




Milvus auf GPUs mit NVIDIA RAPIDS cuVS
Einleitung
Die Leistung in der Produktion ist ein entscheidender Faktor für den Erfolg unserer KI-Anwendung. Je schneller wir dem Benutzer Ergebnisse liefern können, desto besser. Diese Dringlichkeit macht eine Optimierung erforderlich.
Betrachten wir ein Beispiel aus der Praxis - eine Retrieval Augmented Generation (RAG)-Anwendung. In einem RAG-System ist die Vektorsuche der Motor, der die Benutzererfahrung vorantreibt und relevante Ergebnisse auf der Grundlage ihrer Abfragen liefert. Wir wissen jedoch nur zu gut, dass die Vektorsuche eine ressourcenintensive Aufgabe ist. Je mehr Daten wir speichern, desto teurer und zeitaufwändiger werden die Berechnungen.
Es muss eine Lösung gefunden werden, um die Leistung unserer KI-Anwendungen in solchen Fällen zu optimieren. In einem kürzlich gehaltenen Vortrag beim Unstructured Data Meetup, das von Zilliz veranstaltet wurde, sprach Corey Nolet, Principal Engineer bei NVIDIA, über NVIDIAs neueste Entwicklungen zur Lösung dieses Problems, die wir in diesem Artikel näher beleuchten werden. Sie können sich auch Coreys Vortrag auf YouTube ansehen.
Wir werden uns insbesondere auf cuVS konzentrieren, eine von NVIDIA entwickelte Bibliothek, die mehrere Algorithmen zur Vektorsuche enthält und die Beschleunigungsleistung von Grafikprozessoren nutzt. Wir werden sehen, wie diese Bibliothek die Leistung von Vektorsuchoperationen verbessern und die Gesamtbetriebskosten optimieren kann. Also, ohne weitere Umschweife, lasst uns eintauchen!
Vektorsuche und die Rolle der Vektordatenbank dabei
Die Vektorsuche ist eine Information Retrieval-Methode, bei der sowohl die Suchanfrage des Benutzers als auch die gesuchten Dokumente als Vektoren dargestellt werden. Um eine Vektorsuche durchzuführen, müssen wir unsere Anfrage und die Dokumente (die Bilder, Texte usw. sein können) in Vektoren umwandeln.
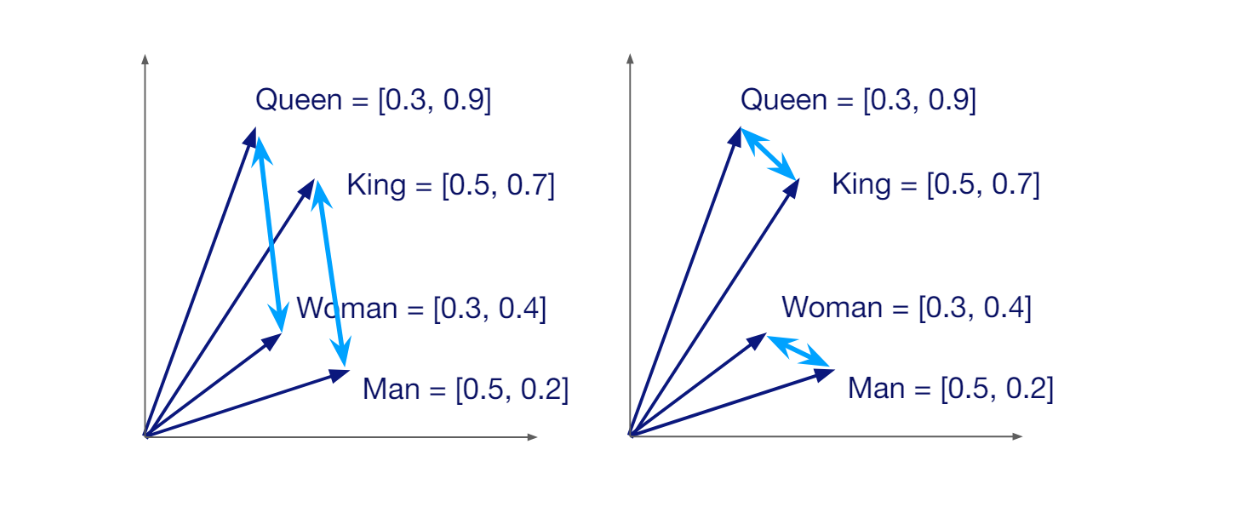
Ein Vektor hat eine bestimmte Dimension, die von der Methode abhängt, mit der er erzeugt wurde. Wenn wir zum Beispiel ein HuggingFace-Modell namens all-MiniLM-L6-v2 verwenden, um unsere Abfrage in einen Vektor umzuwandeln, erhalten wir einen Vektor mit einer Dimension von 384. Vektoren tragen die semantische Bedeutung der Daten oder Dokumente, die sie darstellen. Wenn also zwei Daten einander ähnlich sind, werden die entsprechenden Vektoren im Vektorraum nahe beieinander positioniert.
 Semantische Ähnlichkeit zwischen Vektoren in einem Vektorraum..png
Semantische Ähnlichkeit zwischen Vektoren in einem Vektorraum..png
Semantische Ähnlichkeit zwischen Vektoren in einem Vektorraum.
Die Tatsache, dass jeder Vektor die semantische Bedeutung der Daten trägt, die er repräsentiert, ermöglicht es uns, die Ähnlichkeit zwischen jedem beliebigen Vektorpaar zu berechnen. Wenn sie ähnlich sind, ist der Ähnlichkeitswert hoch und umgekehrt. Der Hauptzweck der Vektorsuche besteht darin, die Vektoren zu finden, die dem Vektor unserer Anfrage am ähnlichsten sind.
Die Implementierung der Vektorsuche ist relativ einfach, wenn es sich um einige wenige Dokumente handelt. Die Komplexität nimmt jedoch zu, wenn wir mehr Dokumente haben und mehr Vektoren speichern müssen. Je mehr Vektoren wir haben, desto länger dauert es, eine Vektorsuche durchzuführen. Außerdem steigen die Betriebskosten erheblich, wenn wir mehr Vektoren im lokalen Speicher ablegen. Wir brauchen also eine skalierbare Lösung, und hier kommen [Vektordatenbanken] (https://zilliz.com/learn/what-is-vector-database) ins Spiel.
