {Frage}
"""
sections.append(common_prompt)
# Datensatz-Prompt
data_set = []
for i, collection_name in enumerate(collection_names):
data_set.append(f"{sammlungsname}: {sammlungsbeschreibungen[i]}")
data_set_prompt = f"""Nachfolgend finden Sie alle Informationen zum Datensatz. Das Format der Datensatzinformationen ist Datensatzname: Datensatzbeschreibung.
Datensätze und Beschreibungen:
"""
sections.append(data_set_prompt + "\n".join(data_set))
# Kontextaufforderung
if context:
context_prompt = f"""Das Folgende ist eine komprimierte Version des historischen Gesprächs. Diese Informationen müssen in dieser Analyse kombiniert werden, um Fragen zu generieren, die näher an der Antwort sind. Sie dürfen nicht dieselben oder ähnliche Fragen für denselben Datensatz generieren, und Sie können auch keine Fragen für Datensätze neu generieren, bei denen festgestellt wurde, dass sie in keinem Zusammenhang stehen.
Historische Konversation:
"""
Abschnitte.append(kontext_prompt + "\n".join(kontext))
# response_prompt
response_prompt = f"""Ausgehend von den obigen Ausführungen können Sie nur einige wenige Datensätze aus der folgenden Datensatzliste auswählen, um für die ausgewählten Datensätze entsprechende Fragen zu generieren, mit denen die obigen Probleme gelöst werden können. Das Ausgabeformat ist json, wobei der Schlüssel der Name des Datensatzes und der Wert die entsprechende generierte Frage ist.
Datensätze:
"""
sections.append(antwort_prompt + "\n".join(collection_names))
footer = """Antworten Sie ausschließlich im gültigen JSON-Format, das dem genauen JSON-Schema entspricht.
Kritische Anforderungen:
- NUR EINEN Aktionstyp einbeziehen
- Niemals nicht unterstützte Schlüssel hinzufügen
- Alle Nicht-JSON-Texte, Markdowns oder Erklärungen müssen ausgeschlossen werden.
- Strikte JSON-Syntax beibehalten"""
Abschnitte.append(Fußzeile)
return "\n\n".join(abschnitte)
Wir sorgen dafür, dass der LLM eine strukturierte Ausgabe als JSON zurückgibt, um seine Ausgabe leicht in eine Entscheidung über das weitere Vorgehen umwandeln zu können.
Suche
Nachdem im vorherigen Schritt verschiedene Datenbanksammlungen ausgewählt wurden, führt der Suchschritt eine Ähnlichkeitssuche mit Milvus durch. Ähnlich wie im vorigen Beitrag wurden die Quelldaten im Voraus festgelegt, gechunked, eingebettet und in der Vektordatenbank gespeichert. Für DeepSearcher müssen die Datenquellen, sowohl lokal als auch online, manuell festgelegt werden. Die Online-Suche lassen wir für künftige Arbeiten stehen.
Reflexion
Im Gegensatz zum vorherigen Beitrag zeigt DeepSearcher eine echte Form der agentenbasierten Reflexion, indem die vorherigen Ergebnisse als Kontext in eine Eingabeaufforderung eingegeben werden, die darüber "reflektiert", ob die bisher gestellten Fragen und die relevanten abgerufenen Chunks Informationslücken enthalten. Dies kann als ein Analyseschritt angesehen werden.
Hier ist die Methode zur Erstellung des Prompts:
def get_reflect_prompt(
Frage: str,
mini_questions: List[str],
mini_chuncks: List[str],
):
mini_chunk_str = ""
for i, chunk in enumerate(mini_chuncks):
mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n"""
reflect_prompt = f"""Ermitteln Sie auf der Grundlage der ursprünglichen Abfrage, früherer Unterabfragen und aller abgerufenen Dokumentenchunks, ob zusätzliche Suchabfragen erforderlich sind. Wenn weitere Recherchen erforderlich sind, geben Sie eine Python-Liste mit bis zu 3 Suchanfragen an. Wenn keine weiteren Recherchen erforderlich sind, geben Sie eine leere Liste zurück.
Wenn die ursprüngliche Abfrage darin besteht, einen Bericht zu schreiben, und Sie es vorziehen, einige weitere Abfragen zu erstellen, geben Sie stattdessen eine leere Liste zurück.
Ursprüngliche Abfrage: {Frage}
Vorherige Unterabfragen: {mini_questions}
Verwandte Chunks:
{mini_chunk_str}
"""
footer = """Antworte ausschließlich im gültigen Format List of str ohne weiteren Text."""
return reflect_prompt + footer
Noch einmal sorgen wir dafür, dass der LLM eine strukturierte Ausgabe zurückgibt, dieses Mal als in Python interpretierbare Daten.
