




Lokaler agentenbasierter RAG mit LangGraph und Llama 3.2
Aktualisiert am 25. September 2024 mit Llama 3.2.
In diesem Beitrag zeigen wir, wie man Agenten erstellt, die auf intelligente Weise Werkzeuge aufrufen können, um bestimmte Aufgaben mit LangGraph und Llama 3 auszuführen, während sie gleichzeitig Milvus Lite für eine effiziente Datenspeicherung nutzen. Diese Agenten vereinen mehrere wichtige Fähigkeiten, einschließlich Planung, Speicher und Werkzeugaufrufe, um die Leistung von Retrieval-Augmented Generation (RAG) Systemen zu verbessern.
Einführung in LangGraph und Llama 3
LangGraph ist eine Erweiterung von LangChain, die entwickelt wurde, um robuste, zustandsbehaftete Multi-Aktor-Anwendungen mit large language models (LLMs) zu erstellen. Während LangChain einen Rahmen für die Integration von LLMs in verschiedene Arbeitsabläufe bietet, erweitert LangGraph dies durch die Modellierung von Aufgaben als Knoten und Kanten in einer Graphenstruktur. Dies ermöglicht komplexere Kontrollflüsse, so dass LLMs planen, lernen und sich an die jeweilige Aufgabe anpassen können. LangGraph bietet die Flexibilität, Systeme zu implementieren, in denen Agenten mehrstufige Überlegungen anstellen und dynamisch die richtigen Werkzeuge für jeden Schritt auswählen. Darüber hinaus kann LangGraph verwendet werden, um zuverlässige RAG-Agenten zu erstellen, die jedes Mal, wenn sie ausgeführt werden, einem benutzerdefinierten Kontrollfluss folgen und so Konsistenz und Vorhersagbarkeit in ihren Antworten gewährleisten.
LangGraph ermöglicht auch kompliziertere, agentenähnliche Verhaltensweisen, indem es die Einbindung von Zyklen in Arbeitsabläufe ermöglicht. Diese Zyklen ermöglichen es den Agenten, bei Bedarf zu vorherigen Schritten zurückzukehren und ihre Aktionen auf der Grundlage neuer Informationen oder Überlegungen dynamisch anzupassen. Dies führt zu intelligenteren Agenten, die in der Lage sind, ihr Denken im Laufe der Zeit zu verfeinern, wodurch robustere und anpassungsfähigere RAG-Systeme entstehen.
Llama 3, ein Open-Source-Sprachmodell, dient als Kern des Agentengedächtnisses und als Denkmaschine. In Kombination mit LangGraph kann Llama 3 Eingaben analysieren, entscheiden, welche Aktionen durchgeführt werden sollen, und die notwendigen Werkzeuge aufrufen. Anstatt nur Text zu generieren, ermöglicht Llama 3 - angetrieben von LangGraph - den Agenten, ihre Aktionen zu planen, auszuführen und zu reflektieren, was sie intelligenter und leistungsfähiger macht.
In diesem Beitrag zeigen wir, wie man ein agentic rag System mit LangGraph, Llama 3 und Milvus Lite erstellt. Dieses Setup erlaubt es Ihnen, alles lokal zu betreiben, ohne externe Server zu benötigen, was es ideal für datenschutzbewusste Benutzer und Offline-Umgebungen macht.
Bau eines Tool-Calling-Agenten mit LangGraph
Der Arbeitsablauf von LangGraph basiert auf dem Konzept der Knoten, wobei jeder Knoten eine bestimmte Aufgabe oder ein bestimmtes Werkzeug repräsentiert. Diese Aufgaben können das Aufrufen von LLMs, das [Abrufen von Informationen] (https://zilliz.com/learn/what-is-information-retrieval) oder das Aufrufen eigener Werkzeuge beinhalten. In einem Werkzeugaufruf-Agenten sind zwei Schlüsselkomponenten im Spiel:
LLM-Knoten: Dieser Knoten entscheidet auf der Grundlage der Eingaben des Benutzers, welches Tool verwendet werden soll. Er analysiert die Anfrage und gibt den Werkzeugnamen und die relevanten Argumente aus.
Werkzeugknoten: Dieser Knoten übernimmt den Werkzeugnamen und die Argumente vom LLM-Knoten, ruft das entsprechende Werkzeug auf und gibt das Ergebnis an den LLM zurück.
