




Was ist eine echte Vektordatenbank?
Dieser Artikel wurde ursprünglich in The New Stack veröffentlicht und wird hier mit Genehmigung erneut veröffentlicht.
Das Aufkommen von ChatGPT signalisiert den Beginn einer neuen Ära der künstlichen Intelligenz (KI). KI revolutioniert alles, wobei Vektordatenbanken in der neuen Ära zu einer wesentlichen Infrastruktur werden. Dieser Trend ist angesichts der steigenden Nachfrage nach KI-gestützten Anwendungen nicht überraschend.
Im vorherigen Beitrag haben wir unstrukturierte Daten und deren Verarbeitung, Analyse und Abfrage vorgestellt. Dieser Beitrag wird sich eingehend mit Vektordatenbanken, ihren Unterschieden zu traditionellen Vektorabrufmethoden und der Auswahl der optimalen Vektordatenbank für Ihr Projekt befassen.
Was ist eine Vektordatenbank?
Um die Frage zu beantworten: Was ist eine Vektordatenbank, müssen Sie die Rolle einer traditionellen relationalen Datenbank kennen, die Daten mit vordefinierten Formaten in Tabellen speichert und verarbeitet und üblicherweise exakte Suchen durchführt.
Im Gegensatz dazu speichern und rufen Vektordatenbanken unstrukturierte Daten wie Bilder, Audio, Videos und Text über hochdimensionale Werte ab, die als Embeddings bezeichnet werden. Vektordatenbanken werden häufig für Ähnlichkeitssuchen unter Verwendung des Approximate Nearest Neighbor (ANN)-Algorithmus eingesetzt. Dieser Algorithmus organisiert Daten auf der Grundlage räumlicher Beziehungen und ermöglicht es, den nächsten Nachbarn eines gegebenen Abfragepunkts in einem großen Datensatz von Punkten zu finden.
Mit dem Aufstieg von ChatGPT sind Vektordatenbanken noch wichtiger geworden, um Probleme zu lösen, mit denen große Sprachmodelle (LLMs) konfrontiert sind.
Vektordatenbanken vs. Vektorsuchbibliotheken
Spezialisierte Vektordatenbanken sind nicht der einzige Stack für Ähnlichkeitssuchen. Vor dem Aufkommen von Vektordatenbanken gab es viele Vektorsuchbibliotheken wie FAISS, ScaNN und HNSW für den Vektorabruf. Beide Stacks können Vektoren abfragen, aber worin bestehen die Unterschiede?
Vektorsuchbibliotheken haben eine begrenzte Funktionalität. Sie können nur eine kleine Datenmenge verarbeiten und haben Schwierigkeiten, mit größeren Datensätzen und höherer Benutzernachfrage zu skalieren. Sie erlauben keine Änderungen an ihren Indexdaten und können während des Datenimports nicht abgefragt werden.
Im Gegensatz dazu sind Vektordatenbanken wie Milvus und Zilliz Cloud eine optimalere Lösung für die Speicherung und den Abruf unstrukturierter Daten. Sie können Millionen oder sogar Milliarden von Vektoren speichern und abfragen und gleichzeitig Echtzeitantworten liefern; sie sind hochgradig skalierbar, um den wachsenden geschäftlichen Anforderungen der Nutzer gerecht zu werden.
Spezialisierte Vektordatenbanken bieten viele benutzerfreundliche Funktionen, darunter CRUD-Unterstützung (create, read, update, and delete), Disaster Recovery, rollenbasierte Zugriffskontrolle und Mandantenfähigkeit. Viele Anbieter von Vektordatenbanken, wie Zilliz, bieten außerdem vollständig verwaltete Cloud-Dienste an, um Nutzern dabei zu helfen, den Aufwand für Wartungsarbeiten zu vermeiden und sich auf ihr Geschäft zu konzentrieren.