Vektordatenbanken bieten eine effiziente, schnelle und skalierbare Lösung für die Speicherung einer großen Sammlung von Vektoren. Sie bieten fortschrittliche Indizierungsmethoden für ein schnelleres Auffinden bei Vektorsuchvorgängen sowie eine einfache Integration mit gängigen KI-Frameworks, um den Entwicklungsprozess unserer KI-Anwendungen zu vereinfachen. In Vektordatenbanken wie Milvus und Zilliz Cloud (das verwaltete Milvus) können wir auch die Metadaten der Vektoren speichern und während der Suchvorgänge erweiterte Filterprozesse durchführen.
 Vollständiger Arbeitsablauf eines Vektorsuchvorgangs..png
Vollständiger Arbeitsablauf eines Vektorsuchvorgangs..png
Vollständiger Arbeitsablauf eines Vektorsuchlaufs.
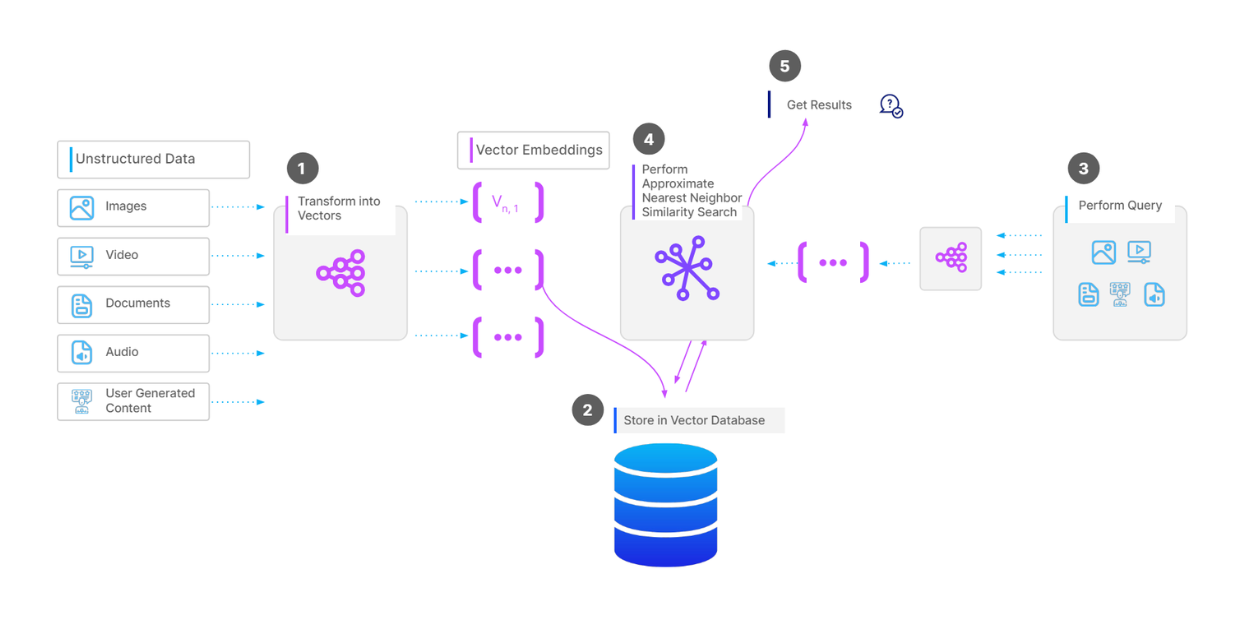
Um eine Sammlung von Vektoren in einer Vektordatenbank wie Milvus zu speichern, müssen wir zunächst die Daten je nach Datentyp vorverarbeiten. Wenn es sich bei unseren Daten beispielsweise um eine Sammlung von Dokumenten handelt, können wir den Text in jedem Dokument in Abschnitte (Chunks) aufteilen. Als Nächstes wandeln wir jedes Stück in einen Vektor um, indem wir [ein Einbettungsmodell] (https://zilliz.com/ai-models) unserer Wahl verwenden. Anschließend nehmen wir alle Vektoren in unsere Vektordatenbank auf und erstellen einen Index für sie, um sie bei Vektorsuchvorgängen schneller abrufen zu können.
Wenn wir eine Abfrage haben und eine Vektorsuche durchführen wollen, wandeln wir die Abfrage in einen Vektor um, indem wir dasselbe Einbettungsmodell wie zuvor verwenden, und berechnen dann seine Ähnlichkeit mit den Vektoren in der Datenbank. Schließlich werden uns die ähnlichsten Vektoren zurückgegeben.
Vektorsuchvorgang auf der CPU
Vektorsuchvorgänge sind rechenintensiv, und die Rechenkosten steigen, je mehr Vektoren in einer Vektordatenbank gespeichert sind. Mehrere Faktoren wirken sich direkt auf die Berechnungskosten aus, z. B. die Indexerstellung, die Gesamtzahl der Vektoren, die Vektordimensionalität und die gewünschte Qualität der Suchergebnisse.
CPUs sind aufgrund ihrer Kosteneffizienz und der einfachen Integration mit anderen Komponenten in KI-Anwendungen die gängigsten Verarbeitungseinheiten für Vektorsuchoperationen. Viele Vektorsuchalgorithmen sind vollständig für CPUs optimiert, wobei Hierarchical Navigable Small World (HNSW) der beliebteste ist.