Hier ist ein Beispiel für neue Unterabfragen, die durch Reflexion "entdeckt" wurden, nachdem die anfänglichen Unterabfragen oben beantwortet wurden:
Neue Suchanfragen für die nächste Iteration: [
"Wie haben Veränderungen in der Besetzung der Simpsons und im Produktionsteam die Entwicklung der Serie im Laufe der verschiedenen Staffeln beeinflusst?",
"Welche Rolle hat die Satire und der soziale Kommentar der Simpsons bei der Anpassung an aktuelle Themen über Jahrzehnte hinweg gespielt?",
Wie haben die Simpsons Veränderungen im Medienkonsum, wie z. B. Streaming-Dienste, in ihren Vertriebs- und Inhaltsstrategien berücksichtigt und einbezogen?]
Bedingte Wiederholung
Im Gegensatz zu unserem vorherigen Beitrag veranschaulicht DeepSearcher den Ablauf der bedingten Ausführung. Nach der Prüfung, ob die bisherigen Fragen und Antworten vollständig sind, wiederholt der Agent die obigen Schritte, wenn weitere Fragen gestellt werden müssen. Wichtig ist, dass der Ausführungsfluss (eine while-Schleife) eine Funktion des LLM-Outputs ist und nicht hart kodiert wurde. In diesem Fall gibt es nur eine binäre Wahl: Recherche wiederholen oder einen Bericht erstellen. Bei komplexeren Agenten kann es mehrere geben, wie z.B.: Hyperlink folgen, Bausteine abrufen, im Speicher ablegen, reflektieren usw. Auf diese Weise wird die Frage immer weiter verfeinert, bis der Agent beschließt, die Schleife zu verlassen und den Bericht zu erstellen. In unserem Simpsons-Beispiel führt DeepSearcher zwei weitere Runden durch, um die Lücken mit zusätzlichen Unterabfragen zu füllen.
Synthetisieren
Schließlich werden die vollständig zerlegte Frage und die abgerufenen Chunks zu einem Bericht mit einer einzigen Eingabeaufforderung synthetisiert. Hier ist der Code zur Erstellung der Eingabeaufforderung:
def get_final_answer_prompt(
Frage: str,
mini_questions: List[str],
mini_chuncks: List[str],
):
mini_chunk_str = ""
for i, chunk in enumerate(mini_chuncks):
mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n"""
summary_prompt = f"""Sie sind ein Experte für KI-Inhaltsanalyse und können Inhalte gut zusammenfassen. Bitte fassen Sie eine spezifische und detaillierte Antwort oder einen Bericht auf der Grundlage der vorherigen Abfragen und der abgerufenen Dokumentenstücke zusammen.
Ursprüngliche Abfrage: {Frage}
Vorherige Unterabfragen: {mini_questions}
Verwandte Chunks:
{mini_chunk_str}
"""
return summary_prompt
Dieser Ansatz hat gegenüber unserem Prototyp, der jede Frage separat analysierte und die Ergebnisse einfach zusammenfügte, den Vorteil, dass er einen Bericht erzeugt, in dem alle Abschnitte miteinander konsistent sind, d.h. keine wiederholten oder widersprüchlichen Informationen enthalten. Ein komplexeres System könnte Aspekte von beidem kombinieren, indem es einen bedingten Ausführungsablauf verwendet, um den Bericht zu strukturieren, zusammenzufassen, umzuschreiben, zu reflektieren und auszurichten, usw., was wir für zukünftige Arbeiten vorsehen.