Darüber hinaus arbeiten Vektordatenbanken auf einer anderen Abstraktionsebene als Vektorsuchbibliotheken und dienen als vollwertige Dienste statt als Komponenten zur Integration. Um die Bedeutung dieser Abstraktion zu veranschaulichen, betrachten wir den Prozess des Hinzufügens eines unstrukturierten Datenelements zu einer Vektordatenbank wie Milvus.
from pymilvus import Collectioncollection = Collection('book')mr = collection.insert(data)
Wie Sie sehen, ist das Einfügen unstrukturierter Daten in Milvus mit nur drei Codezeilen äußerst einfach. Bei der Verwendung von Bibliotheken wie FAISS oder ScaNN ist es jedoch kompliziert. Diese Bibliotheken erfordern das manuelle Neuerstellen des gesamten Index an Checkpoints.
Vektordatenbanken vs. Vektorsuch-Plugins
Da Vektordatenbanken zunehmend Aufmerksamkeit gewinnen, beeilen sich viele herkömmliche Datenbanken und Suchsysteme wie Clickhouse, Elasticsearch, MongoDB und Databricks, integrierte Plugins für die Vektorsuche einzubinden. Elasticsearch 8.0 hat beispielsweise Funktionen wie Vektoreinfügung und ANN-Suche aktualisiert, die über RESTful-API-Endpunkte zugänglich sind.
Es ist jedoch wichtig zu beachten, dass Plugins für die Vektorsuche keinen umfassenden Ansatz für Embedding-Management und Vektorsuche bieten. Sie sind lediglich Add-ons zu bestehenden Systemen, was ihre Leistung in Bezug auf Latenz, Kapazität und Durchsatz einschränken kann. Der Versuch, Anwendungen für unstrukturierte Daten auf einer traditionellen Datenbank aufzubauen, ist wie der Einbau von Lithiumbatterien und Elektromotoren in den Rahmen eines benzinbetriebenen Autos – keine besonders gute Idee.
Vektordatenbanken sind für LLM-Augmentation unerlässlich
Da LLMs und KI-Anwendungen florieren, werden Vektordatenbanken zu einer wichtigen Infrastruktur für KI-bezogene Tech-Stacks.
Obwohl LLMs bei der Inhaltserzeugung beeindruckend sind, haben sie viele Einschränkungen. Beispielsweise sind sie aufgrund des Mangels an aktuellem und domänenspezifischem Wissen anfällig für Halluzinationen. Schlimmer noch: Die Token-Begrenzung von LLMs verhindert, dass Sie beim Stellen von Abfragen umfangreiche Kontextinformationen zu Prompts hinzufügen.
Eine Vektordatenbank kann als Langzeitgedächtnis von LLMs dienen und die Wissensbasis von LLMs erweitern. Sie speichert private Daten oder domänenspezifische Informationen außerhalb des LLM als Embeddings. Wenn ein Benutzer eine Frage stellt, sucht die Vektordatenbank nach den topk-Ergebnissen, die für diese Frage am relevantesten sind. Anschließend werden die Ergebnisse mit der ursprünglichen Abfrage kombiniert, um einen Prompt zu erstellen, der dem LLM einen umfassenden Kontext bietet, damit es genauere Antworten generieren kann. Diese Lösung ist auch als CVP stack (ChatGPT/LLMs + Vektordatenbank + prompt-as-code) bekannt.