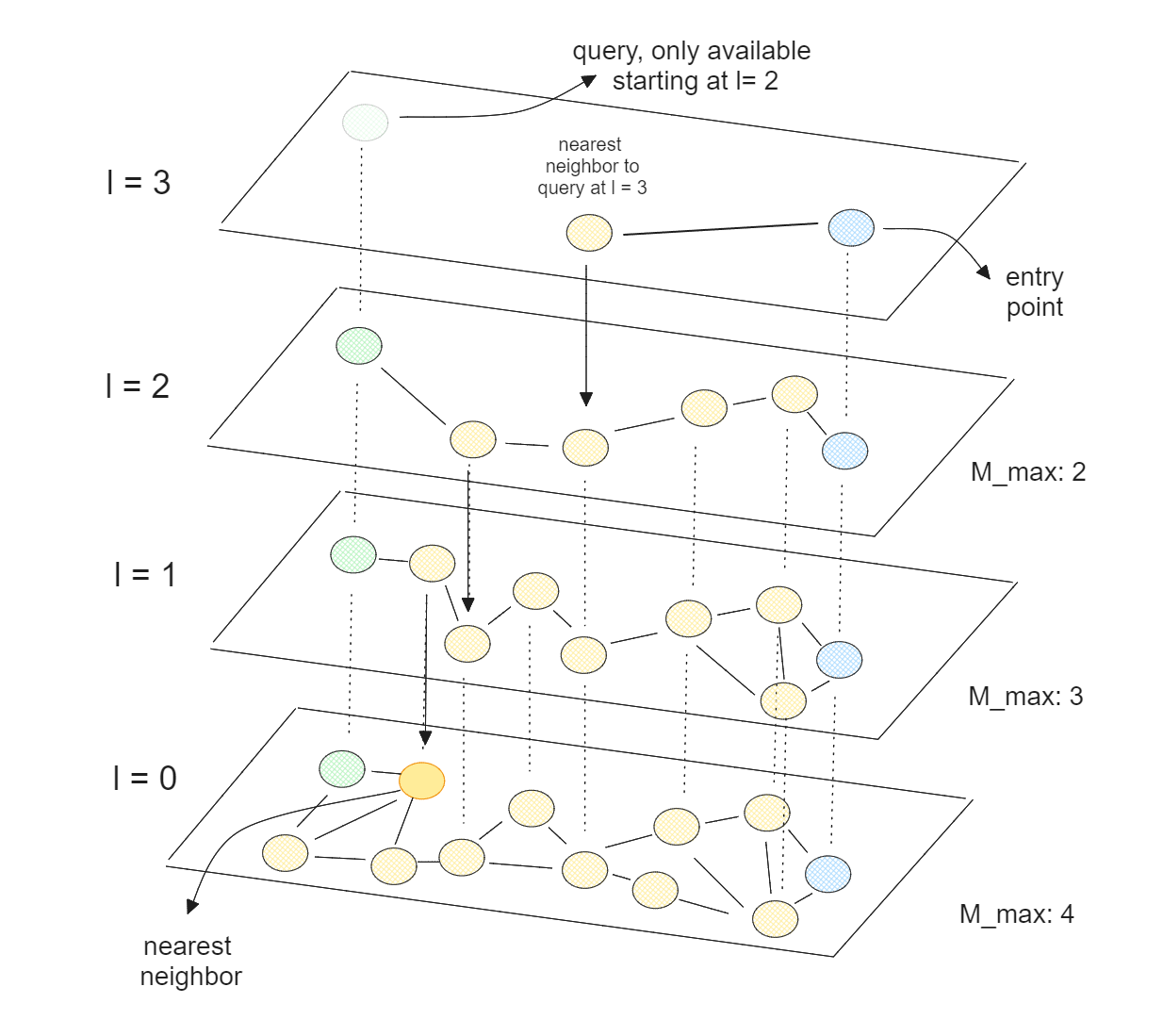
Im Kern kombiniert HNSW die Konzepte von Skip Lists und Navigable Small World (NSW). Bei einem NSW-Algorithmus wird der Graph aufgebaut, indem zunächst die Datenpunkte zufällig gemischt werden. Anschließend werden die Datenpunkte nacheinander eingefügt, wobei jeder Punkt über eine vordefinierte Anzahl von Kanten mit seinen nächsten Nachbarn verbunden ist.
 Vektorsuche mit HNSW..png
Vektorsuche mit HNSW..png
Vektorsuche mit HNSW.
HNSW ist eine mehrschichtige NSW, bei der die unterste Schicht alle Datenpunkte enthält, während die oberste Schicht nur eine kleine Teilmenge unserer Datenpunkte enthält. Das bedeutet, dass wir umso mehr Datenpunkte auslassen, je höher die Schicht ist, was der Theorie der Sprunglisten entspricht.
Mit HNSW haben wir einen Graphen, bei dem die meisten Knoten von jedem anderen Knoten aus durch eine geringe Anzahl von Iterationen erreicht werden können. Diese Eigenschaft ermöglicht es HNSW, schnell und effizient durch den Graphen zu navigieren, um die ungefähren nächsten Nachbarn zu finden. Da HNSW für CPUs optimiert ist, können wir seine Ausführung auch auf mehrere CPU-Kerne verteilen, um den Vektorsuchprozess weiter zu beschleunigen.
Die Berechnungszeit von HNSW leidet jedoch immer noch, wenn wir mehr Daten in der Vektordatenbank speichern. Noch schlimmer kann es werden, wenn die Dimensionalität unserer Vektoren sehr hoch ist. Daher benötigen wir eine andere Lösung für Fälle, in denen wir eine große Anzahl von Vektoren mit hoher Dimensionalität haben.
Vektorsuchvorgang auf GPU
Eine Lösung zur Verbesserung der Vektorsuchleistung bei einer großen Anzahl von hochdimensionalen Vektoren ist die Arbeit auf einem Grafikprozessor. Um dies zu erleichtern, können wir NVIDIAs RAPIDS cuVS verwenden, eine Bibliothek, die mehrere GPU-optimierte Vektorsuchimplementierungen enthält. Sie vereinfacht die Verwendung von GPUs sowohl für Vektorsuchoperationen als auch für den Indexaufbau.
cuVS bietet mehrere Algorithmen für die nächste Nachbarschaft zur Auswahl, darunter:
Brute-force: Eine erschöpfende Suche nach den nächsten Nachbarn, bei der die Anfrage mit jedem Vektor in der Datenbank verglichen wird.
IVF-Flat: Ein Algorithmus zur approximativen nächsten Nachbarschaft (ANN), der die Vektoren in der Datenbank in mehrere sich nicht überschneidende Partitionen unterteilt. Die Abfrage wird dann nur mit Vektoren in denselben (und optional benachbarten) Partitionen verglichen.