Durch die Strukturierung von Aufgaben (wie z.B. Websuche) als Knoten und Kanten ermöglicht LangGraph die Erstellung von intelligenten, mehrstufigen Arbeitsabläufen, in denen LLMs über die Frage des Benutzers nachdenken können, welche Aktionen zu unternehmen sind, welche Werkzeuge zu verwenden sind, welche Antworten auf die Frage zu geben sind und wie die Antworten zu verfeinern sind. Milvus Lite spielt hier eine Schlüsselrolle, da es eine effiziente lokale Speicherung und Abfrage von [vektorisierten Daten] (https://zilliz.com/learn/an-ultimate-guide-to-vectorizing-structured-data) ermöglicht.
Wie Milvus Lite die lokalen Werkzeugaufrufe verbessert
Milvus Lite ist eine leichtgewichtige, lokale Version von Milvus, die für den Betrieb weder Docker noch Kubernetes benötigt. Dies macht es einfach, Milvus auf Ihrem Laptop, Jupyter-Notebook oder sogar in Google Colab auszuführen. Die lokale Bereitstellung von Milvus Lite ermöglicht es Ihnen, Vektoren zu speichern, die aus verschiedenen Webquellen oder Dokumenten generiert wurden, ohne sich auf externe Datenbanken verlassen zu müssen. Milvus Lite lässt sich nahtlos in LangGraph integrieren, um Vektorsuchen durchzuführen, was es zu einer idealen Lösung für lokale RAG Systeme macht.
Milvus Lite kann zum Beispiel verwendet werden, um indizierte Dokumente zu speichern, die vom Agenten während einer Websuche abgerufen werden. Wenn der Agent nach Informationen sucht, ermöglicht die Vektordatenbank ein schnelles und genaues Auffinden der relevanten Dokumente.
Erstellen eines lokalen RAG-Systems mit LangGraph und Llama 3
Wir verwenden LangGraph, um einen eigenen lokalen RAG-Agenten auf Basis von Llama 3.2 zu erstellen, der verschiedene Ansätze verwendet:
Wir implementieren jeden Ansatz als einen Kontrollfluss in LangGraph:
Routing (Adaptive RAG) - Ermöglicht es dem Agenten, Benutzeranfragen intelligent an die am besten geeignete Abfragemethode weiterzuleiten, basierend auf der Frage selbst. Der LLM-Knoten analysiert die Anfrage und kann sie auf der Grundlage von Schlüsselwörtern oder der Struktur der Frage an bestimmte Retrieval-Knoten weiterleiten.
Beispiel 1: Fragen, die sachliche Antworten erfordern, könnten an einen Knoten für die Dokumentensuche weitergeleitet werden, der eine vorindizierte Wissensdatenbank durchsucht (unterstützt durch Milvus).
Beispiel 2: Offene, kreative Aufforderungen könnten an das LLM für Generierungsaufgaben weitergeleitet werden.
Fallback (Corrective RAG) - Stellt sicher, dass der Agent über einen Backup-Plan verfügt, wenn seine anfänglichen Abrufmethoden keine relevanten Ergebnisse liefern. Angenommen, die anfänglichen Abfrageknoten (z. B. Abfrage von Dokumenten aus der Wissensdatenbank) liefern keine zufriedenstellenden Antworten (auf der Grundlage von Relevanzwerten oder Vertrauensschwellen). In diesem Fall greift der Agent auf einen Websuchknoten zurück.
- Der Web-Suchknoten kann externe Such-APIs nutzen.
Selbstkorrektur (Self-RAG) - Ermöglicht dem Agenten, seine eigenen Fehler oder irreführenden Ausgaben zu erkennen und zu korrigieren. Der LLM-Knoten generiert eine Antwort, die dann an einen anderen Knoten zur Auswertung weitergeleitet wird. Dieser Bewertungsknoten kann verschiedene Techniken verwenden:
Reflection: Der Agent kann seine Antwort mit der ursprünglichen Anfrage abgleichen, um zu sehen, ob sie alle Aspekte berücksichtigt.
Vertrauenswürdigkeitswert-Analyse: Der LLM kann seiner Antwort einen Vertrauenswert zuweisen. Liegt der Wert unter einem bestimmten Schwellenwert, wird die Antwort zur Überarbeitung an den LLM zurückgeleitet.