LLMs berechnen Gebühren für jedes Token in Abfragen. Wenn Benutzer also ähnliche oder wiederholte Fragen stellen, würden ihnen mehrere Male Gebühren berechnet, was zu hohen Kosten führt. Während der Spitzenzeiten können Antworten sehr langsam sein. Um Zeit und Aufwand zu sparen, können Entwickler eine Vektordatenbank mit GPTCache integrieren, einem semantischen Open-Source-Cache, der LLM-Antworten speichert. Auf diese Weise ruft die Vektordatenbank, wenn der Benutzer eine Frage stellt, die das LLM bereits zuvor beantwortet hat, die Antworten aus GPTCache ab und gibt sie schnell an die Benutzer zurück, ohne das LLM aufzurufen.
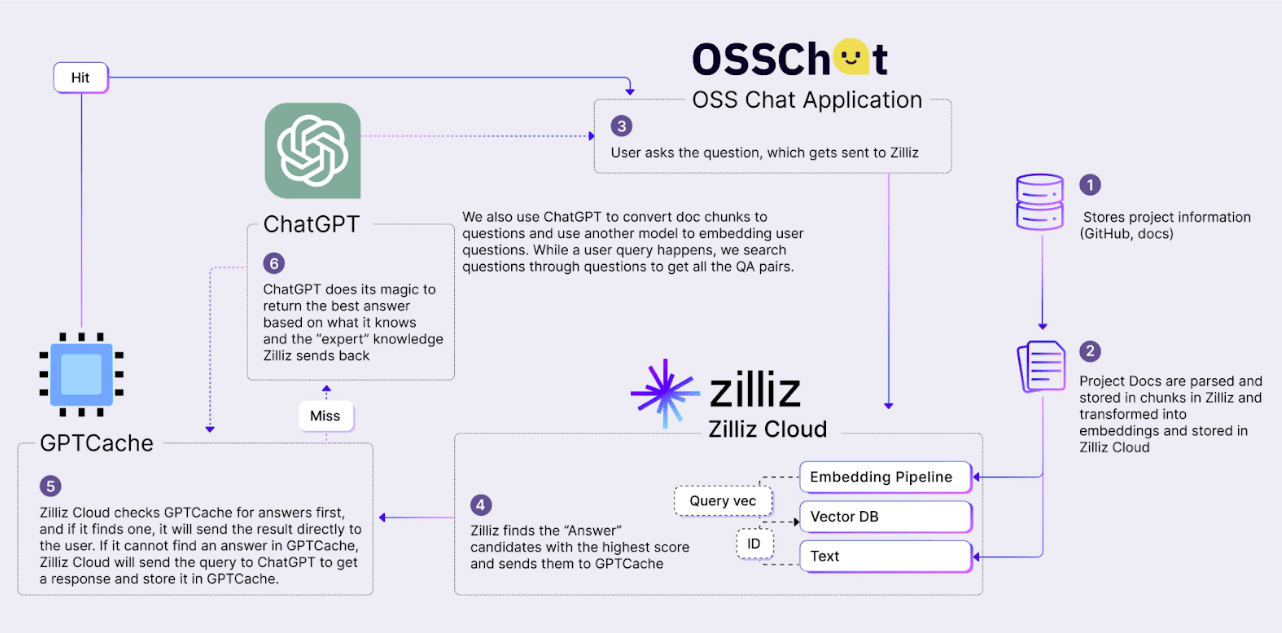 OSS Chat-Architektur
OSS Chat-Architektur
Das obige Diagramm zeigt die Architektur von OSS Chat, einem KI-Chatbot, der Zilliz Cloud und GPTCache nutzt.
Zusätzlich zur LLM augmentation sind Vektordatenbanken für viele Anwendungsfälle wertvoll, darunter Empfehlungssysteme, Ähnlichkeitssuchen für Bilder/Audio/Video/Text, Anomalieerkennung, Frage-Antwort-Systeme und molekulare Ähnlichkeitssuchen.
Wie wählt man die am besten geeignete Vektordatenbank für Ihr Projekt aus?
Haben Sie Schwierigkeiten, eine geeignete Vektordatenbank für Ihre Projekte auszuwählen? Bei den zahlreichen verfügbaren Optionen kann das überwältigend sein. Glücklicherweise gibt es eine Lösung, die Ihnen hilft, eine fundierte Entscheidung zu treffen.
VectorDBBench ist ein Open-Source-Benchmarking-Tool für Vektordatenbanken. Es bewertet verschiedene Vektordatenbanksysteme im Hinblick auf QPS, Latenz, Kapazität und andere Kennzahlen. Es ist in Python geschrieben und unter der MIT-Open-Source-Lizenz lizenziert, sodass jeder es frei nutzen, ändern und verbreiten kann.
Mit VectorDBBench können Sie die beste Vektordatenbank auf der Grundlage der tatsächlichen Leistung statt auf Basis von Marketingbehauptungen auswählen. Um loszulegen, lesen Sie dieses Tutorial.
Zusammenfassung
Dieser Beitrag bietet einen Überblick über Vektordatenbanken und erklärt, wie sie sich von Vektor-Retrieval-Bibliotheken und Vektorsuch-Plugins auf Basis traditioneller relationaler Datenbanken unterscheiden. Am wichtigsten ist, dass wir VectorDBBench vorstellen, ein Open-Source-Benchmarking-Tool, das Nutzern hilft, fundierte Entscheidungen zu treffen.
Im folgenden Beitrag stellen wir Milvus vor, die weltweit erste und am weitesten verbreitete Open-Source-Vektordatenbank, und zeigen Ihnen, wie Sie mit Milvus loslegen.

Weiterlesen

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.

Zilliz Cloud Introduces Advanced BYOC-I Solution for Ultimate Enterprise Data Sovereignty
Explore Zilliz Cloud BYOC-I, the solution that balances AI innovation with data control, enabling secure deployments in finance, healthcare, and education sectors.

1 Table = 1000 Words? Foundation Models for Tabular Data
TableGPT2 automates tabular data insights, overcoming schema variability, while Milvus accelerates vector search for efficient, scalable decision-making.