IVF-PQ: Eine quantisierte Version von IVF-Flat, die den Speicherbedarf der gespeicherten Vektoren in der Datenbank reduziert.
CAGRA: Ein GPU-nativer Algorithmus ähnlich wie HNSW.
 CAGRA graph construction. .png
CAGRA graph construction. .png
CAGRA-Graphkonstruktion. Quelle.
Unter diesen Algorithmen zur Bestimmung der nächsten Nachbarn konzentrieren wir uns auf CAGRA.
CAGRA ist ein graphenbasierter Algorithmus, der von NVIDIA für eine schnelle und effiziente approximative Suche nach nächsten Nachbarn eingeführt wurde und die parallele Verarbeitungsleistung von GPUs nutzt.
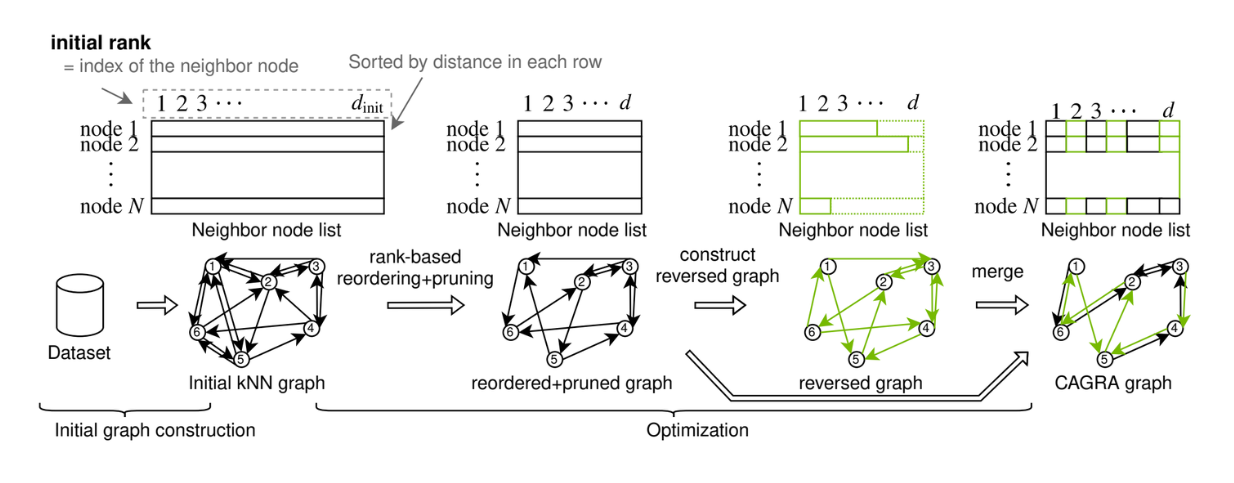
Der Graph in CAGRA kann entweder mit der IVF-PQ-Methode oder der NN-DESCENT-Methode erstellt werden:
IVF-PQ-Methode: Verwendet einen Index, um einen speichereffizienten Ausgangsgraphen zu erstellen, indem jeder Punkt mit vielen Nachbarn verbunden wird.
NN-DESCENT-Methode: Verwendet einen iterativen Prozess zum Aufbau eines Graphen durch Erweiterung und Verfeinerung der Verbindungen zwischen Punkten.
Im Vergleich zu HNSW sind die CAGRA-Methoden zur Graphenerstellung leichter zu parallelisieren und beinhalten weniger Dateninteraktion zwischen den Aufgaben, was die Zeit für die Graphen- oder Indexerstellung erheblich verkürzt. Wenn Sie mehr über CAGRA erfahren möchten, lesen Sie das offizielle Papier oder den CAGRA-Artikel.
CAGRA hat bei Vektorsuchoperationen eine Spitzenleistung erbracht. Um dies zu demonstrieren, werden wir im nächsten Abschnitt seine Leistung mit HNSW vergleichen.
Vergleich der Leistung von CAGRA und HNSW
Bei der Vektorsuche gibt es zwei kritische Operationen, bei denen die Leistung entscheidend ist: der Indexaufbau und die Suche selbst. Wir werden die Leistung von CAGRA und HNSW bei diesen beiden Operationen vergleichen.
Beginnen wir mit der Indexerstellung.
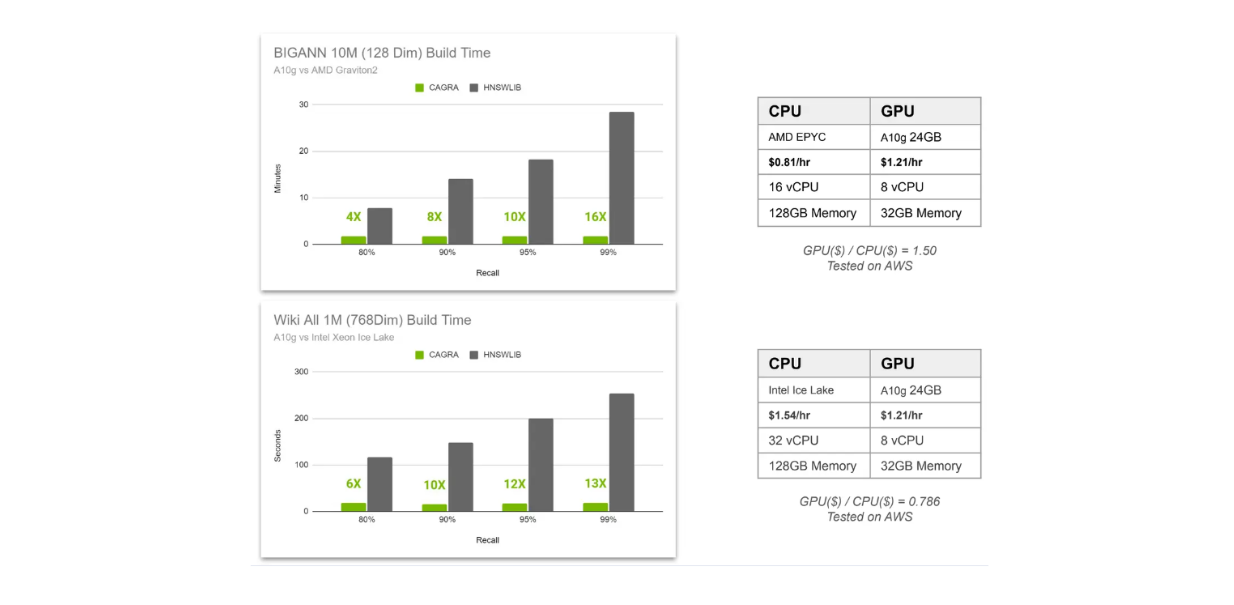 Indexaufbauzeitvergleich CAGRA vs HNSW..png
Indexaufbauzeitvergleich CAGRA vs HNSW..png
Indexaufbauzeit-Vergleich CAGRA vs. HNSW._
In der obigen Visualisierung vergleichen wir die Indexerstellungszeit von CAGRA und HNSW in zwei verschiedenen Szenarien. Erstens haben wir 10M 128-dimensionale Vektoren in einer Vektordatenbank gespeichert, und zweitens haben wir 1M 768-dimensionale Vektoren. Im ersten Szenario wird AMD Graviton2 als CPU für HNSW und A10G GPU für CAGRA verwendet, während im zweiten Szenario Intel Xeon Ice Lake als CPU für HNSW und A10G GPU für CAGRA verwendet wird.