Allgemeine Ideen für Agenten
Reflexion- Der Selbstkorrekturmechanismus ist eine Form der Reflexion, bei der der LangGraph-Agent über seine Abfrage und seine Generationen nachdenkt. Er führt Informationen zur Auswertung zurück und ermöglicht dem Agenten eine Form von rudimentärer Reflexion, die seine Ausgabequalität mit der Zeit verbessert.
Der im Graphen dargestellte Kontrollfluss ist eine Form der Planung. Der Agent reagiert nicht nur auf die Anfrage, sondern legt einen schrittweisen Prozess fest, um die beste Antwort zu finden oder zu generieren.
Werkzeugverwendung- Der Kontrollfluss des LangGraph-Agenten enthält spezifische Knoten für verschiedene Werkzeuge. Dazu können Abfrageknoten für die Wissensbasis (z.B. Milvus) gehören, die seine Fähigkeit demonstrieren, einen riesigen Informationspool anzuzapfen, und Websuchknoten für externe Informationen.
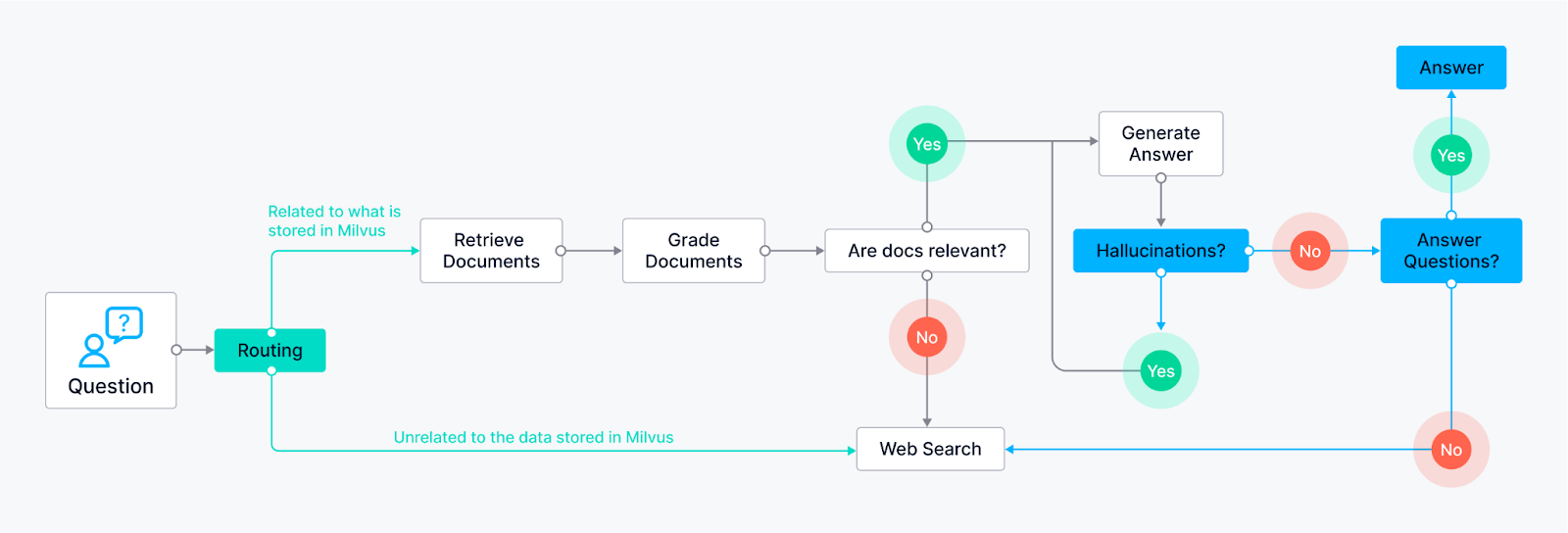
Beispiele für Agenten
Um die Fähigkeiten unserer LLM-Agenten zu demonstrieren, wollen wir uns zwei Schlüsselkomponenten ansehen: den Hallucination Grader und den Answer Grader. Während der vollständige Code am Ende dieses Beitrags verfügbar ist, werden diese Ausschnitte ein besseres Verständnis dafür vermitteln, wie diese Agenten innerhalb des LangChain-Frameworks funktionieren.