Ergebnisse
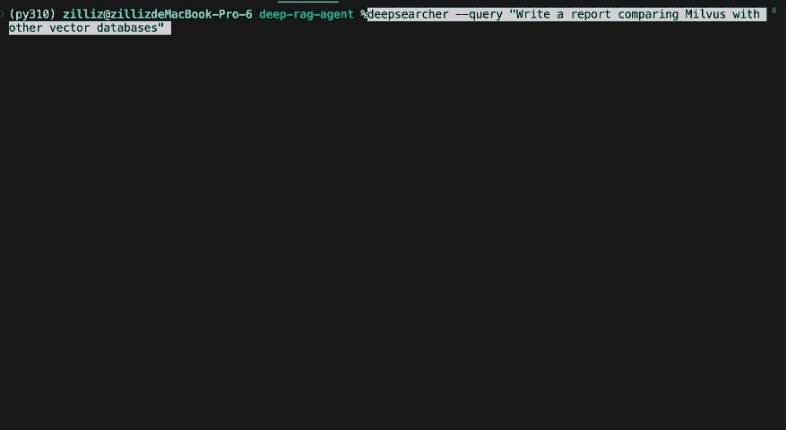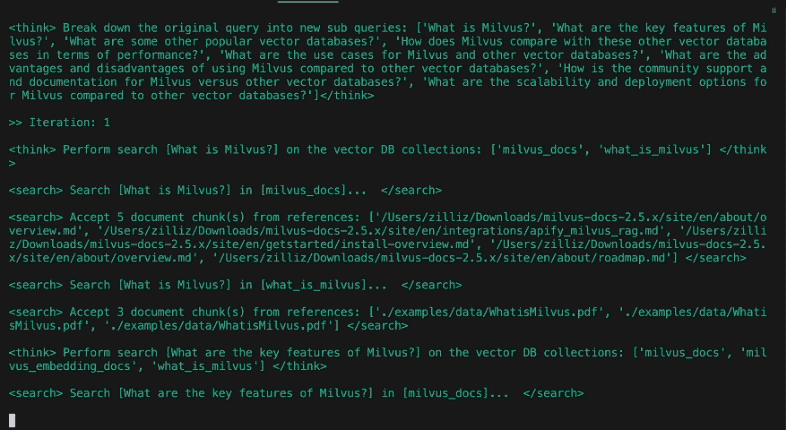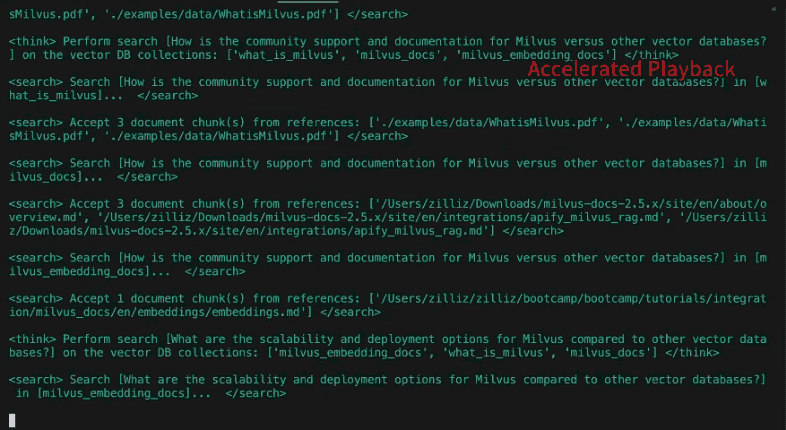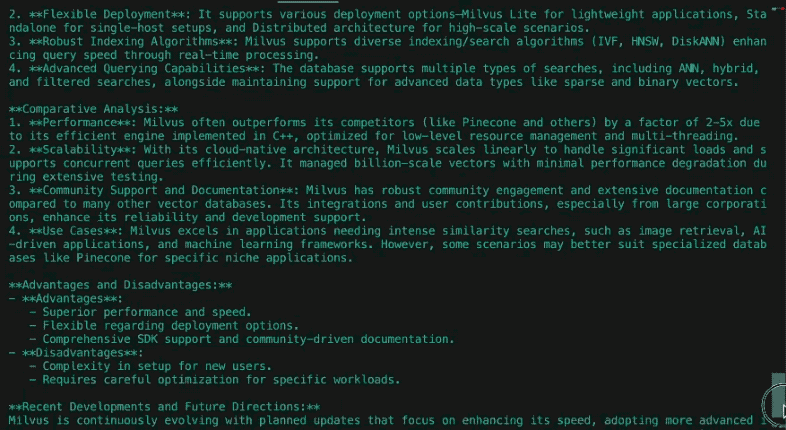
Hier ist ein Beispiel aus dem Bericht, der durch die Abfrage "Wie haben sich die Simpsons im Laufe der Zeit verändert?" mit DeepSeek-R1 generiert wurde, wobei die Wikipedia-Seite über die Simpsons als Quellenmaterial verwendet wurde:
Bericht: Die Entwicklung der Simpsons (1989-Gegenwart)
1. Kultureller Einfluss und gesellschaftliche Relevanz
Die Simpsons debütierten als subversive Kritik am amerikanischen Mittelstandsleben und erlangten in den 1990er Jahren durch ihre freche Satire Berühmtheit. Anfangs war die Serie ein gegenkulturelles Phänomen, das mit Episoden, die Religion, Politik und Konsumverhalten thematisierten, Normen in Frage stellte. Im Laufe der Zeit nahm die kulturelle Dominanz der Serie ab, da Konkurrenten wie South Park und Family Guy die Grenzen immer weiter verschoben. In den 2010er Jahren wandelte sich die Serie von einem Trendsetter zu einer nostalgischen Institution und schaffte den Spagat zwischen der Anziehungskraft des Erbes und dem Versuch, moderne Themen wie Klimawandel und LGBTQ+-Rechte anzusprechen, wenn auch mit weniger gesellschaftlicher Resonanz.