Wir vergleichen die Indexerstellungszeit bei vier verschiedenen Recall-Werten, die von 80 % bis 99 % reichen. Wie Sie vielleicht bereits wissen, ist die erforderliche Berechnung umso intensiver, je höher der Recall-Wert ist.
Das liegt daran, dass wir bei einer graphbasierten Vektorsuche zwei Faktoren feinabstimmen können: die Anzahl der Nachbarn, die berücksichtigt werden, um den nächsten Nachbarn auf jeder Ebene zu finden, und die Anzahl der nächsten Nachbarn, die als Einstiegspunkt in jeder Ebene berücksichtigt werden. Je höher der Recall, desto mehr Nachbarn werden berücksichtigt, was zu einer höheren Abrufgenauigkeit, aber auch zu höheren Rechenkosten führt.
Aus der obigen Visualisierung geht hervor, dass der Einsatz eines Grafikprozessors sinnvoller ist, wenn wir Ergebnisse mit einer hohen Wiederauffindbarkeit erzielen wollen. Außerdem steigt der Geschwindigkeitszuwachs durch den Einsatz von GPUs, wenn wir die Anzahl der hochdimensionalen Vektoren in unserer Vektordatenbank erhöhen.
Als Nächstes wollen wir die Leistung von HNSW und CAGRA anhand zweier gängiger Metriken für die Vektorsuche vergleichen:
Durchsatz: die Anzahl der Abfragen, die in einem bestimmten Zeitintervall abgeschlossen werden können.
Latenz**: die Zeit, die der Algorithmus benötigt, um eine Abfrage abzuschließen.
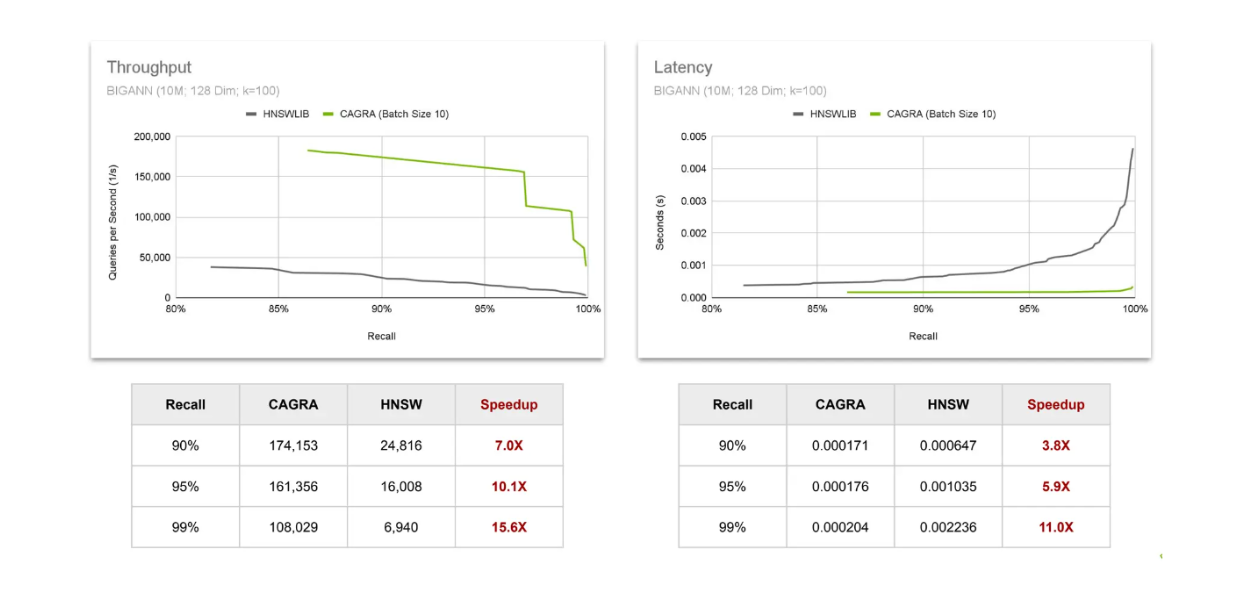 Durchsatz- und Latenzvergleiche CAGRA vs HNSW..png
Durchsatz- und Latenzvergleiche CAGRA vs HNSW..png
Durchsatz- und Latenzvergleiche CAGRA vs. HNSW.png
Zur Bewertung des Durchsatzes wird die Anzahl der Abfragen betrachtet, die in einer Sekunde abgeschlossen werden können. Die Ergebnisse zeigen, dass der Geschwindigkeitszuwachs durch die Verwendung von CAGRA auf der GPU zunimmt, wenn wir Ergebnisse mit höheren Wiedererkennungswerten benötigen. Derselbe Trend ist bei der Latenzzeit zu beobachten, wo die Beschleunigung mit steigendem Recall-Wert zunimmt. Dies bestätigt, dass der Wert des Einsatzes von GPU zunimmt, wenn wir präzisere Ergebnisse aus der Vektorsuche suchen.