Halluzination Grader
Der Hallucination Grader versucht, ein häufiges Problem mit LLMs zu lösen: Halluzinationen, bei denen das Modell Antworten generiert, die zwar plausibel klingen, aber keine sachliche Grundlage haben. Dieser Agent fungiert als Faktenprüfer, der prüft, ob die Antwort des LLMs mit einem vorgegebenen Satz von aus Milvus abgerufenen Dokumenten übereinstimmt.
### Halluzination Grader
# LLM
llm = ChatOllama(model=local_llm, format="json", temperature=0)
# Prompt
prompt = PromptTemplate(
template="""Sie sind ein Bewerter, der beurteilt, ob
eine Antwort auf einer Reihe von Fakten beruht bzw. von ihnen gestützt wird. Geben Sie eine binäre Bewertung 'ja' oder 'nein' ab, um anzugeben
ob die Antwort auf einer Reihe von Fakten basiert/gestützt ist. Geben Sie die binäre Bewertung als JSON mit einem
einzelnen Schlüssel 'score' und ohne Präambel oder Erklärung.
Hier sind die Fakten:
{Dokumente}
Hier ist die Antwort:
{Generation}
""",
input_variables=["Generation", "Dokumente"],
)
hallucination_grader = prompt | llm | JsonOutputParser()
hallucination_grader.invoke({"documents": docs, "generation": generation})
Antwort-Grader
Nach dem Halluzinations-Grader tritt ein weiterer Agent auf den Plan. Dieser Agent prüft einen weiteren entscheidenden Aspekt: Er stellt sicher, dass die Antwort des LLMs direkt auf die ursprüngliche Frage des Nutzers eingeht. Er verwendet denselben LLM, aber mit einer anderen Aufforderung, die speziell dafür entwickelt wurde, die Relevanz der Antwort für die Frage zu bewerten.
def grade_generation_v_documents_and_question(state):
"""
Legt fest, ob die Generierung im Dokument begründet ist und Fragen beantwortet.
Args:
state (dict): Der aktuelle Zustand des Graphen
Rückgabe:
str: Entscheidung für den nächsten aufzurufenden Knoten
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
dokumente = zustand["dokumente"]
generation = status["generation"]
score = hallucination_grader.invoke({"documents": documents, "generation": generation})
Note = score['score']
# Halluzination prüfen
wenn Note == "ja":
print("---Entscheidung: GENERATION IST IN DOKUMENTE GEBUNDEN---")
# Fragebeantwortung prüfen
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"Frage": Frage, "Generation": Generation})
Note = score['score']
if grade == "yes":
print("---Entscheidung: GENERATION BEANTWORTET FRAGE---")
return "nützlich"
else:
print("---Entscheidung: GENERATION ERFOLGT NICHT DER FRAGE---")
return "nicht nützlich"
sonst:
print("---Entscheidung: GENERATION IST NICHT DURCH DOKUMENTE GESTÜTZT, WIEDERVERSUCH---")
return "nicht unterstützt"
Sie können im obigen Code sehen, dass wir die Vorhersagen des LLM, den wir als Klassifikator verwenden, überprüfen.
Kompilieren des LangGraph-Graphen
Dies kompiliert alle Agenten, die wir definiert haben, und macht es möglich, verschiedene Werkzeuge für Ihr RAG-System zu verwenden.
# Kompilieren
app = workflow.compile()
# Testen
von pprint importieren pprint
inputs = {"Frage": "Was ist Prompt Engineering?"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f "Beendete Ausführung: {Schlüssel}:")
pprint(wert["generation"])
'Beendete Ausführung: Erzeugung:'
('Prompt Engineering ist der Prozess der Kommunikation mit Large Language '
''Modellen (LLMs), um deren Verhalten in Richtung gewünschter Ergebnisse zu lenken, ohne '
'die Modellgewichte zu aktualisieren. Der Schwerpunkt liegt dabei auf der Ausrichtung und der Steuerbarkeit des Modells, '
''erfordert Experimente und Heuristiken aufgrund der unterschiedlichen Auswirkungen zwischen '
'Modellen. Das Ziel ist die Verbesserung der steuerbaren Texterzeugung durch Optimierung '
' 'Prompts für bestimmte Anwendungen.')
Schlussfolgerung
In diesem Blogbeitrag haben wir gezeigt, wie man ein RAG-System mit Agenten mit LangChain/ LangGraph, Llama 3.2 und Milvus aufbaut. Diese Agenten machen es möglich, dass LLMs über Planungs-, Speicher- und verschiedene Werkzeugnutzungsfähigkeiten verfügen, was zu robusteren und informativeren Antworten führen kann.