...
Fazit
Die Simpsons haben sich von einer radikalen Satire zu einer Institution des Fernsehens entwickelt und dabei Veränderungen in den Bereichen Technologie, Politik und Zuschauererwartungen bewältigt. Während ihre Brillanz aus dem goldenen Zeitalter unübertroffen bleibt, sichert ihre Anpassungsfähigkeit - durch Streaming, aktualisierten Humor und globale Reichweite - ihren Platz als kultureller Prüfstein. Die Langlebigkeit der Show spiegelt sowohl Nostalgie als auch eine pragmatische Umarmung des Wandels wider, auch wenn sie sich mit den Herausforderungen der Relevanz in einer fragmentierten Medienlandschaft auseinandersetzt.
Hier finden Sie [den vollständigen Bericht] (https://drive.google.com/file/d/1GE3rvxFFTKqro67ctTkknryUf-ojhduN/view?usp=sharing), und [einen von DeepSearcher mit GPT-4o mini erstellten Bericht] (https://drive.google.com/file/d/1EGd16sJDNFnssk9yTd5o9jzbizrY_NS_/view?usp=sharing) zum Vergleich.
Diskussion
Wir haben DeepSearcher vorgestellt, einen Agenten zur Durchführung von Recherchen und zum Schreiben von Berichten. Unser System baut auf der Idee in unserem vorherigen Artikel auf und fügt Funktionen wie bedingten Ausführungsfluss, Abfrage-Routing und eine verbesserte Schnittstelle hinzu. Wir sind von lokaler Inferenz mit einem kleinen quantisierten 4-Bit-Schlussfolgermodell zu einem Online-Inferenzdienst für das massive DeepSeek-R1-Modell übergegangen und haben damit unseren Ausgabebericht qualitativ verbessert. DeepSearcher arbeitet mit den meisten Inferenzdiensten wie OpenAI, Gemini, DeepSeek und Grok 3 (in Kürze!).
Reasoning-Modelle, vor allem in Forschungsagenten, sind inferenzlastig, und wir hatten das Glück, das schnellste Angebot von DeepSeek-R1 von SambaNova auf ihrer eigenen Hardware nutzen zu können. Für unsere Demonstrationsabfrage haben wir fünfundsechzig Aufrufe des DeepSeek-R1-Inferenzdienstes von SambaNova durchgeführt, bei denen etwa 25k Token eingegeben und 22k Token ausgegeben wurden und die $0,30 kosteten. Wir waren beeindruckt von der Geschwindigkeit der Inferenz, wenn man bedenkt, dass das Modell 671 Milliarden Parameter enthält und ein 3/4 Terabyte groß ist. Mehr Details finden Sie hier!
Wir werden diese Arbeit in zukünftigen Beiträgen weiter ausbauen und weitere Agenten-Konzepte und den Designraum von Forschungsagenten untersuchen. In der Zwischenzeit laden wir alle ein, DeepSearcher auszuprobieren, uns auf GitHub zu unterstützen, und uns Ihr Feedback mitzuteilen!
Ressourcen
Hintergrundlektüre: "Ich habe einen DeepSearcher mit Open Source gebaut - und das können Sie auch!"
"SambaNova startet den schnellsten DeepSeek-R1 671B mit der höchsten Effizienz"
DeepSearcher: DeepSeek-R1-Bericht über Die Simpsons
DeepSearcher: GPT-4o-Mini-Bericht zu "Die Simpsons"
Milvus Open-Source-Vektor-Datenbank](https://milvus.io/docs)

Weiterlesen

How Zilliz Ended Up at the Center of NVIDIA’s Unstructured Data Story at GTC 2026
If unstructured data is the context of AI, then the ceiling of AI applications will be set not just by models, but by how mature the infrastructure for unstructured data becomes.

Introducing Customer-Managed Encryption Keys (CMEK) on Zilliz Cloud
We're announcing the general availability of Customer-Managed Encryption Keys (CMEK) on Zilliz Cloud.

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.