Manchmal möchten wir jedoch bei der Vektorsuche aufgrund ihrer Einfachheit und der leichten Integration mit anderen Komponenten in unserer KI-Anwendung weiterhin die CPU verwenden. In diesem Fall ist die Implementierung von Nearest Neighbors-Algorithmen mit CAGRA immer noch hilfreich, da wir die Vektorsuche anschließend sowohl auf der GPU als auch auf der CPU durchführen können.
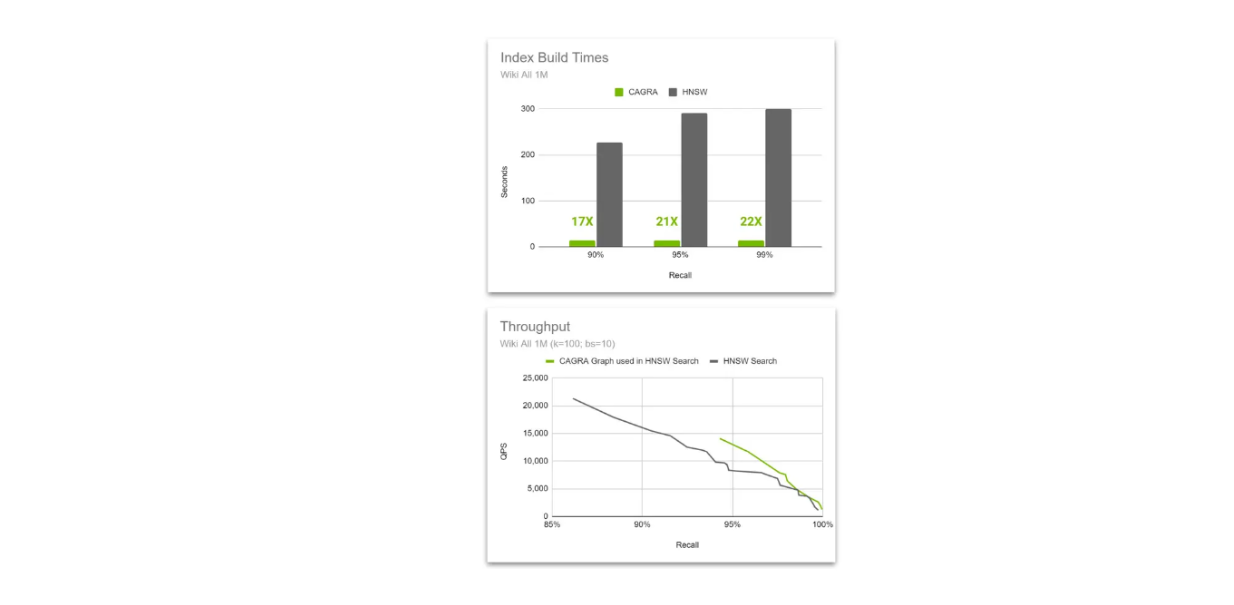 Durchsatzvergleich zwischen nativem HNSW- und CAGRA-Diagramm, das in der HNSW-Suche verwendet wird..png
Durchsatzvergleich zwischen nativem HNSW- und CAGRA-Diagramm, das in der HNSW-Suche verwendet wird..png
Durchsatzvergleich zwischen nativem HNSW- und CAGRA-Graph in der HNSW-Suche.
Die Idee besteht darin, die Beschleunigungsleistung von CAGRA und GPU während der Indexerstellung zu nutzen, aber dann während der Vektorsuche zu HNSW zu wechseln. Diese Methode ist möglich, weil der HNSW-Algorithmus eine Suche mit einem von CAGRA erstellten Graphen durchführen kann und seine Leistung mit zunehmender Vektordimension sogar besser ist als der mit HNSW erstellte Graph.
CAGRA bietet auch eine Quantisierungsmethode namens CAGRA-Q, um den Speicher der gespeicherten Vektoren weiter zu komprimieren. Dies ist besonders hilfreich, um die Speicherzuweisung effizienter zu gestalten, und ermöglicht es uns, quantisierte Vektoren auf einem kleineren Gerätespeicher zu speichern und schneller abzurufen.
Nehmen wir an, wir haben einen Gerätespeicher, der im Vergleich zum Hostspeicher eine kleinere Speichergröße hat. Erste Leistungs-Benchmarks von NVIDIA haben gezeigt, dass quantisierte Vektoren, die im Gerätespeicher mit dem im Host-Speicher gespeicherten Graphen gespeichert werden, bei höheren Abrufraten eine ähnliche Leistung aufweisen wie die ursprünglichen, nicht quantisierten Vektoren und der im Gerätespeicher gespeicherte Graph.
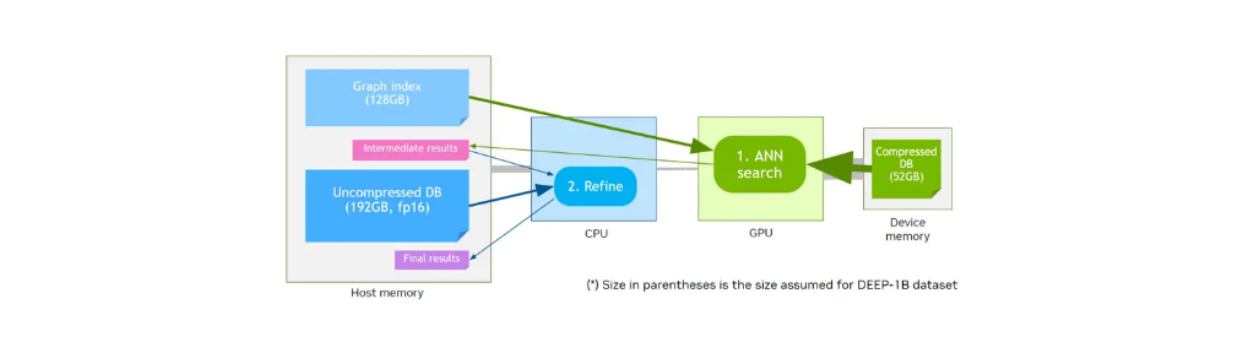 Arbeitsablauf bei der Vektorsuche unter Verwendung von Gerätespeicher und CAGRA-Q..png
Arbeitsablauf bei der Vektorsuche unter Verwendung von Gerätespeicher und CAGRA-Q..png
Arbeitsablauf bei der Vektorsuche unter Verwendung von Gerätespeicher und CAGRA-Q.