Nächste Schritte zur Verbesserung
Während die derzeitige Implementierung des agentic RAG Systems für lokale Einzelagenten-Workflows effektiv ist, gibt es mehrere spannende Richtungen für weitere Verbesserungen und Innovationen.
Multi-Agenten-Koordination: Zurzeit wird LangGraph verwendet, um Einzel-Agenten-Systeme zu entwerfen, die innerhalb eines vordefinierten Kontrollflusses arbeiten, wie z.B. eine Websuche. Es wäre jedoch eine natürliche Weiterentwicklung, dieses System so zu erweitern, dass es mehrere Agenten unterstützt, die parallel oder koordiniert arbeiten. In Szenarien, in denen eine Aufgabe spezielles Wissen oder mehrere Abfragequellen erfordert, können Agenten verschiedene Teile der Aufgabe gemeinsam bearbeiten. So könnte sich beispielsweise ein Agent auf das Abrufen von Sachinformationen konzentrieren, während ein anderer kreative Aufgaben oder die Benutzerinteraktion übernimmt und ein dritter die Gesamtqualität der Ausgabe bewertet. Solche Multi-Agenten-Systeme würden komplexere Operationen ermöglichen, die zu einer höheren Effizienz und Genauigkeit bei der Bearbeitung verschiedener Anfragen führen.
Echtzeitdaten** Aktualisierungen:** Eine weitere mögliche Verbesserung könnte darin bestehen, dass die Agenten ihre Datenquellen in Echtzeit aktualisieren können. Derzeit dient Milvus Lite als statische Wissensbasis; in dynamischen Bereichen können die Informationen jedoch schnell veraltet sein. Agenten könnten so konzipiert werden, dass sie ihren lokalen Vektorspeicher kontinuierlich überwachen und mit frischen Daten aus dem Internet oder anderen APIs aktualisieren, um sicherzustellen, dass die Ergebnisse des Systems relevant und aktuell bleiben. Wird ein Agent beispielsweise nach den neuesten Börsenkursen oder aktuellen Nachrichten gefragt, könnte er automatisch die neuesten Daten abrufen, wodurch das System in schnelllebigen Umgebungen viel anpassungsfähiger und nützlicher wird.
Verbesserte Reflexion und Selbstverbesserung: Während der derzeitige Reflexionsmechanismus nützlich ist, gibt es Raum für Verbesserungen in Bezug auf die Selbstkorrektur. Zukünftige Versionen des Agenten könnten fortschrittlichere Techniken beinhalten, wie z. B. Verstärkungslernen oder kontinuierliche Lernmechanismen, die es dem Agenten ermöglichen, im Laufe der Zeit aus seinen vergangenen Erfahrungen und Fehlern zu lernen. Indem wir den Agenten in die Lage versetzen, seine Antwortqualität iterativ zu verbessern, könnten wir ein System schaffen, das nicht nur qualitativ hochwertige Antworten abruft und erzeugt, sondern auch seine Prozesse auf der Grundlage von Rückmeldungen verfeinert.
Durch diese nächsten Schritte können wir die Fähigkeiten von agentenbasierten RAG-Systemen erheblich verbessern und sie flexibler, anpassungsfähiger und effektiver bei der Lösung komplexer Aufgaben in einer Vielzahl von Branchen machen.
Sie können sich den Code im [Milvus Bootcamp Repository] (https://github.com/milvus-io/bootcamp/tree/master/bootcamp/RAG/advanced_rag) ansehen.
Wenn Ihnen dieser Blog-Beitrag gefallen hat, geben Sie uns doch einen Stern auf , und teilen Sie Ihre Erfahrungen mit der Community, indem Sie sich unserem
Dies ist inspiriert von dem Github Repository von Meta mit Rezepten für die Verwendung von Llama 3

Weiterlesen

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.

Announcing the General Availability of Zilliz Cloud BYOC on Google Cloud Platform
Zilliz Cloud BYOC on GCP offers enterprise vector search with full data sovereignty and seamless integration.

OpenAI o1: What Developers Need to Know
In this article, we will talk about the o1 series from a developer's perspective, exploring how these models can be implemented for sophisticated use cases.