Milvus auf der GPU mit CuVS
[Milvus] (https://zilliz.com/what-is-milvus) unterstützt die Integration mit der cuVS-Bibliothek, die es uns ermöglicht, Milvus mit CAGRA zu kombinieren, um KI-Anwendungen zu erstellen. Die Architektur von Milvus besteht aus mehreren Knoten, wie Indexknoten, Abfrageknoten und Datenknoten. cuVS optimiert die Leistung von Milvus, indem es Prozesse innerhalb der Abfrageknoten und Indexknoten beschleunigt.
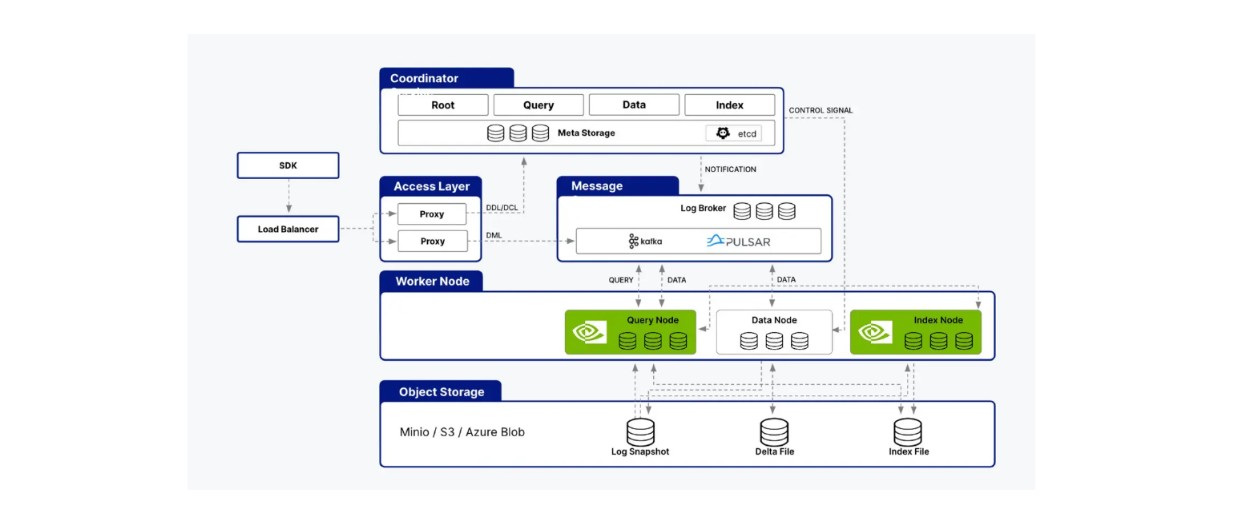 cuVS unterstützt sowohl Abfrage- als auch Indexknoten der Milvus-Architektur..png
cuVS unterstützt sowohl Abfrage- als auch Indexknoten der Milvus-Architektur..png
cuVS unterstützt sowohl Abfrage- als auch Indexknoten der Milvus-Architektur.
Wie Sie vielleicht bereits wissen, sind Indexknoten für den Aufbau von Indizes zuständig, während Abfrageknoten Benutzeranfragen verarbeiten, Vektorsuchen durchführen und die Ergebnisse an den Benutzer zurückgeben. Wir haben im vorherigen Abschnitt gesehen, wie CAGRA all diese Aspekte im Vergleich zu nativen CPU-Algorithmen wie HNSW verbessert.
Nun wollen wir die Leistung der Indexerstellung mit cuVS und Milvus vor Ort untersuchen. Konkret werden wir die Zeit für die Indexerstellung mit CAGRA und IVF-PQ für verschiedene Anzahlen von Vektoren betrachten: 10, 20, 40 und 80 Millionen.
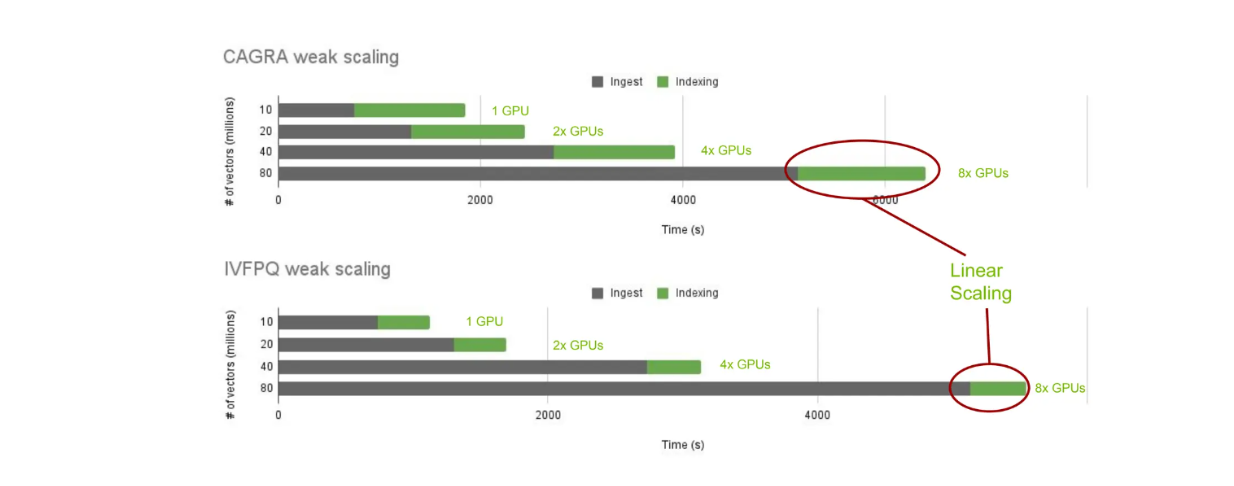 cuVS-Skalierung der Indexerstellungszeit über verschiedene Algorithmen für nächste Nachbarn..png
cuVS-Skalierung der Indexerstellungszeit über verschiedene Algorithmen für nächste Nachbarn..png
cuVS-Skalierung der Indexerstellungszeit über verschiedene Algorithmen der nächsten Nachbarn hinweg.
Wie erwartet, steigt die Ingest-Zeit mit der Anzahl der gespeicherten Vektoren. Die Indexerstellungszeit bleibt jedoch konstant, wenn wir je nach Anzahl der gespeicherten Vektoren linear weitere GPUs hinzufügen. Dies ermöglicht es uns, die Indexerstellungszeit über verschiedene Nearest-Neighbour-Algorithmen mit cuVS zu skalieren und zu vergleichen.
Wir wissen, dass GPUs im Vergleich zu CPUs schnellere Rechenoperationen bieten. Allerdings sind die Betriebskosten für die Nutzung von GPUs auch höher. Daher müssen wir das Kosten-Leistungs-Verhältnis der Verwendung von GPUs und CPUs mit Milvus vergleichen, wie unten dargestellt.
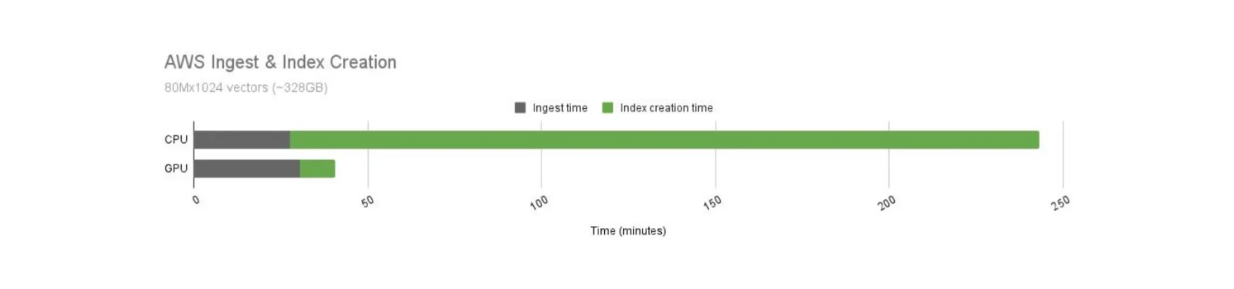 Vergleich der Indexerstellungszeit von Milvus zwischen GPU und CPU..png
Vergleich der Indexerstellungszeit von Milvus zwischen GPU und CPU..png
Vergleich der Indexerstellungszeit von Milvus zwischen GPU und CPU.
Die Indexerstellungszeit mit GPUs ist deutlich schneller als mit CPUs. In diesem Anwendungsfall bietet das GPU-beschleunigte Milvus eine 21-fache Beschleunigung im Vergleich zu seinem CPU-Pendant. Allerdings sind die Betriebskosten von GPUs auch teurer als die von CPUs. Die GPU kostet 16,29 pro Stunde kostet.
Wenn wir das Kosten-Leistungs-Verhältnis von GPUs und CPUs normalisieren, führt die Verwendung von GPUs zur Indexerstellung immer noch zu besseren Ergebnissen. Bei gleichen Kosten ist die Indexerstellungszeit mit GPUs 12,5x schneller.
In einem weiteren Benchmark-Test haben wir einen Index für 635M 1024-dimensionale Vektoren erstellt. Bei Verwendung von 8 DGX H100 GPUs dauert die Indexerstellung mit der IVF-PQ-Methode etwa 56 Minuten. Im Gegensatz dazu würde die Durchführung der gleichen Aufgabe mit einer CPU etwa 6,22 Tage dauern.
Vergleich der Indexerstellungszeit von Milvus in großem Maßstab zwischen GPU und CPU..png](https://assets.zilliz.com/Large_scale_Milvus_index_building_time_comparison_between_GPU_and_CPU_c987afe852.png)
Vergleich der Indexerstellungszeit von Milvus in großem Maßstab zwischen GPU und CPU.
Schlussfolgerung
Die Fortschritte bei der GPU-beschleunigten Vektorsuche durch die cuVS-Bibliothek von NVIDIA und den CAGRA-Algorithmus sind für die Optimierung der Leistung von KI-Anwendungen in der Produktion von großem Nutzen. Insbesondere bieten GPUs signifikante Verbesserungen gegenüber CPUs in Fällen mit hohen Recall-Werten, hoher Vektordimensionalität und einer großen Anzahl von Vektoren.
Dank der Integrationsmöglichkeiten von Milvus können wir cuVS nun problemlos in unsere Milvus-Vektordatenbank einbinden. Obwohl die Betriebskosten von GPUs höher sind als die von CPUs, ist das Leistungs-Kosten-Verhältnis bei großen Anwendungen oft immer noch zugunsten von GPUs, wie die obigen Benchmarks zeigen. Wenn Sie mehr über cuVS erfahren möchten, können Sie die umfassende Dokumentation des NVIDIA-Teams lesen.
Weitere Ressourcen
Was sind Vektordatenbanken und wie funktionieren sie?](https://zilliz.com/learn/what-is-vector-database)
Wie Sie die Leistung Ihrer RAG-Pipeline verbessern können](https://zilliz.com/learn/how-to-enhance-the-performance-of-your-rag-pipeline)
Effiziente Vektorsuche in RecSys mit Milvus und NVIDIA Merlin](https://zilliz.com/blog/efficient-vector-similarity-search-recommender-workflows-using-milvus-nvidia-merlin)
Generative KI Ressource Hub | Zilliz](https://zilliz.com/learn/generative-ai)
Weiterlesen

Vector Lakebase: End the AI Data Silo
Learn how Vector Lakebase unifies vector search, data lakes, and AI data operations so teams can serve RAG and agents without copy-and-sync pipelines.

We spent 8 years making vector databases faster. Then we stopped.
Rarely queried embeddings still need to stay searchable. See how Vector Lakebase enables on-demand vector search without always-on compute costs.

Milvus 2.6.x Now Generally Available on Zilliz Cloud, Making Vector Search Faster, Smarter, and More Cost-Efficient for Production AI
Milvus 2.6.x is now GA on Zilliz Cloud, delivering faster vector search, smarter hybrid queries, and lower costs for production RAG and AI applications.